
Sowohl MySQL als auch MariaDB nutzen nahtlos die Effizienz der Balanced-Tree-Indizierung (B-Tree), um Datenoperationen zu optimieren. Dieser gemeinsame Indexierungsmechanismus sorgt für einen schnellen Datenabruf, verbessert die Abfrageleistung und minimiert die Ein-/Ausgabe auf der Festplatte, was zu einer reaktionsschnellen und effizienten Datenbank beiträgt.
Dieser Artikel wirft einen genaueren Blick auf die Indizierung, zeigt dir, wie du Indizes erstellst, und gibt dir Tipps, wie du sie in MySQL- und MariaDB-Datenbanken effektiver nutzen kannst.
Was ist ein Index?
Wenn du eine MySQL-Datenbank nach bestimmten Informationen abfragst, durchsucht die Abfrage jede Zeile in einer Datenbanktabelle, bis sie die richtige Zeile gefunden hat. Das kann lange dauern, vor allem, wenn die Datenbank sehr umfangreich ist.
Datenbankmanager nutzen die Indizierung, um den Datenabruf zu beschleunigen und die Abfrageeffizienz zu optimieren. Durch die Indizierung wird eine Datenstruktur aufgebaut, die die Menge der zu durchsuchenden Daten minimiert, indem sie die Daten systematisch organisiert, was zu einer schnelleren und effektiveren Ausführung der Abfrage führt.
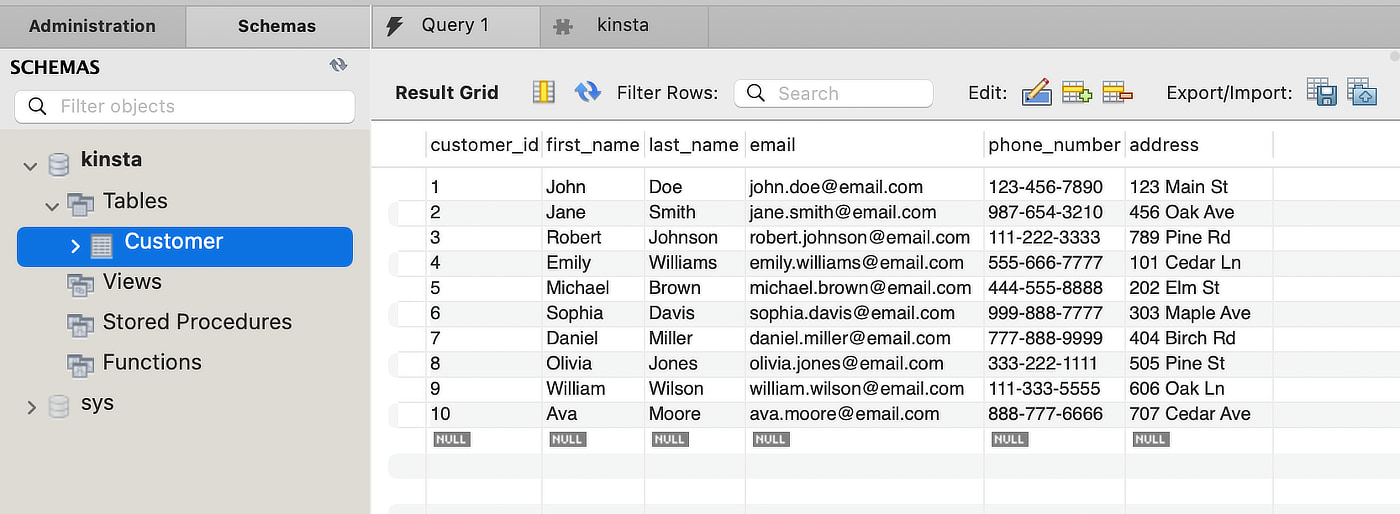
Angenommen, du möchtest einen Kunden mit dem Vornamen Ava in der folgenden Kundentabelle finden:
Durch das Hinzufügen eines B-Tree-Index zur Spalte first_name wird eine Struktur geschaffen, die eine effizientere Suche nach den gewünschten Informationen ermöglicht. Die Struktur ähnelt einem Baum mit dem Wurzelknoten an der Spitze, der sich bis zu den Blattknoten am unteren Ende verzweigt.
Sie ähnelt einem gut organisierten Baum, bei dem jede Ebene die Suche auf der Grundlage der sortierten Reihenfolge der Daten leitet.
