
Tutta la verità
sul traffico AI & bot
Cosa rivelano 10 miliardi di richieste, crawler malfunzionanti e l'infrastruttura di WordPress sulla nuova realtà del traffico generato dai bot.

Scegli una sezione
I tuoi dati analitici ti stanno ingannando: una parte consistente del "traffico" del tuo sito web non è generata da esseri umani.
La maggior parte dei consigli che si trovano in giro non sono di grande aiuto. Ti dicono o di bloccare tutto o di consentire l'accesso a tutto perché l'intelligenza artificiale è il futuro. Nessuna delle due posizioni ti aiuta a gestire effettivamente un sito WordPress.
Nell'ultimo anno, il traffico generato dai bot è diventato molto più di una semplice questione di sicurezza o di SEO. Oggi è una questione che riguarda l'infrastruttura. I crawler raggiungono endpoint dinamici, rimangono intrappolati in loop di stringhe di query, aggirano la cache e generano modelli di traffico che assomigliano meno a una normale indicizzazione e più a un'automazione malfunzionante su larga scala.
Risultati interessanti
Per capire cosa fosse cambiato, abbiamo esaminato studi di settore, parlato con tecnici e professionisti e analizzato oltre 10 miliardi di richieste sull'infrastruttura gestita da Kinsta. Ciò che è emerso non è stata la necessità di bloccare tutto o di consentire tutto, ma piuttosto quella di usare il buon senso.
Considerazioni dei
nostri collaboratori
“Dal punto di vista dell'infrastruttura, non esiste il concetto di "è solo traffico generato dai bot". Ogni richiesta rappresenta un carico di lavoro effettivo. Su larga scala, una scansione inefficiente smette di essere un problema di traffico e diventa un problema di risorse.”
“La maggior parte di ciò che osserviamo non è di natura dannosa. Si tratta di bot che, su larga scala, funzionano in modo inefficiente, ed è proprio lì che iniziano i veri problemi.”
“L'errore comune è pensare che il traffico generato dai bot sia semplicemente una questione di "bloccare o consentire". In realtà, si tratta di politiche, visibilità e controllo economico.”
Il problema non è che ci sono più bot.
Ciò che è cambiato è il modo in cui si comportano.
Per anni, il dibattito sul traffico generato dai bot si è concentrato sul volume.
I team hanno valutato il grado di automazione, hanno scartato i casi più evidenti di attività sospette e sono passati oltre. Questo approccio funzionava quando la maggior parte dei bot si comportava in modo prevedibile, ovvero scansionando le pagine, indicizzando i contenuti e poi andandosene.
Quel modello non è più valido. Negli ultimi due anni, il web è stato invaso da bot progettati non solo per indicizzare i contenuti ai fini dei risultati di ricerca, ma anche per acquisirli su larga scala per l'addestramento dei modelli, la generazione potenziata dal recupero e le query attivate dagli utenti. Questi crawler sono più voraci, più veloci e, in sostanza, molto meno "educati" rispetto a qualsiasi cosa vista in precedenza.
Alla fine del 2025, i crawler basati sull'intelligenza artificiale rappresentavano il 4,2% delle richieste HTML sulla rete di Cloudflare e, sommando il traffico proveniente da crawler come Googlebot, tale percentuale raggiungeva l'8,5%. Allo stesso tempo, i team incaricati della gestione dei siti web hanno iniziato a notare schemi ricorrenti quali richieste ripetute, loop e accessi massicci a endpoint di scarso valore, che non sembravano affatto rientrare nella tradizionale attività di crawling.
Quel 4,2% è una media annuale. Il dato effettivo ha oscillato dal 2,4% di inizio aprile al 6,4% di fine giugno (con una crescita di quasi tre volte in un solo anno). Il solo GPTBot è cresciuto del 305% tra maggio 2024 e maggio 2025. L'80% di tutte le attività di crawling dell'IA è destinato esclusivamente all'addestramento dei modelli (non alla ricerca o alle query degli utenti). Non genera traffico di riferimento verso il tuo sito.
