
MySQLとMariaDBは、どちらもB木インデックスの効率性をシームレスに活用し、データ操作を最適化します。このインデックスメカニズムは、迅速なデータ検索、クエリパフォーマンスの向上、ディスクI/Oの最小化を実現し、応答性の高い効率的なデータベース体験に貢献しています。
今回は、データベースのインデックス作成について詳しくご説明し、MySQLまたはMariaDBで、インデックスをより効果的に活用するヒントをご紹介します。
インデックスとは
MySQLデータベースに特定の情報をクエリすると、データベーステーブルの各行から該当するデータが探し出されます。このプロセスは、データベースの規模が大きければ大きいほど時間を要するのが一般的です。
データベース管理者は、インデックスを使ってデータ検索プロセスを高速化し、クエリの効率を最適化することになります。インデックスの作成により、データを体系的に整理することで、検索しなければならないデータ量を最小限に抑え、迅速かつ効果的にクエリを実行することができます。
具体例を見てみましょう。以下の「Customer」テーブルで、名前がAvaの顧客を検索したいとします。
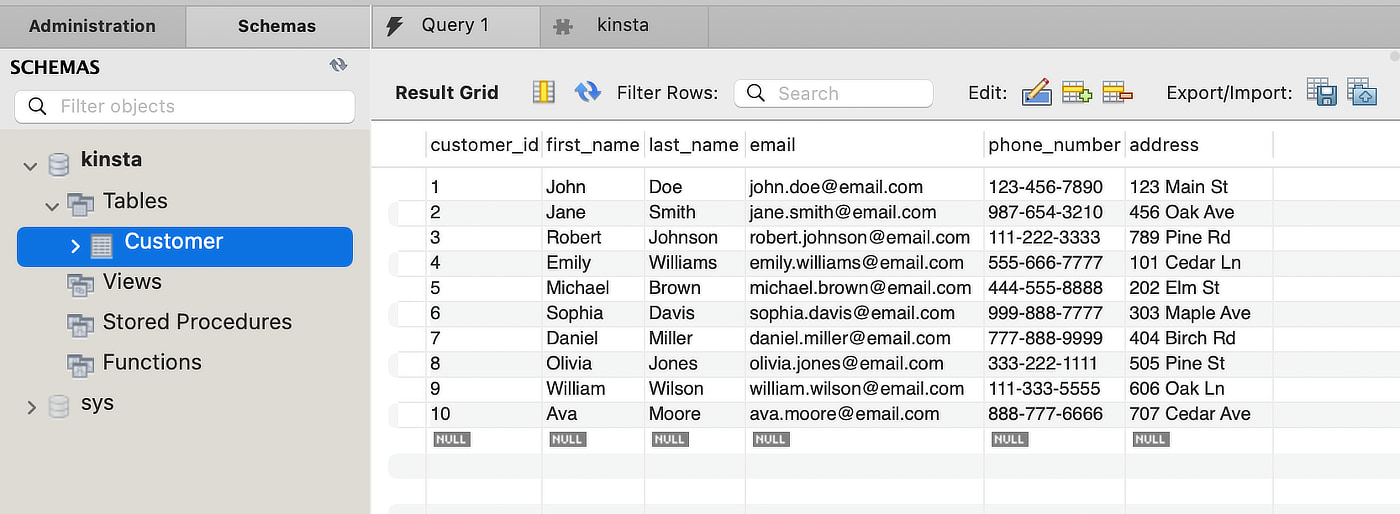
first_name列にB木インデックスを追加し、対象の情報をより効率的に検索できる構造が作成できます。この構造は、ルートノードを頂点に枝分かれし、最下層にはリーフ(葉)ノードがくるため、木のような構造になっています。
この構造では、各階層がデータのソート順に基づいて検索を誘導します。
B木インデックスの検索パスを図に表すと、以下のようになります。
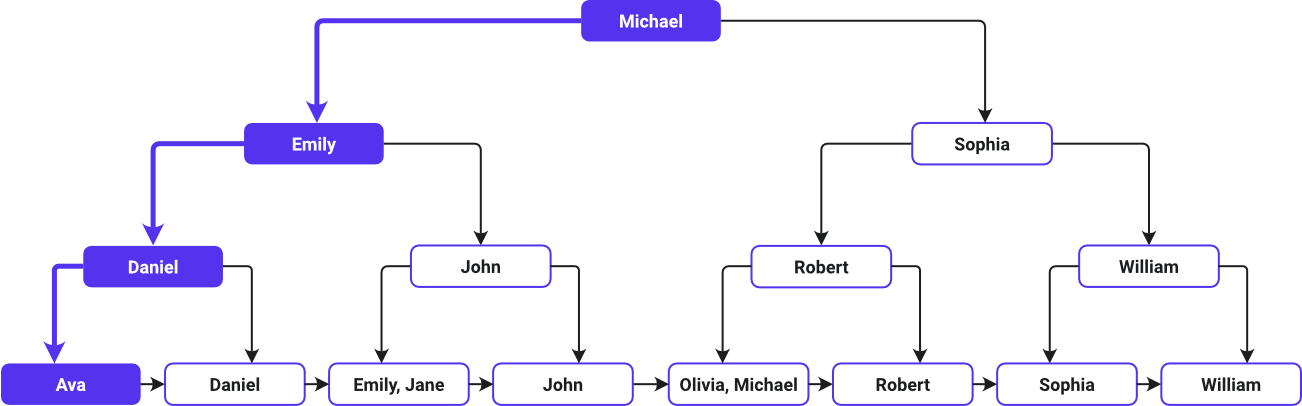
先ほどの例に戻り、Avaはアルファベット(A-Z)の昇順で最初に、Williamは最後に位置しています。B木では、リストの中央の値がルートノードとして指定されます。上の例では、Michaelがルートノードになります。ルートノードを頂点に枝分かれし、Michaelの左と右に値が並びます。
木の階層を下るにつれて、各ノードには、アルファベット順に並んだ名前を検索するためのキー(元のデータ行への直接リンク)が増えていきます。最後にリーフノードですべての顧客の名のデータが揃います。
検索プロセスは、まずAvaをルートノードであるMichaelと比較することから始まります。Avaはアルファベット順でMichaelよりも前にあると判断して、左に移動します。それから左のノードに続くEmily、Daniel、そしてAvaに進み、Avaの情報を含むリーフノードに到達します。
B木は、ナビゲーションシステムの簡易版として機能し、データセット内のすべての名をチェックすることなく、検索を特定の場所に効率的に誘導します。よく整備された道をナビゲーションを考慮して設置された標識に従い、目的のデータに迷うことなくたどり着くことができます。
インデックスの種類
インデックスには、さまざまな目的に応じた種類があります。
1. 単一列インデックス
単一列インデックスは、インデックスのキーとテーブルデータを対応づけます。インデックス内の各キーは、1つのテーブル行に対応します。
customer_id列は、Customerテーブルの主キーで、単一列インデックスとして機能します。キーは各顧客を識別し、テーブル内の各顧客の情報をリンクします。
| インデックス(customer_id) | 行ポインタ |
| 1 | 行1 |
| 2 | 行2 |
| 3 | 行3 |
| 4 | 行4 |
| … | … |
このように、customer_idキーと個々の顧客情報の関係性はシンプルです。行数(あるいは明確な値を持つ列)の少ないテーブルに適しています。statusやcategoryのような列が良い候補です。
単一列インデックスは、単一の列に基づいて特定の行を検索する単純なクエリに使用するため、実装はシンプルでわかりやすく、小規模なデータセットでは効率的です。
2. 複数列インデックス
