
La IA y el tráfico de bots
: una visión realista
Lo que 10.000 millones de solicitudes, los rastreadores averiados y la infraestructura de WordPress nos revelan sobre la nueva realidad del tráfico de bots.

Ir a una sección
Tus analíticas te están mintiendo: una parte importante del "tráfico" de tu sitio web no es humano.
La mayoría de los consejos que hay por ahí no sirven de mucho. Te dicen que o lo bloqueas todo o lo dejas pasar todo porque la IA es el futuro. Ninguna de las dos opciones te ayuda realmente a gestionar un sitio de WordPress.
En el último año, el tráfico de bots ha dejado de ser solo un problema de seguridad o de SEO. Ahora es un problema de infraestructura. Los rastreadores acceden a endpoints dinámicos, se quedan atascados en bucles de cadenas de consulta, eluden la caché y generan patrones de tráfico que se parecen menos a una indexación normal y más a una automatización defectuosa a gran escala.
Algunas conclusiones clave
Para entender qué ha cambiado, hemos consultado estudios del sector, hemos hablado con ingenieros y profesionales, y hemos analizado más de 10.000 millones de solicitudes en la infraestructura administrada por Kinsta. Lo que se desprende no es que haya que bloquearlo todo ni permitirlo todo, sino que hay que aplicar un mejor criterio.
Opiniones de
nuestros colaboradores
“Desde el punto de vista de la infraestructura, no existe eso de "solo tráfico de bots". Cada solicitud supone un trabajo real. A gran escala, un rastreo ineficiente deja de ser un problema de tráfico y se convierte en un problema de recursos.”
“La mayoría de lo que vemos no es malicioso. Son bots que funcionan de forma ineficaz a gran escala, y ahí es donde empiezan los verdaderos problemas.”
“El error es pensar que el tráfico de bots es simplemente una cuestión de "bloquear o permitir". En realidad, se trata de políticas, visibilidad y control económico.”
El problema no es que haya más bots.
Lo que ha cambiado es cómo se comportan.
Durante años, el debate sobre el tráfico de bots se centró en el volumen.
Los equipos analizaron qué parte estaba automatizada, descartaron a los malos actores más evidentes y siguieron adelante. Ese enfoque funcionaba cuando la mayoría de los bots se comportaban de forma predecible: rastreaban páginas, indexaban contenido y se marchaban.
Ese modelo ya no sirve. En los últimos dos años, la web se ha visto inundada de bots diseñados no solo para indexar contenido para los resultados de búsqueda, sino también para recopilarlo a gran escala con fines de entrenamiento de modelos, generación aumentada por recuperación y consultas iniciadas por los usuarios. Estos rastreadores son más voraces, más rápidos y, en esencia, mucho menos educados que cualquiera de sus predecesores.
A finales de 2025, los rastreadores de IA representaban el 4,2 % de las solicitudes HTML en la red de Cloudflare y, si sumamos el tráfico de rastreadores como Googlebot, esa cifra llegaba al 8,5 %. Al mismo tiempo, los equipos que gestionaban sitios web empezaron a detectar patrones como solicitudes repetidas, bucles y un gran volumen de visitas a endpoints de bajo valor que no se parecían en nada al rastreo tradicional.
Ese 4,2 % es una media anual. La cifra real osciló entre el 2,4 % a principios de abril y el 6,4 % a finales de junio (casi el triple en un solo año). Solo GPTBot creció un 305 % entre mayo de 2024 y mayo de 2025. De toda la actividad de rastreo de la IA, el 80 % se destina exclusivamente al entrenamiento de modelos (no a búsquedas ni a consultas de usuarios). No genera tráfico de referencia hacia tu sitio.
Review del año 2025 de Cloudflare Radar
Solo Googlebot representa alrededor del 4,5 % del tráfico HTML, lo que supone más que todos los bots de IA que no son de Google juntos. Ha rastreado el 11,6 % de las páginas web únicas, frente al 3,6 % de GPTBot, y alcanzó un máximo del 11 % de todas las solicitudes HTML a finales de abril. Bloquearlo para aliviar la carga del servidor sería la medida más contraproducente que podría tomar el propietario de un sitio web.
