
Att skapa en webbplats är det första steget i byggandet av en närvaro på Internet. För att lyckas på längre sikt så måste du även se till att din webbplats kan anpassas för att klara av att växa. Ett av de första stegen är att implementera en databas som kan skalas med dig. Annars så riskerar du att drabbas av långsamma sökresultat och databasavbrott.
I det här inlägget så diskuterar vi hur du kan använda databas-sharding för att uppnå hög skalbarhet och tillgänglighet för dina data. Vi kommer även att beröra nackdelarna med sharding och de olika sharding-arkitekturerna som du kan använda.
Vad är databas-sharding?
Sharding är en optimeringsteknik som distribuerar tabeller över andra databasservrar. Det påminner om partitionering i den meningen att båda innebär att data delas upp i mindre delmängder. Skillnaden är att sharding distribuerar dessa delmängder till olika servrar medan partitionering lagrar dem i en och samma databas. Dessa servrar använder samma databasmotor och hårdvarutyp för att uppnå en liknande prestandanivå för alla shards.
Sharding syftar till att åstadkomma en arkitektur som inte delar något, vilket eliminerar flaskhalsar i bearbetningen och enstaka felpunkter.
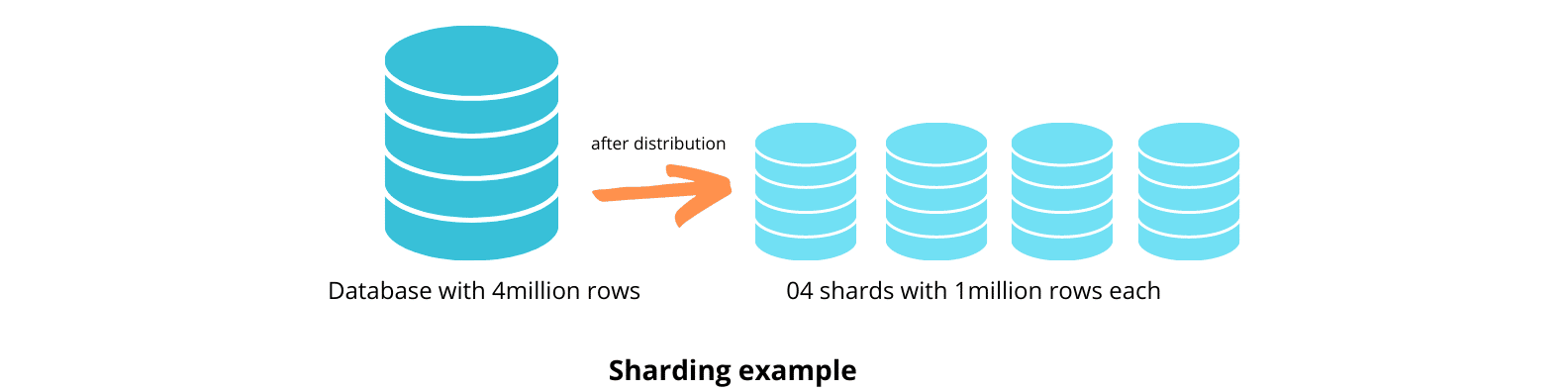
Du kan implementera sharding på två sätt – horisontellt och vertikalt. Horisontell sharding delar upp tabellen utifrån rader, medan vertikal sharding delar upp tabellerna utifrån kolumner.
I det här avseendet så är sharding som partitionering, som delar upp stora tabeller i mindre tabeller.
Horisontell sharding är effektivt för databaser där de flesta frågor returnerar en delmängd av rader. Detta kan exempelvis vara en kunddatabas som returnerar data (som namn, adress, e-post och så vidare) på samma gång.
Vertikal sharding är effektiv för databaser där förfrågningar returnerar enstaka kolumner. Om kunddatabasen exempelvis returnerar kundens namn eller e-post separat så kan du separera namn och e-post i olika kluster.
Fördelar med databas-sharding
Nedan följer några av fördelarna med databas-sharding.
Förbättrad horisontell skalning
Du kan skala din databas vertikalt eller horisontellt. Vertikal skalning innebär att man lägger till fler centrala processorenheter (CPU) och RAM-minne (Random Access Memory) till servern för att förbättra prestandan. Vertikal skalning är en bra lösning för små och medelstora databaser. När data växer blir vertikal skalning dock ogenomförbar. Det finns endast en viss mängd kraft som du kan lägga till i en enda server.
Horisontell skalning är mer flexibel. Den gör att du kan skala din databas efter behov genom att lägga till fler servrar i systemet. Var och en av dessa servrar tillhandahåller resurser till olika databasdelar. Detta fördelar arbetsbelastningen och förbättrar systemets förmåga att hantera fler förfrågningar.
Snabbare svarstider för förfrågningar
Shards har endast ett fåtal rader och kolumner. Tack vare detta så tar det mindre tid att bearbeta databasfrågor. En förfrågan i en icke-omvandlad databas kan kräva en sökning genom hundratals – eller till och med tusentals – rader.
Ökad tillförlitlighet vid avbrottssituationer
Databasavbrott inträffar av olika anledningar. Dett kan exempelvis ske genom oavsiktlig radering av data, anslutningsfel och cybersäkerhetsattacker. Sharding minimerar effekterna av avbrott. Eftersom varje shard är självständig så är det bara den berörda sharden som drabbas av driftstopp. Om du exempelvis har fyra shards och ett av dem drabbas av ett avbrott så kommer endast 25 procent av verksamheten att påverkas.
Nackdelar med Sharding
Även om sharding förbättrar databasens tillförlitlighet och tillgänglighet så är det komplicerat att implementera detta. Om man använder fel sharding-arkitektur så kan det sänka prestandan och leda till dataförluster.
