
Dans le monde actuel axé sur les données, où le volume et la complexité des données continuent de croître à un rythme sans précédent, le besoin de solutions de bases de données robustes et évolutives est devenu primordial. On estime que 180 zettaoctets de données seront créés d’ici 2025. Il s’agit là de chiffres importants à prendre en compte.
À mesure que les données et la demande des utilisateurs montent en flèche, il n’est plus possible de s’appuyer sur une seule base de données. Cela ralentit votre système et surcharge les développeurs. Vous pouvez adopter diverses solutions pour optimiser votre base de données, comme le partage de base de données.
Dans ce guide complet, nous nous plongeons dans les profondeurs du sharding MongoDB, en démystifiant ses avantages, ses composants, ses meilleures pratiques, ses erreurs courantes et la manière dont vous pouvez commencer.
Qu’est-ce que le sharding de base de données ?
Le sharding de base de données est une technique de gestion de base de données qui consiste à partitionner horizontalement une base de données en croissance en unités plus petites et plus faciles à gérer, connues sous le nom de shards.
Au fur et à mesure que votre base de données se développe, il devient pratique de la diviser en plusieurs parties plus petites et de stocker chaque partie séparément sur des machines différentes. Ces parties plus petites, ou « « shards », sont des sous-ensembles indépendants de la base de données globale. C’est ce processus de division et de distribution des données qui constitue la division de la base de données.
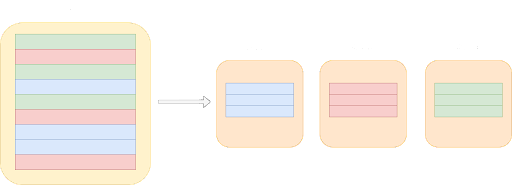
Lors de la mise en œuvre d’une base de données partagée, il existe deux approches principales : développer une solution de partage personnalisée ou payer pour une solution existante. La question se pose alors de savoir s’il est préférable de développer une solution de sharding ou de payer pour une telle solution.

Pour faire ce choix, vous devez prendre en compte le coût de l’intégration d’une tierce partie, en gardant à l’esprit les facteurs suivants :
- Compétences des développeurs et facilité d’apprentissage : La courbe d’apprentissage associée au produit et son adéquation avec les compétences de vos développeurs.
- Le modèle de données et l’API proposés par le système : Chaque système de données a sa propre façon de représenter ses données. La commodité et la facilité avec lesquelles vous pouvez intégrer vos applications au produit est un facteur clé à prendre en compte.
- Assistance à la clientèle et documentation en ligne : Si vous rencontrez des difficultés ou si vous avez besoin d’aide pendant l’intégration, la qualité et la disponibilité de l’assistance à la clientèle et d’une documentation en ligne complète sont cruciales.
- Disponibilité du déploiement dans le cloud : Étant donné que de plus en plus d’entreprises passent au cloud, il est important de déterminer si le produit tiers peut être déployé dans un environnement cloud.
Sur la base de ces facteurs, vous pouvez maintenant décider de construire une solution de sharding ou de payer pour une solution qui fait le gros du travail à votre place.
Aujourd’hui, la plupart des bases de données disponibles sur le marché prennent en charge le sharding de base de données. Par exemple, les bases de données relationnelles comme MariaDB (qui fait partie de la pile de serveurs haute performance de Kinsta) et les bases de données NoSQL comme MongoDB.
Qu’est-ce que le sharding dans MongoDB ?
L’objectif principal de l’utilisation d’une base de données NoSQL est sa capacité à répondre aux exigences de calcul et de stockage pour l’interrogation et le stockage d’énormes volumes de données.
En général, une base de données MongoDB contient un grand nombre de collections. Chaque collection est constituée de divers documents contenant des données sous la forme de paires clé-valeur. Vous pouvez diviser cette grande collection en plusieurs collections plus petites à l’aide de MongoDB sharding. Cela permet à MongoDB d’effectuer des requêtes sans trop solliciter le serveur.
Par exemple, Telefónica Tech gère plus de 30 millions d’appareils IoT dans le monde. Pour faire face à l’augmentation constante de l’utilisation des appareils, l’entreprise avait besoin d’une plateforme capable de s’adapter de manière élastique et de gérer un environnement de données en croissance rapide. La technologie sharding de MongoDB était le bon choix pour eux, car elle correspondait le mieux à leurs besoins en termes de coûts et de capacité.
