
アプリケーション開発が進歩を遂げる中、データベースは多くのアプリケーションの中核をなし、オンラインビジネスの重要なデータを保存・管理する存在となりました。このデータが増大し複雑化するにつれ、データベースの効率性を確保することは、アプリケーションの要件を満たすために必要不可欠に。
したがって、重要になるのがデータベースのメンテナンスです。具合的にはクリーニング、バックアップ、そしてパフォーマンスを高めるためのインデックスの最適化などのタスクが挙げられます。
この記事では、データベースのメンテナンスに関する重要なヒントをご紹介し、具体的な設定手順をご説明します。Node.jsアプリケーションでAPIトリガーと統合されたPostgreSQL使用し、データのバックアップ、インデックスの再構築、アーカイブ、データのクリーンアップといった様々なメンテナンスタスクを実装していきましょう。
トリガーとは
データベースのメンテナンスタスクを設定する前に、様々なトリガーについて理解する必要があります。各トリガーは、メンテナンスタスクを簡素化してくれる明確な役割を持っています。一般的に使用されるのは、以下の3種類です。
- 手動、APIベースのトリガー:API呼び出しを使用して単発のタスクを実行。データベースのバックアップの復元や、パフォーマンスが突然低下した際のインデックスの再構築などに役立つ。
- スケジュール型のトリガー(cronジョブのようなもの):トラフィックが少ない時間帯に合わせて、自動メンテナンスタスクを設定。アーカイブやクリーンアップのようなリソース集約的な処理の実行に理想的。node-scheduleのようなパッケージを使用して、Node.jsで設定を行い、必要次に処理を自動的にトリガーする。
- データベースの通知:データベースの変更に応じて、メンテナンスタスクを実行。例えば、ユーザーがプラットフォームにコメントを投稿すると、保存されたデータは即座に不規則な文字、不適切な表現、絵文字のチェックなどをトリガー。Node.jsでは、pg-listenなどパッケージを使用してこの機能を実装する。
前提条件
これからご紹介する操作では、ローカルコンピュータに以下のツールが必要になります。
- Git─アプリのソースコードのバージョン管理を行う
- Node.js─バックエンドアプリを構築する
- psql─ターミナルを使用してリモートのPostgreSQLデータベースとやり取りする
- PGAdmin(任意)─グラフィカルユーザーインターフェース(GUI)を使用してリモートのPostgreSQLデータベースとやり取りする
Node.jsアプリの構築とホスティング
Node.jsプロジェクトをセットアップしてGitHubにコミットしたら、Kinstaへの自動デプロイパイプラインを作成することができます。また、KinstaにPostgreSQLデータベースをプロビジョニングし、自動メンテナンスタスクをテストすることも欠かせません。
まずは次のコマンドを使用し、ローカルシステムに新規ディレクトリを作成します。
mkdir node-db-maintenance続いて、作成したフォルダに移動し、以下を実行して新規プロジェクトを作成します。
cd node-db-maintenance
yarn init -y # or npm init -yこれで、Node.jsプロジェクトがデフォルト設定で初期化されます。次のコマンドを実行し、必要な依存関係をインストールします。
yarn add express pg nodemon dotenv各依存関係の概要は以下のとおりです。
express:ExpressベースのREST APIをセットアップするpg:Node.jsアプリを通じてPostgreSQLデータベースとやりとりするnodemon:アプリケーション開発に際しビルドをスムーズに更新する(変更を加えるたびに停止したり起動したりする必要がなくなる)dotenv:.envファイルからprocess.envオブジェクトに環境変数を読み込む
次に、package.jsonファイルに以下のスクリプトを貼り付け、開発用サーバーをすぐに起動できるようにし、また本番環境でもサーバーを実行できるようにします。
{
// ...
