Som enhver webstedsejer vil fortælle dig, kan tab af data og nedetid, selv i minimale doser, være katastrofalt. De kan ramme den uforberedte når som helst og føre til nedsat produktivitet, tilgængelighed og produkttillid.
For at beskytte integriteten af dit websted er det vigtigt at opbygge sikkerhedsforanstaltninger mod muligheden for nedetid eller datatab.
Det er her, datareplikering kommer ind i billedet.
Datareplikering er en automatiseret sikkerhedskopieringsproces, hvor dine data gentagne gange kopieres fra hoveddatabasen til en anden fjernplacering til opbevaring. Det er en integreret teknologi for ethvert websted eller enhver app, der kører en databaseserver. Du kan også udnytte den replikerede database til at behandle skrivebeskyttet SQL, hvilket gør det muligt at køre flere processer i systemet.
Opsætning af replikering mellem to databaser giver fejltolerance mod uventede uheld. Det anses for at være den bedste strategi til at opnå høj tilgængelighed under katastrofer.
I denne artikel dykker vi ned i de forskellige strategier, der kan implementeres af backend-udviklere til problemfri PostgreSQL-replikation.
Hvad er PostgreSQL replikering?
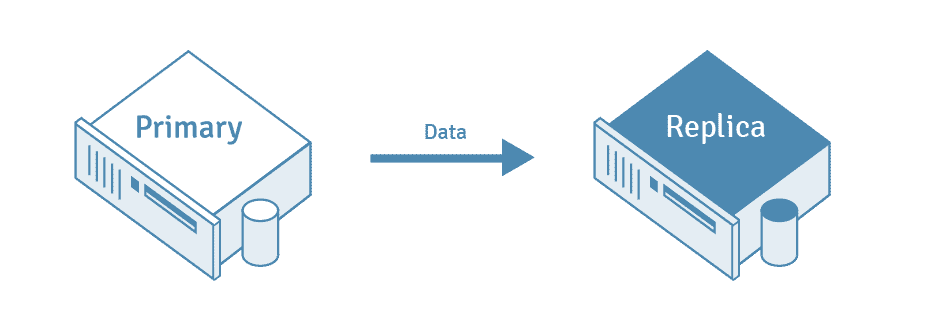
PostgreSQL replikering er defineret som processen med at kopiere data fra en PostgreSQL-databaseserver til en anden server. Kildedatabaseserveren er også kendt som den “primære” server, mens den databaseserver, der modtager de kopierede data, er kendt som “replika”-serveren.
PostgreSQL-databasen følger en simpel replikationsmodel, hvor alle skrivninger går til en primær knude. Den primære knude kan derefter anvende disse ændringer og sende dem til sekundære knuder.
Hvad er automatisk fejlfinding?
Failover er en metode til at genoprette data, hvis den primære server af en eller anden grund giver op. Så længe du har konfigureret PostreSQL til at administrere din fysiske streamingreplikation, vil du – og dine brugere – være beskyttet mod nedetid på grund af en fejl på den primære server.
Bemærk, at failover-processen kan tage noget tid at opsætte og starte. Der er ingen indbyggede værktøjer til overvågning og omfang af serverfejl i PostgreSQL, så du bliver nødt til at være kreativ.
Heldigvis behøver du ikke at være afhængig af PostgreSQL til failover. Der findes dedikerede værktøjer, der muliggør automatisk failover og automatisk skift til standby, hvilket reducerer nedetiden for databasen.
Ved at opsætte failover-replikation garanterer du næsten høj tilgængelighed ved at sikre, at standbys er tilgængelige, hvis den primære server nogensinde bryder sammen.
Fordele ved at bruge PostgreSQL Replication
Her er et par vigtige fordele ved at udnytte PostgreSQL replikering:
- Datamigrering: Du kan udnytte PostgreSQL replikering til datamigrering enten gennem en ændring af databaseserverhardware eller gennem systemimplementering.
- Fejltolerance: Hvis den primære server fejler, kan standby-serveren fungere som server, fordi de indeholdte data for både primære og standby-servere er de samme.
- Ydelse ved online transaktionsbehandling (OLTP): Du kan forbedre transaktionsbehandlingstiden og forespørgselstiden for et OLTP-system ved at fjerne rapportering af forespørgselsbelastningen. Transaktionsbehandlingstiden er den tid, det tager for en given forespørgsel at blive udført, før en transaktion er afsluttet.
