
Le trafic lié à l'IA et aux bots
vérification de la réalité
Ce que 10 milliards de requêtes, des robots d'exploration défaillants et l'infrastructure WordPress révèlent sur la nouvelle réalité du trafic des robots.

Aller à une section
Vos analyses vous trompent : une part importante du « trafic » de votre site web n'est pas humaine.
La plupart des conseils que j'ai trouvés ne m'ont pas beaucoup aidé. On me dit soit de tout bloquer, soit de tout autoriser car l'IA représente l'avenir. Aucune de ces solutions ne permet de gérer efficacement un site WordPress.
Au cours de l'année écoulée, le trafic des robots d'exploration est devenu bien plus qu'un simple problème de sécurité ou de référencement. Il s'agit désormais d'un problème d'infrastructure. Les robots d'exploration interrogent des points de terminaison dynamiques, se retrouvent piégés dans des boucles de requêtes, contournent le cache et génèrent des schémas de trafic qui ressemblent moins à une indexation normale qu'à une automatisation défaillante à grande échelle.
Quelques conclusions clés
Pour comprendre ce qui a changé, nous avons examiné des études sectorielles, discuté avec des ingénieurs et des praticiens, et analysé plus de 10 milliards de requêtes sur l'infrastructure gérée par Kinsta. Il en est ressorti qu'il ne s'agissait pas de tout bloquer ou de tout autoriser, mais plutôt de faire preuve de discernement.
Points de vue de
nos contributeurs
“Du point de vue de l'infrastructure, le terme « trafic de robots uniquement » n'existe pas. Chaque requête représente un véritable travail. À grande échelle, l'exploration inefficace cesse d'être un problème de trafic et devient un problème de ressources.”
“La plupart des comportements observés ne sont pas malveillants. Il s'agit de robots qui agissent de manière inefficace à grande échelle, et c'est là que les véritables problèmes commencent.”
“L'erreur consiste à croire que le trafic des robots se résume à un simple problème de « blocage ou d'autorisation ». En réalité, il s'agit de politiques, de visibilité et de contrôle économique.”
Le problème n'est pas le nombre de robots.
Ce qui a changé, c'est leur comportement.
Pendant des années, le débat sur le trafic des robots s'est concentré sur le volume.
Les équipes ont suivi le niveau d'automatisation, éliminé les robots malveillants les plus évidents et poursuivi leurs efforts. Cette approche a fonctionné lorsque la plupart des robots se comportaient de manière prévisible : ils exploraient les pages, indexaient le contenu et quittaient les lieux.
Ce modèle est désormais obsolète. Ces deux dernières années, le web a été envahi par des robots conçus non seulement pour indexer le contenu dans les résultats de recherche, mais aussi pour l'ingérer à grande échelle afin d'entraîner des modèles, de générer du contenu enrichi par la recherche et de répondre aux demandes des utilisateurs. Ces robots d'exploration sont plus voraces, plus rapides et, fondamentalement, beaucoup moins bien conçus que tous ceux qui les ont précédés.
Fin 2025, les robots d'exploration IA représentaient 4,2 % des requêtes HTML sur le réseau Cloudflare, et avec le trafic combiné de robots comme Googlebot, ce chiffre atteignait 8,5 %. Parallèlement, les équipes en charge de l'administration des sites web ont commencé à observer des anomalies telles que des requêtes répétées, des boucles et un volume élevé de requêtes sur des points de terminaison à faible valeur ajoutée, des comportements qui ne ressemblaient en rien à une exploration traditionnelle.
Ce taux de 4,2 % est une moyenne annuelle. Le chiffre réel a fluctué entre 2,4 % début avril et 6,4 % fin juin (soit une variation de près de 3 fois en un an). GPTBot, à lui seul, a connu une croissance de 305 % entre mai 2024 et mai 2025. Sur l'ensemble des activités d'exploration par IA, 80 % sont exclusivement consacrées à l'entraînement des modèles (et non à la recherche ou aux requêtes des utilisateurs). Elles ne génèrent aucun trafic de référence vers votre site.