Avec le sharding de MongoDB, Telefónica Tech exécute plus de 115.000 requêtes par seconde. Cela représente 30 000 insertions dans la base de données par seconde, avec moins d’une milliseconde de latence !
Avantages du sharding MongoDB
Voici quelques avantages du sharding MongoDB pour les données à grande échelle dont vous pouvez profiter :
Capacité de stockage
Nous avons déjà vu que le sharding permet de répartir les données entre les différentes unités du cluster. Grâce à cette répartition, chaque arbre contient un fragment de l’ensemble des données de la grappe. Des disques supplémentaires augmenteront la capacité de stockage du cluster au fur et à mesure que la taille de votre ensemble de données augmentera.
Lecture/écriture
MongoDB répartit la charge de travail de lecture et d’écriture sur les tessons d’un cluster partagé, ce qui permet à chaque tesson de traiter un sous-ensemble d’opérations du cluster. Les deux charges de travail peuvent être mises à l’échelle horizontalement dans le cluster en ajoutant des shards supplémentaires.
Haute disponibilité
Le déploiement de grappes et de serveurs de configuration en tant qu’ensembles de répliques offre une disponibilité accrue. Désormais, même si un ou plusieurs jeux de répliques sont totalement indisponibles, le cluster partagé peut effectuer des lectures et des écritures partielles.
Protection contre les pannes
De nombreux utilisateurs sont affectés lorsqu’une machine tombe en panne à la suite d’un arrêt non planifié. Dans un système non partagé, la base de données entière ayant été interrompue, l’impact est massif. Le rayon d’action d’une mauvaise expérience/impact utilisateur peut être contenu grâce au sharding MongoDB.
Géodistribution et performances
Les serveurs répliqués peuvent être placés dans différentes régions. Cela signifie que les clients peuvent bénéficier d’un accès à leurs données avec une faible latence, c’est-à-dire que les requêtes des consommateurs peuvent être redirigées vers le shard le plus proche. En fonction de la politique de gouvernance des données d’une région, il est possible de configurer des serveurs spécifiques pour qu’ils soient placés dans une région donnée.
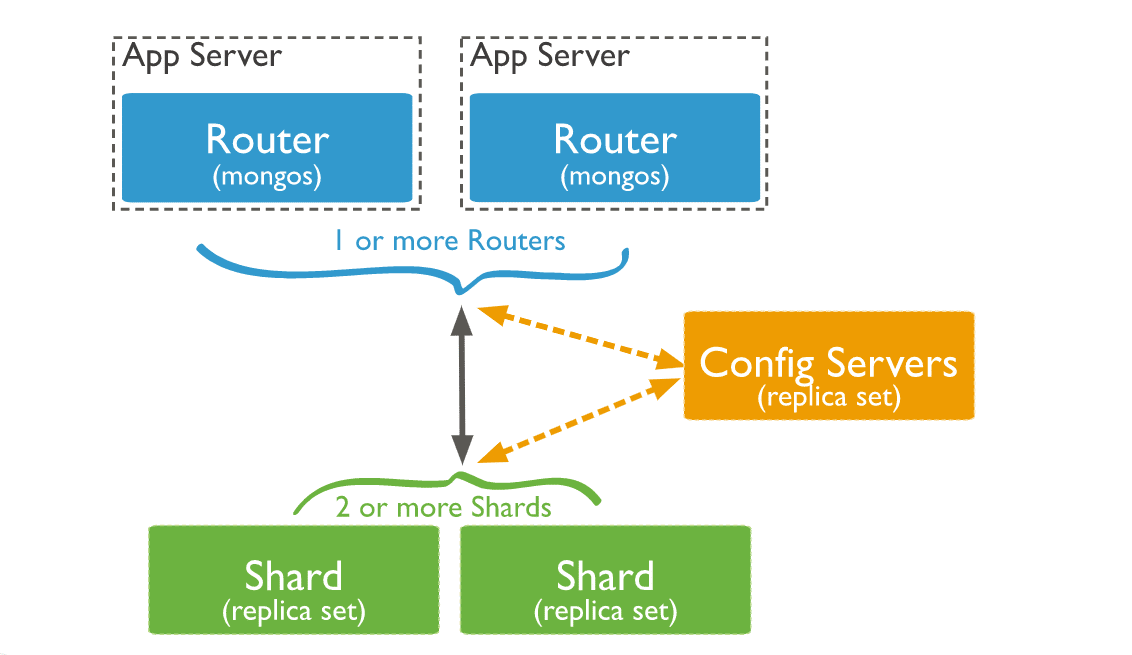
Composants des clusters MongoDB Sharded
Après avoir expliqué le concept d’un cluster MongoDB sharded, nous allons nous pencher sur les composants de ces clusters.
