
Já ouviu falar no termo robots.txt e se perguntou como ele se aplica ao seu site? A maioria dos sites possui um arquivo robots.txt, mas isso não significa que a maioria dos proprietários de sites o compreenda. Neste artigo, esperamos mudar isso oferecendo uma análise detalhada do arquivo robots.txt do WordPress e como ele pode controlar e limitar o acesso ao seu site.
Há muito para abordar, então vamos começar!
O que é um arquivo WordPress robots.txt?
Antes de falarmos sobre o arquivo robots.txt do WordPress, é importante definir o que é um “robô” nesse contexto. Robôs são qualquer tipo de “bot” que visita sites na Internet. O exemplo mais comum são os rastreadores de mecanismos de pesquisa. Esses bots “rastreiam” a web para ajudar mecanismos de pesquisa como o Google a indexar e classificar bilhões de páginas na Internet.
Portanto, bots são, em geral, algo necessário para a Internet. Mas isso não significa necessariamente que você, ou outros proprietários de sites, querem bots correndo sem restrições. O desejo de controlar como os robôs da internet interagem com os sites levou à criação do padrão de exclusão de robôs em meados da década de 90. Robots.txt é a implantação prática desse padrão – ele permite que você controle como os bots participantes interagem com o seu site. Você pode bloquear totalmente os bots, restringir o acesso deles a certas áreas do seu site, e muito mais.
Essa parte de “participar” é importante, no entanto. Robots.txt não pode forçar um bot a seguir suas diretrizes. E os bots maliciosos podem e vão ignorar o arquivo robots.txt. Além disso, mesmo organizações respeitáveis ignoram alguns comandos que você pode colocar no arquivo robots.txt. Por exemplo, o Google ignorará quaisquer regras que você adicionar ao seu robots.txt sobre a frequência com que seus rastreadores visitam. Você pode ajustar a taxa a qual o Google rastreia seu site na página Crawl Rate Settings para sua propriedade no Google Search Console.
Se você está tendo muitos problemas com bots, uma solução de segurança como Cloudflare ou Sucuri pode ajudar.
Como encontrar o robots.txt?
O arquivo robots.txt vive na raiz do seu site, então adicionar /robots.txt após o seu domínio deve carregar o arquivo (se você tiver um). Por exemplo, https://kinsta.com/robots.txt.
Quando você deve usar um arquivo robots.txt?
Para a maioria dos proprietários de sites, os benefícios de um arquivo robots.txt bem estruturado se resumem a duas categorias:
- Otimizando os recursos dos mecanismos de pesquisa, dizendo-lhes para não perderem tempo em páginas que você não quer ser indexado. Isso ajuda a garantir que os mecanismos de pesquisa se concentrem em rastrear as páginas com as quais você mais se importa.
- Otimizando o uso do seu servidor através do bloqueio de bots que estão desperdiçando recursos.
Robots.txt não se trata especificamente de controlar quais páginas são indexadas nos mecanismos de pesquisa
Robots.txt não é uma maneira infalível de controlar que páginas os mecanismos de pesquisa indexam. Se seu objetivo principal é impedir que certas páginas sejam incluídas nos resultados dos mecanismos de pesquisa, a abordagem adequada é usar uma meta noindex tag ou proteção por senha.
Isso porque o seu robots.txt não está dizendo diretamente aos mecanismos de pesquisa para não indexar conteúdo – está apenas dizendo a eles para não rastrear. Enquanto o Google não vai rastrear as áreas marcadas de no seu site, o próprio Google afirma que se um site externo se conecta a uma página que você exclui com o seu arquivo robots.txt, o Google ainda pode indexar essa página.
John Mueller, um analista de webmaster do Google, também confirmou que se uma página possui links apontando para ela, mesmo que esteja bloqueada pelo robots.txt, ainda pode ser indexada. Abaixo está o que ele disse em uma sessão de perguntas e respostas do Webmaster Central:
Uma coisa a se ter em mente é que, se essas páginas estiverem bloqueadas pelo arquivo robots.txt, teoricamente pode acontecer de alguém aleatoriamente criar um link para uma dessas páginas. E se isso acontecer, é possível que indexemos essa URL sem nenhum conteúdo, pois ela está bloqueada pelo robots.txt. Nesse caso, não saberíamos que você não deseja que essas páginas sejam realmente indexadas.
Por outro lado, se essas páginas não estiverem bloqueadas pelo arquivo robots.txt, você pode adicionar uma meta tag noindex nessas páginas. Se alguém criar um link para essas páginas e nós rastrearmos esse link, veremos a meta tag noindex e entenderemos que essas páginas não precisam ser indexadas. Assim, podemos ignorá-las completamente durante o processo de indexação.
Portanto, nesse sentido, se houver algo nessas páginas que você não deseja que seja indexado, não as bloqueie completamente. Em vez disso, use a meta tag noindex.
Preciso de um arquivo robots.txt?
É importante lembrar que você não é obrigado a ter um arquivo robots.txt em seu site. Se você não se importa que todos os bots tenham livre acesso para rastrear todas as suas páginas, você pode optar por não adicionar um, já que não há instruções específicas a serem dadas aos rastreadores.
Em alguns casos você pode até não conseguir adicionar um arquivo robots.txt devido a limitações com o CMS que você está usando. Isso é bom, e existem outros métodos para instruir os bots sobre como rastrear suas páginas sem usar um arquivo robots.txt.
Qual código de status HTTP deve ser retornado para o arquivo robots.txt?
O arquivo robots.txt deve retornar um código de status HTTP de 200 OK Para que os rastreadores possam acessá-lo.
Se você está tendo problemas para indexar suas páginas pelos mecanismos de pesquisa, vale a pena verificar duas vezes o código de status retornado para o seu arquivo robots.txt. Qualquer coisa que não seja um código de status 200 pode impedir que rastreadores acessem o seu site.
Alguns proprietários de sites relataram que suas páginas foram desindexadas devido ao retorno de um status não-200 pelo arquivo robots.txt. Um proprietário de um site perguntou sobre um problema de indexação em uma sessão de perguntas e respostas sobre SEO do Google em março de 2022, e John Mueller explicou que o arquivo robots.txt deve retornar um status 200 se estiver presente ou um status 4XX se o arquivo não existir. Nesse caso específico, estava sendo retornado um erro interno de 500 servidores, o que Mueller mencionou como possível motivo para o Googlebot excluir o site da indexação.
