
No mundo atual, orientado por dados, em que o volume e a complexidade dos dados continuam a se expandir em um ritmo sem precedentes, a necessidade de soluções de bancos de dados robustas e dimensionáveis tornou-se fundamental. Estima-se que 180 zettabytes de dados serão criados até 2025, um número difícil até de imaginar.
À medida que os dados e a demanda dos usuários crescem exponencialmente, confiar em um banco de dados hospedado em um único local se torna impraticável. Isso faz o sistema ficar mais lento e sobrecarrega os desenvolvedores. Mas você pode adotar várias soluções para otimizar seu banco de dados, como o sharding — a fragmentação do banco de dados.
Neste guia completo, exploraremos em detalhes o MongoDB Sharding. Vamos esclarecer seus benefícios, componentes, práticas recomendadas e erros comuns, além de mostrar como você pode dar os primeiros passos.
O que é sharding de banco de dados?
Sharding de banco de dados é uma técnica de gerenciamento de banco de dados que envolve a divisão horizontal de um banco de dados em crescimento em unidades menores e mais gerenciáveis, conhecidas como fragmentos (shards).
À medida que seu banco de dados se expande, torna-se prático dividi-lo em várias partes menores e armazenar cada parte separadamente em diferentes máquinas. Essas partes menores, ou shards, são subconjuntos independentes do banco de dados total. Esse processo de dividir e distribuir dados é o que constitui o sharding de banco de dados.
Ao implementar um banco de dados fragmentado (sharded), existem duas abordagens principais: desenvolver uma solução de sharding personalizada ou pagar por uma já existente. Isso levanta a questão de qual é mais adequado: construir uma solução fragmentada ou pagar por uma.

Para fazer essa escolha, você precisa considerar o custo da integração com terceiros, tendo em mente os seguintes fatores:
- Habilidades do desenvolvedor e capacidade de aprendizado: A curva de aprendizado associada ao produto e quanto ele se alinha com as habilidades de seus desenvolvedores.
- O modelo de dados e a API oferecidos pelo sistema: Cada sistema de dados tem sua própria maneira de representar os dados. A conveniência e a facilidade com que você pode integrar seus aplicativos ao produto é um fator importante a ser considerado.
- Suporte ao cliente e documentação on-line: Nos casos em que você pode encontrar desafios ou precisar de assistência durante a integração, a qualidade e a disponibilidade do suporte ao cliente e uma documentação on-line abrangente se tornam cruciais.
- Disponibilidade de implantação na nuvem: À medida que mais empresas fazem a transição para a nuvem, é importante determinar se o produto de terceiros pode ser implantado em um ambiente de nuvem.
Com base nesses fatores, você pode decidir entre criar uma solução de sharding ou pagar por uma solução que faça o trabalho pesado por você.
Atualmente a maioria dos bancos de dados disponíveis no mercado suporta o sharding de banco de dados. Por exemplo, bancos de dados relacionais como o MariaDB (parte da pilha de servidores de alta performance na Kinsta) e bancos de dados NoSQL como o MongoDB.
O que é o MongoDB Sharding?
O principal objetivo do uso de um banco de dados NoSQL é sua capacidade de lidar com os requisitos de computação e armazenamento que envolvem os processos de consulta e armazenamento de enormes volumes de dados.
Em geral, um banco de dados MongoDB contém um grande número de coleções. Cada coleção consiste em vários documentos que contêm dados na forma de pares de valores-chave. Você pode dividir essa grande coleção em várias coleções menores usando o MongoDB Sharding. Isso permite que o MongoDB realize consultas sem sobrecarregar muito o servidor.
Por exemplo, a Telefónica Tech gerencia mais de 30 milhões de dispositivos IoT em todo o mundo. Para acompanhar o uso cada vez maior dos dispositivos, eles precisavam de uma plataforma que pudesse ser dimensionada de forma elástica e gerenciar um ambiente de dados em rápido crescimento. A tecnologia do MongoDB Sharding foi a escolha certa para eles, pois era a mais adequada às suas necessidades de custo e capacidade.
