
Nos últimos 18 meses, o foco em torno do tráfego de bots deixou de estar relacionado apenas ao rastreamento e à indexação para se concentrar no impacto que ele causa no desempenho do seu servidor, nos custos de hospedagem e na capacidade de atender usuários reais.
Sabemos disso porque analisamos mais de 10 bilhões de solicitações na infraestrutura gerenciada da Kinsta. O que encontramos não foi uma história sobre ataques, mas sobre consumo de recursos.
“Do ponto de vista da infraestrutura, não existe ‘apenas tráfego de bots’. Toda solicitação representa trabalho real. Em escala, rastreamentos ineficientes deixam de ser um problema de tráfego e passam a ser um problema de consumo de recursos.” — Daniel Pataki, CTO da Kinsta
Neste artigo, você entenderá por que essa mudança aconteceu, quanto ela realmente custa para proprietários de sites WordPress e por que a forma de enxergar esse problema precisa mudar.
O modelo antigo já não funciona mais
O gerenciamento tradicional de bots era baseado em uma ideia simples: bloquear os bots maliciosos e permitir a passagem dos legítimos. Durante muitos anos, isso foi suficiente. O Googlebot rastreava suas páginas, indexava o conteúdo e seguia em frente. Já os bots maliciosos tentavam invadir a página de login. Eram dois problemas completamente diferentes, cada um com sua própria solução.
O que nenhum desses modelos considerava era uma terceira categoria: tráfego automatizado que não é malicioso nem bloqueado, mas que ainda assim causa impactos mensuráveis no desempenho do seu site quando ocorre em grande escala.
Os Crawlers de IA — bots desenvolvidos não apenas para indexar páginas em mecanismos de pesquisa, mas também para coletar conteúdo destinado ao treinamento de modelos, geração aumentada por recuperação (RAG) e consultas em tempo real — operam em uma escala completamente diferente de tudo o que existia anteriormente. Somente o GPTBot cresceu 305% entre maio de 2024 e maio de 2025. No início de 2025, aproximadamente uma em cada 200 visitas à web era feita por um bot de IA. No final do ano, essa proporção passou para uma em cada 31 visitas.
No fim de 2025, os Crawlers de IA já representavam 4,2% de todas as solicitações HTML na rede do Cloudflare. Esse percentual variou de 2,4% no início de abril para 6,4% no fim de junho, praticamente triplicando em apenas um ano.
Esses crawlers fazem solicitações frequentes e persistentes, além de se comportarem de maneira diferente dos bots tradicionais dos mecanismos de pesquisa. Muitos geram grandes volumes de solicitações para endpoints dinâmicos não armazenados em cache, obrigando o servidor a executar “trabalho real”.
O que significa “trabalho real” para um site WordPress
É nesse ponto que o problema de infraestrutura fica evidente — e essa é uma parte da história que costuma passar despercebida na maioria das análises sobre tráfego de bots.
Quando um visitante acessa uma página armazenada em cache em um site WordPress, o servidor faz muito pouco trabalho. Ele apenas entrega um arquivo HTML previamente gerado, da mesma forma que entrega uma imagem ou um arquivo CSS. O servidor de origem praticamente nem percebe a solicitação. Esse é justamente o objetivo do cache.
No entanto, uma parcela significativa das solicitações em um site WordPress real — especialmente em lojas WooCommerce — não pode ser atendida pelo cache. Essas solicitações incluem:
- Endpoints de carrinho e checkout (
?add-to-cart=,/cart,/checkout) - Páginas de produtos filtradas com parâmetros na URL.
- Consultas de pesquisa.
- Interações baseadas em AJAX (adição à lista de desejos, atualização dinâmica de preços e pop-ups dinâmicos).
- Páginas baseadas em sessão que exigem que o servidor valide ou crie o contexto do usuário.
Quando um bot acessa esses endpoints, é isso que acontece no servidor:
- Uma Thread PHP é reservada. Cada solicitação dinâmica no WordPress ocupa uma Thread PHP durante todo o processamento — normalmente entre 200 e 500 ms, podendo levar mais tempo em páginas complexas. Durante esse período, essa thread não pode atender a nenhuma outra solicitação. Seu plano de hospedagem possui uma quantidade limitada delas.
- O banco de dados executa consultas. Páginas dinâmicas consultam o banco de dados a cada carregamento. Em condições normais de tráfego humano, isso é perfeitamente administrável. Porém, sob carga contínua de bots acessando caminhos não armazenados em cache, essas consultas passam a ocorrer constantemente. Se os bots acessarem diferentes variações de URL que não geram cache, cada uma iniciará sua própria sequência de consultas.
- Há sobrecarga de sessões. Páginas de carrinho e checkout criam ou validam sessões mesmo para bots que nunca concluirão uma compra. Isso adiciona processamento extra a cada solicitação.
- As Threads PHP se esgotam. Quando todas as Threads PHP disponíveis estão ocupadas, visitantes legítimos deixam de ser atendidos imediatamente e suas solicitações entram em fila. Se essa fila atingir o limite, começam a surgir páginas lentas, checkouts travados e erros 504. Para um cliente tentando finalizar uma compra, o site simplesmente parece estar quebrado.
