Pour les agences modernes, un système de rapports cohérent et de haute qualité est essentiel pour conserver la confiance des clients et les fidéliser à long terme. Un rapport clair et informatif vous permet de suivre les tendances des ventes, de démontrer l’efficacité des campagnes, de calculer le retour sur investissement (ROI), et bien plus encore.
Cependant, pour une agence gérant des dizaines, voire des centaines de sites, la génération de ces rapports périodiques peut devenir un goulot d’étranglement majeur, compromettant l’évolutivité de vos opérations.
C’est pourquoi l’optimisation et l’automatisation de la récupération des données sont cruciales. Elle rétablit l’efficacité et libère votre équipe pour qu’elle se concentre sur des activités à forte valeur ajoutée, comme le développement de nouveaux projets.
Dans cet article, vous apprendrez comment exploiter l’API Kinsta pour récupérer automatiquement vos données d’hébergement et générer des rapports stratégiques grâce à la puissance de l’IA.
Êtes-vous prêt à faire évoluer votre système de reporting ? Lisez la suite.
Accéder à Kinsta Analytics via MyKinsta et Kinsta API
Les clients de Kinsta ont accès à une multitude de données via le tableau de bord d’hébergement MyKinsta. Vous pouvez accéder aux données de votre plan dans la section Analyses de votre tableau de bord.
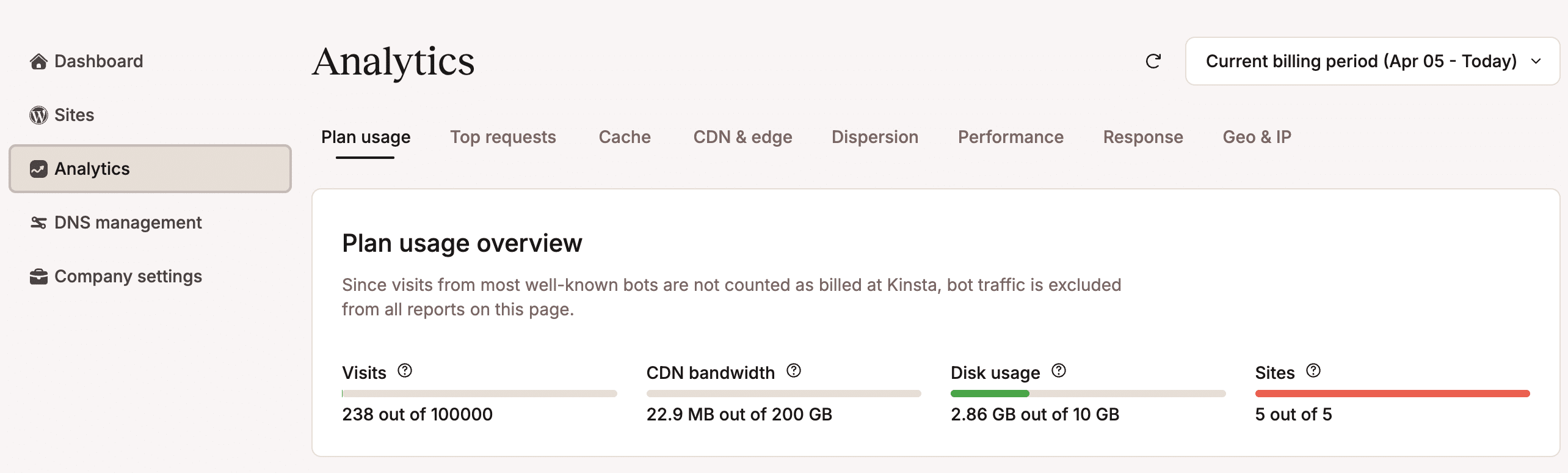
La page Analyses est divisée en plusieurs onglets, chacun se concentrant sur un aspect spécifique de l’activité de votre site :
- Utilisation du plan : affiche la consommation de ressources de votre plan, à la fois cumulée et ventilée par site individuel.
- Principales requêtes : cet onglet vous permet d’identifier les principales requêtes adressées à votre site, classées par bande passante et par nombre de vues.
- Cache : fournit une ventilation de l’utilisation du cache, y compris la ventilation du cache, les composants du cache du serveur et les contournements du cache du serveur.
- CDN & edge : fournit des données sur la consommation de la bande passante du CDN, la bande passante du cache périphérique et des listes des principaux fichiers servis à partir du cache CDN.
- Dispersion : indique le pourcentage de visites provenant d’ordinateurs de bureau, de tablettes et de mobiles.
- Performance : inclut diverses mesures de performance telles que le temps de réponse moyen de PHP MySQL, le débit de PHP, la limite de threads de PHP, etc.
- Réponse : fournit des statistiques sur les codes de réponse, y compris une ventilation détaillée des codes d’erreur.
- Géo & IP : affiche les listes des principaux pays, villes et IP clients d’où proviennent les requêtes adressées à votre site.
Vous pouvez accéder à ces mêmes analyses au niveau du site en naviguant vers Sites > nom du site > Analyses.
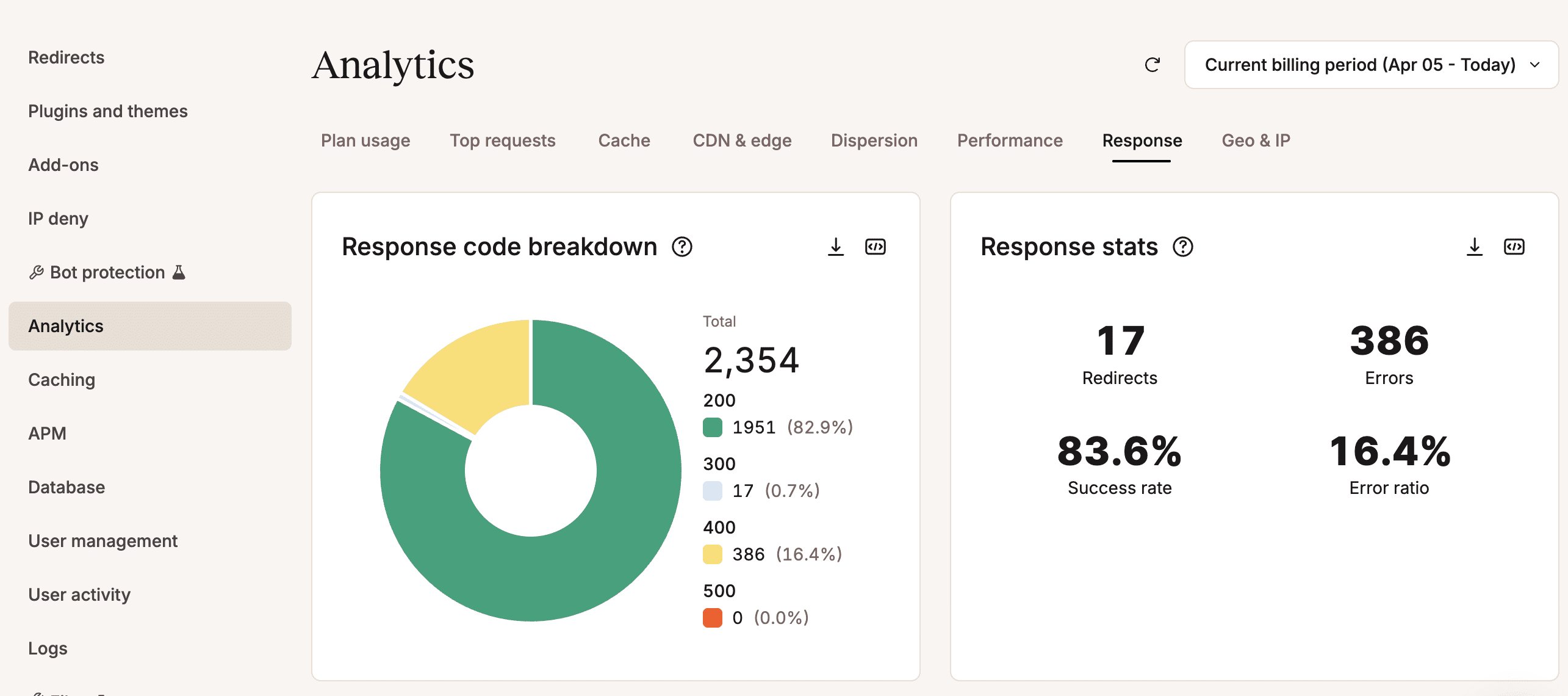
Kinsta Analytics fournit un ensemble de données stupéfiant ; le simple fait de naviguer dans votre tableau de bord MyKinsta vous donne une image très claire de la consommation de ressources, de l’efficacité et de la performance de votre site. Vous saurez exactement d’où viennent la plupart des requêtes et lesquelles consomment le plus de ressources.
Combiné avec notre outil Kinsta APM, Kinsta Analytics vous permet d’optimiser la performance de vos sites WordPress.
Ce que tout le monde ne sait pas, c’est que les données de Kinsta Analytics sont également accessibles via l’API de Kinsta. Cela vous permet d’extraire des données de manière programmatique et de construire des métriques d’hébergement, que vous pouvez ensuite utiliser pour générer des rapports automatisés à partager avec vos clients.
Explorons les points de terminaison de l’API Kinsta.
Le point de terminaison Analytics de l’API Kinsta
Avec le point de terminaison Analytics de l’API Kinsta, vous pouvez accéder à des données brutes sur l’utilisation des ressources et l’état de santé de votre site web.
- Utilisation des visites, utilisation de la bande passante du serveur et utilisation de la bande passante du CDN : ces mesures permettent de suivre l’utilisation de vos ressources par rapport à votre plan d’hébergement pendant la période de facturation en cours.