Bilan annuel de Cloudflare Radar 2025
Googlebot représente à lui seul environ 4,5 % du trafic HTML, soit plus que tous les autres robots d'intelligence artificielle hors Google réunis. Il a exploré 11,6 % des pages web uniques, contre 3,6 % pour GPTBot, et a atteint un pic de 11 % des requêtes HTML fin avril. Le bloquer pour alléger la charge du serveur serait la décision la plus contre-productive qu'un propriétaire de site puisse prendre.
Bilan annuel de Cloudflare Radar 2025
Le tableau d'ensemble
La plupart des robots n'attaquent pas.
Ils sont juste bloqués.
La plupart des robots d'exploration IA sont conçus pour suivre chaque lien et enregistrer chaque adresse de page unique. Cette approche fonctionne bien sur les sites simples. Mais les sites web modernes, notamment les sites de commerce électronique, génèrent des URL légèrement différentes pour une même page.
Par exemple, l'équipe a observé que meta-externalagent (robot d'exploration Facebook/Meta AI) parcourait de manière répétée des variations de chaînes de requête sur plusieurs sites. Pour un humain, un lien produit avec filtre de couleur, un lien panier avec quantité ou une page calendrier avec ordre de tri apparaissent comme une seule et même page. Pour un robot suivant les URL, chacune semble inédite.
Le robot suit donc le premier lien… cette page génère une autre variante, que le robot suit également. Et encore une autre. Et encore une autre… Il est incapable de se rendre compte qu'il tourne en rond, et certaines de ces boucles sont restées indétectées pendant plusieurs jours avant que les règles de l'infrastructure ne les repèrent.
Ce type de comportement ne provient pas toujours de systèmes très sophistiqués.
Comme le souligne David Belson de Cloudflare, tous les robots ne fonctionnent pas avec le même niveau de discipline : « Il y a la personne qui ne savait pas du tout ce qu’elle faisait hier, mais qui a programmé un robot au feeling aujourd’hui et l’a lâché – elle ne prend même pas la peine de vérifier le fichier robots.txt ».
7,67 millions de requêtes ont été effectuées sur les URL d'ajout au panier en 24 heures
Même le robot d'exploration de Google, celui qu'il est absolument impossible de bloquer, est tombé dans le même piège.
Pour mettre les chiffres en perspective, 3,75 millions de requêtes en 24 heures représentent environ une requête toutes les 23 millisecondes, jour et nuit, chaque requête étant traitée sur le serveur comme une nouvelle requête, plutôt que comme une requête pouvant être mise en cache.
À grande échelle, ce type de comportement n'est pas toujours intentionnel.
« On ne peut pas se contenter de bombarder un site web de requêtes… il faut se comporter comme un utilisateur responsable », explique Belson. « On ne peut pas le saturer de requêtes ».
Votre serveur ne sait pas qu'il
parle à un robot
Le comportement en lui-même n'est pas le problème. Si chaque requête était peu coûteuse, les boucles et les visites répétées n'auraient que peu d'importance.
Sur une page statique simple, la plupart des requêtes peuvent être traitées par le cache. Le serveur renvoie une version mise en cache de la page, et le coût par requête reste faible.
Ce modèle s'avère rapidement inadapté aux sites WordPress réels, en particulier ceux qui utilisent WooCommerce, la recherche, le filtrage ou des fonctionnalités nécessitant de nombreuses extensions.
Une grande partie du trafic n'atteint même pas les pages statiques. Il atteint des points de terminaison comme :
Ces données ne peuvent pas être mises en cache de la même manière. Elles nécessitent un traitement effectif du serveur à chaque fois.
Chaque déclencheur de requête
Un thread PHP (ou worker PHP) est réservé pour toute la durée de chaque requête. En cas de charge importante de robots, les threads s'épuisent et les visiteurs légitimes doivent patienter.
Les pages dynamiques interrogent votre base de données à chaque chargement. Aucune couche de cache ne peut absorber cette charge à grande échelle.