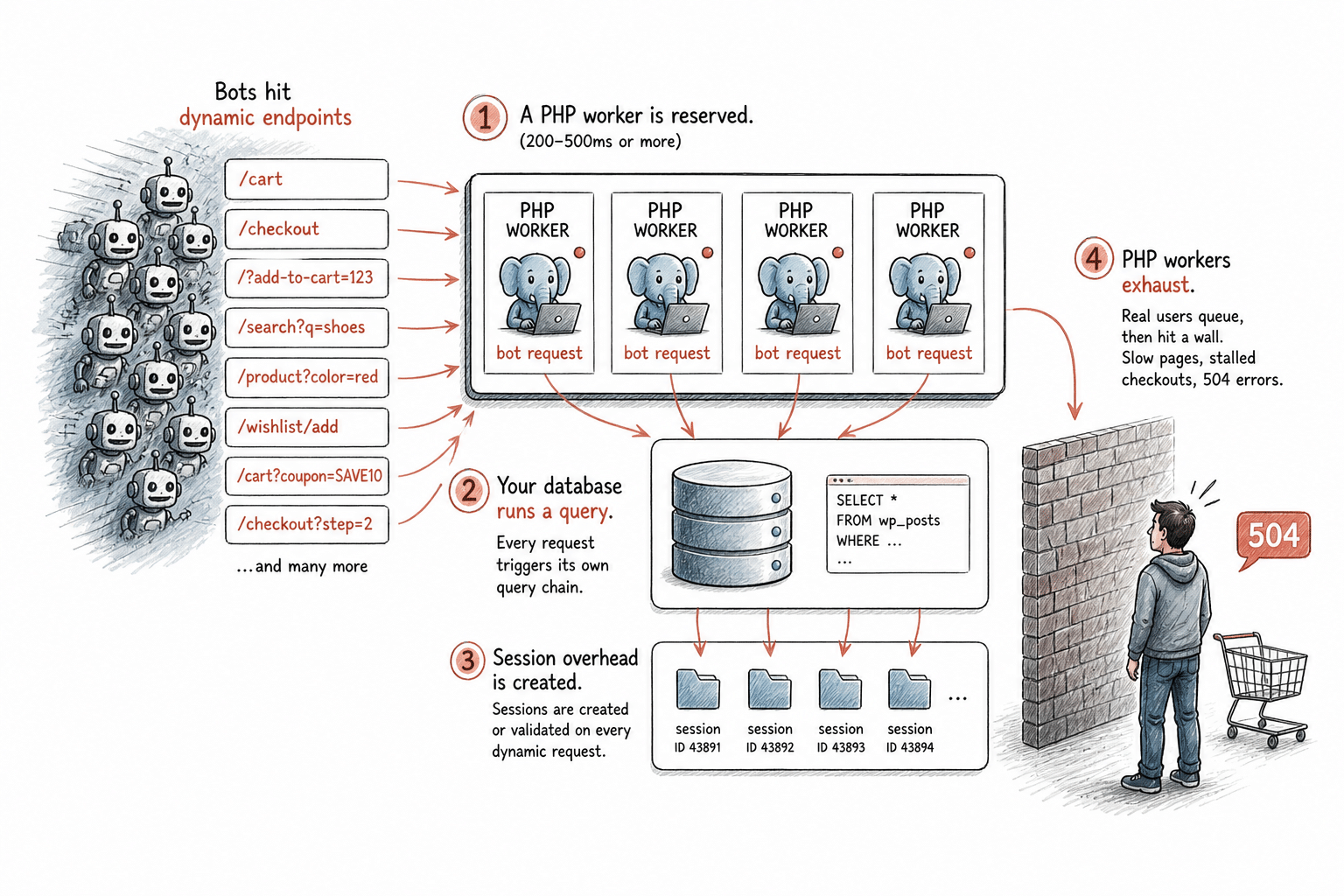
Esse é o mecanismo que transforma o tráfego de bots em um problema de infraestrutura. Não se trata de uma hipótese, mas da sequência exata de eventos que ocorre quando solicitações automatizadas inundam endpoints dinâmicos em um site WordPress em produção.
O que os dados da infraestrutura da Kinsta realmente mostram
O problema deixa de ser abstrato quando analisamos dados reais da infraestrutura que administramos em larga escala.
Um dado que chamou particularmente nossa atenção foi que um único bot (ClaudeBot) gerou 3,75 milhões de solicitações para URLs de adicionar ao carrinho em apenas 24 horas. Isso equivale a aproximadamente uma solicitação a cada 23 milissegundos, durante todo o dia e toda a noite. Como os endpoints de carrinho são inerentemente dinâmicos, o servidor tratou cada uma dessas solicitações como uma nova operação.