Com o MongoDB Sharding, a Telefónica Tech executa bem mais de 115.000 consultas por segundo. Isso equivale a 30.000 inserções no banco de dados por segundo, com menos de um milésimo de segundo de latência!
Benefícios do MongoDB Sharding
Aqui estão alguns benefícios do MongoDB Sharding para dados em grande escala que você pode aproveitar:
Capacidade de armazenamento
Já vimos que a fragmentação espalha os dados entre os fragmentos (shards) do cluster. Essa distribuição permite que cada fragmento contenha um pedaço dos dados totais do cluster. Fragmentos extras podem aumentar a capacidade de armazenamento do cluster sob medida para o conjunto crescente de dados.
Leituras/escritas
O MongoDB distribui a carga de trabalho de leitura e gravação entre os fragmentos em um cluster fragmentado, permitindo que cada fragmento processe um subconjunto das operações do cluster. Ambas as cargas de trabalho podem ser dimensionadas horizontalmente no cluster adicionando-se mais fragmentos.
Alta disponibilidade
A implantação de fragmentos e servidores de configuração como conjuntos de réplicas oferece maior disponibilidade. Agora, mesmo que um ou mais conjuntos de réplicas de fragmentos fiquem completamente indisponíveis, o cluster fragmentado pode executar leituras e gravações parciais.
Proteção contra interrupção
Distribuição geográfica e desempenho
Os fragmentos replicados podem ser colocados em diferentes regiões. Isso permite fornecer aos clientes acesso com baixa latência aos seus dados, ou seja, redirecionar as solicitações dos consumidores para o fragmento localizado na região mais próxima deles. De acordo com a política de governança de dados de uma região específica, pode-se configurar fragmentos específicos para serem alojados nessa região.
Componentes dos clusters fragmentados do MongoDB
1. Shard (Fragmento)
Cada shard possui um subconjunto dos dados fragmentados. A partir do MongoDB 3.6, os shards devem ser implantados como um conjunto de réplicas para garantir alta disponibilidade e redundância.
Cada banco de dados no cluster fragmentado possui um shard primário que conterá todas as coleções não fragmentadas desse banco de dados. O shard primário não está relacionado ao primário em um conjunto de réplicas.
Para alterar o shard primário de um banco de dados, você pode usar o comando movePrimary. O processo de migração do shard primário pode levar um tempo considerável para ser concluído.
Durante esse tempo, não é recomendado tentar acessar as coleções associadas ao banco de dados até que o processo de migração seja concluído. Esse processo pode impactar as operações gerais do cluster com base na quantidade de dados sendo migrados.
Você pode usar o método sh.status() no mongosh para obter uma visão geral do cluster. Este método retornará o shard primário para o banco de dados, juntamente com a distribuição de chunks pelos
2. Servidores de configuração
A implantação de servidores de configuração para clusters fragmentados como conjuntos de réplicas pode melhorar a consistência no servidor de configuração. Isso ocorre porque o MongoDB pode aproveitar os protocolos padrão de leitura e gravação do conjunto de réplicas para os dados de configuração.
Para implementar servidores de configuração como um conjunto de réplicas, você terá de executar o mecanismo de armazenamento WiredTiger. O WiredTiger usa controle de simultaneidade no nível do documento para as operações de gravação. Assim, vários clientes podem modificar diferentes documentos de uma coleção ao mesmo tempo.
Os servidores de configuração armazenam os metadados de um cluster fragmentado no banco de dados de configuração. Para acessar o banco de dados de configuração, você pode usar o seguinte comando no shell do MongoDB:
use configAqui estão algumas restrições que você deve ter em mente:
- Uma configuração de conjunto de réplicas usada para servidores de configuração deve ter zero árbitro. Um árbitro participa de uma eleição para o primário, mas não tem uma cópia do conjunto de dados e não pode se tornar o primário.
