
Zowel MySQL als MariaDB maken naadloos gebruik van de efficiëntie van balanced tree (B-Tree) indexering om gegevensbewerkingen te optimaliseren. Dit gedeelde indexeringsmechanisme zorgt voor het snel ophalen van gegevens, verbetert de queryprestaties en minimaliseert de schijfinvoer en -uitvoer (I/O), wat bijdraagt aan een responsievere en efficiëntere database-ervaring.
Dit artikel gaat dieper in op indexeren, begeleidt je bij het maken van indexen en geeft tips om ze effectiever te gebruiken in MySQL en MariaDB databases.
Wat is een index?
Wanneer je een MySQL database om specifieke informatie vraagt, doorzoekt de query elke rij in een databasetabel totdat de juiste rij is gevonden. Dit kan lang duren, vooral als de database erg uitgebreid is.
Databasebeheerders gebruiken indexering om het ophalen van gegevens te versnellen en query’s efficiënter te maken. Indexering bouwt een datastructuur die de hoeveelheid gegevens die moet worden doorzocht minimaliseert door ze systematisch te organiseren, wat leidt tot snellere en effectievere query-uitvoering.
Stel dat je een klant wilt vinden met de voornaam Ava in de volgende tabel Customer:
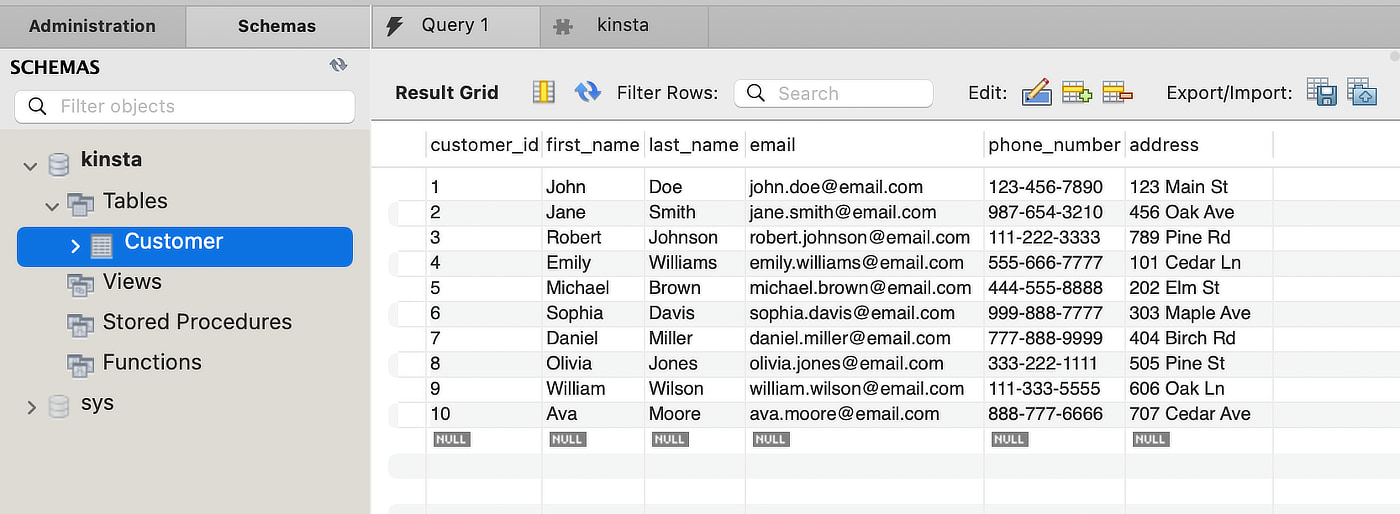
Het toevoegen van een B-Tree index aan de first_name kolom creëert een structuur die het zoeken naar de gewenste informatie efficiënter maakt. De structuur lijkt op een boom met de wortelknoop bovenaan en vertakkingen naar beneden naar de bladknopen onderaan.
Het lijkt op een goed georganiseerde boom, waarbij elk niveau de zoekopdracht leidt op basis van de gesorteerde volgorde van de gegevens.
