
Seitdem sich die Kameras verbessert haben, ist die Objekterkennung in Echtzeit zu einer immer gefragteren Funktion geworden. Von selbstfahrenden Autos über intelligente Überwachungssysteme bis hin zu Augmented-Reality-Anwendungen wird diese Technologie in vielen Situationen eingesetzt.
Computer Vision, ein schicker Begriff für die Technologie, die Kameras mit Computern nutzt, um die oben genannten Aufgaben zu erfüllen, ist ein weites und kompliziertes Feld. Vielleicht weißt du aber nicht, dass du mit der Objekterkennung in Echtzeit ganz einfach von deinem Browser aus loslegen kannst.
In diesem Artikel erfährst du, wie du mit React eine Anwendung zur Echtzeit-Objekterkennung erstellst und sie auf Kinsta bereitstellst. Die Echtzeit-Objekterkennungs-Anwendung nutzt den Webcam-Feed des Nutzers.
Voraussetzungen
Hier eine Übersicht über die wichtigsten Technologien, die in diesem Leitfaden verwendet werden:
- React: React wird verwendet, um die Benutzeroberfläche (UI) der Anwendung zu erstellen. React eignet sich hervorragend für das Rendern dynamischer Inhalte und wird bei der Darstellung des Webcam-Feeds und der erkannten Objekte im Browser nützlich sein.
- TensorFlow.js: TensorFlow.js ist eine JavaScript-Bibliothek, die die Möglichkeiten des maschinellen Lernens in den Browser bringt. Sie ermöglicht es dir, trainierte Modelle für die Objekterkennung zu laden und direkt im Browser auszuführen, sodass keine komplexe serverseitige Verarbeitung erforderlich ist.
- Coco SSD: Die Anwendung verwendet ein vortrainiertes Objekterkennungsmodell namens Coco SSD, ein leichtgewichtiges Modell, das in der Lage ist, eine Vielzahl von Alltagsgegenständen in Echtzeit zu erkennen. Coco SSD ist zwar ein leistungsfähiges Werkzeug, aber es ist wichtig zu wissen, dass es auf einem allgemeinen Datensatz von Objekten trainiert wurde. Wenn du spezielle Anforderungen an die Erkennung hast, kannst du ein eigenes Modell mit TensorFlow.js trainieren, indem du diese Anleitung befolgst.
Richte ein neues React-Projekt ein
- Erstelle ein neues React-Projekt. Dazu führst du den folgenden Befehl aus:
npm create vite@latest kinsta-object-detection --template reactDadurch wird mit vite ein React-Basisprojekt für dich erstellt.
- Als Nächstes installierst du die TensorFlow- und Coco SSD-Bibliotheken, indem du die folgenden Befehle im Projekt ausführst:
npm i @tensorflow-models/coco-ssd @tensorflow/tfjs
Jetzt kannst du mit der Entwicklung deiner Anwendung beginnen.