- Visites : indique le nombre total de visites dans un environnement donné au cours d’une période donnée.
- Espace disque : indique l’espace disque total utilisé par un environnement donné au cours d’une période donnée.
- Bande passante du serveur : indique la bande passante consommée par un environnement donné au cours d’une période donnée.
- Bande passante CDN : indique la bande passante CDN consommée par un environnement donné au cours d’une période donnée.
- Principaux pays : fournit une liste des principaux pays d’où proviennent les requêtes adressées au site au cours d’une période donnée.
- Principales villes : fournit une liste des principales villes d’où proviennent les requêtes adressées au site au cours d’une période donnée.
- Principales adresses IP des clients : fournit une liste des principales adresses IP des clients à l’origine des requêtes adressées au site au cours d’une période donnée.
- Dispersion des visites : fournit des données sur la répartition des visites entre les ordinateurs de bureau, les tablettes et les appareils mobiles au cours d’une période donnée.
- Ventilation des codes de réponse : fournit une ventilation des codes d’état HTTP renvoyés par le serveur au cours d’une période donnée.
Vous trouverez ci-dessous quelques exemples d’utilisation du point de terminaison analytics.
Visites
La requête suivante fournit le nombre total de visites sur votre site et le nombre d’adresses IP uniques qui y ont accédé au cours des 30 derniers jours :
https://api.kinsta.com/v2/sites/environments/{KINSTA_ENV_ID}/analytics/visits?time_span=30_days&company_id={KINSTA_COMPANY_ID}La réponse sera structurée comme suit :
{
"analytics": {
"analytics_response": {
"key": "uniqueip",
"data": [
{
"name": "uniqueip",
"total": 1000,
"dataset": [
{
"key": "2025-10-28T00:00:00.000Z",
"value": "1000"
},
{
"key": "2025-10-28T00:00:00.000Z",
"value": "900"
},
{
"key": "2025-10-28T00:00:00.000Z",
"value": "820"
},
...
]
}
]
}
}
}Bande passante
L’exemple suivant montre comment interroger l’API Kinsta pour obtenir l’utilisation de la bande passante du serveur au cours des 30 derniers jours :
https://api.kinsta.com/v2/sites/environments/{KINSTA_ENV_ID}/analytics/bandwidth?time_span=30_days&company_id={KINSTA_COMPANY_ID}La réponse du serveur Kinsta fournit l’utilisation quotidienne de la bande passante pour les 30 derniers jours :
{
"analytics": {
"analytics_response": {
"key": "bandwidth",
"data": [
{
"name": "bandwidth",
"total": 1000,
"dataset": [
{
"key": "2026-03-11T00:00:00.000Z",
"value": "37347250"
},
{
"key": "2026-03-12T00:00:00.000Z",
"value": "9276458"
},
...
]
}
]
}
}
}Bande passante CDN
Dans cet autre exemple, nous interrogeons l’API Kinsta pour connaitre l’utilisation de la bande passante du CDN au cours des sept derniers jours :
https://api.kinsta.com/v2/sites/environments/{KINSTA_ENV_ID}/analytics/cdn-bandwidth?time_span=7_days&company_id={KINSTA_COMPANY_ID}Le serveur fournira les données suivantes :
{
"analytics": {
"analytics_response": {
"key": "cdn-bandwidth",
"data": [
{
"name": "cdn-bandwidth",
"total": 1000,
"dataset": [
{
"key": "2026-04-02T00:00:00.000Z",
"value": "753447"
},
{
"key": "2026-04-03T00:00:00.000Z",
"value": "16911"
},
...
]
}
]
}
}
}Vous pouvez l’essayer vous-même en saisissant votre clé API Kinsta (bearer token), l’ID de l’environnement et l’ID de l’entreprise dans le terrain de jeu de l’API.
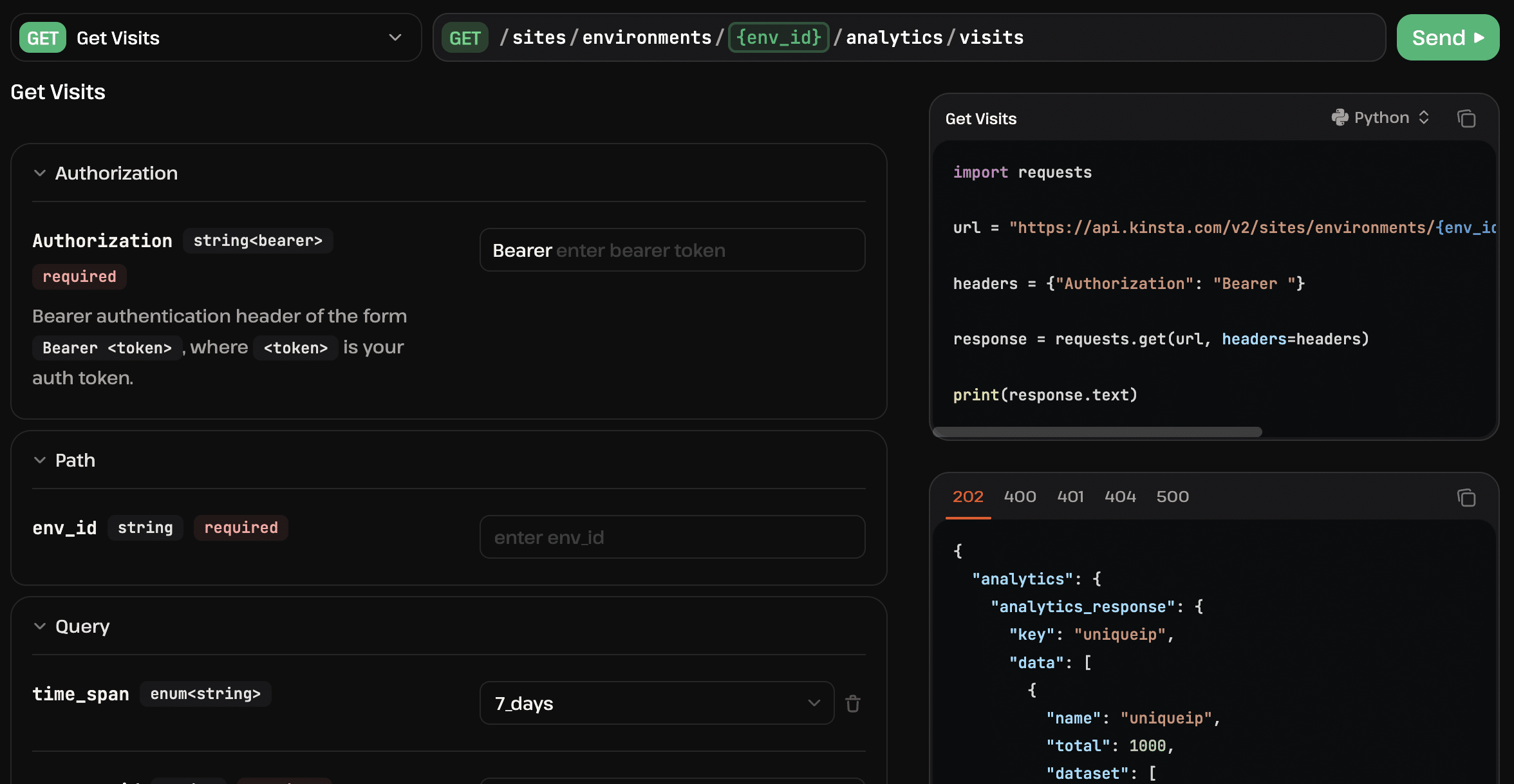
Maintenant que vous savez comment accéder aux données analytiques de votre site sur Kinsta, vous pouvez les utiliser pour automatiser vos opérations. Cela inclut également l’automatisation du système de reporting.
Les sections suivantes vous montreront comment automatiser le système de reporting de votre agence à l’aide de l’API Kinsta. Nous allons créer un script Python et utiliser les actions GitHub pour automatiser la construction et l’exécution. Ce script transformera les données brutes renvoyées par l’API en tableaux et en graphiques, et interrogera Google AI pour générer un rapport final.
Il est temps de mettre la main à la pâte.
