
Tanto MySQL como MariaDB aprovechan a la perfección la eficacia de la indexación en árbol equilibrado (B-Tree) para optimizar las operaciones con datos. Este mecanismo de indexación compartida garantiza una rápida recuperación de los datos, mejora el rendimiento de las consultas y minimiza la entrada/salida (I/O, input/output) del disco, contribuyendo a una experiencia de base de datos más ágil y eficiente.
Este artículo profundiza en la indexación, te guía en la creación de índices y comparte consejos para utilizarlos de forma más eficaz en las bases de datos MySQL y MariaDB.
¿Qué es un índice?
Cuando consultas una base de datos MySQL en busca de información específica, la consulta busca en cada fila de una tabla de la base de datos hasta localizar la correcta. Esto puede llevar mucho tiempo, sobre todo cuando la base de datos es extensa.
Los gestores de bases de datos utilizan la indexación para agilizar los procesos de recuperación de datos y optimizar la eficacia de las consultas. La indexación construye una estructura de datos que minimiza la cantidad de datos que hay que buscar organizándolos sistemáticamente, lo que permite una ejecución más rápida y eficaz de las consultas.
Supongamos que quieres encontrar un cliente cuyo nombre de pila es Ava en la siguiente tabla Clientes:
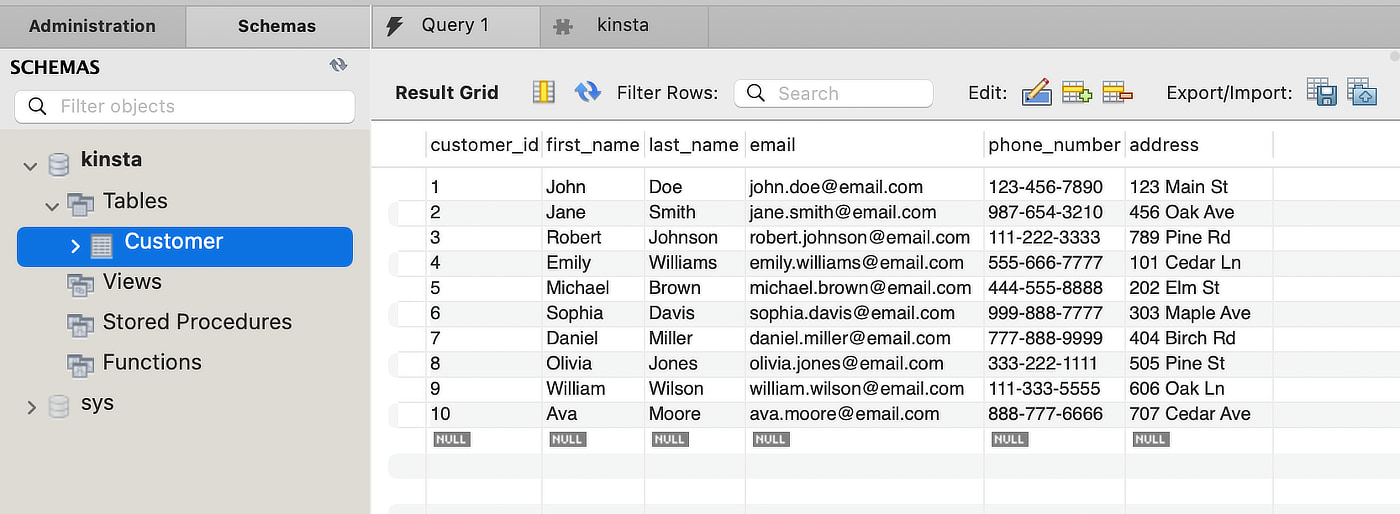
Si añades un índice B-Tree a la columna first_name, se crea una estructura que facilita una búsqueda más eficaz de la información deseada. La estructura se asemeja a un árbol con el nodo raíz en la parte superior, que se ramifica hasta los nodos hoja en la parte inferior.
Es similar a un árbol bien organizado, en el que cada nivel guía la búsqueda basándose en el orden de clasificación de los datos.
