Oprettelse af et websted er det første skridt, når du etablerer din tilstedeværelse på internettet. Hvis du skal klare dig godt på længere sigt, skal du også sikre dig, at dit websted kan skaleres, så det kan rumme vækst. Og et af de første skridt er at implementere en database, der kan skaleres sammen med dig. Ellers risikerer du at opleve langsom forespørgselsydelse og databaseafbrydelser.
I dette indlæg vil vi diskutere, hvordan du kan bruge database-sharding til at opnå høj skalerbarhed og tilgængelighed for dine data. Vi vil også berøre ulemperne ved sharding og de forskellige sharding-arkitekturer, du kan bruge.
Hvad er Database Sharding?
Sharding er en optimeringsteknik, der distribuerer tabeller på tværs af andre databaseservere. Det er ligesom partitionering i den forstand, at begge involverer opdeling af data i mindre delmængder. Forskellen er, at sharding fordeler disse delmængder på forskellige servere, mens partitionering gemmer dem i én database. Disse servere bruger den samme databasemotor og hardwaretype for at opnå et lignende ydelsesniveau for alle shards.
Sharding har til formål at opnå en arkitektur med deling af intet, hvilket eliminerer flaskehalse i behandlingen og enkeltstående fejlpunkter.
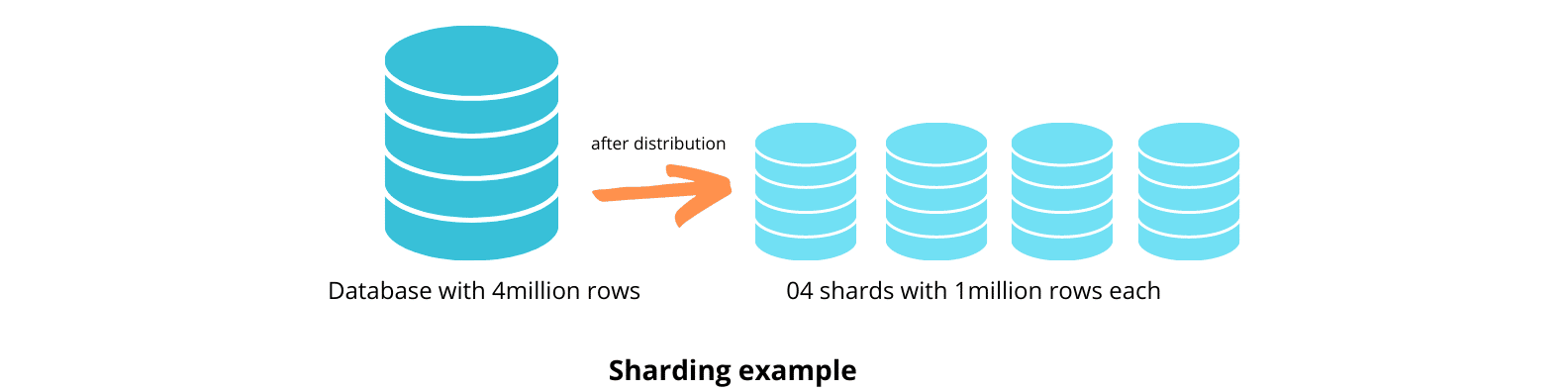
Du kan implementere sharding på to måder – horisontalt og vertikalt. Horisontal sharding opdeler tabellen baseret på rækker, mens vertikal sharding opdeler tabellerne baseret på kolonner.
I denne henseende er sharding ligesom partitionering, som opdeler store tabeller i mindre tabeller.
Horisontal sharding er effektiv til databaser, hvor de fleste forespørgsler returnerer en delmængde af rækker, f.eks. en kundedatabase, der returnerer data (f.eks. navn, adresse, e-mail osv.) på en gang.
Vertikal sharding er effektiv til databaser, hvis forespørgsler returnerer enkelte kolonner. Hvis kundedatabasen f.eks. returnerede kundens navn eller e-mail separat, kunne du adskille navn og e-mail i forskellige klynger.
