
Per le agenzie moderne, un sistema di reportistica coerente e di alta qualità è essenziale per mantenere la fiducia dei clienti e costruire una fedeltà a lungo termine. Un report chiaro e informativo permette di monitorare le tendenze di vendita, dimostrare l’efficacia delle campagne, calcolare il ritorno sugli investimenti (ROI) e molto altro ancora.
Tuttavia, per un’agenzia che gestisce decine o addirittura centinaia di siti, la generazione di questi report periodici può diventare un grosso collo di bottiglia, compromettendo la scalabilità delle operazioni.
Ecco perché ottimizzare e automatizzare il recupero dei dati è fondamentale. In questo modo si ripristina l’efficienza e si lascia che il team si concentri su attività ad alto valore aggiunto, come lo sviluppo di nuovi progetti.
In questo articolo vedremo come sfruttare l’API di Kinsta per recuperare automaticamente i dati dell’hosting e generare report strategici con la potenza dell’intelligenza artificiale.
Non vedi l’ora di ottimizzare il tuo sistema di reporting? Continua a leggere.
Accesso alle statistiche di Kinsta tramite MyKinsta e Kinsta API
I clienti Kinsta hanno accesso a una grande quantità di dati attraverso la dashboard dell’hosting MyKinsta. È possibile accedere ai dati del proprio piano nella sezione Statistiche della dashboard.
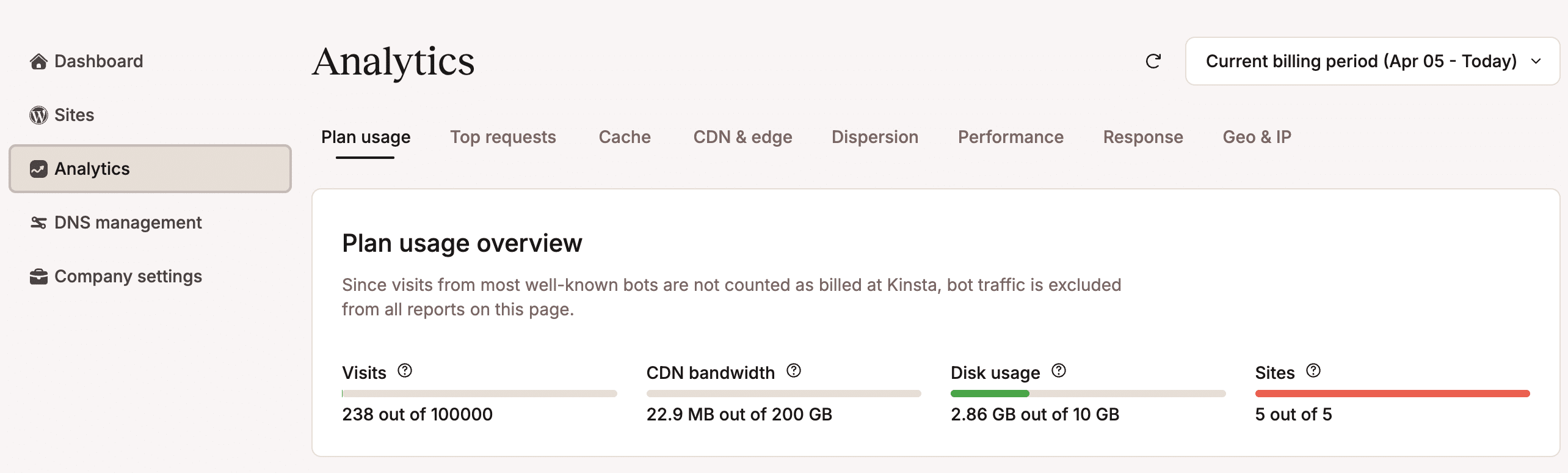
La pagina delle Statistiche è suddivisa in diverse schede, ognuna delle quali si concentra su un aspetto specifico dell’attività del sito:
- Utilizzo del piano – Mostra il consumo di risorse del piano, sia in modo cumulativo che suddiviso per singolo sito.
- Richieste principali – Permette di identificare le principali richieste al sito, suddivise per larghezza di banda e visualizzazioni.
- Cache – Fornisce una ripartizione dell’uso della cache, compresa la ripartizione della cache, i componenti della cache del server e i bypass della cache del server.
- CDN & edge – Offre dati sul consumo di banda del CDN, sulla larghezza di banda della cache Edge e gli elenchi dei principali file serviti dalla cache CDN.
- Dispersione – Mostra la percentuale di visite da desktop, tablet e mobile.
- Prestazioni – Include varie metriche sulle prestazioni come il tempo medio di risposta PHP MySQL, il throughput PHP, il limite di thread PHP e altro ancora.
- Risposta – Fornisce statistiche sui codici di risposta, compresa una ripartizione dettagliata dei codici di errore.
- Geo & IP – Mostra gli elenchi dei principali Paesi, città e client IP da cui provengono le richieste al sito.
Puoi accedere a queste stesse analisi a livello di sito navigando su Siti > nome del sito > Statistiche.
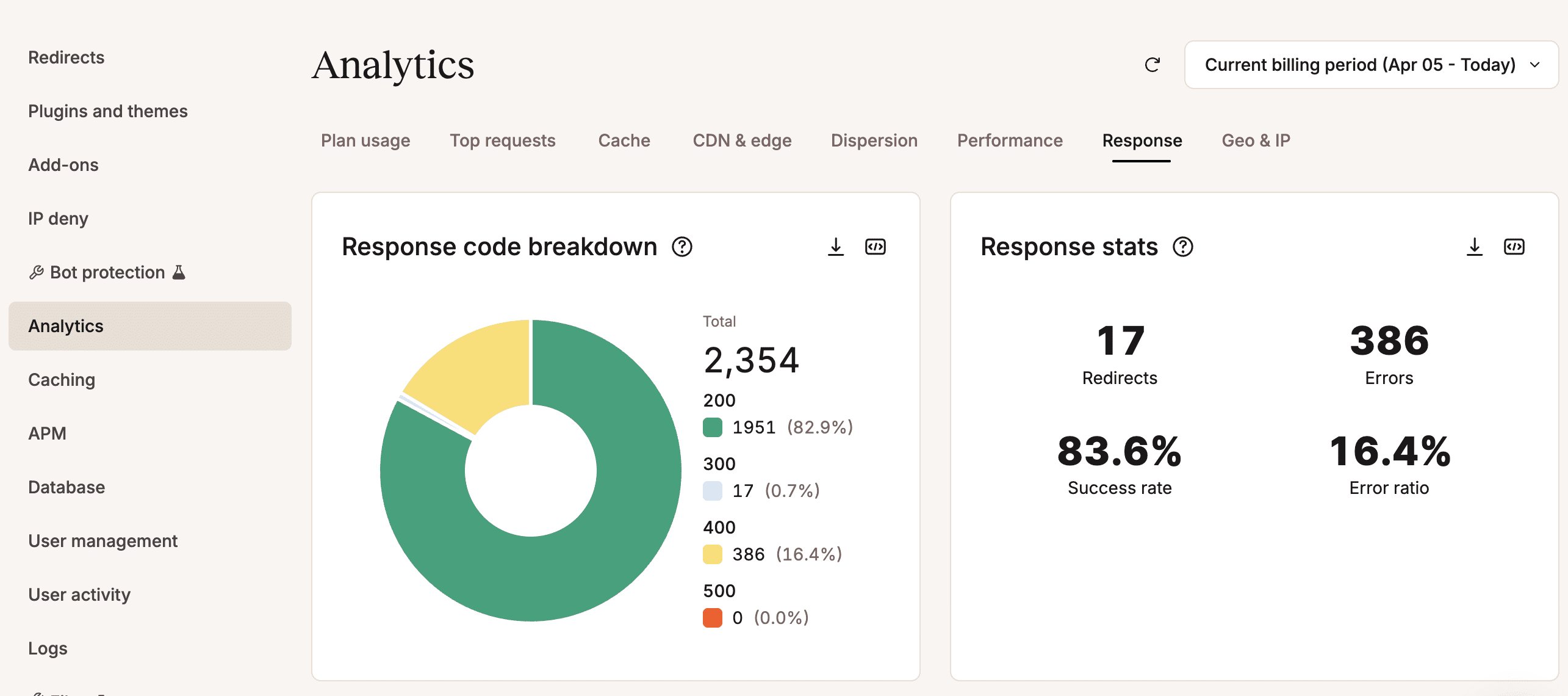
Le statistiche di Kinsta forniscono una serie di dati sbalorditivi; semplicemente navigando nella dashboard di MyKinsta potrai avere un quadro molto chiaro del consumo di risorse, dell’efficienza e delle prestazioni di un sito. Saprai esattamente da dove proviene la maggior parte delle richieste e quali sono quelle che consumano più risorse.
