For de fleste marketingfolk er det nødvendigt med konstante opdateringer for at holde deres websted opdateret og forbedre deres SEO-rangering.
Nogle websteder har dog hundredvis eller endog tusindvis af sider, hvilket gør det til en udfordring for de teams, der manuelt skubber opdateringerne til søgemaskinerne. Hvis indholdet opdateres så hyppigt, hvordan kan teams så sikre, at disse forbedringer påvirker deres SEO-rangeringer?
Det er her, crawlerbots kommer ind i billedet. En webcrawlerbot skraber dit sitemap for nye opdateringer og indekserer indholdet i søgemaskinerne.
I dette indlæg vil vi skitsere en omfattende crawlerliste, der dækker alle de webcrawlerbots, du skal kende. Før vi dykker ned i det, skal vi først definere webcrawler-bots og vise, hvordan de fungerer.
Se vores videoguide om de mest almindelige webcrawlere
Hvad er en webcrawler?
En webcrawler er et computerprogram, der automatisk scanner og systematisk læser websider for at indeksere siderne til søgemaskinerne. Webcrawlere er også kendt som spiders eller bots.
For at søgemaskinerne kan præsentere opdaterede, relevante websider for brugere, der starter en søgning, skal der foretages en crawlning fra en webcrawler-bot. Denne proces kan nogle gange ske automatisk (afhængigt af både crawlerens og dit websteds indstillinger), eller den kan iværksættes direkte.
Mange faktorer påvirker dine siders SEO-rangering, herunder relevans, backlinks, webhosting og meget mere. Men ingen af disse har nogen betydning, hvis dine sider ikke bliver crawlet og indekseret af søgemaskinerne. Derfor er det så vigtigt at sikre, at dit websted tillader de korrekte crawls finder sted og fjerner eventuelle hindringer i deres vej.
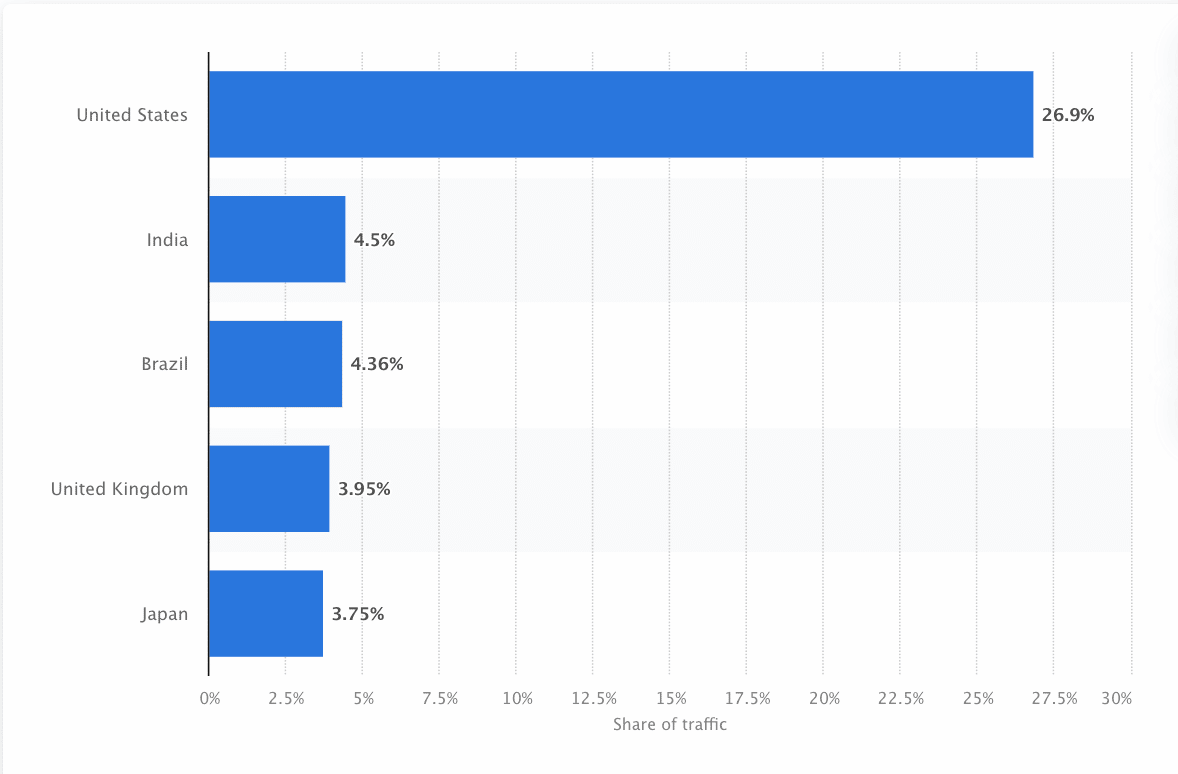
Bots skal hele tiden scanne og skrabe nettet for at sikre, at de mest korrekte oplysninger præsenteres. Google er det mest besøgte websted i USA, og ca. 26,9% af søgningerne kommer fra amerikanske brugere:
Der findes dog ikke én webcrawler, der crawler for alle søgemaskiner. Hver søgemaskine har unikke styrker, så udviklere og marketingfolk udarbejder nogle gange en “crawler-liste” Denne crawler-liste hjælper dem med at identificere forskellige crawlere i deres webstedslog, som de skal acceptere eller blokere.
