
Atualmente, quase todo software ou aplicativo web requer um banco de dados no backend. O aumento das transações que ocorrem por segundo e os terabytes de dados armazenados exige uma estrutura estável e flexível para hospedar e servir esses dados.
Naturalmente, para os startups, a questão do custo também entra em cena. Sabia que você pode acessar e até mesmo construir este banco de dados sem custos, sem compromisso?
Sim, você ouviu bem – o banco de dados PostgreSQL garante tudo o que mencionamos acima, incluindo algumas vantagens extras! Neste artigo, vamos rever vários aspectos do PostgreSQL que permitem que ele se mantenha alto em um segmento em rápida evolução.
Vamos ao que interessa!
O que é PostgreSQL?
PostgreSQL é um sistema de banco de dados open-source, altamente estável que fornece suporte a diferentes funções de SQL, como chaves estrangeiras, subconsultas, triggers, e diferentes tipos e funções definidas pelo usuário. Ele aumenta ainda mais a linguagem SQL oferecendo várias características que meticulosamente escalam e reservam cargas de trabalho de dados. É usada principalmente para armazenar dados para muitas aplicativos móveis, web, geoespaciais e analíticas.
Vamos mergulhar profundamente em cada aspecto do PostgreSQL neste artigo, começando com suas principais características na próxima seção. Vamos começar a trabalhar.
Principais características do PostgreSQL
Existem algumas características chave do banco de dados PostgreSQL que o tornam único e amplamente favorecido quando comparado a outros bancos de dados. Atualmente, é o segundo banco de dados mais utilizado, ficando atrás apenas do MySQL.
Vamos dar uma olhada mais detalhada nestas características.
Confiabilidade e conformidade de padrões
PostgreSQL oferece verdadeira semântica ACID para transações e tem total suporte para chaves estrangeiras, joinins, views, triggers e procedimentos armazenados, em muitos idiomas diferentes. Ele inclui a maioria dos tipos de dados SQL como INTEGER, VARCHAR, TIMESTAMP, e BOOLEAN. Também suporta o armazenamento de grandes objetos binários, incluindo imagens, vídeos ou sons. Ele é confiável, pois tem uma grande rede de suporte integrada à comunidade. O PostgreSQL é um banco de dados tolerante a falhas graças ao seu registro write-ahead.
Extensões
O PostgreSQL possui vários conjuntos robustos de recursos, incluindo recuperação point-in-time, Controle de Concorrência Multi-Versão (MVCC), tablespaces, controles de acesso granulares, replicação assíncrona, um planejador/otimizador de consultas refinado e registro write-ahead. O Controle de Concorrência Multi-Versões permite a leitura e escrita simultânea de tabelas, bloqueando apenas atualizações simultâneas da mesma linha. Desta forma, os conflitos são evitados.
Escalabilidade
O PostgreSQL suporta Unicode, conjuntos de caracteres internacionais, codificações de caracteres multi-byte, e é sensível ao local para ordenação, sensibilidade a maiúsculas e minúsculas, e formatação. O PostgreSQL é altamente escalável – no número de usuários simultâneos, ele pode acomodar assim como a quantidade de dados que ele pode gerenciar. Além disso, o PostgreSQL é multi-plataforma e pode rodar em muitos sistemas operacionais incluindo Linux, Microsoft Windows, OS X, FreeBSD, e Solaris.
Carregamento dinâmico
O servidor PostgreSQL também pode incluir código escrito pelo usuário em si mesmo através de carregamento dinâmico. O usuário pode especificar um arquivo de código objeto; por exemplo, uma biblioteca compartilhada que implementa uma nova função ou tipo e o PostgreSQL irá carregá-lo conforme necessário. A habilidade de modificar sua operação na hora faz com que ela seja unicamente adequada para implementar novas estruturas de armazenamento e aplicativos rapidamente.