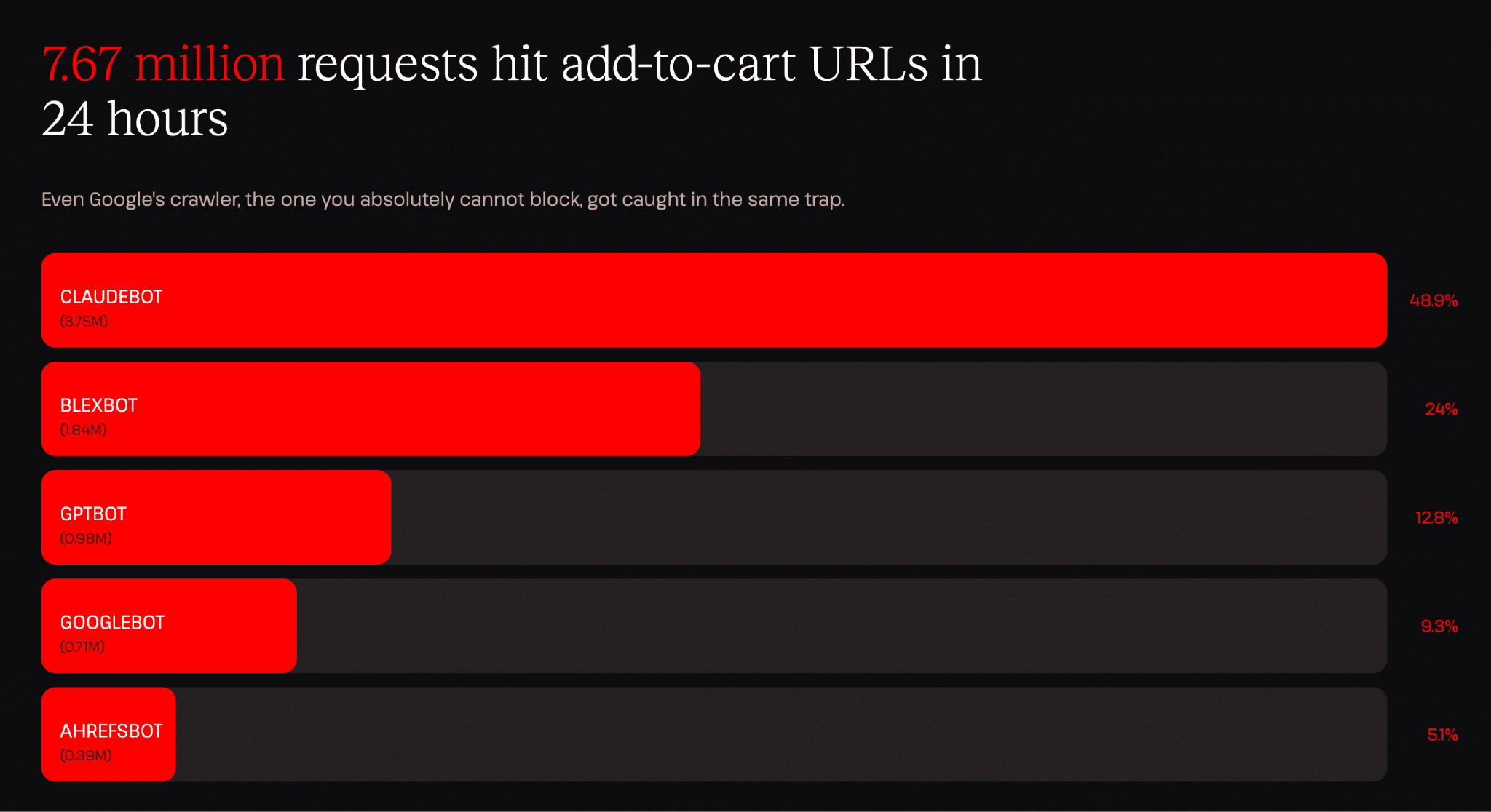
Para colocar esse número em perspectiva, solicitações de adicionar ao carrinho estão entre os endpoints mais caros de uma loja WooCommerce. Elas criam sessões, executam consultas ao banco de dados e atualizam o estado do carrinho. Cada uma representa trabalho real para o servidor. Os 3,75 milhões de solicitações que observamos provenientes de uma única origem em apenas um dia representam um padrão de tráfego capaz de tirar um site do ar.
Outro dado reforça o quanto esses padrões podem ser persistentes: um único comportamento incorreto de loop gerou 550 milhões de solicitações ao longo de 30 dias, volume suficiente para justificar a criação de uma regra dedicada de mitigação em nossa infraestrutura. Não se trata de um ataque DDoS nem de uma campanha de malware. É apenas um bot preso em um loop de rastreamento, solicitando repetidamente URLs que já havia visitado.
Esses não são casos isolados. São padrões que observamos continuamente em toda a plataforma da Kinsta.
O problema dos loops: os bots não estão atacando, estão presos
Um dos aspectos menos compreendidos do problema atual do tráfego de bots é que grande parte do que causa danos à infraestrutura nem sequer é malicioso. Trata-se de automação ineficiente executada em grande escala.
Sites modernos, especialmente lojas virtuais, geram URLs ligeiramente diferentes para, na prática, a mesma página:
- Um produto com um filtro de cor aplicado.
- Uma página de carrinho com um token de sessão.
- Uma categoria de produtos com um parâmetro de ordenação.
Para um usuário, todas essas URLs representam a mesma página. Para um bot que segue links, cada uma delas parece ser uma página totalmente nova para rastrear.