1. Shard
Chaque shard possède un sous-ensemble de données partagées. À partir de MongoDB 3.6, les shards doivent être déployés en tant qu’ensemble de répliques afin d’assurer une haute disponibilité et une redondance.
Chaque base de données dans le cluster partagé a un shard primaire qui contiendra toutes les collections non partagées pour cette base de données. Le premier dépôt n’est pas lié au premier dépôt d’un ensemble de répliques.
Pour modifier le shard primaire d’une base de données, vous pouvez utiliser la commande movePrimary. Le processus de migration du shard primaire peut prendre beaucoup de temps.
Pendant cette période, vous ne devez pas essayer d’accéder aux collections associées à la base de données tant que le processus de migration n’est pas terminé. Ce processus peut avoir un impact sur les opérations globales du cluster en fonction de la quantité de données en cours de migration.
Vous pouvez utiliser la méthode sh.status() de mongosh pour consulter la vue d’ensemble du cluster. Cette méthode renvoie le shard principal de la base de données ainsi que la répartition des morceaux entre les shards.
2. Configurations de serveurs
Le déploiement de serveurs de configuration pour les clusters partagés en tant qu’ensembles de répliques améliorerait la cohérence du serveur de configuration. En effet, MongoDB peut exploiter les protocoles standard de lecture et d’écriture des ensembles de répliques pour les données de configuration.
Pour déployer des serveurs de configuration en tant qu’ensembles de répliques, vous devez exécuter le moteur de stockage WiredTiger. WiredTiger utilise un contrôle de la concurrence au niveau des documents pour ses opérations d’écriture. Par conséquent, plusieurs clients peuvent modifier simultanément différents documents d’une collection.
Les serveurs de configuration stockent les métadonnées d’un cluster partagé dans la base de données de configuration. Pour accéder à la base de données de configuration, vous pouvez utiliser la commande suivante dans le shell Mongo :
use configVoici quelques restrictions à prendre en compte :
- Une configuration d’ensemble de répliques utilisée pour les serveurs de configuration doit avoir zéro arbitre. Un arbitre participe à une élection pour le primaire, mais il n’a pas de copie du jeu de données et ne peut pas devenir le primaire.
- Cet ensemble de répliques ne peut pas avoir de membres retardés. Les membres retardés ont des copies de l’ensemble de données de l’ensemble de répliques. Mais l’ensemble de données d’un membre retardé contient un état antérieur ou retardé de l’ensemble de données.
- Vous devez créer des index pour les serveurs de configuration. Pour faire simple, aucun membre ne doit avoir le paramètre
members[n].buildIndexesdéfini surfalse.
Si l’ensemble de répliques du serveur de configuration perd son membre principal et ne peut pas en élire un, les métadonnées du cluster deviennent en lecture seule. Vous serez toujours en mesure de lire et d’écrire à partir des shards, mais aucune division de morceaux ou migration ne se produira jusqu’à ce que l’ensemble de répliques puisse élire un membre principal.
3. Routeurs de requêtes
Les instances MongoDB mongos peuvent servir de routeurs de requêtes, permettant aux applications clientes et aux clusters partagés de se connecter facilement.
À partir de la version 4.4 de MongoDB, les instances mongos peuvent prendre en charge les lectures couvertes afin de réduire les temps de latence. Avec les lectures couvertes, les instances mongos enverront des opérations de lecture à deux membres de l’ensemble de répliques pour chaque grappe interrogée. Les résultats sont ensuite renvoyés par le premier répondant de chaque dépôt.
Voici comment les trois composants interagissent au sein d’un cluster partagé :
Une instance de MongoDB dirigera une requête vers un cluster en :
- Vérifiant la liste des serveurs qui doivent recevoir la requête.
- Établissant un curseur sur tous les serveurs ciblés.
Mongo fusionne ensuite les données de chaque groupe ciblé et renvoie le document de résultat. Certains modificateurs de requête, comme le tri, sont exécutés sur chaque serveur avant que les mongos ne récupèrent les résultats.