- Systemtestning parallelt: Når du opgraderer et nyt system, skal du sikre dig, at systemet klarer sig godt med eksisterende data, og derfor er det nødvendigt at teste med en produktionsdatabase-kopi før implementering.
Sådan fungerer PostgreSQL replikering
Generelt tror folk, at når man dribler med en primær og sekundær arkitektur, er der kun én måde at opsætte backups og replikering på. PostgreSQL-implementeringer kan imidlertid følge en af disse tre metoder:
- Streaming replikering: Replikerer data fra den primære knude til den sekundære, kopierer derefter data til Amazon S3 eller Azure Blob til backuplagring.
- Replikering på volumenniveau: Replikerer data i lagringslaget, startende fra den primære knude til den sekundære knude, og kopierer derefter data til Amazon S3 eller Azure Blob til backuplagring.
- Inkrementelle backups: Replikerer data fra den primære knude, mens der oprettes en ny sekundær knude fra Amazon S3- eller Azure Blob-lagring, hvilket giver mulighed for streaming direkte fra den primære knude.
Metode 1: Streaming
PostgreSQL-streamingreplikation, også kendt som WAL-replikation, kan opsættes problemfrit efter installation af PostgreSQL på alle servere. Denne tilgang til replikering er baseret på at flytte WAL-filerne fra den primære til måldatabasen.
Du kan implementere PostgreSQL-streamingreplikation ved at bruge en primær-sekundær konfiguration. Den primære server er den primære instans, der håndterer den primære database og alle dens operationer. Den sekundære server fungerer som den supplerende instans og udfører alle ændringer i den primære database på sig selv og genererer i den forbindelse en identisk kopi. Den primære server er en skrive/læse-server, mens den sekundære server kun er skrivebeskyttet.
Ved denne metode skal du konfigurere både den primære knude og standbyknuden. I de følgende afsnit forklares de trin, der er nødvendige for at konfigurere dem nemt.
Konfiguration af den primære knude
Du kan konfigurere den primære knude til streamingreplikation ved at udføre følgende trin:
Trin 1: Initialisér databasen
For at initialisere databasen kan du bruge kommandoen initdb utility command. Derefter kan du oprette en ny bruger med replikeringsrettigheder ved at bruge følgende kommando:
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';Brugeren skal angive et password og et brugernavn til den givne forespørgsel. Nøgleordet replikation bruges til at give brugeren de nødvendige rettigheder. En eksempelforespørgsel ville se nogenlunde sådan ud:
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';Trin 2: Konfigurer Streaming-egenskaber
Dernæst kan du konfigurere streamingegenskaberne med PostgreSQL-konfigurationsfilen (postgresql.conf), der kan ændres som følger:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onHer er lidt baggrund omkring de parametre, der blev brugt i det foregående uddrag:
wal_log_hints: Denne parameter er nødvendig forpg_rewind-funktionen, som er praktisk, når standby-serveren ikke er synkroniseret med den primære server.wal_level: Du kan bruge denne parameter til at aktivere PostgreSQL streaming replikation, med mulige værdier, herunderminimal,replica, ellerlogical.max_wal_size: Dette kan bruges til at angive størrelsen af WAL-filer, der kan bevares i logfiler.hot_standby: Du kan udnytte denne parameter til en read-on-forbindelse med den sekundære, når den er indstillet til ON.max_wal_senders: Du kan brugemax_wal_senderstil at angive det maksimale antal samtidige forbindelser, der kan etableres med standbyserverne.
Trin 3: Opret ny post
Når du har ændret parametrene i filen postgresql.conf, kan en ny replikeringspost i filen pg_hba.conf give serverne mulighed for at etablere en forbindelse med hinanden med henblik på replikering.
Du kan normalt finde denne fil i PostgreSQL’s datamappe. Du kan bruge følgende kodestump til det samme:
host replication rep_user IPaddress md5Når kodeudsnittet er blevet udført, tillader den primære server en bruger kaldet rep_user at oprette forbindelse og fungere som standby-server ved at bruge den angivne IP til replikation. F.eks:
host replication rep_user 192.168.0.22/32 md5Konfigurering af standby-knude
Følg disse trin for at konfigurere standbyknuden til streamingreplikation:
Trin 1: Sikkerhedskopiering af primær knude
For at konfigurere standbyknuden skal du bruge værktøjet pg_basebackup til at generere en sikkerhedskopi af den primære knude. Dette vil tjene som udgangspunkt for standbyknuden. Du kan bruge dette hjælpeprogram med følgende syntaks:
pg_basebackp -D -h -X stream -c fast -U rep_user -WDe parametre, der anvendes i ovennævnte syntaks, er følgende:
-h: Du kan bruge dette til at nævne den primære host.-D: Denne parameter angiver den mappe, du arbejder på i øjeblikket.-C: Du kan bruge denne parameter til at angive kontrolpunkterne.-X: Denne parameter kan bruges til at medtage de nødvendige transaktionslogfiler.-W: Du kan bruge denne parameter til at bede brugeren om et password, før der oprettes en forbindelse til databasen.
