
À medida que o desenvolvimento de aplicativos evolui, os bancos de dados permanecem sendo o núcleo da maioria dos aplicativos, armazenando e gerenciando dados cruciais para os negócios digitais. E quando esses dados crescem e se tornam mais complexos, garantir a eficiência do seu banco de dados é vital para atender às necessidades do seu aplicativo.
E é aí que entra em cena a ideia da manutenção do banco de dados, que envolve tarefas como limpeza, backups e otimização de índices para turbinar o desempenho.
Este artigo oferece ideias valiosas sobre gatilhos de manutenção e apresenta instruções práticas de configuração. E explica o processo de implementação de várias tarefas de manutenção do banco de dados, como backup de dados, reconstrução de índices, arquivamento e limpeza de dados usando PostgreSQL, integrado a um gatilho de API em um aplicativo Node.js.
Entendendo os gatilhos
Antes de realizar operações de manutenção no seu banco de dados, é importante entender as diversas formas como elas podem ser acionadas. Cada gatilho serve a propósitos distintos para facilitar as tarefas de manutenção. Os três principais gatilhos comumente usados são:
- Manual, baseado em API: Esse gatilho permite executar operações pontuais usando uma chamada de API. É útil em situações como a restauração de um backup de banco de dados ou a reconstrução de índices quando o desempenho cai repentinamente.
- Agendamento (como o CRON): Esse gatilho permite automatizar atividades de manutenção programadas durante períodos de baixo tráfego de usuários. É ideal para executar operações com uso intensivo de recursos, como arquivamento e limpeza. Você pode usar pacotes como node-schedule para configurar agendamentos no Node.js que acionam operações automaticamente quando necessário.
- Notificações de banco de dados: Esse gatilho permite executar operações de manutenção como resposta a alterações no banco de dados. Por exemplo, quando um usuário publica um comentário em uma plataforma, os dados salvos podem acionar instantaneamente verificações de caracteres irregulares, linguagem ofensiva ou emojis. Você pode implementar essa funcionalidade no Node.js usando pacotes como o pg-listen.
Pré-requisitos
Para seguir este guia, você deve ter as seguintes ferramentas em seu computador local:
- Git: Para gerenciar o controle de versão do código-fonte do seu aplicativo
- Node.js: para criar seu aplicativo de backend
- psql: Para interagir com seu banco de dados PostgreSQL remoto usando seu terminal
- PGAdmin (opcional): Para interagir com seu banco de dados PostgreSQL remoto usando uma interface gráfica de usuário (GUI).
Criação e hospedagem de um aplicativo Node.js
Vamos configurar um projeto Node.js, fazer o commit dele para o GitHub e configurar um pipeline de implantação automática na Kinsta. Você também precisa provisionar um banco de dados PostgreSQL na Kinsta para testar suas rotinas de manutenção nele.
Comece criando um novo diretório em seu sistema local usando o seguinte comando:
mkdir node-db-maintenanceEm seguida, vá para a pasta recém-criada e execute o seguinte comando para criar um novo projeto:
cd node-db-maintenance
yarn init -y # or npm init -yIsso inicializa um projeto Node.js para você com a configuração padrão. Agora você pode instalar as dependências necessárias executando o seguinte comando:
yarn add express pg nodemon dotenvAqui está uma rápida descrição de cada pacote:
express: permite que você configure uma API REST baseada em Express.pg: permite que você interaja com um banco de dados PostgreSQL por meio do seu aplicativo Node.js.nodemon: permite que a sua build de desenvolvimento seja atualizada à medida que você desenvolve o aplicativo, liberando-o da necessidade constante de parar e iniciar o aplicativo cada vez que fizer uma alteração.dotenv: permite carregar variáveis de ambiente de um arquivo .env para seu objetoprocess.env.
Em seguida, adicione os seguintes scripts ao seu arquivo package.json para poder iniciar seu servidor de desenvolvimento com facilidade, bem como executar o seu servidor em produção:
{
// ...
