
Tanto o MySQL quanto o MariaDB aproveitam perfeitamente a eficiência da indexação de árvore balanceada (B-Tree) para otimizar as operações de dados. Esse mecanismo de indexação compartilhada garante a recuperação rápida de dados, melhora o desempenho das consultas e minimiza a entrada/saída (E/S) do disco, contribuindo para uma experiência de banco de dados mais ágil e eficiente.
Este artigo examina mais detalhadamente a indexação, orienta você na criação de índices e compartilha dicas sobre como usá-los com mais eficiência nos bancos de dados MySQL e MariaDB.
O que é um índice?
Quando você consulta um banco de dados MySQL para obter informações específicas, a consulta pesquisa em cada linha de uma tabela do banco de dados até localizar a linha correta. Isso pode levar muito tempo, especialmente nos casos em que o banco de dados é extenso.
Os gerenciadores de banco de dados usam a indexação para acelerar os processos de recuperação de dados e otimizar a eficiência da consulta. A indexação cria uma estrutura de dados que minimiza a quantidade de dados que devem ser pesquisados, organizando sistematicamente, o que resulta em uma execução de consulta mais rápida e eficaz.
Digamos que você queira encontrar um cliente cujo primeiro nome seja Ava na seguinte tabela Customer:
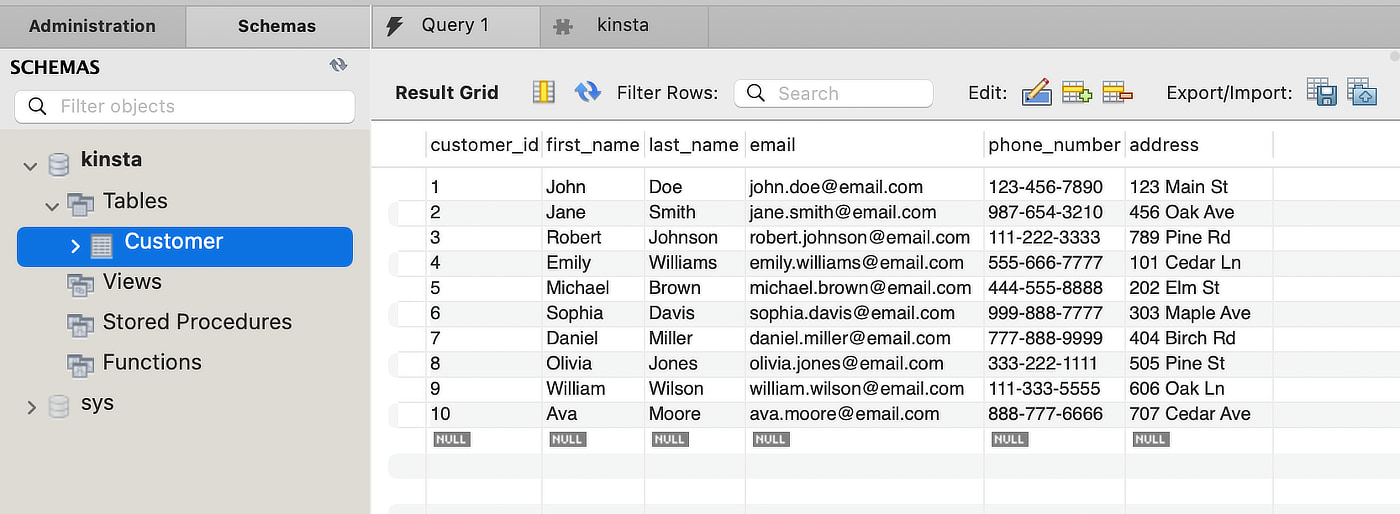
Ao adicionar um índice B-Tree à coluna first_name, você cria uma estrutura que facilita uma pesquisa mais eficiente das informações desejadas. A estrutura se assemelha a uma árvore com o node raiz no topo, ramificando-se para os nodes na parte inferior.
É semelhante a uma árvore bem organizada, em que cada nível orienta a pesquisa com base na ordem de classificação dos dados.