O mesmo pode ser visto neste Tweet, onde um dono de site relatou que seu site inteiro foi desindexado devido a um arquivo robots.txt devolvendo um erro de 500.
[Quick SEO tip]
If you are having issue with indexing, make sure your robots.txt file is returning either 200 or 404.
If your file returns 500, Google will eventually deindex your website, as I've seen with this project. pic.twitter.com/8KiYLgDVRo
— Antoine Eripret (@antoineripret) November 14, 2022
A meta tag dos robots pode ser usada ao invés de um arquivo robots.txt?
Não. A meta tag robots permite que você controle quais páginas são indexadas, enquanto o arquivo robots.txt permite que você controle quais páginas são rastreadas. Bots devem primeiro rastrear as páginas para ver as meta tags, então você deve evitar tentar usar tanto uma meta tag não permitida quanto uma noindex, já que a noindex não seria capturada.
Se o seu objetivo é excluir uma página dos mecanismos de pesquisa, a meta tag noindex é geralmente a melhor opção.
Como criar e editar seu arquivo robots.txt no WordPress
Por padrão, o WordPress cria automaticamente um arquivo robots.txt virtual para o seu site. Então mesmo se você não levantar um dedo, seu site já deve ter o arquivo robots.txt padrão. Você pode testar se este é o caso anexando “/robots.txt” ao final do seu nome de domínio. Por exemplo, “https://kinsta.com/robots.txt” traz o arquivo robots.txt que usamos aqui no Kinsta.
Exemplo de um arquivo robots.txt
Aqui está um exemplo do arquivo robots.txt da Kinsta:
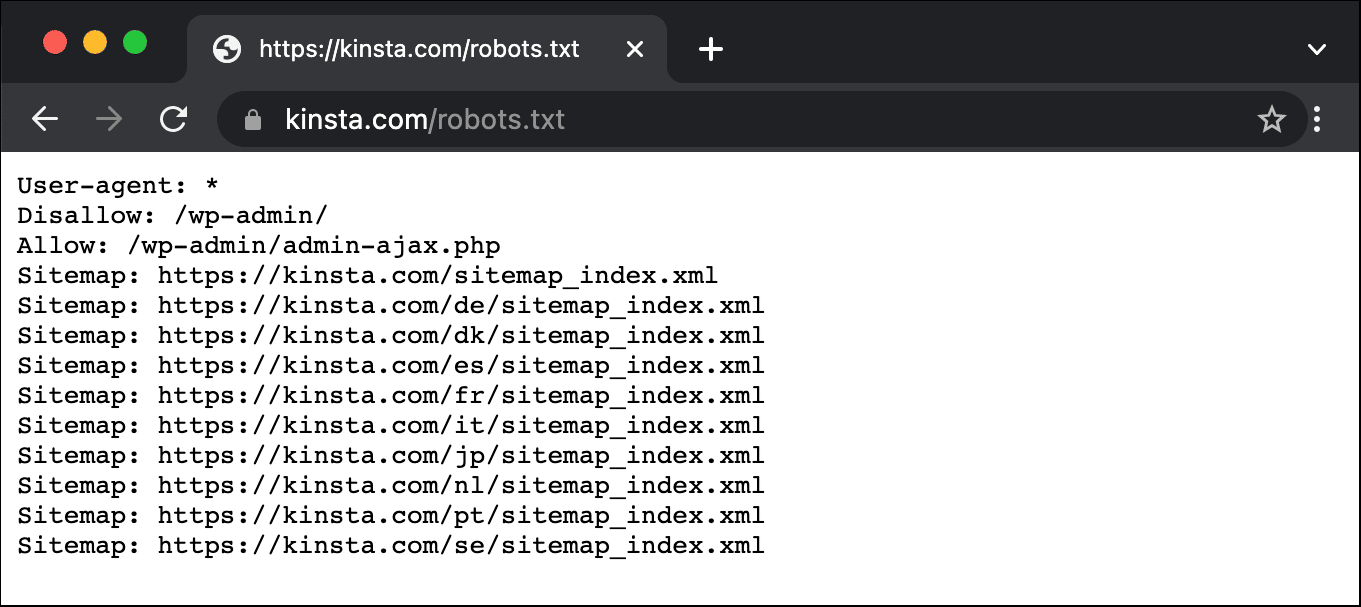
Isso fornece a todos os robots instruções sobre quais caminhos ignorar (por exemplo, o caminho wp-admin), com quaisquer exceções (por exemplo, o arquivo admin-ajax.php), juntamente com a localização do mapa do site XML da Kinsta.
Mas como este arquivo é virtual, você não pode editá-lo. Caso você queira editar seu arquivo robots.txt, você precisará realmente criar um arquivo físico em seu servidor que você pode manipular conforme necessário. Aqui estão três maneiras simples de fazer isso:
Como criar e editar um arquivo robots.txt no WordPress com Yoast SEO
Se você estiver usando o popular plugin Yoast SEO, você pode criar (e depois editar) seu arquivo robots.txt diretamente da interface do Yoast. Antes de acessá-lo, porém, você precisa acessar o SEO → Tools e clicar em File editor.