Arquitetura do PostgreSQL
O servidor PostgreSQL tem uma estrutura simples, consistindo de uma Memória Compartilhada, Processos de Background e uma estrutura de Diretório de Dados. Nesta seção, nós discutimos cada componente, e como eles interagem uns com os outros. Dada abaixo é uma ilustração da arquitetura do PostgreSQL. Inicialmente, uma solicitação é enviada pelo cliente para o servidor. Então, o servidor PostgreSQL processa os dados usando buffers compartilhados e processos em segundo plano. O arquivo físico do servidor de banco de dados do PostgreSQL é armazenado no diretório de dados.
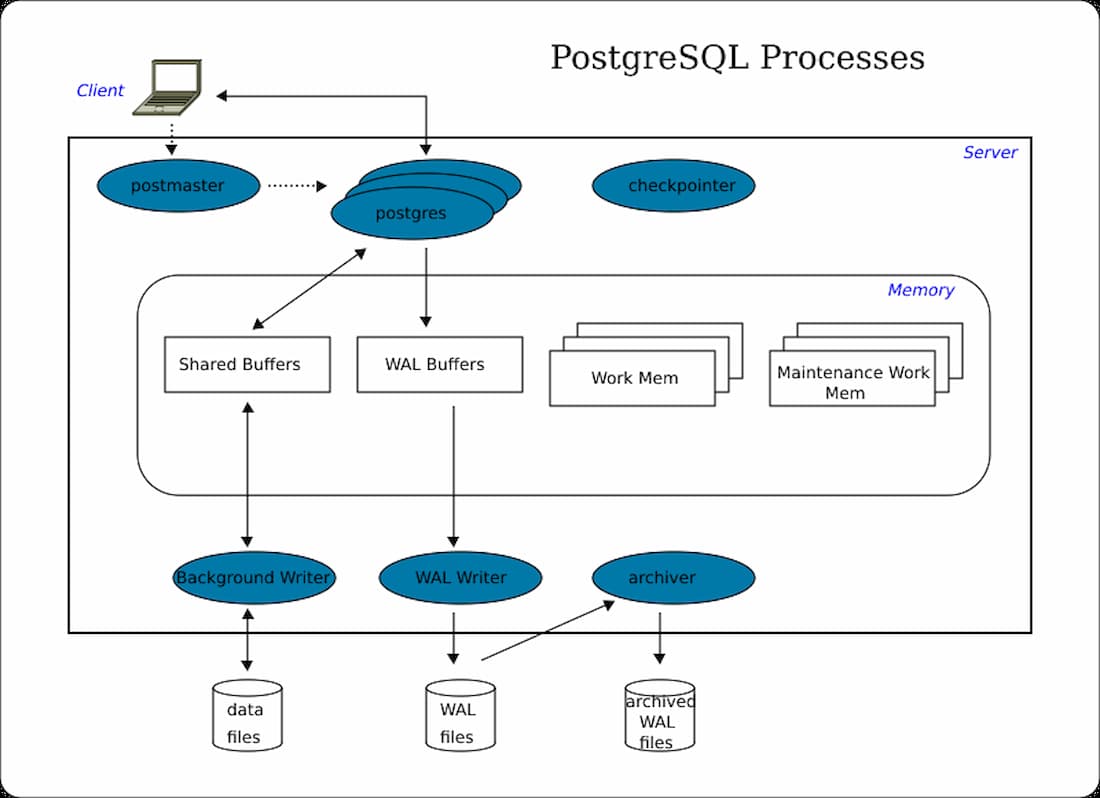
Memória compartilhada
A memória compartilhada é reservada para cache de log de transações e cache de banco de dados. Ela ainda tem elementos como Buffers Compartilhados, Buffers WAL, Memória de Trabalho e Memória de Trabalho de Manutenção. Vamos detalhar cada tópico abaixo.
Buffers compartilhados
Estes buffers servem para minimizar o DISK IO do servidor. Para cumprir este objetivo, é justo definir o valor do buffer compartilhado como 25% da memória total se nós tivermos um servidor dedicado para o PostgreSQL. O valor padrão dos buffers compartilhados a partir da versão 9.3 é de 128 MB. É imperativo tentar minimizar a contenção quando vários usuários o acessam simultaneamente. Blocos frequentemente utilizados devem ficar no buffer o máximo de tempo possível. Isto permite que ele acesse os dados o mais rápido possível.