"scripts": {
"start-dev": "nodemon index.js",
"start": "NODE_ENV=production node index.js"
},
// …
}Agora você pode criar um arquivo index.js que contém o código-fonte do seu aplicativo. Cole o seguinte código no arquivo:
const express = require("express")
const dotenv = require('dotenv');
if (process.env.NODE_ENV !== 'production') dotenv.config();
const app = express()
const port = process.env.PORT || 3000
app.get("/health", (req, res) => res.json({status: "UP"}))
app.listen(port, () => {
console.log(`Server running at port: ${port}`);
});O código acima inicializa um servidor Express e configura variáveis de ambiente usando o pacote dotenv se não estiver no modo de produção. Também configura um caminho /health que retorna um objeto JSON {status: "UP"}. Por fim, inicia o aplicativo usando a função app.listen() para escutar na porta especificada, com o padrão 3000 se nenhuma porta for fornecida por meio da variável de ambiente.
Agora que você tem um aplicativo básico pronto, inicialize um novo repositório git com seu provedor git de preferência (BitBucket, GitHub ou GitLab) e envie seu código. A Kinsta suporta a implantação de aplicativos de todos esses provedores git. Para este artigo, vamos usar o GitHub.
Quando seu repositório estiver pronto, siga estes passos para implantar seu aplicativo na Kinsta:
- Faça login ou crie uma conta para visualizar seu painel MyKinsta.
- Autorize a Kinsta com seu provedor Git.
- Na barra lateral esquerda, clique em Aplicativos, e daí em Adicionar aplicativo.
- Selecione o repositório e o branch do qual você deseja implantar.
- Selecione um dos locais de centros de dados disponíveis na lista de 29 opções. A Kinsta detecta automaticamente as configurações de build para seus aplicativos por meio do Nixpacks.
- Escolha os recursos do aplicativo, como RAM e espaço em disco.
- Clique em Criar aplicativo.
Quando a implantação estiver concluída, copie o link do aplicativo implantado e navegue até /health. Você deverá ver o seguinte JSON em seu navegador:
{status: "UP"}Isso indica que o aplicativo foi configurado corretamente.
Configuração de uma instância do PostgreSQL na Kinsta
A Kinsta fornece uma interface fácil para você provisionar instâncias de banco de dados. Comece criando uma nova conta na Kinsta, se você ainda não tiver uma. Em seguida, siga as etapas abaixo:
- Faça login em seu painel MyKinsta.
- Na barra lateral esquerda, clique em Bancos de dados, e então em Adicionar banco de dados.
- Selecione PostgreSQL como o tipo de banco de dados e escolha a versão que preferir. Escolha um nome para o seu banco de dados e modifique o nome de usuário e a senha, se desejar.
- Selecione um local de centro de dados na lista de 29 opções.
- Escolha o tamanho do seu banco de dados.
- Clique em Criar banco de dados.
Depois que o banco de dados for criado, certifique-se de recuperar o host, a porta, o nome de usuário e a senha do banco de dados.
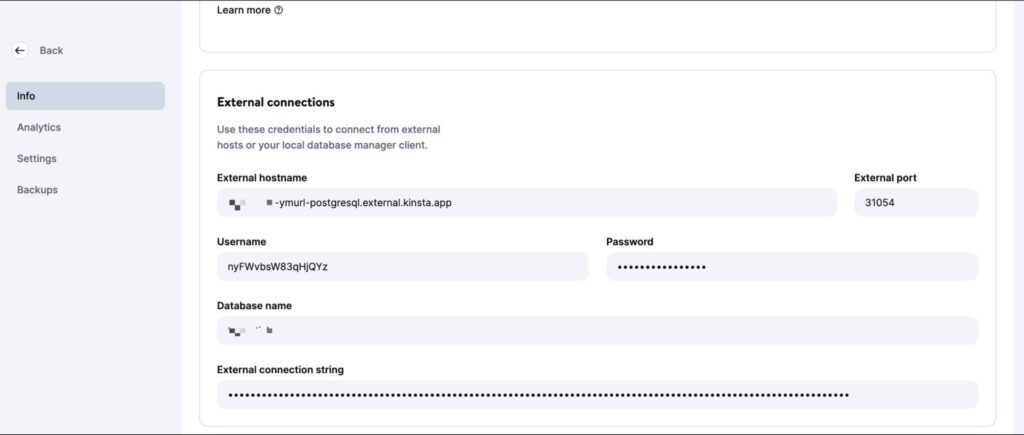
Você pode então inserir esses valores na sua CLI do psql (ou na interface do PGAdmin) para gerenciar o banco de dados. Para testar seu código localmente, crie um arquivo .env no diretório raiz do seu projeto e armazene os seguintes segredos nele:
DB_USER_NAME=your database user name
DB_HOST=your database host
DB_DATABASE_NAME=your database’s name
DB_PORT=your database port
PGPASS=your database passwordAo fazer a implantação na Kinsta, você precisa adicionar esses valores como variáveis de ambiente para a implantação do seu aplicativo.