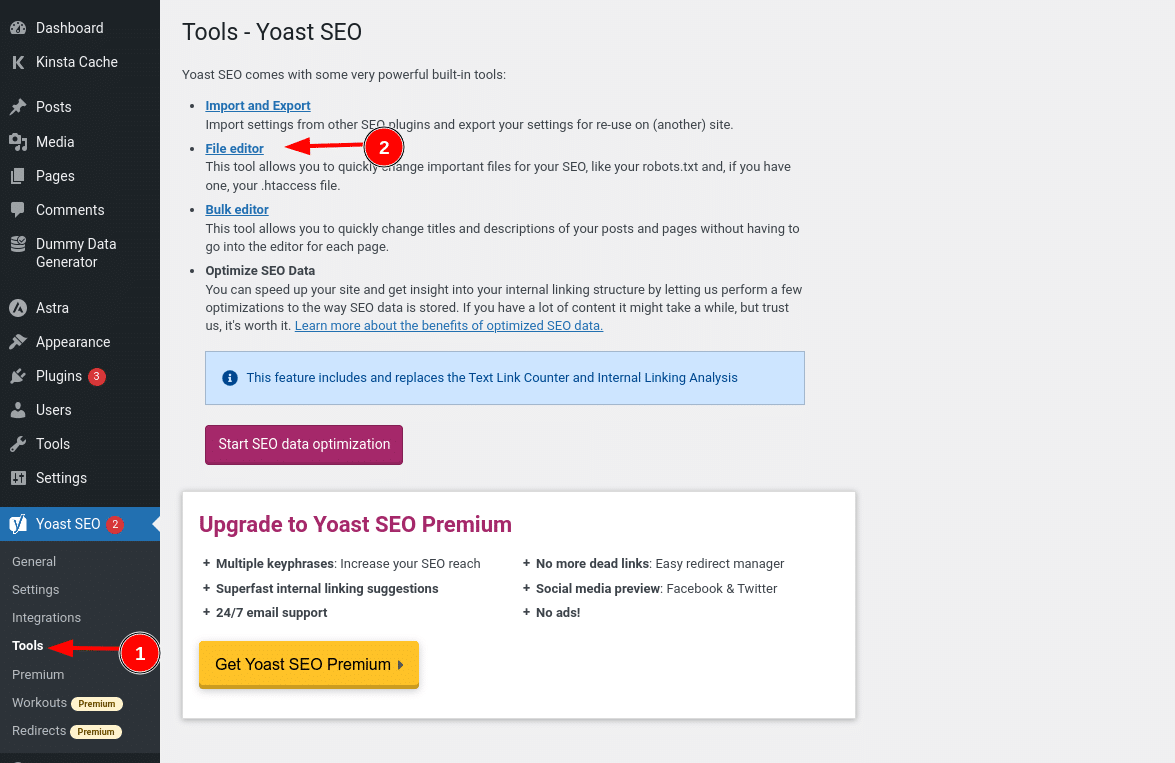
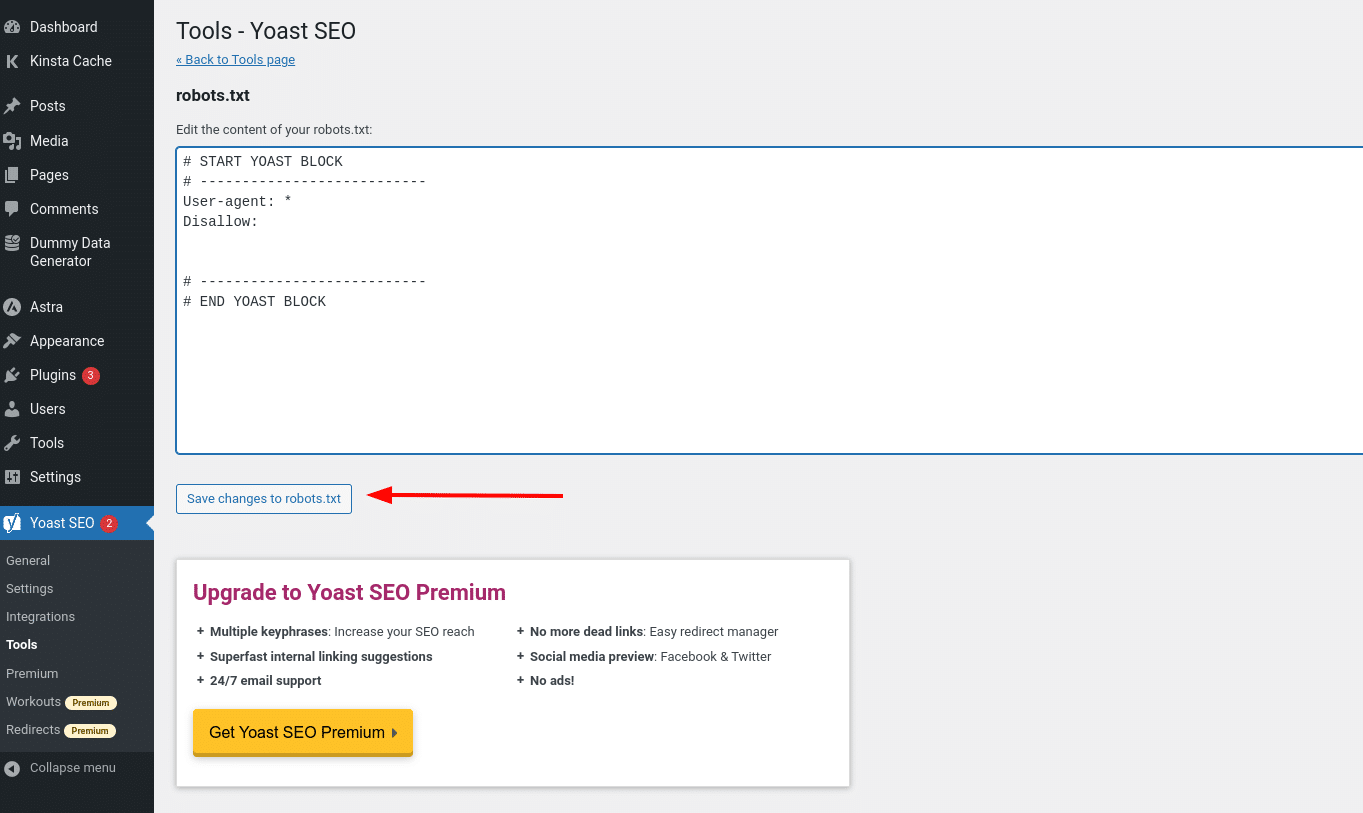
E quando você clicar nesse botão, você será capaz de editar o conteúdo do seu arquivo robots.txt diretamente da mesma interface e então salvar quaisquer alterações feitas.