"scripts": {
"start-dev": "nodemon index.js",
"start": "NODE_ENV=production node index.js"
},
// …
}続いて、アプリのソースコードを含むindex.jsファイルを作成します。このファイルに以下を貼り付けましょう。
const express = require("express")
const dotenv = require('dotenv');
if (process.env.NODE_ENV !== 'production') dotenv.config();
const app = express()
const port = process.env.PORT || 3000
app.get("/health", (req, res) => res.json({status: "UP"}))
app.listen(port, () => {
console.log(`Server running at port: ${port}`);
});このコードがExpressサーバーを初期化し、dotenvパッケージを使って環境変数を設定します。また、JSONオブジェクト{status: "UP"}を返す/healthルートも定義されます。最後に、app.listen()関数でアプリを起動し、指定されたポートをリッスンします(環境変数でポートが指定されていない場合、デフォルトは3000)。
これで基本的なアプリケーションの準備が整います。あとは任意のGitサービス(BitBucket、GitHub、またはGitLab)を使用して新規Gitリポジトリを初期化し、コードをプッシュします。Kinstaでは、いずれのGitサービスもご利用いただけますが、今回はGitHubを利用した例を見ていきます。
リポジトリの準備ができたら、以下の手順に従ってアプリケーションをKinstaにデプロイします。
- ログインまたはアカウントを作成し、MyKinstaにアクセスする
- GitサービスでKinstaを認証する
- 左サイドバーで「アプリケーション」を選択し、「アプリケーションを追加」をクリック
- デプロイしたいリポジトリとブランチを選択する
- 28箇所あるデータセンターから任意の場所を選択する(アプリケーションのビルド設定は、Nixpacksを通じて自動で検出されます)。
- RAMやディスク容量などのアプリケーションリソースを選択する
- 「アプリケーションの作成」をクリック
デプロイが完了したら、デプロイされたアプリケーションのリンクをコピーして、/healthに移動します。すると、ブラウザに以下のJSONが表示されます。
{status: "UP"}以上でアプリケーションのセットアップが完了です。
KinstaでPostgreSQLインスタンスをセットアップする方法
Kinstaのインターフェースでは、データベースインスタンスのプロビジョニングが簡単です。Kinstaをご利用でない場合は、まずMyKinstaアカウントを作成してください。その後、以下の手順で進めていきます。
- MyKinstaにログインする
- 左サイドバーから「データベース」を選択し、「データベースを追加」をクリック
- データベースタイプは「PostgreSQL」を選択し、任意のバージョンを選択(データベース名の入力、および必要に応じてユーザー名とパスワードの変更も)
- 28箇所あるデータセンターから任意の場所を選択
- データベースのサイズを選択する
- 「データベースの作成」をクリック
データベースが作成できたら「情報」画面でデータベースの外部ホスト名、外部ポート、ユーザー名、パスワードを確認します。
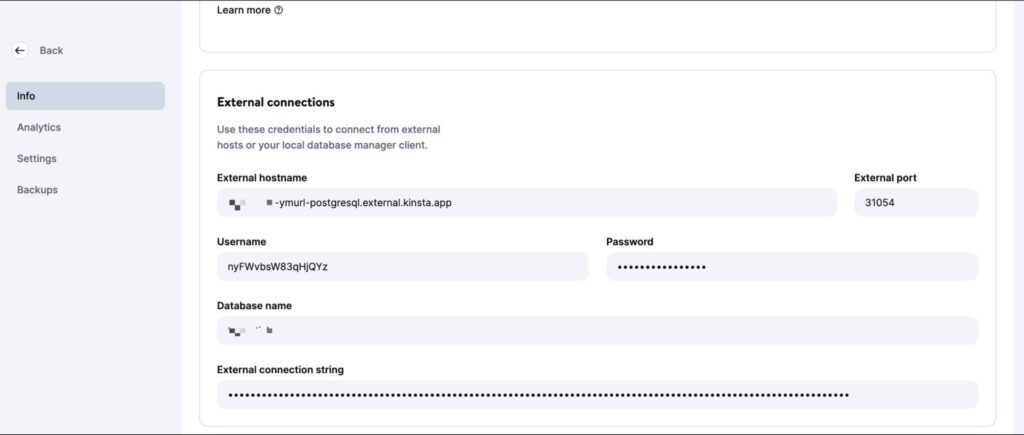
これらの値をpsql CLI(またはPGAdmin GUI)に入力してデータベースを管理します。ローカルでコードをテストするには、プロジェクトのルートディレクトリに.envファイルを作成し、以下の認証情報を保存します。
DB_USER_NAME=データベースのユーザー名
DB_HOST=データベースのホスト
DB_DATABASE_NAME=データベース名
DB_PORT=データベースのポート
PGPASS=データベースのパスワードKinstaにデプロイする際には、上記の値を環境変数としてアプリケーションのデプロイメントに追加する必要があります。
データベースの操作を行うため、こちらのSQLスクリプトをダウンロードして実行し、テーブル(ユーザー、投稿、コメント)を作成して、サンプルデータを挿入します。以下のコマンドでプレースホルダを特定の値に置き換えて、作成したPostgreSQLデータベースにデータを追加します。
psql -h <host> -p <port> -U <username> -d <db_name> -a -f <sql file e.g. test-data.sql>上記のコマンドには、正確なファイル名とパスを入力してください。実行すると、認証のためにデータベースのパスワードの入力が促されます。
以上で、データベースのメンテナンスタスクを設定する準備が整いました。各操作が完了したら、ご自由にコードをGitリポジトリにプッシュし、Kinstaのプラットフォームでの動作を確認してみてください。
メンテナンスタスクの設定方法
ここからは、PostgreSQLデータベースの一般的な自動メンテナンスタスクの設定方法をご紹介します。
1. バックアップの作成
データベースの定期的なバックアップは大事な操作です。データベースの内容全体のコピーを作成し、安全な場所に保存することを意味します。バックアップがあれば、偶発的な紛失やデータの完全性に影響を与えるエラーが発生した場合であっても、復元することができて安心です。
Kinstaのようなサーバーサービスでは、自動バックアップ機能を提供していますが、必要な時に自分でバックアップを作成する方法は知っておいて損はありません。
PostgreSQLには、データベースをバックアップするためにpg_dumpが搭載されていますが、コマンドラインから直接実行する必要があり、そのためのnpmパッケージは用意されていません。pg_dumpコマンドをNodeアプリのローカル環境で実行するには、@getvim/executeパッケージを使用します。
以下のコマンドを実行して、パッケージをインストールします。