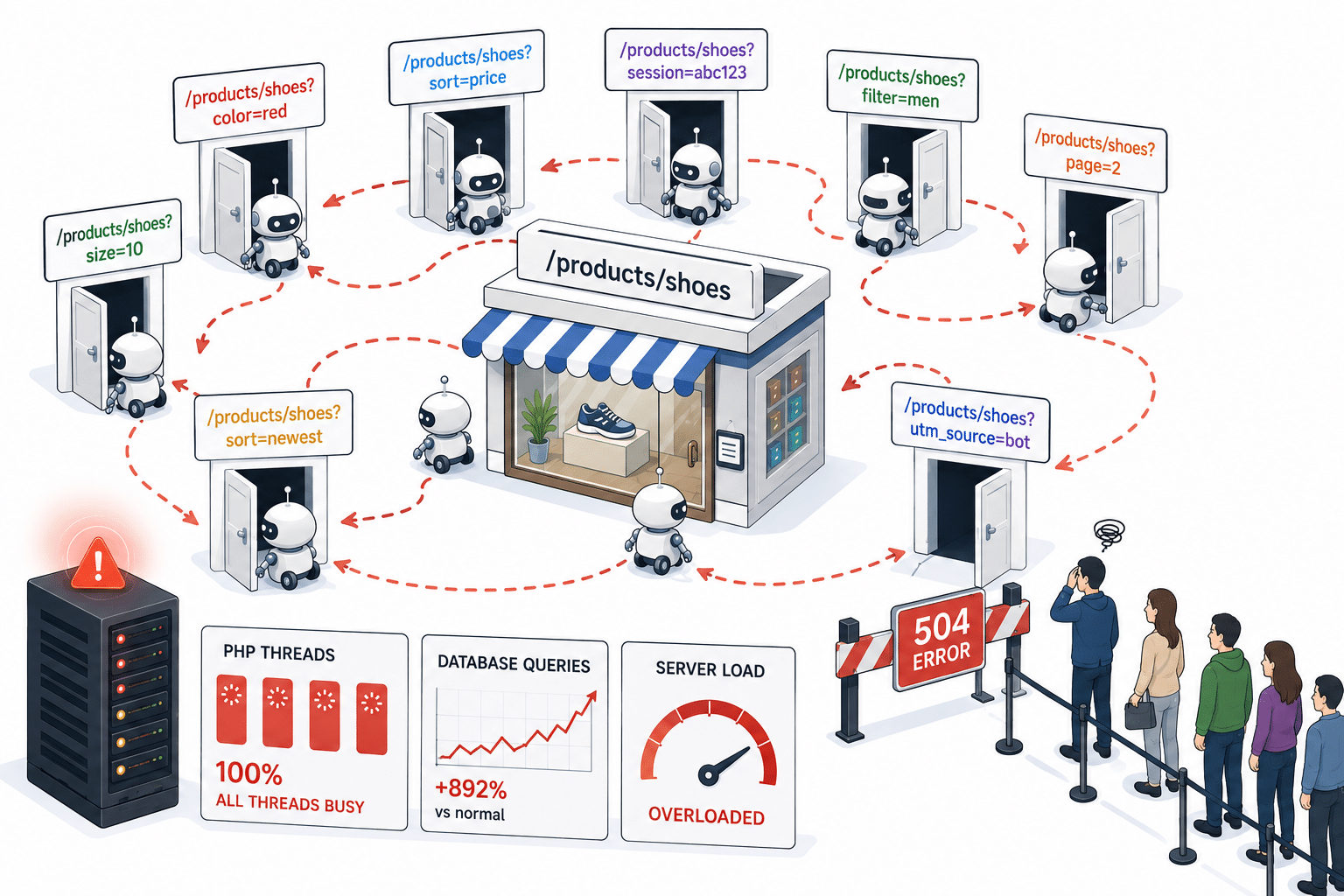
Assim, o bot segue o primeiro link. Essa página gera outra variação de URL, que o bot também segue. Depois, outra. Depois, mais outra. Ele não possui nenhum mecanismo para reconhecer que está andando em círculos, e alguns desses loops permaneceram ativos durante vários dias em infraestruturas monitoradas antes que regras de mitigação conseguissem identificá-los.
No relatório AI & Bot Traffic que publicamos recentemente, David Belson, ex-chefe de Data Insights do Cloudflare, comentou: “Tem gente que ontem não fazia ideia do que estava fazendo, mas hoje criou um bot usando vibe coding e simplesmente o colocou para rodar. Nem sequer se preocupou em verificar o robots.txt.”
Esse comportamento nem sempre vem de agentes mal-intencionados. Muitas vezes, ele é resultado de sistemas de Crawlers de IA que não foram projetados para lidar com navegação facetada, proliferação de parâmetros em URLs ou URLs geradas por sessões, recursos comuns em sites WordPress modernos.
O próprio Google identifica explicitamente a navegação facetada e URLs baseadas em parâmetros como fontes de ineficiência no rastreamento, observando que bots podem explorar um número praticamente infinito de variações da mesma página.
A conta do seu servidor agora também depende do gerenciamento de bots
Até pouco tempo atrás, muitos planos de hospedagem eram dimensionados com base no número de visitas, o que funcionava razoavelmente bem como um indicador do uso real por pessoas. A premissa era simples: quanto mais visitas, maior o número de usuários interagindo com o site.
Essa premissa deixou de ser válida.
O tráfego automatizado passou a inflar o número de visitas de uma forma que pouco tem relação com a atividade real do negócio. Solicitações feitas por bots podem aumentar a contagem de visitas sem gerar qualquer engajamento, conversão ou receita. Como consequência, muitos proprietários de sites passaram a receber cobranças por exceder os limites do plano devido a tráfego de bots que nunca solicitaram nem tinham como controlar.