Dans certains cas, lorsque la clé du dépôt ou un préfixe de clé du dépôt fait partie de la requête, les mongos exécutent une opération planifiée à l’avance, en orientant les requêtes vers une sous-classe de dépôts dans le cluster.
Pour un cluster en production, assurez-vous que les données sont redondantes et que vos systèmes sont hautement disponibles. Vous pouvez choisir la configuration suivante pour le déploiement d’un cluster de production :
- Déployer chaque grappe en tant qu’ensemble de répliques à 3 membres
- Déployez les serveurs de configuration en tant qu’ensemble de répliques à trois membres
- Déployez un ou plusieurs routeurs mongos
Pour un cluster de non-production, vous pouvez déployer un cluster sharded avec les composants suivants :
- Un ensemble de répliques à shard unique
- Un serveur de configuration de l’ensemble de répliques
- Une instance mongos
Comment fonctionne le sharding MongoDB ?
Maintenant que nous avons discuté des différents composants d’un cluster partagé, il est temps de plonger dans le processus.
Pour répartir les données sur plusieurs serveurs, vous utiliserez mongos. Lorsque vous vous connectez pour envoyer les requêtes à MongoDB, mongos cherche et trouve où résident les données. Il les récupère ensuite sur le bon serveur et les fusionne si elles ont été réparties sur plusieurs serveurs.
Étant donné que tout cela est pris en charge par le backend, vous n’aurez rien à faire du côté de l’application. MongoDB agira comme s’il s’agissait d’une connexion de requête normale. Votre client se connectera à MongoDB, et le serveur de configuration s’occupera du reste.
Comment configurer le sharding MongoDB étape par étape ?
La mise en place du sharding MongoDB est un processus qui implique plusieurs étapes afin d’assurer un cluster de base de données stable et efficace. Voici une instruction détaillée, étape par étape, sur la façon de configurer le sharding MongoDB.
Avant de commencer, il est important de noter que pour configurer le sharding dans MongoDB, vous devez avoir au moins trois serveurs : un pour le serveur de configuration, un pour l’instance mongos et un ou plusieurs pour les shards.
1. Créer un répertoire à partir du serveur de configuration
Pour commencer, nous allons créer un répertoire pour les données du serveur de configuration. Pour ce faire, exécutez la commande suivante sur le premier serveur :
mkdir /data/configdb2. Démarrer MongoDB en mode configuration
Ensuite, nous allons démarrer MongoDB en mode configuration sur le premier serveur à l’aide de la commande suivante :
mongod --configsvr --dbpath /data/configdb --port 27019Cette commande démarrera le serveur de configuration sur port 27019 et stockera ses données dans le répertoire /data/configdb. Notez que nous utilisons le drapeau --configsvr pour indiquer que ce serveur sera utilisé comme serveur de configuration.
3. Démarrer l’instance Mongos
L’étape suivante consiste à démarrer l’instance mongos. Ce processus va router les requêtes vers les bons shards en se basant sur la clé de sharding. Pour démarrer l’instance mongos, utilisez la commande suivante :
mongos --configdb <config server>:27019Remplacez <config server> par l’adresse IP ou le nom d’hôte de la machine sur laquelle tourne le serveur de configuration.
4. Se connecter à l’instance Mongos
Une fois que l’instance Mongos est en cours d’exécution, nous pouvons nous y connecter à l’aide du shell MongoDB. Pour ce faire, exécutez la commande suivante :
mongo --host <mongos-server> --port 27017Dans cette commande, <mongos-server> doit être remplacé par le nom d’hôte ou l’adresse IP du serveur exécutant l’instance mongos. Cela ouvrira le shell MongoDB, ce qui nous permettra d’interagir avec l’instance mongos et d’ajouter des serveurs au cluster.
Remplacez<mongos-server> par l’adresse IP ou le nom d’hôte de la machine sur laquelle tourne l’instance mongos.
5. Ajouter des serveurs aux clusters
Maintenant que nous sommes connectés à l’instance mongos, nous pouvons ajouter des serveurs au cluster en exécutant la commande suivante :
sh.addShard("<shard-server>:27017")Dans cette commande, <shard-server> doit être remplacé par le nom d’hôte ou l’adresse IP du serveur qui exécute le shard. Cette commande ajoutera le groupe de serveurs au cluster et le rendra disponible pour l’utilisation.
Répétez cette étape pour chaque groupe de stockage que vous souhaitez ajouter au cluster.