In combinazione con il nostro strumento Kinsta APM, le Statistiche di Kinsta ti permettono di ottimizzare le prestazioni dei tuoi siti WordPress.
Non tutti sanno che i dati delle Statistiche di Kinsta sono accessibili anche tramite l’API di Kinsta. Ciò permette di recuperare programmaticamente i dati e di costruire metriche di hosting, che potrai poi utilizzare per generare report automatici da condividere con i tuoi clienti.
Scopriamo qualcosa in più sugli endpoint dell’API di Kinsta.
L’endpoint Analytics dell’API di Kinsta
Con l’endpoint Analytics dell’API di Kinsta puoi accedere ai dati grezzi sull’utilizzo delle risorse e sullo stato di salute del tuo sito web.
- Utilizzo delle visite, utilizzo della larghezza di banda del server e utilizzo della larghezza di banda del CDN: queste metriche tengono conto dell’utilizzo delle risorse rispetto al tuo piano di hosting durante il periodo di fatturazione corrente.
- Visite: fornisce il numero totale di visite a un determinato ambiente in un determinato periodo di tempo.
- Spazio su disco: fornisce lo spazio totale su disco utilizzato da un determinato ambiente in un determinato periodo di tempo.
- Larghezza di banda del server: fornisce la larghezza di banda consumata da un determinato ambiente in un determinato periodo di tempo.
- Larghezza di banda CDN: fornisce la larghezza di banda CDN consumata da un determinato ambiente in un determinato periodo di tempo.
- Paesi principali: fornisce un elenco dei principali Paesi da cui provengono le richieste al sito in un determinato periodo di tempo.
- Città principali: fornisce un elenco delle principali città da cui provengono le richieste al sito in un determinato periodo di tempo.
- Top Client IPs: fornisce un elenco dei principali indirizzi IP dei clienti da cui provengono le richieste al sito in un determinato periodo di tempo.
- Dispersione delle visite: fornisce dati sulla distribuzione delle visite tra dispositivi desktop, tablet e mobili in un determinato periodo di tempo.
- Disaggregazione dei codici di risposta: Fornisce una ripartizione dei codici di stato HTTP restituiti dal server in un determinato periodo di tempo.
Di seguito sono riportati alcuni esempi di utilizzo dell’endpoint analytics.
Visite
La seguente richiesta fornisce il numero totale di visite al sito e il numero di indirizzi IP unici che vi hanno avuto accesso negli ultimi 30 giorni:
https://api.kinsta.com/v2/sites/environments/{KINSTA_ENV_ID}/analytics/visits?time_span=30_days&company_id={KINSTA_COMPANY_ID}La risposta sarà strutturata come segue:
{
"analytics": {
"analytics_response": {
"key": "uniqueip",
"data": [
{
"name": "uniqueip",
"total": 1000,
"dataset": [
{
"key": "2025-10-28T00:00:00.000Z",
"value": "1000"
},
{
"key": "2025-10-28T00:00:00.000Z",
"value": "900"
},
{
"key": "2025-10-28T00:00:00.000Z",
"value": "820"
},
...
]
}
]
}
}
}Larghezza di banda
Il seguente esempio mostra come interrogare l’API di Kinsta per recuperare l’utilizzo della larghezza di banda del server negli ultimi 30 giorni:
https://api.kinsta.com/v2/sites/environments/{KINSTA_ENV_ID}/analytics/bandwidth?time_span=30_days&company_id={KINSTA_COMPANY_ID}La risposta del server Kinsta fornisce l’utilizzo giornaliero della larghezza di banda negli ultimi 30 giorni:
{
"analytics": {
"analytics_response": {
"key": "bandwidth",
"data": [
{
"name": "bandwidth",
"total": 1000,
"dataset": [
{
"key": "2026-03-11T00:00:00.000Z",
"value": "37347250"
},
{
"key": "2026-03-12T00:00:00.000Z",
"value": "9276458"
},
...
]
}
]
}
}
}Larghezza di banda CDN
In quest’altro esempio, interroghiamo l’API di Kinsta per conoscere l’utilizzo della larghezza di banda CDN negli ultimi 7 giorni:
https://api.kinsta.com/v2/sites/environments/{KINSTA_ENV_ID}/analytics/cdn-bandwidth?time_span=7_days&company_id={KINSTA_COMPANY_ID}Il server fornirà i seguenti dati:
{
"analytics": {
"analytics_response": {
"key": "cdn-bandwidth",
"data": [
{
"name": "cdn-bandwidth",
"total": 1000,
"dataset": [
{
"key": "2026-04-02T00:00:00.000Z",
"value": "753447"
},
{
"key": "2026-04-03T00:00:00.000Z",
"value": "16911"
},
...
]
}
]
}
}
}Puoi provarlo inserendo la tua chiave API Kinsta (bearer token), l’ID dell’ambiente e l’ID dell’azienda nel playground dell’API.
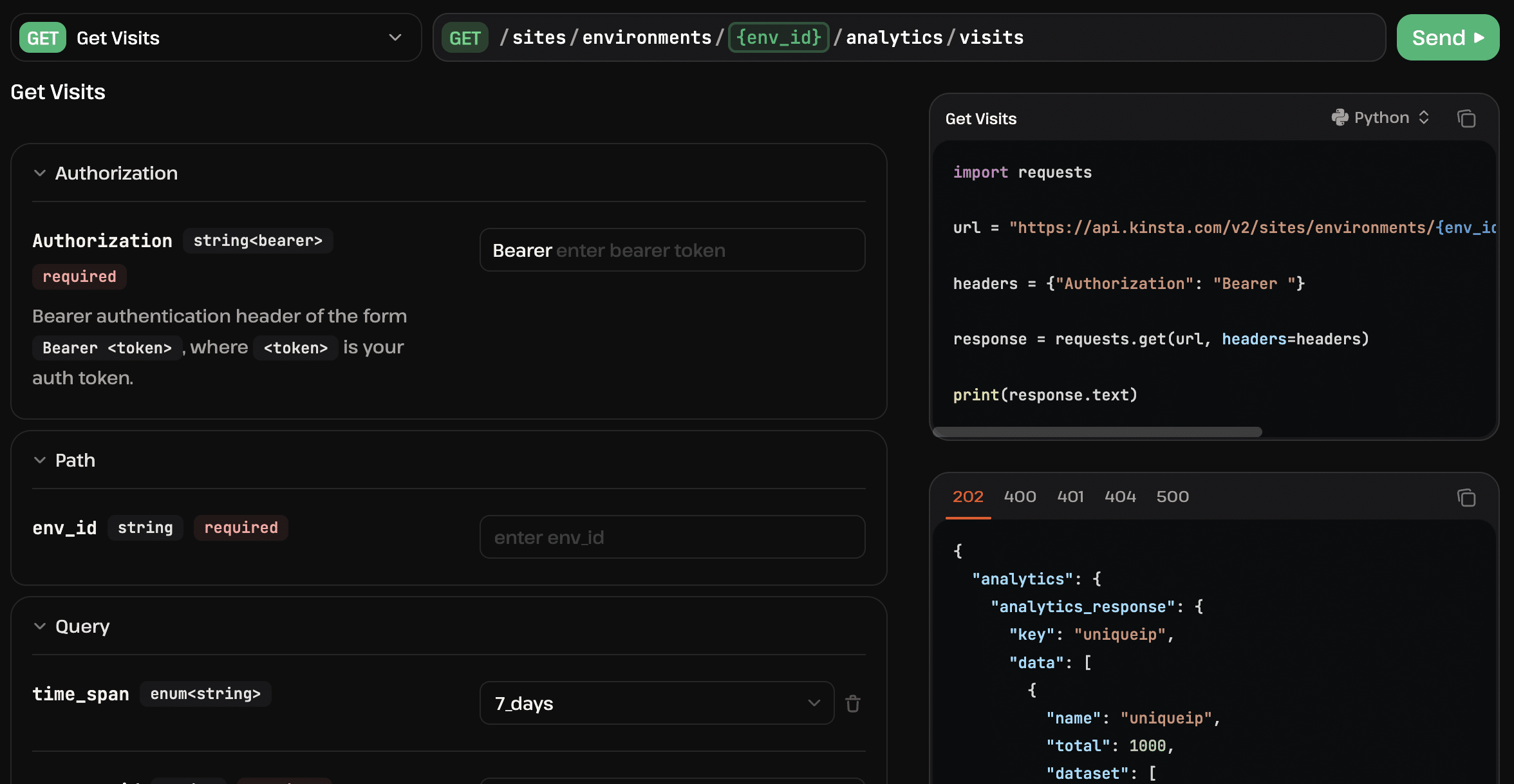
Ora che sai come accedere ai dati analitici del tuo sito su Kinsta, puoi usarli per automatizzare le tue operazioni. Questo include anche l’automazione del sistema di reporting.
