
Da quando le telecamere sono migliorate, il rilevamento degli oggetti in tempo reale è diventato una funzionalità sempre più richiesta. Dalle auto a guida autonoma ai sistemi di sorveglianza intelligenti, fino alle applicazioni di realtà aumentata, questa tecnologia viene utilizzata in molte situazioni.
La computer vision, termine usato per indicare la tecnologia che utilizza le telecamere e i computer per svolgere operazioni come quelle sopra citate, è un campo vasto e complicato. Tuttavia, forse non sapete che è possibile iniziare a rilevare oggetti in tempo reale in modo molto semplice, comodamente dal vostro browser.
Questo articolo spiega come costruire un’applicazione per il rilevamento di oggetti in tempo reale utilizzando React e distribuendola su Kinsta. L’applicazione per il rilevamento di oggetti in tempo reale sfrutta il feed della webcam dell’utente.
Prerequisiti
Ecco una panoramica delle tecnologie chiave utilizzate in questa guida:
- React: React viene utilizzato per costruire l’interfaccia utente (UI) dell’applicazione. React eccelle nel rendering di contenuti dinamici e sarà utile per presentare il feed della webcam e gli oggetti rilevati nel browser.
- TensorFlow.js: TensorFlow.js è una libreria JavaScript che porta la potenza dell’apprendimento automatico nel browser. Permette di caricare modelli pre-addestrati per il rilevamento degli oggetti e di eseguirli direttamente nel browser, eliminando la necessità di una complessa elaborazione lato server.
- Coco SSD: L’applicazione utilizza un modello di rilevamento degli oggetti pre-addestrato chiamato Coco SSD, un modello leggero in grado di riconoscere una vasta gamma di oggetti quotidiani in tempo reale. Sebbene Coco SSD sia uno strumento potente, è importante notare che è stato addestrato su un insieme generale di oggetti. Se si hanno esigenze specifiche di riconoscimento, è possibile addestrare un modello personalizzato utilizzando TensorFlow.js seguendo questa guida.
Impostare un nuovo progetto React
- Creiamo un nuovo progetto React. Eseguiamo questo comando:
npm create vite@latest kinsta-object-detection --template reactIn questo modo verrà creato un progetto React di base utilizzando vite.
- Successivamente, installiamo le librerie TensorFlow e Coco SSD eseguendo i comandi qui sotto nel progetto:
npm i @tensorflow-models/coco-ssd @tensorflow/tfjs
Ora siamo pronti per iniziare a sviluppare la nostra applicazione.
Configurazione dell’applicazione
Prima di scrivere il codice per la logica di rilevamento degli oggetti, cerchiamo di capire cosa viene sviluppato in questa guida. Ecco come appare l’interfaccia utente dell’applicazione:
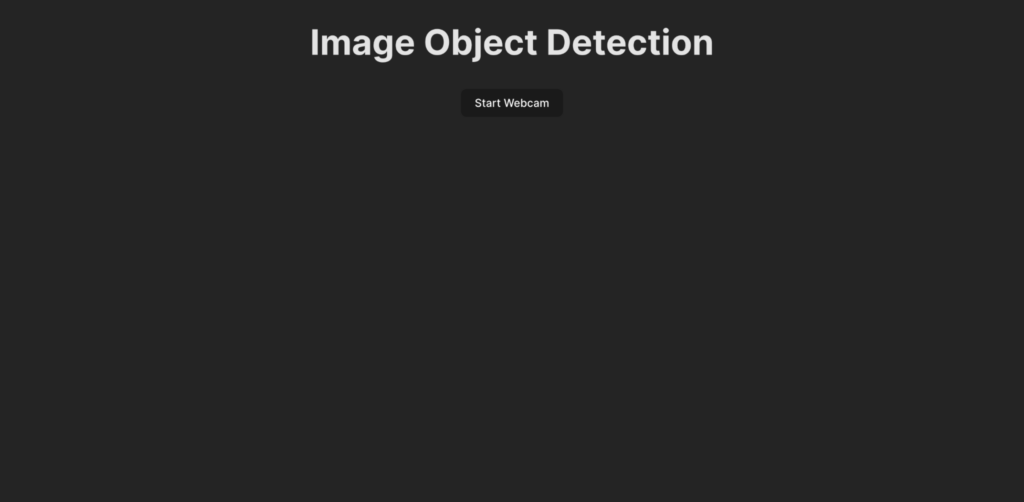
Quando un utente clicca sul pulsante Avvia webcam, gli viene chiesto di concedere all’applicazione il permesso di accedere al feed della webcam. Una volta concessa l’autorizzazione, l’applicazione inizia a mostrare il feed della webcam e rileva gli oggetti presenti nel feed. A questo punto, crea un riquadro per mostrare gli oggetti rilevati sul live feed e aggiunge anche un’etichetta.
