
Criar um site é o primeiro passo para construir sua presença na Internet. Para o sucesso a longo prazo, seu site também precisa estar pronto para o crescimento. E um dos primeiros passos é implementar um banco de dados escalável. Caso contrário, suas consultas do banco de dados terão um desempenho ruim e correm o risco de paralisar.
Este artigo descreve como usar a fragmentação de Banco de Dados (database sharding) para obter alta escalabilidade e disponibilidade de seus dados. Também discutimos as deficiências do sharding e as diferentes arquiteturas de sharding que você pode usar.
O que é fragmentação de banco de dados (Database Sharding?)
O Sharding é uma técnica de otimização que distribui tabelas por outros servidores de banco de dados. É como o particionamento no sentido de que ambos envolvem a divisão de dados em subconjuntos menores. A diferença é que o sharding distribui esses subconjuntos para servidores diferentes enquanto o particionamento os armazena em um único banco de dados. Estes servidores usam o mesmo mecanismo de banco de dados e tipo de hardware para alcançar um nível de desempenho similar para todos os fragmentos.
A fragmentação visa alcançar uma arquitetura sem compartilhamento, eliminando gargalos de processamento e pontos únicos de falha.
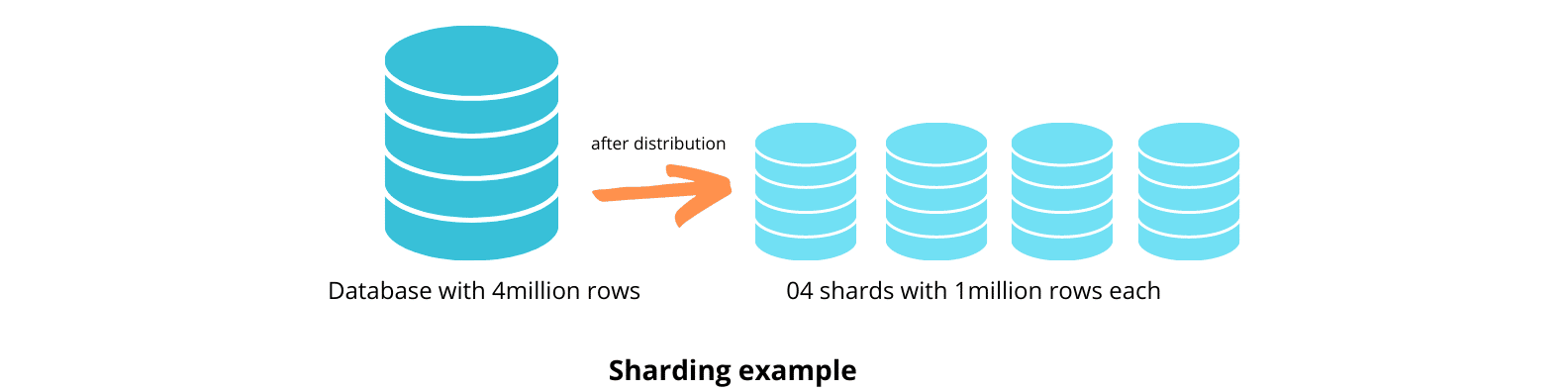
Você pode implementar a fragmentação de duas maneiras – horizontal e vertical. A fragmentação horizontal divide a tabela com base em linhas, enquanto a fragmentação vertical divide as tabelas com base em colunas.
A este respeito, a fragmentação é como a partição, que divide as tabelas grandes em tabelas menores.
A fragmentação horizontal é eficaz para bancos de dados onde a maioria das consultas retorna um subconjunto de linhas, como um banco de dados de clientes que retorna dados (como nome, endereço, e-mail e assim por diante) de uma só vez.
A fragmentação vertical é eficaz para bancos de dados cujas consultas retornam colunas únicas. Por exemplo, se o banco de dados do cliente retornasse o nome do cliente ou e-mail separadamente, você poderia separar o nome e e-mail em diferentes clusters.
Benefícios da fragmentação de banco de dados
Abaixo estão algumas das vantagens da fragmentação de banco de dados.