Les pages de panier et de commande créent ou valident des sessions, ce qui ajoute une surcharge même pour les robots qui ne convertissent jamais.
Le coût du référencement
S'agit-il d'une attaque ? D'une activité normale de robots ? Ou d'une situation intermédiaire ? Cette ambiguïté rend le problème difficile à résoudre. Puisque les mêmes schémas affectent à la fois les performances et la détectabilité, la réponse appropriée dépend de ce que vous cherchez à protéger.
Choisissez ce que vous
optimisez pour
Après avoir constaté le comportement des robots et leur impact potentiel, la réaction naturelle est de les bloquer. Mais bloquer les robots sans discernement n'est pas la solution, pas plus que de laisser la porte grande ouverte.
Comme le dit Belson : « Il faut faire le premier pas et mettre un videur à l'extérieur pour décider qui entre et qui ne rentre pas. »
Tous les robots ne sont pas nuisibles et tout le trafic ne doit pas être traité de la même manière. Certains robots améliorent la visibilité, d'autres consomment des ressources sans valeur ajoutée, et d'autres encore se situent entre les deux.
Même au niveau du réseau, l'objectif n'est pas d'éliminer complètement les robots. « Je ne suis pas du genre à conseiller de bloquer tous les robots », explique Belson. « Une partie de ce trafic a une réelle valeur. »
Le défi n'est plus de déterminer si les robots sont bons ou mauvais, mais de comprendre l'impact des différentes décisions sur votre site et de définir le niveau de compromis que vous êtes prêt à accepter.
Comme l'explique Cristian Lopez, rédacteur en chef chez HostingAdvice : « On se méprend en pensant qu'il s'agit simplement d'une question de « bloquer ou d'autoriser ». En réalité, c'est désormais une question de politique, de visibilité et de contrôle économique. »
Découvrabilité et performance
Les robots d'exploration des moteurs de recherche sont essentiels pour que les internautes découvrent votre site, mais leur fonctionnement n'est pas toujours optimal, ce qui nécessite un juste équilibre. Les bloquer de manière trop stricte peut limiter votre visibilité dans les résultats de recherche, tandis qu'un accès illimité peut engendrer une charge inutile, notamment lorsqu'ils accèdent à des pages dynamiques qui requièrent un traitement réel plutôt qu'un simple chargement depuis le cache.
L’objectif n’est pas de choisir l’un plutôt que l’autre, mais de contrôler la part de chacun autorisée, en fonction du comportement réel de votre site.
Coût d'accès et des ressources
Certains robots apportent une valeur ajoutée indirecte — systèmes d'IA référençant votre contenu, outils indexant vos pages ou services agrégeant des données sur le web — mais chaque requête a un coût en termes d'utilisation du processeur, de requêtes de base de données, de mémoire et de bande passante. À mesure que cette activité s'intensifie, ces coûts ne restent pas marginaux ; ils s'accumulent et finissent par avoir un impact significatif.
L'accès ne doit pas nécessairement être illimité. La valeur ajoutée d'un robot doit être mise en balance avec les coûts qu'il engendre.
Contrôle et simplicité
Dans les cas les plus simples, l'automatisation peut gérer efficacement les robots, mais la meilleure approche dépend en fin de compte du type de site que vous exploitez, du trafic que vous recevez et de vos priorités. Se fier entièrement à l'automatisation peut simplifier les choses, mais cela signifie aussi que vous ne maîtrisez pas la manière dont ces décisions sont prises pour votre site.
Les meilleurs systèmes ne vous obligent pas à choisir entre simplicité et contrôle. Ils vous permettent de commencer simplement et d'ajuster là où c'est nécessaire.
Ce chevauchement engendre de la confusion : pics de trafic, baisses de performance, et il n’est pas toujours évident de savoir s’il faut bloquer, autoriser ou ignorer, même pour un même schéma sur deux sites différents.
« Devrais-je autoriser les robots ? »
« Quels robots, sur quelles parties de mon site, et dans quelles conditions ? »
Répondre à cette question exige une approche différente. Nous l'explorerons dans la section suivante.
