
Alla webbplatsägare kan intyga att dataförlust och driftstopp, även i minimala doser, kan vara katastrofala. De kan drabba den oförberedde när som helst och leda till minskad produktivitet, tillgänglighet och minskat produktförtroende.
För att skydda integriteten hos din webbplats så är det viktigt att bygga upp ditt skydd mot driftstopp eller dataförlust.
Det är där som datareplikering kommer in i bilden.
Datareplikering är en automatiserad säkerhetskopierings-process där dina data upprepade gånger kopieras från huvuddatabasen till en annan, avlägsen plats för förvaring. Det är en integrerad teknik för alla webbplatser eller appar som kör en databasserver. Du kan även utnyttja den replikerade databasen för att bearbeta skrivskyddad SQL, vilket gör att fler processer kan köras i systemet.
Att ställa in replikering mellan två databaser ger en feltolerans mot oväntade missöden. Det anses vara den bästa strategin för att uppnå en hög tillgänglighet vid katastrofer.
I den här artikeln så kommer vi att djupdyka i de olika strategier som kan implementeras av backend-utvecklare för sömlös PostgreSQL-replikering.
Vad är PostgreSQL-replikering?
PostgreSQL-replikering definieras som processen för kopiering av data från en PostgreSQL-databasserver till en annan server. Källdatabasservern kallas även för den ”primära” servern. Databasservern som tar emot de kopierade uppgifterna kallas för ”replika”-servern.
PostgreSQL-databasen följer en enkel replikerings-modell där alla skrivningar går till en primär nod. Den primära noden kan sedan tillämpa dessa ändringar och sända dem till sekundära noder.
Vad är automatisk växling?
Failover är en metod för att återställa data om den primära servern av någon anledning ger upp. Så länge som du har konfigurerat PostreSQL för att hantera din fysiska strömmande replikering så kommer du – och dina användare – att vara skyddade från driftsstopp på grund av en primärserver som krånglar.
Observera att failover-processen kan ta lite tid att konfigurera och initiera. Det finns inga inbyggda verktyg för att övervaka och avgränsa serverfel i PostgreSQL, så du måste vara kreativ.
Du behöver som tur är inte vara beroende av PostgreSQL för failover. Det finns dedikerade verktyg som möjliggör automatisk failover och automatisk växling till standby, vilket minskar nertiden för databasen.
Genom att ställa in failover-replikering så garanterar du nästan en hög tillgänglighet genom att se till att reserver finns tillgängliga om den primära servern någonsin kollapsar.
Fördelar med att använda PostgreSQL-replikering
Här är några viktiga fördelar med att använda PostgreSQL-replikering:
- Datamigrering: Du kan utnyttja PostgreSQL-replikering för datamigrering antingen genom byte av databasserverns hårdvara eller genom systemdistribuering.
- Feltolerans: Om den primära servern går sönder så kan standby-servern fungera som en server eftersom uppgifterna för både primära servrar och standby-servrar är desamma.
- Prestanda för transaktionsbehandling på nätet (OLTP): Du kan förbättra transaktionsbehandlingstiden och frågetiden för ett OLTP-system genom att ta bort rapporterande frågelast. Transaktionsbehandlingstiden är den tid som det tar för en viss sökfråga att utföras innan en transaktion är avslutad.
- Systemtestning parallellt: När du uppgraderar ett nytt system så måste du försäkra dig om att systemet klarar sig bra med befintliga data. Det finns därför ett behov att testa med en produktionsdatabaskopia innan det tas i bruk.
Hur PostgreSQL-replikering fungerar
Folk tror generellt att det bara finns ett sätt att konfigurera säkerhetskopior och replikering, när man håller på med en primär och sekundär arkitektur. PostgreSQL-implementeringar kan dock följa någon av dessa tre metoder:
- Strömnings-replikering: Replikerar data från den primära noden till den sekundära och kopierar sedan data till Amazon S3 eller Azure Blob för säkerhetskopiering.
- Replikering på volymnivå: Replikerar data på arkiv-lagret, med början från den primära noden till den sekundära noden, och kopierar sedan data till Amazon S3 eller Azure Blob för säkerhetskopiering.
