Persistent storage henviser til opbevaring af data på en ikke-flygtig måde, så de forbliver tilgængelige, selv efter at en enhed eller en applikation er slukket eller genstartet. Lagring og hentning af data gør det muligt for webapplikationer at gemme brugeroplysninger og -tilstande og fungere pålideligt.
I monolitiske applikationer er adgangen til lageret ukompliceret, fordi serveren og lageret bor sammen. Geografisk distribuerede systemer gør imidlertid adgangen mere kompleks, da lagringssystemet skal være tilgængeligt for alle komponenter i hele verden.
Containerisering komplicerer problemet yderligere, fordi containere er lette, tilstandsløse og flygtige – uegnede egenskaber til lagring af data. Derfor skal enhver persistent storage-løsning kunne fungere problemfrit med containere, hvilket tilføjer endnu et lag af kompleksitet.
Kinstas containeriserede Applikation Hostingplatform bruger Kubernetes vedvarende volumener til at knytte persistent storage til en eller flere af en applikations processer. Kinsta-brugere kan definere deres vedvarende lagringskrav, mens de opretter applikationer i MyKinsta-dashboardet.
Denne artikel tager et platformsuafhængigt kig på persistent storage ved at udforske dens typer, arkitektur og anvendelsesmuligheder. Den indeholder også en praktisk demonstration, der illustrerer forskellen mellem volumenlagring og persistent volumenlagring i Docker.
Typer af Persistent Storage
Der findes flere typer af ikke-flygtig lagring, herunder traditionelle spindediske (harddiske eller HDD’er), SSD’er (Solid State Drives), NAS (Network-Attached Storage) og SAN’er (Storage Area Networks).
-
- HDD’er er elektromekaniske datalagringsenheder, der lagrer og henter digitale data ved hjælp af spindeldiske af magnetiske medier. Diskene anvender magnetiske hoveder på en bevægelig aktuatorarm, der læser og skriver data.
- SSD’er, der undertiden kaldes halvlederlagringsenheder, solid-state-enheder eller solid-state-diske, anvender integrerede kredsløb til vedvarende lagring af data, normalt ved hjælp af sammenkoblede flash-enheder uden bevægelige dele. Deres stationære karakter gør dem hurtigere og mere pålidelige end HDD’er.
- Netværkstilsluttet lagring er en gruppe af HDD’er, SSD’er eller begge dele, der er forbundet via et lokalt netværk ved hjælp af et filsystem som NTFS (New Technology File System) eller EXT4 (4th Extended Filesystem).
- SAN’er er netværksbaserede højhastighedslagerenheder på blokniveau, som f.eks. båndbiblioteker eller disk arrays. Deres forbindelse vises for operativsystemet som lokal lagring og er ikke tilgængelig via LAN (Local Area Network).
Arkitektur for persistant storage
Der findes tre tilgange til persistent storage, hver med unikke anvendelsesmuligheder og begrænsninger.
Objektbestandig arkitektur
Den vedvarende objektarkitektur anvender objekt-relationel mapping (ORM) til at lagre data som objekter i en relationel database eller en nøgleværdi-database. Denne tilgang er nyttig, når dataene ikke har et defineret skema, da ORM’en håndterer lagring og hentning af dataene.
Blokpersistent arkitektur
Ved blokpersistent arkitektur anvendes lagerenheder på blokniveau, som er nyttige ved lagring af store filer. Denne tilgang er fordelagtig, når der skal lagres store mængder data, da du kan bruge flere blokke for at øge lagerkapaciteten.
Filestore persistent arkitektur
Som navnet antyder, bruger filestore persistent arkitekturtilgangen et filsystem til at gemme data. En metode indebærer brug af databaseservere, som giver en centraliseret måde at lagre data på. Cloudhostingløsninger som Kinsta’s bruger databaseservere, der let kan tilknyttes applikationer og tilbyder persistens.
Filestore persistent arkitektur er nyttig i applikationer, der kræver hyppig hentning af filer, og når du har brug for en grænseflade til at administrere dem.
Anvendelsestilfælde for persistent storage
I dette afsnit gennemgås nogle af anvendelsestilfældene for de enkelte lagringstyper.
Persistent objektlagring
- Opbevaring i skyen: Objektpersistent lagring bruges ofte i cloud-lagringsløsninger til at lagre og hente store mængder ustrukturerede data, f.eks. billeder, videoer og dokumenter. Cloud-udbydere bruger objektlagring til at give kunderne skalerbare, meget tilgængelige og holdbare lagertjenester.