Para preparar as operações de banco de dados, baixe e execute este script SQL para criar tabelas (usuários, publicações, comentários) e inserir dados de amostra. Use o comando abaixo, substituindo os espaços reservados por seus dados específicos, para adicionar os dados ao seu banco de dados PostgreSQL recém-criado:
psql -h <host> -p <port> -U <username> -d <db_name> -a -f <sql file e.g. test-data.sql>Certifique-se de inserir o nome e o caminho exatos do arquivo no comando acima. A execução desse comando solicita que você digite a senha do banco de dados para obter autorização.
Quando esse comando terminar de ser executado, você estará pronto para começar a escrever operações para a manutenção do seu banco de dados. Sinta-se à vontade para enviar seu código para o seu repositório Git quando terminar cada operação para vê-lo em ação na plataforma da Kinsta.
Escrevendo rotinas de manutenção
Esta seção explica várias operações comumente usadas para a manutenção de bancos de dados PostgreSQL.
1. Criação de backups
O backup regular de bancos de dados é uma operação comum e essencial. Envolve criar uma cópia de todo o conteúdo do banco de dados, e armazená-la em um local seguro. Esses backups são cruciais para restaurar os dados em caso de perda acidental ou erros que afetem a integridade dos dados.
Embora plataformas como a Kinsta ofereçam backups automatizados como parte de seus serviços, é importante saber como configurar uma rotina de backup personalizada, se necessário.
O PostgreSQL oferece a ferramenta pg_dump para criar backups de banco de dados. No entanto, ela precisa ser executada diretamente da linha de comando, e não há um pacote npm para ela. De modo que você precisa usar o pacote @getvim/execute para executar o comando pg_dump no ambiente local do seu aplicativo Node.
Instale o pacote executando o seguinte comando:
yarn add @getvim/executeEm seguida, importe o pacote em seu arquivo index.js adicionando esta linha de código na parte superior:
const {execute} = require('@getvim/execute');Os backups são gerados como arquivos no sistema de arquivos local do seu aplicativo Node. Assim, é melhor criar um diretório dedicado para eles com o nome backup no diretório raiz do projeto.
Agora, você pode usar o seguinte caminho para gerar e baixar backups do seu banco de dados quando necessário:
app.get('/backup', async (req, res) => {
// Create a name for the backup file
const fileName = "database-backup-" + new Date().valueOf() + ".tar";
// Execute the pg_dump command to generate the backup file
execute("PGPASSWORD=" + process.env.PGPASS + " pg_dump -U " + process.env.DB_USER_NAME
+ " -d " + process.env.DB_DATABASE_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -f backup/" + fileName + " -F t"
).then(async () => {
console.log("Backup created");
res.redirect("/backup/" + fileName)
}).catch(err => {
console.log(err);
res.json({message: "Something went wrong"})
})
})Além disso, você precisa adicionar a seguinte linha no início do seu arquivo index.js depois que o aplicativo Express for inicializado:
app.use('/backup', express.static('backup'))Isso permite que a pasta backup seja servida estaticamente usando a função de middleware express.static, permitindo que o usuário baixe os arquivos de backup gerados a partir do aplicativo Node.