Construire un système de reporting automatisé en utilisant l’API Kinsta et l’IA de Google
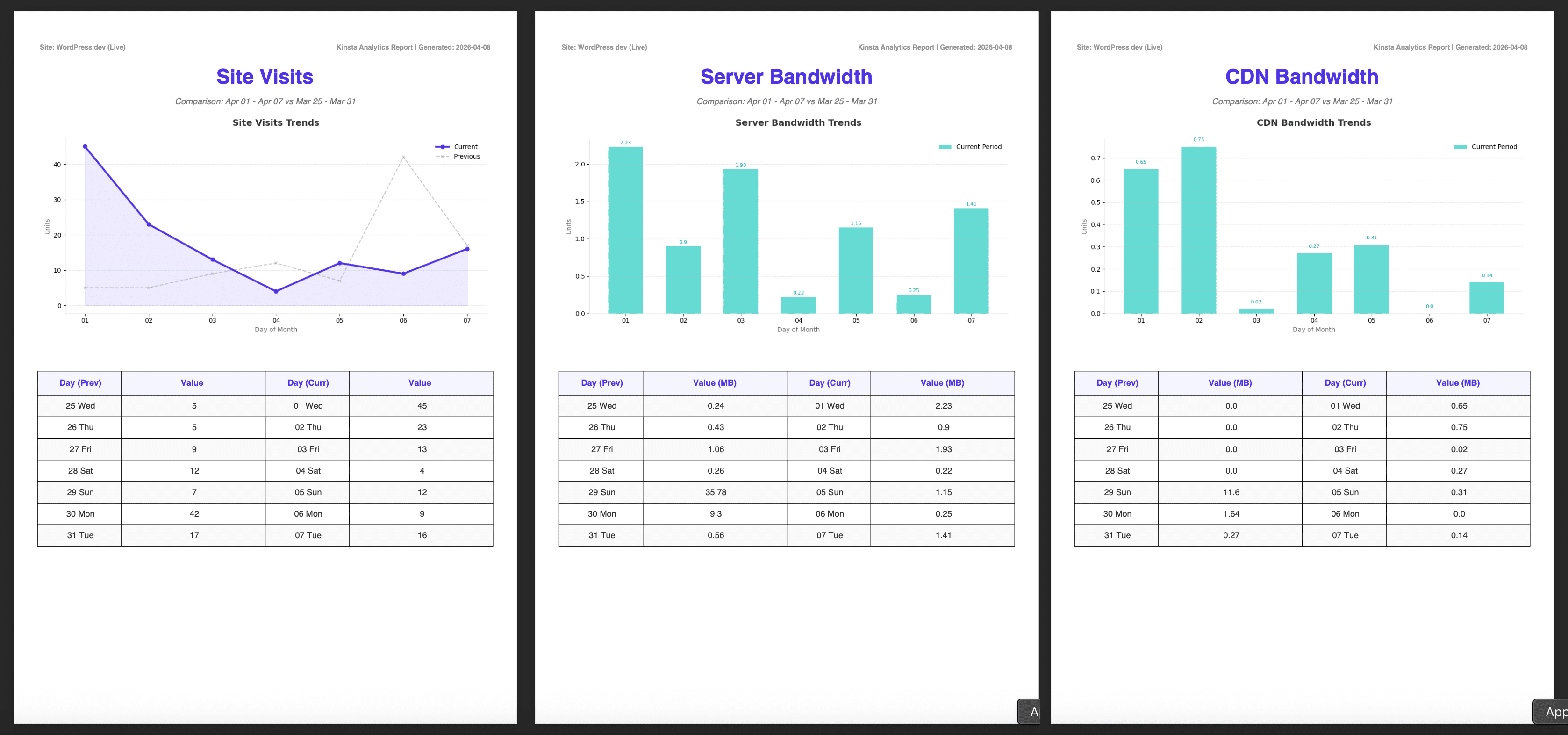
Notre objectif est de créer un rapport automatisé qui est généré à des intervalles spécifiques. Le système interrogera l’API Kinsta pour récupérer des données sur les visites, la bande passante du serveur et la bande passante du CDN. Ces données seront ensuite utilisées pour créer des graphiques et des tableaux dans un fichier PDF. Dans le cadre de ce processus, les données seront envoyées à l’API Gemini pour produire une analyse des données extraites, qui sera ensuite incluse dans le rapport.
Mise en place du projet sur GitHub
Sur la page d’accueil de GitHub, cliquez sur le bouton vert Nouveau pour créer un nouveau projet. Une fois que vous avez un projet vide, allez dans Réglages > Secrets et variables > Actions et ajoutez les secrets montrés dans l’image suivante.
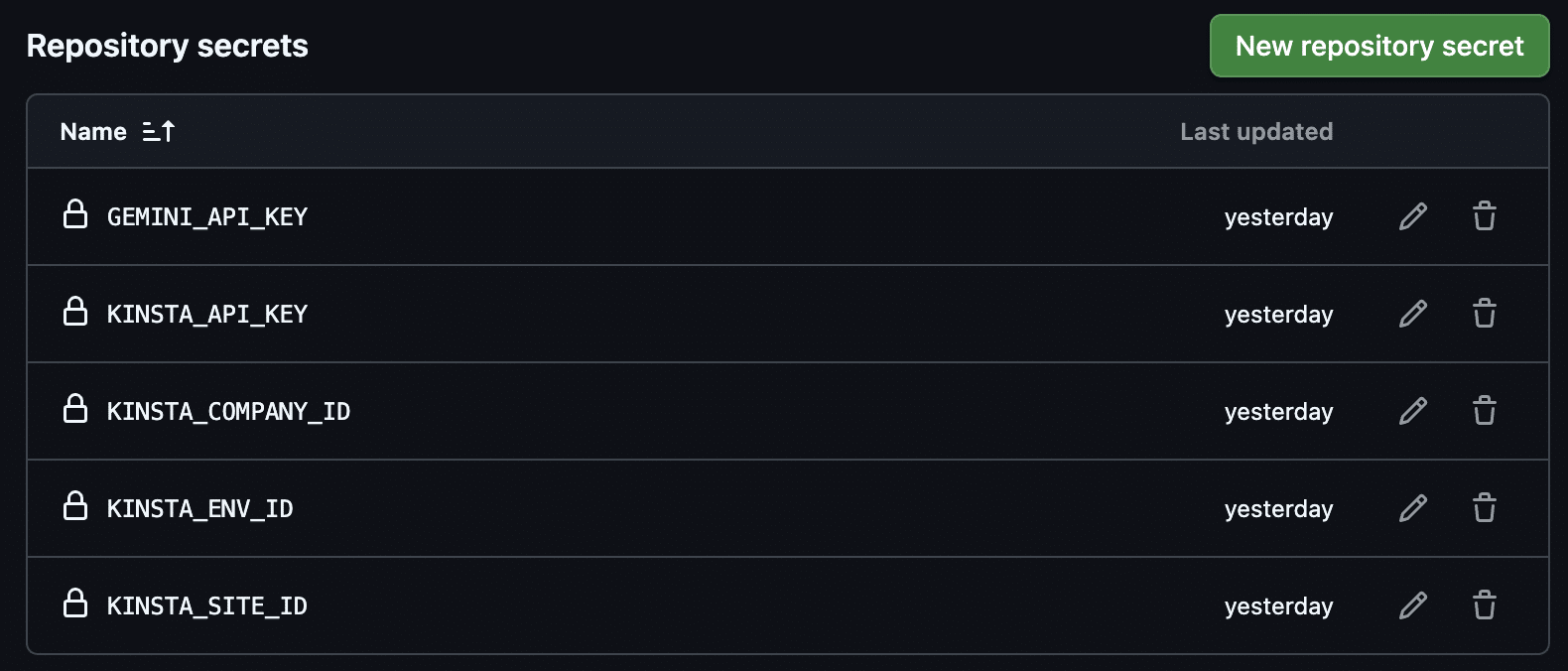
Le stockage de vos clés d’API et de vos identifiants dans GitHub Secrets les rend inaccessibles à quiconque et contribue à garantir la sécurité de votre code.
GEMINI_API_KEY
Vous pouvez générer une clé d’API Google AI dans le tableau de bord Google AI Studio. Pour plus d’informations, consultez la documentation de Google AI.
CLÉ D’API KINSTA
Ensuite, suivez les instructions de notre article pour générer une clé API Kinsta.
KINSTA_COMPANY_ID, KINSTA_ENV_ID, KINSTA_SITE_ID
Vous pouvez trouver l’ID du site, l’ID de l’environnement et l’ID de l’entreprise sous Sites > nom du site > Info dans votre tableau de bord MyKinsta.
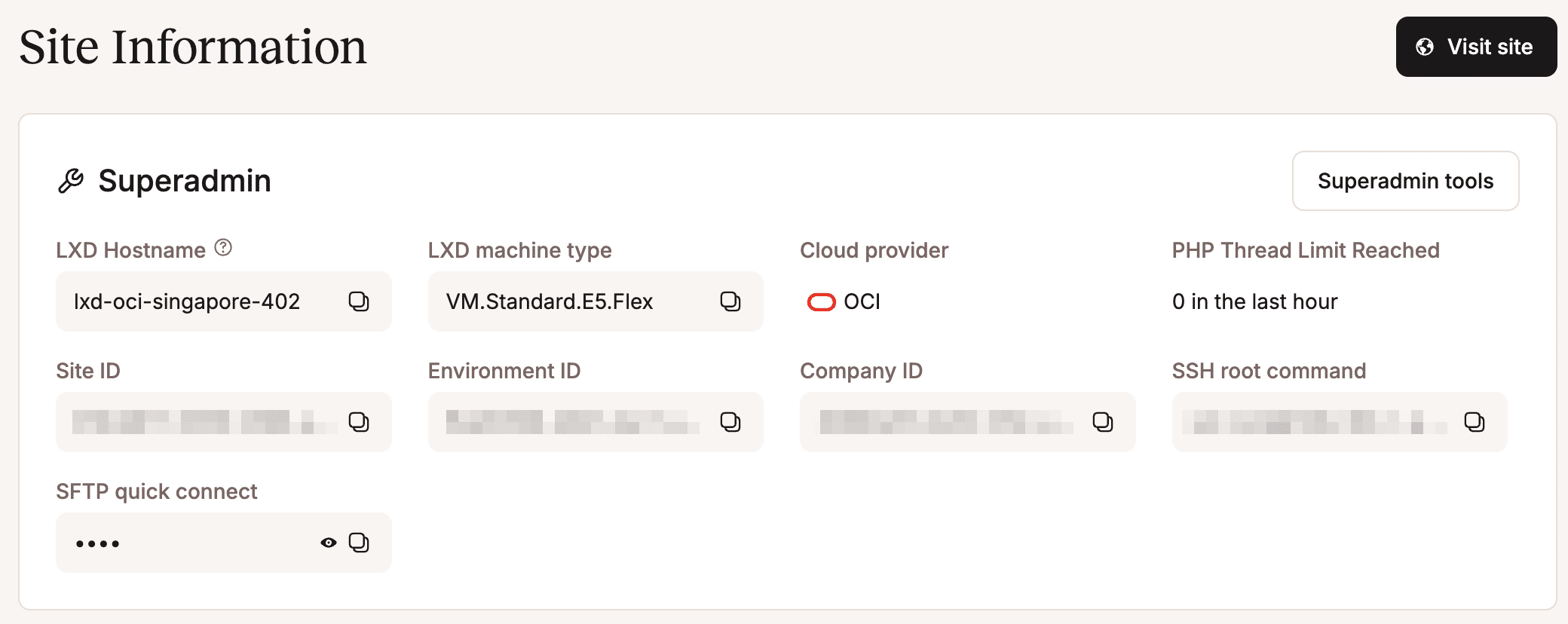
Passons maintenant aux fichiers du projet.