Buffers WAL
Os Buffers WAL armazenam temporariamente as mudanças no banco de dados. O arquivo WAL consiste de conteúdo escrito pelo buffer WAL em um ponto pré-determinado no tempo. Os arquivos WAL e os buffers WAL são significativos para recuperar os dados durante o backup e a recuperação.
Memória de trabalho
Este espaço de memória é usado para operações de bitmap, ordenação, fusão de junções e hash para gravar dados em arquivos temporários em disco. A configuração padrão a partir da versão 9.3 é de 4 MB.
Memória de trabalho de manutenção
Este slot de memória é usado para operações de banco de dados como ANALYZE, VACUUM, ALTER TABLE, e CREATE INDEX. A configuração padrão a partir da versão 9.4 é de 64 MB.
Processos de fundo
Cada processo de fundo é integral e executa uma função única para gerenciar o servidor. Alguns processos importantes de fundo são mais elaborados abaixo:
Processo Checkpointer
Quando ocorre um ponto de verificação, o dirty buffer é gravado no arquivo. O Checkpointer essencialmente grava todas as páginas sujas da memória para o disco e limpa a área de buffer compartilhada. Se o banco de dados falhar, a perda de dados pode ser medida obtendo a diferença entre o tempo do último ponto de verificação e o tempo de parada do PostgreSQL.
Background Writer Process
Ele atualiza os logs e as informações de backup. Até a versão 9.1, este processo era integrado junto com o processo de checkpointer, que era feito regularmente. Entretanto, a partir da versão 9.2, o processo de checkpointer foi separado do processo de escrita em segundo plano.
Writer WAL
Este processo escreve e descarrega os dados WAL no buffer WAL periodicamente para o armazenamento persistente.
Arquivador
Se habilitado, este processo tem a responsabilidade de copiar os arquivos de log WAL para um diretório especificado.
Logger/Logging Collector
Este processo escreve um buffer WAL para o arquivo WAL.
Data Files/Data Directory Structure
O PostgreSQL tem vários bancos de dados, juntos formando um cluster de bancos de dados. Quando inicializados, os bancos de dados template0, template1 e Postgres são criados. A criação do novo banco de dados do usuário é feita através de bancos de dados modelo, que consistem nas tabelas do catálogo do sistema. Embora a lista de tabelas no template0 e template1 seja a mesma após a inicialização, somente o banco de dados template1 pode criar os objetos que o usuário precisa, portanto o banco de dados do usuário é criado através da clonagem do banco de dados template1.
Os dados necessários para o cluster são armazenados dentro do diretório de dados do cluster, que também é chamado de “PGDATA”. Ele consiste de vários subdiretórios. Alguns subdiretórios importantes são mencionados abaixo:
- Global: O subdiretório global consiste de tabelas em cluster, tais como o banco de dados de usuários.
- Base: O subdiretório Base é a localização física do espaço de tabelas padrão. Ele contém vários subdiretórios por banco de dados, dentro dos quais os catálogos do sistema são armazenados.
- PID: O arquivo PID consiste no atual ID do processo de pós-mestre (PID).
- PG_VERSION: Este subdiretório consiste na informação da versão do banco de dados.
- PG_NOTIFY: Este subdiretório contém os dados de status LISTEN/NOTIFY. Estes arquivos podem ser úteis para a solução de problemas.
Por que usar o PostgreSQL?
Além de fornecer um conjunto de recursos como índices, views e procedimentos armazenados, o PostgreSQL tem muito mais a oferecer, ou seja, o PostgreSQL tem muito mais a oferecer:
- Suporte de linguagens
- Open-Source
- Banco de Dados Relacional a Objetos
- Desempenho
- Extensibilidade
- Capacidade de balanceamento de carga
- Confiabilidade
- Internacionalização
Vamos examiná-las com mais detalhes.