Esse comportamento tornou-se tão recorrente que levou a Kinsta a lançar seus planos de hospedagem baseados em largura de banda do servidor, como resposta direta a uma categoria de sites cujas métricas de visitas passaram a divergir significativamente do consumo real de recursos.
O problema relacionado à cobrança é mensurável e pode ser resolvido. O desafio maior é que a maioria dos proprietários de sites nem percebe que isso está acontecendo, porque os painéis de monitoramento simplesmente não mostram o quadro completo.
O que suas análises mostram (e o que elas não mostram)
Uma das consequências do tráfego de bots operar nessa escala é que as análises tradicionais deixaram de retratar com precisão o desempenho real do seu site.
Se o número de visitas está aumentando, mas a receita, o tempo de permanência na página e o comportamento de rejeição não acompanham esse crescimento, os bots provavelmente fazem parte da explicação. Da mesma forma, se o servidor apresenta degradação de desempenho sem qualquer pico de tráfego relacionado à publicação de conteúdo, campanhas de marketing ou outros eventos esperados, vale a pena investigar se bots estão acessando endpoints não armazenados em cache.
A Kinsta filtra automaticamente user agents de bots conhecidos das Análises e dos cálculos de uso do plano. No entanto, tráfego automatizado que se comporta de maneira semelhante ao de usuários reais ainda pode aparecer nas suas métricas.
Os principais sinais aos quais você deve ficar atento são:
- Solicitações repetidas para os mesmos tipos de URL, principalmente caminhos baseados em parâmetros ou sessões.
- Picos de tráfego em horários que não coincidem com publicações, campanhas promocionais ou sazonalidade.
- Degradação no desempenho do servidor (TTFB mais alto e esgotamento das Threads PHP) durante períodos de aumento de tráfego que não correspondem a eventos do mundo real.
- Crescimento no número de visitas maior do que o crescimento da largura de banda do servidor, das conversões ou das métricas de engajamento.
Nenhum desses sinais, isoladamente, é conclusivo. No entanto, qualquer combinação entre eles merece investigação antes que esses números sejam atribuídos ao crescimento do negócio.
Por que esse problema é mais complexo do que parece
A reação mais comum diante de dados sobre tráfego de bots é bloquear tudo. Outras pessoas preferem permitir tudo, afinal, “a IA é o futuro”.
Nenhuma dessas abordagens funciona.
Bloquear indiscriminadamente significa bloquear também crawlers verificados, incluindo o Googlebot, cuja cobertura de rastreamento determina se seu conteúdo aparecerá ou não nos resultados de pesquisa. Isso também significa bloquear bots de descoberta usados por IA, que podem estar exibindo seu conteúdo em pesquisas conversacionais, recomendações baseadas em IA ou mecanismos de resposta. Para uma loja WooCommerce ou um site de conteúdo, isso representa um custo relevante de distribuição.
Por outro lado, permitir todo o tráfego significa aceitar custos de infraestrutura que não geram nenhum retorno. E, para os endpoints dinâmicos que costumam ser os principais alvos dos bots, esses custos estão longe de ser insignificantes. Eles se acumulam continuamente, principalmente sob cargas automatizadas persistentes.
A solução está em algum ponto entre esses dois extremos e exige compreender as diferenças entre as categorias de tráfego, em vez de tratar todos os bots como um único grupo.
Como explicou Cristian Lopez, editor-chefe da HostingAdvice, no relatório: “O equívoco é pensar que o tráfego de bots é apenas uma questão de ‘bloquear ou permitir’. Na realidade, trata-se de política, visibilidade e controle econômico.”
Bots verificados, como Googlebot, Bing e ferramentas legítimas de monitoramento, normalmente devem ser permitidos, embora seja possível restringir caminhos específicos que não possuem valor para rastreamento (por exemplo, sua página de checkout não contribui em nada para o SEO). Já bots não verificados, sem identificação clara ou finalidade conhecida, merecem uma análise mais cuidadosa. Os Crawlers de IA voltados para treinamento de modelos, que geram grandes volumes de solicitações para endpoints dinâmicos, representam uma categoria específica que pode justificar bloqueio ou limitação da taxa de solicitações, dependendo do tipo de site e das suas prioridades.
No nosso relatório sobre IA e tráfego de bots, desenvolvemos uma estrutura interativa de decisão que orienta a escolha da melhor estratégia para diferentes tipos de sites. O exemplo abaixo mostra a configuração recomendada para uma loja WooCommerce cujo foco é desempenho e estabilidade.