Nelle sezioni seguenti vedremo come automatizzare il sistema di reporting della tua agenzia utilizzando l’API di Kinsta. Creeremo uno script Python e sfrutteremo le GitHub Actions per automatizzare la creazione e l’esecuzione. Questo trasformerà i dati grezzi restituiti dall’API in tabelle e grafici e interrogherà Google AI per generare un report finale.
Mettiamoci al lavoro.
Costruire un sistema di report automatico utilizzando l’API di Kinsta e Google AI
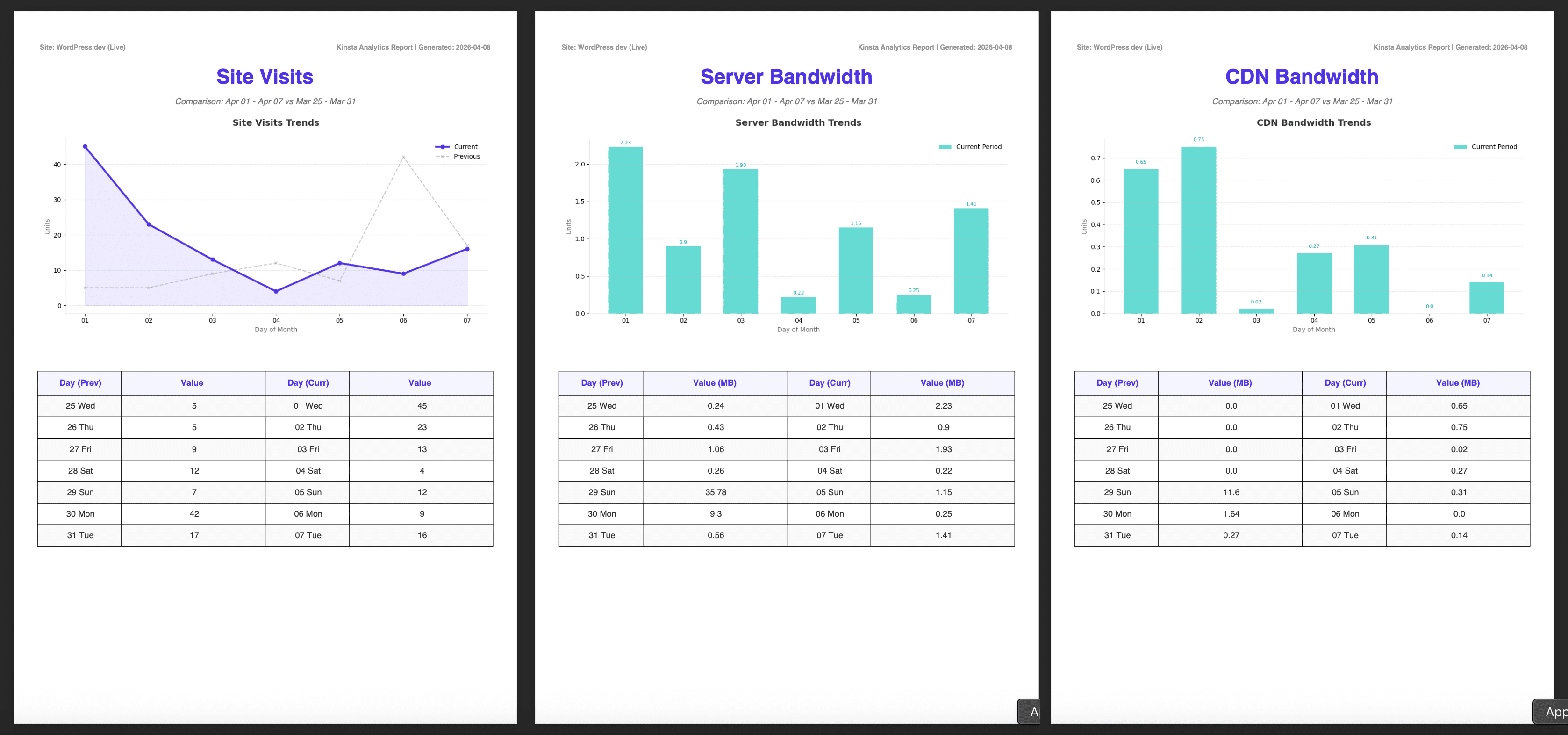
Il nostro obiettivo è creare un report automatico che venga generato a intervalli specifici. Il sistema interrogherà l’API di Kinsta per recuperare i dati relativi alle visite, alla larghezza di banda del server e alla larghezza di banda del CDN. Questi dati verranno poi utilizzati per creare grafici e tabelle in un file PDF. Come parte di questo processo, i dati saranno inviati all’API Gemini per produrre un’analisi dei dati estratti, che sarà poi inclusa nel report.
Impostazione del progetto su GitHub
Nella homepage di GitHub, clicca sul pulsante verde New per creare un nuovo progetto. Una volta creato un progetto vuoto, vai su Settings > Secrets and variables > Actions e aggiungi i segreti mostrati nell’immagine seguente.
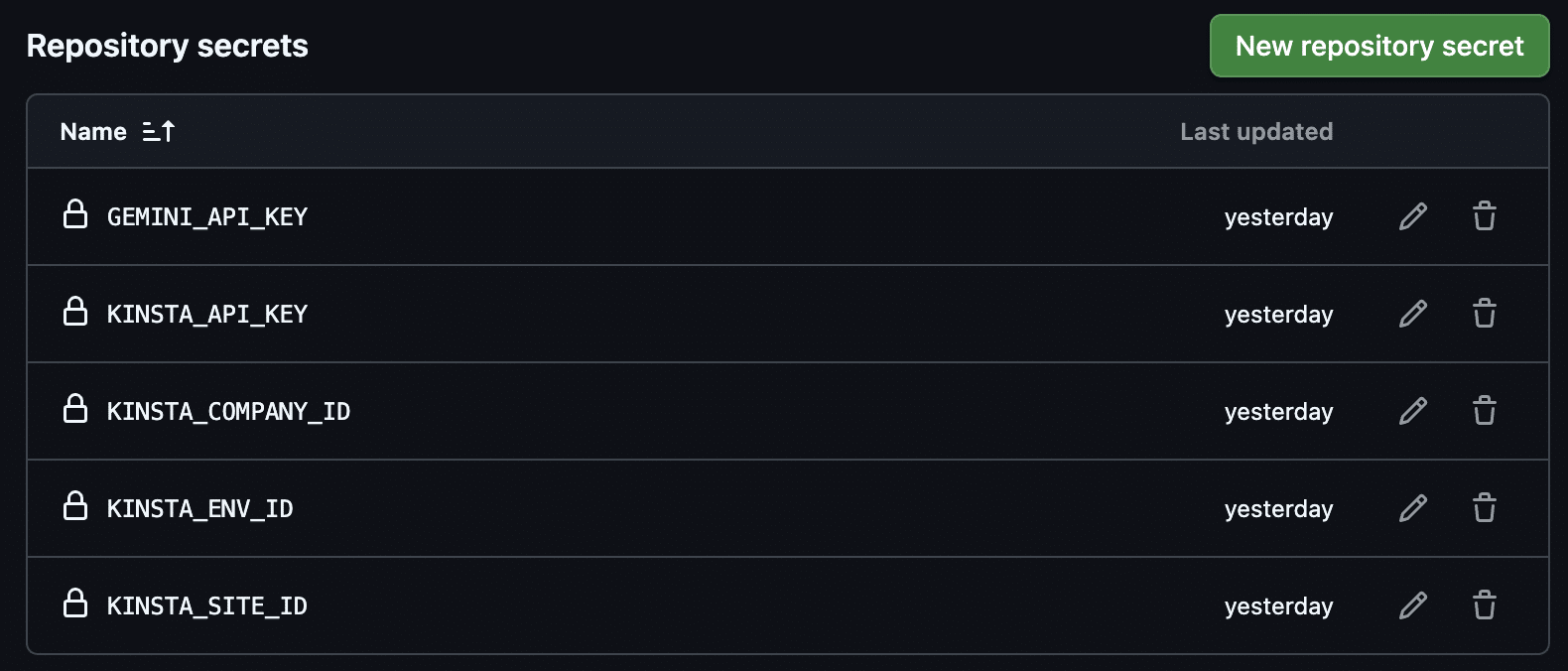
Memorizzare le chiavi API e gli ID in GitHub Secrets li rende inaccessibili a chiunque e contribuisce a garantire la sicurezza del tuo codice.