Markedsførere skal samle en crawlerliste fuld af de forskellige webcrawlere og forstå, hvordan de evaluerer deres websted (i modsætning til indholdsskrabere, der stjæler indholdet) for at sikre, at de optimerer deres landingssider korrekt til søgemaskinerne.
Hvordan fungerer en webcrawler?
En webcrawler scanner automatisk din webside, efter at den er offentliggjort, og indekserer dine data.
Webcrawlere leder efter specifikke nøgleord, der er forbundet med websiden, og indekserer disse oplysninger til relevante søgemaskiner som Google, Bing og andre.
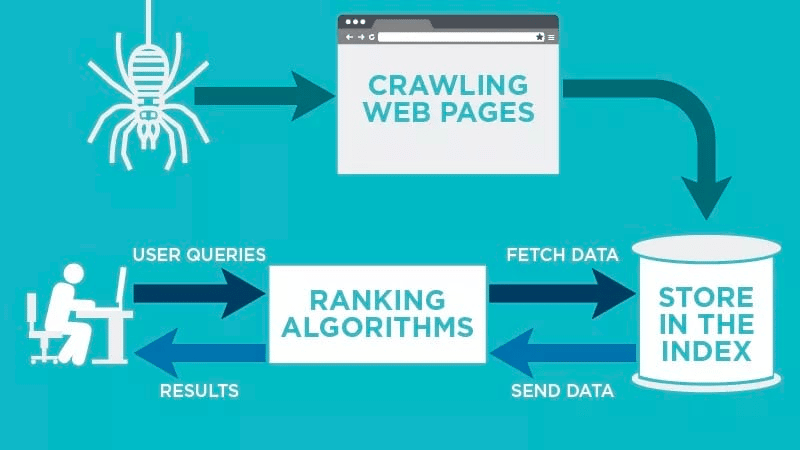
Algoritmer til søgemaskinerne henter disse data, når en bruger indsender en forespørgsel på det relevante søgeord, der er knyttet til den.
Crawls starter med kendte URL’er. Det er etablerede websider med forskellige signaler, der leder webcrawlere til disse sider. Disse signaler kan være:
- Backlinks: Antallet af gange et websted linker til det
- Besøgende: Antal besøgende: Hvor meget trafik der er på vej til den pågældende side
- Domæneautoritet: Den overordnede kvalitet af domænet
Derefter lagrer de dataene i søgemaskinens indeks. Når brugeren indleder en søgning, henter algoritmen dataene fra indekset, og de vises på søgemaskinens resultatside. Denne proces kan ske på få millisekunder, og derfor vises resultaterne ofte hurtigt.
Som webmaster kan du selv styre, hvilke bots der gennemsøger dit websted. Derfor er det vigtigt at have en crawlerliste. Det er den robots.txt-protokollen der bor på de enkelte webstedsservere, som leder crawlere til nyt indhold, der skal indekseres.
Afhængigt af, hvad du indtaster i din robots.txt-protokol på hver webside, kan du fortælle en crawler, at den skal scanne eller undgå at indeksere den pågældende side i fremtiden.
Ved at forstå, hvad en webcrawler ser efter i sin scanning, kan du forstå, hvordan du bedre kan placere dit indhold til søgemaskinerne.