Bibliothèques nécessaires et configuration des actions GitHub
Dans le répertoire racine de votre projet GitHub, créez un fichier nommé requirements.txt et ajoutez-y ce qui suit :
google-genai
requests
matplotlib
fpdf2Ce fichier liste les composants nécessaires à votre projet.
google-genai: c’est la bibliothèque de Google pour interagir avec les modèles Gemini.requests: une bibliothèque pour effectuer des requêtes HTTP. Dans ce projet, elle sera utilisée pour envoyer des requêtes HTTP à l’API Kinsta.matplotlib: une bibliothèque Python pour créer des graphiques et visualiser des données.fpdf2: il s’agit d’une bibliothèque qui vous permet de générer des fichiers PDF.
Ensuite, créez un fichier nommé .github/workflows/generate_report.yml avec le code suivant :
name: Generate Kinsta Analytics Report
on:
push:
branches: [main]
workflow_dispatch:
jobs:
build-and-run:
runs-on: ubuntu-latest
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.12'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Report Script
env:
KINSTA_API_KEY: ${{ secrets.KINSTA_API_KEY }}
KINSTA_ENV_ID: ${{ secrets.KINSTA_ENV_ID }}
KINSTA_SITE_ID: ${{ secrets.KINSTA_SITE_ID }}
KINSTA_COMPANY_ID: ${{ secrets.KINSTA_COMPANY_ID }}
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
run: python main.py
- name: Upload Report
uses: actions/upload-artifact@v4
with:
name: Kinsta-Advanced-Report
path: "*.pdf"GitHub utilise ce fichier pour exécuter automatiquement votre code via GitHub Actions. Voyons cela de plus près :
name: Generate Kinsta Analytics Report
on:
push:
branches: [main]
workflow_dispatch:name: le nom de votre projet tel qu’il apparait dans l’onglet Actions sur GitHub.on: détermine quand déclencher le flux de travail.push: le flux de travail s’exécute chaque fois que vous transférez une modification de code vers la branche principale.workflow_dispatch: vous permet d’exécuter le flux de travail manuellement.
jobs:
build-and-run:
runs-on: ubuntu-latestjobs: le début des tâches à effectuer.build-and-run: un nom arbitraire qui identifie une séquence spécifique d’actions.runs-on: spécifie le système sur lequel le flux de travail doit s’exécuter.ubuntu-latest: définit la dernière version d’Ubuntu Linux.
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.12'steps: la séquence d’opérations à effectuer.name: le nom de l’opération à effectueruses: le module GitHub préconfiguré (Action)
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txtpython -m pip install --upgrade pip: met à jour pip (le gestionnaire de paquets Python) vers la dernière version disponible.pip install -r requirements.txt: lit le fichierrequirements.txtet installe les paquets qui y sont répertoriés.
- name: Run Report Script
env:
KINSTA_API_KEY: ${{ secrets.KINSTA_API_KEY }}
KINSTA_ENV_ID: ${{ secrets.KINSTA_ENV_ID }}
KINSTA_SITE_ID: ${{ secrets.KINSTA_SITE_ID }}
KINSTA_COMPANY_ID: ${{ secrets.KINSTA_COMPANY_ID }}
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
run: python main.pyenv: récupère les valeurs des variables d’environnement de GitHub Secrets.run: python main.py: lance l’interpréteur Python et exécute le fichiermain.py.
- name: Upload Report
uses: actions/upload-artifact@v4
with:
name: Kinsta-Advanced-Report
path: "*.pdf"uses: actions/upload-artifact@v4 : utilise l’action GitHub pour gérer les artefacts, un fichier ou un dossier généré pendant l’exécution du script.with: définit les réglages de configuration.
La configuration de votre projet d’automatisation est terminée. Il est maintenant temps de créer les scripts Python.
Interroger l’API Kinsta par programme
Une fois que vous avez terminé la configuration, naviguez vers le répertoire racine de votre projet GitHub et créez un nouveau fichier nommé kinsta_utils.py avec le code suivant :
import requests
import os
KINSTA_API_KEY = os.getenv("KINSTA_API_KEY")
KINSTA_SITE_ID = os.getenv("KINSTA_SITE_ID")
KINSTA_ENV_ID = os.getenv("KINSTA_ENV_ID")
KINSTA_COMPANY_ID = os.getenv("KINSTA_COMPANY_ID")
BASE_URL = f"https://api.kinsta.com/v2/sites/environments/{KINSTA_ENV_ID}/analytics"
def get_headers():
return {"Authorization": f"Bearer {KINSTA_API_KEY}"}- Les deux premières instructions d’
importationchargent la bibliothèque standard permettant d’effectuer des requêtes HTTP et le module permettant d’interagir avec le système d’exploitation (os). - Les quatre lignes suivantes (
os.getenv) récupèrent vos informations d’identification auprès de GitHub Secrets. BASE_URLdéfinit le point de terminaison principal de l’API Kinsta utilisé par le script.- La fonction
get_headersgénère l’en-tête d’autorisation, qui comprendra la clé de l’API Kinsta.
Ensuite, créez une fonction d’aide qui convertit les données brutes renvoyées par l’API en mégaoctets.
def format_bytes_to_mb(bytes_value):
"""Converts raw bytes from API to human-readable Megabytes."""
try:
# Standard conversion to MB
# return round(int(bytes_value) / (1024 * 1024), 2)
# Decimal standard (used in MyKinsta dashboard)
return round(int(bytes_value) / 1_000_000, 2)
except (ValueError, TypeError):
return 0- Ce code propose deux options. La première utilise la norme binaire (
1024 x 1024) et la seconde la norme décimale. La division par1_000_000garantit que le nombre dans votre rapport PDF correspond au nombre que vos clients verraient dans MyKinsta Analytics.
La fonction suivante interroge l’API Kinsta et renvoie un ensemble de données brutes :
def fetch_kinsta_metric(endpoint, start_date, end_date):
url = f"{BASE_URL}/{endpoint}"
params = {
"company_id": KINSTA_COMPANY_ID,
"from": f"{start_date}T00:00:00.000Z",
"to": f"{end_date}T23:59:59.000Z"
}
try:
response = requests.get(url, headers=get_headers(), params=params)
if response.status_code == 200:
data_node = response.json()['analytics']['analytics_response']['data'][0]
total = data_node.get('total', 0)
dataset = data_node.get('dataset', [])[:7]
return total, dataset
except Exception as e:
print(f"Error fetching {endpoint}: {e}")
return 0, []- La fonction
fetch_kinsta_metricprend trois arguments :endpoint,start_dateetend_date. Ceux-ci sont utilisés pour construire l’URL de la requête. Le point de terminaison peut êtrevisits,bandwidthoucdn-bandwidth. - Le tableau
paramscontient les paramètres de la requête. - La réponse de Kinsta est un objet JSON imbriqué (
data_node) qui fournit les valeurs agrégées pour la période (total) et une liste de valeurs quotidiennes (dataset).
La dernière fonction du fichier kinsta_utils.py récupère le nom du site.
def fetch_site_name():
url = f"https://api.kinsta.com/v2/sites/{KINSTA_SITE_ID}"
try:
response = requests.get(url, headers=get_headers())
if response.status_code == 200:
data = response.json()
site_data = data.get('site', {})
site_label = site_data.get('display_name', 'Unknown Site')
env_label = "Unknown Env"
envs = site_data.get('environments', [])
for env in envs:
if env.get('id') == KINSTA_ENV_ID:
env_label = env.get('display_name')
break
return f"{site_label} ({env_label})"
else:
print(f"Kinsta API Error: {response.status_code} - {response.text}")
except Exception as e:
print(f"Error fetching site name: {e}")
return "Unknown Site"Ce code devrait être explicite. Veuillez vous référer à la référence de l’API pour plus de détails sur le point de terminaison sites.
Il ne reste plus qu’à mettre en place le flux de travail.
Automatiser le flux de travail avec Python et Gemini
Le dernier fichier que vous devez créer est le moteur de votre application. Toujours dans le répertoire racine de votre projet GitHub, créez un fichier main.py. Pour commencer, ajoutez le code suivant :
import os
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from google.genai import Client
from fpdf import FPDF, XPos, YPos
from datetime import datetime, timedelta
from kinsta_utils import fetch_kinsta_metric, format_bytes_to_mb, fetch_site_name
REPORT_LANG = "en"
MODEL_ID = "gemini-2.5-flash"
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
client = Client(api_key=GEMINI_API_KEY)
today = datetime.now()
curr_end_dt = today - timedelta(days=1)
curr_start_dt = today - timedelta(days=7)
prev_end_dt = today - timedelta(days=8)
prev_start_dt = today - timedelta(days=14)
CURR_RANGE = f"{curr_start_dt.strftime('%b %d')} - {curr_end_dt.strftime('%b %d')}"
PREV_RANGE = f"{prev_start_dt.strftime('%b %d')} - {prev_end_dt.strftime('%b %d')}"
DATES = [
prev_start_dt.strftime("%Y-%m-%d"),
prev_end_dt.strftime("%Y-%m-%d"),
curr_start_dt.strftime("%Y-%m-%d"),
curr_end_dt.strftime("%Y-%m-%d")
]
CURR_DAYS_LABELS = [(curr_start_dt + timedelta(days=i)).strftime("%d %a") for i in range(7)]
PREV_DAYS_LABELS = [(prev_start_dt + timedelta(days=i)).strftime("%d %a") for i in range(7)]
X_AXIS_LABELS = [(curr_start_dt + timedelta(days=i)).strftime("%d") for i in range(7)]Voici comment le script est configuré :
- Les déclarations
importchargent les bibliothèques nécessaires, etmatplotlib.use('Agg')demande à Python de générer les graphiques et de les garder en mémoire. - Le bloc suivant définit la langue (
en) et le modèle (gemini-2.5-flash), puis initialise le client Google. - Il définit ensuite des fenêtres temporelles pour comparer les valeurs des sept derniers jours avec celles des sept jours précédents.