- Inkrementella säkerhetskopior: Replikerar data från den primära noden samtidigt som en ny sekundär nod konstrueras från Amazon S3- eller Azure Blob-lagring. Detta möjliggör strömning direkt från den primära noden.
Metod 1: Strömning
PostgreSQL strömnings-replikering, även känt som WAL-replikering, kan konfigureras sömlöst efter installation av PostgreSQL på alla servrar. Detta tillvägagångssätt för replikering bygger på att WAL-filerna flyttas från den primära databasen till måldatabasen.
Du kan implementera PostgreSQL strömnings-replikering genom att använda en primär-sekundär konfiguration. Den primära servern är den huvudinstans som hanterar den primära databasen och all dess verksamhet. Den sekundära servern fungerar som den kompletterande instansen och utför alla ändringar som görs i den primära databasen på sig själv. Detta genererar en identisk kopia i processen. Den primära servern är en läs- och skrivserver medan den sekundära servern endast är skrivskyddad.
För den här metoden så måste du både konfigurera den primära noden och reservnoden. I följande avsnitt så beskrivs de steg som krävs för att konfigurera dem på ett enkelt sätt.
Konfigurera den primära noden
Du kan konfigurera den primära noden för strömmande replikering genom att utföra följande steg:
Steg 1: Initialisera databasen
För att initialisera databasen så kan du använda kommandot initdb. Därefter så kan du skapa en ny användare med replikerings-rättigheter med hjälp av följande kommando:
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';Användaren måste ange ett lösenord och ett användarnamn för den givna sökfrågan. Nyckelordet replikering används för att ge användaren de nödvändiga privilegierna. En exempelfråga exempelvis kunna se ut så här:
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';Steg 2: Konfigurera egenskaper för strömning
Därefter så kan du konfigurera strömnings-egenskaperna med PostgreSQL-konfigurationsfilen (postgresql.conf) som kan ändras på följande sätt:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onHär är lite bakgrundsinformation om de parametrar som användes i föregående utdrag:
wal_log_hints: Den här parametern krävs förpg_rewind-funktionen som är praktisk när reservservern inte är synkroniserad med den primära servern.wal_level: Du kan använda den här parametern för att aktivera PostgreSQL strömings-replikering, med möjliga värden somminimal,replicaellerlogical.max_wal_size: Detta kan användas för att ange storleken på WAL-filer som kan behållas i loggfiler.hot_standby: Du kan utnyttja den här parametern för en anslutning till den sekundära datorn när den är inställd på ON.max_wal_senders: Du kan användamax_wal_sendersför att ange det maximala antalet samtidiga anslutningar som kan upprättas med reserv-servrarna.
Steg 3: Skapa en ny post
När du har ändrat parametrarna i filen postgresql.conf så sker nåt viktigt. Då kan nämligen en ny replikeringspost i filen pg_hba.conf göra det möjligt för servrarna att upprätta en anslutning med varandra för replikering.
Du hittar vanligtvis den här filen i PostgreSQL’s datakatalog. Du kan använda följande kodutdrag för samma sak:
host replication rep_user IPaddress md5När kodstycket exekveras så tillåter den primära servern en användare som heter rep_user att ansluta och agera som reserv-server genom att använda den angivna IP-adressen för replikering. Exempelvis:
host replication rep_user 192.168.0.22/32 md5Konfigurera standby-nod
Följ de här stegen för att konfigurera standby-noden för strömnings-replikering:
Steg 1: Säkerhetskopiera den primära noden
För att konfigurera standby-noden så använder du verktyget pg_basebackup för att skapa en säkerhetskopia av den primära noden. Detta kommer att fungera som utgångspunkt för standby-noden. Du kan använda det här verktyget med följande syntax:
pg_basebackp -D -h -X stream -c fast -U rep_user -WDe parametrar som används i syntaxen ovan är följande:
-h: Du kan använda detta för att ange den primära hosten.-D: Den här parametern anger den katalog som du för närvarande arbetar i.-C: Du kan använda den här parametern för att ange kontrollpunkter.-X: Den här parametern kan användas för att inkludera de nödvändiga transaktionsloggfilerna.-W: Du kan använda den här parametern för att uppmana användaren att ange ett lösenord innan anslutning till databasen.
Steg 2: Konfigurera konfigurationsfilen för replikering
Därefter så måste du kontrollera om replikeringskonfigurationsfilen finns. Om den inte existerar så kan du generera replikeringskonfigurationsfilen som recovery.conf.