Cloudflare Radar 2025 Year in Review
Googlebot da solo rappresenta circa il 4,5% del traffico HTML, una percentuale superiore a quella di tutti i bot di intelligenza artificiale non Google messi insieme. Ha indicizzato l'11,6% delle pagine web uniche, contro il 3,6% di GPTBot, e ha raggiunto un picco dell'11% di tutte le richieste HTML alla fine di aprile. Bloccarlo per alleggerire il carico del server sarebbe la mossa più controproducente che chi gestisce un sito possa compiere.
Cloudflare Radar 2025 Year in Review
Il quadro generale
La maggior parte dei bot non è in modalità di attacco.
È semplicemente bloccata.
La maggior parte dei crawler basati sull'AI è progettata per seguire ogni link che trova e registrare ogni indirizzo di pagina unico. Questo approccio funziona bene sui siti semplici. Tuttavia, i siti web moderni, in particolare i negozi di e-commerce, generano URL leggermente diversi per pagine sostanzialmente identiche.
Ad esempio, il team ha osservato che meta-externalagent (il crawler di Facebook/Meta AI) ha ripetutamente analizzato diverse varianti delle stringhe di query su più siti. A un utente umano, un link a un prodotto con un filtro per colore, un link al carrello con una quantità specificata o una pagina del calendario con un ordine di visualizzazione sembrano tutti la stessa pagina. A un bot che segue gli URL, invece, ognuno di essi appare come una pagina completamente nuova.
Quindi il bot segue il primo link… quella pagina genera un'altra variante, che il bot segue. E poi un'altra. E un'altra ancora… Non ha modo di rendersi conto che sta girando a vuoto, e alcuni di questi loop sono rimasti inosservati per diversi giorni prima che le regole dell'infrastruttura li individuassero.
Questo tipo di comportamento non deriva sempre da sistemi altamente sofisticati.
Come sottolinea David Belson di Cloudflare, non tutti i bot operano con lo stesso livello di rigore: «C'è chi ieri non sapeva nemmeno cosa stesse facendo, ma oggi ha programmato un bot a braccio e l'ha lasciato libero di agire — senza nemmeno preoccuparsi di controllare il file robots.txt».
7,67 milioni di richieste raggiungono gli URL "Aggiungi al carrello" in 24 ore
Persino il crawler di Google, quello che non si può assolutamente bloccare, è caduto nella stessa trappola.
Per contestualizzare questi dati, 3,75 milioni di richieste in 24 ore equivalgono all'incirca a una richiesta ogni 23 millisecondi, giorno e notte, ciascuna delle quali viene gestita dal server come una nuova richiesta, anziché come un dato che può essere memorizzato nella cache.
Su larga scala, questo tipo di comportamento non è sempre intenzionale.
«Non basta sparare a caso… bisogna comportarsi da utente finale responsabile», spiega Belson. «Non si può bombardare un sito web di richieste».
Il tuo server non sa che sta
comunicando con un bot
Il problema non è il comportamento in sé. Se ogni richiesta fosse poco costosa, i loop e le visite ripetute non avrebbero molta importanza.
In una semplice pagina statica, la maggior parte delle richieste può essere gestita dalla cache. Il server restituisce una versione della pagina memorizzata nella cache e il costo per richiesta rimane basso.
Quel modello si rivela ben presto inadeguato nei siti WordPress reali, specialmente in quelli che utilizzano WooCommerce, funzioni di ricerca e filtraggio o che si avvalgono di numerosi plugin.
Gran parte del traffico non arriva nemmeno alle pagine statiche, ma a endpoint come:
Questi elementi non possono essere memorizzati nella cache allo stesso modo. Richiedono che il server esegua effettivamente l'operazione ogni volta.
Ogni richiesta attiva
Un thread PHP (precedentemente noto come "PHP worker") viene riservato per l'intera durata di ogni richiesta. In caso di carico prolungato da parte dei bot, i thread si esauriscono e i visitatori legittimi rimangono in attesa.
Le pagine dinamiche interrogano il database ad ogni caricamento. Nessun livello di cache è in grado di gestirlo su larga scala.
Le pagine del carrello e del checkout creano o convalidano le sessioni, generando un sovraccarico anche per i bot che non generano mai conversioni.