Per iniziare, creiamo l’interfaccia utente dell’applicazione incollando il seguente codice nel file App.jsx:
import ObjectDetection from './ObjectDetection';
function App() {
return (
<div className="app">
<h1>Image Object Detection</h1>
<ObjectDetection />
</div>
);
}
export default App;Questo frammento di codice specifica un’intestazione per la pagina e importa un componente personalizzato chiamato ObjectDetection. Questo componente contiene la logica per catturare il feed della webcam e rilevare gli oggetti in tempo reale.
Per creare questo componente, creiamo un nuovo file chiamato ObjectDetection.jsx nella cartella src e incolliamoci il seguente codice:
import { useEffect, useRef, useState } from 'react';
const ObjectDetection = () => {
const videoRef = useRef(null);
const [isWebcamStarted, setIsWebcamStarted] = useState(false)
const startWebcam = async () => {
// TODO
};
const stopWebcam = () => {
// TODO
};
return (
<div className="object-detection">
<div className="buttons">
<button onClick={isWebcamStarted ? stopWebcam : startWebcam}>{isWebcamStarted ? "Stop" : "Start"} Webcam</button>
</div>
<div className="feed">
{isWebcamStarted ? <video ref={videoRef} autoPlay muted /> : <div />}
</div>
</div>
);
};
export default ObjectDetection;Il codice qui sopra definisce una struttura HTML con un pulsante per avviare e interrompere il feed della webcam e un elemento <video> che verrà utilizzato per mostrare all’utente il feed della webcam una volta attivo. Un contenitore di stato isWebcamStarted viene utilizzato per memorizzare lo stato del feed della webcam. Due funzioni, startWebcam e stopWebcam, sono utilizzate per avviare e interrompere il feed della webcam. Definiamole:
Ecco il codice della funzione startWebcam:
const startWebcam = async () => {
try {
setIsWebcamStarted(true)
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
if (videoRef.current) {
videoRef.current.srcObject = stream;
}
} catch (error) {
setIsWebcamStarted(false)
console.error('Error accessing webcam:', error);
}
};Questa funzione si occupa di chiedere all’utente di concedere l’accesso alla webcam e, una volta concessa l’autorizzazione, imposta <video> per mostrare all’utente il feed della webcam in diretta.
Se il codice non riesce ad accedere al feed della webcam (forse a causa della mancanza di una webcam sul dispositivo corrente o perché all’utente viene negata l’autorizzazione), la funzione stamperà un messaggio nella console. Possiamo utilizzare un blocco di errore per mostrare all’utente il motivo del fallimento.
Quindi, sostituiamo la funzione stopWebcam con il seguente codice:
const stopWebcam = () => {
const video = videoRef.current;
if (video) {
const stream = video.srcObject;
const tracks = stream.getTracks();
tracks.forEach((track) => {
track.stop();
});
video.srcObject = null;
setPredictions([])
setIsWebcamStarted(false)
}
};Questo codice controlla le tracce del flusso video in esecuzione a cui l’oggetto <video> sta accedendo e arresta ciascuna di esse. Infine, imposta lo stato isWebcamStarted su false.
A questo punto, proviamo a eseguire l’applicazione per verificare se possiamo accedere e visualizzare il feed della webcam.
Incolliamo il seguente codice nel file index.css per assicurarci che l’app abbia lo stesso aspetto dell’anteprima che abbiamo visto prima:
#root {
font-family: Inter, system-ui, Avenir, Helvetica, Arial, sans-serif;
line-height: 1.5;
font-weight: 400;
color-scheme: light dark;
color: rgba(255, 255, 255, 0.87);
background-color: #242424;
min-width: 100vw;
min-height: 100vh;
font-synthesis: none;
text-rendering: optimizeLegibility;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
a {
font-weight: 500;
color: #646cff;
text-decoration: inherit;
}
a:hover {
color: #535bf2;
}
body {
margin: 0;
display: flex;
place-items: center;
min-width: 100vw;
min-height: 100vh;
}
h1 {
font-size: 3.2em;
line-height: 1.1;
}
button {
border-radius: 8px;
border: 1px solid transparent;
padding: 0.6em 1.2em;
font-size: 1em;
font-weight: 500;
font-family: inherit;
background-color: #1a1a1a;
cursor: pointer;
transition: border-color 0.25s;
}
button:hover {
border-color: #646cff;
}
button:focus,
button:focus-visible {
outline: 4px auto -webkit-focus-ring-color;
}
@media (prefers-color-scheme: light) {
:root {
color: #213547;
background-color: #ffffff;
}
a:hover {
color: #747bff;
}
button {
background-color: #f9f9f9;
}
}
.app {
width: 100%;
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
}
.object-detection {
width: 100%;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
.buttons {
width: 100%;
display: flex;
justify-content: center;
align-items: center;
flex-direction: row;
button {
margin: 2px;
}
}
div {
margin: 4px;
}
}Inoltre, rimuoviamo il file App.css per evitare di rovinare gli stili dei componenti. Ora siamo pronti a scrivere la logica per integrare il rilevamento degli oggetti in tempo reale nell’app.