- Esse conjunto de réplicas não pode ter nenhum membro atrasado. Os membros atrasados têm cópias do conjunto de dados do conjunto de réplicas. Mas o conjunto de dados de um membro atrasado contém um estado anterior ou atrasado do conjunto de dados.
- Você precisa criar índices para os servidores de configuração. Em termos simples, nenhum membro deve ter a configuração
members[n].buildIndexesdefinida comofalse.
Se o conjunto de réplicas do servidor de configuração perder seu membro principal e não puder eleger um, os metadados do cluster se tornarão somente leitura. Você ainda poderá ler e gravar nos fragmentos, mas não haverá divisão de partes ou migração até que o conjunto de réplicas possa eleger um primário.
3. Roteadores de consulta
As instâncias mongos do MongoDB podem servir como roteadores de consulta, permitindo que os aplicativos clientes e os clusters fragmentados se conectem facilmente.
A partir do MongoDB 4.4, mongos suporta consultas cobertas para diminuir as latências. Com isso, as instâncias mongos enviarão operações de leitura para dois membros do conjunto de réplicas para cada fragmento consultado. E então retornarão os resultados do primeiro respondente por fragmento.
Veja como os três componentes interagem em um cluster fragmentado:
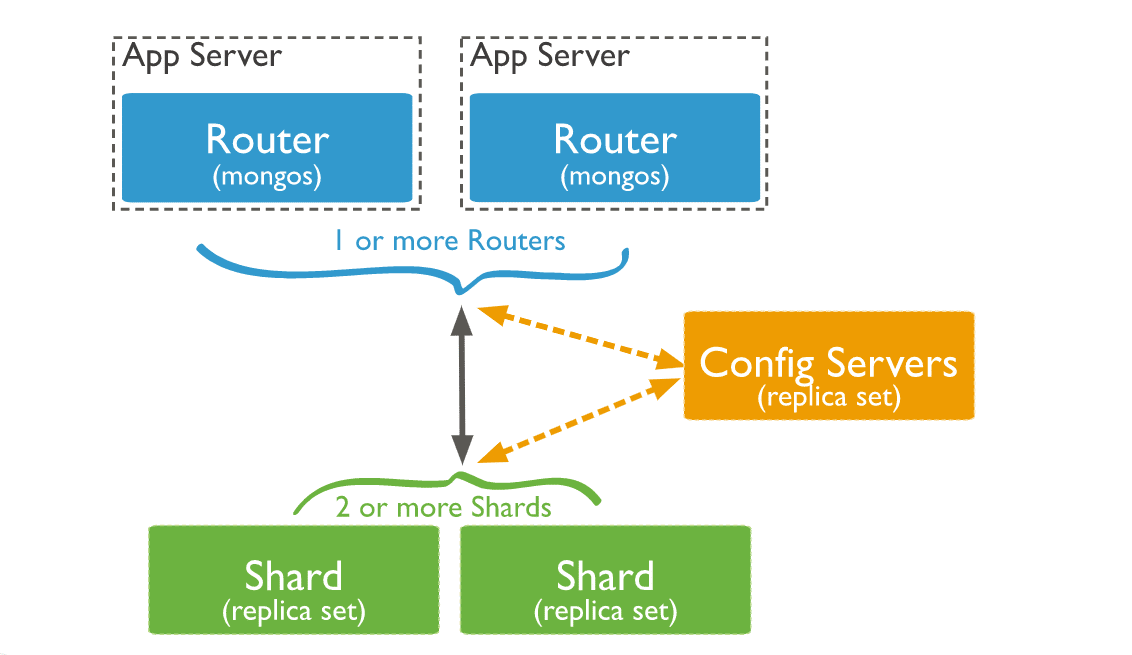
Uma instância mongos direcionará uma consulta a um cluster por:
- Verificando a lista de shards que precisam receber a consulta.
