
Se você gerencia muitos sites WordPress, provavelmente está sempre em busca de maneiras de simplificar e acelerar seus fluxos de trabalho.
Agora, imagine o seguinte: com um único comando em seu terminal, você pode acionar backups manuais para todos os seus sites, mesmo que esteja gerenciando dezenas deles. Esse é o poder da combinação de scripts de shell com a API da Kinsta.
Este guia ensina como usar scripts Shell para configurar comandos personalizados que tornam o gerenciamento dos seus sites muito mais eficiente.
Pré-requisitos
Antes de começarmos, aqui está o que você precisa:
- Um terminal: Todos os sistemas operacionais modernos vêm com software de terminal, portanto, você pode começar a criar scripts imediatamente.
- Um IDE ou editor de texto: Use uma ferramenta com a qual você se sinta confortável, seja o VS Code, o Sublime Text ou até mesmo um editor leve como o Nano para edições rápidas no terminal.
- Uma chave de API da Kinsta: Isso é essencial para você interagir com a API da Kinsta. Para gerar a sua:
- Faça login em seu painel MyKinsta.
- Vá para Seu nome > Configurações da empresa > Chaves API.
- Clique em Criar chave API e salve-a com segurança.
curlejq: Essenciais para fazer solicitações de API e manipular dados JSON. Certifique-se de que estão instalados ou instale-os se necessário.- Conhecimento básico de programação: Você não precisa ser um especialista, mas será útil entender os conceitos básicos de programação e a sintaxe de script de shell.
Escrevendo seu primeiro script
Criar seu primeiro script de shell para interagir com a API da Kinsta é mais simples do que você imagina. Vamos começar com um script simples que lista todos os sites WordPress gerenciados em sua conta Kinsta.
Etapa 1: Configure seu ambiente
Comece criando uma pasta para seu projeto e um novo arquivo de script. A extensão .sh é usada para scripts de shell. Por exemplo, você pode criar uma pasta, navegar até ela e criar e abrir um arquivo de script no VS Code usando estes comandos:
mkdir my-first-shell-scripts
cd my-first-shell-scripts
touch script.sh
code script.shEtapa 2: Defina variáveis de ambiente
Para manter sua chave de API segura, armazene em um arquivo .env em vez de codificá-la no script. Isso permite que você adicione o arquivo .env ao .gitignore, evitando que ele seja enviado para o controle de versão.
Em seu arquivo .env, adicione:
API_KEY=your_kinsta_api_keyEm seguida, importe a chave de API do arquivo .env para o seu script adicionando o seguinte à parte superior do script:
#!/bin/bash
source .envO shebang #!/bin/bash garante que o script seja executado usando o Bash, enquanto source .env importa as variáveis de ambiente.
Etapa 3: Escreva a solicitação de API
Primeiro, armazene o ID da sua empresa (disponível no MyKinsta em Configurações da Empresa > Detalhes de Cobrança) em uma variável:
COMPANY_ID="<your_company_id>"Em seguida, adicione o comando curl para fazer uma solicitação GET ao endpoint /sites, passando o ID da empresa como parâmetro de consulta. Use jq para formatar a saída e torná-la mais legível:
curl -s -X GET
"https://api.kinsta.com/v2/sites?company=$COMPANY_ID"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json" | jqEssa solicitação recupera detalhes sobre todos os sites associados à sua empresa, incluindo seus IDs, nomes e status.
Etapa 4: Torne o script executável
Salve o script e torne-o executável, executando:
chmod +x script.shEtapa 5: Execute o script
Agora, execute o script para ver a lista formatada dos seus sites:
./list_sites.shAo executar o script, você obterá uma resposta semelhante a esta:
{
"company": {
"sites": [
{
"id": "a8f39e7e-d9cf-4bb4-9006-ddeda7d8b3af",
"name": "bitbuckettest",
"display_name": "bitbucket-test",
"status": "live",
"site_labels": []
},
{
"id": "277b92f8-4014-45f7-a4d6-caba8f9f153f",
"name": "duketest",
"display_name": "zivas Signature",
"status": "live",
"site_labels": []
}
]
}
}Isso funciona, mas podemos melhorar o script tornando a formatação mais legível.