Impostare il rilevamento degli oggetti in tempo reale
- Iniziamo aggiungendo le importazioni di Tensorflow e Coco SSD all’inizio di ObjectDetection.jsx:
import * as cocoSsd from '@tensorflow-models/coco-ssd'; import '@tensorflow/tfjs'; - Quindi, creiamo uno stato nel componente
ObjectDetectionper memorizzare l’array di previsioni generate dal modello Coco SSD:const [predictions, setPredictions] = useState([]); - Creiamo poi una funzione che carichi il modello Coco SSD, raccolga il feed video e generi le previsioni:
const predictObject = async () => { const model = await cocoSsd.load(); model.detect(videoRef.current).then((predictions) => { setPredictions(predictions); }) .catch(err => { console.error(err) }); };Questa funzione utilizza il feed video e genera previsioni per gli oggetti presenti nel feed. Ci fornirà un array di oggetti previsti, ognuno dei quali contiene un’etichetta, una percentuale di attendibilità e una serie di coordinate che indicano la posizione dell’oggetto nel fotogramma video.
Dobbiamo richiamare continuamente questa funzione per elaborare i fotogrammi video man mano che arrivano e poi utilizzare le previsioni memorizzate nello stato
predictionsper mostrare i riquadri e le etichette di ogni oggetto identificato sul video in diretta. - Quindi, utilizziamo la funzione
setIntervalper richiamare la funzione in modo continuo. Dobbiamo anche impedire che questa funzione venga richiamata dopo che l’utente ha interrotto il feed della webcam. Per farlo, usiamo la funzioneclearIntervalda JavaScript. Aggiungiamo il seguente contenitore di stato e l’hookuseEffectnel componenteObjectDetectionper impostare la funzionepredictObjectin modo che venga chiamata continuamente quando la webcam è attiva e rimossa quando la webcam è disattivata:const [detectionInterval, setDetectionInterval] = useState() useEffect(() => { if (isWebcamStarted) { setDetectionInterval(setInterval(predictObject, 500)) } else { if (detectionInterval) { clearInterval(detectionInterval) setDetectionInterval(null) } } }, [isWebcamStarted])In questo modo l’applicazione rileva gli oggetti presenti davanti alla webcam ogni 500 millisecondi. Possiamo modificare questo valore a seconda della velocità con cui vogliamo che il rilevamento degli oggetti avvenga, tenendo presente che un’operazione troppo frequente potrebbe far sì che l’applicazione utilizzi molta memoria nel browser.
- Ora che abbiamo i dati di previsione nel contenitore di stato
prediction, possiamo usarli per visualizzare un’etichetta e un riquadro intorno all’oggetto nel video in diretta. Per farlo, aggiorniamo la dichiarazionereturndel contenitoreObjectDetectionin modo che restituisca quanto segue:return ( <div className="object-detection"> <div className="buttons"> <button onClick={isWebcamStarted ? stopWebcam : startWebcam}>{isWebcamStarted ? "Stop" : "Start"} Webcam</button> </div> <div className="feed"> {isWebcamStarted ? <video ref={videoRef} autoPlay muted /> : <div />} {/* Add the tags below to show a label using the p element and a box using the div element */} {predictions.length > 0 && ( predictions.map(prediction => { return <> <p style={{ left: `${prediction.bbox[0]}px`, top: `${prediction.bbox[1]}px`, width: `${prediction.bbox[2] - 100}px` }}>{prediction.class + ' - with ' + Math.round(parseFloat(prediction.score) * 100) + '% confidence.'}</p> <div className={"marker"} style={{ left: `${prediction.bbox[0]}px`, top: `${prediction.bbox[1]}px`, width: `${prediction.bbox[2]}px`, height: `${prediction.bbox[3]}px` }} /> </> }) )} </div> {/* Add the tags below to show a list of predictions to user */} {predictions.length > 0 && ( <div> <h3>Predictions:</h3> <ul> {predictions.map((prediction, index) => ( <li key={index}> {`${prediction.class} (${(prediction.score * 100).toFixed(2)}%)`} </li> ))} </ul> </div> )} </div> );Questo renderà un elenco di previsioni proprio sotto il feed della webcam e disegnerà un riquadro intorno all’oggetto previsto utilizzando le coordinate di Coco SSD insieme a un’etichetta nella parte superiore del riquadro.