- Big data-analyse: Vedvarende objektlagring anvendes i big data-analyse til at lagre og administrere store datasæt, der ofte anvendes til dataanalyse, maskinlæring og AI. Objektlagring gør det muligt at få adgang til data hurtigt og effektivt, hvilket gør det til en vigtig komponent i big data-arkitekturer.
- Netværk til levering af indhold: Vedvarende objektlagring anvendes i content delivery netowrk (CDN’er) til at lagre og distribuere indhold, f.eks. billeder, videoer og statiske filer, på tværs af et globalt netværk af servere. Objektlagring gør det muligt for CDN’er at levere højhastighedsindhold til brugere over hele verden, uanset hvor de befinder sig.
Persistent blokopbevaring
- Højtydende databehandling (HPC): HPC-miljøer hurtig og effektiv behandling af store datamængder. Block persistent storage gør det muligt for HPC-klynger at lagre og hente store datasæt, f.eks. videnskabelige simuleringer, vejrmodellering og finansielle analyser. Bloklagring foretrækkes ofte til HPC, fordi den giver højtydende adgang til data med lav latenstid og muliggør parallelle input/output-operationer (I/O), hvilket kan forbedre behandlingstiden betydeligt.
- Videoredigering: Videoredigeringsprogrammer kræver højtydende adgang til store videofiler med lav latenstid og høj ydeevne. De skal også kunne håndtere et betydeligt antal I/O-operationer pr. sekund og lav latenstid for at kunne rendere og redigere videofiler i realtid. Bloklagring giver disse muligheder, hvilket gør det til en ideel løsning til videoredigering af arbejdsgange.
- Spil: Spilapplikationer kræver også høj ydeevne og lav latenstid for at få adgang til spilaktiver og spillerdata. Block storage lagrer og henter hurtigt store datamængder, hvilket sikrer, at spilmiljøer indlæses hurtigt og forbliver responsive under spillet.
Filestore Persistent storage
- Medier og underholdning: Videoredigering, animation og renderingsprogrammer bruger ofte vedvarende lagring. Disse programmer kræver højtydende adgang til store mediefiler, f.eks. video, lyd og billeder, med lav forsinkelse og høj ydeevne. Filestore tilbyder et delt filsystem, som flere klienter kan få adgang til, hvilket gør det til en ideel lagerløsning til disse applikationer.
- Styring af webindhold: Web vontent management systemer (CMS’er) bruger filestore vedvarende lagring i delte filsystemer til at lagre og administrere webindhold, f.eks. tekst, billeder og multimediefiler. Filestore giver en central placering for webstedsindhold, hvilket gør det lettere at administrere og opdatere det. Det gør det også muligt for flere brugere at arbejde samtidigt på det samme indhold, hvilket forbedrer samarbejdet og produktiviteten.
Persistent storage i containere
Containere er lette, bærbare, sikre og ukomplicerede og tilbyder en fusion mellem forskellige applikationer. De skal have en mekanisme til at persistere data mellem genstart og fjernelse af containere. Containere har filopbevaring eller et filsystem ligesom traditionelle applikationer, men når du genopbygger dem med nye ændringer, mister du alle ikke-persistente data.
Derfor tilbyder containere mulighed for at inkludere volumenlagring eller montere et lagringsvolumen. Containere behandler lagringsvolumener som en mappe. Alle data, der skrives til volumenet, går ind i hostsfilsystemet.
Persistent storage for containere skal fungere på denne måde, fordi genstart af en container skaber en ny instans og kasserer den gamle instans. Hvis en container ikke har en konsistent visning af dataene, vil dataene forsvinde, når containeren genstartes. Et lagringsvolumen bevarer dataene på tværs af sessioner og genstart af containeren, så containeren kan bevare sin tilstand, selv om den flyttes eller genstartes.
Volumen vs. persistent volumen
Containere tilbyder 2 måder at lagre vedvarende data på: ved hjælp af volumener og vedvarende volumener. Der er en væsentlig forskel mellem dem. En container administrerer dataene i volumenlagring. Når du stopper en container, forbliver dataene og er tilgængelige, når du genstarter containeren. Men når du sletter eller fjerner en container, går dataene tabt, da du også sletter den underliggende volumenlagring.
Persistent volumenlagring eller bind mounts er en måde at lagre data uden for containerens filsystem på. På denne måde går dataene ikke tabt, selv når du sletter containeren. De er persistente, indtil de slettes manuelt.
I det følgende afsnit demonstreres begge volumetyper med eksempler.
Demonstration af vedvarende opbevaring af containere
Vi har oprettet en lille webapplikation for at demonstrere vedvarende lagring med Docker-containere. Du kan følge med ved at installere Docker og hente koden fra dette GitHub-repository.