Trin 2: Opsætning af konfigurationsfil til replikering
Dernæst skal du kontrollere, om replikeringskonfigurationsfilen findes. Hvis den ikke gør det, kan du generere replikeringskonfigurationsfilen som recovery.conf.
Du skal oprette denne fil i datamappen i PostgreSQL-installationen. Du kan generere den automatisk ved at bruge indstillingen -R i værktøjet pg_basebackup.
Recovery.conf-filen skal indeholde følgende kommandoer:
standby_mode = 'on'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"'
recovery_target_timeline = 'latest'De parametre, der anvendes i ovennævnte kommandoer, er følgende:
primary_conninfo: Du kan bruge dette til at oprette en forbindelse mellem den primære og den sekundære server ved at udnytte en forbindelsesstreng.standby_mode: Denne parameter kan få den primære server til at starte som standby-server, når den tændes.recovery_target_timeline: Du kan bruge denne parameter til at indstille genoprettelsestiden.
Hvis du vil oprette en forbindelse, skal du angive brugernavn, IP-adresse og password som værdier for parameteren primary_conninfo. F.eks:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Trin 3: Genstart sekundær server
Endelig kan du genstarte den sekundære server for at afslutte konfigurationsprocessen.
Streaming replikering er dog forbundet med flere udfordringer, f.eks:
- Forskellige PostgreSQL-klienter (skrevet i forskellige programmeringssprog) konverserer med et enkelt slutpunkt. Når den primære knude fejler, vil disse klienter blive ved med at forsøge det samme DNS- eller IP-navn igen. Dette gør failover synlig for applikationen.
- PostgreSQL-replikation leveres ikke med indbygget failover og overvågning. Når den primære knude fejler, skal du fremme en sekundær knude til at være den nye primære knude. Denne forfremmelse skal udføres på en måde, hvor klienterne kun skriver til én primær knude, og de observerer ikke datainkonsistens.
- PostgreSQL replikerer hele sin tilstand. Når du skal udvikle en ny sekundær knude, skal den sekundære knude genopstille hele historikken for tilstandsændringer fra den primære knude, hvilket er ressourcekrævende og gør det dyrt at fjerne knuder i hovedet og oprette nye.
Metode 2: Replikeret blokanordning
Metoden med replikeret blokanordning er afhængig af diskspejling (også kendt som volumenreplikation). I denne metode skrives ændringer til et vedvarende volumen, som synkront spejles til et andet volumen.
Den ekstra fordel ved denne metode er dens kompatibilitet og holdbarhed af data i cloud-miljøer med alle relationelle databaser, herunder PostgreSQL, MySQL og SQL Server, for blot at nævne nogle få.
Diskspejlingstilgangen til PostgreSQL-replikering kræver dog, at du replikerer både WAL-log- og tabeldata. Da hver skrivning til databasen nu skal gå synkront over netværket, har du ikke råd til at miste en enkelt byte, da det kan efterlade din database i en korrupt tilstand.
Denne metode udnyttes normalt ved hjælp af Azure PostgreSQL og Amazon RDS.
Metode 3: WAL
WAL består af segmentfiler (16 MB som standard). Hvert segment har en eller flere poster. En logsekvenspost (LSN) er en pegepind til en post i WAL, der fortæller dig om positionen/placeringen, hvor posten er blevet gemt i logfilen.
En standby-server udnytter WAL-segmenter – også kendt som XLOGS i PostgreSQL-terminologi – til løbende at replikere ændringer fra den primære server. Du kan bruge write-ahead logging til at sikre holdbarhed og atomicitet i et DBMS ved at serialisere bidder af byte-array-data (hver med et unikt LSN) til stabil lagring, før de anvendes i en database.