- Per creare correttamente i riquadri e l’etichetta, aggiungiamo il seguente codice al file index.css:
.feed { position: relative; p { position: absolute; padding: 5px; background-color: rgba(255, 111, 0, 0.85); color: #FFF; border: 1px dashed rgba(255, 255, 255, 0.7); z-index: 2; font-size: 12px; margin: 0; } .marker { background: rgba(0, 255, 0, 0.25); border: 1px dashed #fff; z-index: 1; position: absolute; } }Questo completa lo sviluppo dell’applicazione. Ora possiamo riavviare il server dev per testare l’applicazione. Ecco come dovrebbe apparire una volta completata:

Dimostrazione del rilevamento di oggetti in tempo reale tramite webcam
Il codice completo si trova in questo repository GitHub.
Distribuire l’applicazione completata su Kinsta
Il passo finale consiste nel distribuire l’app su Kinsta per renderla disponibile ai nostri utenti. Per farlo, Kinsta permette di ospitare gratuitamente fino a 100 siti web statici direttamente dal proprio provider Git preferito (Bitbucket, GitHub o GitLab).
Una volta che il repository git sarà pronto, seguiamo questi passaggi per distribuire l’app di rilevamento oggetti su Kinsta:
- Accediamo o creiamo un account per visualizzare la nostra dashboard MyKinsta.
- Autorizziamo Kinsta con il provider Git.
- Clicchiamo su Siti statici nella barra laterale di sinistra e poi su Aggiungi sito.
- Selezioniamo il repository e il branch da cui desideriamo effettuare il deploy.
- Assegniamo un nome unico al sito.
- Aggiungiamo le impostazioni di build nel seguente formato:
- Comando di build:
yarn buildoppurenpm run build - Versione node:
20.2.0 - Directory di pubblicazione:
dist
- Comando di build:
- Infine, clicchiamo su Crea sito.
Una volta che l’applicazione è stata distribuita, possiamo cliccare su Visita il sito dalla dashboard per accedere all’applicazione. Ora possiamo provare a eseguire l’applicazione su vari dispositivi con telecamere per vedere come si comporta.
In alternativa all’Hosting di Siti Statici, possiamo distribuire il nostro sito statico con l’Hosting di Applicazioni di Kinsta, che offre una maggiore flessibilità di hosting, una gamma più ampia di vantaggi e l’accesso a funzioni più robuste. Ad esempio, la scalabilità, la distribuzione personalizzata tramite un file Docker e l’analisi completa dei dati storici e in tempo reale.
Riepilogo
Abbiamo realizzato con successo un’applicazione per il rilevamento di oggetti in tempo reale utilizzando React, TensorFlow.js e Kinsta. Questo ci permette di esplorare l’entusiasmante mondo della computer vision e di creare esperienze interattive direttamente nel browser dell’utente.
Ricordate che il modello Coco SSD che abbiamo utilizzato è solo un punto di partenza. Con un’ulteriore esplorazione, potrete approfondire il rilevamento di oggetti personalizzati utilizzando TensorFlow.js, e quindi personalizzare l’app per identificare oggetti specifici rilevanti per le vostre esigenze.
Le possibilità sono vastissime: questa applicazione è la base per costruire applicazioni più dettagliate, come esperienze di realtà aumentata o sistemi di sorveglianza intelligenti. Distribuendo la vostra applicazione sull’affidabile piattaforma di Kinsta, potrete condividere la vostra creazione con il mondo e vedere la potenza della computer vision prendere vita.
C’è qualche problema che avete riscontrato e che pensate possa essere risolto con il rilevamento degli oggetti in tempo reale? Fatecelo sapere nei commenti qui sotto!

Kumar è software developer e autore tecnico con sede in India. È specializzato in JavaScript e DevOps. Per saperne di più sul suo lavoro, visitate il suo sito web.