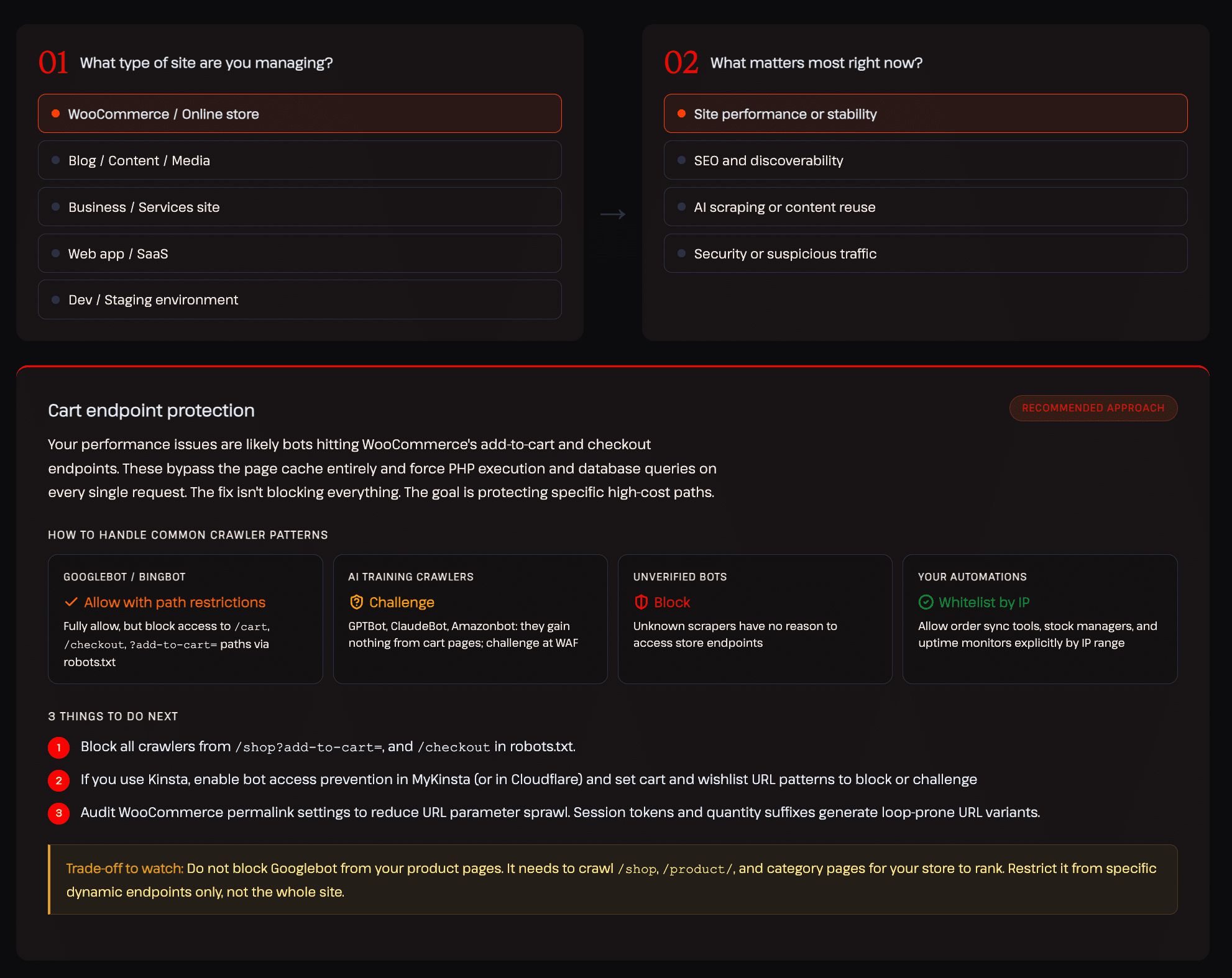
Esse tipo de controle detalhado, baseado em categorias de tráfego, é justamente o que a maioria das ferramentas atuais não oferece.
A abordagem da Kinsta para Proteção contra bots
A Proteção contra bots da Kinsta foi desenvolvida especificamente para enfrentar os desafios de infraestrutura descritos acima.
O sistema classifica o tráfego em categorias como bots verificados, prováveis humanos, prováveis bots, tráfego automatizado e tráfego malicioso, permitindo que você configure níveis de proteção compatíveis com as necessidades reais do seu site.

Os níveis de proteção não são simplesmente “permitir” ou “bloquear”. Bloquear automações bloqueia o tráfego automatizado confirmado enquanto permite a passagem de bots verificados. Aplicar verificação a bots adiciona uma etapa de verificação para automações não verificadas sem interromper a experiência de visitantes legítimos. Aplicar verificação a todos está disponível para períodos de alta pressão sobre o tráfego, embora apresente as consequências esperadas para uma configuração mais restritiva.
Um diferencial importante é que a ferramenta utiliza a pontuação de bots de nível empresarial do Cloudflare, baseada em Aprendizado de Máquina (Machine Learning) em tempo real. Cada visitante recebe uma pontuação de um a 99 com base em sinais comportamentais, e não apenas no user agent. Isso é especialmente importante porque confiar apenas no user agent está se tornando cada vez menos eficaz. Atualmente, 12,9% dos bots de IA ignoram as diretivas do robots.txt, contra 3,3% apenas um trimestre antes. A classificação baseada em comportamento consegue identificar aquilo que regras baseadas apenas em user agents deixam passar.
A ferramenta também oferece um sistema de exceções Sempre permitir, destinado a integrações confiáveis, serviços de monitoramento e automações críticas para o negócio que não devem ser afetadas pelas regras de proteção. sso é importante porque bloquear excessivamente também gera custos, especialmente para lojas WooCommerce que dependem de sincronização automática de pedidos, integrações com gateways de pagamento ou monitores de disponibilidade.