Suporte de linguagem
PL/PGSQL é uma linguagem procedural nativa fornecida pelo PostgreSQL que tem diferentes características modernas. Ele apoia o tipo de dados JSON que é leve e garante a flexibilidade incluída em um único pacote. Como resultado, o PostgreSQL suporta várias linguagens de programação e protocolos incluindo Perl, Ruby, Python, .Net, C/C++, Java, ODBC, e Go.
Open-Source
É gratuito e de código aberto – este é de longe o benefício mais significativo do PostgreSQL. Ele tem sido apoiado por mais de 20 anos de desenvolvimento comunitário, o que por sua vez tem contribuído para seu alto nível de integridade. Seu código fonte está disponível sob uma licença open-source que permite a você usá-lo, modificá-lo e implementá-lo da forma que você achar conveniente – sem custo extra.
Banco de dados relacional a objetos
Objetos, classes e sobrecarga de funções são suportados diretamente no PostgreSQL. É possível estender os tipos de dados para criar tipos de dados personalizados, devido às suas características orientadas a objetos. Isto garante alta flexibilidade para desenvolvedores que operam com modelos de dados complexos que requerem integração com banco de dados.
A herança de tabela é outra característica suportada pelo PostgreSQL devido às suas características orientadas a objetos. O child table pode herdar as colunas do parent table, além das outras colunas que a child table possui, tornando-a diferente de si mesma.
Desempenho
As operações de escrita no PostgreSQL podem ser realizadas simultaneamente sem a necessidade de cadeados de leitura/gravação. Os índices são usados para acelerar as consultas ao lidar com grandes quantidades de dados, o que permite aos bancos de dados encontrar uma linha específica sem a necessidade de percorrer todos os dados.
Com o PostgreSQL, você pode até mesmo criar um índice de expressão, que funciona no resultado de uma expressão ou função em vez de apenas o valor de uma coluna. A indexação parcial também é suportada, na qual apenas uma parte da tabela é indexada. Ele também suporta a paralelização de consultas de leitura, compilação Just-in-time (JIT) de expressões e transações aninhadas (via savepoints) garantindo grande performance e eficiência.
Extensibilidade
PostgreSQL é altamente extensível, pois sua operação é orientada por catálogo, ou seja, as informações são armazenadas em bancos de dados, colunas, tabelas, etc. O PostgreSQL não apenas detém uma quantidade maior de informações em seus catálogos, mas também detalhes sobre os tipos de dados, métodos de acesso, funções, e assim por diante. Você pode até mesmo ir ao ponto de escrever seus códigos a partir de diferentes linguagens de programação sem recompilar seu banco de dados e definir seus tipos de dados.
Capacidades de balanceamento de carga
Ele garante alta disponibilidade e balanceamento de carga através da operação do servidor standby, planejamento contínuo, preparação do primário para servidores standby, configuração de um servidor standby, streaming de replicação, slots de replicação, replicação em cascata, e arquivamento contínuo em standby. Adicionalmente, o PostgreSQL suporta replicação síncrona, onde duas instâncias de banco de dados podem ser executadas ao mesmo tempo e o banco de dados mestre é sincronizado com um banco de dados escravo simultaneamente, garantindo ainda mais alta disponibilidade.
Confiabilidade
Além de armazenar os dados com segurança e permitir que o usuário recupere os dados quando a solicitação é processada, ela é apoiada por uma comunidade de colaboradores que regularmente encontram bugs e tentam melhorar o software, tornando o PostgreSQL confiável.
Internacionalização
O processo de projetar software para que ele possa ser utilizado em uma série de regiões é conhecido como internacionalização. Ele suporta conjuntos de caracteres internacionais através de codificações de caracteres multi-byte, colações de UTI, Unicode, e é sensível ao local para ordenação, formatação e sensibilidade ao caso. A visualização de mensagens geradas pelo PostgreSQL no idioma de sua escolha é um exemplo de Internacionalização.
Quando usar o PostgreSQL
Você precisa construir consultas complexas e relacionamentos que precisam ser atualizados frequentemente e mantidos consistentemente da maneira mais econômica possível? O PostgreSQL pode ser uma opção adequada. Não apenas o PostgreSQL é gratuito, mas também é multiplataforma, e não está limitado apenas ao sistema operacional Windows. Se você quiser analisar dados, o PostgreSQL fornece uma grande quantidade de expressões regulares como base para o trabalho analítico.