Il costo SEO
Si tratta di un attacco? Di una normale attività dei bot? Di qualcosa a metà strada tra le due? È proprio questa ambiguità a rendere difficile porvi rimedio. Poiché gli stessi schemi influenzano sia le prestazioni che la reperibilità, la risposta adeguata dipende da ciò che stai cercando di proteggere.
Scegli l'obiettivo per cui stai
ottimizzando
Dopo aver visto come si comportano i bot e l'impatto che possono avere, la reazione naturale è: li blocco. Ma bloccarli indiscriminatamente non è la soluzione, né lo è lasciare la porta spalancata.
Come dice Belson: «Bisogna fare il primo passo e mettere un buttafuori all'ingresso per decidere chi può entrare e chi no».
Non tutti i bot sono dannosi, e non tutto il traffico va trattato allo stesso modo. Alcuni bot favoriscono la visibilità, altri consumano risorse senza apportare alcun valore aggiunto, mentre altri ancora si collocano in una via di mezzo.
Anche a livello di rete, l'obiettivo non è quello di eliminare completamente i bot. «Non sono il tipo che consiglierebbe a qualcuno di bloccare tutti i bot», afferma Belson. «Parte di quel traffico ha un valore reale».
La sfida ora non è stabilire se i bot siano "buoni" o "cattivi". Si tratta piuttosto di capire in che modo le diverse scelte influiscono sul proprio sito e quali compromessi si è disposti ad accettare.
Come afferma Cristian Lopez, caporedattore di HostingAdvice: «L'errore comune è pensare che si tratti semplicemente di una questione di "bloccare o consentire". In realtà, oggi è una questione di politica, visibilità e controllo economico».
Discoverability e performance
I crawler dei motori di ricerca sono fondamentali per aiutare gli utenti a scoprire il tuo sito, ma non sempre funzionano in modo efficiente, il che richiede un delicato equilibrio. Bloccarli in modo troppo aggressivo può limitare la tua discoverability nei risultati di ricerca, mentre consentire loro un accesso illimitato può comportare un carico superfluo, soprattutto quando iniziano a visitare pagine dinamiche che richiedono un'elaborazione effettiva anziché essere fornite dalla cache.
L'obiettivo non è quello di privilegiare l'uno rispetto all'altro, ma di regolare la quantità di ciascuno in base al comportamento effettivo del tuo sito.
Costi di accesso e delle risorse
Alcuni bot offrono un valore indiretto — sistemi di intelligenza artificiale che fanno riferimento ai tuoi contenuti, strumenti che indicizzano le tue pagine o servizi che raccolgono dati dal web — ma ogni richiesta comporta un costo in termini di utilizzo della CPU, query al database, memoria e larghezza di banda. Man mano che tale attività cresce, questi costi non rimangono marginali, ma si accumulano e iniziano ad avere un impatto tangibile.
Non tutti gli accessi devono necessariamente essere illimitati. Il valore offerto da un bot dovrebbe essere valutato rispetto ai costi che comporta.
Controllo e semplicità
Nei casi più semplici, l'automazione può gestire efficacemente i bot, ma l'approccio più adeguato dipende in ultima analisi dal tipo di sito che gestisci, dal tipo di traffico che registri e da ciò che conta di più per i tuoi obiettivi. Affidarsi interamente all'automazione può semplificare le cose, ma significa anche che non sei tu a determinare come vengono prese quelle decisioni per il tuo sito specifico.
I sistemi migliori non costringono a scegliere tra semplicità e controllo. Ti permettono di iniziare in modo semplice e di adattarli dove serve.
Questa sovrapposizione crea confusione. Si verificano picchi di traffico e cali di prestazioni, e non è sempre chiaro se sia meglio bloccare, consentire o ignorare, anche quando si tratta dello stesso schema su due siti diversi.
"Devo autorizzare i bot?"
"Quali bot, in quali sezioni del mio sito e in quali circostanze?"
Per rispondere a questa domanda occorre un approccio diverso. Ne parleremo nella prossima sezione.