Udarbejdelse af din crawlerliste: Hvad er de forskellige typer af webcrawlere?
Når du begynder at tænke på at udarbejde din crawlerliste, er der tre hovedtyper af crawlere, som du skal kigge efter. Disse omfatter:
- In-house crawlere: Det er crawlere, der er designet af en virksomheds udviklingsteam til at scanne virksomhedens websted. Typisk bruges de til revision og optimering af websteder.
- Kommercielle crawlere: Det er specialfremstillede crawlere som Screaming Frog, som virksomheder kan bruge til at crawle og effektivt evaluere deres indhold.
- Crawlere med åben kildekode: Disse er crawlere, der kan bruges gratis, og som er bygget af en række udviklere og hackere rundt om i verden.
Det er vigtigt at forstå de forskellige typer crawlere, der findes, så du ved, hvilken type du skal udnytte til dine egne forretningsmål.
De 14 mest almindelige webcrawlere, der skal føjes til din crawlerliste
Der findes ikke én crawler, der gør alt arbejdet for alle søgemaskiner.
I stedet er der en række forskellige webcrawlere, der vurderer dine websider og scanner indholdet til alle de søgemaskiner, der er tilgængelige for brugere i hele verden.
Lad os se på nogle af de mest almindelige webcrawlere i dag.
1. Googlebot
Googlebot er Googles generiske webcrawler, som er ansvarlig for at crawle websteder, der vises i Googles søgemaskine.

Selv om der teknisk set findes to versioner af Googlebot – Googlebot Desktop og Googlebot Smartphone (Mobile) – betragter de fleste eksperter Googlebot som én enkelt crawler.
Det skyldes, at begge følger det samme unikke produkttoken (kendt som et brugeragenttoken), der er skrevet i hvert websted i robots.txt. Googlebot-brugeragenten er simpelthen “Googlebot.”
Googlebot går på arbejde og får typisk adgang til dit websted med få sekunders mellemrum (medmindre du har blokeret den i dit websted i robots.txt). En backup af de scannede sider gemmes i en samlet database kaldet Google Cache. Dette gør det muligt for dig at se gamle versioner af dit websted.
Derudover er Google Search Console også et andet værktøj, som webmastere bruger til at forstå, hvordan Googlebot gennemtrawler deres websted, og til at optimere deres sider til søgning.
| User Agent | Googlebot |
| Full User Agent String | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
2. Bingbot
Bingbot blev oprettet i 2010 af Microsoft for at scanne og indeksere URL’er for at sikre, at Bing tilbyder relevante, opdaterede søgemaskineresultater til platformens brugere.
Ligesom Googlebot kan udviklere eller marketingfolk i deres robots.txt på deres websted definere, om de godkender eller afviser agentidentifikatoren “bingbot” til at scanne deres websted eller ej.
Derudover har de mulighed for at skelne mellem mobile-first indexing crawlere og desktop crawlere, da Bingbot for nylig skiftede til en ny agenttype. Dette giver sammen med Bing Webmaster Tools webmastere større fleksibilitet til at vise, hvordan deres websted bliver opdaget og vist frem i søgeresultaterne.
| User Agent | Bingbot |
| Full User Agent String | Desktop – Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36
Mobile – Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) “W.X.Y.Z” will be substituted with the latest Microsoft Edge version Bing is using, for eg. “100.0.4896.127″ |
3. Yandex Bot
Yandex Bot er en crawler specielt til den russiske søgemaskine Yandex. Dette er en af de største og mest populære søgemaskiner i Rusland.

Webmastere kan gøre siderne på deres websted tilgængelige for Yandex Bot via deres robots.txt-fil.
Derudover kan de også tilføje et Yandex.Metrica-tag til specifikke sider, indeksere siderne igen i Yandex Webmaster eller udstede en IndexNow-protokol, en unik rapport, der påpeger nye, ændrede eller deaktiverede sider.
| User Agent | YandexBot |
| Full User Agent String | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
4. Apple Bot
Apple har bestilt Apple Bot til at crawle og indeksere websider til Apples Siri og Spotlight Suggestions.