GEMINI_API_KEY
Puoi generare una chiave API di Google AI nella dashboard di Google AI Studio. Per maggiori informazioni, consulta la documentazione di Google AI.
KINSTA_API-KEY
Successivamente, segui le istruzioni del nostro articolo per generare una chiave API Kinsta.
KINSTA_COMPANY_ID, KINSTA_ENV_ID, KINSTA_SITE_ID
Puoi trovare l’ID del sito, l’ID dell’ambiente e l’ID dell’azienda in Siti > nome del sito > Info nella tua dashboard MyKinsta.
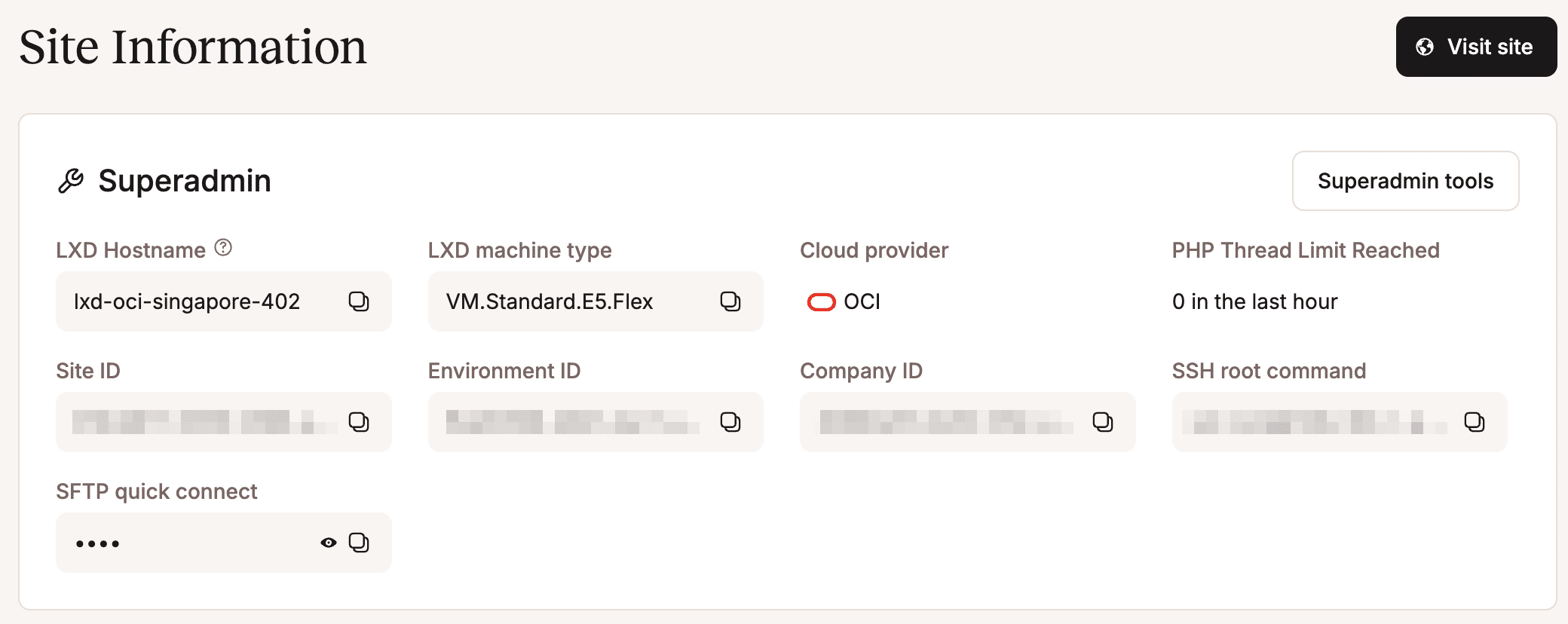
Ora passiamo ai file del progetto.
Librerie necessarie e configurazione delle GitHub Actions
Nella directory principale del progetto GitHub, crea un file chiamato requirements.txt e aggiungi quanto segue:
google-genai
requests
matplotlib
fpdf2Questo file elenca i componenti necessari per il tuo progetto.
google-genai: è la libreria di Google per interagire con i modelli Gemini.requests: una libreria per effettuare richieste HTTP. In questo progetto verrà utilizzata per inviare richieste HTTP all’API di Kinsta.matplotlib: una libreria Python per creare grafici e visualizzare dati.fpdf2: è una libreria che permette di generare file PDF.
Quindi, crea un file chiamato .github/workflows/generate_report.yml con il seguente codice:
name: Generate Kinsta Analytics Report
on:
push:
branches: [main]
workflow_dispatch:
jobs:
build-and-run:
runs-on: ubuntu-latest
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.12'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Report Script
env:
KINSTA_API_KEY: ${{ secrets.KINSTA_API_KEY }}
KINSTA_ENV_ID: ${{ secrets.KINSTA_ENV_ID }}
KINSTA_SITE_ID: ${{ secrets.KINSTA_SITE_ID }}
KINSTA_COMPANY_ID: ${{ secrets.KINSTA_COMPANY_ID }}
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
run: python main.py
- name: Upload Report
uses: actions/upload-artifact@v4
with:
name: Kinsta-Advanced-Report
path: "*.pdf"GitHub utilizza questo file per eseguire automaticamente il codice tramite le GitHub Actions. Diamo un’occhiata più da vicino:
name: Generate Kinsta Analytics Report
on:
push:
branches: [main]
workflow_dispatch:name: il nome del progetto così come appare nella scheda Actions di GitHub.on: determina quando attivare il workflow.push: il workflow viene eseguito ogni volta che si apporta una modifica al codice nel branch principale.workflow_dispatch: permette di eseguire il flusso di lavoro manualmente.
jobs:
build-and-run:
runs-on: ubuntu-latestjobs: l’inizio dei task da eseguire.build-and-run: un nome arbitrario che identifica una sequenza specifica di azioni.runs-on: specifica il sistema su cui il workflow deve essere eseguito.ubuntu-latest: imposta l’ultima versione di Ubuntu Linux.
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.12'steps: la sequenza di operazioni da eseguire.name: il nome dell’operazione da eseguireuses: il modulo GitHub preconfigurato (Action)
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txtpython -m pip install --upgrade pip: aggiorna pip (il gestore di pacchetti Python) all’ultima versione disponibile.pip install -r requirements.txt: legge il filerequirements.txte installa i pacchetti in esso elencati.
- name: Run Report Script
env:
KINSTA_API_KEY: ${{ secrets.KINSTA_API_KEY }}
KINSTA_ENV_ID: ${{ secrets.KINSTA_ENV_ID }}
KINSTA_SITE_ID: ${{ secrets.KINSTA_SITE_ID }}
KINSTA_COMPANY_ID: ${{ secrets.KINSTA_COMPANY_ID }}
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
run: python main.pyenv: recupera i valori delle variabili d’ambiente da GitHub Secrets.run: python main.py: avvia l’interprete Python ed esegue il filemain.py.
- name: Upload Report
uses: actions/upload-artifact@v4
with:
name: Kinsta-Advanced-Report
path: "*.pdf"uses: actions/upload-artifact@v4: utilizza l’azione GitHub per gestire gli artifact, un file o una cartella generati durante l’esecuzione dello script.with: imposta i parametri di configurazione.
La configurazione del progetto di automazione è completa. Ora è il momento di creare gli script Python.
Interrogare l’API di Kinsta in modo programmatico
Una volta completata la configurazione, naviga nella directory principale del progetto GitHub e crea un nuovo file chiamato kinsta_utils.py con il seguente codice:
import requests
import os
KINSTA_API_KEY = os.getenv("KINSTA_API_KEY")
KINSTA_SITE_ID = os.getenv("KINSTA_SITE_ID")
KINSTA_ENV_ID = os.getenv("KINSTA_ENV_ID")
KINSTA_COMPANY_ID = os.getenv("KINSTA_COMPANY_ID")
BASE_URL = f"https://api.kinsta.com/v2/sites/environments/{KINSTA_ENV_ID}/analytics"
def get_headers():
return {"Authorization": f"Bearer {KINSTA_API_KEY}"}- Le prime due dichiarazioni di
importcaricano la libreria standard per effettuare le richieste HTTP e il modulo per interagire con il sistema operativo(os). - Le quattro righe successive
(os.getenv) recuperano le credenziali da GitHub Secrets. BASE_URLdefinisce l’endpoint principale dell’API di Kinsta utilizzato dallo script.- La funzione
get_headersgenera l’Authorization Header, che includerà la chiave API di Kinsta.