É também um dos melhores bancos de dados quando se trata de suporte CSV. Comandos simples como “copiar de” e “copiar para” ajudam no rápido processamento de dados. Se houver um problema de importação, ele irá lançar um erro e interromper a importação imediatamente. As seções seguintes irão cobrir alguns dos aplicativos mais comuns do PostgreSQL no mundo moderno. Vamos começar.
Dados geospaciais do governo
O PostGIS Geospatial database add-on de extensão para PostgreSQL é, sem dúvida, benéfico. Quando utilizado junto com a extensão PostGIS, o PostgreSQL suporta objetos geográficos e pode ser utilizado como um armazenamento de dados geoespaciais para sistemas de informação geográfica (GIS) e serviços baseados em localização.
Indústria financeira
O PostgreSQL é um sistema de SGBD ideal para a indústria financeira. Por ser totalmente compatível com ACID, é uma escolha ideal para OLTP (Online Transaction Processing), já que estes bancos de dados precisam ser escritos, lidos e atualizados frequentemente, juntamente com uma ênfase no processamento rápido. Ele também é apto para executar a análise de bancos de dados. Pode ser integrado com qualquer software que realize operações matemáticas como Matlab e R.
Dados científicos
Dados científicos requerem terabytes de dados. É imperativo tratar os dados da maneira mais eficiente possível. O PostgreSQL fornece uma analítica maravilhosa e um poderoso mecanismo SQL. Isto ajuda a gerenciar uma grande quantidade de dados com facilidade.
Tecnologia Web
Os sites frequentemente lidam com centenas ou milhares de pedidos por segundo. Se o desenvolvedor está procurando uma solução econômica e escalável, o PostgreSQL seria o mais adequado. O PostgreSQL pode executar sites e aplicativos dinâmicos como parte de uma alternativa robusta à pilha LAMP, ou seja, a pilha LAPP. (Linux, Apache, PostgreSQL, PHP, Python, e Perl)
Manufatura
Muitas startups e grandes empresas utilizam o PostgreSQL como a principal solução de armazenamento de dados para produtos, soluções e aplicativos em escala de internet. O desempenho da cadeia de suprimentos pode ser otimizado usando este SGBD de código aberto como um backend de armazenamento. Como resultado, isto permite que as empresas reduzam o custo de operação de seus negócios.
Desafios operacionais do PostgreSQL
Somente colocamos os elogios do PostgreSQL neste artigo até agora, então é justo que mostremos a você algumas falhas que você pode tropeçar enquanto se dedica ao PostgreSQL. Aqui estão alguns desafios operacionais que você pode encontrar durante o processo de adoção do PostgreSQL.
- Falta de um ecossistema do banco de dados maduro: PostgreSQL possui uma das comunidades que mais cresce, mas ao contrário dos fornecedores tradicionais de banco de dados, a comunidade PostgreSQL não tem o conforto de um ecossistema de banco de dados desenvolvido.
- A caridade da especialidade: PostgreSQL é frequentemente acoplado a vários bancos de dados, tais como o MongoDB. Agora, cada banco de dados precisa de proezas especializadas, e contratar pessoal técnico com a proficiência desejada do PostgreSQL pode ser uma ordem alta a ser preenchida. Junto com ferramentas de gerenciamento para PostgreSQL, especialistas em bancos de dados e equipes DevOps precisam lidar com vários bancos de dados de vários fornecedores. Isto pode ser difícil de gerenciar quando você não pode alternar entre os processos existentes.
- Inconsistência: Como o PostgreSQL é uma ferramenta de código aberto, diferentes equipes de desenvolvimento de TI dentro de uma organização podem começar a aproveitá-la organicamente. Isto pode levar a outro bloqueio – falta de um único ponto de conhecimento para todas as instâncias do PostgreSQL dentro do ambiente de TI. Outro problema que pode surgir de diferentes equipes tentando resolver o mesmo problema é a duplicação e redundância de trabalho.
