
Se gestite molti siti WordPress, probabilmente sarete sempre alla ricerca di modi per semplificare e velocizzare i vostri workflow.
Ora, immaginate questo: con un solo comando nel terminale, potete attivare i backup manuali per tutti i vostri siti, anche se ne gestite a decine. Questa è la comodità di combinare lo shell scripting con l’API di Kinsta.
Questa guida mostra come utilizzare gli shell script per impostare comandi personalizzati che rendono più efficiente la gestione dei vostri siti.
Prerequisiti
Prima di iniziare, ecco cosa serve:
- Un terminale. Tutti i sistemi operativi moderni sono dotati di un software di terminale, quindi è possibile iniziare a creare script subito.
- Un IDE o un editor di testo. Consigliamo di usare uno strumento che si conosce bene, come VS Code, Sublime Text o anche un editor leggero come Nano per modificare rapidamente il terminale.
- Una chiave API Kinsta. È essenziale per interagire con l’API di Kinsta. Per generare una chiave API basta:
- Accedere alla dashboard MyKinsta.
- Andare su Nome utente > Impostazioni azienda > Chiavi API.
- Cliccare su Crea chiave API e salvarla in modo sicuro.
curlejq. Essenziali per effettuare richieste API e gestire i dati JSON. Consigliamo di verificare che siano installati o di installarli.- Conoscenze di base di programmazione. Non è necessario essere degli esperti, ma la comprensione delle basi della programmazione e della sintassi degli shell script sarà molto utile.
Scrivere il primo script
Creare il primo shell script per interagire con l’API di Kinsta è più semplice di quanto possiate pensare. Cominciamo con un semplice script che elenca tutti i siti WordPress gestiti da un account Kinsta.
Passo 1: Configurare l’ambiente
Iniziamo creando una cartella per il nostro progetto e un nuovo file di script. L’estensione .sh è utilizzata per gli shell script. Ad esempio, possiamo creare una cartella, navigare al suo interno e creare e aprire un file di script in VS Code utilizzando questi comandi:
mkdir my-first-shell-scripts
cd my-first-shell-scripts
touch script.sh
code script.shPasso 2: Definire le variabili d’ambiente
Per proteggere la chiave API, memorizziamola in un file .env invece di inserirla nello script. Ciò permette di aggiungere il file .env a .gitignore, evitando che venga inviato al controllo di versione.
Nel file .env, aggiungiamo:
API_KEY=your_kinsta_api_keySuccessivamente, inseriamo la chiave API dal file .env nello script aggiungendo quanto segue all’inizio dello script:
#!/bin/bash
source .envLo shebang #!/bin/bash assicura che lo script venga eseguito con Bash, mentre source .env importa le variabili d’ambiente.
Passo 3: Scrivere la richiesta API
Per prima cosa, memorizziamo l’ID azienda (che si trova in MyKinsta alla voce Impostazioni azienda > Dettagli di fatturazione) in una variabile:
COMPANY_ID="<your_company_id>"Quindi, aggiungiamo il comando curl per effettuare una richiesta GET all’endpoint /sites, passando l’ID dell’azienda come parametro della query. Usiamo jq per formattare l’output in modo da renderlo più leggibile:
curl -s -X GET
"https://api.kinsta.com/v2/sites?company=$COMPANY_ID"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json" | jqQuesta richiesta recupera i dettagli di tutti i siti associati all’azienda, compresi i loro ID, nomi e stati.
Passo 4: Rendere lo script eseguibile
Salviamo lo script e rendiamolo eseguibile:
chmod +x script.shPasso 5: Eseguire lo script
Eseguiamo lo script per visualizzare un elenco formattato dei nostri siti:
./list_sites.shEseguendo lo script, otterremo una risposta simile a questa:
{
"company": {
"sites": [
{
"id": "a8f39e7e-d9cf-4bb4-9006-ddeda7d8b3af",
"name": "bitbuckettest",
"display_name": "bitbucket-test",
"status": "live",
"site_labels": []
},
{
"id": "277b92f8-4014-45f7-a4d6-caba8f9f153f",
"name": "duketest",
"display_name": "zivas Signature",
"status": "live",
"site_labels": []
}
]
}
}Anche se funziona, miglioriamolo impostando una funzione che recuperi e formatti i dettagli del sito per facilitarne la lettura.