Deze afbeelding toont een B-Tree index zoekpad:
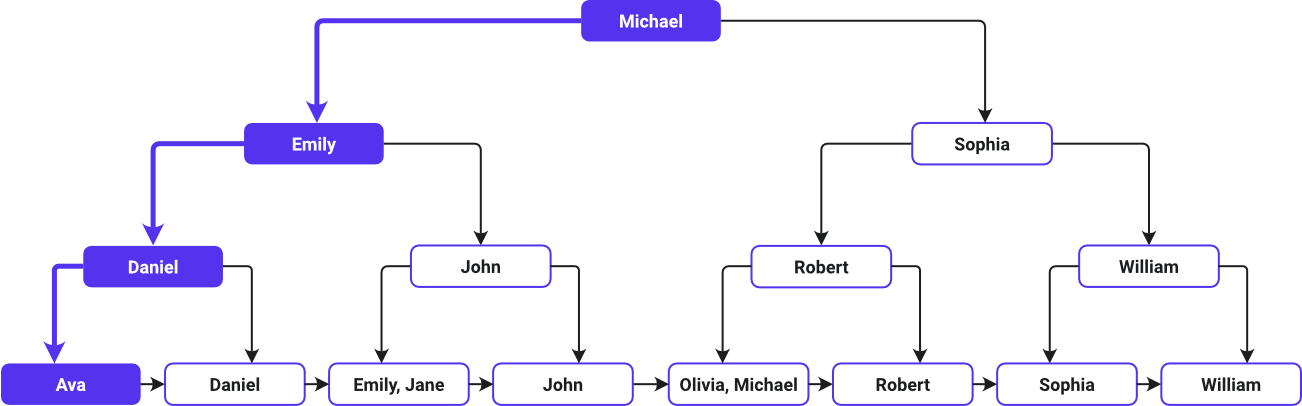
Ava staat als eerste in de lijst en William als laatste in oplopende alfabetische volgorde – hoe de B-Tree de namen heeft gerangschikt. Het B-Tree systeem wijst de middelste waarde in de lijst aan als root node. Omdat Michael in het midden van de alfabetische lijst staat, is het de root node. De boom vertakt zich vervolgens, met waarden links en rechts van Michael.
Naar beneden toe biedt elke node meer sleutels (directe links naar de oorspronkelijke rijen met gegevens) om het zoeken door de alfabetisch geordende namen te leiden. Vervolgens vind je de gegevens voor de voornaam van elke klant op de leaf nodes.
De query begint met het vergelijken van Ava met het root node Michael. Hij gaat naar links nadat hij heeft vastgesteld dat Ava alfabetisch vóór Michael staat. Het gaat naar beneden naar het linker child (Emily), dan weer naar links naar Daniel, en nog een keer naar links naar Ava voordat het aankomt bij de leaf node die de informatie van Ava bevat.
De B-Tree functioneert als een vereenvoudigd navigatiesysteem, dat de zoekopdracht effectief naar een bepaalde plaats leidt zonder elke naam in de dataset te controleren. Het is alsof je door een zorgvuldig geordende map navigeert door strategisch geplaatste wegwijzers te volgen die je rechtstreeks naar de bestemming brengen.
Soorten indexen
Er zijn verschillende soorten indexen voor verschillende doeleinden. Laten we deze verschillende types hieronder bespreken.
1. Single-level indexen
Single-level indexen, ook wel flat indexen, koppelen indexsleutels aan tabelgegevens. Elke sleutel in de index komt overeen met een enkele tabelrij.
De kolom customer_id is een primaire sleutel in de tabel Customer en dient als single-level index. De sleutel identificeert elke klant en koppelt hun informatie in de tabel.
| Index (customer_id) | Row Pointer |
| 1 | Rij 1 |
| 2 | Rij 2 |
| 3 | Rij 3 |
| 4 | Rij 4 |
| .. | .. |
De relatie tussen customer_id sleutels en individuele klantgegevens is eenvoudig. Single-level indexen blinken uit in scenario’s met tabellen die maar een paar rijen of kolommen met weinig verschillende waarden bevatten. Kolommen zoals status of categorie zijn bijvoorbeeld goede kandidaten.
