
A realidade do tráfego
de IA e bots
O que 10 bilhões de solicitações, crawlers fora de controle e a infraestrutura WordPress revelam sobre a nova realidade do tráfego de bots.

Ir para uma seção
Suas análises estão mentindo para você: uma parte significativa do “tráfego” do seu site não é humana.
Grande parte dos conselhos disponíveis não tem ajudado muito. Dizem para você bloquear tudo ou permitir tudo porque IA é o futuro. Nenhuma dessas abordagens realmente ajuda a gerenciar um site WordPress.
Ao longo do último ano, o tráfego de bots se tornou muito mais do que apenas uma questão de segurança ou SEO. Agora, é uma questão de infraestrutura. Crawlers estão acessando endpoints dinâmicos, entrando em loops de strings de consulta, ignorando cache e criando padrões de tráfego que se parecem menos com indexação normal e mais com automações descontroladas em larga escala.
Algumas descobertas importantes
Para entender o que mudou, analisamos pesquisas do setor, conversamos com engenheiros e especialistas da área e analisamos mais de 10 bilhões de solicitações em toda a infraestrutura gerenciada pela Kinsta. O que surgiu não foi um argumento para bloquear ou permitir tudo, mas sim um caminho para decisões melhores.
Insights dos
nossos colaboradores
“Sob a perspectiva da infraestrutura, não existe "apenas tráfego de bots". Cada solicitação representa trabalho real. Em escala, crawling ineficiente deixa de ser um problema de tráfego e passa a ser um problema de consumo de recursos.”
“A maior parte do que estamos vendo não é maliciosa. São bots se comportando de forma ineficiente em escala, e é aí que os verdadeiros problemas começam.”
“O equívoco é pensar que o tráfego de bots é um problema simples de ‘bloquear ou permitir’. Na realidade, trata-se de política, visibilidade e controle econômico.”
Mais bots não são o problema.
O que mudou é como eles se comportam.
Durante anos, a conversa sobre tráfego de bots focou no volume.
As equipes monitoravam quanto do tráfego era automatizado, filtravam os agentes maliciosos mais óbvios e seguiam em frente. Essa abordagem funcionava quando a maioria dos bots se comportava de forma previsível, rastreando páginas, indexando conteúdo e indo embora.
Esse modelo não funciona mais. Nos últimos dois anos, bots desenvolvidos não apenas para indexar conteúdo para resultados de pesquisa, mas também para ingerir conteúdo em larga escala para treinamento de modelos, geração aumentada por recuperação e consultas acionadas por usuários inundaram a web. Esses crawlers são mais agressivos, mais rápidos e muito menos comportados do que qualquer coisa que existia antes.
No final de 2025, crawlers de IA representavam 4,2% das solicitações HTML na rede do Cloudflare e, quando combinados com o tráfego de crawlers como o Googlebot, esse número chegou a 8,5%. Ao mesmo tempo, equipes que operam e gerenciam sites começaram a observar padrões como solicitações repetidas, loops e acessos em alto volume a endpoints sem valor de indexação que não se pareciam em nada com rastreamento tradicional.
Esses 4,2% são uma média anual. O número real variou de 2,4% no início de abril a 6,4% no fim de junho (uma variação de quase 3x dentro de um mesmo ano). Só o GPTBot cresceu 305% entre maio de 2024 e maio de 2025. De toda a atividade de rastreamento de IA, 80% é exclusivamente para treinamento de modelos (não para pesquisa ou consultas de usuários). Isso não gera tráfego de referência para o seu site.
Relatório Anual Cloudflare Radar 2025
Somente o Googlebot representa cerca de 4,5% do tráfego HTML, mais do que todos os bots de IA não pertencentes ao Google combinados. Ele rastreou 11,6% das páginas web únicas, em comparação com os 3,6% do GPTBot, e atingiu um pico de 11% de todas as solicitações HTML no final de abril. Bloqueá-lo para reduzir a carga do servidor seria uma das decisões mais contraproducentes que um proprietário de site poderia tomar.
Relatório Anual Cloudflare Radar 2025
O panorama geral
A maioria dos bots não está atacando.
Eles estão apenas presos em loops.
A maior parte dos crawlers de IA foi desenvolvida para seguir todos os links encontrados e registrar cada endereço de página único. Essa abordagem funciona bem em sites simples. Mas sites modernos, especialmente lojas eCommerce, geram URLs ligeiramente diferentes para praticamente a mesma página.