6. Activer le sharding pour la base de données
Enfin, nous allons activer le sharding pour une base de données en exécutant la commande suivante :
sh.enableSharding("<database>")Dans cette commande, <database> doit être remplacé par le nom de la base de données que vous souhaitez partager. Cette commande activera le sharding pour la base de données spécifiée, ce qui vous permettra de distribuer ses données sur plusieurs shards.
Et c’est tout ! En suivant ces étapes, vous devriez maintenant disposer d’un cluster partagé MongoDB entièrement fonctionnel, prêt à évoluer horizontalement et à gérer des charges de trafic élevées.
Meilleures pratiques pour le sharding MongoDB
Bien que nous ayons mis en place notre cluster partagé, il est essentiel de le surveiller et de le maintenir régulièrement pour garantir des performances optimales. Voici quelques bonnes pratiques pour le sharding MongoDB :
1. Déterminez la bonne clé de partage
La clé de partage est un facteur critique dans le partage MongoDB qui détermine la façon dont les données sont distribuées entre les partages. Il est important de choisir une clé de stockage qui distribue uniformément les données sur les serveurs et prend en charge les requêtes les plus courantes. Vous devez éviter de choisir une clé de répartition qui provoque des points chauds ou une répartition inégale des données, car cela peut entraîner des problèmes de performance.
Pour choisir la bonne clé de répartition, vous devez analyser vos données et les types de requêtes que vous effectuerez et sélectionner une clé qui réponde à ces exigences.
2. Prévoyez la croissance des données
Lors de la mise en place de votre cluster, prévoyez une croissance future en commençant par un nombre de shards suffisant pour gérer votre charge de travail actuelle et en ajoutant d’autres shards si nécessaire. Assurez-vous que votre infrastructure matérielle et réseau peut prendre en charge le nombre de grappes et la quantité de données que vous prévoyez d’avoir à l’avenir.
3. Utilisez du matériel dédié pour les shards
Pour des performances et une fiabilité optimales, utilisez du matériel dédié pour chaque groupe de stockage. Chaque groupe doit avoir son propre serveur ou sa propre machine virtuelle, afin de pouvoir utiliser toutes les ressources sans interférence.
L’utilisation de matériel partagé peut entraîner des conflits de ressources et une dégradation des performances, ce qui a un impact sur la fiabilité globale du système.
4. Utilisez des jeux de répliques pour les serveurs de shard
L’utilisation d’ensembles de répliques pour les serveurs de stockage permet d’assurer la haute disponibilité et la tolérance aux pannes de votre cluster de stockage MongoDB. Chaque ensemble de répliques doit comporter au moins trois membres, et chaque membre doit résider sur une machine physique distincte. Cette configuration garantit que votre cluster partagé peut survivre à la défaillance d’un seul serveur ou d’un seul membre de l’ensemble de répliques.
5. Surveiller les performances des shards
Il est essentiel de surveiller les performances de vos grappes pour identifier les problèmes avant qu’ils ne deviennent majeurs. Vous devez surveiller l’unité centrale, la mémoire, les entrées/sorties de disque et les entrées/sorties de réseau pour chaque serveur de grappes afin de vous assurer que la grappe est en mesure de gérer la charge de travail.
Vous pouvez utiliser les outils de surveillance intégrés à MongoDB, tels que mongostat et mongotop, ou des outils de surveillance tiers, tels que Datadog, Dynatrace et Zabbix, pour suivre les performances des serveurs partagés.
6. Planifiez la reprise après sinistre
La planification de la reprise après sinistre est essentielle pour maintenir la fiabilité de votre cluster MongoDB. Vous devez disposer d’un plan de reprise après sinistre comprenant des sauvegardes régulières, des tests de validité des sauvegardes et un plan de restauration des sauvegardes en cas de défaillance.
7. Utilisez le sharding basé sur les hachages lorsque c’est nécessaire
Lorsque les applications émettent des requêtes basées sur des plages, la mise en rangée est bénéfique car les opérations peuvent être limitées à un plus petit nombre de disques, le plus souvent à un seul. Vous devez comprendre vos données et les modèles de requête pour mettre en œuvre cette solution.
La répartition par hachage garantit une distribution uniforme des lectures et des écritures. Cependant, il ne permet pas d’effectuer des opérations efficaces basées sur des plages.
Quelles sont les erreurs courantes à éviter lors du sharding de votre base de données MongoDB ?