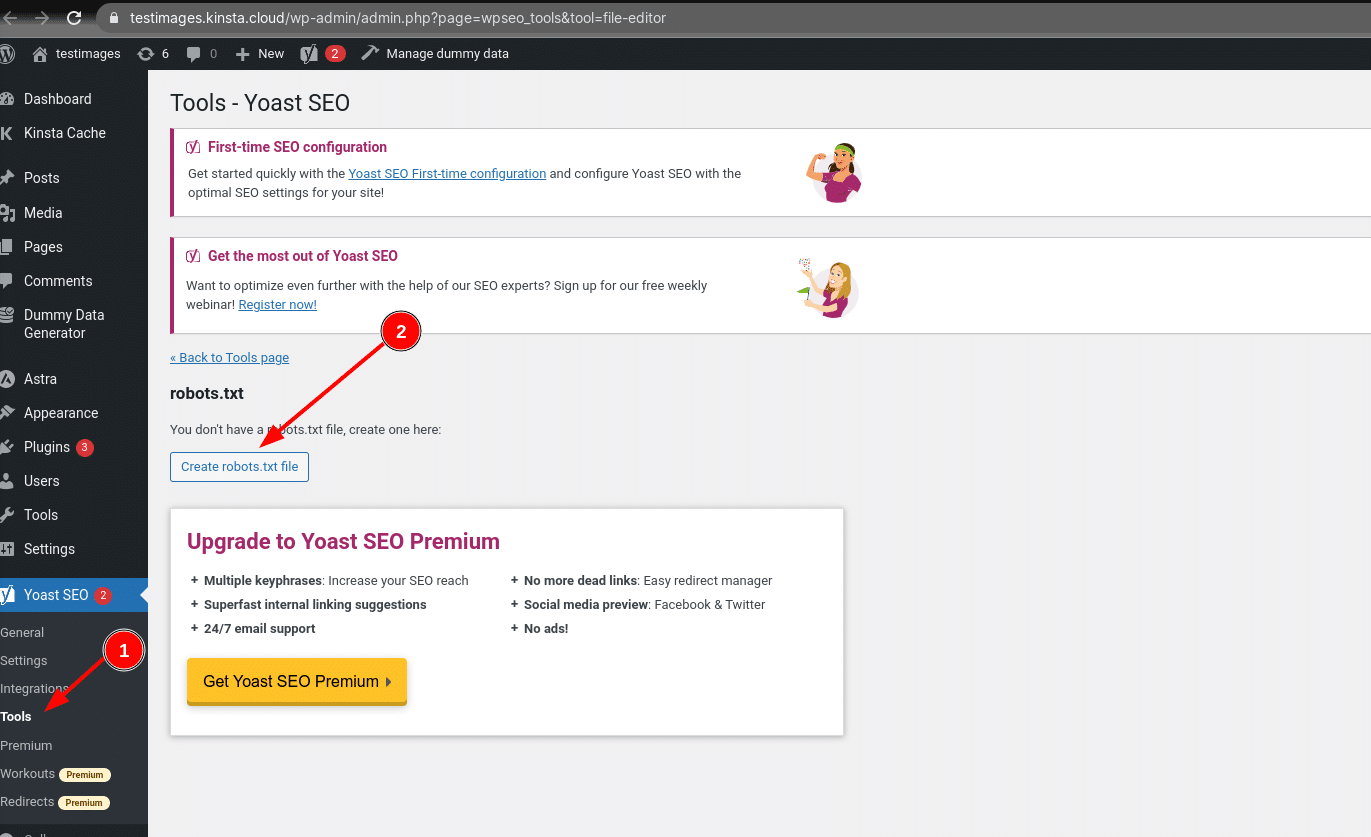
Assumindo que você ainda não tenha um arquivo robots.txt físico, Yoast lhe dará a opção Create robots.txt file:
Conforme avançamos, vamos explorar mais detalhes sobre os tipos de diretivas que você deve incluir no arquivo robots.txt do seu WordPress.
Como criar e editar um arquivo robots.txt com o plugin All in One SEO
Se você estiver usando o plugin All in One SEO Pack, que é quase tão popular quanto o Yoast, também é possível criar e editar o arquivo robots.txt do seu WordPress diretamente na interface do plugin. Tudo o que você precisa fazer é acessar All in One SEO → Tools:
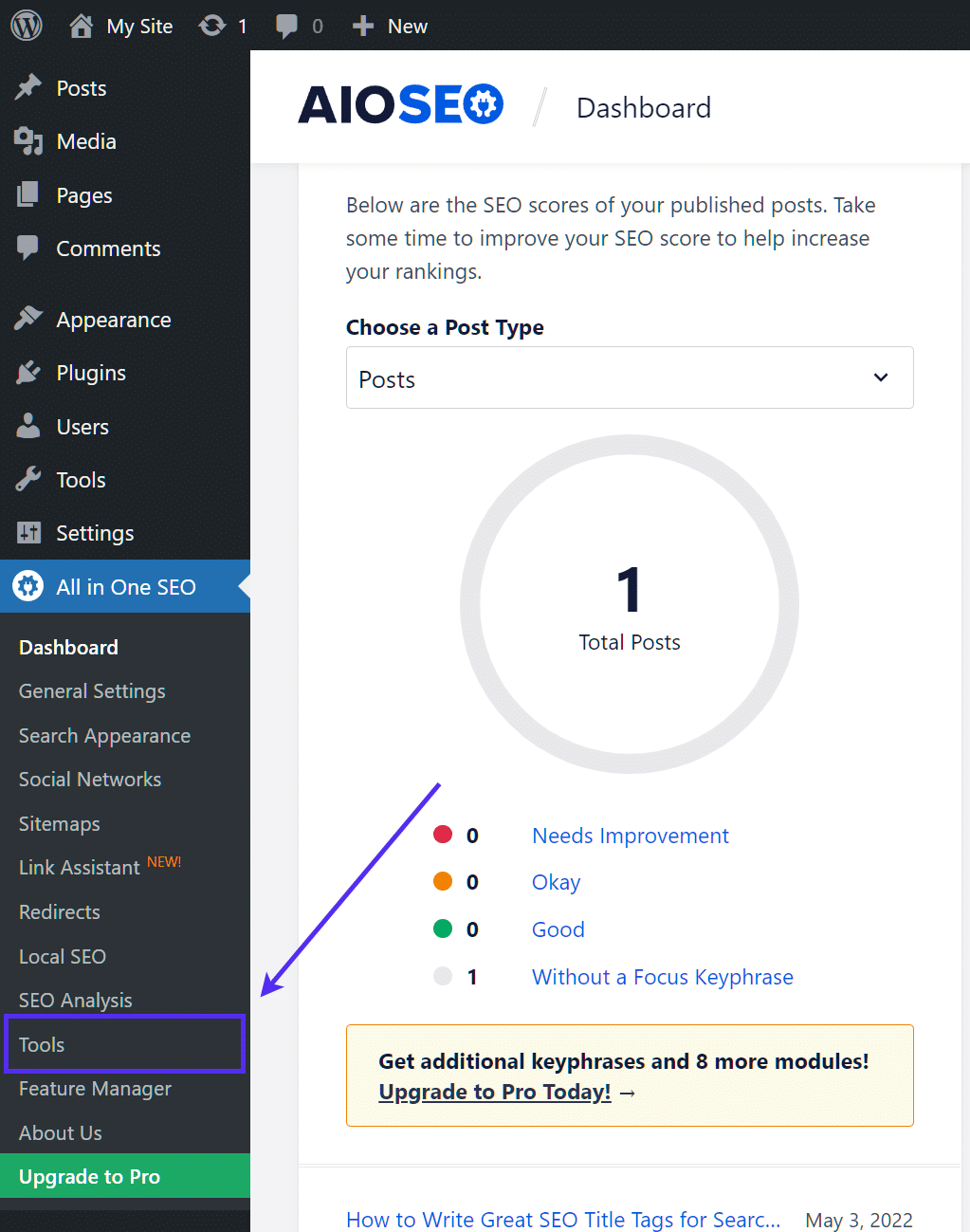