yarn add @getvim/execute次に、index.jsファイルの先頭に次のコードを貼り付け、パッケージをインポートします。
const {execute} = require('@getvim/execute');バックアップは、Nodeアプリのローカルファイルシステム上にファイルとして生成されるため、プロジェクトのルートディレクトリに「backup」という名前で専用のディレクトリを作成するのが得策です。
これで、必要な時に以下のルートを使ってデータベースのバックアップを作成、ダウンロードすることができます。
app.get('/backup', async (req, res) => {
// バックアップファイル名を作成
const fileName = "database-backup-" + new Date().valueOf() + ".tar";
// pg_dumpコマンドを実行してバックアップファイルを生成
execute("PGPASSWORD=" + process.env.PGPASS + " pg_dump -U " + process.env.DB_USER_NAME
+ " -d " + process.env.DB_DATABASE_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -f backup/" + fileName + " -F t"
).then(async () => {
console.log("Backup created");
res.redirect("/backup/" + fileName)
}).catch(err => {
console.log(err);
res.json({message: "Something went wrong"})
})
})また、Expressアプリの初期化後、index.jsファイルの先頭に以下の行を追加してください。
app.use('/backup', express.static('backup'))これにより、ミドルウェア関数express.staticを使用してbackupフォルダが静的に提供され、生成されたバックアップファイルをNodeアプリからダウンロードできるようになります。
2. バックアップの復元
Postgresでは、pg_restoreコマンドラインツールを使用して、バックアップを復元することができます。しかし、先ほどのpg_dumpコマンドのように、executeパッケージを使用します。ルートコードは以下のとおりです。
app.get('/restore', async (req, res) => {
const dir = 'backup'
// バックアップファイルを作成日順に並べ替える
const files = fs.readdirSync(dir)
.filter((file) => fs.lstatSync(path.join(dir, file)).isFile())
.map((file) => ({ file, mtime: fs.lstatSync(path.join(dir, file)).mtime }))
.sort((a, b) => b.mtime.getTime() - a.mtime.getTime());
if (!files.length){
res.json({message: "No backups available to restore from"})
}
const fileName = files[0].file
// 選択したバックアップファイルからデータベースを復元
execute("PGPASSWORD=" + process.env.PGPASS + " pg_restore -cC "
+ "-U " + process.env.DB_USER_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -d postgres backup/" + fileName
)
.then(async ()=> {
console.log("Restored");
res.json({message: "Backup restored"})
}).catch(err=> {
console.log(err);
res.json({message: "Something went wrong"})
})
})上記コードは、はじめにローカルのbackupディレクトリに保存されているファイルを探し、最新のバックアップファイルを見つけるために作成日順に並べ替えます。その後、executeパッケージを使って、選択したバックアップファイルを復元します。
以下をindex.jsファイルに追加します。これにより、ローカルファイルシステムにアクセスするために必要なモジュールがインポートされ、関数が正しく実行されます。
const fs = require('fs')
const path = require('path')3. インデックスの再構築
Postgresのデータベーステーブルのインデックスが破損し、パフォーマンスが低下することがあります。これはソフトウェアのバグやエラーに起因しており、空のページ(またはほぼ空のページ)が多すぎてインデックスが肥大化してしまう可能性があります。
このような状況では、Postgresのインスタンスからインデックスを再構築するのが効果的です。
Postgresには、インデックス再構築に便利なREINDEXコマンドがあり、node-postgresパッケージを使って実行することができます(後で他の操作を実行することも可)。
yarn add pgデータベース接続を正しく初期化するために、index.jsファイルの一番上のimports以下に次のコードを貼り付けます。
const {Client} = require('pg')
const client = new Client({
user: process.env.DB_USER_NAME,
host: process.env.DB_HOST,
database: process.env.DB_DATABASE_NAME,
password: process.env.PGPASS,
port: process.env.DB_PORT
})
client.connect(err => {
if (err) throw err;
console.log("Connected!")