Le sharding MongoDB est une technique puissante qui peut vous aider à faire évoluer votre base de données horizontalement et à distribuer les données sur plusieurs serveurs. Cependant, il y a plusieurs erreurs communes que vous devriez éviter lorsque vous partagez votre base de données MongoDB. Vous trouverez ci-dessous quelques-unes des erreurs les plus courantes et la manière de les éviter.
1. Choisir la mauvaise clé de sharding
L’une des décisions les plus cruciales que vous prendrez lors du sharding de votre base de données MongoDB est le choix de la clé de sharding. Cette clé détermine la manière dont les données sont réparties entre les différents serveurs, et le choix d’une mauvaise clé peut entraîner une répartition inégale des données, des points chauds et des performances médiocres.
Une erreur fréquente consiste à choisir une valeur de clé de répartition qui n’augmente que pour les nouveaux documents lorsque vous utilisez une répartition basée sur une plage plutôt qu’une répartition par hachage. Par exemple, un horodatage (naturellement) ou tout ce qui a une composante temporelle comme élément le plus important, comme ObjectID (les quatre premiers octets sont un horodatage).
Si vous sélectionnez une clé de dépôt, toutes les insertions iront dans le bloc ayant la plus grande plage. Même si vous ajoutez sans cesse de nouvelles unités, votre capacité d’écriture maximale n’augmentera jamais.
Si vous prévoyez d’augmenter la capacité d’écriture, essayez d’utiliser une clé de dépôt basée sur le hachage, qui permettra d’utiliser le même champ tout en offrant une bonne évolutivité en écriture.
2. Tentative de modification de la valeur de la clé de sharding
Les clés de sharding sont immuables pour un document existant, ce qui signifie que vous ne pouvez pas modifier la clé. Vous pouvez effectuer certaines mises à jour avant le sharding, mais pas après. Si vous essayez de modifier la clé de dépôt d’un document existant, vous obtiendrez l’erreur suivante :
cannot modify shard key's value fieldid for collection: collectionnameVous pouvez supprimer et réinsérer le document pour réorganiser la clé de sharding au lieu d’essayer de la modifier.
3. Échec de la surveillance du cluster
Le sharding introduit une complexité supplémentaire dans l’environnement de la base de données, et il est donc essentiel de surveiller étroitement le cluster. Ne pas surveiller le cluster peut entraîner des problèmes de performance, des pertes de données et d’autres problèmes.
Pour éviter cette erreur, vous devez mettre en place des outils de surveillance permettant de suivre des paramètres clés tels que l’utilisation du processeur, de la mémoire, de l’espace disque et du trafic réseau. Vous devez également mettre en place des alertes lorsque certains seuils sont dépassés.
4. Attendre trop longtemps pour ajouter un nouveau groupe de sharding (surcharge)
L’une des erreurs les plus courantes à éviter lors du sharding de votre base de données MongoDB est d’attendre trop longtemps avant d’ajouter un nouveau shard. Lorsqu’un shard est surchargé de données ou de requêtes, cela peut entraîner des problèmes de performance et ralentir l’ensemble du cluster.
Supposons que vous disposiez d’un cluster imaginaire composé de deux disques durs, avec 20000 blocs (5000 considérés comme « actifs »), et que nous devions ajouter un troisième disque dur. Ce troisième dépôt stockera finalement un tiers des blocs actifs (et des blocs totaux).
La difficulté consiste à déterminer à quel moment le groupe de stockage cesse d’ajouter des frais généraux et devient un atout. Nous devrions calculer la charge que le système produirait lors de la migration des blocs actifs vers le nouveau bloc et déterminer à quel moment elle serait négligeable par rapport au gain global du système.
Dans la plupart des scénarios, il est relativement facile d’imaginer que cette série de migrations prendrait encore plus de temps sur un ensemble de serveurs surchargés, et qu’il faudrait beaucoup plus de temps pour que notre nouveau serveur franchisse le seuil et devienne un gain net. Il est donc préférable d’être proactif et d’ajouter de la capacité avant que cela ne devienne nécessaire.
Parmi les stratégies d’atténuation possibles, citons la surveillance régulière du cluster et l’ajout proactif de nouvelles unités à des moments où le trafic est faible, de manière à réduire la concurrence pour les ressources. Il est suggéré d’équilibrer manuellement les morceaux « chauds » ciblés (accédés plus que d’autres) pour déplacer l’activité vers le nouveau shard plus rapidement.