Esta imagem mostra um caminho de pesquisa de índice B-Tree:
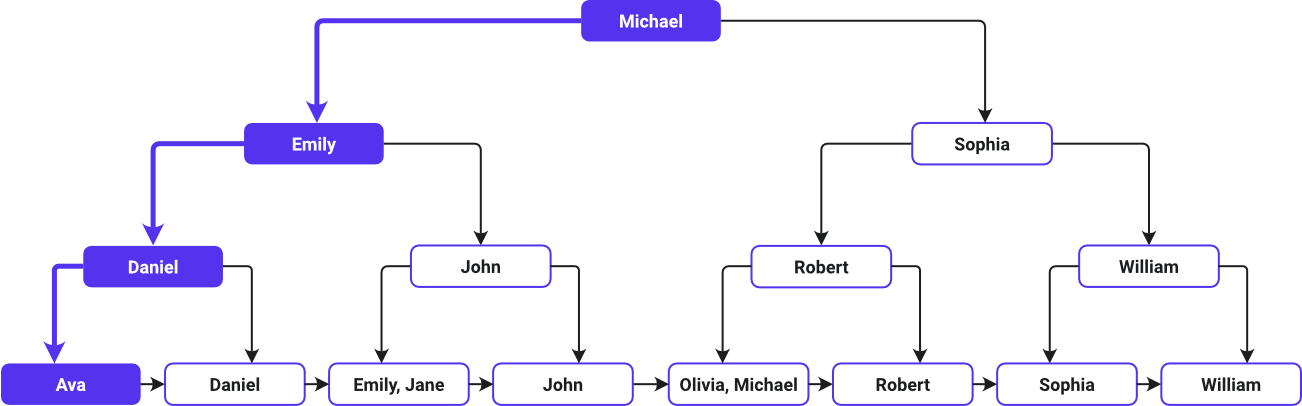
Ava é listado primeiro e William por último em ordem alfabética ascendente – como a B-Tree organizou os nomes. O sistema B-Tree designa o valor do meio da lista como um node raiz. Como Michael está no meio da lista alfabética, ele é o node raiz. Em seguida, a árvore se ramifica, com valores à esquerda e à direita de Michael.
À medida que você avança pelas camadas da árvore, cada node oferece mais chaves (links diretos para as linhas originais de dados) para orientar a pesquisa pelos nomes em ordem alfabética. Em seguida, você encontra os dados do primeiro nome de cada cliente nos nodes das folhas.
A pesquisa começa comparando Ava com o node raiz Michael. Você se move para a esquerda depois de determinar que Ava aparece antes de Michael em ordem alfabética. Você desce até o filho da esquerda (Emily), depois desce novamente para a esquerda até Daniel e desce mais uma vez para a esquerda até Ava antes de chegar ao node folha que contém as informações de Ava.
A B-Tree funciona como um sistema de navegação simplificado, orientando efetivamente a pesquisa para um determinado local sem verificar todos os nomes no conjunto de dados. É como navegar em um diretório cuidadosamente ordenado, seguindo placas de sinalização estrategicamente posicionadas que levam você diretamente ao destino.
Tipos de índices
Há diferentes tipos de índices para várias finalidades. Vamos discutir esses diferentes tipos a seguir.
1. Índices de nível único
Os índices de nível único, ou índices planos, mapeiam as chaves do índice para os dados da tabela. Cada chave no índice corresponde a uma única linha da tabela.
A coluna customer_id é uma chave primária na tabela Customer, servindo como um índice de nível único. A chave identifica cada cliente e vincula suas informações na tabela.
| Índice (customer_id) | Ponteiro de linha |
| 1 | Linha 1 |
| 2 | Linha 2 |
| 3 | Fileira 3 |
| 4 | Linha 4 |
| .. | .. |
A relação entre as chaves customer_id e os detalhes individuais do cliente é direta. Os índices de nível único são excelentes em cenários com tabelas que contêm poucas linhas ou colunas com poucos valores distintos. Colunas como status ou categoria, por exemplo, são boas candidatas.
Use um índice de nível único para consultas simples que localizam uma linha específica com base em uma única coluna. Sua implementação é simples, direta e eficiente para conjuntos de dados menores.
2. Índices de vários níveis
Diferentemente dos índices de nível único para recuperação organizada de dados, os índices multinível usam uma estrutura hierárquica. Eles têm vários níveis de orientação. O índice de nível superior direciona a pesquisa para um índice de nível inferior, e assim por diante, até chegar ao nível de folha, que armazena os dados. Essa estrutura diminui o número de comparações necessárias durante as pesquisas.
Considere um índice de vários níveis com as colunas address e customer_id.
| Índice (endereço) | Subíndice (customer_id) | Ponteiro de linha |
| 123 Main St | 1 | Linha 1 |
| 456 Oak Ave | 2 | Linha 2 |
| 789 Pine Rd | 3 | Linha 3 |
| .. | .. | .. |
O primeiro nível organiza os endereços. O segundo nível, dentro de cada endereço, organiza ainda mais as IDs de clientes.
Esta organização é excelente para conjuntos de dados maiores que exigem uma hierarquia de busca organizada. Também é útil para colunas como last_name, que possuem uma cardinalidade moderada (a unicidade dos valores de dados em uma coluna específica).