Du bör skapa den här filen i datakatalogen i PostgreSQL-installationen. Den kan genereras automatiskt genom alternativet -R i verktyget pg_basebackup.
Filen recovery.conf bör innehålla följande kommandon:
standby_mode = 'on'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"'
recovery_target_timeline = 'latest'De parametrar som används i de ovannämnda kommandona är följande:
primary_conninfo: Du kan använda detta för att skapa en anslutning mellan den primära och sekundära servern genom att använda en anslutningssträng.standby_mode: Den här parametern kan få den primära servern att starta som standby-server när den slås på.recovery_target_timeline: Du kan använda den här parametern för att ställa in återhämtningstiden.
Om du vill upprätta en anslutning så måste du ange användarnamn, IP-adress och lösenord som hosten för parametern primary_conninfo. Exempelvis:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Steg 3: Starta om den sekundära servern
Slutligen så kan du starta om den sekundära servern för att slutföra konfigurationen.
Strömnings-replikering innebär dock flera utmaningar, exempelvis:
- Olika PostgreSQL-klienter (skrivna i olika programmeringsspråk) konverserar med en enda slutpunkt. När den primära noden misslyckas så kommer dessa klienter att fortsätta att försöka upprepa samma DNS- eller IP-namn. Detta gör att failover blir synligt för applikationen.
- PostgreSQL-replikering har ingen inbyggd failover och övervakning. När den primära noden misslyckas så måste du befordra en sekundär nod till att bli den nya primära noden. Denna befordran måste utföras på ett sådant sätt att klienterna skriver till endast en primär nod och att de inte observerar data-inkonsekvenser.
- PostgreSQL replikerar hela sitt tillstånd. När du behöver utveckla en ny sekundär nod så måste den sekundära noden återskapa hela historiken över tillståndsändringar från den primära noden. Detta är resurskrävande och gör det kostsamt att eliminera huvud-noder och skapa nya.
Metod 2: Replikerad blockenhet
Metoden med replikerad blockenhet är beroende av diskspegling (även känt som volymreplikering). I detta tillvägagångssätt så skrivs ändringar till en beständig volym som speglas synkront till en annan volym.
Fördelen med den här metoden är dess kompatibilitet och datadurabilitet i molnmiljöer med alla relationsdatabaser. Detta inkluderar exempelvis PostgreSQL, MySQL och SQL Server, för att nämna några.
Diskspeglingsmetoden för PostgreSQL-replikering kräver dock att du både replikerar WAL-logg- och tabelldata. Eftersom varje skrivning till databasen nu måste gå över nätverket synkront så har du inte råd att förlora en enda byte. Som ett resultat så kan detta nämligen leda till att din databas hamnar i ett korrupt tillstånd.
Den här metoden används normalt med Azure PostgreSQL och Amazon RDS.
Metod 3: WAL
WAL består av segmentfiler (16 MB som standard). Varje segment har en eller flera poster. En loggsekvenspost (LSN) är en pekare mot en post i WAL, som ger dig information om positionen/platsen där posten har sparats i loggfilen.
En standby-server utnyttjar WAL-segmenten – även kallade XLOGS i PostgreSQL-terminologi – för att kontinuerligt replikera ändringar från den primära servern. Du kan använda write-ahead logging för att ge hållbarhet och atomicitet i ett DBMS. Detta görs genom serialisering av delar av byte-array-data (var och en med ett unikt LSN) till stabil lagring innan de tillämpas i en databas.
Att tillämpa en mutation på en databas kan leda till olika filsystemoperationer. En relevant fråga som dyker upp är följande: Hur kan en databas garantera atomicitet i händelse av ett serverfel på grund av strömavbrott medan den är mitt uppe i en filsystemuppdatering. När en databas startar upp så kör den en start- eller återspelningsprocess som kan läsa de tillgängliga WAL-segmenten och jämföra dem med det LSN som finns lagrat på varje datasida. Varje datasida är markerad med LSN för den senaste WAL-posten som påverkar sidan.
Replikering baserad på loggtransport (blocknivå)
Strömnings-replikering förfinar loggförsändelseprocessen. I motsats till att vänta på WAL-omkopplingen så skickas posterna när de skapas, vilket minskar replikeringsfördröjningen.