Apple Bot tager flere faktorer i betragtning, når den beslutter, hvilket indhold der skal fremhæves i Siri- og Spotlight-forslagene. Disse faktorer omfatter brugerengagement, søgeudtrykkets relevans, antal/kvalitet af links, positionsbaserede signaler og endda websidedesign.
| User Agent | Applebot |
| Full User Agent String | Mozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, like Gecko) Version/Safari_version Safari/WebKit_version (Applebot/Applebot_version) |
5. DuckDuck Bot
DuckDuckBot er webcrawler for DuckDuckGo, som tilbyder “Sømløs beskyttelse af privatlivets fred i din webbrowser.”
Webmastere kan bruge DuckDuckBot API’et til at se, om DuckDuck Bot har crawlet deres websted. Efterhånden som den crawler, opdaterer den DuckDuckBot API-databasen med de seneste IP-adresser og brugeragenter.
Dette hjælper webmastere med at identificere eventuelle bedrageriske eller ondsindede robotter, der forsøger at blive forbundet med DuckDuck Bot.
| User Agent | DuckDuckBot |
| Full User Agent String | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
6. Baidu Spider
Baidu er den førende kinesiske søgemaskine, og Baidu Spider er webstedets eneste crawler.

Google er forbudt i Kina, så det er vigtigt at aktivere Baidu Spider til at crawle dit websted, hvis du ønsker at nå det kinesiske marked.
For at identificere Baidu Spider, der crawler dit websted, skal du kigge efter følgende brugeragenter: baiduspider, baiduspider-image, baiduspider-video m.fl.
Hvis du ikke laver forretninger i Kina, kan det give mening at blokere Baidu Spider i dit robots.txt-script. Dette vil forhindre Baidu Spider i at crawle dit websted og dermed fjerne enhver chance for, at dine sider vises på Baidu’s søgemaskineresultatsider (SERP).
| User Agent | Baiduspider |
| Full User Agent String | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
7. Sogou Spider
Sogou er en kinesisk søgemaskine, der angiveligt er den første søgemaskine med 10 milliarder indekserede kinesiske sider.

Hvis du har forretninger på det kinesiske marked, er dette en anden populær søgemaskinecrawler, som du skal kende til. Sogou Spider følger robottens udelukkelsestekst og crawl delay-parametre.
Ligesom med Baidu Spider bør du, hvis du ikke ønsker at gøre forretninger på det kinesiske marked, deaktivere denne spider for at undgå langsomme indlæsningstider for websteder.
| User Agent | Sogou Pic Spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou head spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07) Sogou Orion spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (compatible; MSIE 5.5; Windows 98) |
8. Facebook eksternt hit
Facebook External Hit, også kendt som Facebook Crawler, gennemtrawler HTML-koden for en app eller et websted, der deles på Facebook.

Dette gør det muligt for den sociale platform at generere et preview, der kan deles, af hvert link, der er lagt ud på platformen. Titlen, beskrivelsen og miniaturebilledet vises takket være crawleren.
Hvis crawlet ikke udføres inden for få sekunder, viser Facebook ikke indholdet i den brugerdefinerede snippet, der genereres før deling.
| User Agent | facebot facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
9. Exabot
Exalead er en softwarevirksomhed, der blev oprettet i 2000 og har hovedkvarter i Paris, Frankrig. Virksomheden leverer søgeplatforme til forbrugere og virksomheder.
Exabot er crawleren for deres kernesøgemaskine, der er bygget på deres CloudView-produkt.
Som de fleste søgemaskiner tager Exalead både hensyn til backlinking og indholdet på websiderne, når de rangerer. Exabot er brugeragenten for Exaleads robot. Robotten opretter et “hovedindeks”, som samler de resultater, som søgemaskinens brugere vil se.
| User Agent | Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Exabot-Thumbnails) Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot) |
10. Swiftbot
Swiftype er en brugerdefineret søgemaskine til dit websted. Den kombinerer “den bedste søgeteknologi, algoritmer, frameworks for indholdsindsamling, klienter og analyseværktøjer.”
Hvis du har et komplekst websted med mange sider, tilbyder Swiftype en nyttig grænseflade til at katalogisere og indeksere alle dine sider for dig.
Swiftbot er Swiftypes webcrawler. Men i modsætning til andre robotter crawler Swiftbot kun de websteder, som deres kunder anmoder om.
| User Agent | Swiftbot |
| Full User Agent String | Mozilla/5.0 (compatible; Swiftbot/1.0; UID/54e1c2ebd3b687d3c8000018; +http://swiftype.com/swiftbot) |
11. Slurp Bot
Slurp Bot er Yahoos søgerobot, som crawler og indekserer sider for Yahoo.