Passo 6: Rifattorizzare con una funzione
Sostituiamo la richiesta di curl con una funzione riutilizzabile per gestire il recupero e la formattazione dell’elenco dei siti:
list_sites() {
echo "Fetching all sites for company ID: $COMPANY_ID..."
RESPONSE=$(curl -s -X GET "https://api.kinsta.com/v2/sites?company=$COMPANY_ID"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
# Check for errors
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API."
exit 1
fi
echo "Company Sites:"
echo "--------------"
echo "$RESPONSE" | jq -r '.company.sites[] | "(.display_name) ((.name)) - Status: (.status)"'
}
# Run the function
list_sitesQuando eseguiremo nuovamente lo script, otterremo un output ben formattato:
Fetching all sites for company ID: b383b4c-****-****-a47f-83999c5d2...
Company Sites:
--------------
bitbucket-test (bitbuckettest) - Status: live
zivas Signature (duketest) - Status: liveCon questo script, avremo fatto il primo passo verso l’utilizzo degli shell script e dell’API di Kinsta per automatizzare la gestione dei siti WordPress. Nelle prossime sezioni esploreremo la creazione di script più avanzati per interagire con l’API in modi davvero interessanti.
Caso d’uso avanzato 1: Creare dei backup
La creazione di backup è un aspetto cruciale della gestione di un sito web. Permettono di ripristinare il sito in caso di problemi imprevisti. Con l’API di Kinsta e gli shell script, questo processo può essere automatizzato, risparmiando tempo e fatica.
In questa sezione creeremo dei backup e affronteremo il limite di Kinsta di cinque backup manuali per ambiente. Per gestire questo problema, implementeremo un processo per:
- Controllare il numero attuale di backup manuali.
- Identificare ed eliminare il backup più vecchio (con la conferma dell’utente) se il limite è stato raggiunto.
- Procedere alla creazione di un nuovo backup.
Vediamone i dettagli.
Il workflow dei backup
Per creare i backup utilizzando l’API di Kinsta, bisognerà utilizzare il seguente endpoint:
POST /sites/environments/{env_id}/manual-backupsQuesto richiede:
- ID ambiente: identifica l’ambiente (come staging o live) in cui verrà creato il backup.
- Tag del backup: si tratta di un’etichetta per identificare il backup (opzionale).
Recuperare manualmente l’ID ambiente ed eseguire un comando come backup <environment ID> può essere complicato. Invece, creeremo uno script facile da usare in cui dovremo semplicemente specificare il nome del sito e lo script:
- Recupererà l’elenco degli ambienti del sito.
- Chiederà di scegliere l’ambiente di cui eseguire il backup.
- Gestirà il processo di creazione del backup.
Funzioni riutilizzabili per un codice pulito
Per mantenere il nostro script modulare e riutilizzabile, definiremo delle funzioni per compiti specifici. Esaminiamo la configurazione passo dopo passo.
1. Impostare le variabili di base
Possiamo eliminare il primo script che abbiamo creato o creare un nuovo file di script apposito. Iniziamo dichiarando l’URL dell’API Kinsta di base e l’ID dell’azienda nello script:
BASE_URL="https://api.kinsta.com/v2"
COMPANY_ID="<your_company_id>"Queste variabili permettono di costruire gli endpoint dell’API in modo dinamico all’interno dello script.
2. Recuperare tutti i siti
Definiamo una funzione per recuperare l’elenco di tutti i siti aziendali. Ciò permette di recuperare i dettagli di ogni sito in un secondo momento.
get_sites_list() {
API_URL="$BASE_URL/sites?company=$COMPANY_ID"
echo "Fetching all sites for company ID: $COMPANY_ID..."
RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
# Check for errors
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API."
exit 1
fi
echo "$RESPONSE"
}Noterete che questa funzione restituisce una risposta non formattata dall’API. Per ottenere una risposta formattata, possiamo aggiungere un’altra funzione per gestirla (ma non è questo il nostro obiettivo in questa sezione):
list_sites() {
RESPONSE=$(get_sites_list)
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API while fetching sites."
exit 1
fi
echo "Company Sites:"
echo "--------------"
# Clean the RESPONSE before passing it to jq
CLEAN_RESPONSE=$(echo "$RESPONSE" | tr -d 'r' | sed 's/^[^{]*//') # Removes extra characters before the JSON starts
echo "$CLEAN_RESPONSE" | jq -r '.company.sites[] | "(.display_name) ((.name)) - Status: (.status)"'
}Chiamando la funzione list_sites, i siti vengono visualizzati come mostrato in precedenza. L’obiettivo principale, tuttavia, è quello di accedere a ciascun sito e al suo ID, consentendo di recuperare informazioni dettagliate su ciascun sito.