Anvendelse af en mutation på en database kan føre til forskellige filsystemoperationer. Et relevant spørgsmål er, hvordan en database kan sikre atomicitet i tilfælde af en serverfejl som følge af strømafbrydelse, mens den er midt i en filsystemopdatering. Når en database starter op, starter den en opstarts- eller replay-proces, som kan læse de tilgængelige WAL-segmenter og sammenligne dem med det LSN, der er gemt på hver dataside (hver dataside er markeret med LSN’et for den seneste WAL-record, der påvirker siden).
Log Shipping-baseret replikering (blokniveau)
Streamingreplikation forfiner logforsendelsesprocessen. I stedet for at vente på WAL-skiftet sendes posterne, efterhånden som de oprettes, hvilket mindsker replikationsforsinkelsen.
Streamingreplikation er også bedre end logforsendelse, fordi standby-serveren er forbundet med den primære server via netværket ved hjælp af en replikationsprotokol. Den primære server kan derefter sende WAL-poster direkte over denne forbindelse uden at skulle være afhængig af scripts, der leveres af slutbrugeren.
Replikering baseret på logforsendelse (filniveau)
Logforsendelse er defineret som kopiering af logfiler til en anden PostgreSQL-server for at generere en anden standby-server ved at genindspille WAL-filer. Denne server er konfigureret til at arbejde i genoprettelsestilstand, og dens eneste formål er at anvende alle nye WAL-filer, efterhånden som de dukker op.
Denne sekundære server bliver derefter en varm backup af den primære PostgreSQL-server. Den kan også konfigureres til at være en læsereplica, hvor den kan tilbyde forespørgsler med skrivebeskyttet læsning, også kaldet hot standby.
Kontinuerlig WAL-arkivering
Duplikering af WAL-filer, efterhånden som de oprettes, til en anden placering end undermappen pg_wal for at arkivere dem, kaldes WAL-arkivering. PostgreSQL kalder et script, som brugeren har angivet til arkivering, hver gang en WAL-fil oprettes.
Scriptet kan udnytte kommandoen scp til at duplikere filen til et eller flere steder, f.eks. en NFS-montering. Når de er arkiveret, kan WAL-segmentfilerne udnyttes til at gendanne databasen på et hvilket som helst tidspunkt.
Andre logbaserede konfigurationer omfatter:
- Synkron replikering: Før hver synkron replikeringstransaktion bliver bekræftet, venter den primære server, indtil standbys bekræfter, at de har fået dataene. Fordelen ved denne konfiguration er, at der ikke opstår konflikter på grund af parallelle skriveprocesser.