組織的なデータ検索向けの単一列インデックスとは異なり、複数列インデックスは階層構造を使用します。複数列インデックスには、複数の検索方針があり、上層のインデックスが下層のインデックスに検索を誘導し、データを格納するリーフノードに達するまで検索が繰り返されます。この構造により、検索時に求められる比較の回数を減らすことができます。
address列とcustomer_id列を持つインデックスを例に挙げてみます。
| インデックス(address) | サブインデックス(customer_id) | 行ポインタ |
| 123 Main St | 1 | 行1 |
| 456 Oak Ave | 2 | 行2 |
| 789 Pine Rd | 3 | 行3 |
| … | … | … |
第1階層は住所を整理し、第2階層は各住所の中でさらに顧客IDを整理します。
この構成は、整理された検索階層が求められる広範なデータセットに適しています。また、last_nameのようにカーディナリティ(特定の列のデータ値の一意性)が中程度の列にも有用です。
3. クラスタ化インデックス
MySQLのクラスタ化インデックスは、インデックスの論理的な順序とテーブル内のデータの順序を指示します。Customerテーブルのcustomer_id列に適用すると、列の値に基づいて行がソートされます。これはテーブル内のデータの順序がクラスタ化インデックスの順序を反映することを意味し、ディスクI/Oを削減することで、特定のパターンに対するデータ検索を高速化します。
この手法は、データ検索パターンが顧客IDの順序と一致している場合に有効です。また、customer_idのようにカーディナリティの高い列にも適しています。
クラスタ化インデックスは、特定のパターンに対するデータ検索のパフォーマンスにおいて利点はありますが、潜在的な落とし穴も。クラスタ化インデックスに基づいて行をソートすると、特に挿入や更新のパターンがクラスタ化インデックスの順序と一致しない場合、挿入や更新操作のパフォーマンスに影響を与えることがあります。これは、ソートされた順序を維持しながらデータを挿入または更新することで、負荷が増加するためです。
4. 非クラスタ化インデックス
非クラスタ化インデックスは、データベース構造に柔軟性をもたらします。例えば、email列に適用すると、クラスタ化インデックスとは異なり、テーブル内のエントリの順序は変更されません。
代わりに、キー(この場合はメールアドレス)をデータ行にマップする新たな構造が構築されます。これにより、特定のメールアドレスをデータベースに問い合わせると、テーブルの順序に依存することなく関連する行に検索を誘導できます。
このインデックスの利点は、保存されたデータに順序を課すことなく、複数の列を効率的に検索することです。テーブルの主順序に従わないクエリにも対応できるため、汎用性が高くなります。
非クラスタ化インデックスは、データの検索パターンがアルファベット順とは異なる場合や、メールアドレスのように中程度から高いカーディナリティを持つ列に適しています。
インデックスを作成する
インデックスがどのようなものであるかを理解したら、MySQL Workbenchを使用してインデックスを作成する例を見てみましょう。
前提条件
これからご紹介する手順には、以下のものが必要になります。
- MySQLデータベース(MariaDBと互換性あり)
- SQLとMySQLの使用経験
- MySQL Workbench
Customerテーブルの作成
- MySQL Workbenchを起動し、MySQLサーバーに接続します。
- 以下のSQLクエリを実行してCustomerテーブルを作成します。
CREATE TABLE Customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(15), address VARCHAR(255) ); - 以下のデータを挿入します。