Quindi, crea una funzione helper che converta i dati grezzi restituiti dall’API in megabyte.
def format_bytes_to_mb(bytes_value):
"""Converts raw bytes from API to human-readable Megabytes."""
try:
# Standard conversion to MB
# return round(int(bytes_value) / (1024 * 1024), 2)
# Decimal standard (used in MyKinsta dashboard)
return round(int(bytes_value) / 1_000_000, 2)
except (ValueError, TypeError):
return 0- Questo codice offre due opzioni. La prima utilizza lo standard binario
(1024 x 1024), mentre la seconda utilizza lo standard decimale. La divisione per1_000_000assicura che il numero nel report PDF corrisponda al numero che i tuoi clienti vedranno nelle statistiche di MyKinsta.
La seguente funzione interroga l’API di Kinsta e restituisce una serie di dati grezzi:
def fetch_kinsta_metric(endpoint, start_date, end_date):
url = f"{BASE_URL}/{endpoint}"
params = {
"company_id": KINSTA_COMPANY_ID,
"from": f"{start_date}T00:00:00.000Z",
"to": f"{end_date}T23:59:59.000Z"
}
try:
response = requests.get(url, headers=get_headers(), params=params)
if response.status_code == 200:
data_node = response.json()['analytics']['analytics_response']['data'][0]
total = data_node.get('total', 0)
dataset = data_node.get('dataset', [])[:7]
return total, dataset
except Exception as e:
print(f"Error fetching {endpoint}: {e}")
return 0, []- La funzione
fetch_kinsta_metricrichiede tre argomenti:endpoint,start_dateeend_date. Questi vengono utilizzati per costruire l’URL della richiesta. L’endpoint può esserevisits,bandwidthocdn-bandwidth. - L’array
paramscontiene i parametri della richiesta. - La risposta di Kinsta è un oggetto JSON annidato
(data_node) che fornisce i valori aggregati per il periodo(total) e un elenco di valori giornalieri(dataset).
La funzione finale del file kinsta_utils.py recupera il nome del sito.
def fetch_site_name():
url = f"https://api.kinsta.com/v2/sites/{KINSTA_SITE_ID}"
try:
response = requests.get(url, headers=get_headers())
if response.status_code == 200:
data = response.json()
site_data = data.get('site', {})
site_label = site_data.get('display_name', 'Unknown Site')
env_label = "Unknown Env"
envs = site_data.get('environments', [])
for env in envs:
if env.get('id') == KINSTA_ENV_ID:
env_label = env.get('display_name')
break
return f"{site_label} ({env_label})"
else:
print(f"Kinsta API Error: {response.status_code} - {response.text}")
except Exception as e:
print(f"Error fetching site name: {e}")
return "Unknown Site"Questo codice dovrebbe essere autoesplicativo. Per maggiori dettagli sull’endpoint sites, consulta la documentazione dell’API.
Ora non resta che impostare il flusso di lavoro.
Automatizzare il flusso di lavoro con Python e Gemini
L’ultimo file da creare è il motore dell’applicazione. Sempre nella directory principale del progetto GitHub, crea un file main.py. Per iniziare, aggiungi il seguente codice:
import os
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from google.genai import Client
from fpdf import FPDF, XPos, YPos
from datetime import datetime, timedelta
from kinsta_utils import fetch_kinsta_metric, format_bytes_to_mb, fetch_site_name
REPORT_LANG = "en"
MODEL_ID = "gemini-2.5-flash"
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
client = Client(api_key=GEMINI_API_KEY)
today = datetime.now()
curr_end_dt = today - timedelta(days=1)
curr_start_dt = today - timedelta(days=7)
prev_end_dt = today - timedelta(days=8)
prev_start_dt = today - timedelta(days=14)
CURR_RANGE = f"{curr_start_dt.strftime('%b %d')} - {curr_end_dt.strftime('%b %d')}"
PREV_RANGE = f"{prev_start_dt.strftime('%b %d')} - {prev_end_dt.strftime('%b %d')}"
DATES = [
prev_start_dt.strftime("%Y-%m-%d"),
prev_end_dt.strftime("%Y-%m-%d"),
curr_start_dt.strftime("%Y-%m-%d"),
curr_end_dt.strftime("%Y-%m-%d")
]
CURR_DAYS_LABELS = [(curr_start_dt + timedelta(days=i)).strftime("%d %a") for i in range(7)]
PREV_DAYS_LABELS = [(prev_start_dt + timedelta(days=i)).strftime("%d %a") for i in range(7)]
X_AXIS_LABELS = [(curr_start_dt + timedelta(days=i)).strftime("%d") for i in range(7)]Ecco come è impostato lo script:
- Le istruzioni di
importcaricano le librerie necessarie ematplotlib.use('Agg')indica a Python di generare i grafici e di tenerli in memoria. - Il blocco successivo imposta la lingua (
en) e il modello (gemini-2.5-flash), quindi inizializza il client Google. - Poi definisce le finestre temporali per confrontare i valori degli ultimi sette giorni con quelli dei sette giorni precedenti.
- Infine, imposta le etichette per le tabelle e i grafici.
Il passo successivo consiste nel definire una classe KinstaReport per generare pagine di report utilizzando la libreria FPDF:
class KinstaReport(FPDF):
def __init__(self, site_name="Unknown Site"):
super().__init__()
self.site_name = site_name
def header(self):
self.set_font("Helvetica", "B", 8)
self.set_text_color(150)
# Site name
self.cell(100, 10, f"Site: {self.site_name}", align="L")
# Date generated
self.cell(0, 10, f"Kinsta Analytics Report | Generated: {datetime.now().strftime('%Y-%m-%d')}",
align="R", new_x=XPos.LMARGIN, new_y=YPos.NEXT)
def add_metric_page(self, title, chart_path, prev_vals, curr_vals, unit=""):
self.add_page()
# Page title
self.set_font("Helvetica", "B", 24)
self.set_text_color(83, 51, 237)
self.cell(0, 15, title, align="C", new_x=XPos.LMARGIN, new_y=YPos.NEXT)
# Subtitle
self.set_font("Helvetica", "I", 10)
self.set_text_color(120)
self.cell(0, 5, f"Comparison: {CURR_RANGE} vs {PREV_RANGE}", align="C", new_x=XPos.LMARGIN, new_y=YPos.NEXT)
self.image(chart_path, x=10, y=42, w=190)
# Data tables
self.set_y(150)
self.set_font("Helvetica", "B", 10)
self.set_fill_color(245, 245, 255)
self.set_text_color(83, 51, 237)
# Table header
col1, col2 = 35, 60
self.cell(col1, 10, " Day (Prev)", border=1, align='C', fill=True, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col2, 10, f"Value {unit}", border=1, align='C', fill=True, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col1, 10, " Day (Curr)", border=1, align='C', fill=True, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col2, 10, f"Value {unit}", border=1, align='C', fill=True, new_x=XPos.LMARGIN, new_y=YPos.NEXT)
self.set_font("Helvetica", "", 10)
self.set_text_color(50)
for i in range(7):
# Zebra striping
fill = (i % 2 == 0)
if fill: self.set_fill_color(250, 250, 250)
else: self.set_fill_color(255, 255, 255)
self.cell(col1, 9, f" {PREV_DAYS_LABELS[i]}", border=1, align='C', fill=fill, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col2, 9, f" {prev_vals[i]}", border=1, align='C', fill=fill, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col1, 9, f" {CURR_DAYS_LABELS[i]}", border=1, align='C', fill=fill, new_x=XPos.RIGHT, new_y=YPos.TOP)
self.cell(col2, 9, f" {curr_vals[i]}", border=1, align='C', fill=fill, new_x=XPos.LMARGIN, new_y=YPos.NEXT)Non ci dilungheremo troppo su questo codice. Per maggiori informazioni sulla libreria FPDF, consulta le risorse online:
Successivamente, definisci una funzione generated_chart. Questa funzione converte i dati grezzi ricevuti da Kinsta in grafici.
def generate_chart(labels, curr, prev, title, ylabel, filename, is_bar=False):
plt.figure(figsize=(10, 5), dpi=100)
ax = plt.gca()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_color('#dddddd')
ax.spines['bottom'].set_color('#dddddd')
if is_bar:
# Bar Chart for bandwidth
bars = plt.bar(labels, curr, color='#00c4b4', alpha=0.6, label='Current Period', width=0.6)
# Add labels above the bars
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height + 0.02, f'{height}', ha='center', va='bottom', fontsize=8, color='#00a194')
else:
# Line chart for visits
plt.plot(labels, curr, color='#5333ed', marker='o', markersize=6, linewidth=3, label='Current', zorder=3)
plt.plot(labels, prev, color='#a1a1a1', linestyle='--', marker='x', markersize=5, linewidth=1.5, label='Previous', alpha=0.6)
plt.fill_between(labels, curr, color='#5333ed', alpha=0.1)
plt.title(title, fontsize=14, pad=20, color='#333333', fontweight='bold')
plt.ylabel(ylabel, color='#666666')
plt.xlabel("Day of Month", color='#666666')
plt.legend(frameon=False, loc='upper right')
plt.grid(axis='y', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.savefig(filename)
plt.close()Questa funzione utilizza la libreria Matplotlib per convertire i dati estratti da Kinsta in grafici da inserire nel report PDF. Per maggiori informazioni sull’uso della libreria Matplotlib, consulta la documentazione online:
Infine, aggiungi la funzione che combina tutte le parti che abbiamo descritto finora.