Une meilleure façon de décider ce qu'il faut
autoriser, contester ou bloquer
Il n'existe pas de politique anti-robots universelle applicable à tous les sites. Une boutique WooCommerce, un site de contenu, un site web d'entreprise et un environnement de staging ne sont pas exposés aux mêmes risques et ne nécessitent pas les mêmes solutions.
La meilleure approche dépend de la fonction de votre site, du type de trafic qu'il reçoit et de vos objectifs d'optimisation. Dans la plupart des cas, ce niveau de décision est géré par les outils d'infrastructure plutôt que par une configuration manuelle pour chaque requête. Toutefois, comprendre cette logique vous permet de savoir ce qui s'exécute et à quel moment il est judicieux d'apporter des modifications.
Ce qui compte ici, ce n'est pas seulement le trafic, mais le type de visibilité que vous souhaitez, qu'il s'agisse du classement dans les résultats de recherche, des citations de l'IA ou des visites directes des utilisateurs.
Vos problèmes de performance sont probablement dus à des robots qui sollicitent les points de terminaison Ajouter au panier et Commande de WooCommerce. Ces robots contournent complètement le cache de la page et forcent l'exécution de requêtes PHP et de bases de données à chaque requête. La solution ne consiste pas à tout bloquer, mais à protéger les chemins d'accès les plus gourmands en ressources.
/cart, /checkout et ?add-to-cart= via robots.txt/shop?add-to-cart= et /checkout dans robots.txt./shop, /product et les pages de catégories pour que votre boutique soit bien référencée. Limitez son accès à certains points de terminaison dynamiques uniquement, et non à l'ensemble du site.Les configurations ci-dessus illustrent la gestion manuelle du trafic des robots. En pratique, la protection anti-robots de Kinsta gère automatiquement la plupart de ces schémas. Activez le niveau de protection souhaité une seule fois, et notre système s'occupe du reste (aucune règle par chemin ni exception manuelle n'est nécessaire).
La plupart des systèmes n'ont pas été conçus
pour ce niveau de contrôle
La plupart des plateformes gèrent le trafic des robots automatiquement en prenant des décisions en arrière-plan ou proposent des contrôles nécessitant une configuration manuelle.
Les systèmes automatiques détectent les menaces évidentes et autorisent les robots d'exploration connus, mais ils ne tiennent pas compte du comportement du trafic sur certaines parties de votre site, ni de son coût dans son contexte. Dans certains cas, des robots d'exploration IA légitimes sont bloqués en périphérie, créant ainsi une zone d'ombre en matière de détection dont la plupart des équipes ignorent l'existence.
Les commandes manuelles offrent une plus grande flexibilité. Cependant, elles exigent souvent un niveau de précision que la plupart des propriétaires de sites n'ont pas le temps d'assurer en permanence. De plus, sans assistance, il est facile de les configurer incorrectement.
Ce qui manque, ce n'est pas seulement le contrôle, mais un contrôle utilisable.
La possibilité d'ajuster son comportement là où c'est nécessaire, sans interrompre le trafic essentiel et sans avoir à reconstruire toute son approche à chaque changement.
La plupart des sites n'ont pas besoin d'une automatisation ou d'un contrôle total. Ils ont besoin de pouvoir prendre des décisions ciblées sans avoir à reconstruire l'intégralité de leur stratégie de trafic à chaque évolution des tendances.
À ce stade, le défi n'est plus d'identifier le trafic des robots, mais de le gérer de manière à refléter le fonctionnement réel de votre site.
À quoi ressemble la bonne réponse
dans différentes situations
À ce stade, il est clair qu'il n'existe pas de règle unique applicable à toutes les situations. La réponse appropriée dépend du type de site que vous gérez, du trafic qu'il génère et du degré d'urgence de la situation.
Ce qui suit n'est pas une liste de contrôle. C'est une façon de réfléchir aux prochaines étapes à suivre en fonction de votre situation actuelle.