Esta imagen muestra la ruta de búsqueda de un índice B-Tree:
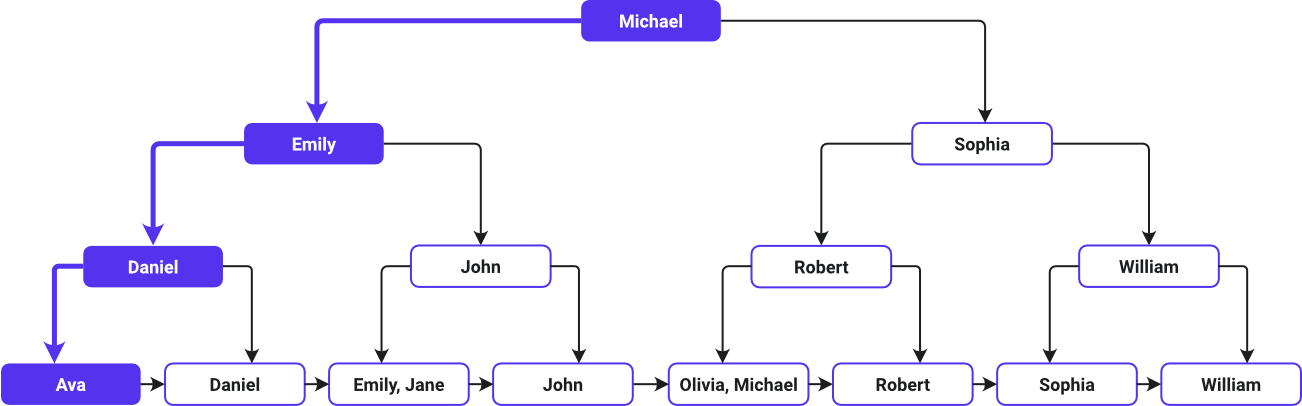
Ava aparece en primer lugar, y William en último lugar, en orden alfabético ascendente: es la forma en que el B-Tree ha ordenado los nombres. El sistema B-Tree designa el valor central de la lista como nodo raíz. Como Michael está en medio de la lista alfabética, es el nodo raíz. A continuación, el árbol se ramifica, con valores a la izquierda y a la derecha de Michael.
A medida que desciendes por los niveles del árbol, cada nodo ofrece más claves (enlaces directos a las filas originales de datos) para guiar la búsqueda a través de los nombres ordenados alfabéticamente. Entonces, encuentras los datos del nombre de pila de cada cliente en los nodos de las hojas.
La búsqueda comienza comparando Ava con el nodo raíz Michael. Se desplaza hacia la izquierda tras determinar que Ava aparece antes que Michael alfabéticamente. Se desplaza hacia abajo hasta el hijo izquierdo (Emily), luego hacia la izquierda de nuevo hasta Daniel, y hacia la izquierda una vez más hasta Ava antes de llegar al nodo hoja que contiene la información de Ava.
El B-Tree funciona como un sistema de navegación simplificado, guiando eficazmente la búsqueda a un lugar concreto sin comprobar cada nombre del conjunto de datos. Es como navegar por un directorio cuidadosamente ordenado siguiendo señales estratégicamente colocadas que te llevan directamente al destino.
Tipos de índices
Existen distintos tipos de índices para diversos fines. Analicemos estos tipos a continuación.
1. Índices de un solo nivel
Los índices de un nivel, o índices planos, asignan claves de índice a datos de la tabla. Cada clave del índice corresponde a una única fila de la tabla.
La columna id_cliente es una clave primaria en la tabla Cliente, que sirve como índice de un solo nivel. La clave identifica a cada cliente y vincula su información en la tabla.
| Índice (id_cliente) | Indicador de fila |
| 1 | Fila 1 |
| 2 | Fila 2 |
| 3 | Fila 3 |
| 4 | Fila 4 |
| .. | .. |
La relación entre las claves id_cliente y los detalles individuales de los clientes es sencilla. Los índices de un solo nivel son excelentes en tablas con pocas filas o columnas con pocos valores distintos. Columnas como estado o categoría, por ejemplo, son buenas candidatas.
Utiliza un índice de un solo nivel para consultas sencillas que localicen una fila concreta basándose en una sola columna. Su implementación es sencilla, directa y eficaz para conjuntos de datos pequeños.
2. Índices multinivel
A diferencia de los índices de un solo nivel para la recuperación organizada de datos, los índices multinivel utilizan una estructura jerárquica. Tienen varios niveles de orientación. El índice de nivel superior dirige la búsqueda a un índice de nivel inferior, y así sucesivamente hasta llegar al nivel hoja, que almacena los datos. Esta estructura disminuye el número de comparaciones necesarias durante las búsquedas.
Considera un índice multinivel con las columnas dirección e id_cliente.
| Índice (dirección) | Subíndice (id_cliente) | Indicador de fila |
| Calle principal 123 | 1 | Fila 1 |
| Avenida del Roble 456 | 2 | Fila 2 |
| Pine Rd 789 | 3 | Fila 3 |
| .. | .. | .. |
El primer nivel organiza las direcciones. El segundo nivel, dentro de cada dirección, organiza aún más los identificadores de cliente.
Esta organización es excelente para conjuntos de datos más extensos que requieren una jerarquía de búsqueda organizada. También es útil para columnas como apellidos con una cardinalidad moderada (la coincidencia de valores de datos en una columna concreta).