Strömnings-replikering är även bättre än loggförsändelse eftersom reservservern är kopplad till den primära servern via nätverket. Den utnyttjar ett replikeringsprotokoll. Som ett resultat så kan den primära servern sedan skicka WAL-poster direkt över denna anslutning. Den är inte beroende av skript som tillhandahålls av slutanvändaren.
Replikering baserad på loggtransport (filnivå)
Loggförsändelse definieras som kopiering av loggfiler till en annan PostgreSQL-server för att generera en annan reservserver. Detta görs genom att spela om WAL-filer. Denna server är konfigurerad för att arbeta i återställningsläge och dess enda syfte är att tillämpa nya WAL-filer när de dyker upp.
Som ett resultat så blir den sekundära servern sedan en varm säkerhetskopia av den primära PostgreSQL-servern. Den kan även konfigureras för att vara en läskopia, där den kan erbjuda skrivskyddade förfrågningar, även kallat hot standby.
Kontinuerlig arkivering av WAL-filer
WAL-arkivering är en duplicering av WAL-filer när de skapas till en annan plats än underkatalogen pg_wal för att arkiveras. PostgreSQL anropar ett skript som användaren har angett för arkivering varje gång som en WAL-fil skapas.
Skriptet kan utnyttja kommandot scp för att duplicera filen till en eller flera platser, t.ex. en NFS-montering. Som ett resultat av arkiveringen så kan WAL-segmentfilerna användas för att återställa databasen vid vilken tidpunkt som helst.
Andra loggbaserade konfigurationer inkluderar:
- Synkron replikering: Innan varje synkron replikeringstransaktion bekräftas, väntar den primära servern tills standbys bekräftar att de har fått data. Fördelen med den här konfigurationen är exempelvis att det inte uppstår några konflikter på grund av parallella skrivprocesser.
- Synkron replikering med flera huvudansvariga: Här kan varje server ta emot skrivförfrågningar, och ändrade data överförs från den ursprungliga servern till alla andra servrar innan varje transaktion bekräftas. Den utnyttjar 2PC-protokollet och följer regeln om allt eller inget.
Detaljer om WAL-strömningsprotokollet
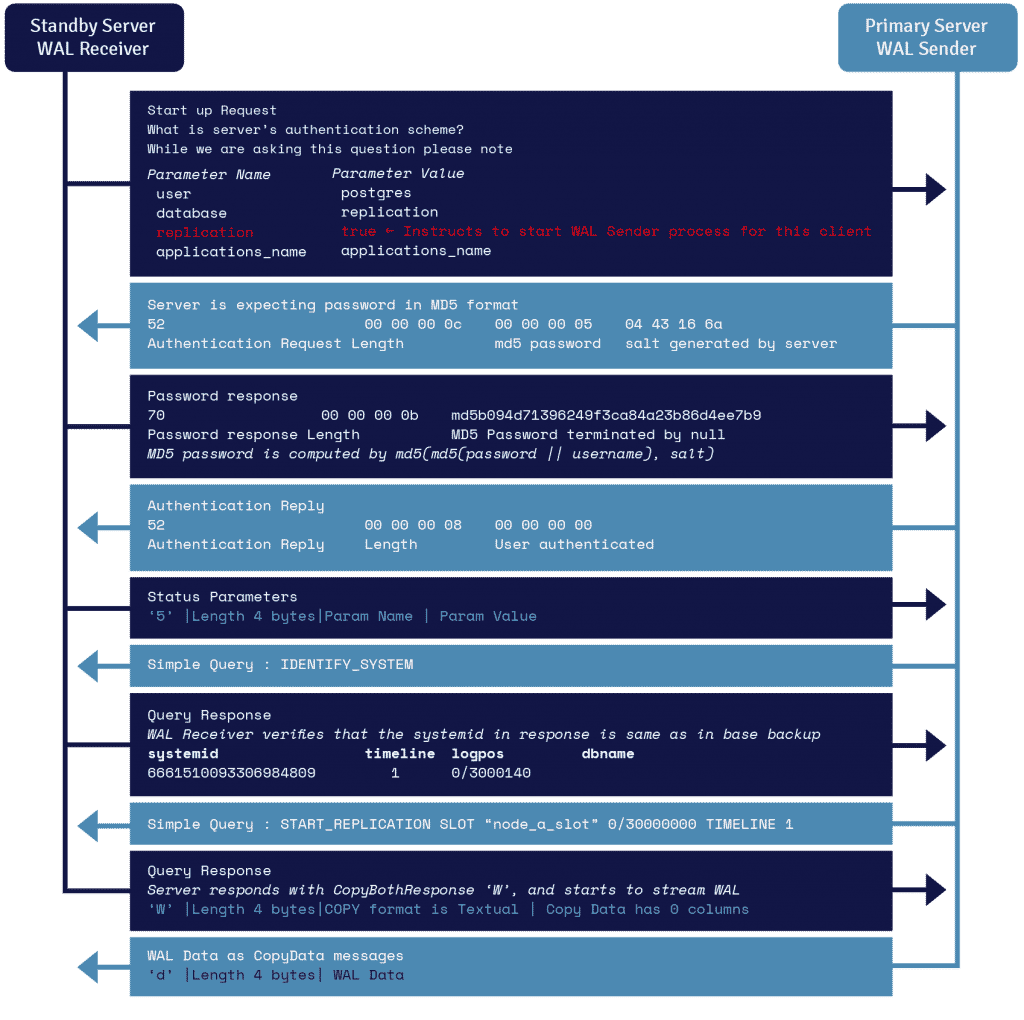
En process som kallas WAL-mottagare och som körs på reservservern utnyttjar de anslutningsuppgifter som anges i parametern primary_conninfo i recovery.conf. Den ansluter till den primära servern genom att utnyttja en TCP/IP-anslutning.