- Estabelecendo um cursor em todos os shards alvo.
Em seguida, o mongos mesclará os dados de cada fragmento alvo e retornará o documento resultante. Alguns modificadores de consulta, como classificação, são executados em cada fragmento antes que o mongos recupere os resultados.
Em alguns casos, quando a chave de fragmento (shard key) ou um prefixo de chave de fragmento fizer parte da consulta, o mongos executará uma operação pré-planejada, apontando as consultas para uma subclasse de fragmentos no cluster.
Para um cluster de produção, garanta que os dados sejam redundantes e que seus sistemas estejam altamente disponíveis. Você pode escolher a seguinte configuração para uma implantação de um cluster de produção fragmentado:
- Implantar cada shard como um conjunto de réplicas de 3 membros.
- Implantar servidores de configuração como um conjunto de réplicas de 3 membros.
- Implantar um ou mais roteadores mongos.
Para um cluster que não seja de produção, você pode implantar um cluster fragmentado com os seguintes componentes:
- Um único conjunto de réplicas de shard.
- Um servidor de configuração de conjunto de réplicas
- Uma instância mongos
Como funciona o Sharding no MongoDB?
Agora que já discutimos os diferentes componentes de um cluster fragmentado, é hora de nos aprofundarmos no processo.
Para dividir os dados em vários servidores, você usará “mongos”. Quando você se conectar para enviar as consultas ao MongoDB, o mongos procurará e descobrirá onde os dados residem. Em seguida, ele os obterá do servidor certo e mesclará tudo, caso tenham sido divididos em vários servidores.
Como isso será feito no backend, você não precisará fazer nada no lado do aplicativo. O MongoDB agirá como se fosse uma conexão de consulta normal. Seu cliente se conectará ao mongos, e o servidor de configuração cuidará do resto.
Como configurar o MongoDB Sharding passo a passo?
Configurar o sharding no MongoDB é um processo que envolve várias etapas para garantir um cluster do banco de dados estável e eficiente. Aqui estão instruções detalhadas passo a passo sobre como configurar o sharding no MongoDB.
Antes de começarmos, é importante observar que para configurar o sharding no MongoDB, você precisará de pelo menos três servidores: um para o servidor de configuração, um para a instância mongos e um ou mais para os shards.
1. Crie um diretório a partir do servidor de configuração
Para começar, criaremos um diretório para os dados do servidor de configuração. Você pode fazer isso executando o seguinte comando no primeiro servidor:
mkdir /data/configdb2. Inicie o MongoDB no modo de configuração
Em seguida, iniciaremos o MongoDB no modo de configuração no primeiro servidor usando o seguinte comando:
mongod --configsvr --dbpath /data/configdb --port 27019Isso iniciará o servidor de configuração em port 27019 e armazenará seus dados no diretório /data/configdb. Observe que estamos usando o sinalizador --configsvr para indicar que esse servidor será usado como um servidor de configuração.
3. Inicie a instância mongos
A próxima etapa é iniciar a instância mongos. Esse processo encaminhará as consultas para os fragmentos corretos com base na chave de fragmentação. Para iniciar a instância mongos, use o seguinte comando:
mongos --configdb <config server>:27019Substitua <config server> pelo endereço IP ou nome do host da máquina em que o servidor de configuração está sendo executado.
4. Conecte à instância mongos
Quando a instância mongos estiver em execução, você poderá se conectar a ela usando o shell do MongoDB. Você pode fazer isso executando o seguinte comando:
mongo --host <mongos-server> --port 27017Nesse comando, <mongos-server> deve ser substituído pelo nome do host ou endereço IP do servidor que está executando a instância mongos. Isso abrirá o shell do MongoDB, permitindo que você interaja com a instância mongos e adicione servidores ao cluster.
Substitua<mongos-server> pelo endereço IP ou nome do host da máquina onde a instância mongos está sendo executada.