})このタスクの実装は非常にシンプルです。
app.get("/reindex", async (req, res) => {
// 必要時にREINDEXコマンドを実行
await client.query("REINDEX TABLE Users;")
res.json({message: "Reindexed table successfully"})
})上記コマンドは、Usersテーブル全体のインデックスを再作成するものです。特定のインデックスやデータベース全体のインデックスを再構築する場合は、必要に応じて編集してください。
4. データのアーカイブとパージ
データベースは徐々に大きくなるもので、過去のデータは不要になることがあります。そのため、古いデータをデータレイクに移す自動タスクを設定しておくのが賢い判断です。
データレイクでのデータの保存と転送には広くParquetファイルが使用されています。ParquetJSライブラリを使えば、PostgresのデータからParquetファイルを作成し、AWS Athenaのようなサービスで読み込むことができます。
以下のコマンドを実行し、ParquetJSライブラリをインストールします。
yarn add parquetjsアーカイブを作成する際には、テーブルから大量のレコードをクエリする必要があります。これほどの大量のデータをアプリのメモリに保存してしまうと、リソースを消費し費用がかさむだけでなくエラーも発生しやすくなります。
したがって、カーソルを使ってデータベースからデータの塊を読み込み、処理するのが得策です。以下のコマンドを実行して、node-postgresパッケージのcursorsモジュールをインストールします。
yarn add pg-cursor次に、両方のライブラリをindex.jsファイルにインポートします。
const Cursor = require('pg-cursor')
const parquet = require('parquetjs')以下のコードで、データベースからParquetファイルを作成します。
app.get('/archive', async (req, res) => {
// カーソルですべてのコメントをクエリし、一度に10件のみ読み込む
// 最低1ヶ月以上前のレコードをアーカイブする、アクティブでないユーザーのレコードのみをアーカイブするなど、要件に合わせてここでクエリを変更可能
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
// Parquetファイルのスキーマを定義
let schema = new parquet.ParquetSchema({
comment_id: { type: 'INT64' },
post_id: { type: 'INT64' },
user_id: { type: 'INT64' },
comment_text: { type: 'UTF8' },
timestamp: { type: 'TIMESTAMP_MILLIS' }
});
// Parquetファイルライターを開く
let writer = await parquet.ParquetWriter.openFile(schema, 'archive/archive.parquet');
let rows = await cursor.read(10)
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// テーブルから各行をParquetファイルに書き込む
await writer.appendRow(rows[i])
}
rows = await cursor.read(10)
}
await writer.close()
// Parquetファイルが生成された時点でテーブルからレコードを削除し、スペースを空けることを検討
// ユーザーをファイルパスへリダイレクトし、ファイルをダウンロードできるようにする
res.redirect("/archive/archive.parquet")
})Expressアプリの初期化後、index.jsファイルの先頭に以下を貼り付けます。
app.use('/archive', express.static('archive'))これでarchiveフォルダが静的に提供されるようになり、サーバーから生成されたParquetファイルをダウンロードできるようになります。
また、アーカイブファイルを保存するため、プロジェクトディレクトリにarchiveディレクトリを作成することをお忘れなく。
このコードを活用して、パーケットファイルをAWS S3 バケットに自動でアップロードし、cronジョブで自動的にこのタスクをトリガーすることも可能です。
5. データのクリーンアップ
古くなったり無関係になったりしたデータをクリーンアップすることも、一般的なメンテナンスタスクとして重要です。以下、メンテナンスの一環としてデータのクリーンアップが必要になる2つのケースをご紹介します。
なお、このタスクはアプリケーションのデータモデルに応じて独自に設定しましょう。以下はあくまでも一例として参考にしてください。
日付(最終更新日または最終アクセス日)に基づいたレコードの削除
日付に基づいたレコードのクリーンアップは、比較的簡単です。設定した日付より古いレコードを削除するクエリを書けばOKです。
例えば、2023年10月9日以前のコメントを削除するには、以下のようになります。
app.get("/clean-by-age", async (req, res) => {
// 2023年10月9日以前に投稿されたすべてのコメントをフィルタリングして削除