2. Restauração a partir de um backup
O Postgres permite a restauração de backups usando a ferramenta de linha de comando pg_restore. No entanto, você precisa usá-la por meio do pacote execute, da mesma forma que usou o comando pg_dump. Aqui está o código do caminho:
app.get('/restore', async (req, res) => {
const dir = 'backup'
// Sort the backup files according to when they were created
const files = fs.readdirSync(dir)
.filter((file) => fs.lstatSync(path.join(dir, file)).isFile())
.map((file) => ({ file, mtime: fs.lstatSync(path.join(dir, file)).mtime }))
.sort((a, b) => b.mtime.getTime() - a.mtime.getTime());
if (!files.length){
res.json({message: "No backups available to restore from"})
}
const fileName = files[0].file
// Restore the database from the chosen backup file
execute("PGPASSWORD=" + process.env.PGPASS + " pg_restore -cC "
+ "-U " + process.env.DB_USER_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -d postgres backup/" + fileName
)
.then(async ()=> {
console.log("Restored");
res.json({message: "Backup restored"})
}).catch(err=> {
console.log(err);
res.json({message: "Something went wrong"})
})
})O snippet de código acima procura primeiro os arquivos armazenados no diretório backup local. Em seguida, classifica-os pelas datas em que foram criados para localizar o arquivo de backup mais recente. Por fim, usa o pacote execute para restaurar o arquivo de backup escolhido.
Certifique-se de adicionar as seguintes importações ao seu arquivo index.js de forma que os módulos necessários para acessar o sistema de arquivos local sejam importados, permitindo que a função seja executada corretamente:
const fs = require('fs')
const path = require('path')3. Reconstrução de um índice
Às vezes os índices das tabelas do Postgres ficam corrompidos, e o desempenho do banco de dados é prejudicado. Isso pode ocorrer devido a bugs ou erros de software. Além disso, os índices também podem ficar pesados devido ao excesso de páginas vazias ou quase vazias.
Nesses casos, você precisa reconstruir o índice para garantir que está obtendo o melhor desempenho da sua instância do Postgres.
O Postgres oferece o comando REINDEX para essa finalidade. Você pode usar o pacote node-postgres para executar esse comando (e também para executar algumas outras operações posteriormente); portanto, instale-o, executando primeiro o seguinte comando:
yarn add pgEm seguida, adicione as seguintes linhas à parte superior do arquivo index.js, abaixo das importações, para inicializar corretamente a conexão com o banco de dados:
const {Client} = require('pg')
const client = new Client({
user: process.env.DB_USER_NAME,
host: process.env.DB_HOST,
database: process.env.DB_DATABASE_NAME,
password: process.env.PGPASS,
port: process.env.DB_PORT
})
client.connect(err => {
if (err) throw err;
console.log("Connected!")
})A implementação dessa operação é bastante simples:
app.get("/reindex", async (req, res) => {
// Run the REINDEX command as needed
await client.query("REINDEX TABLE Users;")
res.json({message: "Reindexed table successfully"})
})O comando mostrado acima reindexa a tabela Users completa. Você pode personalizar o comando de acordo com suas necessidades para reconstruir um índice específico ou até mesmo reindexar o banco de dados completo.
4. Arquivamento e depuração de dados
Para bancos de dados que aumentam de tamanho com o tempo (e os dados históricos são acessados raramente), pode fazer sentido configurar rotinas para descarregar dados antigos em um data lake, onde podem ser armazenados e processados de forma mais conveniente.
Arquivos parquet são um padrão comum para armazenamento e transferência de dados em muitos data lakes. Usando a biblioteca ParquetJS, você pode criar arquivos parquet a partir dos dados do Postgres e usar serviços como o AWS Athena para lê-los diretamente, sem precisar carregá-los novamente no banco de dados no futuro.
Instale a biblioteca ParquetJS executando o seguinte comando:
yarn add parquetjsAo criar arquivos, você precisa consultar um grande número de registros em suas tabelas. Armazenar tal quantidade de dados na memória do aplicativo pode consumir muitos recursos, ser caro e estar sujeito a erros.