Então, clique no botão de opção Enable Custom robots.txt para que ele esteja ativado. Isso permitirá a você criar regras personalizadas e adicioná-las ao seu arquivo robots.txt:
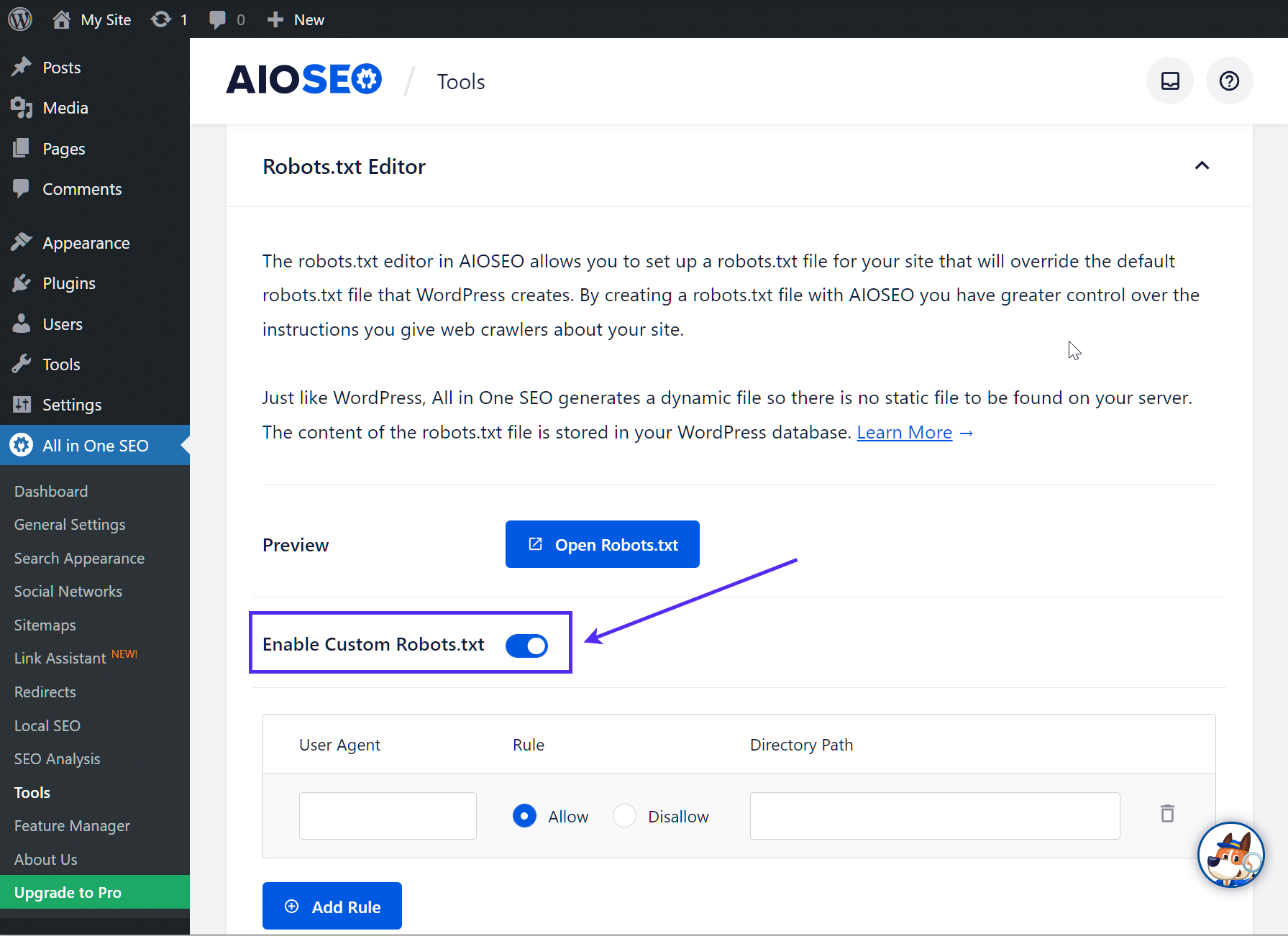
Como criar e editar um arquivo robots.txt via FTP
Se você não está usando um plugin SEO que oferece funcionalidade robots.txt, você ainda pode criar e gerenciar seu arquivo robots.txt via SFTP. Primeiro, use qualquer editor de texto para criar um arquivo vazio chamado “robots.txt”:
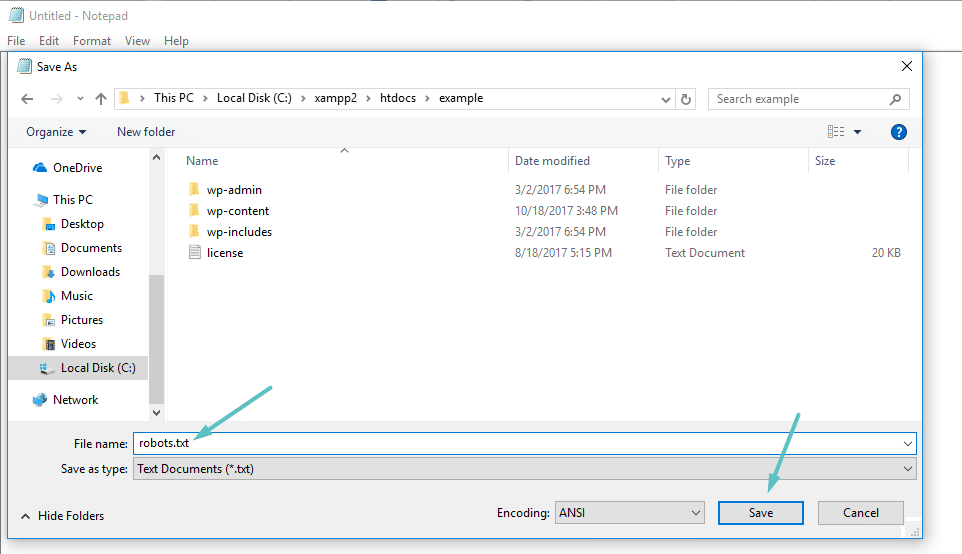
Então, conecte-se ao seu site via SFTP e faça o upload desse arquivo para a pasta root do seu site. Você pode fazer mais modificações no seu arquivo robots.txt editando via SFTP ou fazendo upload de novas versões do arquivo.