Etapa 6: Reestruturar o script usando uma função
Substitua a solicitação curl por uma função reutilizável para lidar com a busca e a formatação da lista de sites:
list_sites() {
echo "Fetching all sites for company ID: $COMPANY_ID..."
RESPONSE=$(curl -s -X GET "https://api.kinsta.com/v2/sites?company=$COMPANY_ID"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
# Check for errors
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API."
exit 1
fi
echo "Company Sites:"
echo "--------------"
echo "$RESPONSE" | jq -r '.company.sites[] | "(.display_name) ((.name)) - Status: (.status)"'
}
# Run the function
list_sitesQuando você executar o script novamente, obterá um resultado bem formatado:
Fetching all sites for company ID: b383b4c-****-****-a47f-83999c5d2...
Company Sites:
--------------
bitbucket-test (bitbuckettest) - Status: live
zivas Signature (duketest) - Status: liveCom esse script, você deu o primeiro passo para usar scripts de shell e a API da Kinsta para automatizar o gerenciamento de sites WordPress. Nas próximas seções, exploraremos a criação de scripts mais avançados para interagir com a API de maneiras ainda mais poderosas.
Caso de uso avançado 1: Criando backups
Criar backups é uma parte essencial do gerenciamento de sites. Eles permitem restaurar seu site em caso de problemas inesperados. Com a API da Kinsta e scripts Shell, esse processo pode ser automatizado, economizando tempo e esforço.
Nesta seção, criaremos backups e abordaremos o limite da Kinsta de cinco backups manuais por ambiente. Para isso, implementaremos um processo que:
- Verifica o número atual de backups manuais.
- Identifica e exclui o backup mais antigo (com confirmação do usuário) caso o limite seja atingido.
- Cria um novo backup automaticamente.
Vamos aos detalhes.
O fluxo de trabalho de backup
Para criar backups usando a API da Kinsta, você usará o seguinte endpoint:
POST /sites/environments/{env_id}/manual-backupsIsso requer:
- ID do ambiente: Identifica o ambiente (como teste ou produção) em que o backup será criado.
- Etiqueta de backup: Uma etiqueta para identificar o backup (opcional).
Obter manualmente o ID do Ambiente e rodar um comando como backup <environment ID> pode ser trabalhoso. Em vez disso, construiremos um script interativo, onde basta informar o nome do site e o script fará o seguinte:
- Busca a lista de ambientes do site.
- Solicita que o usuário escolha o ambiente para backup.
- Executa a criação do backup automaticamente.
Criando funções reutilizáveis para um código mais organizado
Para manter nosso script modular e reutilizável, definiremos funções para tarefas específicas. Vamos examinar a configuração passo a passo.
1. Configure as variáveis básicas
Você pode eliminar o primeiro script que criou ou criar um novo arquivo de script para isso. Comece declarando a URL básica da API da Kinsta e o ID da sua empresa no script:
BASE_URL="https://api.kinsta.com/v2"
COMPANY_ID="<your_company_id>"Essas variáveis permitem construir os endpoints da API dinamicamente dentro do script.
2. Buscar todos os sites
Defina uma função para buscar a lista de todos os sites da empresa. Isso permite que você recupere detalhes sobre cada site posteriormente.
get_sites_list() {
API_URL="$BASE_URL/sites?company=$COMPANY_ID"
echo "Fetching all sites for company ID: $COMPANY_ID..."
RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
# Check for errors
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API."
exit 1
fi
echo "$RESPONSE"
}Você notará que essa função retorna uma resposta não formatada da API. Para você obter uma resposta formatada. Você pode adicionar outra função para lidar com isso (embora essa não seja a nossa preocupação nesta seção):
list_sites() {
RESPONSE=$(get_sites_list)
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API while fetching sites."
exit 1
fi
echo "Company Sites:"
echo "--------------"
# Clean the RESPONSE before passing it to jq
CLEAN_RESPONSE=$(echo "$RESPONSE" | tr -d 'r' | sed 's/^[^{]*//') # Removes extra characters before the JSON starts
echo "$CLEAN_RESPONSE" | jq -r '.company.sites[] | "(.display_name) ((.name)) - Status: (.status)"'
}Ao chamar a função list_sites, você exibe seus sites conforme mostrado anteriormente. O objetivo principal, no entanto, é acessar cada site e seu ID, permitindo que você recupere informações detalhadas sobre cada site.