- Synkron multi-master replikation: Her kan alle servere acceptere skriveanmodninger, og ændrede data overføres fra den oprindelige server til alle andre servere, før hver transaktion bliver bekræftet. Den udnytter 2PC-protokollen og overholder alt-eller-ingen-reglen.
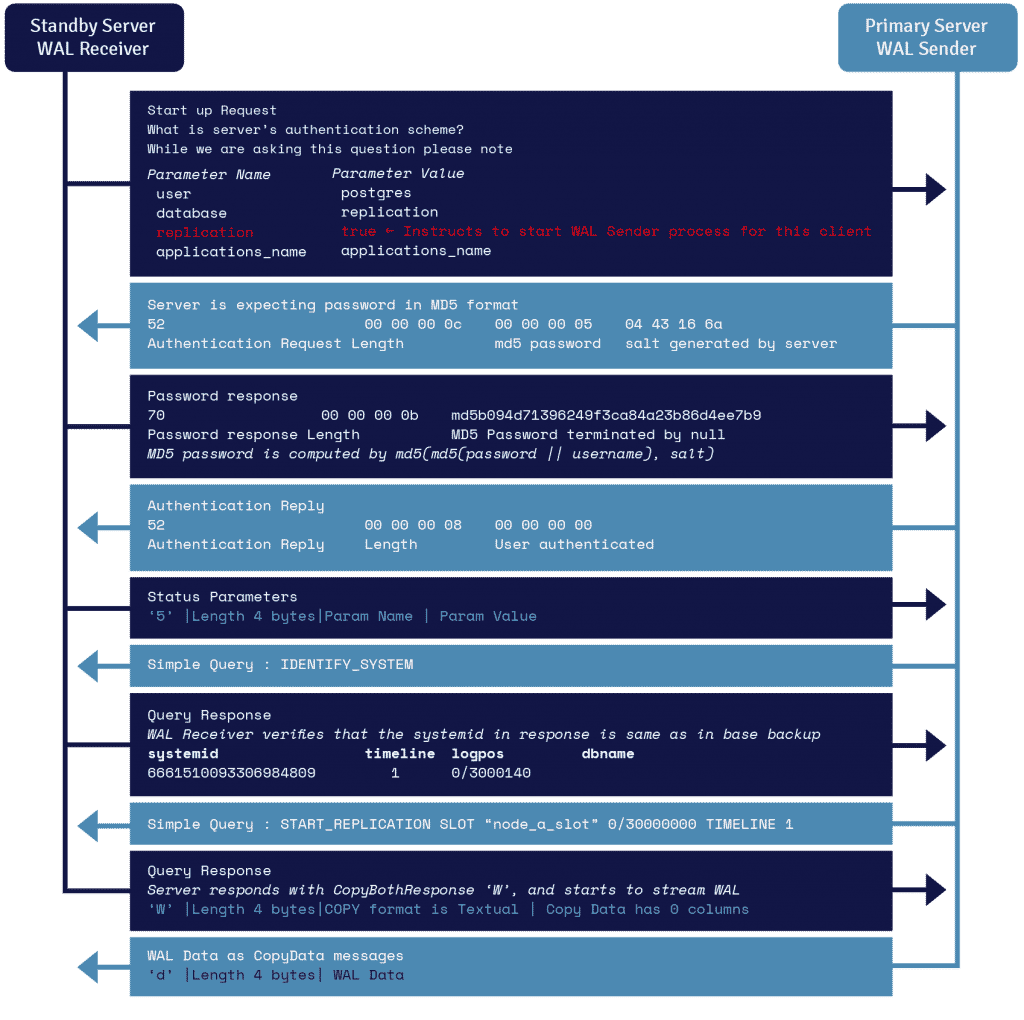
Detaljer om WAL-streamingprotokollen
En proces kaldet WAL-modtager, der kører på standby-serveren, udnytter forbindelsesoplysningerne i parameteren primary_conninfo i recovery.conf og opretter forbindelse til den primære server ved hjælp af en TCP/IP-forbindelse.
For at starte streamingreplikation kan frontend’en sende replikationsparameteren i startmeddelelsen. En boolsk værdi på true, yes, 1 eller ON lader backend’en vide, at den skal gå i fysisk replikering walsender-tilstand.
WAL-sender er en anden proces, der kører på den primære server og er ansvarlig for at sende WAL-posterne til standby-serveren, efterhånden som de bliver genereret. WAL-modtageren gemmer WAL-posterne i WAL, som om de blev oprettet af klientaktivitet fra lokalt tilsluttede klienter.
Når WAL-posterne når frem til WAL-segmentfilerne, bliver standby-serveren konstant ved med at afspille WAL-posterne igen, så primær- og standby-serveren er opdateret.
Elementer af PostgreSQL-replikering
I dette afsnit får du en dybere forståelse af de almindeligt anvendte modeller (single-master og multi-master replikering), typer (fysisk og logisk replikering) og tilstande (synkron og asynkron) for PostgreSQL replikering.
Modeller for PostgreSQL-databasereplikering
Skalerbarhed betyder at tilføje flere ressourcer/hardware til eksisterende knudepunkter for at forbedre databasens evne til at lagre og behandle flere data, hvilket kan opnås horisontalt og vertikalt. PostgreSQL-replikering er et eksempel på horisontal skalerbarhed, som er meget vanskeligere at implementere end vertikal skalerbarhed. Vi kan opnå horisontal skalerbarhed hovedsageligt ved hjælp af single-master replikation (SMR) og multi-master replikation (MMR).
Ved single-master-replikation kan data kun ændres på en enkelt knude, og disse ændringer replikeres til en eller flere knudepunkter. De replikerede tabeller i replika-databasen må ikke acceptere nogen ændringer, undtagen ændringer fra den primære server. Selv hvis de gør det, replikeres ændringerne ikke tilbage til den primære server.
Oftest er SMR tilstrækkeligt til applikationen, fordi det er mindre kompliceret at konfigurere og administrere, og fordi der ikke er nogen risiko for konflikter. Single-master-replikering er også ensrettet, da replikeringsdata hovedsageligt strømmer i én retning, nemlig fra den primære til replika-databasen.