Konfigurieren der Anwendung
Bevor du den Code für die Objekterkennungslogik schreibst, solltest du verstehen, was in diesem Leitfaden entwickelt wird. So würde die Benutzeroberfläche der Anwendung aussehen:
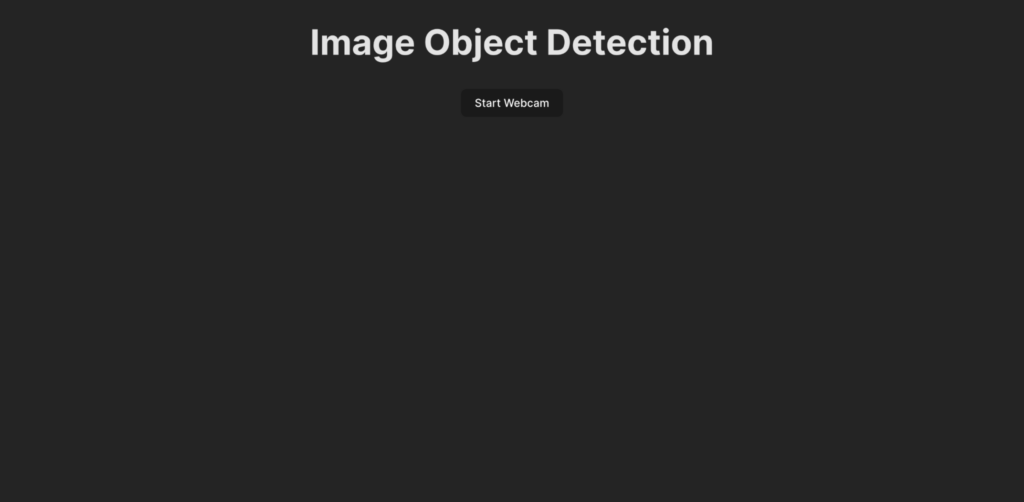
Wenn ein Nutzer auf die Schaltfläche Webcam starten klickt, wird er aufgefordert, der Anwendung den Zugriff auf den Webcam-Feed zu gestatten. Wenn die Erlaubnis erteilt wurde, zeigt die Anwendung den Webcam-Feed an und erkennt Objekte im Feed. Anschließend zeigt sie die erkannten Objekte im Live-Feed in einem Kasten an und versieht ihn mit einer Beschriftung.
Erstelle zunächst die Benutzeroberfläche für die Anwendung, indem du den folgenden Code in die Datei App.jsx einfügst:
import ObjectDetection from './ObjectDetection';
function App() {
return (
<div className="app">
<h1>Image Object Detection</h1>
<ObjectDetection />
</div>
);
}
export default App;Dieser Codeschnipsel legt eine Kopfzeile für die Seite fest und importiert eine benutzerdefinierte Komponente namens ObjectDetection. Diese Komponente enthält die Logik für die Erfassung des Webcam-Feeds und die Erkennung von Objekten in Echtzeit.
Um diese Komponente zu erstellen, erstelle eine neue Datei namens ObjectDetection.jsx in deinem src-Verzeichnis und füge den folgenden Code darin ein:
import { useEffect, useRef, useState } from 'react';
const ObjectDetection = () => {
const videoRef = useRef(null);
const [isWebcamStarted, setIsWebcamStarted] = useState(false)
const startWebcam = async () => {
// TODO
};
const stopWebcam = () => {
// TODO
};
return (
<div className="object-detection">
<div className="buttons">
<button onClick={isWebcamStarted ? stopWebcam : startWebcam}>{isWebcamStarted ? "Stop" : "Start"} Webcam</button>
</div>
<div className="feed">
{isWebcamStarted ? <video ref={videoRef} autoPlay muted /> : <div />}
</div>
</div>
);
};
export default ObjectDetection;Der obige Code definiert eine HTML-Struktur mit einer Schaltfläche zum Starten und Stoppen des Webcam-Feeds und einem <video> Element, das verwendet wird, um dem Benutzer den Webcam-Feed zu zeigen, sobald er aktiv ist. Ein Statuscontainer isWebcamStarted wird verwendet, um den Status des Webcam-Feeds zu speichern. Zwei Funktionen, startWebcam und stopWebcam, werden zum Starten und Stoppen des Webcam-Feeds verwendet. Definieren wir sie:
Hier ist der Code für die Funktion startWebcam:
const startWebcam = async () => {
try {
setIsWebcamStarted(true)
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
if (videoRef.current) {
videoRef.current.srcObject = stream;
}
} catch (error) {
setIsWebcamStarted(false)
console.error('Error accessing webcam:', error);
}
};Diese Funktion fordert den Benutzer auf, den Webcam-Zugang zu gewähren. Sobald die Erlaubnis erteilt wurde, wird die <video> so eingestellt, dass sie dem Benutzer den Live-Webcam-Feed zeigt.