3. Índices agrupados
Los índices agrupados en MySQL dictan el orden lógico del índice y el orden de los datos en la tabla. Si aplicas un índice agrupado a la columna id_cliente de la tabla Cliente, las filas se ordenan en función de los valores de la columna. Esto significa que el orden de los datos en la tabla refleja el orden del índice agrupado, mejorando el rendimiento de la recuperación de datos para patrones específicos al reducir la I/O de disco.
Esta estrategia es eficaz cuando el patrón de recuperación de datos coincide con el orden de los ID de cliente. También es adecuada para columnas con alta cardinalidad, como id_cliente.
Aunque los índices agrupados ofrecen ventajas en cuanto al rendimiento de la recuperación de datos para patrones específicos, es importante tener en cuenta un posible inconveniente. Ordenar las filas basándose en el índice agrupado puede afectar al rendimiento de las operaciones de inserción y actualización, especialmente si el patrón de inserción o actualización no coincide con el orden del índice agrupado. Esto se debe a que los nuevos datos deben insertarse o actualizarse de forma que se mantenga el orden de clasificación, lo que supone una sobrecarga adicional.
4. Índices no agrupados
Los índices no agrupados dan más flexibilidad a las estructuras de las bases de datos. Imagina que utilizas un índice no agrupado en una columna de correo electrónico. A diferencia de un índice agrupado, no cambia el orden de las entradas de la tabla.
En su lugar, construye una nueva estructura que asigna claves — en este caso, direcciones de correo electrónico — a filas de datos. Cuando consultas la base de datos en busca de una dirección de correo electrónico concreta, el índice no agrupado guía la búsqueda directamente a la fila correspondiente sin basarse en el orden de la tabla.
La flexibilidad de los índices no agrupados es su principal ventaja. Permiten realizar búsquedas eficaces en varias columnas sin imponer un orden a los datos almacenados. Este sistema hace que los índices no agrupados sean versátiles, ya que pueden acomodar consultas que no siguen el orden primario de la tabla.
Los índices no agrupados son útiles cuando el patrón de recuperación de datos difiere del orden alfabético y para columnas con cardinalidad de moderada a alta, como el correo electrónico.
Cómo crear índices
Ahora que hemos revisado qué son los índices a un alto nivel, vamos a revisar algunos ejemplos prácticos de creación de índices utilizando MySQL Workbench.
Requisitos previos
Para seguir adelante, necesitas
- Una base de datos MySQL (compatible con MariaDB)
- Algo de experiencia en SQL y MySQL
- MySQL Workbench
Cómo crear la tabla de clientes
- Inicia MySQL Workbench y conéctate a tu servidor MySQL.
- Ejecuta la siguiente consulta SQL para crear una tabla Customer (Cliente):
CREATE TABLE Customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(15), address VARCHAR(255) ); - Inserta los siguientes datos:
-- Adding Data to the Customer Table INSERT INTO Customer (customer_id, first_name, last_name, email, phone_number, address) VALUES (1, 'John', 'Doe', '[email protected]', '123-456-7890', '123 Main St'), (2, 'Jane', 'Smith', '[email protected]', '987-654-3210', '456 Oak Ave'), (3, 'Robert', 'Johnson', '[email protected]', '111-222-3333', '789 Pine Rd'), (4, 'Emily', 'Williams', '[email protected]', '555-666-7777', '101 Cedar Ln'), (5, 'Michael', 'Brown', '[email protected]', '444-555-8888', '202 Elm St'), (6, 'Sophia', 'Davis', '[email protected]', '999-888-7777', '303 Maple Ave'), (7, 'Daniel', 'Miller', '[email protected]', '777-888-9999', '404 Birch Rd'), (8, 'Olivia', 'Jones', '[email protected]', '333-222-1111', '505 Pine St'), (9, 'William', 'Wilson', '[email protected]', '111-333-5555', '606 Oak Ln'), (10, 'Ava', 'Moore', '[email protected]', '888-777-6666', '707 Cedar Ave');
Índices de un solo nivel
Una táctica para optimizar el rendimiento de las consultas en MySQL y MariaDB es utilizar índices de un solo nivel.
Para añadir un índice de nivel único a la tabla Cliente, utiliza la sentencia CREATE INDEX
-- Creating a Single-Level Index on "customer_id"
CREATE INDEX idx_customer_id ON Customer(customer_id);Si se ejecuta correctamente, la base de datos confirma la creación del índice devolviendo el siguiente código:
0 row(s) affected Records: 0 Duplicates: 0 Warnings: 0Ahora, las consultas que filtran datos basándose en valores de la columna customer_id son gestionadas de forma óptima por la base de datos, lo que aumenta enormemente la eficacia.
Índices multinivel
MySQL y MariaDB van más allá de la indexación de columnas individuales al proporcionar índices multinivel. Estos índices abarcan más de un nivel o columna, combinando valores de varias columnas en un índice para que la ejecución de las consultas sea más eficiente.