- Enfin, il définit les libellés des tableaux et des graphiques.
L’étape suivante consiste à définir une classe KinstaReport pour générer des pages de rapport à l’aide de la bibliothèque FPDF :
class KinstaReport(FPDF):
def __init__(self, site_name="Unknown Site"):
super().__init__()
self.site_name = site_name
def header(self):
self.set_font("Helvetica", "B", 8)
self.set_text_color(150)
# Site name
self.cell(100, 10, f"Site: {self.site_name}", align="L")
# Date generated
self.cell(0, 10, f"Kinsta Analytics Report | Generated: {datetime.now().strftime('%Y-%m-%d')}",
align="R", new_x=XPos.LMARGIN, new_y=YPos.NEXT)
def add_metric_page(self, title, chart_path, prev_vals, curr_vals, unit=""):
self.add_page()
# Page title
self.set_font("Helvetica", "B", 24)
self.set_text_color(83, 51, 237)
self.cell(0, 15, title, align="C", new_x=XPos.LMARGIN, new_y=YPos.NEXT)
# Subtitle
self.set_font("Helvetica", "I", 10)
self.set_text_color(120)
self.cell(0, 5, f"Comparison: {CURR_RANGE} vs {PREV_RANGE}", align="C", new_x=XPos.LMARGIN, new_y=YPos.NEXT)
self.image(chart_path, x=10, y=42, w=190)
# Data tables
self.set_y(150)
self.set_font("Helvetica", "B", 10)
self.set_fill_color(245, 245, 255)
self.set_text_color(83, 51, 237)
# Table header
col1, col2 = 35, 60
self.cell(col1, 10, " Day (Prev)", border=1, align='C', fill=True, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col2, 10, f"Value {unit}", border=1, align='C', fill=True, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col1, 10, " Day (Curr)", border=1, align='C', fill=True, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col2, 10, f"Value {unit}", border=1, align='C', fill=True, new_x=XPos.LMARGIN, new_y=YPos.NEXT)
self.set_font("Helvetica", "", 10)
self.set_text_color(50)
for i in range(7):
# Zebra striping
fill = (i % 2 == 0)
if fill: self.set_fill_color(250, 250, 250)
else: self.set_fill_color(255, 255, 255)
self.cell(col1, 9, f" {PREV_DAYS_LABELS[i]}", border=1, align='C', fill=fill, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col2, 9, f" {prev_vals[i]}", border=1, align='C', fill=fill, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col1, 9, f" {CURR_DAYS_LABELS[i]}", border=1, align='C', fill=fill, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col2, 9, f" {curr_vals[i]}", border=1, align='C', fill=fill, new_x=XPos.LMARGIN, new_y=YPos.NEXT)Nous n’entrerons pas dans les détails de ce code. Pour plus d’informations sur la bibliothèque FPDF, veuillez vous référer aux ressources en ligne :
Définissez ensuite la fonction generated_chart. Cette fonction convertit les données brutes reçues de Kinsta en graphiques.
def generate_chart(labels, curr, prev, title, ylabel, filename, is_bar=False):
plt.figure(figsize=(10, 5), dpi=100)
ax = plt.gca()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_color('#dddddd')
ax.spines['bottom'].set_color('#dddddd')
if is_bar:
# Bar Chart for bandwidth
bars = plt.bar(labels, curr, color='#00c4b4', alpha=0.6, label='Current Period', width=0.6)
# Add labels above the bars
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height + 0.02, f'{height}', ha='center', va='bottom', fontsize=8, color='#00a194')
else:
# Line chart for visits
plt.plot(labels, curr, color='#5333ed', marker='o', markersize=6, linewidth=3, label='Current', zorder=3)
plt.plot(labels, prev, color='#a1a1a1', linestyle='--', marker='x', markersize=5, linewidth=1.5, label='Previous', alpha=0.6)
plt.fill_between(labels, curr, color='#5333ed', alpha=0.1)
plt.title(title, fontsize=14, pad=20, color='#333333', fontweight='bold')
plt.ylabel(ylabel, color='#666666')
plt.xlabel("Day of Month", color='#666666')
plt.legend(frameon=False, loc='upper right')
plt.grid(axis='y', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.savefig(filename)
plt.close()Cette fonction utilise la bibliothèque Matplotlib pour convertir les données extraites de Kinsta en graphiques à inclure dans le rapport PDF. Pour plus d’informations sur l’utilisation de la bibliothèque Matplotlib, veuillez vous référer à la documentation en ligne :
Enfin, ajoutez la fonction qui combine toutes les parties que nous avons décrites jusqu’à présent.
def main():
site_display_name = fetch_site_name()
metrics = {
"visits": {"title": "Site Visits", "unit": ""},
"bandwidth": {"title": "Server Bandwidth", "unit": "(MB)"},
"cdn-bandwidth": {"title": "CDN Bandwidth", "unit": "(MB)"}
}
report_data = {}
for key in metrics:
_, data_curr = fetch_kinsta_metric(key, DATES[2], DATES[3])
_, data_prev = fetch_kinsta_metric(key, DATES[0], DATES[1])
curr_vals = []
prev_vals = []
for i in range(7):
c = float(data_curr[i]['value']) if i < len(data_curr) else 0
p = float(data_prev[i]['value']) if i < len(data_prev) else 0
if "bandwidth" in key:
curr_vals.append(format_bytes_to_mb(c))
prev_vals.append(format_bytes_to_mb(p))
else:
curr_vals.append(int(c))
prev_vals.append(int(p))
report_data[key] = {"curr": curr_vals, "prev": prev_vals}
pdf = KinstaReport(site_name=site_display_name)
for key, info in metrics.items():
chart_file = f"{key}_chart.png"
generate_chart(X_AXIS_LABELS, report_data[key]["curr"], report_data[key]["prev"],
f"{info['title']} Trends", "Units", chart_file, is_bar=("bandwidth" in key))
pdf.add_metric_page(info["title"], chart_file, report_data[key]["prev"], report_data[key]["curr"], info["unit"])
# Executive Summary
pdf.add_page()
pdf.set_font("Helvetica", "B", 20)
pdf.set_text_color(83, 51, 237)
pdf.cell(0, 15, "Executive Summary", align="C", new_x=XPos.LMARGIN, new_y=YPos.NEXT)
curr_visits = sum(report_data['visits']['curr'])
prev_visits = sum(report_data['visits']['prev'])
curr_bw = sum(report_data['bandwidth']['curr'])
prev_bw = sum(report_data['bandwidth']['prev'])
try:
summary_prompt = (
f"Analyze Kinsta performance for site {site_display_name}. "
f"Current Period ({CURR_RANGE}): {curr_visits} visits, {curr_bw:.2f}MB server bandwidth. "
f"Previous Period ({PREV_RANGE}): {prev_visits} visits, {prev_bw:.2f}MB server bandwidth. "
f"Compare these periods and identify trends. Language: {REPORT_LANG}. Max 4 sentences."
)
response = client.models.generate_content(model=MODEL_ID, contents=summary_prompt)
summary = response.text
except Exception as e:
summary = f"Analytical insights unavailable. Error: {str(e)}"
pdf.set_y(40)
pdf.set_font("Helvetica", "", 12)
pdf.set_text_color(0)
pdf.multi_cell(0, 8, summary)
report_filename = f"Kinsta_Report_{datetime.now().strftime('%Y-%m-%d')}.pdf"
pdf.output(report_filename)
print(f"Report generated: {report_filename}")
if __name__ == "__main__":
main()Voici ce que fait ce code :
- La boucle
forparcourt le tableau demetricset interroge l’API Kinsta deux fois : une fois pour la semaine en cours et une fois pour la semaine précédente. - Si les données concernent la bande passante, la fonction
format_bytes_to_mb()convertit les données brutes en Mo. - La fonction
report_data()stocke les données récupérées. KinstaReportcrée ensuite un PDF pour chaque site.- La boucle
forsuivante génère des images PNG pour les graphiques et crée une nouvelle page pour chaque mesure. - La section suivante génère le résumé, calcule le nombre total de visites et le nombre total de mégaoctets pour la période, et envoie une invite dynamique à Gemini 2.5 Flash. Enfin, la réponse est utilisée pour compléter la dernière page du PDF.
- Le script enregistre le document avec un nom de fichier qui inclut la date du jour.
- * La condition finale garantit que le processus ne s’exécute que lorsque le script est exécuté en tant que programme principal.
Il est temps de créer et d’exécuter votre application.
Récupération de l’artefact
Vous pouvez maintenant exécuter votre application. Sur la page de votre projet GitHub, cliquez sur l’onglet Actions. Recherchez le nom de votre action dans le menu de gauche (dans notre exemple, il s’agit de Generate Kinsta Analytics Report, comme spécifié dans votre fichier generate_report.yml).