5. Adicione servidores aos clusters
Agora que estamos conectados à instância mongos, podemos adicionar servidores ao cluster executando o seguinte comando:
sh.addShard("<shard-server>:27017")Nesse comando, <shard-server> deve ser substituído pelo nome do host ou endereço IP do servidor que executa o fragmento. Esse comando adicionará o fragmento ao cluster e o tornará disponível para uso.
Repita essa etapa para cada fragmento que você deseja adicionar ao cluster.
6. Habilite a fragmentação para o banco de dados
Finalmente, habilitaremos o sharding para um banco de dados executando o seguinte comando:
sh.enableSharding("<database>")Nesse comando, <database> deve ser substituído pelo nome do banco de dados que você deseja fragmentar. Isso habilitará o sharding para o banco de dados escolhido, permitindo distribuir seus dados por vários shards.
E é isso! Seguindo essas etapas, você deve ter um cluster fragmentado no MongoDB totalmente funcional, pronto para escalar horizontalmente e lidar com cargas de tráfego elevado.
Melhores práticas para o sharding no MongoDB
Embora tenhamos configurado nosso cluster fragmentado, é essencial monitorar e manter o cluster regularmente para garantir o desempenho ideal. Algumas das melhores práticas para o sharding no MongoDB incluem:
1. Determine a chave de fragmento correta
A chave de fragmento (shard key) é um fator crítico na fragmentação do MongoDB que determina como os dados são distribuídos entre os fragmentos. É importante que você escolha uma chave de fragmento que distribua uniformemente os dados entre os fragmentos e ofereça suporte às consultas mais comuns. Você deve evitar escolher uma chave de fragmento que cause hotspots ou distribuição desigual de dados, pois isso pode levar a problemas de desempenho.
Para escolher a chave de fragmento correta, você deve analisar seus dados e os tipos de consultas que realizará e selecionar uma chave que atenda a esses requisitos.
2. Planeje o crescimento dos dados
Ao configurar o cluster fragmentado, planeje o crescimento futuro, começando com fragmentos suficientes para lidar com a carga de trabalho atual e adicionando mais conforme necessário. Certifique-se de que sua infraestrutura de hardware e rede possa suportar o número de fragmentos e a quantidade de dados que você espera ter no futuro.
3. Use hardware dedicado para os fragmentos
Use hardware dedicado para cada fragmento para obter desempenho e confiabilidade ideais. Cada fragmento deve ter seu próprio servidor ou máquina virtual, para que possa utilizar todos os recursos sem nenhuma interferência.
O uso de hardware compartilhado pode levar à contenção de recursos e à degradação do desempenho, afetando a confiabilidade geral do sistema.
4. Use conjuntos de réplicas para servidores de fragmentos
O uso de conjuntos de réplicas para servidores de fragmentos fornece alta disponibilidade e tolerância a falhas para seu cluster de fragmentos do MongoDB. Cada conjunto de réplicas deve ter três ou mais membros, e cada membro deve residir em uma máquina física separada. Essa configuração garante que seu cluster fragmentado possa sobreviver à falha de um único servidor ou membro do conjunto de réplicas.
5. Monitore o desempenho dos fragmentos
Monitorar o desempenho de seus fragmentos é fundamental para identificar problemas antes que eles se tornem graves. Você deve monitorar o CPU, a memória, o E/S do disco e o E/S da rede de cada servidor de fragmentos para garantir que o fragmento possa lidar com a carga de trabalho.
Você pode usar as ferramentas de monitoramento integradas do MongoDB, como mongostat e mongotop, ou ferramentas de monitoramento de terceiros, como Datadog, Dynatrace e Zabbix, para rastrear o desempenho dos fragmentos.
6. Planeje a recuperação de desastres
Planejar a recuperação de desastres é essencial para manter a confiabilidade do seu cluster fragmentado no MongoDB. Você deve ter um plano de recuperação de desastres que inclua backups regulares, testes de backups para garantir que sejam válidos e um plano para restaurar os backups em caso de falha.