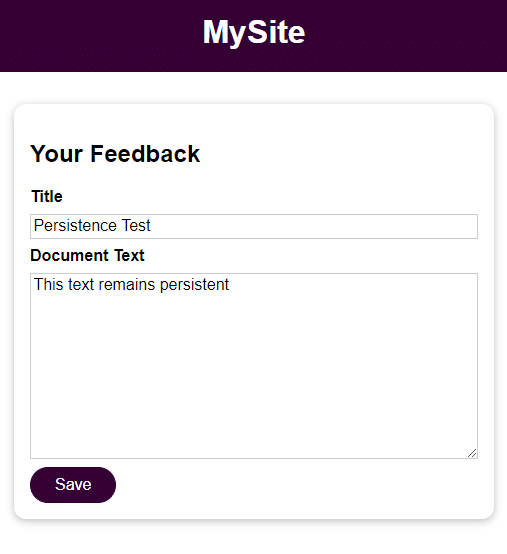
Applikationen er en elementær formular med 2 felter til brugerinput:
- Titel
- Dokumenttekst
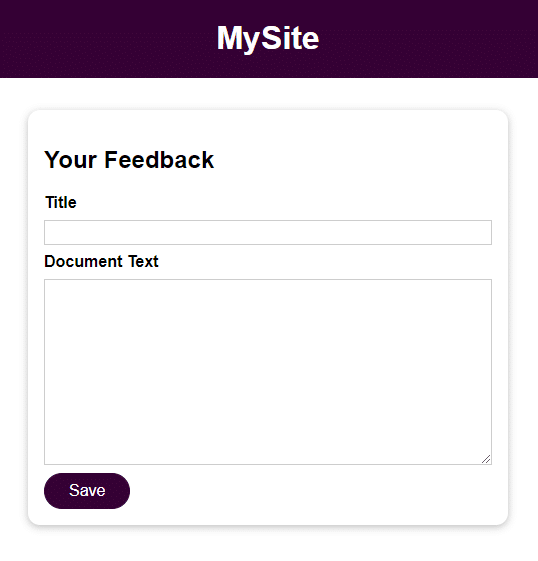
Når du har gemt brugerinputtet, kan du få adgang til det ved at åbne filen i feedback-mappen med det navn, der er angivet i feltet Titel. Indtastningen fra feltet Document Text er filens indhold.
Sådan bruger du Volume Storage
Når du har installeret applikationen på din egen maskine, kan det bruge volumenlagring som vist i Dockerfilen.
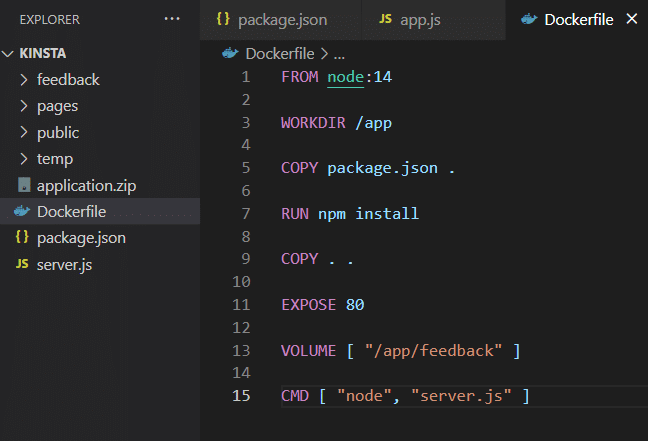
Nu skal du bygge aftrykket og køre containeren. For at gøre det skal du udføre følgende kommandoer.
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app feedback-node:volumes
Når applikationen kører, skal du navigere til localhost:3000 for at sende feedback.
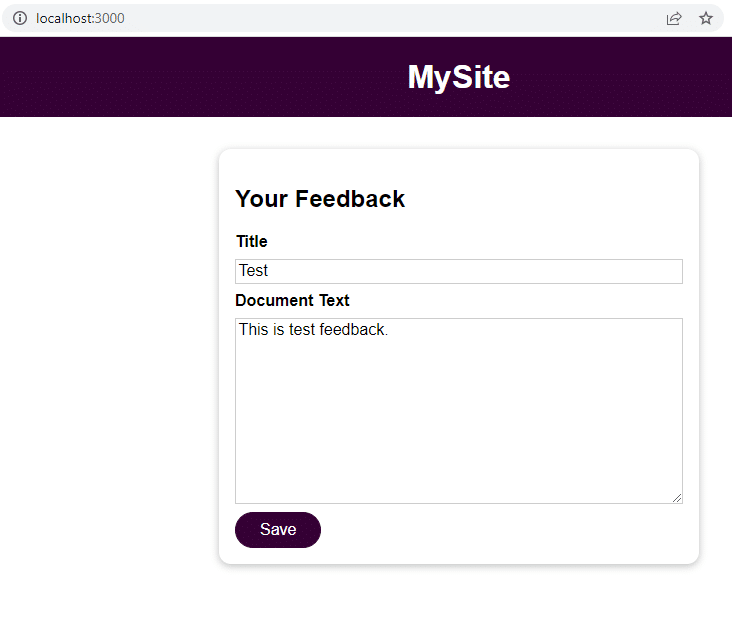
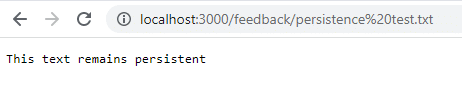
Klik på Gem, og navigér til localhost:3000/feedback/test.txt for at se, om input er gemt med succes eller ej.