Dieses Bild zeigt den Suchpfad eines B-Baum-Indexes:
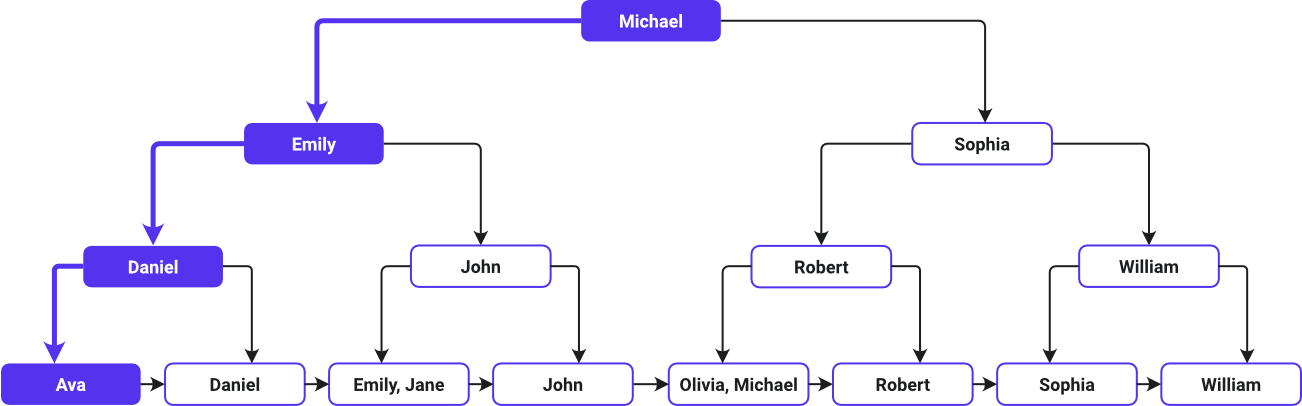
Ava wird zuerst aufgeführt und William zuletzt in aufsteigender alphabetischer Reihenfolge – so wie der B-Baum die Namen angeordnet hat. Das B-Tree-System bezeichnet den mittleren Wert in der Liste als Wurzelknoten. Da Michael in der Mitte der alphabetischen Liste steht, ist es der Wurzelknoten. Der Baum verzweigt sich dann mit den Werten links und rechts von Michael.
Je weiter du in der Baumstruktur nach unten gehst, desto mehr Schlüssel (direkte Links zu den ursprünglichen Datenzeilen) bietet jeder Knoten, um die Suche durch die alphabetisch geordneten Namen zu führen. An den Blattknoten findest du dann die Daten für den Vornamen eines jeden Kunden.
Die Suche beginnt mit dem Vergleich von Ava mit dem Wurzelknoten Michael. Sie bewegt sich nach links, nachdem sie festgestellt hat, dass Ava alphabetisch vor Michael steht. Sie geht nach unten zum linken Kind (Emily), dann wieder nach links zu Daniel und noch einmal nach links zu Ava, bevor sie bei dem Blattknoten ankommt, der die Informationen von Avaenthält.
Der B-Baum funktioniert wie ein vereinfachtes Navigationssystem, das die Suche effektiv zu einem bestimmten Ort führt, ohne dass jeder Name im Datensatz überprüft werden muss. Es ist, als würde man in einem sorgfältig geordneten Verzeichnis navigieren, indem man strategisch platzierten Wegweisern folgt, die einen direkt zum Ziel führen.
Arten von Indizes
Es gibt verschiedene Arten von Indizes für unterschiedliche Zwecke. Im Folgenden gehen wir auf diese verschiedenen Arten ein.
1. Einstufige Indizes
Einstufige Indizes, auch flache Indizes genannt, ordnen Indexschlüssel den Tabellendaten zu. Jeder Schlüssel im Index entspricht einer einzelnen Tabellenzeile.
Die Spalte customer_id ist ein Primärschlüssel in der Tabelle Customer und dient als einstufiger Index. Der Schlüssel identifiziert jeden Kunden und verknüpft seine Informationen in der Tabelle.
| Index (kunden_id) | Zeilenzeiger |
| 1 | Zeile 1 |
| 2 | Zeile 2 |
| 3 | Reihe 3 |
| 4 | Reihe 4 |
| .. | .. |
Die Beziehung zwischen den customer_id-Schlüsseln und den einzelnen Kundendaten ist einfach. Einstufige Indizes eignen sich besonders für Tabellen mit wenigen Zeilen oder Spalten mit wenigen unterschiedlichen Werten. Spalten wie Status oder Kategorie sind z. B. gute Kandidaten.