Portanto, faz sentido usar cursores para carregar pedaços de dados do banco de dados e processá-los. Instale o módulo cursors do pacote node-postgres executando o seguinte comando:
yarn add pg-cursorEm seguida, certifique-se de importar as duas bibliotecas para o seu arquivo index.js:
const Cursor = require('pg-cursor')
const parquet = require('parquetjs')Agora use o snippet de código abaixo para criar arquivos parquet a partir do seu banco de dados:
app.get('/archive', async (req, res) => {
// Query all comments through a cursor, reading only 10 at a time
// You can change the query here to meet your requirements, such as archiving records older than at least a month, or only archiving records from inactive users, etc.
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
// Define the schema for the parquet file
let schema = new parquet.ParquetSchema({
comment_id: { type: 'INT64' },
post_id: { type: 'INT64' },
user_id: { type: 'INT64' },
comment_text: { type: 'UTF8' },
timestamp: { type: 'TIMESTAMP_MILLIS' }
});
// Open a parquet file writer
let writer = await parquet.ParquetWriter.openFile(schema, 'archive/archive.parquet');
let rows = await cursor.read(10)
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// Write each row from table to the parquet file
await writer.appendRow(rows[i])
}
rows = await cursor.read(10)
}
await writer.close()
// Once the parquet file is generated, you can consider deleting the records from the table at this point to free up some space
// Redirect user to the file path to allow them to download the file
res.redirect("/archive/archive.parquet")
})Em seguida, adicione o seguinte código ao início do arquivo index.js depois que o aplicativo Express for inicializado:
app.use('/archive', express.static('archive'))Isso permite que a pasta archive seja servida estaticamente, permitindo que você baixe os arquivos parquet gerados do servidor.
Não se esqueça de criar um diretório archive no diretório do projeto para armazenar os arquivos a ser arquivados.
Você pode personalizar ainda mais esse snippet de código para carregar automaticamente os arquivos parquet para um bucket da AWS S3 e usar jobs CRON para acionar a operação automaticamente em uma rotina.
5. Limpeza de dados
Um objetivo comum da execução de operações de manutenção de banco de dados é limpar os dados que se tornam antigos ou irrelevantes com o tempo. Esta seção aborda dois casos comuns em que limpezas de dados são feitas como parte da manutenção.
Na realidade, você pode configurar sua própria rotina de limpeza de dados, conforme exigido pelos modelos de dados do seu aplicativo. Os exemplos apresentados a seguir são apenas uma referência.
Excluindo registros por idade (última modificação ou último acesso)
A limpeza de registros com base na idade é relativamente simples em comparação com outras operações desta lista. Você pode escrever uma consulta de exclusão que exclua registros anteriores a uma determinada data.
Aqui está um exemplo de exclusão de comentários feitos antes de 9 de outubro de 2023:
app.get("/clean-by-age", async (req, res) => {
// Filter and delete all comments that were made on or before 9th October, 2023
const result = await client.query("DELETE FROM COMMENTS WHERE timestamp < '09-10-2023 00:00:00'")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})Você pode experimentá-lo enviando uma solicitação GET para o caminho /clean-by-age.
Exclusão de registros com base em condições personalizadas
Você também pode configurar limpezas com base em outras condições, tais como a remoção de registros que não estejam vinculados a outros registros ativos no sistema (criando uma situação de orfandade).
Por exemplo, você pode configurar uma operação de limpeza que procure comentários vinculados a publicações excluídas e os exclua, pois eles provavelmente nunca mais aparecerão no aplicativo:
app.get('/conditional', async (req, res) => {
// Filter and delete all comments that are not linked to any active posts
const result = await client.query("DELETE FROM COMMENTS WHERE post_id NOT IN (SELECT post_id from Posts);")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})Você pode criar suas próprias condições específicas para o seu caso de uso.
6. Manipulação de dados
As operações de manutenção de banco de dados também são usadas para realizar manipulação e transformação de dados, como censura de linguagem obscena ou conversão de combinações de texto em emoji.