O que colocar em seu arquivo Robots.txt
Ok, agora você tem um arquivo físico robots.txt em seu servidor que você pode editar conforme necessário. Mas o que você realmente faz com esse arquivo? Bem, como você aprendeu na primeira seção, o robots.txt permite que você controle como os robôs interagem com o seu site. Você faz isso com dois comandos principais:
- User-agent – isso permite que você tenha como alvo bots específicos. Agentes de usuários são o que os bots usam para se identificar. Com eles, você poderia, por exemplo, criar uma regra que se aplica ao Bing, mas não ao Google.
- Disallow – Isso permite que você diga aos robôs para não acessar certas áreas do seu site.
Há também um comando Allow que você usará em situações de nicho. Por padrão, tudo em seu site é marcado com Allow, então não é necessário usar o comando Allow em 99% das situações. No entanto, ele pode ser útil quando você deseja Disallow a uma pasta e suas subpastas, mas permite o acesso (Allow) a uma subpasta específica.
Você adiciona regras especificando primeiro a qual User-agent a regra deve ser aplicada e, em seguida, listando as regras a serem aplicadas usando Disallow e Allow. Existem também outros comandos como Crawl-delay e Sitemap, mas ambos são:
- Ignorados pela maioria dos grandes rastreadores, ou interpretados de formas muito diferentes (no caso de atraso de rastreamento)
- Tornado redundante por ferramentas como o Google Search Console (para sitemaps)
Vamos analisar alguns casos específicos de uso para mostrar como tudo isso se encaixa.
Como usar Robots.txt para bloquear o acesso a todo o seu site com o comando Disallow All
Digamos que você queira bloquear todo o acesso dos rastreadores ao seu site. É improvável que isso ocorra em um site de produção, mas pode ser útil para um site de desenvolvimento. Para fazer isso, você adicionaria o arquivo robots.txt.txt.txt ao seu arquivo WordPress robots.txt:
User-agent: *
Disallow: /O que está acontecendo nesse código?
O asterisco (*) ao lado de User-agent significa “todos os agentes de usuário”. O asterisco é um caractere wildcard, o que significa que se aplica a todos os agentes de usuário. A barra (/) ao lado de Disallow indica que você deseja bloquear o acesso a todas as páginas que contêm “seudominio.com/” (que é cada página do seu site).
Como usar Robots.txt para bloquear o acesso de um único bot ao seu site
Neste exemplo, vamos fingir que você não gosta do fato de que o Bing rastreie suas páginas. Você é a Equipe Google até o fim e não quer nem mesmo que o Bing olhe para o seu site. Para bloquear apenas o Bing de rastrear seu site, você substituiria o wildcard *asterisk pelo Bingbot:
User-agent: Bingbot
Disallow: /Essencialmente, o código acima indica que a regra Disallow se aplica apenas aos bots com o User-agent “Bingbot”. É improvável que você queira bloquear o acesso do Bing ao seu site, mas esse cenário pode ser útil se houver um bot específico que você não queira que acesse seu site. Este site possui uma boa lista dos nomes conhecidos de User-agent da maioria dos serviços.
Como usar o Robots.txt para bloquear o acesso a uma pasta ou arquivo específico
Para este exemplo, digamos que você só queira bloquear o acesso a um arquivo ou pasta específica (e todas as subpastas dessa pasta). Para que isso se aplique ao WordPress, digamos que você queira bloquear:
- A pasta completa wp-admin
- wp-login.php
Você poderia usar os seguintes comandos:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpComo usar Robots.txt para permitir que todos os robots tenham acesso total ao seu site
Se você atualmente não tem nenhuma razão para bloquear o acesso de rastreadores a qualquer uma de suas páginas, você pode adicionar o seguinte comando.
User-agent: *
Allow: /
Ou, alternativamente:
User-agent: *
Disallow:
Como usar o robots.txt para permitir o acesso a um arquivo específico em uma pasta não permitida
Ok, agora vamos dizer que você quer bloquear uma pasta inteira, mas você ainda quer permitir o acesso a um arquivo específico dentro daquela pasta. É aqui que o comando Allow é útil. E, na verdade ele é muito aplicável no WordPress. Na verdade, o arquivo WordPress virtual robots.txt ilustra este exemplo perfeitamente:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpEste snippet bloqueia o acesso para a pasta /wp-admin/ exceto para o arquivo /wp-admin/admin-ajax.php.