Verwende einen einstufigen Index für einfache Abfragen, die eine bestimmte Zeile anhand einer einzigen Spalte finden. Seine Implementierung ist einfach, überschaubar und effizient für kleinere Datensätze.
2. Multi-Level-Indizes
Im Gegensatz zu einstufigen Indizes für organisierte Datenabfragen verwenden mehrstufige Indizes eine hierarchische Struktur. Sie haben mehrere Führungsebenen. Der Top-Level-Index leitet die Suche zu einem Index auf einer niedrigeren Ebene und so weiter, bis er die Blattebene erreicht, auf der die Daten gespeichert sind. Diese Struktur verringert die Anzahl der bei der Suche erforderlichen Vergleiche.
Nehmen wir einen mehrstufigen Index mit den Spalten address und customer_id.
| Index (Adresse) | Sub-Index (kunden_id) | Zeilenzeiger |
| 123 Hauptstraße | 1 | Zeile 1 |
| 456 Oak Ave | 2 | Reihe 2 |
| 789 Pine Rd | 3 | Reihe 3 |
| .. | .. | .. |
Auf der ersten Ebene werden die Adressen organisiert. Auf der zweiten Ebene werden die Kunden-IDs innerhalb jeder Adresse weiter organisiert.
Diese Organisation eignet sich hervorragend für umfangreichere Datensätze, die eine geordnete Suchhierarchie erfordern. Sie ist auch hilfreich für Spalten wie Nachname mit einer mäßigen Kardinalität (die Einzigartigkeit der Datenwerte in einer bestimmten Spalte).
3. Geclusterte Indizes
Geclusterte Indizes in MySQL legen die logische Reihenfolge des Index und die Reihenfolge der Daten in der Tabelle fest. Wenn du einen geclusterten Index auf die Spalte customer_id in der Tabelle Customer anwendest, werden die Zeilen nach den Werten der Spalte sortiert. Das bedeutet, dass die Reihenfolge der Daten in der Tabelle die Reihenfolge des geclusterten Index widerspiegelt, was die Leistung der Datenabfrage für bestimmte Muster verbessert, indem es die Festplatten-E/A reduziert.
Diese Strategie ist effektiv, wenn das Datenabrufmuster mit der Reihenfolge der Kunden-IDs übereinstimmt. Sie eignet sich auch für Spalten mit hoher Kardinalität, wie z. B. customer_id.
Obwohl geclusterte Indizes für bestimmte Muster Vorteile bei der Datenabfrage bieten, gibt es auch einen potenziellen Nachteil. Das Sortieren von Zeilen auf der Grundlage des Cluster-Index kann die Leistung von Einfüge- und Aktualisierungsvorgängen beeinträchtigen, insbesondere wenn das Einfüge- oder Aktualisierungsmuster nicht mit der Reihenfolge des Cluster-Index übereinstimmt. Das liegt daran, dass neue Daten so eingefügt oder aktualisiert werden müssen, dass die sortierte Reihenfolge beibehalten wird, was zu zusätzlichem Overhead führt.
4. Nicht-geclusterte Indizes
Nicht-geclusterte Indizes geben der Datenbankstruktur mehr Flexibilität. Angenommen, du verwendest einen nicht-geclusterten Index für eine E-Mail-Spalte. Anders als ein geclusterter Index ändert er die Reihenfolge der Einträge in der Tabelle nicht.
Stattdessen wird eine neue Struktur erstellt, die die Schlüssel – in diesem Fall die E-Mail-Adressen – den Datenzeilen zuordnet. Wenn du die Datenbank nach einer bestimmten E-Mail-Adresse abfragst, führt der nicht geclusterte Index die Suche direkt zur entsprechenden Zeile, ohne sich auf die Reihenfolge der Tabelle zu verlassen.
Die Flexibilität von nicht geclusterten Indizes ist ihr Hauptvorteil. Sie ermöglichen eine effiziente Suche in mehreren Spalten, ohne den gespeicherten Daten eine bestimmte Reihenfolge aufzuerlegen. Dieses System macht nicht-geclusterte Indizes vielseitig, denn sie können Abfragen erfüllen, die nicht der primären Reihenfolge der Tabelle folgen.
Nicht-geclusterte Indizes sind hilfreich, wenn das Muster der Datenabfrage von der alphabetischen Reihenfolge abweicht und für Spalten mit mittlerer bis hoher Kardinalität, wie z. B. E-Mail.