Review del año 2025 de Cloudflare Radar
El panorama general
La mayoría de los bots no están atacando.
Simplemente están atascados
La mayoría de los rastreadores de IA están diseñados para seguir todos los enlaces que encuentran y registrar todas las direcciones de página únicas. Ese enfoque funciona bien en sitios web sencillos. Pero los sitios web modernos, sobre todo las tiendas de comercio electrónico, generan URLs ligeramente diferentes para páginas que, en esencia, son la misma.
Por ejemplo, el equipo observó que meta-externalagent (el rastreador de Facebook/Meta AI) recorría repetidamente variaciones de cadenas de consulta en múltiples sitios web. Para un humano, un enlace a un producto con un filtro de color, un enlace al carrito con una cantidad o una página de calendario con un orden de clasificación parecen todos la misma página. Para un bot que sigue las URLs, cada una de ellas parece completamente nueva.
Así que el bot sigue el primer enlace… esa página genera otra variante, a la que el bot sigue. Y otra. Y otra… No tiene forma de darse cuenta de que está dando vueltas en círculo, y algunos de estos bucles pasaron desapercibidos durante varios días antes de que las reglas de la infraestructura los detectaran.
Este tipo de comportamiento no siempre proviene de sistemas muy sofisticados.
Como señala David Belson, de Cloudflare, no todos los bots funcionan con el mismo nivel de disciplina: "Hay personas que ayer no tenían ni idea de lo que estaban haciendo, pero hoy han programado un bot sobre la marcha y lo han soltado ahí fuera — ni siquiera se molestan en consultar el archivo robots.txt".
7,67 millones de solicitudes en las URLs de añadir al carrito en 24 horas
Incluso el rastreador de Google, ese que no puedes bloquear bajo ningún concepto, cayó en la misma trampa.
Para poner las cifras en perspectiva, 3,75 millones de solicitudes en 24 horas equivalen aproximadamente a una solicitud cada 23 milisegundos, día y noche, y el servidor las trata a todas como solicitudes nuevas, en lugar de como algo que se pueda almacenar en la caché.
A gran escala, este tipo de comportamiento no siempre es intencionado.
"No basta con lanzar solicitudes al azar… tienes que comportarte como un usuario final responsable», explica Belson. «No puedes saturar tu sitio web con solicitudes".
Tu servidor no sabe que está
hablando con un bot
El problema no es el comportamiento en sí. Si todas las solicitudes fueran baratas, los bucles y las visitas repetidas no tendrían mucha importancia.
En una página estática sencilla, la mayoría de las solicitudes se pueden atender desde la caché. El servidor devuelve una versión de la página almacenada en caché, y el coste por solicitud sigue siendo bajo.
Ese modelo se colapsa rápidamente en los sitios web de WordPress reales, sobre todo en aquellos que utilizan WooCommerce, la función de búsqueda, los filtros o muchos plugins.
Gran parte del tráfico ni siquiera llega a las páginas estáticas. Llega a endpoints como:
Estos no se pueden almacenar en caché de la misma manera. El servidor tiene que hacer un trabajo real cada vez.
Cada solicitud activa
Se reserva un hilo de PHP (también conocido como Worker de PHP) durante toda la duración de cada solicitud. Cuando hay una carga constante de bots, los hilos se agotan y los visitantes legítimos se quedan esperando.
Las páginas dinámicas consultan la base de datos cada vez que se cargan. Ninguna capa de caché puede soportar esto a gran escala.
Las páginas del carrito y de pago crean o validan sesiones, lo que supone una carga adicional incluso para los bots que nunca llegan a realizar una compra.