Como usar robots.txt para impedir bots de rastrear resultados de pesquisa no WordPress
Uma ajuste específico para WordPress que você pode querer fazer é impedir que os crawlers de pesquisa rastreiem suas páginas de resultados de pesquisa. Por padrão, o WordPress usa o parâmetro de consulta “?s=”. Então, para bloquear o acesso, tudo o que você precisa fazer é adicionar a seguinte regra:
User-agent: *
Disallow: /?s=
Disallow: /search/Isso pode ser uma forma eficaz de também evitar erros soft 404, caso você esteja recebendo-os. Certifique-se de ler nosso guia detalhado sobre como acelerar a pesquisa no WordPress.
Como criar regras diferentes para diferentes bots em Robots.txt
Até agora, todos os exemplos trataram de uma regra por vez. Mas e se você quiser aplicar regras diferentes para diferentes bots? Você simplesmente precisa adicionar cada conjunto de regras sob a declaração user-agent para cada bot. Por exemplo, se você quiser criar uma regra que se aplique a todos os bots e outra regra que se aplique apenas ao Bingbot, você poderia fazer assim:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /Neste exemplo, todos os bots serão bloqueados de acessar /wp-admin/, mas o Bingbot será bloqueado de acessar todo o seu site.
Testando seu arquivo robots.txt
Para garantir que seu arquivo robots.txt foi configurado corretamente e está funcionando conforme o esperado, você deve testá-lo minuciosamente. Um único caractere fora do lugar pode ser catastrófico para o desempenho de um site nos mecanismos de pesquisa, então testar pode ajudar a evitar problemas potenciais.
Testador de robots.txt do Google
A ferramenta Google’s robots.txt Tester (anteriormente parte do Google Search Console) é fácil de usar e destaca possíveis problemas no seu arquivo robots.txt.
Basta navegar até a ferramenta e selecionar a propriedade do site que você deseja testar, depois rolar até o final da página e digitar qualquer URL no campo, depois clicar no botão vermelho TEST:
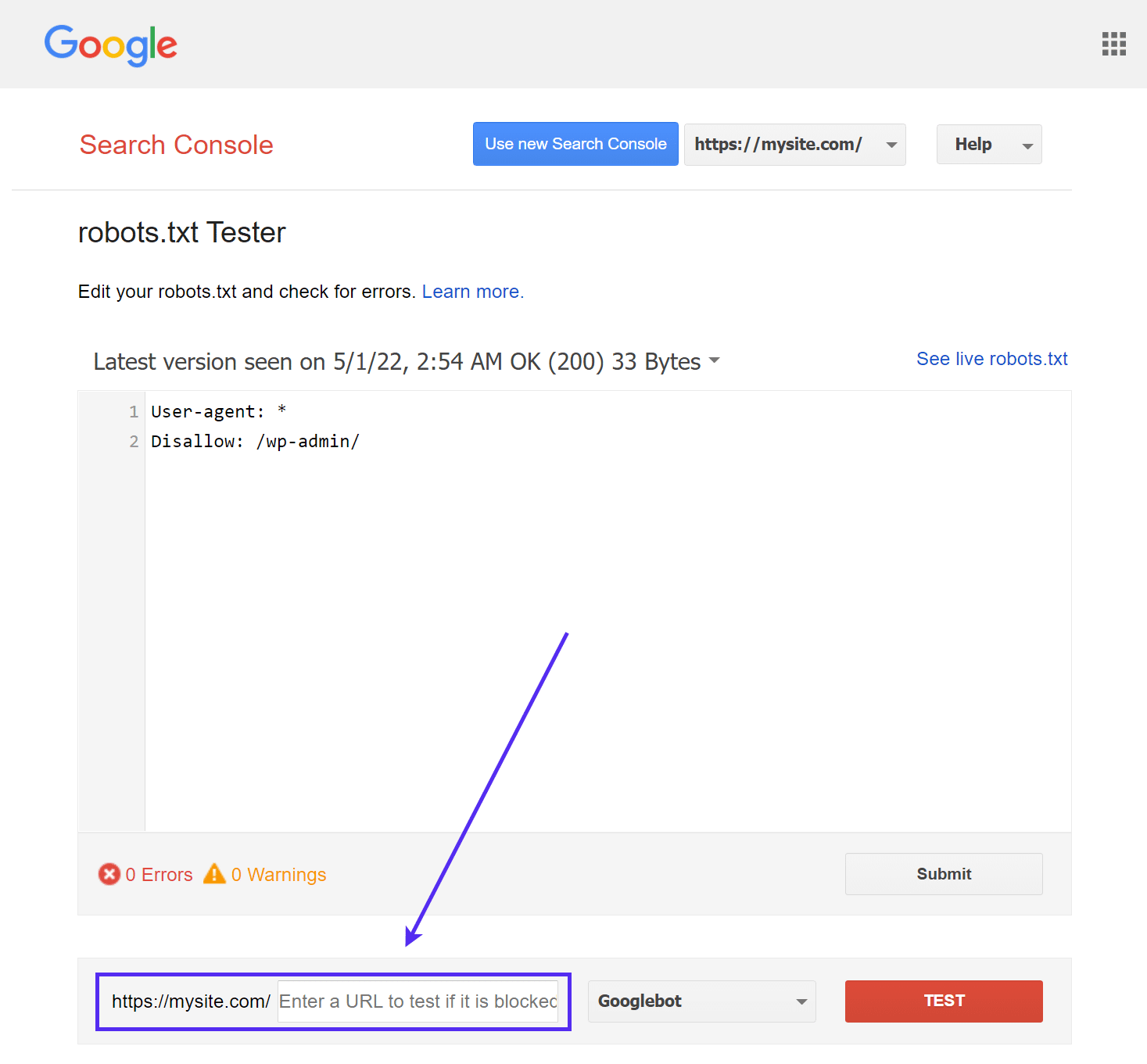
Você verá uma resposta “Allowed” em verde se tudo estiver permitido para rastreamento.
Você também pode selecionar com qual versão do Googlebot você gostaria de executar o teste, escolhendo do Googlebot, Googlebot-News, Googlebot-Image, Googlebot-Video, Googlebot-Mobile, Mediapartners-Google ou Adsbot-Google.
Você também poderia testar cada URL individual que você bloqueou para garantir que eles estão, de fato, bloqueados e/ou Disallowed.