3. Índices clusterizados
Os índices clusterizados no MySQL determinam a ordem lógica do índice e a ordem dos dados na tabela. Se você aplicar um índice clusterizado à coluna customer_id na tabela Customer, as linhas serão classificadas com base nos valores da coluna. Isso significa que a ordem dos dados na tabela reflete a ordem do índice clusterizado, melhorando o desempenho da recuperação de dados para padrões específicos ao reduzir a E/S do disco.
Esta estratégia mostra-se eficaz quando o padrão de recuperação de dados coincide com a sequência dos IDs de clientes. Também se adequa bem a colunas com alta cardinalidade, como o customer_id.
Embora os índices clusterizados ofereçam vantagens em relação ao desempenho da recuperação de dados para padrões específicos, é importante observar uma possível desvantagem. A classificação de linhas com base no índice clusterizado pode afetar o desempenho das operações de inserção e atualização, especialmente se o padrão de inserção ou atualização não estiver alinhado com a ordem do índice clusterizado. Isso ocorre porque os novos dados devem ser inseridos ou atualizados de forma a manter a ordem classificada, resultando em uma sobrecarga adicional.
4. Índices não clusterizados
Os índices não clusterizados oferecem mais flexibilidade às estruturas de banco de dados. Suponha que você use um índice não clusterizado em uma coluna de e-mail. Ao contrário de um índice com cluster, ele não altera a ordem das entradas na tabela.
Em vez disso, ele cria uma nova estrutura que mapeia chaves – nesse caso, endereços de e-mail – para linhas de dados. Quando você consulta o banco de dados em busca de um endereço de e-mail específico, o índice não clusterizado orienta a pesquisa diretamente para a linha relevante, sem depender da ordem da tabela.
A flexibilidade dos índices não clusterizados é sua principal vantagem. Eles permitem pesquisas eficientes de várias colunas sem impor uma ordem aos dados armazenados. Esse sistema torna os índices não clusterizados versáteis, pois eles podem acomodar consultas que não seguem a ordem primária da tabela.
Os índices não clusterizados são úteis quando o padrão de recuperação de dados difere da ordem alfabética e para colunas com cardinalidade moderada a alta, como é o caso do email.
Como criar índices
Agora que já analisamos o que são índices em um nível mais alto, vamos analisar alguns exemplos práticos de criação de índices usando o MySQL Workbench.
Pré-requisitos
Para acompanhar, você precisa de:
- Um banco de dados MySQL (compatível com o MariaDB)
- Alguma experiência em SQL e MySQL
- MySQL Workbench
Como criar a tabela de clientes
- Inicie o MySQL Workbench e conecte-se ao seu servidor MySQL.
- Execute a seguinte consulta SQL para criar uma tabela Customer:
CREATE TABLE Customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(15), address VARCHAR(255) ); - Insira os seguintes dados:
-- Adding Data to the Customer Table INSERT INTO Customer (customer_id, first_name, last_name, email, phone_number, address) VALUES (1, 'John', 'Doe', '[email protected]', '123-456-7890', '123 Main St'), (2, 'Jane', 'Smith', '[email protected]', '987-654-3210', '456 Oak Ave'), (3, 'Robert', 'Johnson', '[email protected]', '111-222-3333', '789 Pine Rd'), (4, 'Emily', 'Williams', '[email protected]', '555-666-7777', '101 Cedar Ln'), (5, 'Michael', 'Brown', '[email protected]', '444-555-8888', '202 Elm St'), (6, 'Sophia', 'Davis', '[email protected]', '999-888-7777', '303 Maple Ave'), (7, 'Daniel', 'Miller', '[email protected]', '777-888-9999', '404 Birch Rd'), (8, 'Olivia', 'Jones', '[email protected]', '333-222-1111', '505 Pine St'), (9, 'William', 'Wilson', '[email protected]', '111-333-5555', '606 Oak Ln'), (10, 'Ava', 'Moore', '[email protected]', '888-777-6666', '707 Cedar Ave');
Índices de nível único
Uma tática para otimizar o desempenho das consultas no MySQL e no MariaDB é usar índices de nível único.
Para adicionar um índice de nível único à tabela Customer, use a declaração CREATE INDEX:
-- Creating a Single-Level Index on "customer_id"
CREATE INDEX idx_customer_id ON Customer(customer_id);Após a execução bem-sucedida, o banco de dados confirma a criação do índice retornando o seguinte código:
0 row(s) affected Records: 0 Duplicates: 0 Warnings: 0Agora, as consultas que filtram dados com base nos valores da coluna customer_id são tratadas de forma otimizada pelo banco de dados, aumentando consideravelmente a eficiência.
Índices de vários níveis
O MySQL e o MariaDB vão além da indexação de colunas individuais, fornecendo índices de vários níveis. Esses índices abrangem mais de um nível ou coluna, combinando valores de várias colunas em um índice para tornar a execução de consultas mais eficiente.