Wenn der Code nicht auf den Webcam-Feed zugreifen kann (z. B. weil auf dem aktuellen Gerät keine Webcam vorhanden ist oder dem Benutzer die Erlaubnis verweigert wird), gibt die Funktion eine Meldung auf der Konsole aus. Du kannst einen Fehlerblock verwenden, um dem Benutzer den Grund für den Fehler anzuzeigen.
Ersetze als Nächstes die Funktion stopWebcam durch den folgenden Code:
const stopWebcam = () => {
const video = videoRef.current;
if (video) {
const stream = video.srcObject;
const tracks = stream.getTracks();
tracks.forEach((track) => {
track.stop();
});
video.srcObject = null;
setPredictions([])
setIsWebcamStarted(false)
}
};Dieser Code prüft die laufenden Videostreams, auf die das Objekt <video> zugreift, und stoppt jeden einzelnen davon. Zum Schluss setzt er den Status von isWebcamStarted auf false.
Versuche nun, die Anwendung zu starten, um zu prüfen, ob du auf den Webcam-Feed zugreifen und ihn ansehen kannst.
Füge den folgenden Code in die Datei index.css ein, um sicherzustellen, dass die Anwendung genauso aussieht wie in der Vorschau, die du vorhin gesehen hast:
#root {
font-family: Inter, system-ui, Avenir, Helvetica, Arial, sans-serif;
line-height: 1.5;
font-weight: 400;
color-scheme: light dark;
color: rgba(255, 255, 255, 0.87);
background-color: #242424;
min-width: 100vw;
min-height: 100vh;
font-synthesis: none;
text-rendering: optimizeLegibility;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
a {
font-weight: 500;
color: #646cff;
text-decoration: inherit;
}
a:hover {
color: #535bf2;
}
body {
margin: 0;
display: flex;
place-items: center;
min-width: 100vw;
min-height: 100vh;
}
h1 {
font-size: 3.2em;
line-height: 1.1;
}
button {
border-radius: 8px;
border: 1px solid transparent;
padding: 0.6em 1.2em;
font-size: 1em;
font-weight: 500;
font-family: inherit;
background-color: #1a1a1a;
cursor: pointer;
transition: border-color 0.25s;
}
button:hover {
border-color: #646cff;
}
button:focus,
button:focus-visible {
outline: 4px auto -webkit-focus-ring-color;
}
@media (prefers-color-scheme: light) {
:root {
color: #213547;
background-color: #ffffff;
}
a:hover {
color: #747bff;
}
button {
background-color: #f9f9f9;
}
}
.app {
width: 100%;
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
}
.object-detection {
width: 100%;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
.buttons {
width: 100%;
display: flex;
justify-content: center;
align-items: center;
flex-direction: row;
button {
margin: 2px;
}
}
div {
margin: 4px;
}
}Entferne außerdem die Datei App.css, damit die Stile der Komponenten nicht durcheinander geraten. Jetzt kannst du die Logik für die Integration der Echtzeit-Objekterkennung in deiner Anwendung schreiben.
Echtzeit-Objekterkennung einrichten
- Beginne damit, die Importe für Tensorflow und Coco SSD oben in ObjectDetection.jsx hinzuzufügen:
import * as cocoSsd from '@tensorflow-models/coco-ssd'; import '@tensorflow/tfjs'; - Als Nächstes erstellst du einen Status in der Komponente
ObjectDetection, um das Array der Vorhersagen zu speichern, die vom Coco SSD-Modell erstellt wurden:const [predictions, setPredictions] = useState([]); - Als Nächstes erstellst du eine Funktion, die das Coco SSD-Modell lädt, den Video-Feed sammelt und die Vorhersagen erstellt:
const predictObject = async () => { const model = await cocoSsd.load(); model.detect(videoRef.current).then((predictions) => { setPredictions(predictions); }) .catch(err => { console.error(err) }); };Diese Funktion verwendet den Video-Feed und erstellt Vorhersagen für die im Feed enthaltenen Objekte. Sie liefert dir ein Array mit den vorhergesagten Objekten, die jeweils ein Label, einen Konfidenzgrad und eine Reihe von Koordinaten enthalten, die die Position des Objekts im Videobild angeben.