3. Recuperare i dettagli del sito
Per ottenere i dettagli di un sito specifico, usiamo la seguente funzione, che recupera l’ID del sito in base al nome del sito e recupera ulteriori dettagli, come gli ambienti:
get_site_details_by_name() {
SITE_NAME=$1
if [ -z "$SITE_NAME" ]; then
echo "Error: No site name provided. Usage: $0 details-name "
return 1
fi
RESPONSE=$(get_sites_list)
echo "Searching for site with name: $SITE_NAME..."
# Clean the RESPONSE before parsing
CLEAN_RESPONSE=$(echo "$RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')
# Extract the site ID for the given site name
SITE_ID=$(echo "$CLEAN_RESPONSE" | jq -r --arg SITE_NAME "$SITE_NAME" '.company.sites[] | select(.name == $SITE_NAME) | .id')
if [ -z "$SITE_ID" ]; then
echo "Error: Site with name "$SITE_NAME" not found."
return 1
fi
echo "Found site ID: $SITE_ID for site name: $SITE_NAME"
# Fetch site details using the site ID
API_URL="$BASE_URL/sites/$SITE_ID"
SITE_RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
echo "$SITE_RESPONSE"
}La funzione precedente filtra il sito utilizzando il nome del sito e poi recupera ulteriori dettagli sul sito utilizzando l’endpoint /sites/<site-id>. Questi dettagli includono gli ambienti del sito, che ci servono per attivare i backup.
Creare i backup
Ora che abbiamo impostato delle funzioni riutilizzabili per recuperare i dettagli del sito ed elencare gli ambienti, possiamo concentrarci sull’automatizzazione del processo di creazione dei backup. L’obiettivo è quello di eseguire un semplice comando con il solo nome del sito e poi scegliere interattivamente l’ambiente di cui eseguire il backup.
Iniziamo creando una funzione (la chiameremo trigger_manual_backup). All’interno della funzione, definiamo due variabili: la prima per accettare il nome del sito come input e la seconda per impostare un tag predefinito (default-backup) per il backup. Questo tag predefinito verrà applicato a meno che non scegliamo di specificare un tag personalizzato in seguito.
trigger_manual_backup() {
SITE_NAME=$1
DEFAULT_TAG="default-backup"
# Ensure a site name is provided
if [ -z "$SITE_NAME" ]; then
echo "Error: Site name is required."
echo "Usage: $0 trigger-backup "
return 1
fi
# Add the code here
}SITE_NAME è l’identificativo del sito che vogliamo gestire. Inoltre, è possibile impostare una condizione in modo che lo script esca con un messaggio di errore se l’identificatore non viene fornito. Ciò assicura che lo script non proceda senza i dati necessari, evitando potenziali errori API.
Successivamente, utilizziamo la funzione riutilizzabile get_site_details_by_name per ottenere informazioni dettagliate sul sito, compresi i suoi ambienti. La risposta viene poi ripulita per eliminare qualsiasi problema di formattazione inatteso che potrebbe verificarsi durante l’elaborazione.
SITE_RESPONSE=$(get_site_details_by_name "$SITE_NAME")
if [ $? -ne 0 ]; then
echo "Error: Failed to fetch site details for site "$SITE_NAME"."
return 1
fi
CLEAN_RESPONSE=$(echo "$SITE_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Una volta ottenuti i dettagli del sito, lo script sottostante estrae tutti gli ambienti disponibili e li visualizza in un formato leggibile. Questo aiuta a visualizzare quali ambienti sono collegati al sito.
Lo script ci chiede quindi di selezionare un ambiente in base al suo nome. Questa fase interattiva rende il processo più semplice eliminando la necessità di ricordare o inserire gli ID degli ambienti.
ENVIRONMENTS=$(echo "$CLEAN_RESPONSE" | jq -r '.site.environments[] | "(.name): (.id)"')
echo "Available Environments for "$SITE_NAME":"
echo "$ENVIRONMENTS"
read -p "Enter the environment name to back up (e.g., staging, live): " ENV_NAMEIl nome dell’ambiente selezionato viene poi utilizzato per cercare l’ID dell’ambiente corrispondente nei dettagli del sito. Questo ID è necessario per le richieste API per creare un backup.