-- Customerテーブルにデータを追加 INSERT INTO Customer (customer_id, first_name, last_name, email, phone_number, address) VALUES (1, 'John', 'Doe', '[email protected]', '123-456-7890', '123 Main St'), (2, 'Jane', 'Smith', '[email protected]', '987-654-3210', '456 Oak Ave'), (3, 'Robert', 'Johnson', '[email protected]', '111-222-3333', '789 Pine Rd'), (4, 'Emily', 'Williams', '[email protected]', '555-666-7777', '101 Cedar Ln'), (5, 'Michael', 'Brown', '[email protected]', '444-555-8888', '202 Elm St'), (6, 'Sophia', 'Davis', '[email protected]', '999-888-7777', '303 Maple Ave'), (7, 'Daniel', 'Miller', '[email protected]', '777-888-9999', '404 Birch Rd'), (8, 'Olivia', 'Jones', '[email protected]', '333-222-1111', '505 Pine St'), (9, 'William', 'Wilson', '[email protected]', '111-333-5555', '606 Oak Ln'), (10, 'Ava', 'Moore', '[email protected]', '888-777-6666', '707 Cedar Ave');
単一列インデックス
MySQLとMariaDBでクエリのパフォーマンスを最適化する方法の一つとして、単一列インデックスを使用できます。
Customerテーブルに単一列インデックスを追加するには、CREATE INDEX文を使用します。
-- "customer_id"に対する単一列インデックスを作成
CREATE INDEX idx_customer_id ON Customer(customer_id);正しく実行されると、データベースから以下のコードが返されインデックスの作成を確認します。
0 row(s) affected Records: 0 Duplicates: 0 Warnings: 0これで、customer_id列の値に基づいてデータを絞り込むクエリがデータベースによって適切に処理され、効率が大幅に向上します。
複数列インデックス
MySQLとMariaDBは、複数列インデックスにより、個々の列のインデックスを拡張することができます。複数の階層や列にまたがり、複数の列の値を1つのインデックスにまとめることで、クエリの実行が効率的になります。
以下のコードを使用して、MySQLまたはMariaDB で、addressおよびcustomer_id列に焦点を当てた複数列インデックスを作成します。
-- "address"と"customer_id"に対する複数列インデックスを作成
CREATE INDEX idx_address_customer_id ON Customer(address, customer_id);複数列インデックスをうまく活用することで、特に複数の列をセットで扱う場合、クエリのパフォーマンスが劇的に向上します。
クラスタ化インデックス
MySQLとMariaDBでは、単一列インデックスと複数列インデックスの他に、クラスタ化インデックスを使用することができます。データ行をインデックスのポインタの順序に合わせることで、データベースのパフォーマンスを改善する動的な選択肢になります。
例えば、Customerテーブルのcustomer_id列にクラスタ化インデックスを適用すると、顧客IDの順序が揃います。
-- "customer_id"に対するクラスタ化インデックスを作成