Melhorando a escalabilidade horizontal
Você pode escalar seu banco de dados verticalmente ou horizontalmente. A escalabilidade vertical refere-se à adição de CPUs (unidades centrais de processamento) e RAMs (memória de acesso aleatório) a um servidor para melhorar o desempenho. A escalabilidade vertical é uma solução útil para bancos de dados pequenos e médios. Entretanto, conforme seus dados crescem, a escalabilidade vertical se torna impraticável. Não há muita potência que possa ser adicionada a um único servidor.
A escalabilidade horizontal é mais flexível. Ele permite que você escale seu banco de dados conforme necessário, adicionando mais servidores ao seu sistema. Cada um desses servidores fornece recursos para diferentes fragmentos de banco de dados. Isso distribui a carga de trabalho e melhora a capacidade do sistema de lidar com mais solicitações.
Tempos de resposta mais rápidos para consultas
Os fragmentos têm apenas algumas filas e colunas. Por causa disso, leva menos tempo para processar as consultas do banco de dados. Por outro lado, as consultas em bancos de dados não fragmentados podem precisar recuperar centenas ou milhares de linhas.
Maior confiabilidade em caso de interrupções de serviço
Falhas no banco de dados acontecem por várias razões, incluindo exclusão acidental de dados, erros de conexão e ataques cibernéticos de segurança. A fragmentação minimiza os efeitos das interrupções. Como cada fragmento é autônomo, apenas o fragmento afetado enfrenta o tempo de inatividade. Por exemplo, se você tiver quatro fragmentos e experimentar uma interrupção em um deles, apenas 25% das operações serão afetadas.
Desvantagens da fragmentação
Embora a fragmentação melhore a confiabilidade e a disponibilidade de um banco de dados, sua implementação é complexa. Usar a arquitetura de fragmentação errada pode diminuir o desempenho e levar à perda de dados.
Certifique-se de escolher um método de fragmentação que permita distribuir os dados uniformemente em todos os fragmentos. Sem este equilíbrio, você arrisca criar hotspots de banco de dados, que acontecem quando um fragmento armazena a maioria dos dados enquanto outros fragmentos permanecem praticamente vazios. Isso reduz o rendimento de gravação para o único fragmento.
Para corrigir isso, você pode dividir ainda mais os fragmentos desequilibrados, mas esse processo é desafiador e pode derrubar seu banco de dados enquanto você migra os dados.
Outra desvantagem da fragmentação é que as uniões SQL envolvendo múltiplas tabelas em diferentes fragmentos podem se tornar muito lentas e degradar o desempenho. No entanto, com uma arquitetura adequada, esse problema pode ser evitado.
Arquiteturas de fragmentação
Você pode implementar a fragmentação usando três arquiteturas:
- Fragmentação com base em chave
- Fragmentação com base no alcance
- Fragmentação com base em diretórios
A arquitetura que você escolher depende do seu caso de uso.
Fragmentação com base em chave
Em uma arquitetura de fragmentação baseada em chave ou hashed, um aplicativo de banco de dados usa uma chave de fragmento para localizar um fragmento. Uma função de hashing tem o valor da chave de fragmentação, e a saída mapeia os dados para um fragmento em particular. Uma simples função de hashing pode ser o módulo da chave e o número de fragmentos.
A função hash pode levar mais de uma chave de fragmentação. Por causa disso, a fragmentação com base em chaves é adequado para registros de dados que podem ter chaves compartilhadas. A distribuição algorítmica dos dados minimiza a possibilidade de criar hotspots de banco de dados onde um fragmento contém mais dados do que o outro.
Entretanto, como a distribuição depende apenas da função hashing, é impossível agrupar os dados logicamente. Portanto, operações de banco de dados que requerem dados de múltiplos fragmentos podem ser ineficientes, pois requerem a leitura de dados de cada fragmento.
Fragmentação com base no alcance
A fragmentação com base no alcance envolve a fragmentação de um banco de dados dependendo de uma faixa específica de valores.