Alternativas chave do PostgreSQL
Aqui estão algumas alternativas chave do PostgreSQL que você pode aproveitar para o seu site WordPress.
MySQL
Quando você pensa em bancos de dados, sua mente instantaneamente se inclina para o MySQL. Foi uma opção bastante onipresente para os desenvolvedores por muito tempo antes das alternativas viáveis começarem a surgir. Ela foi usada por mais de 39% dos desenvolvedores em 2019. Mesmo carecendo da versatilidade do PostgreSQL, ele ainda pode ser útil para vários casos de uso como aplicativos web escaláveis.
O MySQL tem sido mantido pela Oracle desde o seu início em 1995. A Oracle também oferece versões elite do MySQL com plugins proprietários, serviços suplementares, extensões e suporte robusto ao usuário. Para entender melhor o MySQL, você precisa ter um melhor entendimento dos modelos cliente-servidor e bancos de dados relacionais. Simplificando, seus dados são particionados em várias áreas de armazenamento separadas também conhecidas como tabelas, ao contrário de descarregar tudo em uma grande unidade de armazenamento solitária. Esta é a essência de um banco de dados relacional.
Além de ser uma plataforma de banco de dados confiável e sólida, é bastante fácil de dominar. A curva de aprendizado não é tão íngreme quanto alguns de seus contemporâneos, já que você não precisa ter uma compreensão completa de SQL para começar a trabalhar com o MySQL.
Se você utiliza o WordPress para seu site e quer entender como fazer o MySQL rodar mais rápido, sua melhor aposta seria refinar seu banco de dados para se alinhar com a forma como você utiliza o WordPress. Em termos técnicos, isto é conhecido como MySQL Performance Tune. A vantagem óbvia de otimizar o MySQL é tempos de carregamento mais curtos junto com um site mais rápido em geral. Além disso, se você mantém seu banco de dados corretamente, você deve ver uma melhoria constante em seu crescimento mesmo quando ele se expande.
MariaDB
O MariaDB é um garfo comercialmente suportado do Sistema de Gerenciamento de Banco de Dados Relacionais MySQL que ostenta uma abordagem fundamentalmente distinta para atender as necessidades do mundo moderno. O mecanismo de armazenamento MariaDB construído propositadamente oferece suporte para cargas de trabalho que anteriormente precisavam de uma vasta gama de bancos de dados especializados. Isto permite que seja um balcão único para as organizações, seja na nuvem ou no hardware de commodity que elas gostam.
Você pode implantar o MariaDB dentro de minutos para casos de uso analítico, transacional ou híbrido para oferecer destreza operacional incomparável sem renunciar às principais características empresariais. Isto inclui SQL completo e conformidade real com ACID.
MariaDB oferece os seguintes produtos aos seus usuários:
- MariaDB Enterprise: MariaDB Enterprise é uma solução de banco de dados de código aberto absoluta, de grau de produção, que pode lidar com cargas de trabalho analíticas, transacionais ou híbridas analíticas/transacionais com elegância. O MariaDB Enterprise também possui a capacidade de escalar de bancos de dados colunares e autônomos para bancos de dados SQL totalmente distribuídos que podem realizar milhões de transações por segundo. Ela também permite realizar análises interativas e improvisadas em bilhões de filas.
- MariaDB Community Server: MariaDB Community Server é o banco de dados relacional de código aberto alavancado por uma grande maioria dos desenvolvedores de hoje. Não só o Servidor Comunitário MariaDB é compatível com Oracle, MySQL e vários outros bancos de dados, como também é garantido que ele permanecerá em código aberto para sempre. As características salientes incluem armazenamento em colunas para análise, SQL moderno, mecanismos de armazenamento plugáveis e alta disponibilidade.