CREATE CLUSTERED INDEX idx_customer_id_clustered ON Customer(customer_id);データの順序が最適化されるため、ディスクI/Oを削減しながら、特定のパターンのデータ検索を大幅に改善することができます。
非クラスタ化インデックス
非クラスタ化インデックスは、データを特定の順序に強制することなく、列に応じてクエリを最適化することができます。MySQLとMariaDBでは、インデックスが非クラスタ化であることを指定する必要はありません。
テーブルアーキテクチャがそれを示唆しており、クラスタ化インデックスは、プライマリキーまたは最初の非NULLのユニークキーのみに適用され、テーブルのその他のインデックスはすべて非クラスタ化されます。例を見てみましょう。
-- "email"に対する非クラスタ化インデックスを作成
CREATE INDEX idx_email_non_clustered ON Customer(email);非クラスタ化インデックスを活用すると、複数の列を効率的に検索できるため、より多機能で応答性の高いデータベースを実現できます。
ベストプラクティスとヒント
ステータスやカテゴリのように、異なる値の範囲が狭い列を扱う場合は、単一列インデックスがおすすめです。また、メールアドレスのように値の範囲が広い列には、複数列インデックスと非クラスタインデックスを使用します。
クラスタ化インデックスと非クラスタ化インデックスの使い分けは、好みのデータ検索パターンによります。前者では顧客IDのようなカーディナリティの高い列を選択し、後者ではメールアドレスのような中程度から高度なカーディナリティを持つ列を選択するのがベストです。
インデックスの最適化
インデックスのパフォーマンス向上には、カバリングインデックス、冗長なインデックスを削除するなどの実践的な方法があります。
1. カバリングインデックス
カバリングインデックスとは、必要なデータをすべて網羅するインデックスを作成することで、クエリのパフォーマンス向上に役立ちます。クエリに必要なすべての列を含むインデックスにより、データ行にアクセスする必要がなくなります。
-- "first_name"と"last_name"にカバリングインデックスを作成
CREATE INDEX idx_covering_name ON Customer(first_name, last_name);2. 冗長なインデックスの削除
冗長なインデックスの削除も有効ですが、インデックスの削除はクエリのパフォーマンスに影響を与える可能性があるため慎重に行う必要があります。
-- 不要なインデックスを削除
DROP INDEX idx_unnecessary_index ON Customer;定期的にインデックスを見直し、不要なものを削除することで、合理的で効率的なデータベース構造を維持することができます。
3. 過剰なインデックスを避ける
過剰なインデックスは避けるようにしましょう。インデックスは、クエリパフォーマンスを改善しますが、作成しすぎると逆効果です。バランスを見ながら、データベースの肥大化を回避することが大切です。ストレージ要件の増加やパフォーマンスの低下をまねく恐れがあります。
4. クエリのパターンを分析する
インデックスを作成する前に、クエリパターンの分析もお忘れなく。頻繁に実行されるクエリを理解し、WHEREやJOINで使用される列のインデックス作成に集中することは、パフォーマンスの最適化に不可欠です。
まとめ
今回は、MySQLとMariaDBのインデックス作成について、B木インデックスの効率性を軸にご紹介しました。インデックスの基本情報と、さまざまな種類(単一列、複数列、クラスタ化、非クラスタ化)を取り上げました。
Kinstaでは、MySQLとMariaDBのどちらもサポート。読み取りの多いワークロードを最適化したい方、書き込みパフォーマンスを向上させたい方に、インデックスの要件に対応する信頼性に優れた高性能ソリューションをご提供しています。Kinstaのマネージドデータベースサーバーで、MySQLとMariaDB、そしてインデックス機能をフル活用しましょう。