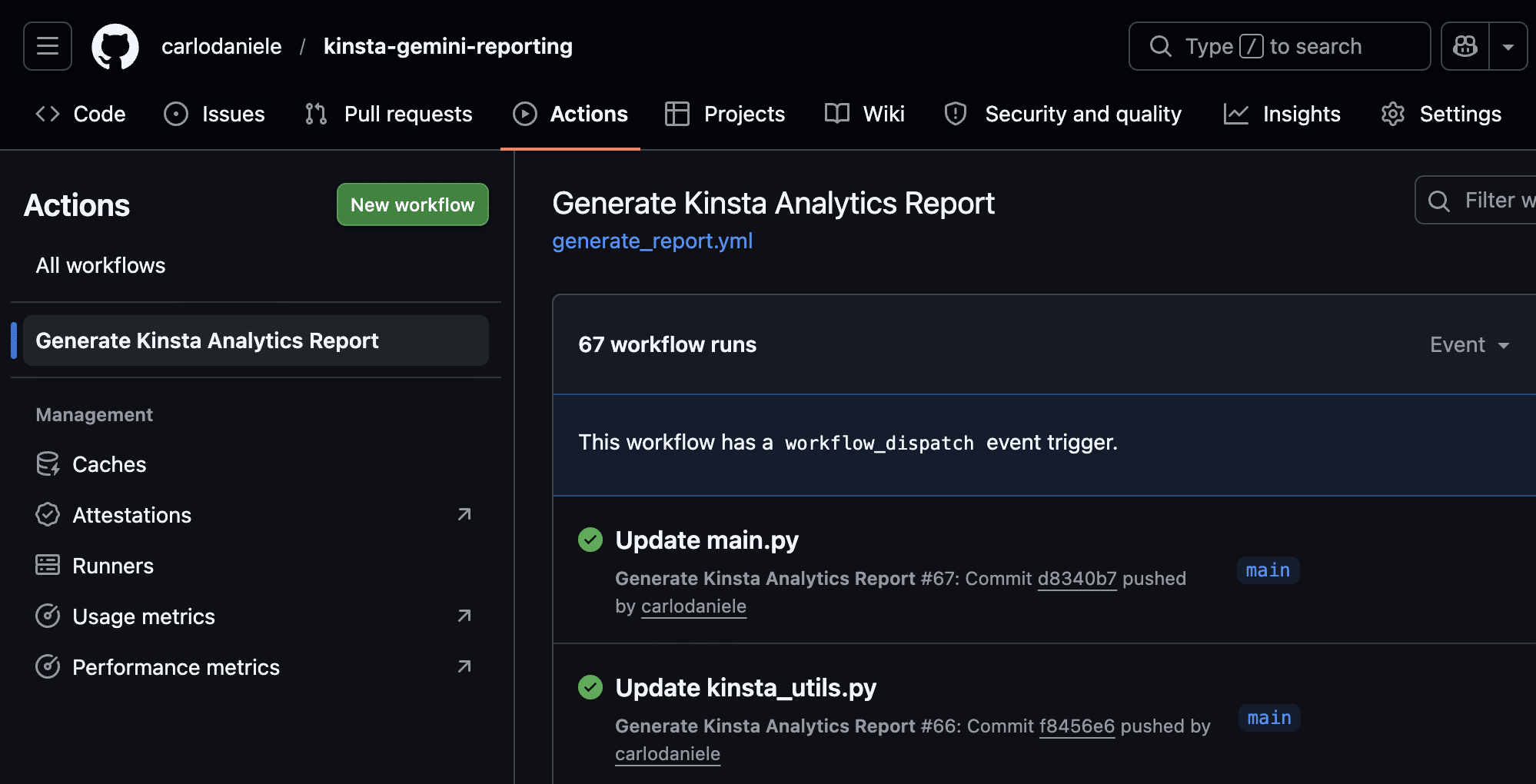
Ensuite, cliquez sur le menu Run workflow à droite, puis sur le bouton vert Run workflow (seule la branche principale est actuellement disponible).
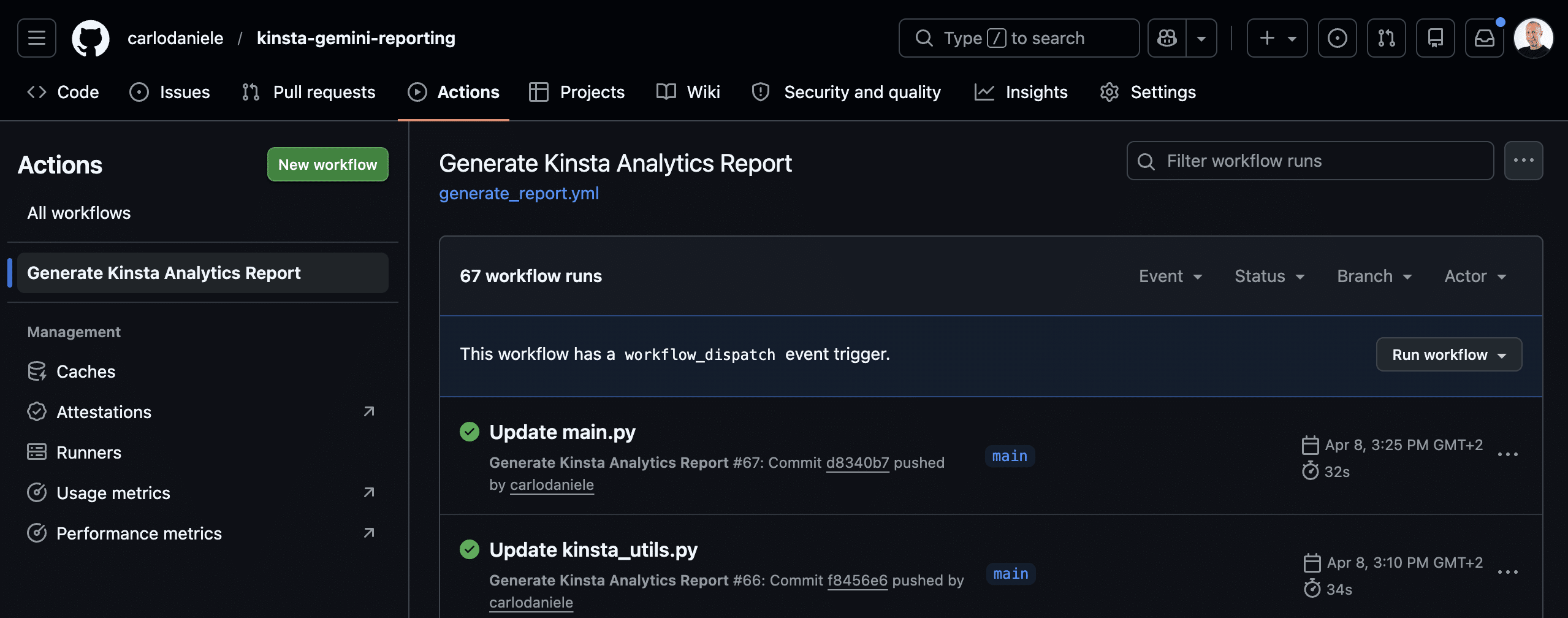
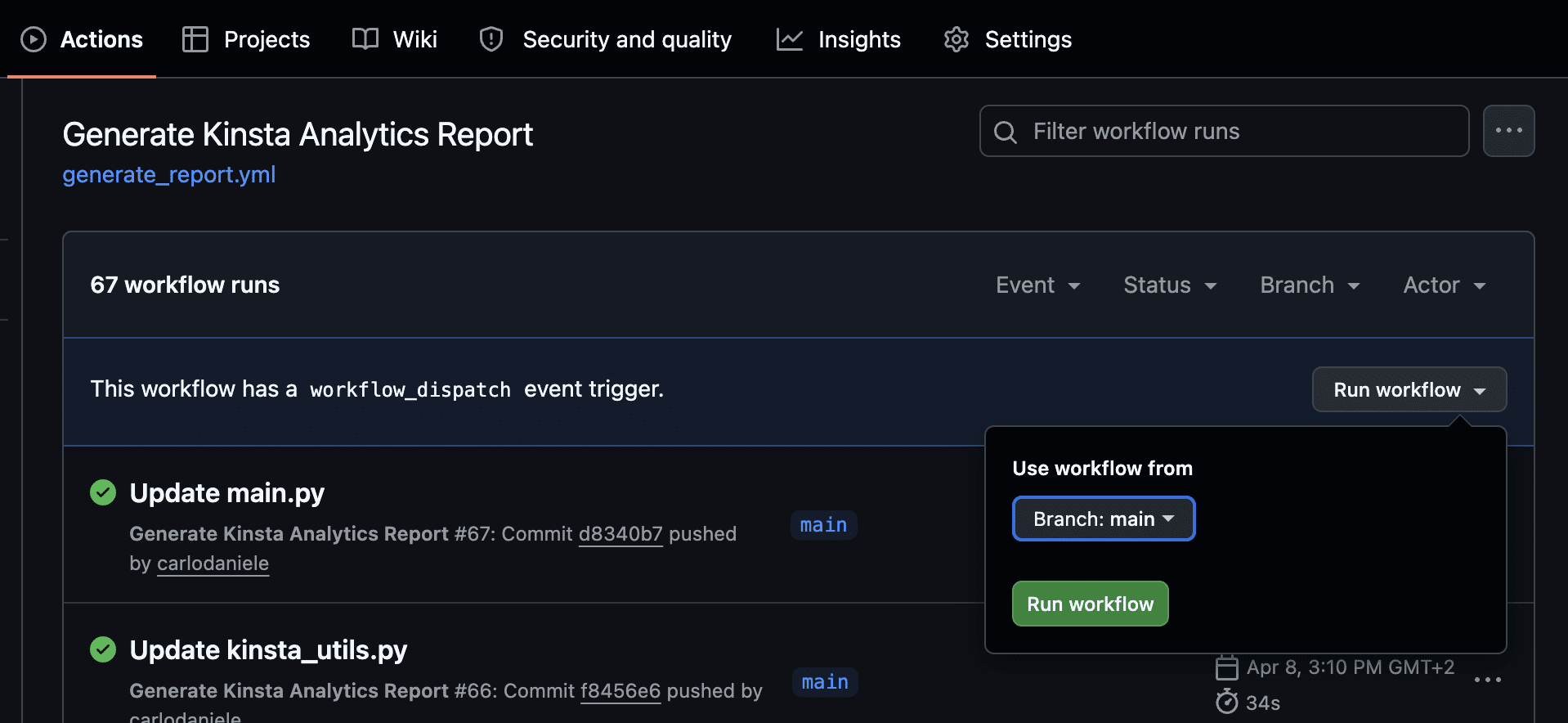
La page suivante montre le flux de travail actuel. Cliquez dessus pour afficher la liste des opérations en cours.