Ele usa uma chave de fragmentação para determinar a que fragmento atribuir um valor. O aplicativo de banco de dados verifica o fragmento que corresponde à chave de fragmentação em uma tabela de pesquisa e armazena os dados. Por causa disso, o fragmento baseado na faixa é fácil de projetar e implementar.
Por exemplo, você poderia usar o valor de identificação do usuário em um banco de dados de usuários como a chave de fragmentação. Você poderia armazenar usuários com IDs de 0-2,000 em um fragmento, aqueles entre 2,000 e 4,000 em outro fragmento, e assim por diante.
A fragmentação com base no alcance pode causar hotspots de banco de dados. Considere um banco de dados de usuários no qual a maioria de seus IDs de usuário esteja entre 2.001 e 4.000. O processo os atribui a um único fragmento, criando um desequilíbrio ao longo do tempo. Portanto, o fragmento baseado em faixa funciona melhor para dados distribuídos uniformemente.
Fragmentação com base em diretórios
Grupos de fragmentação com base em diretórios relacionam logicamente os dados na mesma fragmentação. Ele usa uma tabela de pesquisa contendo uma lista de mapeamentos para cada entidade no banco de dados. Cada mapeamento corresponde a um fragmento do banco de dados.
Fragmentação com base diretórios é mais flexível do que o sharding baseado em alcance ou baseado em chaves porque você pode adicionar dados aos fragmentos dinamicamente. Não há nenhuma função de fragmentação a ser seguida ou valores de faixa a serem mantidos dentro. Esta flexibilidade aumenta a eficiência da base de dados: Você pode armazenar dados relacionados em um fragmento, o que significa que a execução de consultas comuns leva menos tempo.
Por exemplo, se você usou fragmentos baseados em diretórios e agrupou usuários de acordo com sua localização, recuperando usuários de um determinado lugar, você só consulta um único fragmento.
Fragmentação de banco de dados com a Kinsta
A maioria dos modernos mecanismo de banco de dados fornecem suporte para a fragmentação de banco de dados. Um desses mecanismos de banco de dados é o MariaDB, um fork comercialmente suportado do MySQL. É um sistema de banco de dados de código aberto de alto desempenho adotado por empresas como IBM, GitHub, e Wikimedia. Ele também faz parte da pilha de servidores de alta performance na Kinsta.
MariaDB oferece recursos de fragmentação incorporados através do mecanismo de armazenamento spider. O mecanismo de armazenamento spider (Spider Storage Engine) é um mecanismo de formação de clusters que suporta transações de partição e arquitetura estendida (XA). Ele permite que você trate tabelas remotas de diferentes instâncias como se elas estivessem na mesma instância. Uma vez que você cria uma tabela no mecanismo de armazenamento spider, a tabela se liga a outra tabela no servidor remoto MariaDB. Uma vez estabelecida a conexão, o mecanismo de armazenamento compartilha o link com todas as tabelas que fazem parte da mesma transação.
Resumo
A fragmentação de banco de dados é uma técnica de escalonamento que divide as tabelas em subconjuntos menores e as distribui para diferentes servidores chamados shards. Você pode implementar a fragmentação através de vários meios, como a fragmentação com base em chave, a fragmentação com base no alcance e a fragmentação com base em diretórios.
Enquanto a fragmentação melhora a escalabilidade, confiabilidade e disponibilidade de um banco de dados, é muito complexo de ser implementado. Além disso, uma vez criado um fragmento, não é fácil devolver o banco de dados a seu estado não fragmentado. Por causa disso, use o fragmento para otimização somente quando você estiver certo de que outras opções de escalabilidade não funcionarão.
Quer o seu negócio seja uma organização sem fins lucrativos ou uma organização de nível empresarial, as soluções profissionais da Kinsta podem tirar as preocupações de hospedagem do seu site para que você possa se concentrar no que mais importa.

Salman Ravoof é um desenvolvedor web autodidata, escritor, criador e grande admirador de Software Livre e de Código Aberto (FOSS). Além de tecnologia, ele se entusiasma com ciência, filosofia, fotografia, artes, gatos e comida. Saiba mais sobre ele em seu site e conecte-se com Salman no X.