För att starta strömnings-replikering så kan frontend skicka replikeringsparametern i startmeddelandet. Ett boolskt värde på true, yes, 1 eller ON låter backend veta att den måste gå in i fysiskt replikeringsläge för Wal-sändaren.
WAL-sändaren är en annan process som körs på den primära servern och som ansvarar för att skicka WAL-posterna till reservservern när de genereras. Som ett resultat så sparar WAL-mottagaren WAL-posterna i WAL som om de skapades av klientaktivitet av lokalt anslutna klienter.
När WAL-posterna väl når WAL-segmentfilerna så fortsätter standby-servern ständigt att spela upp WAL-posterna så att primär- och standby-servern är uppdaterade.
Element av PostgreSQL-replikering
I det här avsnittet så får du en djupare förståelse för de vanligaste modellerna (replikering med en och flera huvudmän), typerna (fysisk och logisk replikering) och sätten (synkron och asynkron) för PostgreSQL-replikering.
Modeller för PostgreSQL-databasreplikering
Skalbarhet innebär att man lägger till mer resurser/hårdvara till befintliga noder för att öka databasens förmåga att lagra och bearbeta mer data. Detta kan uppnås horisontellt och vertikalt. PostgreSQL-replikering är ett exempel på horisontell skalbarhet som är mycket svårare att genomföra än vertikal skalbarhet. Vi kan uppnå horisontell skalbarhet främst genom replikering med en enda huvudman (SMR) och replikering med flera huvudmän (MMR).
Replikering med en enda huvudman gör det möjligt att ändra data i en enda nod, och dessa ändringar replikeras till en eller flera noder. De replikerade tabellerna i replikeringsdatabasen får inte ta emot några ändringar, förutom de som kommer från den primära servern. Även om de gör detta så replikeras ändringarna inte tillbaka till den primära servern.
För det mesta så räcker SMR för applikationen. Det är nämligen mindre komplicerat att konfigurera och hantera och det finns ingen risk för konflikter. Replikering med en enda huvudserver är även enkelriktad, eftersom replikeringsdata huvudsakligen flödar i en riktning, från den primära till replikdatabasen.
I vissa fall räcker det inte bara med SMR. Du kan behöva implementera MMR. MMR gör det möjligt för fler än en nod att agera som primär nod. Som ett resultat så replikeras ändringar av tabellrader i mer än en utsedd primärdatabas till motsvarande tabeller i alla andra primära databaser. I den här modellen så används ofta konfliktlösningsmetoder för att undvika problem som dubbla primärnycklar.