5. Sous-provisionnement des serveurs de configuration
Si les serveurs de configuration sont sous-provisionnés, cela peut entraîner des problèmes de performance et d’instabilité. Le sous-provisionnement peut être dû à une allocation insuffisante de ressources telles que l’unité centrale, la mémoire ou le stockage.
Il peut en résulter une lenteur des requêtes, des dépassements de délai, voire des pannes. Pour éviter cela, il est essentiel d’allouer suffisamment de ressources aux serveurs de configuration, en particulier dans les grands clusters. La surveillance régulière de l’utilisation des ressources des serveurs de configuration peut aider à identifier les problèmes de sous-provisionnement.
Un autre moyen d’éviter ce problème est d’utiliser du matériel dédié pour les serveurs de configuration, plutôt que de partager les ressources avec d’autres composants de la grappe. Cela permet de s’assurer que les serveurs de configuration disposent de suffisamment de ressources pour gérer leur charge de travail.
6. Absence de sauvegarde et de restauration des données
Les sauvegardes sont essentielles pour s’assurer que les données ne sont pas perdues en cas de panne. La perte de données peut survenir pour diverses raisons, notamment une défaillance matérielle, une erreur humaine ou une attaque malveillante.
Ne pas sauvegarder et restaurer les données peut entraîner des pertes de données et des temps d’arrêt. Pour éviter cette erreur, vous devez mettre en place une stratégie de sauvegarde et de restauration comprenant des sauvegardes régulières, des sauvegardes de test et la restauration des données dans un environnement de test.
7. Ne pas tester le cluster partagé
Avant de déployer votre cluster partagé en production, vous devez le tester complètement pour vous assurer qu’il peut gérer la charge et les requêtes attendues. Ne pas tester le cluster partagé peut entraîner des performances médiocres et des pannes.
Index MongoDB partagé ou en grappe : Lequel est le plus efficace pour les grands ensembles de données ?
Le sharding MongoDB et les index en grappe sont tous deux des stratégies efficaces pour gérer les grands ensembles de données. Mais elles ont des objectifs différents. Le choix de la bonne approche dépend des exigences spécifiques de votre application.
Le sharding est une technique de mise à l’échelle horizontale qui distribue les données sur de nombreux nœuds, ce qui en fait une solution efficace pour gérer les grands ensembles de données avec des taux d’écriture élevés. Elle est transparente pour les applications, ce qui leur permet d’interagir avec MongoDB comme s’il s’agissait d’un serveur unique.
D’autre part, les index en grappe améliorent les performances des requêtes qui récupèrent des données à partir de grands ensembles de données en permettant à MongoDB de localiser les données plus efficacement lorsqu’une requête correspond au champ indexé.
Alors, lequel des deux est le plus efficace pour les grands ensembles de données ? La réponse dépend du cas d’utilisation spécifique et des exigences de la charge de travail.
Si l’application nécessite un débit d’écriture et de requête élevé et qu’elle doit évoluer horizontalement, le sharding MongoDB est probablement la meilleure option. Cependant, les index en grappe peuvent être plus efficaces si l’application a une charge de travail importante en lecture et nécessite que les données fréquemment interrogées soient organisées dans un ordre spécifique.
Le sharding et les index en grappe sont tous deux des outils puissants pour la gestion de grands ensembles de données dans MongoDB. L’essentiel est d’évaluer soigneusement les exigences de votre application et les caractéristiques de la charge de travail afin de déterminer la meilleure approche pour votre cas d’utilisation spécifique.
Résumé
Un cluster sharded est une architecture puissante qui peut gérer de grandes quantités de données et évoluer horizontalement pour répondre aux besoins d’applications en pleine croissance. Le cluster est constitué de shards, de serveurs de configuration, de processus mongos et d’applications clientes, et les données sont partitionnées sur la base d’une clé de shard choisie avec soin pour garantir une distribution et une interrogation efficaces.
En tirant parti de la puissance du sharding, les applications peuvent bénéficier d’une haute disponibilité, de performances améliorées et d’une utilisation efficace des ressources matérielles. Le choix de la bonne clé de répartition est crucial pour une distribution homogène des données.
Que pensez-vous de MongoDB et de la pratique du sharding de base de données ? Y a-t-il un aspect du sharding que nous aurions dû couvrir ? Faites-le nous savoir dans les commentaires !