3. Obter detalhes do site
Para obter informações detalhadas de um site específico, criamos a seguinte função. Ela busca o ID do site com base no nome informado pelo usuário e recupera os detalhes do site, incluindo seus ambientes (necessários para acionar backups).
get_site_details_by_name() {
SITE_NAME=$1
if [ -z "$SITE_NAME" ]; then
echo "Error: No site name provided. Usage: $0 details-name "
return 1
fi
RESPONSE=$(get_sites_list)
echo "Searching for site with name: $SITE_NAME..."
# Clean the RESPONSE before parsing
CLEAN_RESPONSE=$(echo "$RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')
# Extract the site ID for the given site name
SITE_ID=$(echo "$CLEAN_RESPONSE" | jq -r --arg SITE_NAME "$SITE_NAME" '.company.sites[] | select(.name == $SITE_NAME) | .id')
if [ -z "$SITE_ID" ]; then
echo "Error: Site with name "$SITE_NAME" not found."
return 1
fi
echo "Found site ID: $SITE_ID for site name: $SITE_NAME"
# Fetch site details using the site ID
API_URL="$BASE_URL/sites/$SITE_ID"
SITE_RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
echo "$SITE_RESPONSE"
}A função acima filtra o site usando o nome do site e, em seguida, recupera detalhes adicionais sobre o site usando o endpoint /sites/<site-id>. Esses detalhes incluem os ambientes do site, que é o que precisamos para acionar os backups.
Criação de backups
Agora que você configurou funções reutilizáveis para obter detalhes do site e listar ambientes, pode se concentrar na automatização do processo de criação de backups. O objetivo é executar um comando simples com apenas o nome do site e, em seguida, escolher interativamente o ambiente para fazer o backup.
Comece criando uma função (vamos chamá-la de trigger_manual_backup). Dentro da função, defina duas variáveis: a primeira para aceitar o nome do site como entrada e a segunda para definir uma tag padrão (default-backup) para o backup. Essa tag padrão será aplicada, a menos que você opte por especificar uma tag personalizada posteriormente.
trigger_manual_backup() {
SITE_NAME=$1
DEFAULT_TAG="default-backup"
# Ensure a site name is provided
if [ -z "$SITE_NAME" ]; then
echo "Error: Site name is required."
echo "Usage: $0 trigger-backup "
return 1
fi
# Add the code here
}Essa SITE_NAME é o identificador do site que você deseja gerenciar. Você também configura uma condição para que o script se encerre com uma mensagem de erro caso o identificador não seja fornecido. Isso garante que o script não prossiga sem a entrada necessária, prevenindo possíveis erros da API.
Em seguida, use a função reutilizável get_site_details_by_name para obter informações detalhadas sobre o site, incluindo seus ambientes. A resposta é então limpa para remover qualquer formatação inesperada que possa surgir durante o processamento.
SITE_RESPONSE=$(get_site_details_by_name "$SITE_NAME")
if [ $? -ne 0 ]; then
echo "Error: Failed to fetch site details for site "$SITE_NAME"."
return 1
fi
CLEAN_RESPONSE=$(echo "$SITE_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Depois de obter os detalhes do site, o script abaixo extrai todos os ambientes disponíveis e os exibe em um formato legível. Isso ajuda a visualizar quais ambientes estão vinculados ao site.
O script então solicita que você selecione um ambiente pelo nome. Esse passo interativo torna o processo mais amigável, eliminando a necessidade de lembrar ou inserir manualmente os IDs dos ambientes.
ENVIRONMENTS=$(echo "$CLEAN_RESPONSE" | jq -r '.site.environments[] | "(.name): (.id)"')
echo "Available Environments for "$SITE_NAME":"
echo "$ENVIRONMENTS"
read -p "Enter the environment name to back up (e.g., staging, live): " ENV_NAMEO nome do ambiente selecionado é usado para procurar o ID do ambiente correspondente nos detalhes do site. Esse ID é necessário para que as solicitações de API criem um backup.