Det finns några fördelar med att använda MMR:
- Om en host-dator misslyckas så kan andra host-datorer fortfarande tillhandahålla uppdaterings- och inmatningstjänster.
- De primära noderna är utspridda på flera olika platser, så risken för att alla primära noder ska misslyckas är mycket liten.
- Du får möjlighet att använda ett WAN (Wide Area Network) av primära databaser som kan vara geografiskt nära grupper av kunder. Trots detta så kan du ändå upprätthålla datakonsistens i hela nätverket.
Nackdelen med att införa MMR är dock komplexiteten och svårigheten att lösa konflikter.
Flera grenar och program tillhandahåller MMR-lösningar eftersom PostgreSQL inte har något inbyggt stöd för detta. Dessa lösningar kan vara med öppen källkod, kostnadsfria eller betalda. Ett sådant tillägg är bidirektionell replikering (BDR) som är asynkron och bygger på PostgreSQL’s logiska avkodningsfunktion.
Eftersom BDR-applikationen återger transaktioner på andra noder så kan återgivningsoperationen misslyckas om det finns en konflikt mellan den transaktion som tillämpas och den transaktion som har bekräftats på den mottagande noden.
Typer av PostgreSQL-replikering
Det finns två typer av PostgreSQL-replikering: logisk och fysisk replikering.
En enkel logisk operation – initdb – skulle exempelvis utföra den fysiska operationen att skapa en baskatalog för ett kluster. På samma sätt så skulle en enkel logisk operation CREATE DATABASE utföra den fysiska operationen att skapa en underkatalog i baskatalogen.
Fysisk replikering handlar vanligtvis om filer och kataloger. Den vet inte vad dessa filer och kataloger representerar. Som ett resultat av dessa metoder så upprätthålls en fullständig kopia av alla data i ett enskilt kluster. Det sker vanligtvis på en annan maskin, och görs på filsystemnivå eller disknivå och använder exakta blockadresser.
Logisk replikering är ett sätt att reproducera dataenheter och deras ändringar, baserat på deras replikeringsidentitet (vanligtvis en primärnyckel). Till skillnad från fysisk replikering så handlar den om databaser, tabeller och DML-operationer och utförs på databasklusternivå. Den använder en publicerings- och prenumerationsmodell där en eller flera prenumeranter prenumererar på en eller flera publikationer av en publiceringsnod.
Replikeringsprocessen börjar med att ta en ögonblicksbild av data i publiceringsdatabasen och sedan kopiera den till prenumeranten. Prenumeranterna hämtar data från de publikationer som de prenumererar på och kan publicera data på nytt senare. De kan exempelvis möjliggöra kaskad-replikering eller mer komplexa konfigurationer. Prenumeranten tillämpar data i samma ordning som utgivaren så att transaktionskonsistens garanteras för publikationer inom en enda prenumeration, även kallat transaktions-replikering.
De typiska användningsområdena för logisk replikering är följande:
- Skicka inkrementella ändringar i en enskild databas (eller en delmängd av en databas) till prenumeranter när de inträffar.
- Delning av en delmängd av databasen mellan flera databaser.
- Utlösning av enskilda ändringar när de anländer till prenumeranten.
- Konsolidering av flera databaser till en enda.
- Tillgång till replikerade data för olika användargrupper.
Prenumerant-databasen beter sig på samma sätt som alla andra PostgreSQL-instanser. Den kan användas som utgivare för andra databaser genom att definiera dess publikationer.
När prenumeranten behandlas som skrivskyddad av applikationen så blir det inga konflikter från en enda prenumeration. Om det däremot finns andra skrivningar som antingen görs av en applikation eller av andra prenumeranter till samma uppsättning tabeller kan så konflikter uppstå.
PostgreSQL stöder båda mekanismerna samtidigt. Logisk replikering tillåter finkornig kontroll över både datareplikering och säkerhet.
Replikeringsmetoder
Det finns huvudsakligen två lägen för PostgreSQL-replikering: synkron och asynkron. Synkron replikering tillåter att data skrivs till både den primära och sekundära servern samtidigt. Asynkron replikering säkerställer att data först skrivs till hosten och sedan kopieras till den sekundära servern.