def main():
site_display_name = fetch_site_name()
metrics = {
"visits": {"title": "Site Visits", "unit": ""},
"bandwidth": {"title": "Server Bandwidth", "unit": "(MB)"},
"cdn-bandwidth": {"title": "CDN Bandwidth", "unit": "(MB)"}
}
report_data = {}
for key in metrics:
_, data_curr = fetch_kinsta_metric(key, DATES[2], DATES[3])
_, data_prev = fetch_kinsta_metric(key, DATES[0], DATES[1])
curr_vals = []
prev_vals = []
for i in range(7):
c = float(data_curr[i]['value']) if i < len(data_curr) else 0
p = float(data_prev[i]['value']) if i < len(data_prev) else 0
if "bandwidth" in key:
curr_vals.append(format_bytes_to_mb(c))
prev_vals.append(format_bytes_to_mb(p))
else:
curr_vals.append(int(c))
prev_vals.append(int(p))
report_data[key] = {"curr": curr_vals, "prev": prev_vals}
pdf = KinstaReport(site_name=site_display_name)
for key, info in metrics.items():
chart_file = f"{key}_chart.png"
generate_chart(X_AXIS_LABELS, report_data[key]["curr"], report_data[key]["prev"],
f"{info['title']} Trends", "Units", chart_file, is_bar=("bandwidth" in key))
pdf.add_metric_page(info["title"], chart_file, report_data[key]["prev"], report_data[key]["curr"], info["unit"])
# Executive Summary
pdf.add_page()
pdf.set_font("Helvetica", "B", 20)
pdf.set_text_color(83, 51, 237)
pdf.cell(0, 15, "Executive Summary", align="C", new_x=XPos.LMARGIN, new_y=YPos.NEXT)
curr_visits = sum(report_data['visits']['curr'])
prev_visits = sum(report_data['visits']['prev'])
curr_bw = sum(report_data['bandwidth']['curr'])
prev_bw = sum(report_data['bandwidth']['prev'])
try:
summary_prompt = (
f"Analyze Kinsta performance for site {site_display_name}. "
f"Current Period ({CURR_RANGE}): {curr_visits} visits, {curr_bw:.2f}MB server bandwidth. "
f"Previous Period ({PREV_RANGE}): {prev_visits} visits, {prev_bw:.2f}MB server bandwidth. "
f"Compare these periods and identify trends. Language: {REPORT_LANG}. Max 4 sentences."
)
response = client.models.generate_content(model=MODEL_ID, contents=summary_prompt)
summary = response.text
except Exception as e:
summary = f"Analytical insights unavailable. Error: {str(e)}"
pdf.set_y(40)
pdf.set_font("Helvetica", "", 12)
pdf.set_text_color(0)
pdf.multi_cell(0, 8, summary)
report_filename = f"Kinsta_Report_{datetime.now().strftime('%Y-%m-%d')}.pdf"
pdf.output(report_filename)
print(f"Report generated: {report_filename}")
if __name__ == "__main__":
main()Ecco cosa fa questo codice:
- Il ciclo
foritera l’array dimetricse interroga l’API di Kinsta due volte: una per la settimana corrente e una per la settimana precedente. - Se i dati riguardano la larghezza di banda, la funzione
format_bytes_to_mb()converte i dati grezzi in MB. - La funzione
report_data()memorizza i dati recuperati. KinstaReportcrea quindi un PDF per ogni sito.- Il ciclo
forsuccessivo genera immagini PNG per i grafici e crea una nuova pagina per ogni metrica. - La sezione successiva genera il riepilogo, calcola il numero totale di visite e i megabyte totali del periodo e invia un prompt dinamico a Gemini 2.5 Flash. Infine, la risposta viene utilizzata per completare l’ultima pagina del PDF.
- Lo script salva il documento con un nome di file che include la data corrente.
- * La condizione finale assicura che il processo venga eseguito solo quando lo script viene eseguito come programma principale.
È ora di creare ed eseguire l’applicazione.
Recuperare l’artefatto
Ora puoi eseguire la tua applicazione. Nella pagina del tuo progetto GitHub, clicca sulla scheda Actions. Cerca il nome dell’azione nel menu a sinistra (nel nostro esempio è Generate Kinsta Analytics Report, come specificato nel file generate_report.yml ).
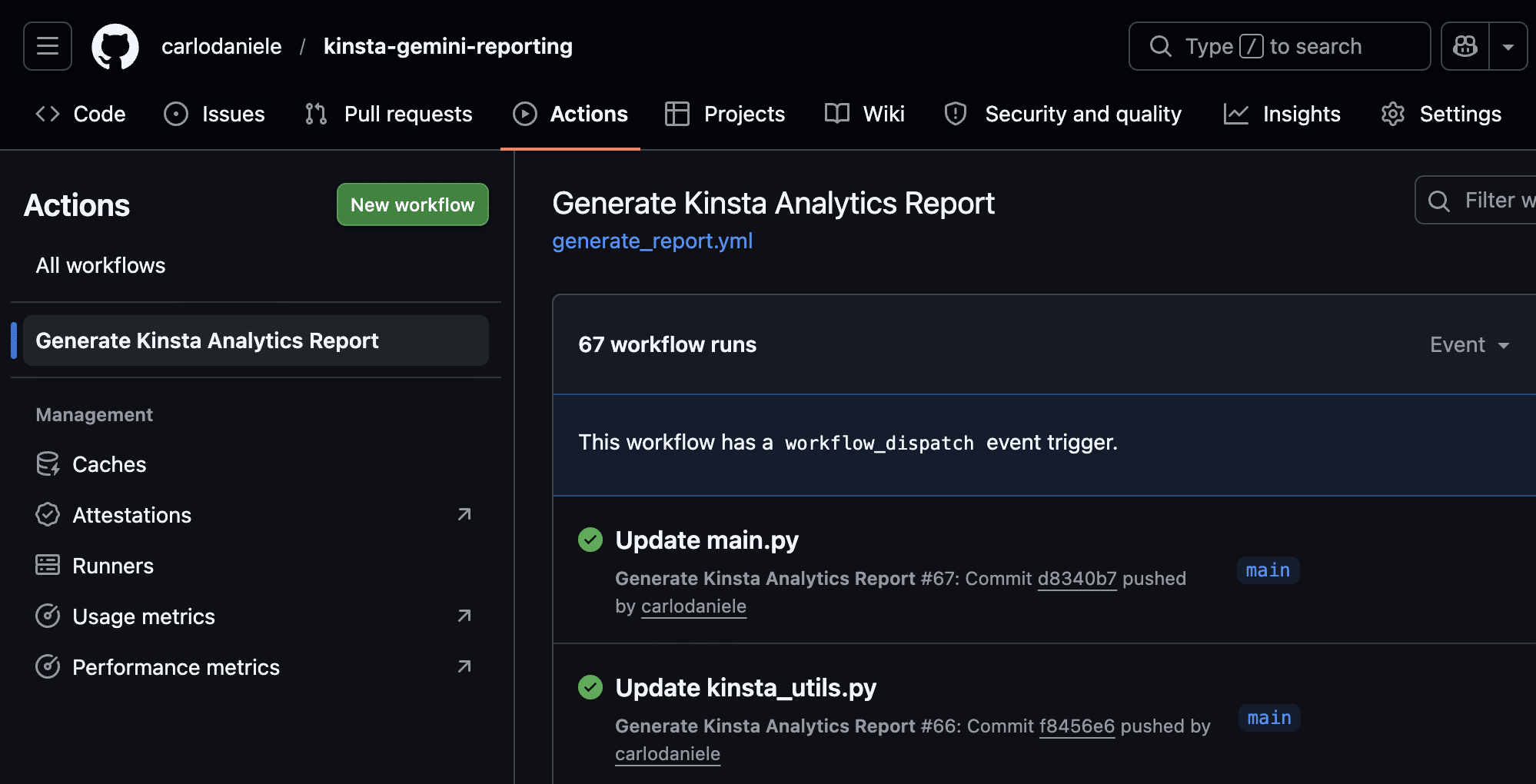
Successivamente, clicca sul menu Run workflow a destra, poi clicca sul pulsante verde Run workflow (al momento è disponibile solo il branch principale).