Por exemplo, a equipe observou o meta-externalagent, crawler de IA do Facebook/Meta, percorrendo repetidamente variações de query strings em vários sites. Para um humano, um link de carrinho com diferentes quantidades ou uma página de calendário com ordenação diferente parecem a mesma página. Para um bot seguindo URLs, cada uma delas parece completamente nova.
Então o bot segue o primeiro link… essa página gera outra variação, que o bot também segue. E depois outra. E outra… Ele não consegue reconhecer que está preso em um loop, e alguns desses loops ficaram vários dias sem ser detectados antes que regras da infraestrutura os identificassem.
Esse tipo de comportamento nem sempre vem de sistemas altamente sofisticados.
Como destaca David Belson, do Cloudflare, nem todos os bots operam com o mesmo nível de disciplina: “Tem gente que ontem nem sabia o que estava fazendo, mas hoje criou um bot no vibe coding e soltou ele na internet, sem nem se preocupar em verificar o robots.txt.”
7,67 milhões de solicitações atingiram URLs de adicionar ao carrinho em 24 horas
Até mesmo o crawler do Google, aquele que você absolutamente não pode bloquear, caiu na mesma armadilha.
Para você ter uma ideia, 3,75 milhões de solicitações em 24 horas equivalem aproximadamente a uma solicitação a cada 23 milissegundos, durante todo o dia e toda a noite, cada uma tratada pelo servidor como uma nova solicitação, e não como algo que pode ser armazenado em cache.
Em escala, esse tipo de comportamento nem sempre é intencional.
Você não pode simplesmente sair disparando solicitações sem critério, precisa agir como um usuário final responsável", explica Belson. "Você não pode bombardear um site com solicitações.
Seu servidor não sabe que está
falando com um bot
O comportamento em si não é o problema. Se cada solicitação tivesse um custo baixo, loops e visitas repetidas não seriam um problema tão grande.
Em uma página estática simples, a maioria das solicitações pode ser atendida pelo cache. O servidor retorna uma versão armazenada em cache da página, e o custo por solicitação permanece baixo.
Esse modelo logo deixa de funcionar em sites WordPress reais, especialmente aqueles que utilizam WooCommerce, pesquisa, filtros ou muitos plugins.
Uma grande parte do tráfego nem sequer acessa páginas estáticas. Ela acessa endpoints como:
Eles não podem ser armazenados em cache da mesma forma. Eles exigem que o servidor execute trabalho real a cada solicitação.
Cada solicitação aciona
Uma thread PHP fica reservada durante toda a duração de cada solicitação. Sob carga contínua de bots, as threads se esgotam e os visitantes legítimos precisam esperar.
Páginas dinâmicas consultam o banco de dados a cada carregamento. Nenhuma camada de cache dá conta nessa escala.
Páginas de carrinho e checkout criam ou validam sessões, adicionando processamento extra mesmo para bots que nunca convertem.
O custo para o SEO
Isso é um ataque? Atividade normal de bots? Algo entre os dois? Essa ambiguidade é exatamente o que torna o problema difícil de resolver. Como os mesmos padrões afetam tanto o desempenho quanto a descoberta de conteúdo, a resposta correta depende do que você está tentando proteger.
Escolha o que você
está otimizando
Depois de entender como os bots se comportam e o impacto que podem causar, a reação natural é: bloqueie-os. Mas bloquear bots indiscriminadamente não é a resposta, assim como também não é deixar a porta completamente aberta.
Como Belson diz: "Você precisa dar o primeiro passo e colocar alguém na porta para decidir quem entra e quem não entra."
Nem todos os bots são prejudiciais, e nem todo tráfego deve ser tratado da mesma forma. Alguns bots ajudam na descoberta de conteúdo, alguns consomem recursos sem gerar valor, e outros ficam em algum ponto entre esses extremos.
Mesmo no nível da rede, o objetivo não é eliminar completamente os bots. "Eu não sou o tipo de pessoa que diria para alguém bloquear todos os bots", afirma Belson. "Existe valor real em parte desse tráfego."
O desafio agora não é decidir se os bots são bons ou ruins. É entender como diferentes decisões afetam seu site e quais impactos você está disposto a aceitar.
Como explica Cristian Lopez, Editor Executivo da HostingAdvice: "O equívoco é pensar que isso é simplesmente uma questão de bloquear ou permitir. Na realidade, trata-se de política, visibilidade e controle econômico."