ENV_ID=$(echo "$CLEAN_RESPONSE" | jq -r --arg ENV_NAME "$ENV_NAME" '.site.environments[] | select(.name == $ENV_NAME) | .id')
if [ -z "$ENV_ID" ]; then
echo "Error: Environment "$ENV_NAME" not found for site "$SITE_NAME"."
return 1
fi
echo "Found environment ID: $ENV_ID for environment name: $ENV_NAME"Nel codice qui sopra, viene creata una condizione in modo che lo script esca con un messaggio di errore se il nome dell’ambiente fornito non corrisponde.
Ora che abbiamo l’ID dell’ambiente, possiamo verificare il numero attuale di backup manuali per l’ambiente selezionato. Il limite di Kinsta di cinque backup manuali per ambiente rende questo passaggio fondamentale per evitare errori.
Iniziamo con il recuperare l’elenco dei backup utilizzando l’endpoint /backups dell’API.
API_URL="$BASE_URL/sites/environments/$ENV_ID/backups"
BACKUPS_RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
CLEAN_RESPONSE=$(echo "$BACKUPS_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')
MANUAL_BACKUPS=$(echo "$CLEAN_RESPONSE" | jq '[.environment.backups[] | select(.type == "manual")]')
BACKUP_COUNT=$(echo "$MANUAL_BACKUPS" | jq 'length')Lo script precedente filtra quindi i backup manuali e li conta. Se il conteggio raggiunge il limite, dobbiamo gestire i backup esistenti:
if [ "$BACKUP_COUNT" -ge 5 ]; then
echo "Manual backup limit reached (5 backups)."
# Find the oldest backup
OLDEST_BACKUP=$(echo "$MANUAL_BACKUPS" | jq -r 'sort_by(.created_at) | .[0]')
OLDEST_BACKUP_NAME=$(echo "$OLDEST_BACKUP" | jq -r '.note')
OLDEST_BACKUP_ID=$(echo "$OLDEST_BACKUP" | jq -r '.id')
echo "The oldest manual backup is "$OLDEST_BACKUP_NAME"."
read -p "Do you want to delete this backup to create a new one? (yes/no): " CONFIRM
if [ "$CONFIRM" != "yes" ]; then
echo "Aborting backup creation."
return 1
fi
# Delete the oldest backup
DELETE_URL="$BASE_URL/sites/environments/backups/$OLDEST_BACKUP_ID"
DELETE_RESPONSE=$(curl -s -X DELETE "$DELETE_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
echo "Delete Response:"
echo "$DELETE_RESPONSE" | jq -r '[
"Operation ID: (.operation_id)",
"Message: (.message)",
"Status: (.status)"
] | join("n")'
fiLa condizione precedente identifica il backup più vecchio ordinando l’elenco in base al timestamp created_at. Ci chiede quindi di confermare se desideriamo eliminarlo.
Se accettiamo, lo script elimina il backup più vecchio utilizzando il suo ID, liberando spazio per quello nuovo. In questo modo si garantisce che i backup possano essere sempre creati senza dover gestire manualmente i limiti.
Ora che c’è spazio, procediamo con il codice per attivare il backup dell’ambiente. Possiamo tranquillamente saltare questo codice, ma per un’esperienza migliore, ci chiederà di specificare un tag personalizzato, che verrà impostato su “default-backup” se non viene fornito.
read -p "Enter a backup tag (or press Enter to use "$DEFAULT_TAG"): " BACKUP_TAG
if [ -z "$BACKUP_TAG" ]; then
BACKUP_TAG="$DEFAULT_TAG"
fi
echo "Using backup tag: $BACKUP_TAG"Infine, lo script sottostante è il punto in cui avviene l’azione di backup. Invia una richiesta POST all’endpoint /manual-backups con l’ID dell’ambiente e il tag di backup selezionati. Se la richiesta va a buon fine, l’API restituisce una risposta che conferma la creazione del backup.
API_URL="$BASE_URL/sites/environments/$ENV_ID/manual-backups"
RESPONSE=$(curl -s -X POST "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json"
-d "{"tag": "$BACKUP_TAG"}")
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API while triggering the manual backup."
return 1
fi
echo "Backup Trigger Response:"
echo "$RESPONSE" | jq -r '[
"Operation ID: (.operation_id)",
"Message: (.message)",
"Status: (.status)"
] | join("n")'Ecco fatto! La risposta ottenuta dalla richiesta precedente è formattata in modo da mostrare l’ID dell’operazione, il messaggio e lo stato per maggiore chiarezza. Se chiamiamo la funzione ed eseguiamo lo script, vedremo un output simile a questo:
Available Environments for "example-site":
staging: 12345
live: 67890
Enter the environment name to back up (e.g., staging, live): live
Found environment ID: 67890 for environment name: live
Manual backup limit reached (5 backups).