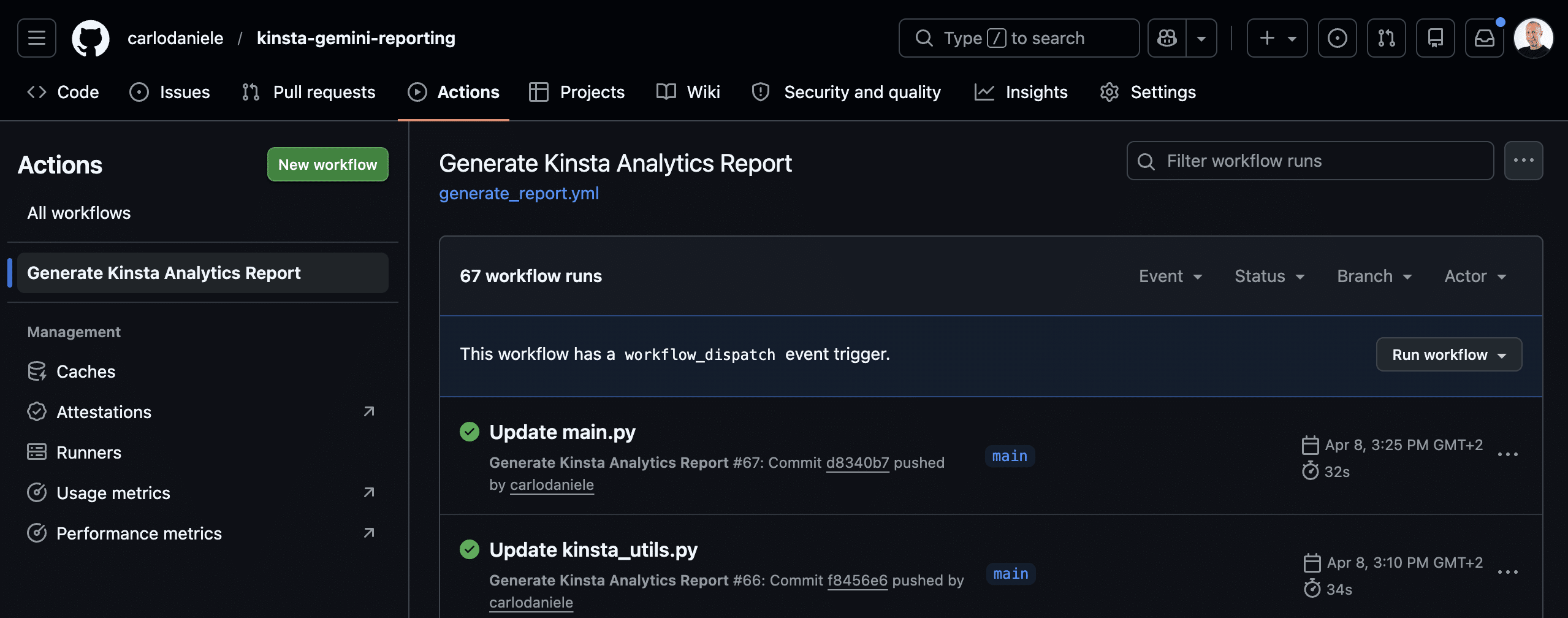
La pagina successiva mostra il flusso di lavoro corrente. Cliccaci per visualizzare l’elenco delle operazioni in corso.
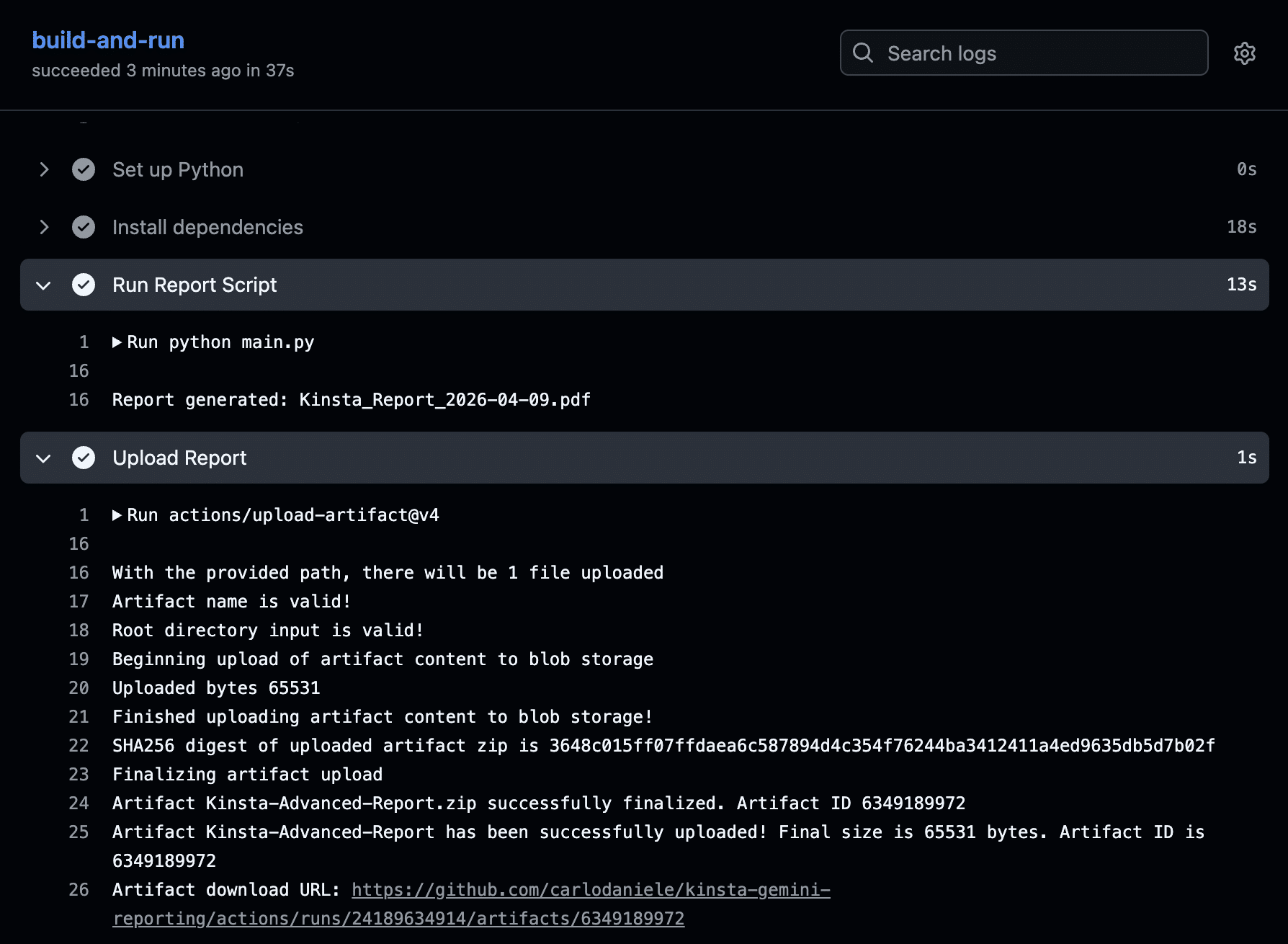
La sezione Run Report Script fornisce un elenco delle operazioni eseguite, mentre la sezione Upload Report fornisce l’URL di download dell’artefatto. Clicca su questo link per scaricare il tuo report in formato PDF.
Troverai lo stesso link nella sezione Artifacts, in fondo alla pagina Summary del flusso di lavoro.