Use o código a seguir para criar um índice multinível no MySQL ou MariaDB, concentrando-se nas colunas address e customer_id:
-- Creating a Multi-Level Index based on "address" and "customer_id"
CREATE INDEX idx_address_customer_id ON Customer(address, customer_id);O uso de índices multinível estrategicamente resulta em melhorias significativas no desempenho da consulta, especialmente ao lidar com conjuntos de colunas.
Índices clusterizados
Além da indexação individual e multinível, o MySQL e o MariaDB usam índices clusterizados, uma ferramenta dinâmica para melhorar o desempenho do banco de dados, alinhando as linhas de dados com a ordem dos ponteiros do índice.
Por exemplo, ao aplicar um índice clusterizado à coluna customer_id na tabela Customer, você alinha a ordem dos IDs dos clientes.
-- Creating a Clustered Index on "customer_id"
CREATE CLUSTERED INDEX idx_customer_id_clustered ON Customer(customer_id);Devido à ordem otimizada dos dados, essa estratégia melhora significativamente a recuperação de dados de padrões específicos e diminui a E/S do disco.
Índices não clusterizados
Os índices não clusterizados podem otimizar as consultas, dependendo das colunas, sem forçar os dados a uma determinada ordem. No MySQL e no MariaDB, você não precisa especificar que um índice é não clusterizado.
A arquitetura da tabela implica isso. Somente a chave primária ou a primeira chave exclusiva não nula pode ser um índice clusterizado. Os outros índices da tabela são todos implicitamente não clusterizados. Como exemplo de um índice não clusterizado, considere o seguinte:
-- Creating a Non-clustered Index on "email"
CREATE INDEX idx_email_non_clustered ON Customer(email);Os índices não clusterizados permitem pesquisas eficientes de várias colunas, resultando em um banco de dados mais versátil e responsivo.
Práticas recomendadas e pontos-chave
Escolha índices de nível único ao trabalhar com colunas com um pequeno intervalo de valores diferentes, como status ou categoria. Use índices de vários níveis e não clusterizados com colunas com uma faixa mais ampla de valores, como e-mail.
Os padrões de recuperação de dados que você prefere são fundamentais ao escolher entre índices com cluster e sem cluster. Para índices em cluster, escolha colunas com alta cardinalidade, como ID do cliente. Para índices não clusterizados, escolha colunas com cardinalidade moderada a alta, como e-mail.
Como otimizar índices
Para aumentar o desempenho de seus índices, você pode usar algumas estratégias práticas, como cobrir índices e remover índices redundantes.
1. Índices de cobertura
Os índices de cobertura melhoram o desempenho da consulta, criando índices que abrangem todos os dados necessários. O termo índice de cobertura significa que um índice inclui todas as colunas necessárias para atender a uma consulta, evitando a necessidade de acessar as linhas de dados.
-- Create a Covering Index on "first_name" and "last_name"
CREATE INDEX idx_covering_name ON Customer(first_name, last_name);2. Remova índices redundantes
Remova os índices redundantes, mas tenha cuidado, pois a remoção de índices pode afetar o desempenho de determinadas consultas.
-- Remove an Unnecessary Index
DROP INDEX idx_unnecessary_index ON Customer;Revise e remova regularmente os índices redundantes para garantir uma estrutura de banco de dados simplificada e eficiente.
3. Evite a indexação excessiva
Evite armadilhas comuns, como a indexação excessiva. Embora os índices melhorem o desempenho da consulta, a criação de um número excessivo pode diminuir os retornos. É fundamental encontrar um equilíbrio e evitar o excesso de indexação, o que pode resultar em maiores requisitos de armazenamento e possível degradação do desempenho.
4. Analise os padrões de consulta
Também é uma armadilha comum ignorar a análise dos padrões de consulta antes de criar índices. Compreender as consultas executadas com frequência e concentrar-se nas colunas de indexação usadas nas cláusulas WHERE ou nas condições JOIN é essencial para o desempenho ideal.
Resumo
Este artigo explorou a indexação no MySQL e no MariaDB, destacando a eficácia do mecanismo B-Tree. Foram abordados os princípios básicos da indexação e os diversos tipos de índices (de nível único, multinível, clusterizado e não clusterizado).
Quer você esteja otimizando cargas de trabalho de leitura pesada ou melhorando o desempenho de gravação, o serviço de hospedagem de banco de dados da Kinsta capacita os usuários do MySQL e do MariaDB com uma solução confiável e de alto desempenho para suas necessidades de indexação. Experimente a hospedagem de banco de dados da Kinsta para aproveitar as vantagens do MySQL e do MariaDB e seus recursos de indexação.