Un modo migliore per decidere cosa
consentire, verificare o bloccare
Non esiste una politica sui bot valida per tutti i siti. Un negozio WooCommerce, un sito di contenuti, un sito aziendale e un ambiente di staging non sono esposti agli stessi rischi e non richiedono le stesse soluzioni.
L'approccio corretto dipende dall'attività del tuo sito, dal tipo di traffico che riceve e dagli obiettivi di ottimizzazione prefissati. Nella maggior parte dei casi, questo livello decisionale viene gestito dagli strumenti di infrastruttura piuttosto che tramite configurazioni manuali per ogni singola richiesta, ma comprenderne la logica aiuta a capire cosa viene eseguito per tuo conto e quando è opportuno apportare delle modifiche.
Ciò che conta in questo caso non è solo il traffico, ma il tipo di visibilità che desideri, che si tratti di posizionamento nei motori di ricerca, citazioni AI o visite dirette degli utenti.
I tuoi problemi di prestazioni sono probabilmente causati da bot che accedono agli endpoint "Aggiungi al carrello" e "Checkout" di WooCommerce. Questi endpoint aggirano completamente la cache della pagina e costringono l'esecuzione di PHP e le query al database ad ogni singola richiesta. La soluzione non consiste nel bloccare tutto, ma nell'intervenire su percorsi specifici che comportano un carico elevato.
/cart, /checkout e ?add-to-cart= tramite il file robots.txt/shop?add-to-cart= e /checkout nel file robots.txt./shop, /product/ e delle pagine delle categorie. Limita l'accesso solo a specifici endpoint dinamici, non all'intero sito.Le configurazioni sopra riportate illustrano come si gestisce manualmente il traffico dei bot. In pratica, la Protezione bot di Kinsta gestisce automaticamente la maggior parte di questi schemi. Basta attivare una volta il livello di protezione desiderato e il nostro sistema si occuperà del resto (senza bisogno di regole per ogni singolo percorso o di eccezioni manuali).
La maggior parte dei sistemi non è stata progettata
per questo livello di controllo
La maggior parte delle piattaforme gestisce il traffico dei bot in modo automatico, prendendo decisioni in background, oppure mette a disposizione strumenti di controllo che richiedono una configurazione manuale.
I sistemi automatici rilevano le minacce evidenti e consentono l'accesso ai crawler noti, ma non tengono conto del comportamento del traffico in specifiche sezioni del sito, né del suo impatto nel contesto specifico. In alcuni casi, i crawler AI legittimi vengono bloccati all'ingresso, creando un punto cieco nella discoverability di cui la maggior parte dei team non è nemmeno a conoscenza.
I controlli manuali offrono maggiore flessibilità. Tuttavia, spesso richiedono un livello di precisione che la maggior parte dei gestori di siti non ha il tempo di garantire costantemente. Inoltre, senza una guida adeguata, è facile configurarli in modo errato.
Ciò che manca non è solo il controllo, ma un controllo funzionale.
La possibilità di modificare il comportamento dove serve, senza compromettere il traffico essenziale e senza dover ricostruire da zero l'intero approccio ogni volta che qualcosa cambia.
La maggior parte dei siti non necessita di un'automazione totale né di un controllo assoluto. Ciò di cui hanno bisogno è la possibilità di prendere decisioni mirate senza dover rielaborare l'intera strategia di traffico ogni volta che gli schemi cambiano.
A questo punto, la sfida non consiste nell'identificare il traffico generato dai bot, bensì nel gestirlo in modo che rispecchi il funzionamento effettivo del tuo sito.
Come dovrebbe essere la risposta
giusta in diverse situazioni
A questo punto, è chiaro che non esiste una regola valida in ogni caso. La risposta giusta dipende dal tipo di sito che gestisci, dal tipo di traffico che registri e dall'urgenza della situazione.
Quello che segue non è una lista di cose da fare. È un modo per riflettere su cosa fare, partendo dalla situazione in cui ti trovi adesso.