Diferentemente da maioria das outras operações, essas operações são melhor executadas quando ocorrem atualizações do banco de dados (em vez de executá-las em todas as linhas em um horário fixo da semana ou do mês).
Esta seção lista duas dessas operações, mas a implementação de qualquer outra operação de manipulação personalizada será muito similar.
Converter texto em emoji
Você pode considerar a conversão de combinações de texto como “:)” e “xD” em emojis reais para proporcionar uma melhor experiência de usuário, além de manter a consistência das informações. Aqui está um snippet de código para ajudá-lo a fazer isso:
app.get("/emoji", async (req, res) => {
// Define a list of emojis that need to be converted
const emojiMap = {
xD: '😁',
':)': '😊',
':-)': '😄',
':jack_o_lantern:': '🎃',
':ghost:': '👻',
':santa:': '🎅',
':christmas_tree:': '🎄',
':gift:': '🎁',
':bell:': '🔔',
':no_bell:': '🔕',
':tanabata_tree:': '🎋',
':tada:': '🎉',
':confetti_ball:': '🎊',
':balloon:': '🎈'
}
// Build the SQL query adding conditional checks for all emojis from the map
let queryString = "SELECT * FROM COMMENTS WHERE"
queryString += " COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[0] + "%' "
if (Object.keys(emojiMap).length > 1) {
for (let i = 1; i < Object.keys(emojiMap).length; i++) {
queryString += " OR COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[i] + "%' "
}
}
queryString += ";"
const result = await client.query(queryString)
if (result.rowCount === 0) {
res.json({message: "No rows to clean up!"})
} else {
for (let i = 0; i < result.rows.length; i++) {
const currentRow = result.rows[i]
let emoji
// Identify each row that contains an emoji along with which emoji it contains
for (let j = 0; j < Object.keys(emojiMap).length; j++) {
if (currentRow.comment_text.includes(Object.keys(emojiMap)[j])) {
emoji = Object.keys(emojiMap)[j]
break
}
}
// Replace the emoji in the text and update the row before moving on to the next row
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + currentRow.comment_text.replace(emoji, emojiMap[emoji]) + "' WHERE COMMENT_ID = " + currentRow.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "All emojis cleaned up successfully!"})
}
})Esse snippet de código primeiro requer que você defina uma lista de emojis e suas representações textuais. Em seguida, consulta o banco de dados para procurar essas combinações textuais e as substitui por emojis.
Censurar linguagem obscena
Uma operação bastante comum usada em aplicativos que permitem conteúdo gerado pelo usuário é a censura de qualquer linguagem indecente. A abordagem aqui é semelhante: identificar as instâncias de linguagem obscena e substituí-las por asteriscos. Você pode usar o pacote bad-words para verificar e censurar palavrões com facilidade.
Instale o pacote executando o seguinte comando:
yarn add bad-wordsEm seguida, inicialize o pacote em seu arquivo index.js:
const Filter = require('bad-words');
filter = new Filter();Agora use o seguinte snippet de código para censurar o conteúdo obsceno em sua tabela de comentários:
app.get('/obscene', async (req, res) => {
// Query all comments using a cursor, reading only 10 at a time
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
let rows = await cursor.read(10)
const affectedRows = []
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// Check each comment for profane content
if (filter.isProfane(rows[i].comment_text)) {
affectedRows.push(rows[i])
}
}
rows = await cursor.read(10)
}
cursor.close()
// Update each comment that has profane content with a censored version of the text
for (let i = 0; i < affectedRows.length; i++) {
const row = affectedRows[i]
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + filter.clean(row.comment_text) + "' WHERE COMMENT_ID = " + row.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "Cleanup complete"})
})Você pode encontrar o código completo para este tutorial neste repositório do GitHub.
Entendendo a limpeza periódica Vacuum do PostgreSQL e sua finalidade
Além de configurar rotinas de manutenção personalizadas como as tratadas acima, você também pode usar uma das funcionalidades de manutenção nativas que o PostgreSQL oferece para garantir a saúde e o desempenho contínuos do seu banco de dados: o processo Vacuum.