Vid replikering i synkront läge så anses transaktioner i den primära databasen vara avslutade först när ändringarna har replikerats till alla replikor. Replikerings-servrarna måste vara tillgängliga hela tiden för att transaktionerna ska kunna slutföras på den primära. Det synkrona replikerings-läget används i avancerade transaktionsmiljöer med krav på omedelbar växling vid fel.
I asynkront läge så är transaktioner på den primära servern slutförda när ändringarna har gjorts på endast den primära servern. Dessa ändringar replikeras senare i replikorna. Replikerings-servrarna kan förbli osynkroniserade under en viss tid, vilket kallas replikerings-fördröjning. Vid en krasch så kan det uppstå dataförlust. Det överskott som asynkron replikering ger är dock väldigt litet, så det är acceptabelt i de flesta fall (det överbelastar inte hosten). Failover från den primära databasen till den sekundära databasen tar längre tid än synkron replikering.
Så här ställer du in PostgreSQL-replikering
I det här avsnittet så kommer vi att demonstrera hur man ställer in PostgreSQL-replikeringsprocessen på ett Linux-operativsystem. I det här fallet så använder vi Ubuntu 18.04 LTS och PostgreSQL 10.
Nu sätter vi igång!
Installation
Du börjar med att installera PostgreSQL på Linux med dessa steg:
- Först så måste du importera PostgreSQL’s signeringsnyckel genom att skriva nedanstående kommando i terminalen:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Lägg sedan till PostgreSQL-arkivet genom att skriva nedanstående kommando i terminalen:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Uppdatera Arkiv Index genom att skriva följande kommando i terminalen:
sudo apt-get update - Installera PostgreSQL-paketet med kommandot apt:
sudo apt-get install -y postgresql-10 - Slutligen så anger du lösenordet för PostgreSQL-användaren med hjälp av följande kommando:
sudo passwd postgres
Du måste installera PostgreSQL på både den primära och den sekundära servern innan du startar PostgreSQL-replikeringsprocessen.
När du har installerat PostgreSQL på båda servrarna så kan du gå vidare till replikeringskonfigurationen av den primära och den sekundära servern.
Inställning av replikering på den primära servern
Utför dessa steg när du har installerat PostgreSQL på både den primära och sekundära servern.
- Först så loggar du in på PostgreSQL-databasen med följande kommando:
su - postgres - Skapa en replikeringsanvändare med följande kommando:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Redigera pg_hba.cnf med en nano-applikation i Ubuntu och lägg till följande konfiguration:
nano /etc/postgresql/10/main/pg_hba.confKonfigurera filen med följande kommando:
host replication replication MasterIP/24 md5 - Öppna och redigera postgresql.conf och lägg in följande konfiguration på den primära servern:
nano /etc/postgresql/10/main/postgresql.confAnvänd följande konfigurationsinställningar:
listen_addresses = 'localhost,MasterIP' wal_level = replica wal_keep_segments = 64 max_wal_senders = 10 - Slutligen så startar du om PostgreSQL på den primära huvudservern:
systemctl restart postgresqlDu har nu slutfört installationen på den primära servern.
Konfigurera replikering på den sekundära servern
Följ de här stegen för att konfigurera replikering på den sekundära servern:
- Logga in på PostgreSQL RDMS med kommandot nedan:
su - postgres - Stoppa PostgreSQL-tjänsten så att vi kan arbeta med den med kommandot nedan:
systemctl stop postgresql - Redigera filen pg_hba.conf med det här kommandot och lägg till följande konfiguration:
// "Edit" command nano /etc/postgresql/10/main/pg_hba.conf // "Configuration" command host replication replication MasterIP/24 md5 - Öppna och redigera postgresql.conf på den sekundära servern och lägg till följande konfiguration eller ta bort kommentaren om den är kommenterad:
nano /etc/postgresql/10/main/postgresql.conf listen_addresses = 'localhost,SecondaryIP' wal_keep_segments = 64 wal_level = replica hot_standby = on max_wal_senders = 10SecondaryIPär adressen till den sekundära servern - Öppna PostgreSQL-datakatalogen på den sekundära servern och ta bort allt:
cd /var/lib/postgresql/10/main rm -rfv * - Kopiera filerna i PostgreSQL-datakatalogen för den primära servern till PostgreSQL-datakatalogen för den sekundära servern. Skriv sedan det här kommandot på den sekundära servern:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -U replication --wal-method=fetch - Skriv in PostgreSQL-lösenordet för den primära servern och tryck på enter. Lägg sedan till följande kommando för återställningskonfigurationen:
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configuration standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Här är
YOUR_PASSWORDlösenordet för replikeringsanvändaren i PostgreSQL på den skapade primära servern. - När lösenordet har ställts in så måste du starta om den sekundära PostgreSQL-databasen eftersom den stoppades:
systemctl start postgresqlTesta din installation
Nu när vi har utfört stegen så kan vi testa replikeringsprocessen och observera den sekundära serverdatabasen. För detta så skapar vi en tabell på den primära servern och observerar om samma sak återspeglas på den sekundära servern.