El coste del SEO
¿Se trata de un ataque? ¿De la actividad habitual de un bot? ¿De algo intermedio? Esa ambigüedad es precisamente lo que hace que sea difícil solucionarlo. Como los mismos patrones afectan tanto al rendimiento como a la visibilidad, la respuesta adecuada depende de lo que estés tratando de proteger.
Elige para qué estás
optimizando
Después de ver cómo se comportan los bots y el impacto que pueden tener, la reacción natural es: bloquearlos. Pero bloquearlos indiscriminadamente no es la solución, y tampoco lo es dejarles la puerta abierta.
Como dice Belson: "Hay que dar el primer paso y poner a un portero en la puerta para decidir quién entra y quién no".
No todos los bots son perjudiciales, y no todo el tráfico debe tratarse de la misma manera. Algunos bots mejoran la visibilidad, otros consumen recursos sin aportar ningún valor, y otros se sitúan en un punto intermedio.
Incluso a nivel de red, el objetivo no es eliminar por completo los bots. "No soy de los que le dirían a nadie que bloquee todos los bots", dice Belson. "Parte de ese tráfico tiene un valor real".
El reto ahora no es decidir si los bots son buenos o malos. Se trata de entender cómo afectan las distintas decisiones a tu sitio y qué grado de cada una de esas concesiones estás dispuesto a aceptar.
Como dice Cristian López, director editorial de HostingAdvice: "El error es pensar que se trata simplemente de una cuestión de "bloquear o permitir". En realidad, ahora es una cuestión de política, visibilidad y control económico".
Visibilidad y rendimiento
Los rastreadores de búsqueda son esenciales para ayudar a la gente a descubrir tu sitio, pero no siempre funcionan de manera eficiente, lo que exige encontrar un equilibrio. Bloquearlos de forma demasiado agresiva puede limitar tu visibilidad en los resultados de búsqueda, mientras que permitirles el acceso sin restricciones puede generar una carga innecesaria, sobre todo cuando empiezan a acceder a páginas dinámicas que requieren un procesamiento real en lugar de servirse desde la caché.
El objetivo no es elegir uno en lugar del otro, sino controlar la cantidad de cada uno que permites, según cómo se comporte realmente tu sitio.
Coste de acceso y de los recursos
Algunos bots aportan un valor indirecto —sistemas de IA que hacen referencia a tu contenido, herramientas que indexan tus páginas o servicios que recopilan datos de toda la web—, pero cada solicitud conlleva un coste en términos de uso de la CPU, consultas a la base de datos, memoria y ancho de banda. A medida que esa actividad aumenta, esos costes dejan de ser marginales; se acumulan y empiezan a tener un impacto notable.
No todo el acceso tiene por qué ser ilimitado. Hay que sopesar el valor que aporta un bot frente al coste que supone.
Control y simplicidad
En casos sencillos, la automatización puede gestionar los bots de forma eficaz, pero el enfoque adecuado depende, en última instancia, del tipo de sitio web que tengas, del tipo de tráfico que recibas y de lo que sea más importante para tus objetivos. Confiar por completo en la automatización puede simplificar las cosas, pero también significa que no estás influyendo en cómo se toman esas decisiones para tu sitio web en concreto.
Los mejores sistemas no te obligan a elegir entre facilidad y control. Te permiten empezar de forma sencilla y ajustar lo que realmente importa.
Este solapamiento genera confusión. El tráfico se dispara, el rendimiento baja y no siempre está claro si hay que bloquear, permitir o ignorar, incluso cuando se trata del mismo patrón en dos sitios web diferentes.
"¿Debería permitir los bots?"
¿Qué bots, en qué partes de tu sitio y en qué condiciones?
Para responder a esta pregunta hay que pensar de otra manera. Lo veremos en la siguiente sección.
Una forma mejor de decidir qué
permitir, desafiar o bloquear
No existe una política universal contra los bots que sirva para todos los sitios web. Una tienda de WooCommerce, un sitio de contenidos, una página web empresarial y un entorno staging no se enfrentan a los mismos riesgos ni requieren las mismas soluciones.