Commencez par la visibilité, puis prenez une décision ciblée
Avant d'apporter des modifications, analysez la composition de votre trafic. L'objectif n'est pas d'identifier chaque robot, mais de repérer des tendances : des requêtes répétées vers les mêmes types d'URL, notamment celles qui ne devraient pas intéresser un robot d'exploration, comme les points de terminaison de panier ou les pages contenant de nombreux paramètres. La plupart des outils d'analyse ou des journaux de serveur vous fourniront une visibilité suffisante pour détecter cette activité.
La plupart des plateformes filtrent déjà les anomalies les plus flagrantes, comme les boucles évidentes ou le trafic abusif connu. Assurez-vous que ces protections de base sont activées et laissez-leur le temps de fonctionner. Elles sont généralement conçues pour être prudentes, ce qui signifie qu'elles réduisent le bruit sans impacter les visiteurs légitimes ni les robots d'exploration des moteurs de recherche.
Une fois un schéma identifié, agissez en conséquence (pas en agissant sur tout en même temps). Si des robots sollicitent fréquemment des points de terminaison dynamiques, limitez l'accès à ces chemins. Si certains robots d'exploration extraient du contenu de manière intensive, évaluez si cet accès est justifié. À ce stade, l'objectif n'est pas la perfection, mais la réduction de la charge inutile sans créer de nouveaux problèmes.
Appliquez ce processus à plusieurs sites clients différents. Les schémas observés sur un site e-commerce, un site de contenu et un site de services seront différents, mais suffisamment cohérents pour élaborer une approche reproductible pour les échanges avec les clients.
Le trafic généré par les robots est là pour rester.
Votre stratégie devrait
À ce stade, la tendance est claire. Le trafic des robots n'est plus un simple bruit de fond occasionnel qu'on peut filtrer superficiellement. Il s'agit d'une composante constante et évolutive de l'accès aux sites web et des contraintes qu'ils subissent.
Ce qui complique la tâche, ce n'est pas seulement le volume, mais aussi le chevauchement. Les mêmes systèmes qui aident les internautes à trouver votre site peuvent également consommer ses ressources, et des comportements qui semblent relever d'une exploration normale peuvent se révéler être une automatisation inefficace à grande échelle.
Il n'existe donc pas de règle unique applicable partout.
La stratégie à adopter dépend de votre site, de son trafic et des données que vous souhaitez protéger. Elle nécessite de comprendre le fonctionnement réel de votre site et de prendre des décisions qui reflètent cette réalité.
Ce type d'évolution n'est pas totalement inédit dans l'histoire du web. Comme l'explique Jordan Sprogis, expert contributeur chez HostingAdvice : « La situation est assez similaire à celle du SSL à ses débuts : longtemps proposé en option payante, le certificat SSL est désormais inclus dans la quasi-totalité des offres d'hébergement ».
L'objectif est généralement de réduire la charge inutile, de préserver la visibilité là où elle est essentielle et de maintenir un système fiable face aux évolutions. La suite sera plus difficile à catégoriser. Le trafic généré par les agents, ces outils automatisés conçus pour agir, est déjà visible dans les données d'infrastructure. Google a récemment annoncé un user-agent dédié pour enregistrer les interactions de ses agents d'IA avec les sites. Les plateformes responsables s'identifieront, respecteront les délais d'exploration et éviteront de surcharger les points de terminaison inutiles. D'autres ne le feront pas. La frontière entre visiteur humain et agent continuera de s'estomper.
Lorsque le trafic automatisé gonfle artificiellement le nombre de visites, les chiffres bruts ne reflètent plus la réalité. Seuls les indicateurs corrélés comptent : volume de recherche de marque, trafic direct, qualité de l’engagement et revenus liés au comportement réel des visiteurs. Si ces indicateurs évoluent également, vous savez que votre visibilité est optimale.