Wie man Indizes erstellt
Nachdem wir nun erklärt haben, was Indizes sind, wollen wir uns einige praktische Beispiele für die Erstellung von Indizes mit MySQL Workbench ansehen.
Voraussetzungen
Um mitmachen zu können, brauchst du:
- Eine MySQL-Datenbank (kompatibel mit MariaDB)
- Etwas Erfahrung mit SQL und MySQL
- MySQL Workbench
So erstellst du die Kundentabelle
- Starte die MySQL Workbench und verbinde dich mit deinem MySQL-Server.
- Führe die folgende SQL-Abfrage aus, um eine Kundentabelle zu erstellen:
CREATE TABLE Customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(15), address VARCHAR(255) ); - Füge die folgenden Daten ein:
-- Adding Data to the Customer Table INSERT INTO Customer (customer_id, first_name, last_name, email, phone_number, address) VALUES (1, 'John', 'Doe', '[email protected]', '123-456-7890', '123 Main St'), (2, 'Jane', 'Smith', '[email protected]', '987-654-3210', '456 Oak Ave'), (3, 'Robert', 'Johnson', '[email protected]', '111-222-3333', '789 Pine Rd'), (4, 'Emily', 'Williams', '[email protected]', '555-666-7777', '101 Cedar Ln'), (5, 'Michael', 'Brown', '[email protected]', '444-555-8888', '202 Elm St'), (6, 'Sophia', 'Davis', '[email protected]', '999-888-7777', '303 Maple Ave'), (7, 'Daniel', 'Miller', '[email protected]', '777-888-9999', '404 Birch Rd'), (8, 'Olivia', 'Jones', '[email protected]', '333-222-1111', '505 Pine St'), (9, 'William', 'Wilson', '[email protected]', '111-333-5555', '606 Oak Ln'), (10, 'Ava', 'Moore', '[email protected]', '888-777-6666', '707 Cedar Ave');
Einstufige Indizes
Eine Taktik zur Optimierung der Abfrageleistung in MySQL und MariaDB ist die Verwendung von Single-Level-Indizes.
Um der Tabelle Customer einen einstufigen Index hinzuzufügen, verwendest du die CREATE INDEX anweisung:
-- Creating a Single-Level Index on "customer_id"
CREATE INDEX idx_customer_id ON Customer(customer_id);Nach erfolgreicher Ausführung bestätigt die Datenbank die Indexerstellung, indem sie den folgenden Code zurückgibt:
0 row(s) affected Records: 0 Duplicates: 0 Warnings: 0Jetzt werden Abfragen, die Daten auf der Grundlage von Werten aus der Spalte customer_id filtern, von der Datenbank optimal verarbeitet, was die Effizienz deutlich erhöht.
Indexe auf mehreren Ebenen
MySQL und MariaDB gehen über die Indizierung einzelner Spalten hinaus, indem sie mehrstufige Indizes bereitstellen. Diese Indizes umfassen mehr als eine Ebene oder Spalte und kombinieren Werte aus mehreren Spalten in einem Index, um die Ausführung von Abfragen effizienter zu machen.
Verwende den folgenden Code, um einen mehrstufigen Index in MySQL oder MariaDB zu erstellen, der sich auf die Spalten address und customer_id konzentriert:
-- Creating a Multi-Level Index based on "address" and "customer_id"
CREATE INDEX idx_address_customer_id ON Customer(address, customer_id);Der strategische Einsatz von Multi-Level-Indizes führt zu erheblichen Verbesserungen der Abfrageleistung, vor allem wenn es sich um Spaltengruppen handelt.
Geclusterte Indizes
Neben der individuellen und mehrstufigen Indexierung verwenden MySQL und MariaDB auch geclusterte Indizes, ein dynamisches Werkzeug zur Verbesserung der Datenbankleistung, indem die Datenzeilen an der Reihenfolge der Indexzeiger ausgerichtet werden.
Wenn du zum Beispiel einen geclusterten Index auf die Spalte customer_id in der Tabelle Customer anwendest, wird die Reihenfolge der Kunden-IDs angeglichen.
-- Creating a Clustered Index on "customer_id"
CREATE CLUSTERED INDEX idx_customer_id_clustered ON Customer(customer_id);Aufgrund der optimierten Reihenfolge der Daten verbessert diese Strategie die Datenabfrage bestimmter Muster erheblich und verringert gleichzeitig die Festplatten-E/A.