El enfoque adecuado depende de la función de tu sitio, del tipo de tráfico que reciba y de los objetivos de optimización que te hayas marcado. En la mayoría de los casos, este tipo de decisiones se gestionan mediante herramientas de infraestructura, en lugar de configurarse manualmente para cada solicitud, pero entender la lógica te ayuda a saber qué se está ejecutando en tu sitio y cuándo conviene hacer ajustes.
Lo que importa aquí no es solo el tráfico, sino el tipo de visibilidad que buscas, ya sea en los resultados de búsqueda, en las citas de IA o en las visitas directas de los usuarios.
Es probable que tus problemas de rendimiento se deban a que hay bots accediendo a los endpoints de Añadir al carrito y Finalizar compra de WooCommerce. Estos eluden por completo la caché de la página y obligan a ejecutar PHP y a realizar consultas a la base de datos en cada solicitud. La solución no consiste en bloquearlo todo. El objetivo es proteger rutas específicas que consumen muchos recursos.
/cart, /checkout y ?add-to-cart= a través del archivo robots.txt/shop?add-to-cart= y /checkout en el archivo robots.txt./shop, /product/ y las páginas de categorías. Limítale el acceso solo a determinados endpoints dinámicos, no a todo el sitio.Las configuraciones anteriores muestran cómo es la gestión del tráfico de bots cuando se hace de forma manual. En la práctica, la protección contra bots de Kinsta gestiona la mayoría de estos patrones de forma automática. Activa el nivel de protección que desees una sola vez y nuestro sistema se encarga del resto (sin necesidad de reglas por ruta ni excepciones manuales).
La mayoría de los sistemas no se diseñaron
para este nivel de control
La mayoría de las plataformas gestionan el tráfico de bots de forma automática, tomando decisiones en segundo plano, o bien ofrecen controles que requieren una configuración manual.
Los sistemas automáticos detectan las amenazas evidentes y permiten el acceso a los rastreadores conocidos, pero no tienen en cuenta cómo se comporta el tráfico en partes concretas de tu sitio, ni cuál es su impacto en el contexto. En algunos casos, los rastreadores de IA legítimos quedan bloqueados en el edge, lo que crea un punto ciego en la visibilidad del que la mayoría de los equipos nunca llegan a enterarse.
Los controles manuales ofrecen más flexibilidad. Pero a menudo requieren un nivel de precisión que la mayoría de los propietarios de sitios web no tienen tiempo de gestionar de forma continua. Y sin una guía, es fácil configurarlos mal.
Lo que falta no es solo control, sino un control que se pueda usar.
La capacidad de ajustar el comportamiento donde realmente importa, sin interrumpir el tráfico esencial y sin tener que reconstruir todo el sistema desde cero cada vez que hay un cambio.
La mayoría de los sitios web no necesitan una automatización total ni un control absoluto. Lo que necesitan es poder tomar decisiones específicas sin tener que replantearse toda su estrategia de tráfico cada vez que cambian las tendencias.
A estas alturas, el reto no es identificar el tráfico de bots, sino gestionarlo de forma que refleje cómo funciona realmente tu sitio.
Cómo debería ser la respuesta adecuada
en diferentes situaciones
A estas alturas, ya queda claro que no hay una regla única que sirva para todo. La respuesta adecuada depende del tipo de sitio web que tengas, del tipo de tráfico que recibas y de lo urgente que sea la situación.
Lo que viene a continuación no es una lista de tareas. Es una forma de pensar en qué hacer a continuación según la situación en la que te encuentres ahora mismo.
Empieza por tener una visión clara de la situación y, a continuación, toma una decisión bien meditada
Antes de hacer cambios, fíjate en cómo está compuesto realmente tu tráfico. No se trata de identificar todos y cada uno de los bots. Lo que buscas son patrones: solicitudes repetidas a los mismos tipos de URLs, sobre todo aquellas que no deberían interesarle a un rastreador, como los endpoints del carrito de la compra o las páginas con muchos parámetros. La mayoría de las herramientas de analítica o los registros del servidor te darán la información necesaria para detectar esta actividad.