The oldest manual backup is "staging-backup-2023-12-31".
Do you want to delete this backup to create a new one? (yes/no): yes
Oldest backup deleted.
Enter a backup tag (or press Enter to use "default-backup"): weekly-live-backup
Using backup tag: weekly-live-backup
Triggering manual backup for environment ID: 67890 with tag: weekly-live-backup...
Backup Trigger Response:
Operation ID: backups:add-manual-abc123
Message: Adding a manual backup to environment in progress.
Status: 202Creare comandi per lo script
I comandi semplificano l’utilizzo dello script. Invece di modificare lo script o di commentare manualmente il codice, gli utenti possono eseguirlo con un comando specifico come:
./script.sh list-sites
./script.sh backup Alla fine dello script (al di fuori di tutte le funzioni), includiamo un blocco condizionale che controlla gli argomenti passati allo script:
if [ "$1" == "list-sites" ]; then
list_sites
elif [ "$1" == "backup" ]; then
SITE_NAME="$2"
if [ -z "$SITE_NAME" ]; then
echo "Usage: $0 trigger-backup "
exit 1
fi
trigger_manual_backup "$SITE_NAME"
else
echo "Usage: $0 {list-sites|trigger-backup }"
exit 1
fiLa variabile $1 rappresenta il primo argomento passato allo script (ad esempio, in ./script.sh list-sites, $1 è list-sites). Lo script utilizza controlli condizionali per abbinare $1 a comandi specifici come list-sites o backup. Se il comando è backup, si aspetta anche un secondo argomento ($2), che è il nome del sito. Se non viene fornito alcun comando valido, lo script si limita a visualizzare le istruzioni d’uso.
Ora possiamo attivare un backup manuale per un sito specifico eseguendo il comando:
./script.sh backupCaso d’uso avanzato 2: Aggiornamento dei plugin su più siti
Gerstire i plugin di WordPress su più siti può essere un compito noioso, soprattutto quando sono disponibili aggiornamenti. Kinsta fa un ottimo lavoro per gestire questo aspetto attraverso la dashboard MyKinsta, grazie alla funzione di azione in blocco che abbiamo introdotto lo scorso anno.
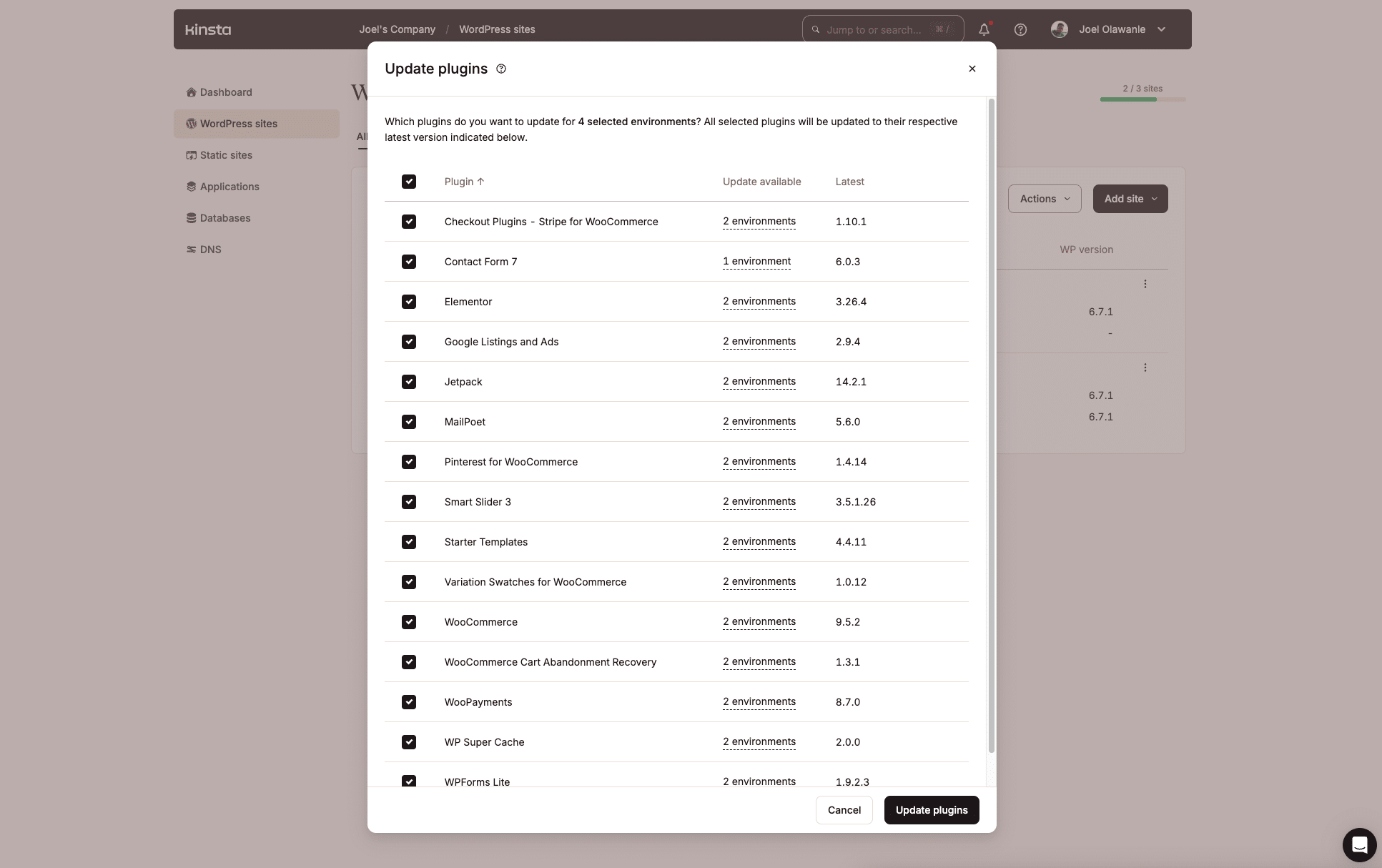