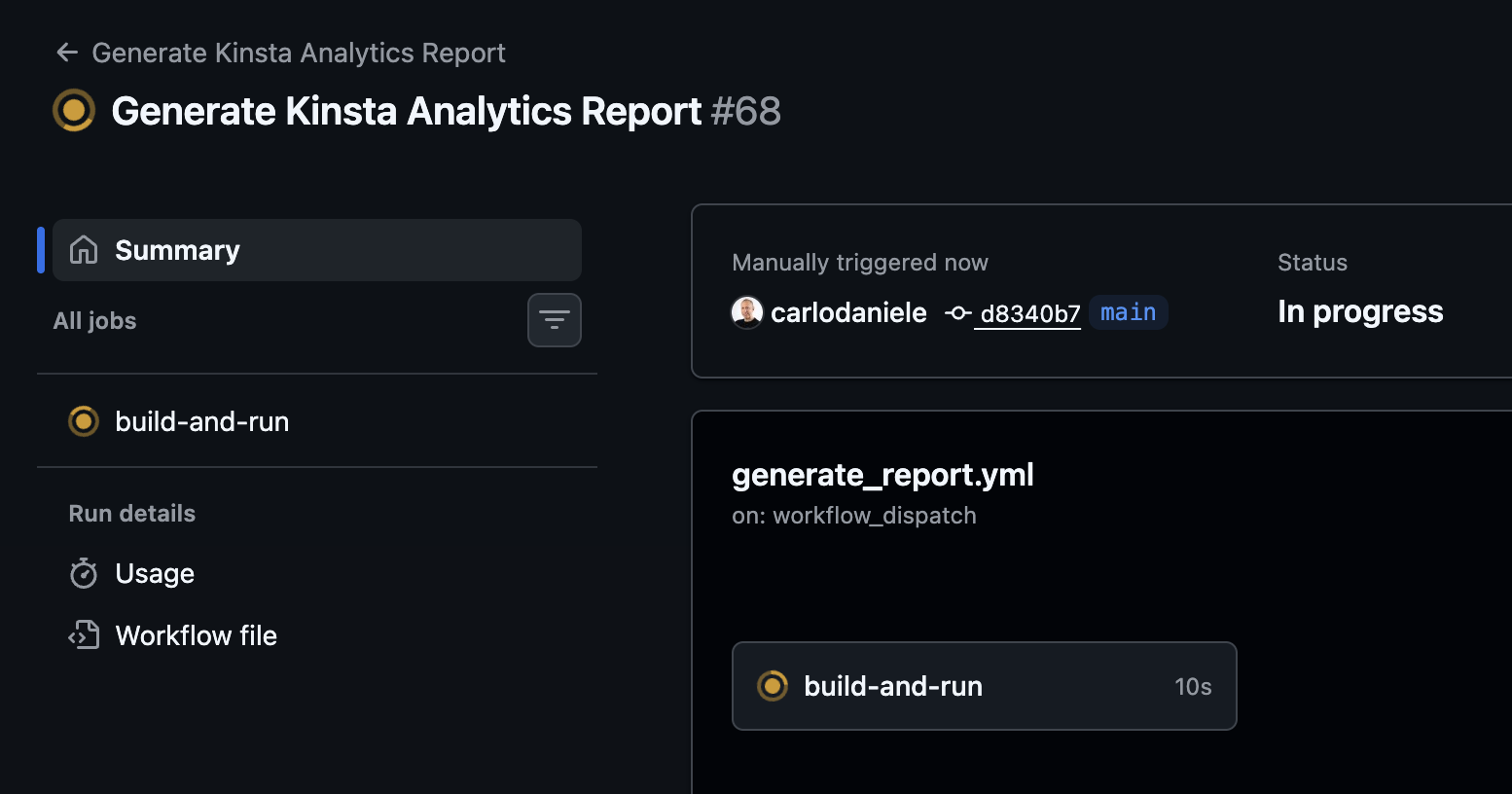
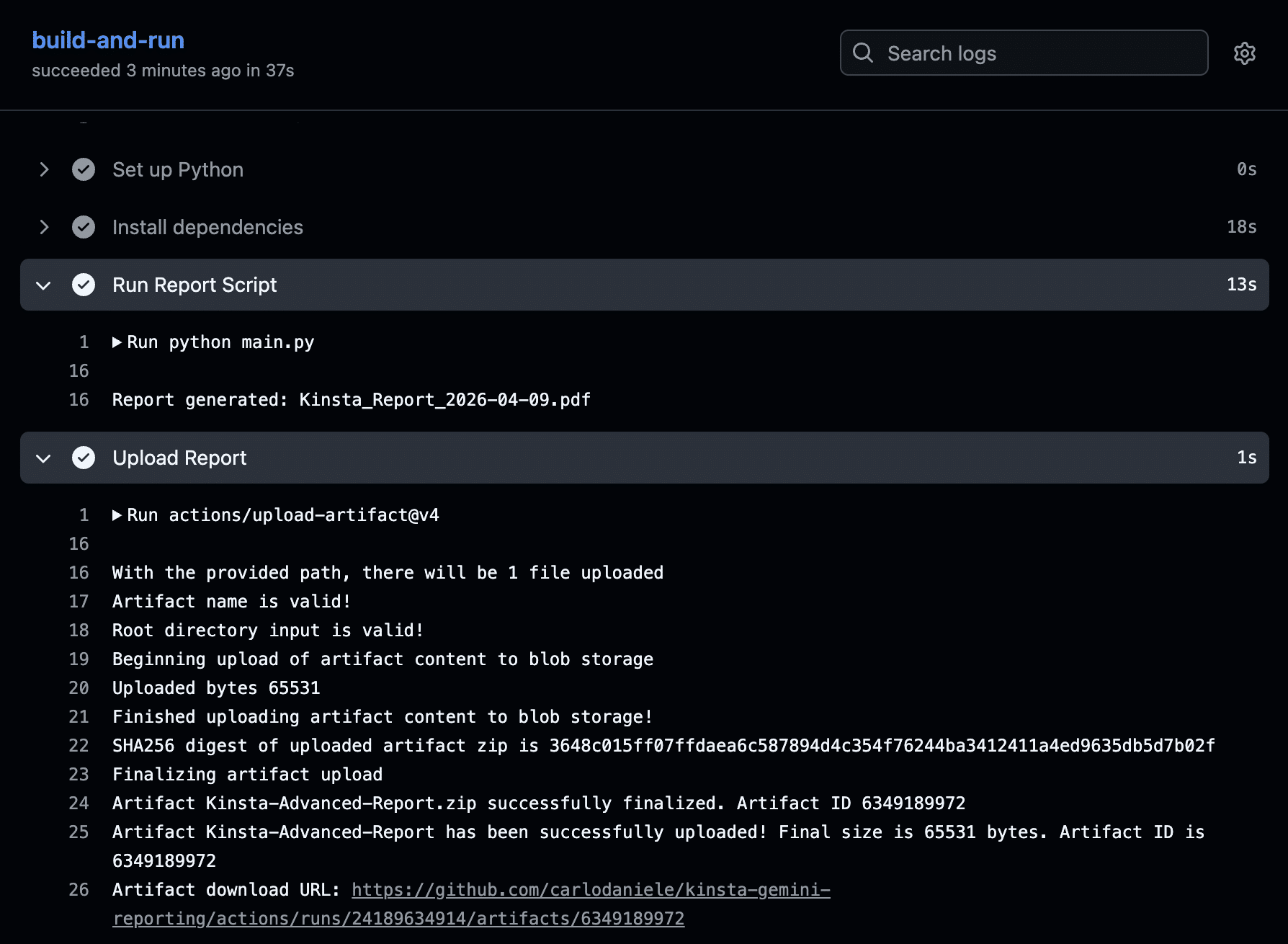
La section Exécuter le script du rapport fournit une liste des opérations effectuées, tandis que la section Téléverser le rapport fournit l’URL de téléchargement de l’artefact. Cliquez sur ce lien pour télécharger votre rapport au format PDF.
Vous trouverez le même lien dans la section Artéfacts, au bas de la page Résumé du flux de travail.
Les images ci-dessous montrent le rapport complet, y compris le résumé généré par Google AI.