Denne crawl er afgørende for både Yahoo.com og dets partnerwebsteder, herunder Yahoo News, Yahoo Finance og Yahoo Sports. Uden den ville der ikke blive vist relevante sideoversigter.
Det indekserede indhold bidrager til en mere personlig weboplevelse for brugerne med mere relevante resultater.
| User Agent | Slurp |
| Full User Agent String | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) |
12. CCBot

CCBot er en Nutch-baseret webcrawler udviklet af Common Crawl, en non-profit organisation fokuseret på (uden omkostninger) at give en kopi af internettet til virksomheder, enkeltpersoner og alle, der er interesseret i online forskning. Botten bruger MapReduce, en programmeringsframework, der giver den mulighed for at kondensere store mængder data til værdifulde samlede resultater.
Takket være CCBot kan folk bruge Common Crawls data til at forbedre sprogoversættelsessoftware og forudsige tendenser. Faktisk blev GPT-3 i vid udstrækning trænet på data fra deres datasæt.
| User Agent | CCBot/2.0 (https://commoncrawl.org/faq/) CCBot/2.0 CCBot/2.0 (http://commoncrawl.org/faq/) |
13. GoogleOther
Dette er en ny en. GoogleOther blev lanceret af Google i april 2023, og det fungerer ligesom Googlebot.
De deler begge den samme infrastruktur og har de samme funktioner og begrænsninger. Den eneste forskel er, at GoogleOther vil blive brugt internt af Google-teams til at crawle offentligt tilgængeligt indhold fra websteder.
Årsagen bag oprettelsen af denne nye crawler er at tage en vis belastning af Googlebots crawlkapacitet og optimere dens webcrawlerprocesser.
GoogleOther vil for eksempel blive brugt til forskning og udvikling (R&D) crawl, hvilket giver Googlebot mulighed for at fokusere på opgaver, der er direkte relateret til søgeindeksering.
| User Agent | GoogleOther |
14. Google-InspectionTool
Folk, der ser på crawl- og botaktiviteten i deres logfiler, vil falde over noget nyt.
En måned efter lanceringen af GoogleOther har vi en ny crawler iblandt os, der også efterligner Googlebot: Google-InspectionTool.
Denne webcrawler bruges af søge-testværktøjer i Search Console, såsom URL-inspektion, og andre Google-ejendomme, såsom Rich Result Test.
| User Agent | Google-InspectionTool Googlebot |
| Full User Agent String | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-InspectionTool/1.0) Mozilla/5.0 (compatible; Google-InspectionTool/1.0) |
De 8 kommercielle crawlere, som SEO-professionelle skal kende
Nu hvor du har 13 af de mest populære bots på din crawlerliste, skal vi se på nogle af de almindelige kommercielle crawlere og SEO-værktøjer for professionelle.
1. Ahrefs Bot
Ahrefs Bot er en webcrawler, der kompilerer og indekserer den 12 billioner linkdatabase, som den populære SEO-software Ahrefs tilbyder.
Ahrefs Bot besøger 6 milliarder websteder hver dag og anses for at være “den næstmest aktive crawler” efter kun Googlebot.
Ligesom andre bots følger Ahrefs Bot’en robots.txt-funktioner samt allows/disallows-regler i hvert enkelt websteds kode.
2. Semrush Bot
Semrush Bot gør det muligt for Semrush, en førende SEO-software, at indsamle og indeksere data om websteder til brug for sine kunder på deres platform.
Dataene bruges i Semrushs offentlige backlink-søgemaskine, site audit-værktøjet, backlink audit-værktøjet, linkbuilding-værktøjet og skriveassistenten.
Den crawler dit websted ved at udarbejde en liste over webside-URL’er, besøge dem og gemme visse hyperlinks til fremtidige besøg.
3. Moz’s Campaign Crawler Rogerbot
Rogerbot er crawleren for det førende SEO-websted, Moz. Denne crawler indsamler specifikt indhold til Moz Pro Campaign site audits.

Rogerbot følger alle regler, der er fastsat i robots.txt-filer, så du kan selv bestemme, om du vil blokere/tilladelse Rogerbot til at scanne dit websted.
Webmastere vil ikke kunne søge efter en statisk IP-adresse for at se, hvilke sider Rogerbot har crawlet på grund af dens mangefacetterede tilgang.