Cuidado com a lista técnica UTF-8
BOM significa “byte order mark” e é basicamente um caractere invisível que às vezes é adicionado em arquivos por editores de texto antigos e similares. Se isso acontecer com o seu arquivo robots.txt, o Google pode não interpretá-lo corretamente. Por isso, é importante verificar seu arquivo em pesquisa de erros. Por exemplo, como visto abaixo, nosso arquivo tinha um caractere invisível e o Google reclama que a sintaxe não foi compreendida. Isso essencialmente invalida a primeira linha do nosso arquivo robots.txt, o que não é bom! Glenn Gabe tem um excelente artigo sobre como um BOM UTF-8 pode prejudicar seu SEO.

O Googlebot tem sua base principal nos Estados Unidos
Também é importante não bloquear o Googlebot a partir dos Estados Unidos, mesmo que você esteja visando uma região local fora dos Estados Unidos. Eles às vezes fazem o rastreamento local, mas o Googlebot é baseado principalmente nos Estados Unidos.
Googlebot is mostly US-based, but we also sometimes do local crawling. https://t.co/9KnmN4yXpe
— Google Search Central (@googlesearchc) November 13, 2017
O que os sites WordPress populares colocam em seu arquivo robots.txt
Para realmente fornecer algum contexto para os pontos listados acima, veja como alguns dos sites WordPress mais populares estão usando seus arquivos robots.txt.
TechCrunch
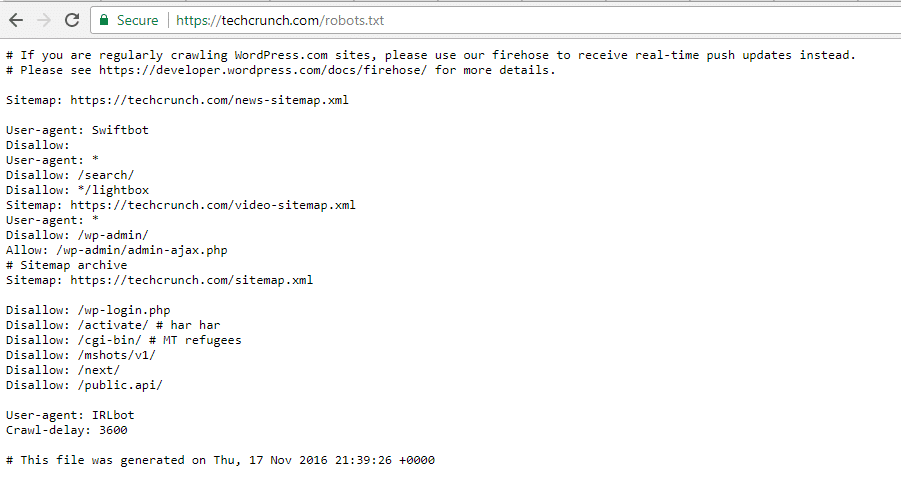
Além de restringir o acesso a várias páginas exclusivas, o TechCrunch especificamente desautoriza os rastreadores de:
- /wp-admin/
- /wp-login.php
Eles também estabelecem restrições especiais em dois bots:
- Swiftbot
- IRLbot
Caso você esteja interessado, IRLbot é um rastreador de um projeto de pesquisa da Universidade do Texas A&M. Isso é curioso!
The Obama Foundation
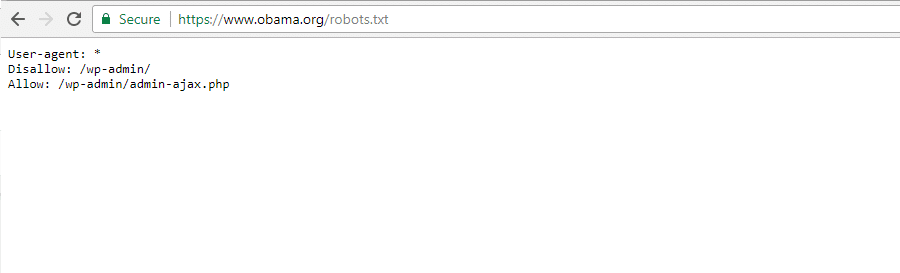
The Obama Foundation não fez nenhuma adição especial, optando exclusivamente por restringir o acesso ao /wp-admin/.
Angry Birds
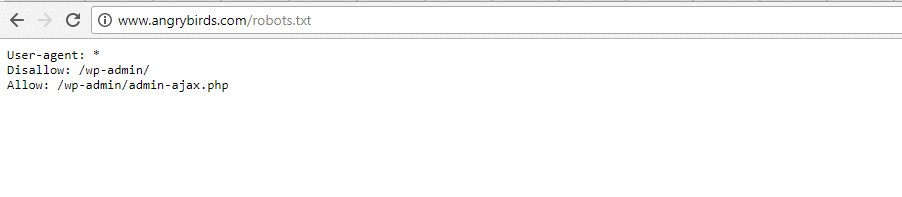
Angry Birds tem a mesma configuração padrão do Obama Foundation. Nada de especial é adicionado.
Drift

Finalmente, Drift opta por definir seus sitesmaps no arquivo Robots.txt, mas caso contrário, deixa as mesmas restrições padrão do Obama Foundation
e Angry Birds.
Use robots.txt corretamente
Conforme concluímos nosso guia sobre o arquivo robots.txt, queremos lembrar mais uma vez que usar o comando Disallow no arquivo robots.txt não é o mesmo que usar a tag noindex. O robots.txt bloqueia o rastreamento, mas não necessariamente a indexação. Você pode usá-lo para adicionar regras específicas para moldar como os mecanismos de pesquisa e outros bots interagem com seu site, mas ele não controlará explicitamente se seu conteúdo será indexado ou não.
Para a maioria dos usuários ocasionais do WordPress, não há uma necessidade urgente de modificar o arquivo virtual padrão robots.txt. Mas se você está tendo problemas com um bot específico, ou quer mudar como os mecanismos de pesquisa interagem com um determinado plugin ou tema que você está usando, você pode querer adicionar suas próprias regras.
Esperamos que você tenha gostado deste guia e certifique-se de deixar um comentário se você tiver qualquer outra dúvida sobre o uso do seu arquivo robots.txt no WordPress.

Brian tem uma enorme paixão pelo WordPress, e tem utilizado há mais de uma década e até desenvolve alguns plugins premium. Brian gosta de blogs, filmes e caminhadas. Conecte-se com Brian no Twitter.