7. Use o sharding baseado em hash quando for apropriado
Quando os aplicativos realizam consultas baseadas em intervalos, o sharding de intervalo é benéfico porque as operações podem ser limitadas a poucos shards, na maioria das vezes um único shard. Você precisa entender seus dados e os padrões de consulta para implementar isso.
O sharding baseado em hash garante uma distribuição uniforme de leituras e gravações. No entanto, ele não oferece operações eficientes baseadas em intervalos.
Quais são os erros comuns que você deve evitar ao fragmentar seu banco de dados MongoDB?
O sharding no MongoDB é uma técnica poderosa que pode ajudá-lo a escalar seu banco de dados horizontalmente e distribuir dados em vários servidores. No entanto, existem vários erros comuns que você deve evitar ao fragmentar seu banco de dados MongoDB. Abaixo estão alguns dos erros mais comuns e como evitá-los.
1. Escolher a chave de fragmento errada
Uma das decisões mais importantes que você tomará ao fragmentar seu banco de dados MongoDB é escolher a chave de fragmento. Ela determina como os dados são distribuídos entre os fragmentos, e a escolha da chave errada pode resultar em distribuição desigual de dados, hotspots e desempenho ruim.
Um erro comum é escolher um valor de chave de fragmento que aumenta para novos documentos somente ao usar a fragmentação baseada em intervalo, mas não para a fragmentação com hash. Por exemplo, um timestamp (naturalmente), ou qualquer coisa que tenha um componente de tempo como seu componente mais importante, como ObjectID (os primeiros quatro bytes são um timestamp).
Se você selecionar uma chave de fragmento, todas as inserções irão para o bloco com o maior intervalo. Mesmo que você continue adicionando novos fragmentos, sua capacidade máxima de gravação nunca aumentará.
Se você planeja escalonar a capacidade de gravação, tente usar uma chave de fragmento baseada em hash, o que permitirá o uso do mesmo campo e, ao mesmo tempo, proporcionará uma boa escalabilidade de gravação.
2. Tentativa de alterar o valor da chave de fragmento
As chaves de fragmento são imutáveis para um documento existente, o que significa que você não pode alterar a chave. Você pode fazer determinadas atualizações antes da fragmentação, mas não depois. Se tentar modificar a chave de fragmento de um documento existente, ocorrerá uma falha com o seguinte erro:
cannot modify shard key's value fieldid for collection: collectionnameVocê pode remover e reinserir o documento para renovar a chave de fragmento, em vez de tentar alterá-la.
3. Falha ao monitorar o cluster
O sharding introduz complexidade adicional ao ambiente de banco de dados, tornando essencial o monitoramento cuidadoso do cluster. A falha em monitorar o cluster pode levar a problemas de desempenho, perda de dados e outros problemas.
Para evitar esse erro, você deve configurar ferramentas de monitoramento para rastrear as principais métricas, como uso do CPU, uso da memória, espaço em disco e tráfego de rede. Também configure alertas para quando determinados limites forem excedidos.
4. Esperar demais para adicionar um novo shard (Sobrecarregado)
Um erro comum a evitar ao fragmentar seu banco de dados MongoDB é esperar demais para adicionar um novo shard. Quando um shard fica sobrecarregado com dados ou consultas, isso pode levar a problemas de desempenho e desacelerar todo o cluster.
Suponha que você tenha um cluster imaginário consistindo de 2 shards, com 20000 chunks (5000 considerados “ativos”), e precisamos adicionar um 3º shard. Este 3º shard eventualmente armazenará um terço dos chunks ativos (e do total de chunks).
O desafio é descobrir quando o shard deixa de adicionar sobrecarga e se torna um ativo. Seria necessário calcular a carga que o sistema produziria ao migrar os chunks ativos para o novo shard e quando ela seria insignificante comparada ao ganho geral do sistema.