- MariaDB SkySQL: O SkySQL é conhecido como uma oferta Database-as-a-Service (DBaaS) que traz o poder completo do MariaDB Enterprise para a nuvem junto com seu suporte para cargas de trabalho analíticas, transacionais e híbridas. O SkySQL é construído sobre Kubernetes e renovado para serviços e infraestrutura de nuvem. O SkySQL fez o seu nome neste espaço ao combinar auto-serviço e facilidade de uso com capacidades de suporte de primeira linha e confiabilidade empresarial. Bastante evidente pela última afirmação, isto compreende tudo que é necessário para executar com segurança bancos de dados pivotal na nuvem, juntamente com a governança corporativa.
Devido à sua compatibilidade com o MySQL, você pode potencializar o MariaDB como um “stand-in” para o MySQL com praticamente nenhuma consequência.
Melhores práticas para o seu banco de dados
Quando você pensa em plataformas amigáveis para iniciantes para proprietários de sites pela primeira vez, você provavelmente está pensando no WordPress. O WordPress permite que você alcance muito sem nenhuma experiência prévia de codificação. Entretanto, para extrair o máximo valor do WordPress, você ainda precisa ter um entendimento claro de como alguns de seus elementos básicos funcionam. Por exemplo, se você vem utilizando o WordPress para o seu site há algum tempo, provavelmente é um bom momento para entender como os bancos de dados do WordPress funcionam.
Isso imediatamente suscita uma pergunta comum: por que o WordPress precisa de um banco de dados afinal de contas? Pode não parecer, mas há mais no WordPress do que se vê. Há muito trabalho nos bastidores para fazê-lo funcionar eficientemente, independentemente do tamanho do seu site.
Para aprofundar, você precisa saber que um site WordPress é composto de muitos tipos diferentes de dados. Agora é fácil saber que toda essa informação é armazenada em um banco de dados WordPress consolidado. Este banco de dados é integral para o seu site WordPress, salvando todas as mudanças que você ou seus visitantes fazem e permitindo que seu site funcione perfeitamente. Aqui estão alguns dados que são coletados em seu banco de dados WordPress:
- Informações organizacionais tais como tags e categorias.
- Configurações em todo o site.
- Páginas, posts e conteúdo relacionado.
- Tema e dados relacionados a plugins.
- Comentários e dados dos usuários.
Quando você instala um site WordPress, uma parte do processo é a criação de um banco de dados para ele. Normalmente, isto acontece automaticamente. Entretanto, há uma provisão se você quiser criar um banco de dados manualmente, ou mesmo alavancar um banco de dados existente com um novo site.
A seção seguinte irá falar sobre as práticas recomendadas para o seu banco de dados WordPress.
Usando uma ferramenta de gerenciamento de banco de dados
A função básica das ferramentas de Gerenciamento de Banco de Dados é permitir que você veja o conteúdo do seu banco de dados. Para que um banco de dados funcione sem problemas, alavancar uma ferramenta de gerenciamento de banco de dados pode ser sua melhor aposta. Em geral, as ferramentas de gerenciamento de banco de dados consolidam funções que atendem às necessidades de três profissionais distintos do banco de dados:
- Os analistas de banco de dados podem extrair os dados de múltiplas fontes. Isto é seguido pela limpeza, integração e preparação dos dados para análise. Para os analistas de banco de dados, ter a capacidade de colaborar em conjuntos de dados e consultas sem ter que confiar na TI para acesso é um requisito integral.
- Os desenvolvedores de bancos de dados precisam de ferramentas que lhes permitam escrever código de alta qualidade na primeira vez e mantê-lo de forma contínua. Os desenvolvedores de banco de dados valorizam ferramentas de colaboração e automação para programação. Isto permite que eles condensem os ciclos de desenvolvimento sem aumentar os riscos.
- Os administradores de banco de dados utilizam ferramentas desenvolvidas para acompanhar a performance e a saúde do banco de dados. Eles lidam com tarefas que vão desde desdobrar e diagnosticar obstruções de performance até executar mudanças no esquema do banco de dados.
Ao procurar no mercado por uma ferramenta de gerenciamento de banco de dados que atenda às suas exigências comerciais, você deve procurar por ferramentas que possam trazer testes, desenvolvimento de banco de dados e tarefas de implantação para o processo de entrega contínua e integração contínua, facilitando o acompanhamento do desenvolvimento de aplicativos.