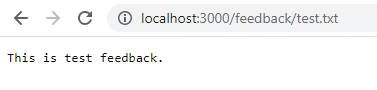
Fjern og genstart beholderen for at se, om input forbliver.
docker stop feedback-app
docker start feedback-appHvis du nu besøger den samme URL, kan du se, at feedbacken stadig er der. Men hvad sker der, hvis du fjerner containeren og genstarter den?
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app feedback-node:volumesHvis du vender tilbage til den pågældende URL, når den er genstartet, eksisterer den ikke længere, fordi dataene gik tabt, da du fjernede containeren. Volumedata forbliver kun ved, når du stopper containeren, ikke når du fjerner den.
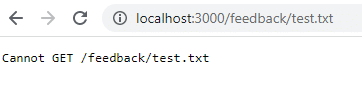
Hvis du vil afhjælpe dette problem og bevare dataene, selv når du fjerner containeren, skal du bruge vedvarende volumenlagring eller navngiven lagring. Først skal du rydde op i containerne og billederne.
docker stop feedback-app
docker rm feedback-app
docker rmi feedback-node:volumesSådan bruger du åersistent volume storage
Før du tester dette, skal du fjerne VOLUME-attributten fra Dockerfilen og genopbygge aftrykket.
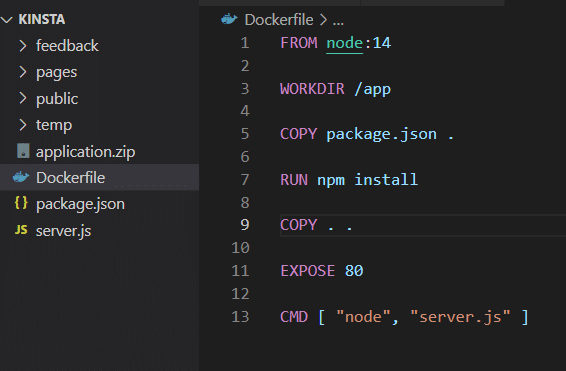
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesSom du kan se, bruger du i den anden kommando -v -flaget til at definere den vedvarende volumen uden for containeren, som består, selv når du fjerner containeren.
Ligesom i det foregående trin skal du prøve at tilføje feedback og få adgang til den, når du stopper, fjerner og genstarter containeren.
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesSom du kan se, er dataene tilgængelige, selv efter at du har stoppet og fjernet containeren, og de forbliver.
Oversigt
Persistent storage er afgørende for containeriserede applikationer, fordi det gør det muligt at persistere data uden for en containers livscyklus. De 2 hovedtyper af persistent storage til containeriserede applikationer er volumener og bind mounts, som hver især har deres fordele og anvendelsesmuligheder.
Volumes er gemt i containerens filsystem, mens bind mounts er direkte tilgængelige på hostsmaskinen.
Persistent storage gør det muligt at dele data mellem containere, hvilket gør det muligt at opbygge komplekse applikationer med flere niveauer. Persistent storage er afgørende for at sikre stabilitet og kontinuitet i containeriserede applikationer og giver en pålidelig og fleksibel måde at opbevare vigtige data på.
Udvikler du en applikation, der kræver vedvarende lagring? Gennemse vores bibliotek med eksempler på hurtig start for at se, hvordan du implementerer din applikation til Kinsta fra Git-host som GitHub, GitLab og Bitbucket. Vores officielle Persistent Storage-dokumentation hjælper dig med at få din applikation og dens data online hurtigt.

"Steve Bonisteel er en teknisk redaktør hos Kinsta, der begyndte sin forfatterkarriere som journalist på en avis, der jagtede ambulancer og brandbiler. Han har dækket internetrelateret teknologi siden slutningen af 1990'erne."