Na maioria dos cenários, é relativamente fácil imaginar esse conjunto de migrações levando ainda mais tempo em um conjunto de shards sobrecarregado e demorando muito mais para que nosso shard recém-adicionado atravesse o limiar e se torne um ganho líquido. Como tal, é melhor ser proativo e adicionar capacidade antes que se torne necessário.
5. Servidores de configuração com provisionamento insuficiente
Se os servidores de configuração estiverem com recursos insuficientes, isso pode levar a problemas de desempenho e instabilidade. A subprovisão pode ocorrer devido à alocação insuficiente de recursos, como CPU, memória ou armazenamento.
Isso pode resultar em desempenho lento de consultas, timeouts e até mesmo falhas do sistema. Para evitar isso, é essencial alocar recursos suficientes para os servidores de configuração, especialmente em clusters maiores. Monitorar regularmente o uso de recursos dos servidores de configuração pode ajudar a identificar problemas de subprovisão.
Outra maneira de evitar isso é usar hardware dedicado para os servidores de configuração, em vez de compartilhar recursos com outros componentes do cluster. Isso pode ajudar a garantir que os servidores de configuração tenham recursos suficientes para lidar com sua carga de trabalho.
6. Falha no backup e na restauração de dados
Os backups são essenciais para garantir que os dados não sejam perdidos em uma falha. A perda de dados pode ocorrer por vários motivos, inclusive falha de hardware, erro humano e ataques mal-intencionados.
Se você não fizer o backup e a restauração dos dados, poderá ter perda de dados e tempo de inatividade. Para evitar esse erro, você deve definir uma estratégia de backup e restauração que inclua backups regulares, backups de teste e restauração de dados em um ambiente de teste.
7. Falha ao testar o cluster fragmentado
Antes de implementar o cluster fragmentado na produção, você deve testá-lo completamente para garantir que possa lidar com a carga e as consultas esperadas. Se você não testar o cluster fragmentado, poderá ter um desempenho ruim e falhas.
MongoDB Sharding vs Índices Clusterizados: Qual é mais eficaz para grandes conjuntos de dados?
Tanto o MongoDB Sharding quanto os índices em cluster são estratégias eficazes para lidar com grandes conjuntos de dados. Mas eles servem a propósitos diferentes. A escolha da abordagem correta depende dos requisitos específicos do seu aplicativo.
O sharding é uma técnica de escalonamento horizontal que distribui dados entre vários nós, tornando-se uma solução eficaz para lidar com grandes conjuntos de dados com altas taxas de escrita. É transparente para os aplicativos, permitindo que interajam com o MongoDB como se fosse um único servidor.
Por outro lado, os índices agrupados melhoram o desempenho das consultas que recuperam dados de grandes conjuntos de dados, permitindo que o MongoDB localize os dados com mais eficiência quando uma consulta corresponde ao campo indexado.
Então, qual deles é mais eficaz para conjuntos de dados maiores? A resposta depende do uso específico e dos requisitos da carga de trabalho.
Se o aplicativo requer alta taxa de escrita e consulta e precisa escalar horizontalmente, então o sharding do MongoDB provavelmente é a opção melhor.
Tanto a fragmentação quanto os índices agrupados são ferramentas poderosas para gerenciar grandes conjuntos de dados no MongoDB. O segredo é avaliar cuidadosamente os requisitos do seu aplicativo e as características da carga de trabalho para determinar a melhor abordagem para o seu uso específico.
Resumo
Ao aproveitar o poder da fragmentação, os aplicativos podem obter alta disponibilidade, melhor desempenho e uso eficiente dos recursos de hardware. A escolha da chave de fragmento correta é fundamental para a distribuição uniforme dos dados.
O que você acha do MongoDB e da prática de fragmentação do banco de dados? Há algum aspecto da fragmentação que você acha que deveríamos ter abordado? Diga-nos nos comentários!