Inizia dalla visibilità, poi prendi una decisione mirata
Prima di apportare modifiche, esamina la composizione effettiva del tuo traffico. Non devi cercare di identificare ogni singolo bot, ma individuare piuttosto degli schemi ricorrenti: richieste ripetute rivolte allo stesso tipo di URL, in particolare quelle che non dovrebbero interessare a un crawler, come gli endpoint del carrello o le pagine con molti parametri. La maggior parte degli strumenti di analisi o dei log di server ti fornirà informazioni sufficienti per individuare questo tipo di attività.
La maggior parte delle piattaforme filtra già gli schemi più palesemente anomali, come i loop evidenti o il traffico abusivo noto. Assicurati che queste protezioni di base siano attive e concedi loro il tempo necessario per funzionare. Di solito sono progettate in modo prudente, il che significa che riducono il rumore di fondo senza influire sui visitatori legittimi o sui crawler dei motori di ricerca.
Una volta individuato uno schema, agisci di conseguenza (senza fare tutto in una volta). Se i bot accedono ripetutamente a endpoint dinamici, limita l'accesso a tali percorsi. Se determinati crawler stanno estraendo contenuti in modo massiccio, valuta se tale accesso giustifica il costo. L'obiettivo in questa fase non è la perfezione, ma ridurre il carico superfluo senza creare nuovi problemi.
Applica questo processo a diversi siti di clienti. Gli schemi che noterai su un sito di e-commerce, un sito di contenuti e un sito di servizi saranno diversi, ma sufficientemente coerenti da consentire di sviluppare un approccio standardizzabile per le conversazioni con i clienti.
Il traffico generato dai bot non scomparirà.
La tua strategia dovrebbe
A questo punto, il quadro è chiaro. Il traffico generato dai bot non è più qualcosa che si può considerare un disturbo occasionale o filtrare ai margini. È una componente costante e in continua evoluzione delle modalità di accesso ai siti web e del carico a cui questi sono sottoposti.
Ciò che rende la situazione complessa non è solo il volume, ma anche la sovrapposizione. Gli stessi sistemi che aiutano gli utenti a trovare il tuo sito possono anche consumarne le risorse, e schemi che sembrano normali attività di scansione possono rivelarsi, su larga scala, come automazioni inefficienti.
Quindi non esiste una regola valida in ogni caso.
L'approccio più adeguato dipende dal tuo sito, dal tuo traffico e da ciò che intendi proteggere. È necessario comprendere come si comporta effettivamente il tuo sito e prendere decisioni che rispecchino tale realtà.
Questo tipo di cambiamento non è del tutto nuovo nell'evoluzione del web. Come afferma Jordan Sprogis, esperto collaboratore di HostingAdvice: «Non è molto diverso da ciò che è successo con l'SSL, che per molto tempo è stato un'opzione a pagamento… ora, invece, i certificati SSL sono inclusi praticamente in ogni pacchetto di hosting».
Il più delle volte, l'obiettivo è ridurre il carico superfluo, preservare la visibilità dove conta e mantenere un sistema su cui poter contare anche quando le cose cambiano. Ciò che verrà dopo sarà più difficile da classificare. Il traffico generato da agenti, ovvero strumenti automatizzati creati per eseguire azioni, sta già comparendo nei dati relativi all'infrastruttura. Google ha recentemente annunciato uno user-agent dedicato per registrare quando i suoi agenti AI interagiscono con i siti. Le piattaforme responsabili si identificheranno, rispetteranno i ritardi di scansione ed eviteranno di sovraccaricare endpoint che non servono a nulla. Altre non lo faranno. Il confine tra un visitatore umano e un agente continuerà a diventare sempre più sfumato.
E quando il traffico automatizzato gonfia il numero delle visite, i dati grezzi non riflettono più la realtà. Gli indicatori che contano sono quelli correlati: il volume delle ricerche relative al brand, il traffico diretto, la qualità del coinvolgimento e i ricavi legati al comportamento effettivo dei visitatori. Se anche questi indicatori sono in crescita, significa che sei visibile dove conta davvero.