Descoberta de conteúdo e desempenho
Os crawlers de pesquisa são essenciais para ajudar as pessoas a encontrarem seu site, mas nem sempre operam de forma eficiente, o que exige equilíbrio. Bloqueá-los de forma agressiva pode limitar sua visibilidade nos resultados de pesquisa, enquanto permitir acesso irrestrito pode introduzir carga desnecessária, especialmente quando eles começam a acessar páginas dinâmicas que exigem processamento real em vez de serem atendidas pelo cache.
O objetivo não é escolher um ou outro, mas controlar quanto de cada tipo de tráfego você permite, com base no comportamento real do seu site.
Acesso e custo de recursos
Alguns bots oferecem valor indireto, como sistemas de IA que utilizam seu conteúdo como referência, ferramentas que indexam suas páginas ou serviços que agregam dados da web. Mas cada solicitação tem um custo em termos de uso de CPU, consultas ao banco de dados, memória e largura de banda. À medida que essa atividade aumenta, esses custos deixam de ser insignificantes, se acumulam e começam a gerar um impacto perceptível.
Nem todo acesso precisa ser liberado sem restrições. O valor que um bot oferece deve ser ponderado em relação ao custo que ele gera.
Controle e simplicidade
Em casos simples, a automação pode gerenciar bots com eficiência, mas a abordagem correta depende do tipo de site que você administra, do tipo de tráfego que está recebendo e do que é mais importante para seus objetivos. Confiar totalmente na automação pode simplificar as coisas, mas também significa que você não está definindo como essas decisões são tomadas para o seu site.
Os melhores sistemas não obrigam você a escolher entre facilidade e controle. Eles permitem começar de forma simples e fazer ajustes onde realmente importa.
Essa sobreposição gera confusão. Picos de tráfego, quedas de desempenho e situações em que nem sempre está claro se o melhor é bloquear, permitir ou ignorar, mesmo quando se trata do mesmo padrão em dois sites diferentes.
"Devo permitir bots?"
"Quais bots, em quais partes do meu site e sob quais condições?"
Responder a essa pergunta exige uma forma diferente de pensar. É isso que exploramos na próxima seção.
Uma maneira melhor de decidir o que
permitir, verificar ou bloquear
Não existe uma política universal para bots que funcione para todos os sites. Uma loja WooCommerce, um site de conteúdo, um site empresarial e um ambiente de teste enfrentam riscos diferentes e não exigem as mesmas soluções.
A abordagem correta depende do que o seu site faz, do tipo de tráfego que recebe e do que você está tentando otimizar. Na maioria dos casos, essas decisões são gerenciadas por ferramentas de infraestrutura, e não por regras configuradas manualmente para cada solicitação. Ainda assim, entender a lógica por trás dessas decisões ajuda você a saber o que está sendo decidido por você e quando faz sentido fazer ajustes.
O que importa aqui não é apenas o tráfego, mas também o tipo de visibilidade que você deseja, seja nos resultados de pesquisa, nas citações por IA ou nas visitas diretas de usuários
Seus problemas de desempenho provavelmente estão relacionados a bots acessando os endpoints de adicionar ao carrinho e checkout do WooCommerce. Eles ignoram completamente o cache de página e forçam a execução de PHP e consultas ao banco de dados em cada solicitação. A solução não é bloquear tudo. O objetivo é proteger caminhos específicos de alto custo.
/cart, /checkout e ?add-to-cart= por meio do robots.txt/shop?add-to-cart= e /checkout por meio do robots.txt./shop/, /product/ e páginas de categorias para que sua loja apareça nos resultados de pesquisa. Restrinja o acesso apenas a endpoints dinâmicos específicos, não ao site inteiro.As configurações acima representam como o gerenciamento do tráfego de bots seria feito manualmente. Na prática, a Proteção contra Bots da Kinsta gerencia automaticamente a maioria desses padrões. Basta habilitar o nível de proteção desejado e nosso sistema cuida do restante, sem necessidade de regras por solicitação ou exceções configuradas manualmente.
A maioria dos sistemas não foi projetada
para este nível de controle.
A maioria das plataformas gerencia o tráfego de bots automaticamente, tomando decisões nos bastidores, ou disponibiliza controles que exigem configuração manual.
Sistemas automáticos identificam ameaças óbvias e permitem crawlers conhecidos, mas não levam em consideração como o tráfego se comporta em partes específicas do seu site nem qual é o custo desse tráfego em cada contexto. Em alguns casos, crawlers legítimos de IA são bloqueados na borda da rede, criando um ponto cego de descoberta que a maioria das equipes nem percebe.
Os controles manuais oferecem mais flexibilidade. Mas geralmente exigem um nível de precisão que a maioria dos proprietários de sites não tem tempo para gerenciar continuamente. E, sem orientação, são fáceis de configurar incorretamente.