Utiliza el siguiente código para crear un índice multinivel en MySQL o MariaDB, centrándote en las columnas address y customer_id:
-- Creating a Multi-Level Index based on "address" and "customer_id"
CREATE INDEX idx_address_customer_id ON Customer(address, customer_id);El uso estratégico de índices multinivel produce mejoras significativas en el rendimiento de las consultas, especialmente cuando se trata de conjuntos de columnas.
Índices agrupados
Además de los índices individuales y multinivel, MySQL y MariaDB utilizan índices agrupados, una herramienta dinámica para mejorar el rendimiento de las bases de datos alineando las filas de datos con el orden de los indicadores del índice.
Por ejemplo, aplicar un índice agrupado a la columna customer_id de la tabla Customer (Cliente) alinea el orden de los ID de cliente.
-- Creating a Clustered Index on "customer_id"
CREATE CLUSTERED INDEX idx_customer_id_clustered ON Customer(customer_id);Debido al orden optimizado de los datos, esta estrategia mejora significativamente la recuperación de datos de patrones específicos a la vez que disminuye la I/O de disco.
Índices no agrupados
Los índices no agrupados pueden optimizar las consultas en función de las columnas sin forzar los datos en un orden determinado. En MySQL y MariaDB, no es necesario especificar que un índice es no agrupado.
La arquitectura de la tabla lo implica. Sólo la clave primaria o la primera clave única no nula puede ser un índice agrupado. Los demás índices de la tabla son todos implícitamente no agrupados. Como ejemplo de índice no agrupado, considera lo siguiente:
-- Creating a Non-clustered Index on "email"
CREATE INDEX idx_email_non_clustered ON Customer(email);Los índices no agrupados permiten realizar búsquedas eficaces en varias columnas, lo que da lugar a una base de datos más versátil y con mayor capacidad de respuesta.
Buenas prácticas y puntos clave
Elige índices de un solo nivel cuando trabajes con columnas con un pequeño rango de valores distintos, como estado o categoría. Utiliza índices multinivel y no agrupados con columnas con un rango más amplio de valores, como correo electrónico.
Tus patrones preferidos de recuperación de datos son clave a la hora de elegir entre índices agrupados y no agrupados. Para los índices agrupados, elige columnas con alta cardinalidad, como el ID de cliente. Para los índices no agrupados, elige columnas con cardinalidad de moderada a alta, como el correo electrónico.
Cómo optimizar los índices
Para aumentar el rendimiento de tus índices, puedes utilizar algunas estrategias prácticas, como implementar índices de cobertura y eliminar los índices redundantes.
1. Índices de cobertura
Los índices de cobertura mejoran el rendimiento de las consultas creando índices que cubren todos los datos necesarios. El término índice de cobertura significa que un índice incluye todas las columnas necesarias para realizar una consulta, evitando la necesidad de acceder a las filas de datos.
-- Create a Covering Index on "first_name" and "last_name"
CREATE INDEX idx_covering_name ON Customer(first_name, last_name);2. Eliminar redundancias
Elimina los índices redundantes, pero ten cuidado, ya que la eliminación de índices puede afectar al rendimiento de determinadas consultas.
-- Remove an Unnecessary Index
DROP INDEX idx_unnecessary_index ON Customer;Revisa y elimina periódicamente los índices redundantes para garantizar una estructura de base de datos racionalizada y eficiente.
3. Evita el exceso de índices
Evita errores comunes como la sobreindexación. Aunque los índices mejoran el rendimiento de las consultas, crear demasiados puede disminuir el rendimiento. Es crucial encontrar un equilibrio y evitar la sobreindexación, que puede provocar un aumento de los requisitos de almacenamiento y una posible degradación del rendimiento.
4. Analiza los patrones de consulta
También es un error común pasar por alto el análisis de los patrones de consulta antes de crear índices. Comprender las consultas que se ejecutan con frecuencia y centrarse en indexar las columnas utilizadas en las cláusulas WHERE o en las condiciones JOIN es esencial para obtener un rendimiento óptimo.
Resumen
Este artículo ha explorado la indexación en MySQL y MariaDB, haciendo hincapié en la eficacia del mecanismo B-Tree. Se han tratado los fundamentos de la indexación y los distintos tipos de índices (de un nivel, multinivel, agrupados y no agrupados).
Tanto si estás optimizando cargas de trabajo de lectura intensiva como mejorando el rendimiento de escritura, el servicio de alojamiento de bases de datos de Kinsta proporciona a los usuarios de MySQL y MariaDB una solución fiable y de alto rendimiento para sus necesidades de indexación. Prueba el alojamiento de bases de datos de Kinsta para aprovechar MySQL y MariaDB y sus capacidades de indexación.