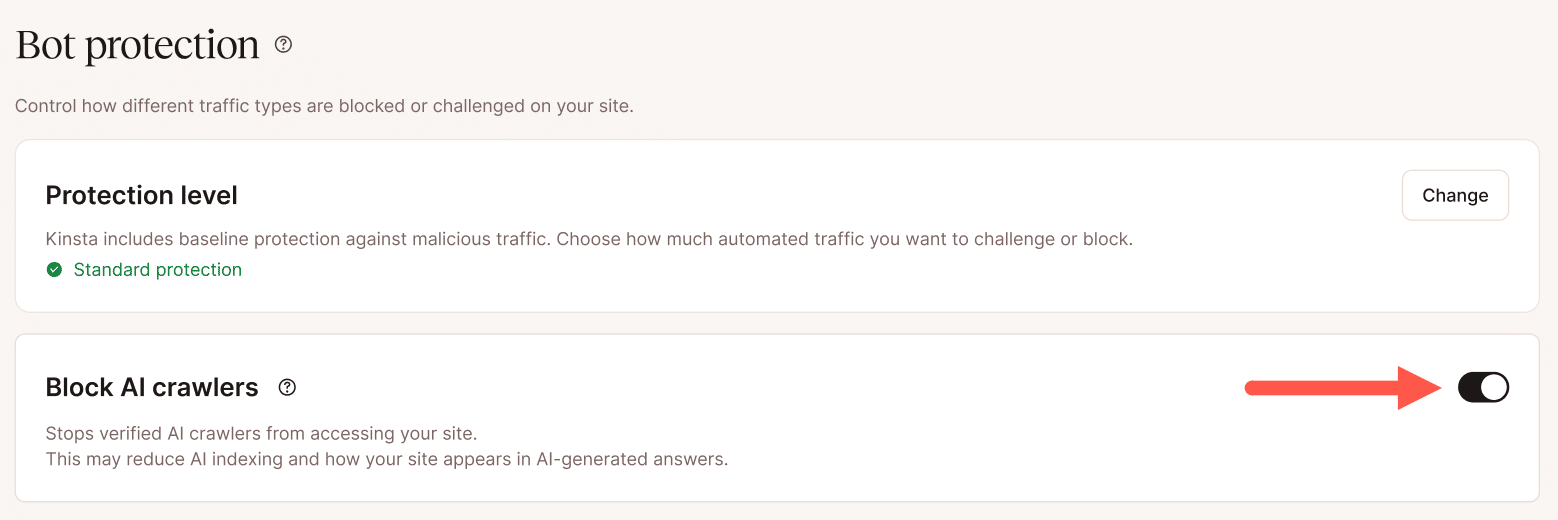
A opção Bloquear Crawlers de IA foi criada especificamente para bloquear bots de treinamento de IA sem afetar crawlers tradicionais dos mecanismos de pesquisa, como Googlebot e Bingbot. Para sites que já identificaram a atividade de Crawlers de IA como uma das causas do aumento de carga, essa é uma forma simples de mitigação que dispensa a criação de regras individuais para cada bot.
Saber que a ferramenta existe é uma coisa. Saber quando e como utilizá-la é outra completamente diferente.
O que fazer se o tráfego de bots for o seu problema
Se você está observando os padrões descritos acima, este é um bom ponto de partida, em ordem de impacto:
Primeiro: verifique a origem. Use o gráfico Detalhamento das solicitações na visualização da Proteção contra Bots do MyKinsta para entender como o tráfego que chega ao seu site está sendo classificado.
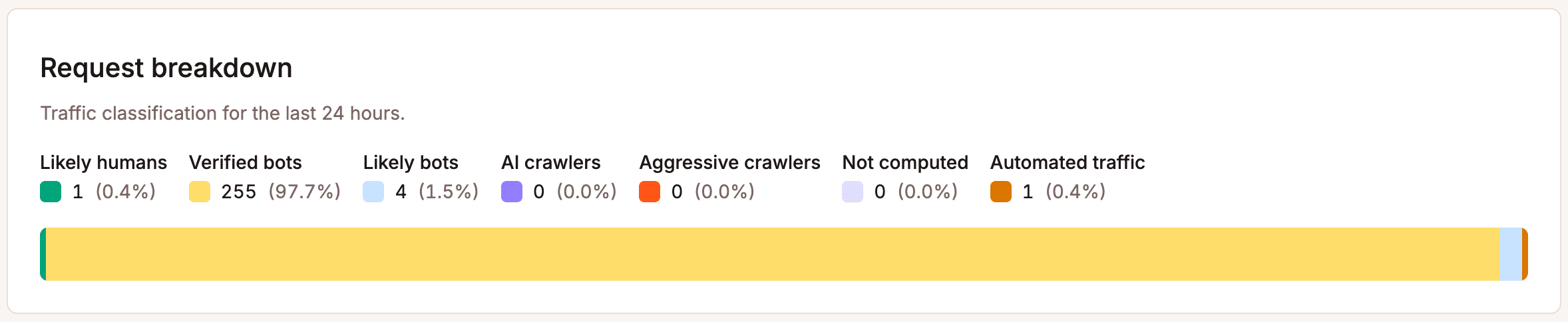
Se uma parte significativa desse tráfego for automatizada ou composta por bots não verificados, esse é o sinal de que você precisa agir. Não pule essa etapa, pois alterar configurações de proteção sem saber exatamente do que você está se protegendo costuma resultar em configurações incorretas.