Var noga med att välja en sharding-teknik som tillåter en balanserad datafördelning över alla shards. Utan denna balans så riskerar du att skapa databas-hotspots, vilket sker när en enda shard lagrar mest data medan andra shards förblir praktiskt taget tomma. Detta minskar skrivgenomströmningen till den enskilda sharden.
För att lösa detta så kan du partitionera den obalanserade sharden ytterligare, men den processen är utmanande och kan ta ner databasen medan du migrerar din data.
En annan nackdel med sharding är att SQL joins som involverar flera tabeller i olika shards kan bli för långsamma och försämra prestandan. Med rätt arkitektur så kan du dock undvika detta problem.
Arkitekturer för sharding
Du kan implementera sharding med hjälp av tre arkitekturer:
- Nyckelbaserad delning
- Räckviddsbaserad delning
- Katalogbaserad delning
Vilken arkitektur som du väljer beror på ditt användningsområde.
Nyckelbaserad delning
I en nyckel- eller hashed-baserad sharding-arkitektur så använder ett databasprogram en shardnyckel för att hitta en shard. En hash-funktion hasherar sharding-nyckelvärdet och resultatet mappar data till en viss shard. En enkel hash-funktion kan vara modulus av nyckeln och antalet shards.
Hash-funktionen kan ta emot mer än en nyckel för delning. På grund av detta så är nyckelbaserad sharding lämplig för dataposter som kan ha delade nycklar. Algoritmisk fördelning av data minimerar möjligheten att skapa databas-hotspots där en shard innehåller mer data än den andra.
Eftersom fördelningen endast bygger på hash-funktionen så är det dock omöjligt att logiskt gruppera data tillsammans. Av den anledningen så kan databasoperationer som kräver data från flera shards vara ineffektiva eftersom de kräver läsning av data från varje shard.
Intervallbaserad sharding
Intervallbaserad sharding innebär att en databas delas upp beroende på ett visst intervall av värden.
En nyckel för delningen används för att avgöra vilken delning som ett värde ska tilldelas. Databasprogrammet kontrollerar den shard som motsvarar sharding-nyckeln i en uppslagstabell och lagrar uppgifterna. Tack vare detta så är intervallbaserad sharding lätt att utforma och implementera.
Du kan exempelvis nyttja användar ID-värdet som sharding-nyckel i en användardatabas. Du kan lagra användare med ID-uppgifter från 0-2 000 i en shard, användare med ID-uppgifter mellan 2 000 och 4 000 i en annan shard och så vidare.
Intervallbaserad sharding kan orsaka hotspots i databasen. Tänk på en användardatabas där de flesta användar-ID:n ligger mellan 2 001 och 4 000. Processen tilldelar dem till en enda shard, vilket skapar obalans med tiden. Intervallbaserad sharding fungerar därför bäst för jämnt fördelad data.
Katalogbaserad delning
Katalogbaserad sharding grupperar logiskt relaterade data i samma shard. Den använder en uppslagstabell som innehåller en lista över mappningar för varje enhet i databasen. Varje mappning motsvarar en databasdel.
Katalogbaserad sharding är mer flexibel än intervallbaserad eller nyckelbaserad sharding eftersom du kan lägga till data till shards dynamiskt. Det finns ingen sharding-funktion att följa eller några intervallvärden att hålla sig inom. Den här flexibiliteten ökar databasens effektivitet: Du kan lagra relaterade data i en shard, vilket innebär att det tar mindre tid att utföra vanliga sökfrågor.
Om du exempelvis skulle använda katalogbaserad sharding och gruppera användare enligt deras plats, och hämta användare från en viss plats, så skulle du endast fråga efter en enda shard.
Databasdelning med Kinsta
De flesta moderna databasmotorer har stöd för databas-sharding. En av dessa databasmotorer är MariaDB, en kommersiellt stödd förgrening av MySQL. Det är ett högpresterande databassystem med öppen källkod som används av företag som IBM, GitHub och Wikimedia. Det är även en del av den högpresterande serverstacken på Kinsta.
MariaDB erbjuder inbyggda sharding-funktioner genom spider storage engine. Spider Storage Engine är en klusterbildningsmotor som stöder partitionering och XA-transaktioner (Extended Architecture). Den gör det möjligt att behandla fjärrtabeller från olika instanser som om de befann sig i samma instans. När du har skapat en tabell i spider storage engine så länkar tabellen till en annan tabell i den fjärrbaserade MariaDB-servern. När anslutningen har upprättats så delar lagringsmotorn länken med alla tabeller som ingår i samma transaktion.
Sammanfattning
Databas-sharding är en skalningsteknik som delar upp tabeller i mindre delmängder och distribuerar dem till olika servrar som kallas shards. Du kan implementera sharding på olika sätt, t.ex. nyckelbaserad sharding, intervallbaserad sharding och katalogbaserad sharding.
Även om sharding förbättrar en databas skalbarhet, tillförlitlighet och tillgänglighet så är detta mycket komplicerat att implementera. När du väl har skapat en shard så är det dessutom inte lätt att återställa databasen till det icke-shardade tillståndet. På grund av detta så ska du använda sharding för optimering endast när du är säker på att andra skalbarhetsalternativ inte fungerar.
Oavsett om din verksamhet är en ideell verksamhet eller ett företag på enterprise-nivå så kan Kinsta’s expertlösningar ta bort dina bekymmer med webbplatshanteringen så att du kan fokusera på det som är viktigast.

Salman Ravoof är en självlärd webbutvecklare, författare, skapare och en stor beundrare av fri och öppen källkod (FOSS). Förutom teknik är han intresserad av vetenskap, filosofi, fotografi, konst, katter och mat. Lär dig mer om honom på hans hemsida och kontakta Salman på X.