Uma ferramenta eficaz de gerenciamento de banco de dados também deve permitir a visualização de dados a partir de resultados tabulares em gráficos, histogramas e gráficos, com fácil distribuição para os tomadores de decisão. Ela também deve ajudar os administradores a localizar problemas antes que eles ocorram na produção, zerando em instruções SQL e aplicativos que não se dimensionam bem com o aumento do volume de transações.
Adminer (anteriormente conhecido como phpMinAdmin) é uma ferramenta de gerenciamento de banco de dados gratuita e de código aberto que oferece toneladas de recursos úteis e uma interface de usuário (User Interface) mais elegante. Você pode facilmente implantar esta útil ferramenta de gerenciamento de banco de dados em seu servidor, e tudo que você precisa fazer é carregar seu único arquivo PHP, apontar seu navegador para ele, e fazer o login.
Usando um plugin de banco de dados
Se você quiser avaliar a qualidade de um site, não procure mais além do seu banco de dados. Cada grão de informação associado ao seu site encontra seu caminho para o seu banco de dados WordPress. Algumas delas são cruciais, enquanto outras apenas retêm você. Isso incluiria tabelas ruins, rascunhos antigos, comentários de spam. Para evitar que eles atrapalhem seu site, você precisa trazer plugins para o banco de dados WordPress.
Os plugins de banco de dados podem vir de várias formas. Alguns plugins podem ser usados para limpar o banco de dados de arquivos junky em uma base mensal ou semanal. Outros plugins podem ser alavancados para fazer backup do seu banco de dados antes de fazer mudanças, por exemplo, durante uma migração. Além de melhorar a velocidade do seu site, você pode usar plugins de banco de dados para fornecer uma experiência de usuário mais eficiente enquanto melhora suas chances de se classificar mais alto nos mecanismos de busca.
Diagnosticando e reparando o seu banco de dados
Como um usuário do WordPress, você provavelmente já teve sua corrida com alguns erros de WordPress irritantes. Aqui está uma das mensagens de erro mais comuns que você pode ter encontrado:
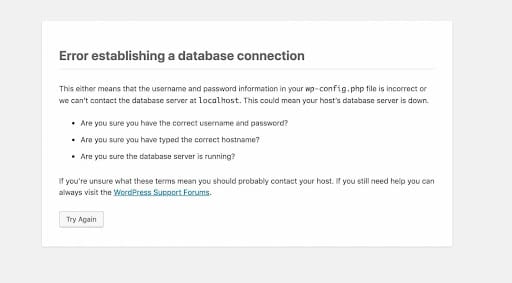
A importância de corrigir o seu banco de dados deve ser bastante óbvia. Os erros do WordPress não apenas prejudicam o bom funcionamento do seu site, mas podem ter um efeito prejudicial na experiência do consumidor. Instalações e atualizações falhadas, tempo de inatividade e recursos ausentes podem deixar uma mossa no seu potencial de ganhos e prejudicar sua credibilidade.
Resumo
PostgreSQL é um sistema de gerenciamento de banco de dados relacional gratuito e de código aberto que foca na conformidade e extensibilidade SQL. Com mais de 30 anos de desenvolvimento ativo, o PostgreSQL é uma das ferramentas de banco de dados open-source mais amplamente utilizadas em todo o mundo.
Neste artigo, cobrimos algumas das características salientes do PostgreSQL, a arquitetura do PostgreSQL, seus casos de uso, benefícios, desafios operacionais e alternativas chave. Envolvemos com algumas práticas recomendadas para manter o seu banco de dados WordPress em perfeitas condições enquanto você continua escalando.

Salman Ravoof é um desenvolvedor web autodidata, escritor, criador e grande admirador de Software Livre e de Código Aberto (FOSS). Além de tecnologia, ele se entusiasma com ciência, filosofia, fotografia, artes, gatos e comida. Saiba mais sobre ele em seu site e conecte-se com Salman no X.


{kind=link}