I nogle tilfælde er SMR alene måske ikke tilstrækkeligt, og det kan være nødvendigt at implementere MMR. MMR giver mulighed for, at mere end én knude kan fungere som primær knude. Ændringer af tabelrækker i mere end én udpeget primær database replikeres til deres modstykke-tabeller i alle andre primære databaser. I denne model anvendes der ofte konfliktløsningsordninger for at undgå problemer som f.eks. duplikerede primære nøgler.
Der er nogle få fordele ved at anvende MMR, nemlig
- I tilfælde af værtssvigt kan andre værter stadig levere opdaterings- og indsættelsestjenester.
- De primære knudepunkter er spredt ud på flere forskellige steder, så risikoen for, at alle primære knudepunkter fejler, er meget lille.
- Mulighed for at anvende et Wide Area Network (WAN) af primære databaser, der kan være geografisk tæt på grupper af klienter, men alligevel bevare datakonsistens på tværs af nettet.
Ulempen ved implementering af MMR er imidlertid kompleksiteten og vanskeligheden ved at løse konflikter.
Flere filialer og applikationer tilbyder MMR-løsninger, da PostgreSQL ikke understøtter det nativt. Disse løsninger kan være open source-løsninger, gratis eller betalte. En sådan udvidelse er bidirektionel replikering (BDR), som er asynkron og er baseret på PostgreSQL’s logiske afkodningsfunktion.
Da BDR-applikationen gengiver transaktioner på andre knudepunkter, kan gengivelsesoperationen mislykkes, hvis der er en konflikt mellem den transaktion, der anvendes, og den transaktion, der er begået på den modtagende knudepunkt.
Typer af PostgreSQL-replikering
Der findes to typer PostgreSQL-replikering: logisk og fysisk replikering.
En simpel logisk operation – initdb – ville udføre den fysiske operation med at oprette en basismappe for en klynge. På samme måde vil en simpel logisk operation CREATE DATABASE udføre den fysiske operation med at oprette en undermappe i basismappen.
Fysisk replikering vedrører normalt filer og mapper. Den ved ikke, hvad disse filer og mapper repræsenterer. Disse metoder bruges til at opretholde en fuld kopi af alle data i en enkelt klynge, typisk på en anden maskine, og de udføres på filsystemniveau eller diskniveau og anvender nøjagtige blokadresser.
Logisk replikation er en måde at reproducere dataenheder og deres ændringer på, baseret på deres replikationsidentitet (normalt en primær nøgle). I modsætning til fysisk replikering omhandler den databaser, tabeller og DML-operationer og udføres på databaseklyngeniveau. Den anvender en udgivelses- og abonnementsmodel, hvor en eller flere abonnenter abonnerer på en eller flere publikationer på en udgiverknude.
Replikationsprocessen starter med at tage et øjebliksbillede af dataene i udgiverdatabasen og derefter kopiere dem til abonnenten. Abonnenterne henter data fra de publikationer, de abonnerer på, og kan senere genudgive data for at muliggøre kaskadeopdatering eller mere komplekse konfigurationer. Abonnenten anvender dataene i samme rækkefølge som udgiveren, således at der garanteres transaktionsmæssig konsistens for publikationer inden for et enkelt abonnement, også kendt som transaktionsmæssig replikering.
De typiske anvendelsestilfælde for logisk replikering er følgende:
- Sende inkrementelle ændringer i en enkelt database (eller en delmængde af en database) til abonnenterne, efterhånden som de sker.
- Deling af en delmængde af databasen mellem flere databaser.
- Udløsning af individuelle ændringer, når de ankommer til abonnenten.
- Konsolidering af flere databaser til én.
- Adgang til replikerede data for forskellige grupper af brugere.
Subscriber-databasen opfører sig på samme måde som enhver anden PostgreSQL-instans og kan bruges som udgiver for andre databaser ved at definere dens publikationer.
Når abonnenten behandles som skrivebeskyttet af programmet, vil der ikke være nogen konflikter fra et enkelt abonnement. På den anden side, hvis der er andre skrivninger udført enten af et program eller af andre abonnenter til det samme sæt tabeller, kan der opstå konflikter.
PostgreSQL understøtter begge mekanismer samtidig. Logisk replikation giver mulighed for finkornet kontrol over både datareplikation og sikkerhed.
Replikationsformer
Der er hovedsageligt to tilstande for PostgreSQL-replikering: synkron og asynkron. Synkron replikering gør det muligt at skrive data til både den primære og sekundære server på samme tid, mens asynkron replikering sikrer, at dataene først skrives til hosten og derefter kopieres til den sekundære server.