Gebruik een single-level voor eenvoudige query’s die een specifieke rij lokaliseren op basis van één enkele kolom. De implementatie ervan is eenvoudig, ongecompliceerd en efficiënt voor kleinere datasets.
2. Multi-level indexen
In tegenstelling tot single-level indexen voor het georganiseerd ophalen van gegevens, gebruiken multi-level indexen een hiërarchische structuur. Ze hebben meerdere niveaus van begeleiding. De top-level index de zoekopdracht naar een index op een lager niveau, enzovoort tot het niveau van de leafs, waar de gegevens worden opgeslagen. Deze structuur vermindert het aantal vergelijkingen dat nodig is tijdens zoekopdrachten.
Kijk eens naar een multi-level index met de kolommen adres en klant_id.
| Index (adres) | Sub-Index (customer_id) | Row Pointer |
| 123 Main Str | 1 | Rij 1 |
| 456 Oak Ave | 2 | Rij 2 |
| 789 Pine Rd | 3 | Rij 3 |
| .. | .. | .. |
Het eerste niveau organiseert adressen. Het tweede niveau, binnen elk adres, organiseert de klant-ID’s verder.
Deze organisatie is uitstekend voor uitgebreidere datasets die een georganiseerde zoekhiërarchie vereisen. Het is ook handig voor kolommen zoals achternaam met een matige kardinaliteit (de uniciteit van gegevenswaarden in een bepaalde kolom).
3. Geclusterde indexen
Geclusterde indexen in MySQL dicteren de logische volgorde van de index en de volgorde van de gegevens in de tabel. Als je een geclusterde index toepast op de kolom klant in de tabel Klant, worden de rijen gesorteerd op basis van de waarden van de kolom. Dit betekent dat de volgorde van de gegevens in de tabel de volgorde van de geclusterde index weerspiegelt, waardoor de prestaties bij het ophalen van gegevens voor specifieke patronen worden verbeterd door de I/O op de schijf te verminderen.
Deze strategie is effectief als het patroon voor het ophalen van gegevens overeenkomt met de volgorde van klant-ID’s. Het is ook geschikt voor kolommen met een hoge kardinaliteit, zoals klant_id.
Hoewel geclusterde indexen voordelen bieden bij het ophalen van gegevens voor specifieke patronen, is het belangrijk om een potentieel nadeel op te merken. Het sorteren van rijen op basis van de geclusterde index kan de prestaties van invoeg- en updatetaken beïnvloeden, vooral als het invoeg- of updatepatroon niet overeenkomt met de volgorde van de geclusterde index. Dit komt doordat nieuwe gegevens moeten worden ingevoegd of bijgewerkt op een manier die de gesorteerde volgorde handhaaft, wat resulteert in extra overhead.
4. Niet-geclusterde indexen
Niet-geclusterde indexen geven databasestructuren meer flexibiliteit. Stel dat je een niet-geclusterde index op een e-mailkolom gebruikt. In tegenstelling tot een geclusterde index, verandert deze de volgorde van de items in de tabel niet.
In plaats daarvan bouwt hij een nieuwe structuur die sleutels – in dit geval e-mailadressen – koppelt aan gegevensrijen. Wanneer je de database opvraagt naar een specifiek e-mailadres, leidt de niet-geclusterde index de zoekopdracht direct naar de relevante rij zonder te vertrouwen op de volgorde in de tabel.
De flexibiliteit van niet-geclusterde indexen is hun belangrijkste voordeel. Ze maken efficiënt zoeken van meerdere kolommen mogelijk zonder een volgorde op te leggen aan de opgeslagen gegevens. Dit systeem maakt niet-geclusterde indexen veelzijdig, omdat ze geschikt zijn voor zoekopdrachten die niet de primaire volgorde van de tabel volgen.