const result = await client.query("DELETE FROM COMMENTS WHERE timestamp < '09-10-2023 00:00:00'")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})/clean-by-ageルートにGETリクエストを送信して、テストすることができます。
独自の条件に基づいたレコードの削除
システム内の他のアクティブなレコードにリンクされていないレコードを削除する(「孤児」の状態にする)など、その他の条件に基づいてクリーンアップを設定することも可能です。
例えば、おそらく二度と必要ないであろう、削除された投稿へのコメントを見つけて削除できます。
app.get('/conditional', async (req, res) => {
// アクティブな投稿にリンクされていないすべてのコメントをフィルタリングして削除
const result = await client.query("DELETE FROM COMMENTS WHERE post_id NOT IN (SELECT post_id from Posts);")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})このような形で、このコードを基本に、独自の条件に合わせてコードを応用してみてください。
6. データ操作
不適切な表現を検閲したり、テキストの組み合わせを絵文字に変換したりするなど、データの操作や変換を実行することもメンテナンスタスクの1つです。
このタスクは他の多くの操作とは異なり、週や月の決まった日時にすべての行に対して実行するのではなく、データベースが更新されたときに実行するのが理想的です。
今回は2つのタスクをご紹介しますが、その他のタスクにも応用可能です。
テキストを絵文字に変換する
情報の一貫性を保ち、より良いユーザー体験を実現するため、「:)」や「xD」(海外で一般的に使用される顔文字)などの文字の組み合わせを絵文字に変換することができます。
app.get("/emoji", async (req, res) => {
// 変換が必要な絵文字のリストを定義
const emojiMap = {
'xD': '😁',
':)': '😊',
':-)': '😄',
':jack_o_lantern:': '🎃',
':ghost:': '👻',
':santa:': '🎅',
':christmas_tree:': '🎄',
':gift:': '🎁',
':bell:': '🔔',
':no_bell:': '🔕',
':tanabata_tree:': '🎋',
':tada:': '🎉',
':confetti_ball:': '🎊',
':balloon:': '🎈'
}
// マップからすべての絵文字に対する条件チェックを追加するSQLクエリを構築
let queryString = "SELECT * FROM COMMENTS WHERE"
queryString += " COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[0] + "%' "
if (Object.keys(emojiMap).length > 1) {
for (let i = 1; i < Object.keys(emojiMap).length; i++) {
queryString += " OR COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[i] + "%' "
}
}
queryString += ";"
const result = await client.query(queryString)
if (result.rowCount === 0) {
res.json({message: "No rows to clean up!"})
} else {
for (let i = 0; i < result.rows.length; i++) {
const currentRow = result.rows[i]
let emoji
// 絵文字を含む行をどの絵文字が使われているのかと共に特定
for (let j = 0; j < Object.keys(emojiMap).length; j++) {
if (currentRow.comment_text.includes(Object.keys(emojiMap)[j])) {
emoji = Object.keys(emojiMap)[j]
break
}
}
// テキスト内の絵文字を置換し、次の行に進む前に行を更新
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + currentRow.comment_text.replace(emoji, emojiMap[emoji]) + "' WHERE COMMENT_ID = " + currentRow.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "All emojis cleaned up successfully!"})
}
})このコードが、絵文字とそのテキスト表現の一覧を定義した後、データベースに照会してそれらの組み合わせを探し、絵文字に置き換えます。
不適切な表現の検閲
ユーザーによるコンテンツの投稿を許可するアプリでよく使われるタスクは、不適切な表現の検閲です。上の絵文字の変換と同様のアプローチで、不適切な表現を特定し、アスタリスク(*)に置き換えることができます。bad-wordsパッケージを使えば、これを容易に実行できます。