Fordele ved database-sharding
Nedenfor er nogle af fordelene ved database-sharding.
Forbedret horisontal skalering
Du kan skalere din database vertikalt eller horisontalt. Vertikal skalering henviser til tilføjelse af flere CPU’er (central processing units) og RAM-hukommelse (random access memory) til serveren for at forbedre ydeevnen. Vertikal skalering er en nyttig løsning for små til mellemstore databaser. Når dine data vokser, bliver vertikal skalering imidlertid uoverkommelig. Der er kun et vist antal kræfter, som du kan tilføje til en enkelt server.
Horisontal skalering er mere fleksibel. Den giver dig mulighed for at skalere din database efter behov ved at tilføje flere servere til dit system. Hver af disse servere leverer ressourcer til forskellige databaseshards. Dette fordeler arbejdsbyrden og forbedrer systemets evne til at håndtere flere anmodninger.
Hurtigere svartider på forespørgsler
Shards har kun få rækker og kolonner. På grund af dette tager det mindre tid at behandle databaseforespørgsler. I modsætning hertil kan en forespørgsel i en ikke-sharded database kræve en søgning gennem hundredvis – eller endog tusindvis – af rækker.
Øget pålidelighed i situationer med afbrydelser
Databasestop kan forekomme af forskellige årsager, herunder utilsigtet sletning af data, forbindelsesfejl og cybersikkerhedsangreb. Sharding minimerer virkningerne af nedbrud. Da hver shard er selvstændig, er det kun den berørte shard, der er udsat for nedetid. Hvis du f.eks. har fire shards og oplever et nedbrud i en af dem, vil kun 25 procent af driften blive påvirket.
Ulemper ved sharding
Selv om sharding forbedrer en databases pålidelighed og tilgængelighed, er det komplekst at implementere det. Brug af den forkerte sharding-arkitektur kan sænke ydelsen og føre til tab af data.
Sørg for at vælge en sharding-teknik, der giver mulighed for en afbalanceret datafordeling på tværs af alle shards. Uden denne balance risikerer du at skabe databasehotspots, hvilket sker, når en shard lagrer de fleste data, mens andre shards praktisk talt forbliver tomme. Dette reducerer skrivegennemstrømningen til den enkelte shard.
For at løse dette problem kan du partitionere den ubalancerede shard endnu mere, men denne proces er udfordrende og kan lægge din database ned, mens du migrerer data.
En anden ulempe ved sharding er, at SQL-joins, der involverer flere tabeller i forskellige shards, kan blive for langsomme og forringe ydelsen. Med den rigtige arkitektur kan du dog undgå dette problem.
Sharding-arkitekturer
Du kan implementere sharding ved hjælp af tre arkitekturer:
- Nøglebaseret sharding
- Rækkeviddebaseret sharding
- Katalogbaseret sharding
Den arkitektur, du vælger, afhænger af dit brugsscenarie.
Nøglebaseret sharding
I en nøgle- eller hash-baseret sharding-arkitektur bruger et databaseprogram en shardnøgle til at finde en shard. En hashing-funktion hasher sharding-nøgleværdien, og resultatet mapper data til en bestemt shard. En simpel hashing-funktion kan være modulet af nøglen og antallet af shards.
Hashfunktionen kan tage mere end én nøgle til opdeling af sharding. Derfor er nøglebaseret sharding velegnet til dataposter, der kan have fælles nøgler. Algoritmisk fordeling af data minimerer muligheden for at skabe database-hotspots, hvor den ene shard indeholder flere data end den anden.
Da fordelingen imidlertid kun er afhængig af hashing-funktionen, er det umuligt at gruppere data logisk sammen. Derfor kan databaseoperationer, der kræver data fra flere shards, være ineffektive, da de kræver læsning af data fra hver shard.