Niet-geclusterde indexen zijn handig wanneer het patroon voor het ophalen van gegevens afwijkt van alfabetische volgorde en voor kolommen met een matige tot hoge kardinaliteit, zoals e-mail.
Indexen maken
Nu we hebben bekeken wat indexen zijn, laten we eens kijken naar enkele praktische voorbeelden van het maken van indexen met MySQL Workbench.
Vereisten
Om mee te kunnen volgen, heb je nodig:
- Een MySQL database (compatibel met MariaDB)
- Enige ervaring met SQL en MySQL
- MySQL Workbench
De klantentabel maken
- Start MySQL Workbench en maak verbinding met je MySQL server.
- Voer de volgende SQL query uit om een klantentabel (customer) te maken:
CREATE TABLE Customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(15), address VARCHAR(255) ); - Voeg de volgende gegevens in:
-- Adding Data to the Customer Table INSERT INTO Customer (customer_id, first_name, last_name, email, phone_number, address) VALUES (1, 'John', 'Doe', '[email protected]', '123-456-7890', '123 Main St'), (2, 'Jane', 'Smith', '[email protected]', '987-654-3210', '456 Oak Ave'), (3, 'Robert', 'Johnson', '[email protected]', '111-222-3333', '789 Pine Rd'), (4, 'Emily', 'Williams', '[email protected]', '555-666-7777', '101 Cedar Ln'), (5, 'Michael', 'Brown', '[email protected]', '444-555-8888', '202 Elm St'), (6, 'Sophia', 'Davis', '[email protected]', '999-888-7777', '303 Maple Ave'), (7, 'Daniel', 'Miller', '[email protected]', '777-888-9999', '404 Birch Rd'), (8, 'Olivia', 'Jones', '[email protected]', '333-222-1111', '505 Pine St'), (9, 'William', 'Wilson', '[email protected]', '111-333-5555', '606 Oak Ln'), (10, 'Ava', 'Moore', '[email protected]', '888-777-6666', '707 Cedar Ave');
Single-level indexen
Een tactiek voor het optimaliseren van queryprestaties in MySQL en MariaDB is het gebruik van single-level indexen.
Om een single-level index toe te voegen aan de tabel customer, gebruik je het CREATE INDEX statement:
-- Creating a Single-Level Index on "customer_id"
CREATE INDEX idx_customer_id ON Customer(customer_id);Bij succesvolle uitvoering bevestigt de database het maken van de index door de volgende code terug te sturen:
0 row(s) affected Records: 0 Duplicates: 0 Warnings: 0Nu worden query’s die gegevens filteren op basis van waarden uit de kolom customer_id optimaal afgehandeld door de database, waardoor de efficiëntie sterk toeneemt.
Multi-level indexen
MySQL en MariaDB gaan verder dan het indexeren van individuele kolommen door multi-level indexen te bieden. Deze indexen omvatten meer dan één niveau of kolom en combineren waarden van meerdere kolommen in één index om het uitvoeren van queries efficiënter te maken.
Gebruik de volgende code om een index op meerdere niveaus te maken in MySQL of MariaDB, met de nadruk op de kolommen adres en customer_id:
-- Creating a Multi-Level Index based on "address" and "customer_id"
CREATE INDEX idx_address_customer_id ON Customer(address, customer_id);Het strategisch gebruik van multi-level indexen leidt tot aanzienlijke verbeteringen in de prestaties van query’s, vooral als het gaat om sets van kolommen.
Geclusterde indexen
Naast individuele indexen en multi-level indexen maken MySQL en MariaDB gebruik van geclusterde indexen, een dynamisch hulpmiddel om de databaseprestaties te verbeteren door de gegevensrijen af te stemmen op de volgorde van de indexaanwijzers.
Door bijvoorbeeld een geclusterde index toe te passen op de kolom customer_id in de tabel Customer wordt de volgorde van de klant-ID’s gelijkgetrokken.
-- Creating a Clustered Index on "customer_id"
CREATE CLUSTERED INDEX idx_customer_id_clustered ON Customer(customer_id);Door de geoptimaliseerde volgorde van gegevens verbetert deze strategie het ophalen van gegevens van specifieke patronen aanzienlijk, terwijl de schijf-I/O afneemt.