Nicht-geclusterte Indizes
Nicht-geclusterte Indizes können Abfragen abhängig von den Spalten optimieren, ohne die Daten in eine bestimmte Reihenfolge zu zwingen. In MySQL und MariaDB musst du nicht angeben, dass ein Index nicht geclustert ist.
Die Tabellenarchitektur impliziert dies. Nur der Primärschlüssel oder der erste eindeutige Schlüssel, der nicht null ist, kann ein geclusterter Index sein. Die anderen Indizes der Tabelle sind alle implizit nicht geclustert. Ein Beispiel für einen nicht-geclusterten Index ist der folgende:
-- Creating a Non-clustered Index on "email"
CREATE INDEX idx_email_non_clustered ON Customer(email);Nicht geclusterte Indizes ermöglichen eine effiziente Suche in mehreren Spalten, was zu einer vielseitigeren und reaktionsschnelleren Datenbank führt.
Bewährte Praktiken und wichtige Punkte
Wähle einstufige Indizes, wenn du mit Spalten arbeitest, die nur wenige unterschiedliche Werte haben, wie Status oder Kategorie. Verwende mehrstufige und nicht geclusterte Indizes für Spalten mit einem größeren Wertebereich, z. B. E-Mail.
Bei der Wahl zwischen geclusterten und nicht geclusterten Indizes sind deine bevorzugten Datenabfragemuster entscheidend. Für geclusterte Indizes wählst du Spalten mit hoher Kardinalität, wie die Kunden-ID. Für nicht geclusterte Indizes wählst du Spalten mit mittlerer bis hoher Kardinalität, z. B. E-Mail.
Wie du Indizes optimierst
Um die Leistung deiner Indizes zu steigern, kannst du einige praktische Strategien anwenden, z. B. das Abdecken von Indizes und das Entfernen redundanter Indizes.
1. Indizes abdecken
Covering-Indizes verbessern die Abfrageleistung, indem sie Indizes erstellen, die alle notwendigen Daten abdecken. Der Begriff „abdeckender Index“ bedeutet, dass ein Index alle Spalten enthält, die für eine Abfrage benötigt werden, so dass ein Zugriff auf die Datenzeilen nicht erforderlich ist.
-- Create a Covering Index on "first_name" and "last_name"
CREATE INDEX idx_covering_name ON Customer(first_name, last_name);2. Redundanzen entfernen
Entferne überflüssige Indizes, aber sei vorsichtig, da das Entfernen von Indizes die Leistung bestimmter Abfragen beeinträchtigen kann.
-- Remove an Unnecessary Index
DROP INDEX idx_unnecessary_index ON Customer;Überprüfe und entferne überflüssige Indizes regelmäßig, um eine schlanke und effiziente Datenbankstruktur zu gewährleisten.
3. Vermeide Überindizierung
Vermeide häufige Fallstricke wie die Überindizierung. Indizes verbessern zwar die Abfrageleistung, aber wenn du zu viele davon erstellst, kann sich das negativ auswirken. Es ist wichtig, ein Gleichgewicht zu finden und eine Überindizierung zu vermeiden, die zu einem erhöhten Speicherbedarf und einer möglichen Leistungsverschlechterung führen kann.
4. Analysiere die Abfragemuster
Ein weiterer häufiger Fehler ist es, die Analyse von Abfragemustern vor der Erstellung von Indizes zu übersehen. Für eine optimale Leistung ist es wichtig, die häufig ausgeführten Abfragen zu verstehen und sich auf die Indizierung von Spalten zu konzentrieren, die in WHERE Klauseln oder JOIN Bedingungen verwendet werden.
Zusammenfassung
In diesem Artikel wurde die Indexierung von MySQL und MariaDB erläutert, wobei die Effizienz des B-Tree-Mechanismus im Vordergrund stand. Er behandelt die Grundlagen der Indexierung und verschiedene Indexarten (einstufig, mehrstufig, geclustert und nicht geclustert).
Ganz gleich, ob du deine Datenbank für leseintensive Workloads optimierst oder die Schreibleistung verbesserst: Mit dem Datenbank-Hosting von Kinsta erhalten MySQL- und MariaDB-Nutzer eine zuverlässige und leistungsstarke Lösung für ihre Indexierungsanforderungen. Nutze das Datenbank-Hosting von Kinsta, um die Vorteile von MySQL und MariaDB und deren Indizierungsfunktionen zu nutzen.