Låt oss börja med det.
- Eftersom vi skapar tabellen på den primära servern så måste du logga in på den:
su - postgres psql - Nu skapar vi en enkel tabell som heter ”testtable” och lägger in data i tabellen genom att köra följande PostgreSQL-förfrågningar i terminalen:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Observera den sekundära serverns PostgreSQL-databas genom att logga in på den sekundära servern:
su - postgres psql - Nu kontrollerar vi om tabellen ”testtable” finns och kan returnera data genom att köra följande PostgreSQL-förfrågningar i terminalen. Detta kommando visar i princip hela tabellen.
select * from testtable;
Detta är resultatet av testtabellen:
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------Du bör kunna se samma data som på den primära servern.
Om du ser ovanstående så har du framgångsrikt genomfört replikeringsprocessen!
Vilka är PostgreSQL’s manuella steg för manuell failover?
Låt oss gå igenom de manuella stegen för en PostgreSQL failover:
- Krascha den primära servern.
- Promota standby-servern genom att köra följande kommando på standby-servern:
./pg_ctl promote -D ../sb_data/ server promoting - Anslut till den främjade standby-servern och lägg in en rad:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
Som ett resultat av en lyckad infogning så har standby-servern, som tidigare var en skrivskyddad server, blivit den nya primära servern.
Hur man automatiserar Failover i PostgreSQL
Det är enkelt att konfigurera automatisk failover.
Du behöver EDB PostgreSQL failover manager (EFM). Efter att ha laddat ner och installerat EFM på varje primär- och standby-nod så kan du skapa ett EFM-kluster. Det består av en primärnod, en eller flera standby-noder och en valfri Witness-nod som bekräftar påståenden i händelse av fel.
EFM övervakar kontinuerligt systemets hälsa och skickar e-postvarningar baserat på systemhändelser. När ett fel inträffar så växlar den automatiskt över till den mest uppdaterade standby-noden. Den konfigurerar sedan om alla andra standby-servrar så att de känner igen den nya primära noden.
Den konfigurerar även om belastningsutjämnare(t.ex. pgPool) och förhindrar att ”split-brain” (när två noder tror att var och en av dem är primär) uppstår.
Sammanfattning
På grund av stora datamängder så har skalbarhet och säkerhet blivit två av de viktigaste kriterierna för databashantering, särskilt i en transaktionsmiljö. Vi kan visserligen förbättra skalbarheten vertikalt genom att lägga till mer resurser/hårdvara till befintliga noder. Detta är dock inte alltid möjligt, ofta på grund av kostnaden eller begränsningarna för att lägga till ny hårdvara.
Det krävs därför en horisontell skalbarhet, vilket innebär att man lägger till fler noder till befintliga nätverksnoder snarare än förbättrar funktionaliteten hos befintliga noder. Det är här som PostgreSQL-replikering kommer in i bilden.
I den här artikeln så har vi diskuterat typerna av PostgreSQL-replikering, fördelar, replikeringslägen, installation och PostgreSQL failover mellan SMR och MMR. Nu vill vi höra vad du har att säga.
Vilken av dem brukar du vanligtvis implementera? Vilken databasfunktion är viktigast för dig och varför? Vi vill gärna läsa dina tankar! Dela dem i kommentarsfältet nedan.

Salman Ravoof är en självlärd webbutvecklare, författare, skapare och en stor beundrare av fri och öppen källkod (FOSS). Förutom teknik är han intresserad av vetenskap, filosofi, fotografi, konst, katter och mat. Lär dig mer om honom på hans hemsida och kontakta Salman på X.