Områdebaseret sharding
Områdebaseret sharding indebærer sharding af en database afhængigt af et bestemt interval af værdier.
Der bruges en shardingnøgle til at bestemme, hvilken shard en værdi skal tildeles. Databaseprogrammet kontrollerer den shard, der svarer til shardingnøglen i en opslagstabel, og gemmer dataene. På grund af dette er intervalbaseret sharding let at designe og implementere.
Du kan f.eks. bruge bruger-ID-værdien i en brugerdatabase som shardingnøgle. Du kan gemme brugere med ID’er fra 0-2.000 på en shard, brugere med ID’er mellem 2.000 og 4.000 på en anden shard osv.
Områdebaseret sharding kan forårsage databasehotspots. Tænk på en brugerdatabase, hvor de fleste af dine bruger-id’er ligger mellem 2.001 og 4.000. Processen tildeler dem til en enkelt shard, hvilket skaber en ubalance over tid. Områdebaseret sharding fungerer derfor bedst til jævnt fordelte data.
Katalogbaseret sharding
Katalogbaseret sharding grupperer logisk relaterede data i den samme shard. Der anvendes en opslagstabel, som indeholder en liste over mappinger for hver enhed i databasen. Hver mapping svarer til en database shard.
Katalogbaseret sharding er mere fleksibel end områdebaseret eller nøglebaseret sharding, fordi du kan tilføje data til shards dynamisk. Der er ingen sharding-funktion, som du skal følge, eller intervalværdier, som du skal holde dig inden for. Denne fleksibilitet øger databasens effektivitet: Du kan gemme relaterede data i én shard, hvilket betyder, at det tager mindre tid at udføre almindelige forespørgsler.
Hvis du f.eks. har brugt mappebaseret sharding og grupperet brugere efter deres placering, og du henter brugere fra et bestemt sted, skal du kun forespørge på en enkelt shard.
Database Sharding med Kinsta
De fleste moderne databasemotorer understøtter database-sharding. En af disse databasemaskiner er MariaDB, en kommercielt understøttet fork af MySQL. Det er et højtydende open source-databasesystem, der er vedtaget af virksomheder som IBM, GitHub og Wikimedia. Det er også en del af den højtydende serverstack hos Kinsta.
MariaDB tilbyder indbyggede sharding-funktioner gennem spider storage engine. Spider storage engine er en klyngedannelsesmotor, der understøtter partitionering og XA-transaktioner (extended architecture). Den giver dig mulighed for at behandle fjerntabeller fra forskellige instanser, som om de er i den samme instans. Når du opretter en tabel i spider storage-motoren, linker tabellen til en anden tabel i den eksterne MariaDB-server. Når forbindelsen er etableret, deler lagermotoren linket med alle tabeller, der er en del af den samme transaktion.
Oversigt
Database sharding er en skaleringsteknik, der opdeler tabeller i mindre delmængder og distribuerer dem til forskellige servere kaldet shards. Du kan implementere sharding på forskellige måder, f.eks. nøglebaseret sharding, områdebaseret sharding og mappebaseret sharding.
Selvom sharding forbedrer en databases skalerbarhed, pålidelighed og tilgængelighed, er det meget komplekst at implementere. Når du først har oprettet en sharding, er det desuden ikke let at vende databasen tilbage til dens ushardede tilstand. På grund af dette skal du kun bruge sharding til optimering, når du er sikker på, at andre muligheder for skalerbarhed ikke vil fungere.
Uanset om din virksomhed er en nonprofit-virksomhed eller en virksomhed på virksomhedsniveau, kan Kinas ekspertløsninger fjerne dine bekymringer med hensyn til webstedshosting, så du kan fokusere på det, der betyder mest.

Han er en selvlært webudvikler, skribent, skaber og en stor beundrer af Free and Open Source Software (FOSS). Udover teknologi, er han begejstret for videnskab, filosofi, fotografi, kunst, katte og mad. Lær mere om ham på hans hjemmeside, og kontakt Salman på X.