Du musst diese Funktion fortlaufend aufrufen, um die eintreffenden Videobilder zu verarbeiten, und dann die im Status
predictionsgespeicherten Vorhersagen verwenden, um Kästchen und Beschriftungen für jedes erkannte Objekt im Live-Videofeed anzuzeigen. - Als Nächstes musst du die Funktion
setIntervalverwenden, um die Funktion kontinuierlich aufzurufen. Du musst auch dafür sorgen, dass diese Funktion nicht mehr aufgerufen wird, nachdem der Nutzer den Webcam-Feed gestoppt hat.clearIntervalFüge den folgenden Zustandscontainer und denuseEffect-Hook in die KomponenteObjectDetectionein, um die FunktionpredictObjectso einzurichten, dass sie kontinuierlich aufgerufen wird, wenn die Webcam aktiviert ist, und entfernt wird, wenn die Webcam deaktiviert wird:const [detectionInterval, setDetectionInterval] = useState() useEffect(() => { if (isWebcamStarted) { setDetectionInterval(setInterval(predictObject, 500)) } else { if (detectionInterval) { clearInterval(detectionInterval) setDetectionInterval(null) } } }, [isWebcamStarted])Damit wird die Anwendung so eingestellt, dass sie alle 500 Millisekunden die Objekte vor der Webcam erkennt. Du kannst diesen Wert ändern, je nachdem, wie schnell die Objekterkennung sein soll, aber bedenke, dass eine zu häufige Ausführung dazu führen kann, dass deine Anwendung viel Speicherplatz im Browser verbraucht.
- Jetzt, da du die Vorhersagedaten im Container
predictionhast, kannst du sie verwenden, um eine Beschriftung und einen Rahmen um das Objekt im Live-Video-Feed anzuzeigen. Dazu aktualisierst du die AnweisungreturnderObjectDetectionso, dass sie Folgendes zurückgibt:return ( <div className="object-detection"> <div className="buttons"> <button onClick={isWebcamStarted ? stopWebcam : startWebcam}>{isWebcamStarted ? "Stop" : "Start"} Webcam</button> </div> <div className="feed"> {isWebcamStarted ? <video ref={videoRef} autoPlay muted /> : <div />} {/* Add the tags below to show a label using the p element and a box using the div element */} {predictions.length > 0 && ( predictions.map(prediction => { return <> <p style={{ left: `${prediction.bbox[0]}px`, top: `${prediction.bbox[1]}px`, width: `${prediction.bbox[2] - 100}px` }}>{prediction.class + ' - with ' + Math.round(parseFloat(prediction.score) * 100) + '% confidence.'}</p> <div className={"marker"} style={{ left: `${prediction.bbox[0]}px`, top: `${prediction.bbox[1]}px`, width: `${prediction.bbox[2]}px`, height: `${prediction.bbox[3]}px` }} /> </> }) )} </div> {/* Add the tags below to show a list of predictions to user */} {predictions.length > 0 && ( <div> <h3>Predictions:</h3> <ul> {predictions.map((prediction, index) => ( <li key={index}> {`${prediction.class} (${(prediction.score * 100).toFixed(2)}%)`} </li> ))} </ul> </div> )} </div> );Dies rendert eine Liste von Vorhersagen direkt unter dem Webcam-Feed und zeichnet einen Rahmen um das vorhergesagte Objekt mit den Koordinaten von Coco SSD sowie eine Beschriftung am oberen Rand des Rahmens.