Ma se non vi piace lavorare con le interfacce utente, l’API di Kinsta offre un’altra opportunità per creare uno shell script per automatizzare il processo di identificazione dei plugin obsoleti e il loro aggiornamento su più siti o ambienti specifici.
Suddivisione del workflow
1. Identificare i siti con plugin obsoleti. Lo script esegue l’iterazione di tutti i siti e gli ambienti alla ricerca del plugin specificato con un aggiornamento disponibile. Il seguente endpoint viene utilizzato per recuperare l’elenco dei plugin per uno specifico ambiente del sito:
GET /sites/environments/{env_id}/pluginsDalla risposta, filtriamo i plugin in cui "update": "available".
2. Richiedere all’utente le opzioni di aggiornamento. Mostra i siti e gli ambienti con il plugin obsoleto, consentendo all’utente di selezionare istanze specifiche o di aggiornarle tutte.
3. Attivare gli aggiornamenti del plugin. Per aggiornare il plugin in un ambiente specifico, lo script utilizza questo endpoint:
PUT /sites/environments/{env_id}/pluginsIl nome del plugin e la sua versione aggiornata vengono passati nel corpo della richiesta.
Lo script
Poiché lo script è lungo, la funzione completa è ospitata su GitHub per facilitare l’accesso. Qui spiegheremo la logica di base utilizzata per identificare i plugin obsoleti su più siti e ambienti.
Lo script inizia accettando il nome del plugin dal comando. Questo nome indica il plugin che si desidera aggiornare.
PLUGIN_NAME=$1
if [ -z "$PLUGIN_NAME" ]; then
echo "Error: Plugin name is required."
echo "Usage: $0 update-plugin "
return 1
fiLo script utilizza quindi la funzione riutilizzabile get_sites_list (spiegata in precedenza) per recuperare tutti i siti dell’azienda:
echo "Fetching all sites in the company..."
# Fetch all sites in the company
SITES_RESPONSE=$(get_sites_list)
if [ $? -ne 0 ]; then
echo "Error: Failed to fetch sites."
return 1
fi
# Clean the response
CLEAN_SITES_RESPONSE=$(echo "$SITES_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Poi arriva il cuore dello script: il looping dell’elenco dei siti per verificare la presenza di plugin obsoleti. Il file CLEAN_SITES_RESPONSE, che è un oggetto JSON contenente tutti i siti, viene passato a un ciclo while per eseguire le operazioni per ogni sito, uno per uno.