Ved synkron replikering anses transaktioner i den primære database først for at være afsluttet, når ændringerne er blevet replikeret til alle replikaer. Replikaserverne skal alle være tilgængelige hele tiden, for at transaktionerne kan afsluttes på den primære database. Den synkrone replikeringstilstand anvendes i avancerede transaktionsmiljøer med krav om øjeblikkelig failover.
I asynkron tilstand kan transaktioner på den primære server erklæres for afsluttet, når ændringerne kun er blevet foretaget på den primære server. Disse ændringer replikeres så senere i replikkerne. Replikaserverne kan forblive usynkroniserede i en vis periode, kaldet replikationsforsinkelse. I tilfælde af et nedbrud kan der opstå datatab, men det overhead, som asynkron replikering giver, er lille, så det er acceptabelt i de fleste tilfælde (det overbelaster ikke hosten). Failover fra den primære database til den sekundære database tager længere tid end synkron replikering.
Sådan opsættes PostgreSQL replikering
I dette afsnit vil vi demonstrere hvordan PostgreSQL replikeringsprocessen opsættes på et Linux-operativsystem. I dette tilfælde bruger vi Ubuntu 18.04 LTS og PostgreSQL 10.
Lad os gå i gang!
Installation
Du begynder med at installere PostgreSQL på Linux med disse trin:
- For det første skal du importere PostgreSQL signeringsnøglen ved at skrive nedenstående kommando i terminalen:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Derefter skal du tilføje PostgreSQL-repositoriet ved at indtaste nedenstående kommando i terminalen:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Opdatér Repository Index ved at skrive følgende kommando i terminalen:
sudo apt-get update - Installer PostgreSQL-pakken ved hjælp af apt-kommandoen:
sudo apt-get install -y postgresql-10 - Endelig skal du indstille adgangskoden til PostgreSQL-brugeren ved hjælp af følgende kommando:
sudo passwd postgres
Installation af PostgreSQL er obligatorisk for både den primære og den sekundære server, før PostgreSQL-replikeringsprocessen startes.
Når du har konfigureret PostgreSQL på begge servere, kan du gå videre til replikeringskonfigurationen af den primære og sekundære server.
Opsætning af replikering i den primære server
Udfør disse trin, når du har installeret PostgreSQL på både den primære og sekundære server.
- For det første skal du logge ind på PostgreSQL-databasen med følgende kommando:
su - postgres - Opret en replikationsbruger med følgende kommando:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Rediger pg_hba.cnf med et nano program i Ubuntu og tilføj følgende konfiguration:
nano /etc/postgresql/10/main/pg_hba.confFor at konfigurere filen skal du bruge følgende kommando:
host replication replication MasterIP/24 md5 - Åbn og rediger postgresql.conf, og indsæt følgende konfiguration på den primære server:
nano /etc/postgresql/10/main/postgresql.confBrug følgende konfigurationsindstillinger:
listen_addresses = 'localhost,MasterIP' wal_level = replica wal_keep_segments = 64 max_wal_senders = 10 - Endelig genstarter du PostgreSQL på den primære hovedserver:
systemctl restart postgresqlDu har nu afsluttet opsætningen på den primære server.
Opsætning af replikering i sekundær server
Følg disse trin for at konfigurere replikering på den sekundære server:
- Log ind på PostgreSQL RDMS med nedenstående kommando:
su - postgres - Stop PostgreSQL-tjenesten fra at fungere, så vi kan arbejde på den med nedenstående kommando:
systemctl stop postgresql - Rediger pg_hba.conf-filen med denne kommando og tilføj følgende konfiguration:
// "Edit" command nano /etc/postgresql/10/main/pg_hba.conf // "Configuration" command host replication replication MasterIP/24 md5 - Åbn og rediger postgresql.conf på den sekundære server, og indsæt følgende konfiguration eller fjern kommentaren, hvis den er kommenteret:
nano /etc/postgresql/10/main/postgresql.conf listen_addresses = 'localhost,SecondaryIP' wal_keep_segments = 64 wal_level = replica hot_standby = on max_wal_senders = 10SecondaryIPer adressen på den sekundære server - Få adgang til PostgreSQL-datakataloget på den sekundære server og fjern alt:
cd /var/lib/postgresql/10/main rm -rfv * - Kopier PostgreSQL primære server datakatalog filer til PostgreSQL sekundære server datakatalog og skriv denne kommando i den sekundære server:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -U replication --wal-method=fetch - Indtast PostgreSQL-password til den primære server og tryk på enter. Tilføj derefter følgende kommando til genoprettelseskonfigurationen:
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configuration standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Her er
YOUR_PASSWORDadgangskoden til replikationsbrugeren i den primære server PostgreSQL oprettet - Når adgangskoden er blevet indstillet, skal du genstarte den sekundære PostgreSQL-database, da den blev stoppet:
systemctl start postgresqlTest af din opsætning
Nu hvor vi har udført trinene, lad os teste replikationsprocessen og observere den sekundære serverdatabase. Til dette formål opretter vi en tabel på den primære server og observerer, om den samme tabel afspejles på den sekundære server.