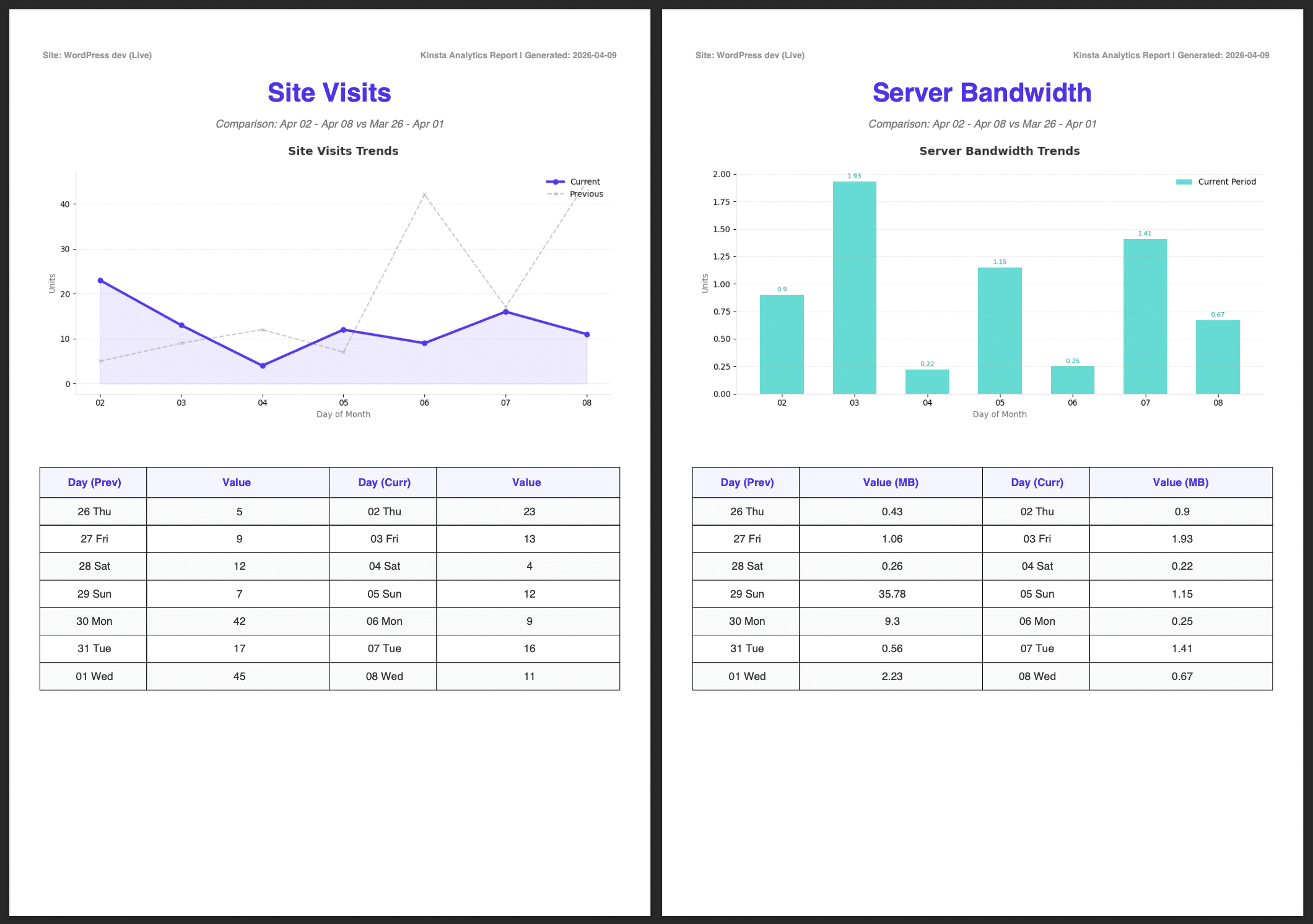
Le immagini sottostanti mostrano il report completo, compreso l’Executive Summary generato da Google AI.
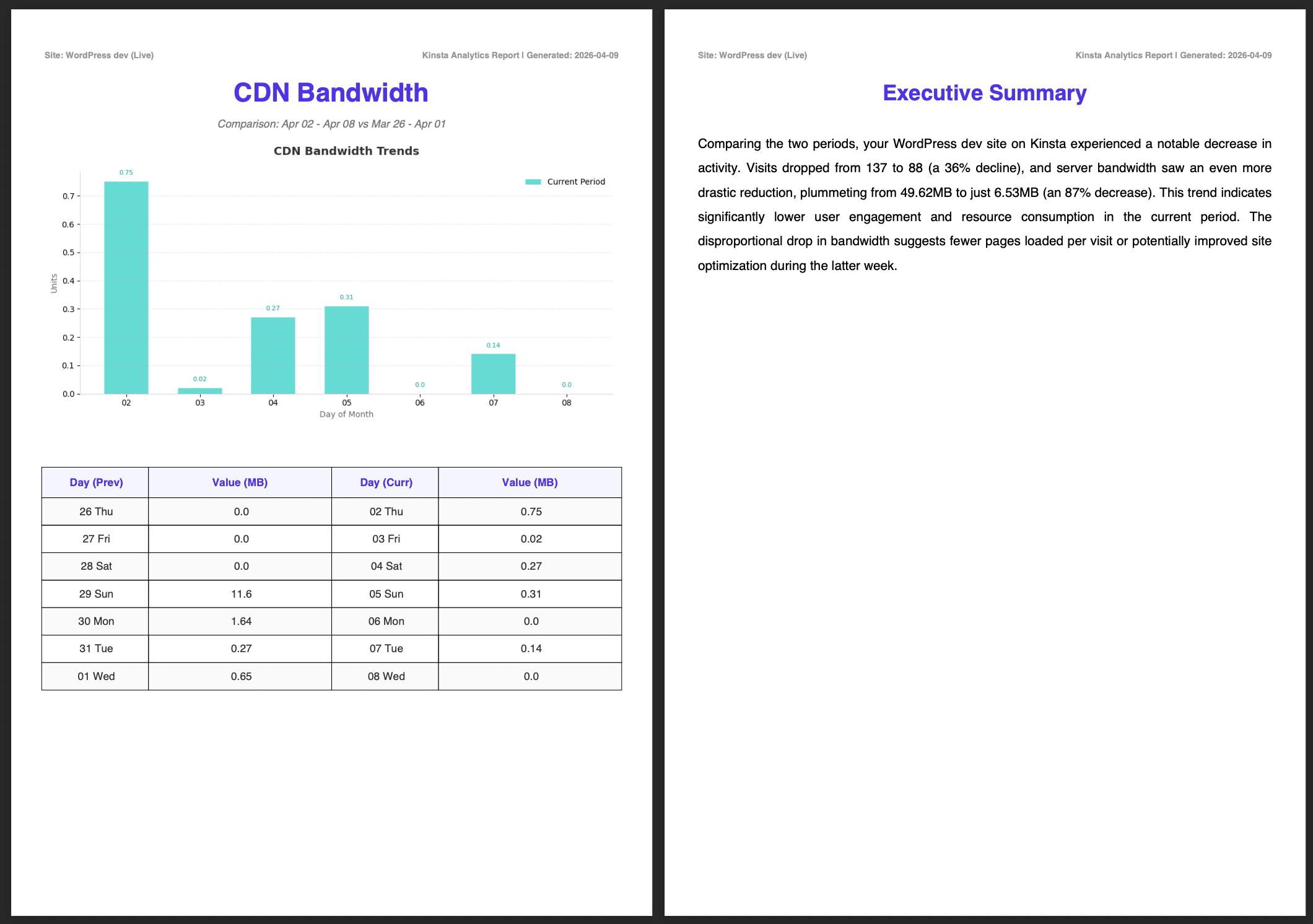
Passi successivi: come migliorare la scalabilità e automatizzare la distribuzione
Questo è solo un assaggio di ciò che l’API di Kinsta può fare se combinata con strumenti di automazione avanzati come GitHub Actions. L’integrazione con l’intelligenza artificiale permette di andare oltre, trasformando i numeri grezzi in rapporti approfonditi pronti per essere condivisi con i tuoi clienti.
Puoi migliorare ulteriormente i tuoi report in diversi modi:
- Puoi configurare la tua applicazione aggiungendo una riga al file YAML (
schedule: '0 9 * * 1') per generare il report ogni lunedì mattina alle 9:00. - Puoi integrare una libreria come
smtplibo un servizio come SendGrid per inviare il report direttamente al cliente. - Se hai un’agenzia con decine o addirittura centinaia di siti, potresti implementare un ciclo che itera su un elenco di ID di siti per generare tutti i report in un’unica esecuzione.
- Puoi arricchire ulteriormente il contenuto del report utilizzando l’API di Kinsta per recuperare dati geografici, codici HTTP, log del server e qualsiasi altro dato tu voglia includere. Analizzando questi dati, l’intelligenza artificiale può identificare i tentativi di attacco (codici 4xx) o i picchi di traffico provenienti da regioni inaspettate.
- Puoi perfezionare la tua richiesta per ottenere risposte dell’IA più dettagliate e complete.
- Puoi personalizzare il template PDF con i loghi della tua agenzia e del tuo cliente.
Il reporting automatico riduce il carico di lavoro del tuo team e la coerenza e la precisione che ne derivano rafforzano la fiducia e la fedeltà dei tuoi clienti.
Vuoi iniziare subito ad automatizzare i report per i tuoi clienti? Scegli il piano più adatto alle tue esigenze e inizia subito a costruire con l’API di Kinsta.

Carlo è cultore appassionato di webdesign e front-end development. Gioca con WordPress da oltre 20 anni, anche in collaborazione con università ed enti educativi italiani ed europei. Su WordPress ha scritto centinaia di articoli e guide, pubblicati sia in siti web italiani e internazionali, che su riviste a stampa. Lo trovate su LinkedIn.