Niet-geclusterde indexen
Niet-geclusterde indexen kunnen queries optimaliseren afhankelijk van de kolommen zonder de gegevens in een bepaalde volgorde te dwingen. In MySQL en MariaDB hoef je niet aan te geven dat een index niet-geclusterd is.
De tabelarchitectuur impliceert het. Alleen de primaire sleutel of de eerste niet-null unieke sleutel kan een geclusterde index zijn. De andere indexen van de tabel zijn allemaal impliciet niet-geclusterd. Als voorbeeld van een niet-geclusterde index kun je het volgende bekijken:
-- Creating a Non-clustered Index on "email"
CREATE INDEX idx_email_non_clustered ON Customer(email);Met niet-geclusterde indexen kun je efficiënt zoeken in meerdere kolommen, wat resulteert in een veelzijdigere en responsievere database.
Best practices en belangrijke punten
Kies single-level indexen als je werkt met kolommen met een klein bereik van verschillende waarden, zoals status of categorie. Gebruik multi-level indexen en niet-geclusterde indexen voor kolommen met een breder scala aan waarden, zoals e-mail.
Je voorkeurspatronen voor het ophalen van gegevens zijn belangrijk bij het kiezen tussen geclusterde en niet-geclusterde indexen. Kies voor geclusterde indexen kolommen met een hoge kardinaliteit, zoals klant-ID. Kies voor niet-geclusterde indexen kolommen met een gemiddelde tot hoge kardinaliteit, zoals e-mail.
Indexen optimaliseren
Om de prestaties van je indexen te verbeteren, kun je een aantal praktische strategieën gebruiken, zoals het coverenvan indexen en het verwijderen van overbodige indexen.
1. Covering index
Covering indexen verbeteren de queryprestaties door indexen te maken die alle benodigde gegevens coveren. De term covering index betekent dat een index alle kolommen bevat die nodig zijn om een query uit te voeren, waardoor het niet nodig is om de gegevensrijen te bevragen.
-- Create a Covering Index on "first_name" and "last_name"
CREATE INDEX idx_covering_name ON Customer(first_name, last_name);2. Verwijder overbodigheden
Verwijder overbodige indexen, maar wees voorzichtig, want het verwijderen van indexen kan bepaalde queryprestaties beïnvloeden.
-- Remove an Unnecessary Index
DROP INDEX idx_unnecessary_index ON Customer;Controleer en verwijder overbodige indexen regelmatig om een gestroomlijnde en efficiënte databasestructuur te garanderen.
3. Vermijd over-indexeren
Vermijd veelvoorkomende valkuilen zoals over-indexeren. Hoewel indexen de queryprestaties verbeteren, kan het maken van te veel indexen het rendement verminderen. Het is cruciaal om een balans te vinden en over-indexeren te vermijden, wat kan leiden tot meer opslagruimte en mogelijke prestatievermindering.
4. Analyseer query patronen
Het is ook een veel voorkomende valkuil om de analyse van querypatronen over het hoofd te zien voordat je indexen aanmaakt. Het begrijpen van de queries die vaak worden uitgevoerd en je richten op het indexeren van kolommen die worden gebruikt in WHERE clausules of JOIN voorwaarden is essentieel voor optimale prestaties.
Samenvatting
Dit artikel verkende MySQL en MariaDB indexering, met de nadruk op de efficiëntie van het B-Tree mechanisme. Het behandelde de basisprincipes van indexeren en verschillende index types (single-level, multi-level, geclusterd en niet-geclusterd).
Of je nu optimaliseert voor werklasten die veel lezen vereisen of de schrijfprestaties wilt verbeteren, de database hosting service van Kinsta biedt MySQL en MariaDB gebruikers een betrouwbare en krachtige oplossing voor hun indexeringsbehoeften. Probeer Kinsta’s Database Hosting om te profiteren van MySQL en MariaDB en hun indexeringsmogelijkheden.