4. Screaming Frog
Screaming Frog er en crawler, som SEO-professionelle bruger til at revidere deres eget websted og identificere områder med forbedringspotentiale, der vil påvirke deres placering i søgemaskinerne.

Når en crawl er startet, kan du gennemgå data i realtid og identificere broken links eller forbedringer, der er nødvendige i dine sidetitler, metadata, robotter, duplikatindhold og meget mere.
For at kunne konfigurere crawlparametrene skal du købe en Screaming Frog-licens.
5. Lumar (tidligere Deep Crawl)
Lumar er et “centraliseret kommandocentral til vedligeholdelse af dit websteds tekniske sundhed” Med denne platform kan du starte et crawl af dit websted for at hjælpe dig med at planlægge din webstedsarkitektur.
Lumar er stolt af at være den “hurtigste website crawler på markedet” og praler af at kunne crawle op til 450 URL’er i sekundet.
6. Majestic
Majestic fokuserer primært på sporing og identifikation af backlinks på URL’er.

Virksomheden er stolt af at have “en af de mest omfattende kilder til backlinkdata på internettet” og fremhæver sit historiske indeks, som er steget fra 5 til 15 års links i 2021.
Webstedets crawler gør alle disse data tilgængelige for virksomhedens kunder.
7. cognitiveSEO
cognitiveSEO er en anden vigtig SEO-software, som mange professionelle bruger.
Den cognitiveSEO-crawler giver brugerne mulighed for at udføre omfattende site audits, der vil informere deres site arkitektur og overordnede SEO-strategi.
Botten gennemtrawler alle sider og leverer “et fuldt tilpasset datasæt”, som er unikt for slutbrugeren. Dette datasæt vil også indeholde anbefalinger til brugeren om, hvordan de kan forbedre deres websted for andre crawlere – både for at påvirke placeringer og blokere crawlere, der er unødvendige.
8. Oncrawl
Oncrawl er en “brancheførende SEO-crawler og loganalysator” til kunder på virksomhedsniveau.
Brugere kan oprette “crawlprofiler” for at skabe specifikke parametre for crawlen. Du kan gemme disse indstillinger (herunder start-URL, crawl-grænser, maksimal crawl-hastighed m.m.) for nemt at køre crawlen igen med de samme fastsatte parametre.
Skal jeg beskytte mit websted mod ondsindede webcrawlere?
Ikke alle crawlere er gode. Nogle kan have en negativ indvirkning på din sidehastighed, mens andre kan forsøge at hacke dit websted eller have ondsindede hensigter.
Derfor er det vigtigt at forstå, hvordan du kan blokere crawlere fra at komme ind på dit websted.
Ved at oprette en liste over crawlere ved du, hvilke crawlere der er de gode at holde øje med. Derefter kan du så sortere de usikre fra og tilføje dem til din blokeringsliste.
Sådan blokerer du skadelige webcrawlere
Med din crawlerliste i hånden kan du identificere, hvilke bots du vil godkende, og hvilke du skal blokere.
Det første skridt er at gennemgå din crawlerliste og definere den brugeragent og den fulde agentstreng, der er knyttet til hver crawler, samt dens specifikke IP-adresse. Det er vigtige identifikationsfaktorer, der er knyttet til hver bot.
Med brugeragenten og IP-adressen kan du matche dem i dine webstedsoptegnelser ved hjælp af et DNS-søgning eller IP-match. Hvis de ikke passer nøjagtigt sammen, har du måske en ondsindet bot, der forsøger at udgive sig for at være den rigtige bot.
Så kan du blokere bedrageren ved at justere tilladelserne ved hjælp af dit robots.txt-webstedtag.
Oversigt
Webcrawlere er nyttige for søgemaskiner og vigtige for marketingfolk at forstå.
Det er vigtigt for din virksomheds succes at sikre, at dit websted bliver crawlet korrekt af de rigtige crawlere. Ved at føre en liste over crawlere kan du vide, hvilke crawlere du skal holde øje med, når de dukker op i loggen for dit websted.
Når du følger anbefalingerne fra kommercielle crawlere og forbedrer dit websteds indhold og hastighed, gør du det lettere for crawlere at få adgang til dit websted og indeksere de rigtige oplysninger til søgemaskinerne og de forbrugere, der søger dem.