ENV_ID=$(echo "$CLEAN_RESPONSE" | jq -r --arg ENV_NAME "$ENV_NAME" '.site.environments[] | select(.name == $ENV_NAME) | .id')
if [ -z "$ENV_ID" ]; then
echo "Error: Environment "$ENV_NAME" not found for site "$SITE_NAME"."
return 1
fi
echo "Found environment ID: $ENV_ID for environment name: $ENV_NAME"No código acima, é criada uma condição para que o script seja encerrado com uma mensagem de erro se o nome do ambiente fornecido não corresponder.
Agora que você tem o ID do ambiente, pode continuar a verificar o número atual de backups manuais para o ambiente selecionado. Como o limite da Kinsta é de cinco backups manuais por ambiente, essa etapa é crucial para evitar erros.
Vamos começar buscando a lista de backups usando o endpoint da API /backups.
API_URL="$BASE_URL/sites/environments/$ENV_ID/backups"
BACKUPS_RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
CLEAN_RESPONSE=$(echo "$BACKUPS_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')
MANUAL_BACKUPS=$(echo "$CLEAN_RESPONSE" | jq '[.environment.backups[] | select(.type == "manual")]')
BACKUP_COUNT=$(echo "$MANUAL_BACKUPS" | jq 'length')O script acima filtra os backups manuais e os conta. Se o número atingir o limite, será necessário gerenciar os backups existentes:
if [ "$BACKUP_COUNT" -ge 5 ]; then
echo "Manual backup limit reached (5 backups)."
# Find the oldest backup
OLDEST_BACKUP=$(echo "$MANUAL_BACKUPS" | jq -r 'sort_by(.created_at) | .[0]')
OLDEST_BACKUP_NAME=$(echo "$OLDEST_BACKUP" | jq -r '.note')
OLDEST_BACKUP_ID=$(echo "$OLDEST_BACKUP" | jq -r '.id')
echo "The oldest manual backup is "$OLDEST_BACKUP_NAME"."
read -p "Do you want to delete this backup to create a new one? (yes/no): " CONFIRM
if [ "$CONFIRM" != "yes" ]; then
echo "Aborting backup creation."
return 1
fi
# Delete the oldest backup
DELETE_URL="$BASE_URL/sites/environments/backups/$OLDEST_BACKUP_ID"
DELETE_RESPONSE=$(curl -s -X DELETE "$DELETE_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
echo "Delete Response:"
echo "$DELETE_RESPONSE" | jq -r '[
"Operation ID: (.operation_id)",
"Message: (.message)",
"Status: (.status)"
] | join("n")'
fiA condição acima identifica o backup mais antigo, classificando a lista com base no registro de data e hora created_at. Em seguida, ele solicita que você confirme se deseja excluí-lo.
Se você concordar, o script excluirá o backup mais antigo usando seu ID, liberando espaço para o novo. Isso garante que os backups sempre possam ser criados sem que você precise gerenciar manualmente os limites.
Agora que há espaço, vamos prosseguir com o código para acionar o backup para o ambiente. Sinta-se à vontade para ignorar esse código, mas, para ter uma experiência melhor, ele solicita que você especifique uma tag personalizada, tendo como padrão “default-backup” se nenhuma for fornecida.
read -p "Enter a backup tag (or press Enter to use "$DEFAULT_TAG"): " BACKUP_TAG
if [ -z "$BACKUP_TAG" ]; then
BACKUP_TAG="$DEFAULT_TAG"
fi
echo "Using backup tag: $BACKUP_TAG"Por fim, o script abaixo é onde a ação de backup acontece. Ele envia uma solicitação POST para o endpoint /manual-backups com o ID do ambiente selecionado e a tag de backup. Se a solicitação for bem-sucedida, a API retornará uma resposta confirmando a criação do backup.