La mayoría de las plataformas ya filtran los patrones más claramente anómalos, como los bucles evidentes o el tráfico malicioso conocido. Asegúrate de que esas protecciones básicas estén activadas y dales tiempo para que funcionen. Por lo general, están diseñadas para ser conservadoras, lo que significa que reducen el ruido sin afectar a los visitantes legítimos ni a los rastreadores de búsqueda.
En cuanto detectes un patrón, actúa en consecuencia (no lo hagas todo a la vez). Si los bots acceden repetidamente a endpoints dinámicos, limita el acceso a esas rutas. Si hay rastreadores específicos que extraen contenido de forma agresiva, decide si ese acceso compensa el coste. El objetivo en esta fase no es la perfección, sino reducir la carga innecesaria sin generar nuevos problemas.
Aplica este proceso a varios sitios web de clientes diferentes. Los patrones que observes en un sitio de comercio electrónico, un sitio de contenidos y un sitio de servicios serán distintos, pero lo suficientemente coherentes como para desarrollar un enfoque repetible en las conversaciones con los clientes.
El tráfico de bots no va a desaparecer.
Tu estrategia debería
A estas alturas, el patrón es claro. El tráfico de bots ya no es algo que se pueda tratar como ruido ocasional o filtrar superficialmente. Es una parte constante y en constante evolución de cómo se accede a los sitios web y cómo se pone a prueba su capacidad.
Lo que lo complica no es solo el volumen, sino la superposición. Los mismos sistemas que ayudan a la gente a encontrar tu sitio también pueden consumir sus recursos, y los patrones que parecen un rastreo normal pueden comportarse como una automatización ineficaz a gran escala.
Así que no hay una regla única que sirva para todo.
El enfoque adecuado depende de tu sitio, de tu tráfico y de lo que quieras proteger. Para ello, hay que entender cómo se comporta realmente tu sitio y tomar decisiones que reflejen esa realidad.
Este tipo de cambio no es del todo nuevo en la evolución de la web. Como dice Jordan Sprogis, experto colaborador de HostingAdvice: "No es muy diferente de lo que pasaba con el SSL, que durante mucho tiempo fue un add-on de pago… ahora, los certificados SSL se incluyen en casi todos los paquetes de alojamiento".
La mayoría de las veces, el objetivo es reducir la carga innecesaria, mantener la visibilidad donde realmente importa y conservar un sistema en el que puedas confiar a medida que las cosas cambian. Lo que se avecina será más difícil de clasificar. El tráfico de agentes, es decir, herramientas automatizadas diseñadas para realizar acciones, ya está apareciendo en los datos de infraestructura. Google anunció recientemente un agente de usuario específico para registrar cuándo sus agentes de IA interactúan con los sitios web. Las plataformas responsables se identificarán, respetarán los retrasos de rastreo y evitarán saturar los endpoints que no sirven para nada. Otras no lo harán. La línea entre un visitante humano y un agente seguirá difuminándose.
Y cuando el tráfico automatizado infla tus cifras de visitas, los números brutos ya no reflejan la realidad. Las señales que importan son las que están correlacionadas: el volumen de búsquedas de marca, el tráfico directo, la calidad de la interacción y los ingresos vinculados al comportamiento real de los visitantes. Si esas métricas también están mejorando, sabrás que eres visible donde realmente importa.