まずは、以下のコマンドを実行してパッケージをインストールします。
yarn add bad-wordsindex.jsファイルでパッケージを初期化します。
const Filter = require('bad-words');
filter = new Filter();続いて、以下のコードを使って、コメントテーブルの不適切な表現を検閲します。
app.get('/obscene', async (req, res) => {
// カーソルを使ってすべてのコメントを照会し、一度に10件だけを読み込む
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
let rows = await cursor.read(10)
const affectedRows = []
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// 各コメントに不適切な表現がないかをチェック
if (filter.isProfane(rows[i].comment_text)) {
affectedRows.push(rows[i])
}
}
rows = await cursor.read(10)
}
cursor.close()
// 不適切な表現を含むコメントは、検閲後のバージョンに変更
for (let i = 0; i < affectedRows.length; i++) {
const row = affectedRows[i]
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + filter.clean(row.comment_text) + "' WHERE COMMENT_ID = " + row.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "Cleanup complete"})
})このセクションでご紹介したコードのすべてはこちらを参照してください。
PostgreSQLのVACUUM
上記でご紹介したような独自のメンテナンスタスクを設定する以外にも、PostgreSQL組み込みのメンテナンス機能である、VACUUMを使用することも可能です。
VACUUMは、データベースの性能を最適化し、ディスク領域を確保するのに役立ちます。auto-vacuumデーモンによって、スケジュール通りに実行されますが、必要に応じて手動でトリガーすることも可能です。バキューム処理を定期的に行うことには、以下のようなメリットがあります。
- ディスク領域の解放─VACCUMの主な役割の1つは、データベース内のブロックされたディスク領域を解放すること。データベースではデータが常に挿入、更新、削除されるため、不要なデータで乱雑になり、ディスク上の領域を必要以上に占有することがあります。バキューム処理によって、これを識別して削除し、ディスク領域を確保できます。この処理なしでは、ディスク領域は徐々に枯渇し、性能低下やシステムクラッシュにつながる恐れもあります。
- 実行計画の更新─クエリ実行計画で使用する統計情報と指標を最新の状態に保つのにも有用です。効率的な実行計画を生成するために、正確なデータ分布と統計情報が必要になります。バキューム処理を行うことで、これらの指標が最新のものであることが保証され、データの取得方法や問い合わせの最適化に関してより適切な判断を下せるようになります。
- 可視性マップの更新─これもバキューム処理の重要な役割で、テーブル内のどのデータブロックが全てのトランザクションから完全に可視であるかを識別し、必要なデータブロックのみをクリーニングの対象にすることを可能にします。費用と手間のかかる不要なI/O操作を最小限に抑えることで、バキューム処理の効率を高めます。
- トランザクションID周回問題の防止─PostgreSQLは32ビットのトランザクションIDカウンタを採用しており、これが最大値に達すると周回が起こる可能性があります。VACCUMによって、古いトランザクションを凍結したものとしてマークし、IDカウンターが周回してデータ破損を引き起こすのを防ぐことができます。これを無視すると、致命的なデータベース障害につながりかねません。
先にも触れましたが、PostgreSQLは、自動VACCUMと手動VACCUMの2種類があります。
自動VACCUMは、定義済みの設定とデータベースの活動に基づいて自動的にプロセスが管理されるため、基本的にはこちらが推奨されます。手動VACCUMでは、より高度な管理を行うため、データベースの保守管理に精通している上級者向けです。
どちらを選択するかは、データベースのサイズ、負荷、利用可能なリソースなどによって決まります。小・中規模のデータベースは、自動VACCUMを使用するので問題ありませんが、大規模あるいは複雑なデータベースは、手動の操作が必要になるかもしれません。
まとめ
データベースのメンテナンスは決して侮れません。定期的にデータを最適化し、クリーニングし、整理整頓を行うことで、PostgreSQLデータベースのパフォーマンスを最大化することができます。また、アプリケーションの規模が大きくなっても、破損することなく、スムーズに動作します。
今回は、Node.jsとExpressを扱う際、PostgreSQLデータベースの念入りなメンテナンスを行うことの重要性について掘り下げました。
他にも重要なデータベースのメンテナンスタスクをご存知ですか?あるいは、今回取り上げたメンテナンスタスクのより良い実装方法をご存知ですか?以下のコメント欄でぜひお聞かせください。