API_URL="$BASE_URL/sites/environments/$ENV_ID/manual-backups"
RESPONSE=$(curl -s -X POST "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json"
-d "{"tag": "$BACKUP_TAG"}")
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API while triggering the manual backup."
return 1
fi
echo "Backup Trigger Response:"
echo "$RESPONSE" | jq -r '[
"Operation ID: (.operation_id)",
"Message: (.message)",
"Status: (.status)"
] | join("n")'Isso é tudo. A resposta obtida da solicitação acima é formatada para exibir o ID da operação, a mensagem e o status, garantindo clareza na saída. Se você chamar a função e executar o script, verá uma saída semelhante a esta:
Available Environments for "example-site":
staging: 12345
live: 67890
Enter the environment name to back up (e.g., staging, live): live
Found environment ID: 67890 for environment name: live
Manual backup limit reached (5 backups).
The oldest manual backup is "staging-backup-2023-12-31".
Do you want to delete this backup to create a new one? (yes/no): yes
Oldest backup deleted.
Enter a backup tag (or press Enter to use "default-backup"): weekly-live-backup
Using backup tag: weekly-live-backup
Triggering manual backup for environment ID: 67890 with tag: weekly-live-backup...
Backup Trigger Response:
Operation ID: backups:add-manual-abc123
Message: Adding a manual backup to environment in progress.
Status: 202Criando comandos para o seu script
Os comandos simplificam o uso do script. Em vez de editar o código manualmente ou comentar partes específicas, os usuários podem executá-lo com um comando específico, como:
./script.sh list-sites
./script.sh backup No final do seu script (fora de todas as funções), inclua um bloco condicional que verifique os argumentos passados para o script:
if [ "$1" == "list-sites" ]; then
list_sites
elif [ "$1" == "backup" ]; then
SITE_NAME="$2"
if [ -z "$SITE_NAME" ]; then
echo "Usage: $0 trigger-backup "
exit 1
fi
trigger_manual_backup "$SITE_NAME"
else
echo "Usage: $0 {list-sites|trigger-backup }"
exit 1
fiA variável $1 representa o primeiro argumento passado para o script (por exemplo, em ./script.sh list-sites, $1 é list-sites). O script usa verificações condicionais para fazer a correspondência entre $1 e comandos específicos, como list-sites ou backup. Se o comando for backup, ele também espera um segundo argumento ($2), que é o nome do site. Se nenhum comando válido for fornecido, o script exibirá por padrão as instruções de uso.
Agora você pode acionar um backup manual para um site específico executando o comando:
./script.sh backupCaso de uso avançado 2: Atualizando plugins em múltiplos sites
Gerenciar plugins do WordPress em múltiplos sites pode ser uma tarefa demorada, especialmente quando há atualizações disponíveis. A Kinsta já oferece um recurso de atualização em massa no painel MyKinsta.
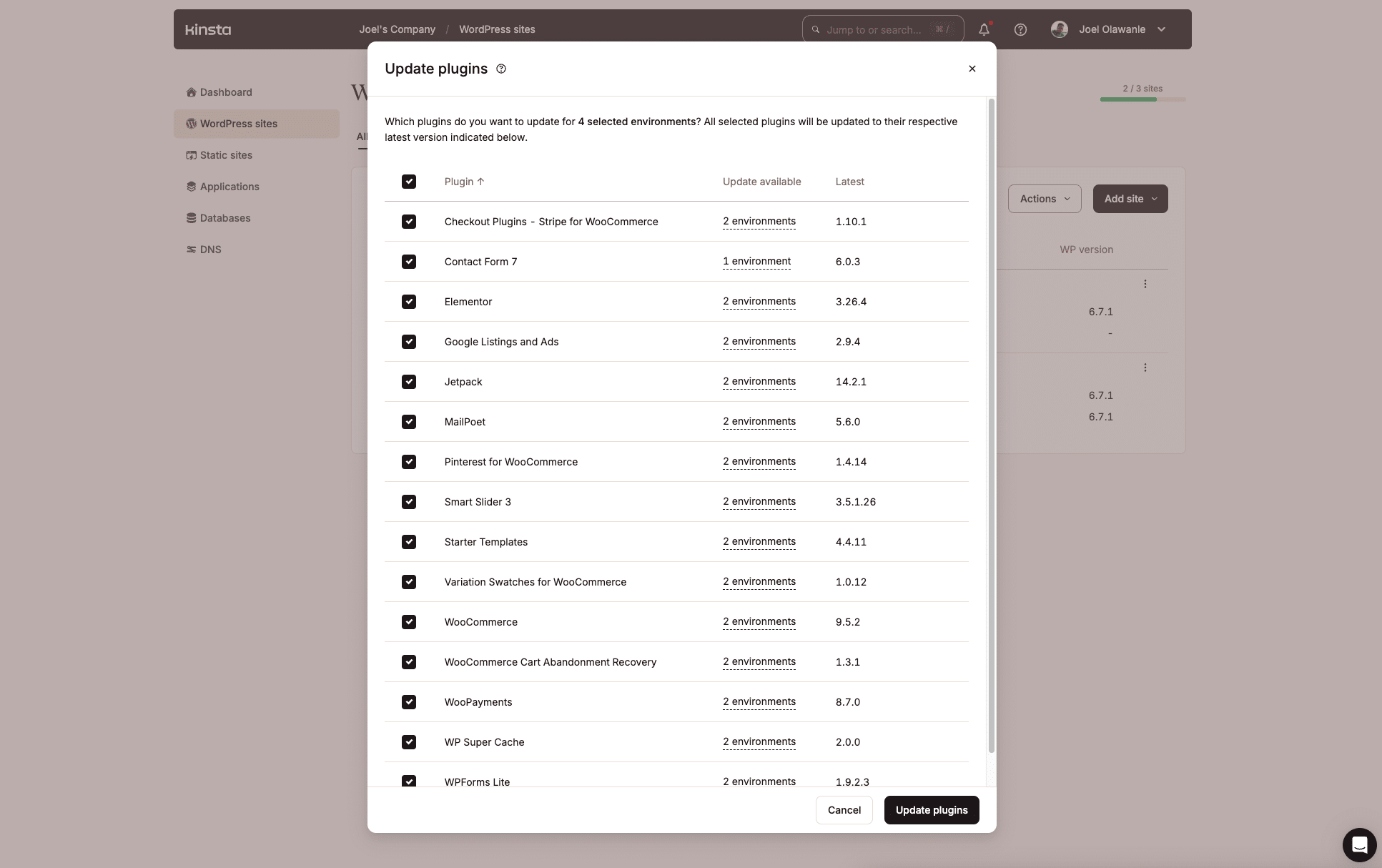
No entanto, se você prefere não utilizar interfaces gráficas, a API da Kinsta permite criar um script Shell para automatizar a identificação de plugins desatualizados e atualizá-los em múltiplos sites ou ambientes específicos.
Detalhando o fluxo de trabalho
1. Identificar sites com plugins desatualizados: O script percorre todos os sites e ambientes, procurando o plugin especificado com uma atualização disponível. O seguinte endpoint é usado para buscar a lista de plugins para um ambiente de site específico:
GET /sites/environments/{env_id}/pluginsA resposta da API é filtrada para encontrar plugins com "update": "available".
2. Solicitar opções de atualização ao usuário: Exibe os sites e ambientes com o plugin desatualizado, permitindo que o usuário selecione instâncias específicas ou atualize todas elas.
3. Acionar atualizações do plugin: Para atualizar o plugin em um ambiente específico, o script usa esse endpoint:
PUT /sites/environments/{env_id}/pluginsO nome do plugin e a versão mais recente são enviados no corpo da requisição.
O script
Como o script é longo, a função completa está hospedada no GitHub para facilitar o acesso. Aqui, explicaremos a lógica principal usada para identificar plugins desatualizados em vários sites e ambientes.
O script começa aceitando o nome do plugin como argumento. Esse nome define o plugin que será atualizado.
PLUGIN_NAME=$1
if [ -z "$PLUGIN_NAME" ]; then
echo "Error: Plugin name is required."
echo "Usage: $0 update-plugin "
return 1
fiEm seguida, o script usa a função reutilizável get_sites_list (explicada anteriormente) para buscar todos os sites da empresa:
echo "Fetching all sites in the company..."
# Fetch all sites in the company
SITES_RESPONSE=$(get_sites_list)
if [ $? -ne 0 ]; then
echo "Error: Failed to fetch sites."
return 1
fi
# Clean the response
CLEAN_SITES_RESPONSE=$(echo "$SITES_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')A seguir, o coração do script: um loop que percorre a lista de sites para verificar se há plugins desatualizados. O JSON limpo contendo todos os sites CLEAN_SITES_RESPONSE é passado para um loop while, que processa cada site um por um.