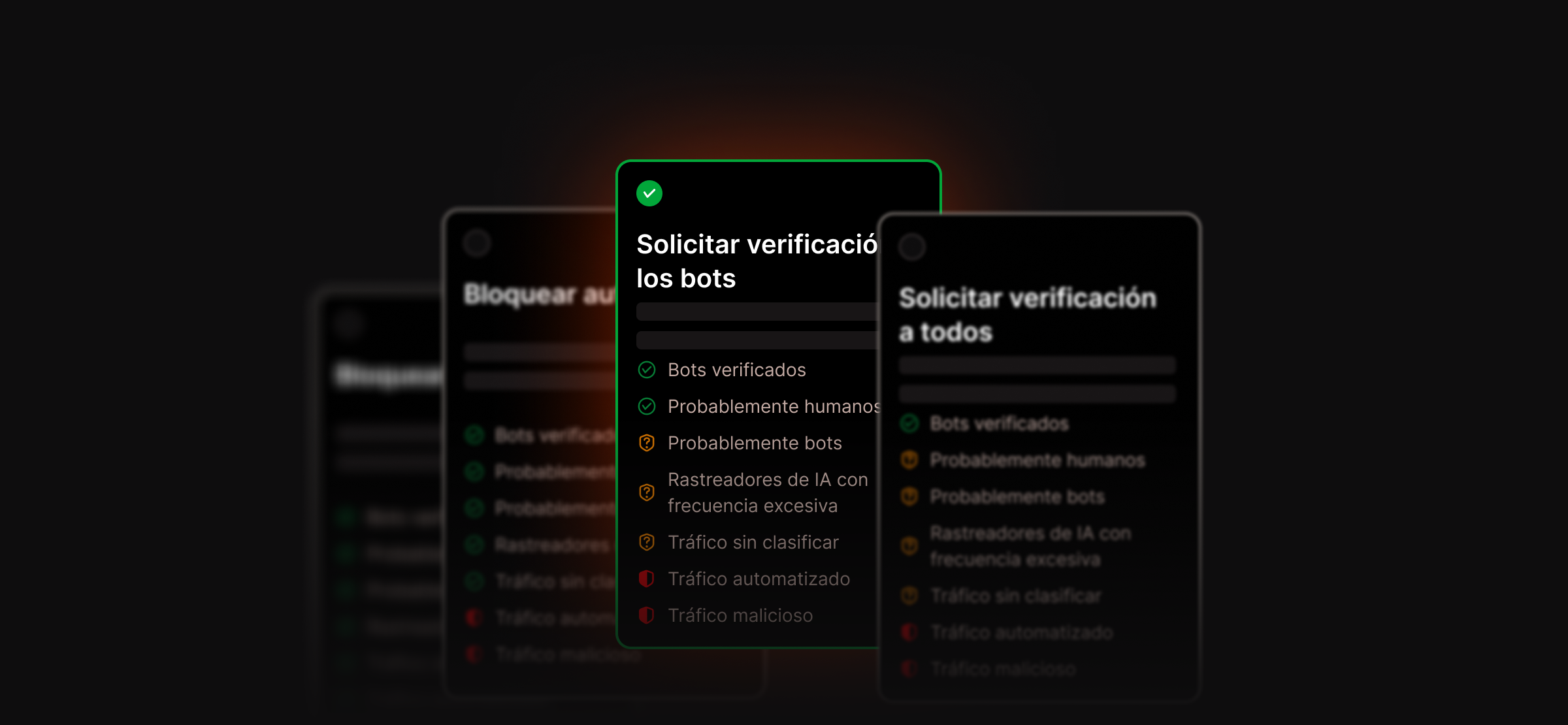
Controla cómo interactúan los bots con tu sitio de WordPress sin afectar a la visibilidad en los motores de búsqueda
La Protección Contra Bots de Kinsta te ofrece un control a nivel de entorno con ajustes predeterminados razonables, para que puedas gestionar cómo interactúan los diferentes tipos de tráfico con tu sitio sin bloquear los motores de búsqueda ni comprometer su visibilidad. Included in all plans.
Este informe ha sido presentado por Kinsta.
Kinsta es una plataforma de alojamiento administrado para WordPress de primera calidad con más de 230.000 clientes en todo el mundo. N. º 1 en satisfacción en G2. Soporte técnico especializado las 24/7 días de la semana, en 10 idiomas.