Segundo: adapte o nível de proteção ao tipo de site. Uma loja WooCommerce possui prioridades diferentes de um site de conteúdo, que, por sua vez, possui necessidades diferentes de um ambiente de teste. Bloquear tráfego automatizado e aplicar verificações a prováveis bots faz sentido para uma loja com muitos endpoints dinâmicos. Já um site de conteúdo pode priorizar permitir bots de descoberta por IA enquanto bloqueia Crawlers de IA voltados ao treinamento de modelos. Um ambiente de teste, por outro lado, normalmente deve permanecer totalmente protegido.
Terceiro: proteja primeiro os endpoints mais caros. Antes de aplicar regras de proteção mais amplas, verifique se os endpoints de maior custo, como carrinho, checkout e manipuladores AJAX, estão acessíveis para crawlers que não têm motivo para visitá-los. Bloquear user agents de bots conhecidos em /cart e ?add-to-cart= por meio do robots.txt pode ser um primeiro passo, mas aplicar essa restrição no WAF — e não apenas sinalizá-la — é o que realmente impede que essas solicitações gerem carga no servidor.
Quarto: monitore e ajuste continuamente. Os padrões de tráfego de bots mudam muito mais rápido do que a maioria dos proprietários de sites imagina. A participação do GPTBot, por exemplo, triplicou em apenas um ano. Definir regras de proteção uma única vez e nunca mais revisá-las não é uma estratégia. O gráfico Resultados da proteção contra bots no MyKinsta mostra, ao longo do tempo, quais solicitações foram bloqueadas, submetidas à verificação ou permitidas.
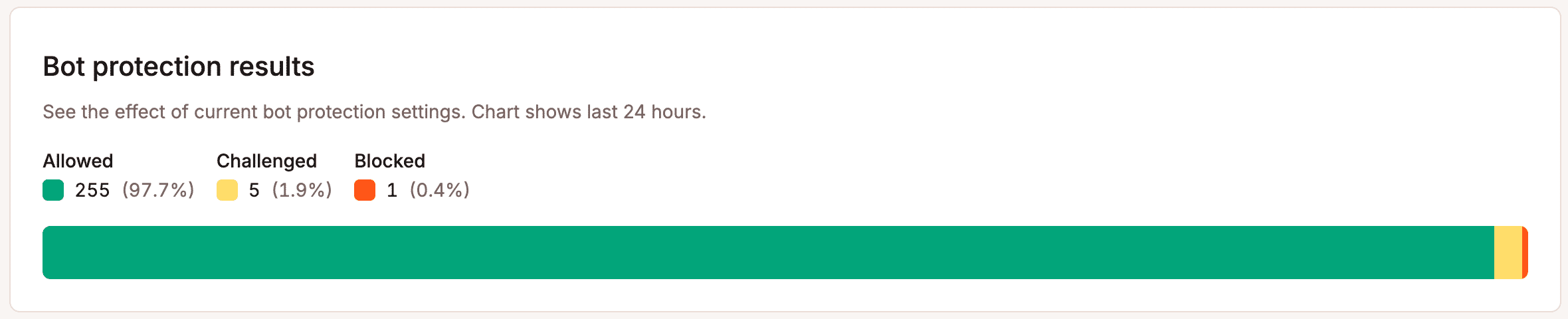
Esses dados devem orientar os ajustes nas suas configurações.
Se os bots estiverem gerando cobranças por exceder o limite de visitas em um plano baseado em visitas, também vale a pena avaliar os planos de hospedagem da Kinsta baseados em largura de banda da Kinsta. Migrar para um plano baseado em largura de banda do servidor não resolve o problema dos bots em si, mas pode refletir com mais precisão o custo real de infraestrutura do perfil de tráfego do seu site, que muitas vezes é significativamente menor do que o número de visitas sugere.
O panorama geral: esse problema só tende a crescer
O tráfego de agentes de IA já está aparecendo nos registros de infraestrutura. O Google já anunciou um user agent dedicado para quando seus agentes de IA interagirem com sites. Esses sistemas automatizados clicam em links, preenchem formulários e realizam solicitações que se parecem cada vez mais com sessões iniciadas por usuários reais.
À medida que a diferença entre interações humanas e automatizadas continua diminuindo, sinais atualmente utilizados para classificar bots, como user agents, frequência de solicitações e análise comportamental, tornam-se cada vez mais difíceis de aplicar com precisão.
A maioria dos proprietários de sites não consegue acompanhar essa evolução sozinha. O comportamento dos bots muda mais rápido do que as regras manuais conseguem acompanhar. O que funcionava há três meses pode já não ser suficiente hoje. E o custo de errar é real e imediato: mais consumo de recursos do servidor, cobranças adicionais e clientes reais enfrentando erros 504 durante o checkout. É justamente por isso que faz sentido contar com uma infraestrutura preparada para lidar com esse cenário.
A plataforma da Kinsta bloqueia entre 15% e 20% do tráfego malicioso antes mesmo que ele chegue ao seu site, opera sobre a rede empresarial do Cloudflare e oferece controles de Proteção contra Bots que se adaptam ao comportamento real do seu site. À medida que o tráfego de bots continua evoluindo, será cada vez mais evidente a diferença entre uma plataforma de hospedagem que trata esse desafio como um problema de infraestrutura e outra que o considera apenas um detalhe.
Os sites que lidarão melhor com esse cenário não serão aqueles que bloquearem a maior quantidade de bots, mas aqueles executados em uma infraestrutura desenvolvida para lidar com eles da forma mais eficiente.