O que está faltando não é apenas controle, mas controle utilizável.
A capacidade de ajustar o comportamento onde isso realmente importa, sem interromper tráfego essencial e sem precisar reconstruir toda a sua estratégia sempre que algo mudar.
A maioria dos sites não precisa de automação total nem de controle total. Precisa da capacidade de tomar decisões direcionadas sem ter que reconstruir toda a estratégia de tráfego sempre que os padrões mudam.
Nesse ponto, o desafio não é identificar tráfego de bots. É gerenciá-lo de uma forma que reflita como seu site realmente funciona.
Como agir da forma certa
em diferentes situações
Neste ponto, o padrão já está claro: não existe uma única regra que funcione em todos os lugares. A resposta correta depende do tipo de site que você administra, do tipo de tráfego que está observando e da urgência da situação.
O que vem a seguir não é uma checklist. É uma forma de pensar sobre o que fazer a seguir com base em onde você está agora.
Comece com visibilidade e, em seguida, tome uma decisão direcionada
Antes de fazer alterações, analise do que seu tráfego é realmente composto. Você não está tentando identificar cada bot individualmente. Está procurando padrões: solicitações repetidas para os mesmos tipos de URLs, especialmente aquelas que não deveriam ser relevantes para um crawler, como endpoints de carrinho ou páginas com muitos parâmetros. A maioria das ferramentas de análise ou logs do servidor oferece visibilidade suficiente para identificar esse tipo de atividade.
A maioria das plataformas já filtra os padrões mais claramente problemáticos, como loops evidentes ou tráfego abusivo conhecido. Certifique-se de que essas proteções básicas estejam ativas e dê tempo para fazerem efeito. Elas costumam ser conservadoras por padrão, o que significa que reduzem o ruído sem afetar visitantes legítimos ou crawlers de busca.
Quando identificar um padrão, aja sobre ele, não sobre tudo ao mesmo tempo. Se bots estiverem acessando repetidamente endpoints dinâmicos, limite o acesso a esses caminhos. Se determinados crawlers estiverem coletando conteúdo de forma agressiva, avalie se esse acesso compensa o custo. O objetivo nesta etapa não é alcançar a perfeição, mas reduzir a carga desnecessária sem criar novos problemas.
Aplique esse processo em alguns sites de clientes diferentes. Os padrões observados em uma loja de eCommerce, em um site de conteúdo e em um site de serviços serão diferentes, mas consistentes o suficiente para criar uma abordagem repetível para conversas com clientes.
O tráfego de bots não vai desaparecer.
Sua estratégia deve evoluir com ele
Neste ponto, o padrão já está claro. O tráfego de bots não é mais algo que você pode tratar como ruído ocasional ou simplesmente filtrar nas bordas. Ele é uma parte constante e em evolução da forma como os sites são acessados e sobrecarregados.
O que torna isso difícil não é apenas o volume, mas a sobreposição. Os mesmos sistemas que ajudam as pessoas a encontrar seu site também podem consumir seus recursos, e padrões que parecem rastreamento normal podem se comportar como automação ineficiente em larga escala.
Por isso, não existe uma única regra que funcione em todos os casos.
A abordagem correta depende do seu site, do seu tráfego e do que você está tentando proteger. Ela exige compreender como seu site realmente se comporta e tomar decisões que reflitam essa realidade.
Esse tipo de mudança não é totalmente novo na evolução da web. Como disse Jordan Sprogis, especialista colaborador da HostingAdvice: "Não é tão diferente da época em que o SSL era um complemento pago de longo prazo... agora, certificados SSL estão incluídos em praticamente qualquer pacote de hospedagem."
Na maioria das vezes, o objetivo é reduzir a carga desnecessária, preservar a visibilidade onde ela realmente importa e manter um sistema confiável à medida que as coisas mudam. O que vem a seguir será mais difícil de categorizar. O tráfego agentic, ferramentas automatizadas projetadas para executar ações, já está aparecendo nos dados de infraestrutura. Recentemente, o Google anunciou um user-agent dedicado para registrar quando seus agentes de IA interagem com sites. As plataformas responsáveis se identificarão, respeitarão atrasos de rastreamento e evitarão sobrecarregar endpoints que não oferecem valor algum. Outras não farão isso. A diferença entre um visitante humano e um agente continuará ficando cada vez mais difícil de identificar.