O processo Vacuum ajuda a otimizar o desempenho do banco de dados e a recuperar espaço em disco. O PostgreSQL executa operações de limpeza periódica agendadas usando seu daemon autovacuum, mas você também pode acioná-lo manualmente se necessário. Aqui estão algumas maneiras pelas quais a limpeza periódica frequente pode ajudá-lo:
- Recuperação de espaço em disco bloqueado: Um dos principais objetivos do Vacuum é recuperar espaço em disco bloqueado no banco de dados. À proporção que os dados são constantemente inseridos, atualizados e excluídos, o PostgreSQL pode ficar cheio de linhas “mortas” ou obsoletas que ainda ocupam espaço no disco. O Vacuum identifica e remove essas linhas mortas, tornando o espaço disponível para novos dados. Sem o Vacuum, o espaço em disco gradualmente se esgotaria, podendo levar à degradação do desempenho e até mesmo a falhas do sistema.
- Atualização das métricas do planejador de consultas: A limpeza periódica também ajuda o PostgreSQL a manter estatísticas e métricas atualizadas usadas pelo seu planejador de consultas, que depende da distribuição precisa de dados e de informações estatísticas para gerar planos de execução eficientes. Ao executar regularmente o Vacuum, o PostgreSQL garante que essas métricas estejam atualizadas, permitindo que ele tome decisões melhores sobre como recuperar dados e otimizar consultas.
- Atualização do Mapa de Visibilidade: O Mapa de Visibilidade é outro aspecto crucial do processo Vacuum do PostgreSQL. Ele ajuda a identificar quais blocos de dados em uma tabela são totalmente visíveis para todas as transações, permitindo que o Vacuum direcione apenas os blocos de dados necessários para a limpeza. Isso aumenta a eficiência do processo Vacuum, minimizando operações de E/S desnecessárias, que seriam caras e demoradas.
- Prevenção de falhas de estouro do ID de transação (“wraparound”): O Vacuum também desempenha um papel crucial na prevenção de falhas de estouro do ID de transação. O PostgreSQL utiliza um contador de ID de transação de 32 bits, o que pode levar a um estouro quando atinge seu valor máximo. O Vacuum marca transações antigas como “congeladas”, evitando que o contador de ID dê a volta e cause corrupção de dados. Negligenciar este aspecto pode levar a falhas catastróficas do banco de dados.
Como mencionado anteriormente, o PostgreSQL oferece duas opções para a execução do Vacuum: Autovacuum e Manual Vacuum.
O Autovacuum é a escolha recomendada para a maioria dos cenários, pois gerencia automaticamente o processo Vacuum com base em configurações predefinidas e na atividade do banco de dados. O Manual Vacuum, por outro lado, oferece mais controle, mas requer uma compreensão mais detalhada da manutenção do banco de dados.
A decisão entre os dois depende de fatores como o tamanho do banco de dados, a carga de trabalho e os recursos disponíveis. Os bancos de dados de pequeno e médio porte geralmente podem contar com o Autovacuum, enquanto bancos de dados maiores ou mais complexos podem requerer intervenção manual.
Resumo
A manutenção do banco de dados não é apenas uma questão de limpeza de rotina: é a base de um aplicativo saudável e de alto desempenho. Ao otimizar, limpar e organizar regularmente os dados, você garante que o seu banco de dados PostgreSQL continue a oferecer desempenho máximo, permaneça livre de corrupção e opere de forma eficiente, mesmo quando o seu aplicativo ganha escala.
Neste guia abrangente, exploramos a importância crítica de estabelecer planos de manutenção de banco de dados bem estruturados para o PostgreSQL ao trabalhar com o Node.js e o Express.
Deixamos passar alguma operação de rotina de manutenção de banco de dados que você possa ter implementado no seu banco de dados? Ou conhece uma maneira melhor de implementar algumas das operações discutidas acima? Fique à vontade para nos informar nos comentários!

Kumar é um desenvolvedor de software e autor técnico baseado na Índia. Ele é especialista em JavaScript e DevOps. Você pode saber mais sobre o trabalho dele em seu site.