Inizia estraendo alcuni dati importanti come l’ID del sito, il nome e il nome visualizzato nelle variabili:
while IFS= read -r SITE; do
SITE_ID=$(echo "$SITE" | jq -r '.id')
SITE_NAME=$(echo "$SITE" | jq -r '.name')
SITE_DISPLAY_NAME=$(echo "$SITE" | jq -r '.display_name')
echo "Checking environments for site "$SITE_DISPLAY_NAME"..."Il nome del sito viene poi utilizzato insieme alla funzione get_site_details_by_name definita in precedenza per ottenere informazioni dettagliate sul sito, compresi tutti i suoi ambienti.
SITE_DETAILS=$(get_site_details_by_name "$SITE_NAME")
CLEAN_SITE_DETAILS=$(echo "$SITE_DETAILS" | tr -d 'r' | sed 's/^[^{]*//')
ENVIRONMENTS=$(echo "$CLEAN_SITE_DETAILS" | jq -r '.site.environments[] | "(.id):(.name):(.display_name)"')Gli ambienti vengono poi passati in rassegna per estrarre i dettagli di ogni ambiente, come l’ID, il nome e il nome visualizzato:
while IFS= read -r ENV; do
ENV_ID=$(echo "$ENV" | cut -d: -f1)
ENV_NAME=$(echo "$ENV" | cut -d: -f2)
ENV_DISPLAY_NAME=$(echo "$ENV" | cut -d: -f3)
echo "Checking plugins for environment "$ENV_DISPLAY_NAME"..."Per ogni ambiente, lo script recupera l’elenco dei plugin utilizzando l’API di Kinsta.
PLUGINS_RESPONSE=$(curl -s -X GET "$BASE_URL/sites/environments/$ENV_ID/plugins"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
CLEAN_PLUGINS_RESPONSE=$(echo "$PLUGINS_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Successivamente, lo script controlla se il plugin specificato esiste nell’ambiente e se ha un aggiornamento disponibile:
OUTDATED_PLUGIN=$(echo "$CLEAN_PLUGINS_RESPONSE" | jq -r --arg PLUGIN_NAME "$PLUGIN_NAME" '.environment.container_info.wp_plugins.data[] | select(.name == $PLUGIN_NAME and .update == "available")')Se viene trovato un plugin non aggiornato, lo script ne registra i dettagli e li aggiunge all’array SITES_WITH_OUTDATED_PLUGIN:
if [ ! -z "$OUTDATED_PLUGIN" ]; then
CURRENT_VERSION=$(echo "$OUTDATED_PLUGIN" | jq -r '.version')
UPDATE_VERSION=$(echo "$OUTDATED_PLUGIN" | jq -r '.update_version')
echo "Outdated plugin "$PLUGIN_NAME" found in "$SITE_DISPLAY_NAME" (Environment: $ENV_DISPLAY_NAME)"
echo " Current Version: $CURRENT_VERSION"
echo " Update Version: $UPDATE_VERSION"
SITES_WITH_OUTDATED_PLUGIN+=("$SITE_DISPLAY_NAME:$ENV_DISPLAY_NAME:$ENV_ID:$UPDATE_VERSION")
fiEcco come appaiono i dettagli registrati dei plugin obsoleti:
Outdated plugin "example-plugin" found in "Site ABC" (Environment: Production)
Current Version: 1.0.0
Update Version: 1.2.0
Outdated plugin "example-plugin" found in "Site XYZ" (Environment: Staging)
Current Version: 1.3.0
Update Version: 1.4.0Da qui, eseguiamo gli aggiornamenti dei plugin per ogni plugin utilizzando il relativo endpoint. Lo script completo si trova in questo repository GitHub.
Riepilogo
Questo articolo ci ha guidato nella creazione di uno shell script per interagire con l’API di Kinsta.
Prendetevi un po’ di tempo per esplorare ulteriormente l’API di Kinsta: scoprirete altre funzionalità che potrete automatizzare per gestire attività adatte alle vostre esigenze specifiche. Potreste prendere in considerazione l’integrazione dell’API con altre API per migliorare il vostro processo decisionale e l’efficienza.
Infine, controllate regolarmente la dashboard di MyKinsta per scoprire le nuove funzionalità pensate per rendere la gestione del sito web ancora più semplice grazie alla sua interfaccia intuitiva.