Primeiro, o script extrai os dados importantes do site, como ID, nome e nome de exibição:
while IFS= read -r SITE; do
SITE_ID=$(echo "$SITE" | jq -r '.id')
SITE_NAME=$(echo "$SITE" | jq -r '.name')
SITE_DISPLAY_NAME=$(echo "$SITE" | jq -r '.display_name')
echo "Checking environments for site "$SITE_DISPLAY_NAME"..."O nome do site é então usado junto com a função get_site_details_by_name definida anteriormente para buscar informações detalhadas sobre o site, incluindo todos os seus ambientes.
SITE_DETAILS=$(get_site_details_by_name "$SITE_NAME")
CLEAN_SITE_DETAILS=$(echo "$SITE_DETAILS" | tr -d 'r' | sed 's/^[^{]*//')
ENVIRONMENTS=$(echo "$CLEAN_SITE_DETAILS" | jq -r '.site.environments[] | "(.id):(.name):(.display_name)"')Os ambientes do site são então percorridos para extrair ID, nome e nome de exibição de cada um:
while IFS= read -r ENV; do
ENV_ID=$(echo "$ENV" | cut -d: -f1)
ENV_NAME=$(echo "$ENV" | cut -d: -f2)
ENV_DISPLAY_NAME=$(echo "$ENV" | cut -d: -f3)
echo "Checking plugins for environment "$ENV_DISPLAY_NAME"..."Para cada ambiente, o script agora obtém sua lista de plugins usando a API da Kinsta.
PLUGINS_RESPONSE=$(curl -s -X GET "$BASE_URL/sites/environments/$ENV_ID/plugins"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
CLEAN_PLUGINS_RESPONSE=$(echo "$PLUGINS_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Em seguida, o script verifica se o plugin especificado existe no ambiente e se há uma atualização disponível:
OUTDATED_PLUGIN=$(echo "$CLEAN_PLUGINS_RESPONSE" | jq -r --arg PLUGIN_NAME "$PLUGIN_NAME" '.environment.container_info.wp_plugins.data[] | select(.name == $PLUGIN_NAME and .update == "available")')Se um plugin desatualizado for encontrado, o script exibe suas informações e o adiciona ao array SITES_WITH_OUTDATED_PLUGIN:
if [ ! -z "$OUTDATED_PLUGIN" ]; then
CURRENT_VERSION=$(echo "$OUTDATED_PLUGIN" | jq -r '.version')
UPDATE_VERSION=$(echo "$OUTDATED_PLUGIN" | jq -r '.update_version')
echo "Outdated plugin "$PLUGIN_NAME" found in "$SITE_DISPLAY_NAME" (Environment: $ENV_DISPLAY_NAME)"
echo " Current Version: $CURRENT_VERSION"
echo " Update Version: $UPDATE_VERSION"
SITES_WITH_OUTDATED_PLUGIN+=("$SITE_DISPLAY_NAME:$ENV_DISPLAY_NAME:$ENV_ID:$UPDATE_VERSION")
fiEsta é a aparência dos detalhes registrados de plugins desatualizados:
Outdated plugin "example-plugin" found in "Site ABC" (Environment: Production)
Current Version: 1.0.0
Update Version: 1.2.0
Outdated plugin "example-plugin" found in "Site XYZ" (Environment: Staging)
Current Version: 1.3.0
Update Version: 1.4.0A partir daqui, realizamos atualizações de plugins para cada plugin usando seu endpoint. O script completo está neste repositório do GitHub.
Resumo
Este artigo guiou você na criação de um script Shell para interagir com a API da Kinsta.
Reserve um tempo para explorar mais a fundo a API da Kinsta — você descobrirá recursos adicionais que podem ser automatizados para gerenciar tarefas personalizadas conforme suas necessidades específicas. Você também pode considerar integrar a API da Kinsta com outras APIs para aprimorar a tomada de decisões e a eficiência.
Por fim, verifique regularmente o painel MyKinsta para acompanhar novos recursos desenvolvidos para facilitar ainda mais o gerenciamento de sites por meio de sua interface intuitiva.