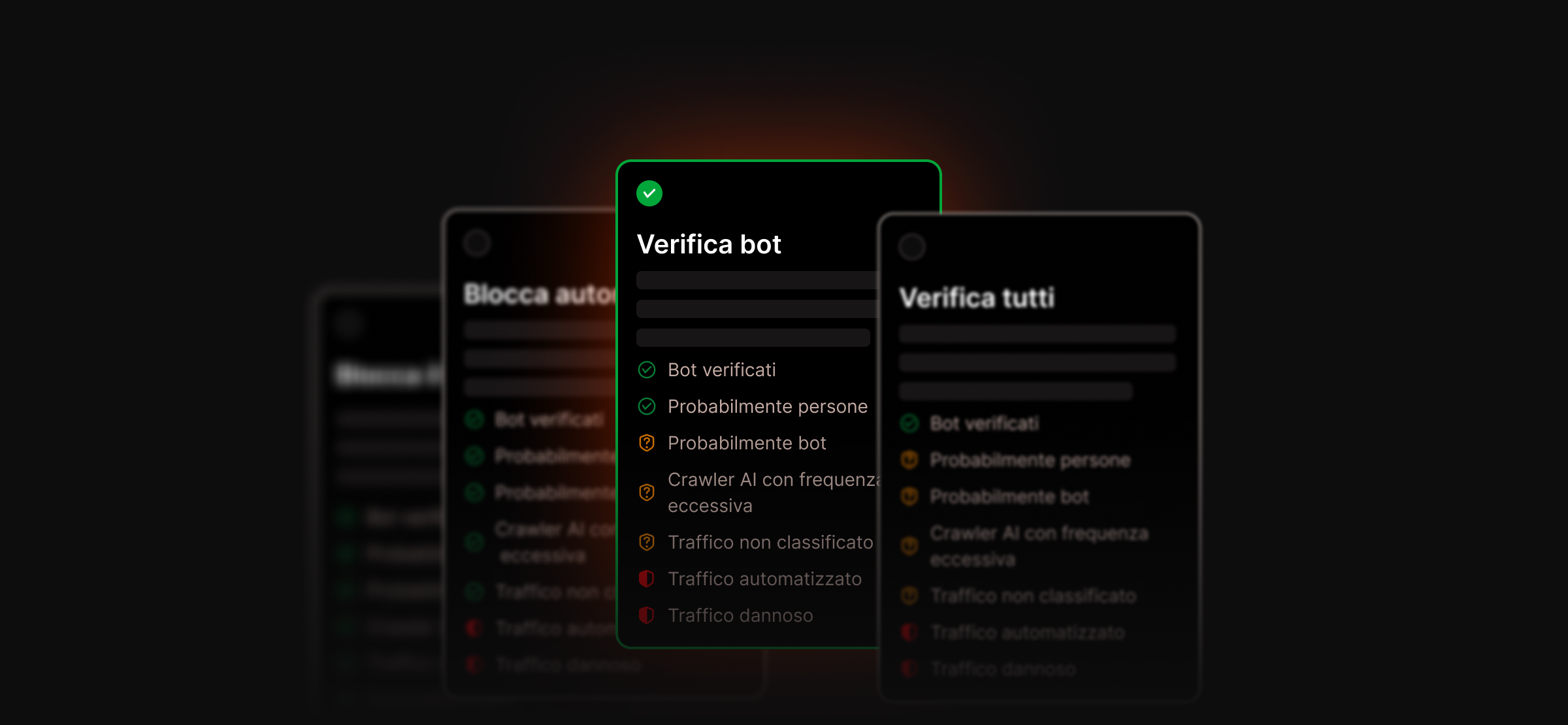
Controlla il modo in cui i bot interagiscono con il tuo sito WordPress senza compromettere la visibilità nei motori di ricerca
La Protezione bot di Kinsta ti offre un controllo a livello di ambiente con impostazioni predefinite ottimali, per poter gestire il modo in cui i diversi tipi di traffico interagiscono con il tuo sito senza bloccare i motori di ricerca né comprometterne la visibilità. Included in all plans.
Questo report è stato offerto da Kinsta.
Kinsta è una piattaforma di hosting WordPress gestito premium con oltre 230.000 clienti in tutto il mondo. Al primo posto su G2 per soddisfazione. Supporto di esperti 24 ore su 24, 7 giorni su 7, in 10 lingue.