Lad os komme i gang.
- Da vi opretter tabellen på den primære server, skal du logge ind på den primære server:
su - postgres psql - Nu opretter vi en simpel tabel ved navn ‘testtable’ og indsætter data i tabellen ved at køre følgende PostgreSQL forespørgsler i terminalen:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Overvåg PostgreSQL-databasen på den sekundære server ved at logge ind på den sekundære server:
su - postgres psql - Nu kontrollerer vi, om tabellen “testtable” eksisterer, og kan returnere dataene ved at køre følgende PostgreSQL forespørgsler i terminalen. Denne kommando viser i det væsentlige hele tabellen.
select * from testtable;
Dette er resultatet af testtabellen:
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------Du bør kunne observere de samme data som dem på den primære server.
Hvis du ser ovenstående, så har du gennemført replikeringsprocessen med succes!
Hvad er PostgreSQL Manual Failover trinene?
Lad os gennemgå trinene for en PostgreSQL manuel failover:
- Crash den primære server.
- Promote standby-serveren ved at køre følgende kommando på standby-serveren:
./pg_ctl promote -D ../sb_data/ server promoting - Opret forbindelse til den promoverede standby-server, og indsæt en række:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
Hvis indsættelsen fungerer fint, er standby-serveren, som tidligere var en skrivebeskyttet server, blevet forfremmet som den nye primære server.
Sådan automatiseres Failover i PostgreSQL
Det er nemt at opsætte automatisk failover.
Du skal bruge EDB PostgreSQL failover manager (EFM). Når du har downloadet og installeret EFM på hver primær og standby-node, kan du oprette en EFM Cluster, som består af en primær node, en eller flere Standby-noder og en valgfri Witness-node, der bekræfter assertions i tilfælde af fejl.
EFM overvåger løbende systemets tilstand og sender advarsler via e-mail baseret på systemhændelser. Når der opstår en fejl, skifter den automatisk over til den mest opdaterede standby-node og rekonfigurerer alle andre standby-servere til at genkende den nye primære knude.
Den rekonfigurerer også load balancers (f.eks. pgPool) og forhindrer “split-brain” (når to knudepunkter hver især tror, at de er primære) i at forekomme.
Opsummering
På grund af store datamængder er skalerbarhed og sikkerhed blevet to af de vigtigste kriterier inden for databaseadministration, især i et transaktionsmiljø. Selv om vi kan forbedre skalerbarheden vertikalt ved at tilføje flere ressourcer/hardware til eksisterende knudepunkter, er det ikke altid muligt, ofte på grund af omkostningerne eller begrænsningerne ved at tilføje ny hardware.
Derfor er der behov for horisontal skalerbarhed, hvilket betyder, at der skal tilføjes flere knuder til eksisterende netværksknuder i stedet for at forbedre funktionaliteten af eksisterende knuder. Det er her, PostgreSQL-replikering kommer ind i billedet.
I denne artikel har vi diskuteret typerne af PostgreSQL replikationer, fordele, replikationsformer, installation og PostgreSQL failover Mellem SMR og MMR. Lad os nu høre fra dig.
Hvilken af dem implementerer du normalt? Hvilken databasefunktion er den vigtigste for dig og hvorfor? Vi vil meget gerne læse dine tanker! Del dem i kommentarfeltet nedenfor.

Han er en selvlært webudvikler, skribent, skaber og en stor beundrer af Free and Open Source Software (FOSS). Udover teknologi, er han begejstret for videnskab, filosofi, fotografi, kunst, katte og mad. Lær mere om ham på hans hjemmeside, og kontakt Salman på X.