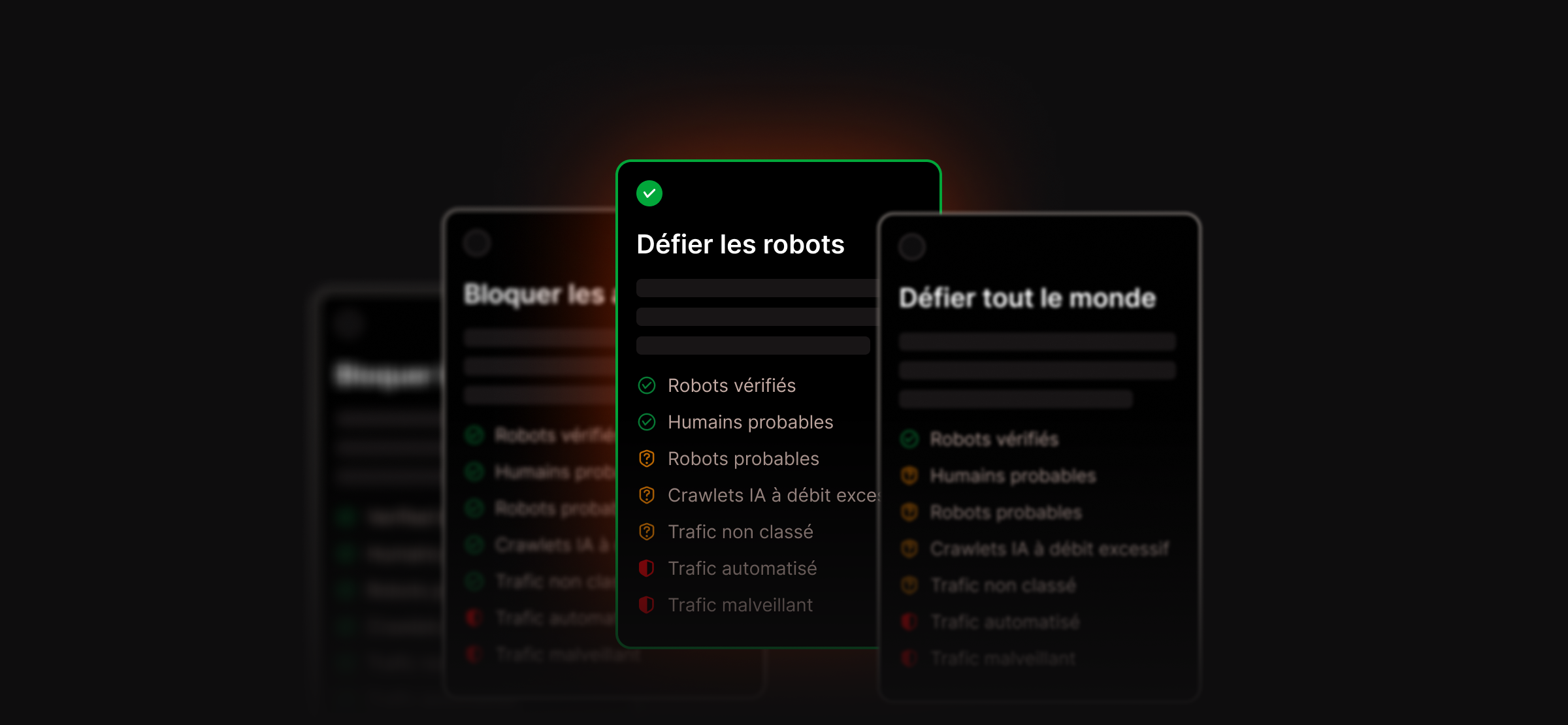
Contrôlez la manière dont les robots interagissent avec votre site WordPress sans nuire à sa visibilité dans les moteurs de recherche
La protection Kinsta contre les robots vous offre un contrôle au niveau de l'environnement avec des valeurs par défaut judicieuses, vous permettant ainsi de gérer la manière dont différents types de trafic interagissent avec votre site sans bloquer les moteurs de recherche ni compromettre la visibilité. Included in all plans.
Ce rapport vous est présenté par Kinsta.
Kinsta est une plateforme d'hébergement WordPress premium infogéré, comptant plus de 230.000 clients dans le monde. Numéro 1 sur G2 pour la satisfaction client. Support expert 24/7 en 10 langues.