E quando o tráfego automatizado infla suas contagens de visitas, os números brutos deixam de refletir a realidade. Os sinais que realmente importam são os correlacionados: volume de buscas pela marca, tráfego direto, qualidade do engajamento e receita associada ao comportamento de visitantes reais. Se essas métricas também estiverem crescendo, você sabe que está visível onde realmente importa.
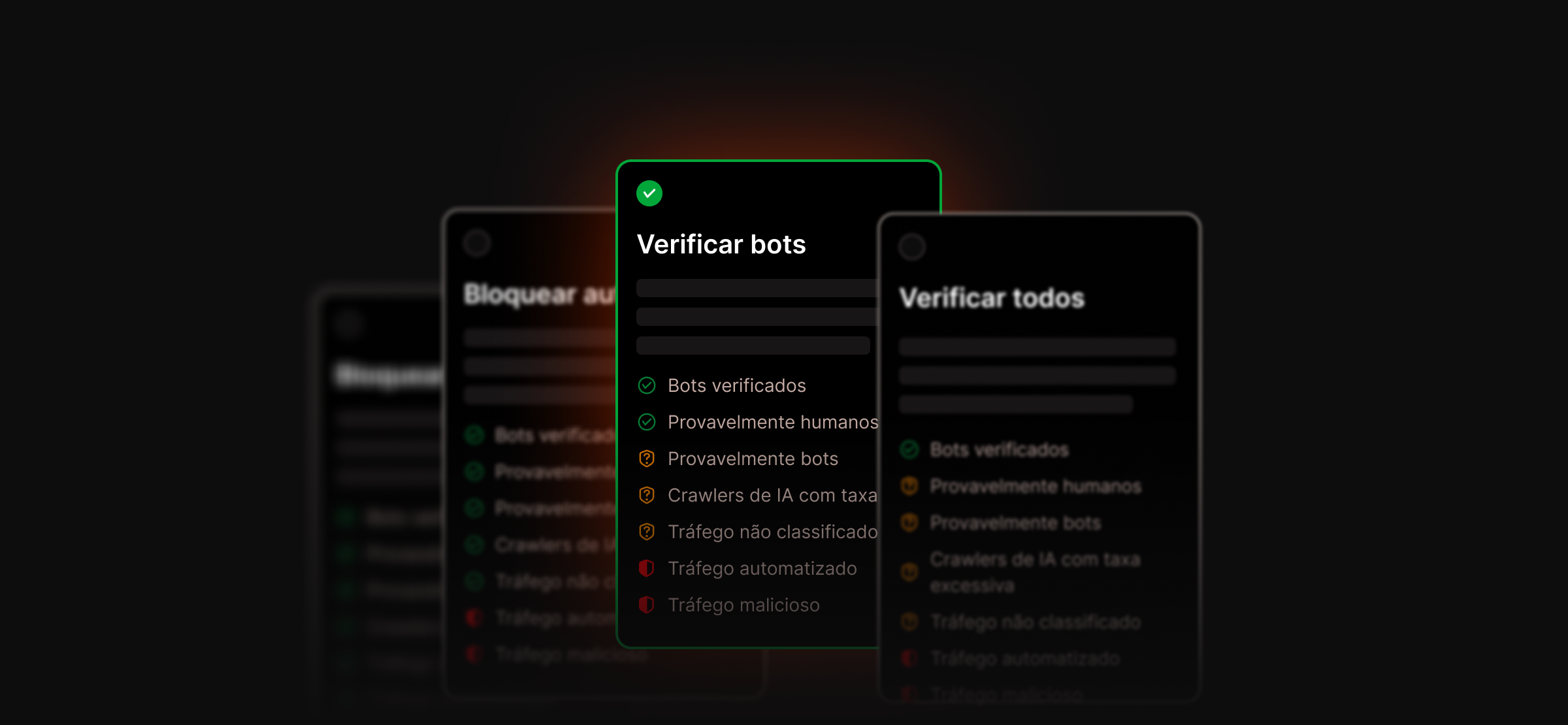
Controle como os bots interagem com seu site WordPress sem comprometer sua visibilidade nos mecanismos de pesquisa.
A Proteção contra Bots da Kinsta oferece controle em nível de ambiente com configurações inteligentes por padrão, permitindo que você gerencie como diferentes tipos de tráfego interagem com seu site sem bloquear mecanismos de busca nem comprometer sua visibilidade. Incluído em todos os planos.
Este relatório foi apresentado pela Kinsta.
A Kinsta é uma plataforma premium de hospedagem gerenciada para WordPress, com mais de 230.000 clientes em todo o mundo. Nº 1 no G2 em satisfação. Suporte especializado 24/7/365, em 10 idiomas.