- Um die Boxen und die Beschriftung richtig zu gestalten, füge den folgenden Code in die Datei index.css ein:
.feed { position: relative; p { position: absolute; padding: 5px; background-color: rgba(255, 111, 0, 0.85); color: #FFF; border: 1px dashed rgba(255, 255, 255, 0.7); z-index: 2; font-size: 12px; margin: 0; } .marker { background: rgba(0, 255, 0, 0.25); border: 1px dashed #fff; z-index: 1; position: absolute; } }Damit ist die Entwicklung der Anwendung abgeschlossen. Du kannst jetzt den Dev-Server neu starten, um die Anwendung zu testen. So sollte sie nach der Fertigstellung aussehen:

Demo der Echtzeit-Objekterkennung mit der Webcam
Den vollständigen Code findest du in diesem GitHub-Repository.
Die fertige Anwendung auf Kinsta bereitstellen
Im letzten Schritt musst du die Anwendung auf Kinsta bereitstellen, um sie für deine Nutzer/innen verfügbar zu machen. Dazu kannst du bei Kinsta bis zu 100 statische Websites kostenlos direkt von deinem bevorzugten Git-Anbieter (Bitbucket, GitHub oder GitLab) hosten.
Sobald dein Git-Repository fertig ist, befolge diese Schritte, um deine Objekterkennungs-Anwendung auf Kinsta bereitzustellen:
- Logge dich ein oder erstelle ein Konto, um dein MyKinsta-Dashboard zu sehen.
- Autorisiere Kinsta mit deinem Git-Anbieter.
- Klicke in der linken Seitenleiste auf Statische Websites und dann auf Website hinzufügen.
- Wähle das Repository und den Zweig aus, von dem aus du bereitstellen möchtest.
- Gib deiner Website einen eindeutigen Namen.
- Füge die Build-Einstellungen in folgendem Format hinzu:
- Build-Befehl:
yarn buildodernpm run build - Node-Version:
20.2.0 - Verzeichnis veröffentlichen:
dist
- Build-Befehl:
- Zum Schluss klickst du auf Site erstellen.
Sobald die Anwendung bereitgestellt ist, kannst du im Dashboard auf Website besuchen klicken, um auf die Anwendung zuzugreifen. Jetzt kannst du die Anwendung auf verschiedenen Geräten mit Kameras ausprobieren, um zu sehen, wie sie sich verhält.
Als Alternative zum Statischen-Seiten-Hosting kannst du deine statische Website auch mit dem Anwendungs-Hosting von Kinsta bereitstellen, das eine größere Hosting-Flexibilität, eine breitere Palette von Vorteilen und Zugang zu robusteren Funktionen bietet. Dazu gehören z. B. Skalierbarkeit, benutzerdefinierte Bereitstellung mithilfe eines Dockerfiles und umfassende Analysen, die Echtzeit- und historische Daten umfassen.
Zusammenfassung
Du hast erfolgreich eine Echtzeit-Anwendung zur Objekterkennung mit React, TensorFlow.js und Kinsta erstellt. Damit kannst du die aufregende Welt der Computer Vision erkunden und interaktive Erlebnisse direkt im Browser des Nutzers schaffen.
Denk daran, dass das von uns verwendete Coco SSD-Modell nur ein Ausgangspunkt ist. Wenn du weiter forschst, kannst du mit TensorFlow.js in die benutzerdefinierte Objekterkennung eintauchen und die Anwendung so anpassen, dass sie bestimmte Objekte erkennt, die für deine Bedürfnisse relevant sind.
Die Möglichkeiten sind vielfältig! Diese Anwendung dient als Grundlage, um detailliertere Anwendungen wie Augmented Reality oder intelligente Überwachungssysteme zu entwickeln. Wenn du deine Anwendung auf der zuverlässigen Plattform von Kinsta bereitstellst, kannst du deine Kreation mit der Welt teilen und erleben, wie die Macht der Computer Vision zum Leben erweckt wird.
Auf welches Problem bist du gestoßen, von dem du denkst, dass die Echtzeit-Objekterkennung es lösen kann? Lass es uns in den Kommentaren unten wissen!

Kumar ist Softwareentwickler und technischer Autor in Indien. Er hat sich auf JavaScript und DevOps spezialisiert. Auf seiner Website kannst du mehr über seine Arbeit erfahren.