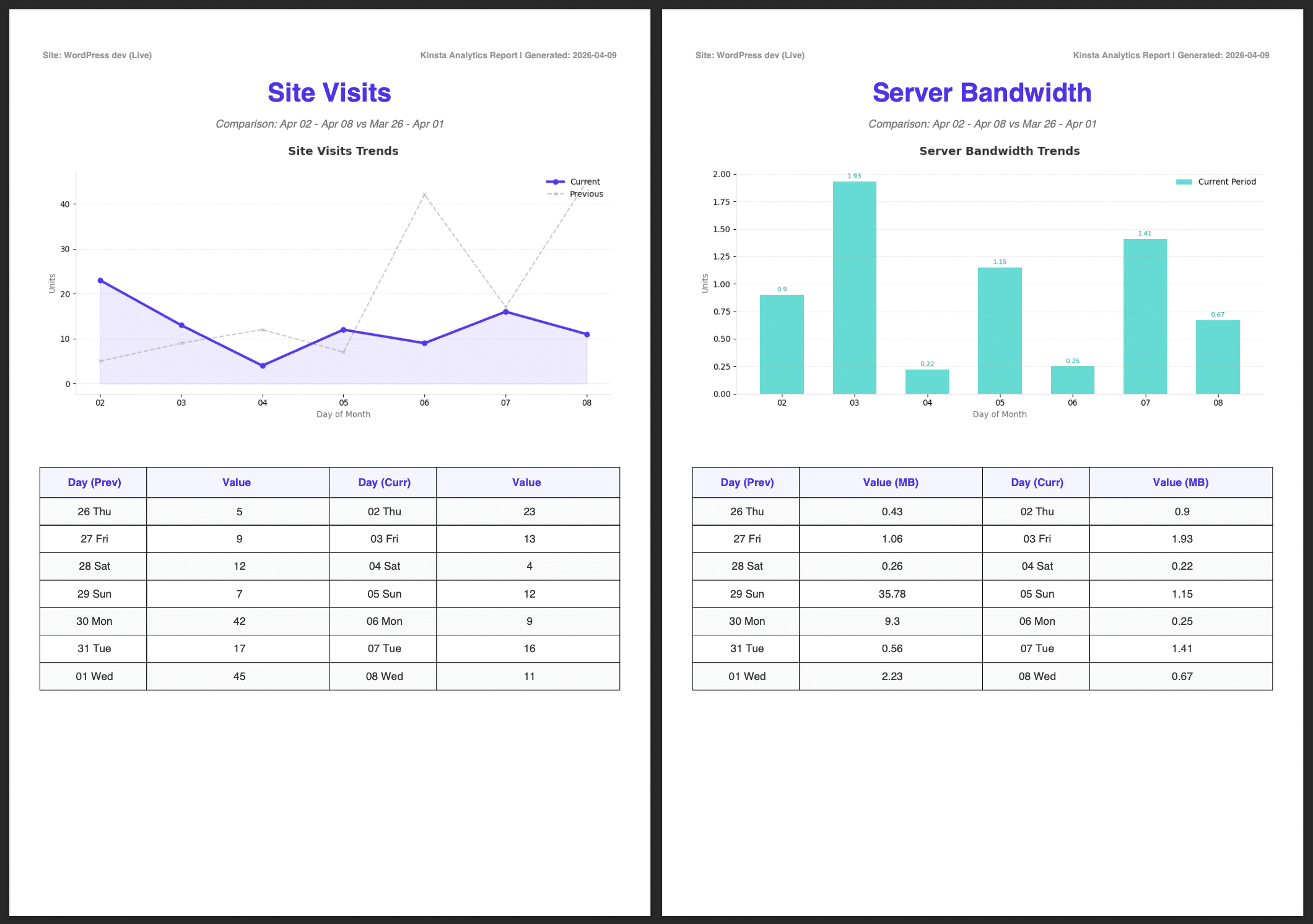
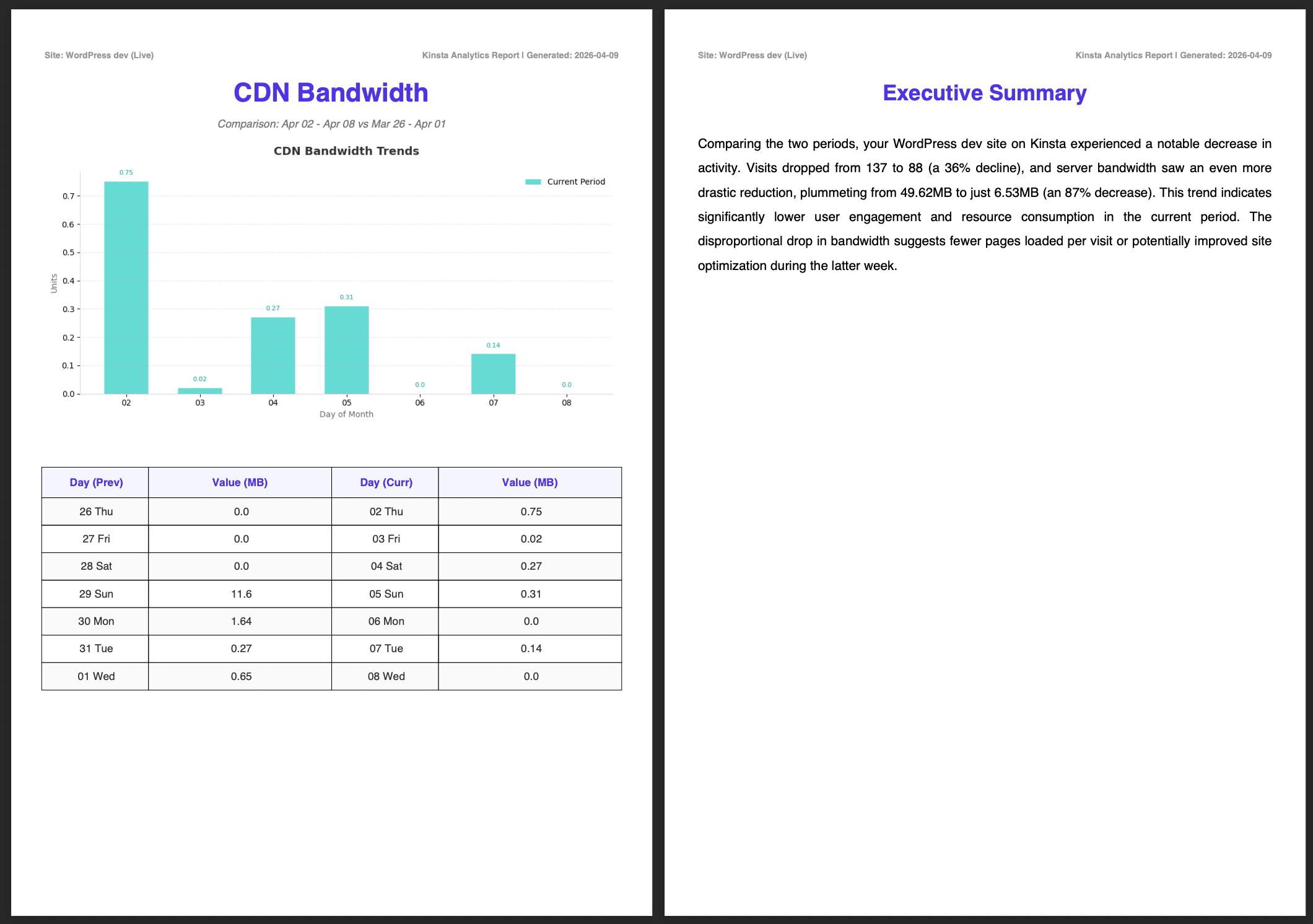
Prochaines étapes : Comment améliorer l’évolutivité et automatiser la livraison
Ce n’est qu’un avant-goût de ce que l’API Kinsta peut faire lorsqu’elle est associée à des outils d’automatisation avancés tels que GitHub Actions. L’intégration de l’IA va plus loin, transformant les chiffres bruts en rapports approfondis prêts à être partagés avec vos clients.
Vous pouvez améliorer vos rapports de plusieurs façons :
- Vous pouvez configurer votre application en ajoutant une ligne au fichier YAML (
schedule : '0 9 * * 1') pour générer le rapport tous les lundis matin à 9h00. - Vous pouvez intégrer une bibliothèque comme
smtplibou un service comme SendGrid pour envoyer le rapport directement à votre client. - Si vous êtes une agence possédant des dizaines, voire des centaines de sites, vous pouvez mettre en œuvre une boucle qui itère sur une liste d’identifiants de sites pour générer tous vos rapports en une seule fois.
- Vous pouvez enrichir le contenu de votre rapport en utilisant l’API de Kinsta pour récupérer des données géographiques, des ventilations de code HTTP, des journaux de serveur et toute autre donnée que vous souhaitez inclure. En analysant ces données, l’IA peut identifier les tentatives d’attaque (codes 4xx) ou les pics de trafic provenant de régions inattendues.
- Vous pouvez affiner votre demande pour obtenir des réponses plus détaillées et plus complètes de l’IA.
- Vous pouvez personnaliser le modèle PDF avec les logos de votre agence et de votre client.
Les rapports automatisés réduisent la charge de travail de votre équipe, et la cohérence et la précision qu’ils apportent renforcent la confiance et la fidélité de vos clients.
Vous voulez commencer à automatiser vos rapports clients dès maintenant ? Souscrivez au plan qui correspond le mieux à vos besoins et commencez à construire avec l’API Kinsta dès aujourd’hui.

Carlo est un passionné de webdesign et de développement frontend. Il joue avec WordPress depuis plus de 10 ans, notamment en collaboration avec des universités et des établissements d'enseignement italiens et européens. Il a écrit des dizaines d'articles et de guides sur WordPress, publiés à la fois sur des sites web italiens et internationaux, ainsi que dans des magazines imprimés. Vous pouvez trouver Carlo sur X et LinkedIn.