
En la actualidad, casi todas las aplicaciones de software o web requieren una base de datos en el backend. El aumento de las transacciones que se producen por segundo y los terabytes de datos almacenados exigen un marco estable y flexible para albergar y servir esos datos.
Naturalmente, para las startups, la cuestión del coste también entra en escena. Pero, ¿y si te decimos que puedes acceder a esta base de datos, e incluso construirla, sin coste alguno?
Sí, has oído bien: la base de datos PostgreSQL garantiza todo lo que hemos mencionado anteriormente, ¡incluyendo algunas ventajas adicionales! En este artículo, repasaremos los distintos aspectos de PostgreSQL que le permiten mantenerse en pie en un segmento que evoluciona rápidamente.
Vayamos al grano.
¿Qué es PostgreSQL?
PostgreSQL es un sistema de bases de datos de código abierto, altamente estable, que proporciona soporte a diferentes funciones de SQL, como claves foráneas, subconsultas, disparadores y diferentes tipos y funciones definidas por el usuario. Además, aumenta el lenguaje SQL ofreciendo varias funciones que escalan y reservan meticulosamente las cargas de trabajo de datos. Se utiliza principalmente para almacenar datos para muchas aplicaciones móviles, web, geoespaciales y de análisis.
Profundizaremos en todos los aspectos de PostgreSQL en este artículo, empezando por sus características clave en la siguiente sección. Manos a la obra.
Características principales de PostgreSQL
Hay algunas características clave de la base de datos PostgreSQL que la hacen única y ampliamente favorecida en comparación con otras bases de datos. Actualmente, es la segunda base de datos más utilizada, sólo por detrás de MySQL.
Veamos estas características con más detalle.
Fiabilidad y cumplimiento de normas
PostgreSQL ofrece una verdadera semántica ACID para las transacciones y tiene soporte completo para claves foráneas, uniones, vistas, disparadores y procedimientos almacenados, en muchos lenguajes diferentes. Incluye la mayoría de los tipos de datos de SQL, como los de INTEGER, VARCHAR, TIMESTAMP y BOOLEAN. También admite el almacenamiento de objetos binarios de gran tamaño, como imágenes, vídeos o sonidos. Es fiable, ya que cuenta con una amplia red de soporte comunitario integrada. PostgreSQL es una base de datos tolerante a fallos gracias a su registro de escritura anticipada.
Extensiones
PostgreSQL cuenta con varios conjuntos de características robustas, como la recuperación puntual, el Control de Concurrencia Multiversional (MVCC), los tablespaces, los controles de acceso granulares, la replicación asíncrona, un planificador/optimizador de consultas refinado y el registro de escritura anticipada. El Control de Concurrencia Multiversional permite la lectura y escritura concurrentes de las tablas, bloqueando sólo las actualizaciones concurrentes de la misma fila. Así se evitan los choques.
Escalabilidad
PostgreSQL admite Unicode, conjuntos de caracteres internacionales, codificaciones de caracteres multibyte, y tiene en cuenta la localización para la ordenación, la distinción entre mayúsculas y minúsculas y el formato. PostgreSQL es altamente escalable, tanto en el número de usuarios concurrentes que puede acomodar como en la cantidad de datos que puede gestionar. Además, PostgreSQL es multiplataforma y puede funcionar en muchos sistemas operativos, como Linux, Microsoft Windows, OS X, FreeBSD y Solaris.
Carga dinámica
El servidor PostgreSQL también puede incluir en sí mismo código escrito por el usuario mediante la carga dinámica. El usuario puede especificar un archivo de código objeto; por ejemplo, una biblioteca compartida que implemente una nueva función o tipo y PostgreSQL lo cargará según sea necesario. La capacidad de modificar su funcionamiento sobre la marcha lo hace especialmente adecuado para implementar rápidamente nuevas estructuras de almacenamiento y aplicaciones.
Arquitectura de PostgreSQL
El servidor PostgreSQL tiene una estructura sencilla, que consiste en una memoria compartida, procesos en segundo plano y una estructura de directorio de datos. En esta sección, hablaremos de cada componente y de cómo interactúan bufferentre sí. A continuación se muestra una ilustración de la arquitectura de PostgreSQL. Inicialmente, el cliente envía una petición al servidor. A continuación, el servidor PostgreSQL procesa los datos utilizando bufferes compartidos y procesos en segundo plano. El archivo físico del servidor de bases de datos PostgreSQL se almacena en el directorio de datos.
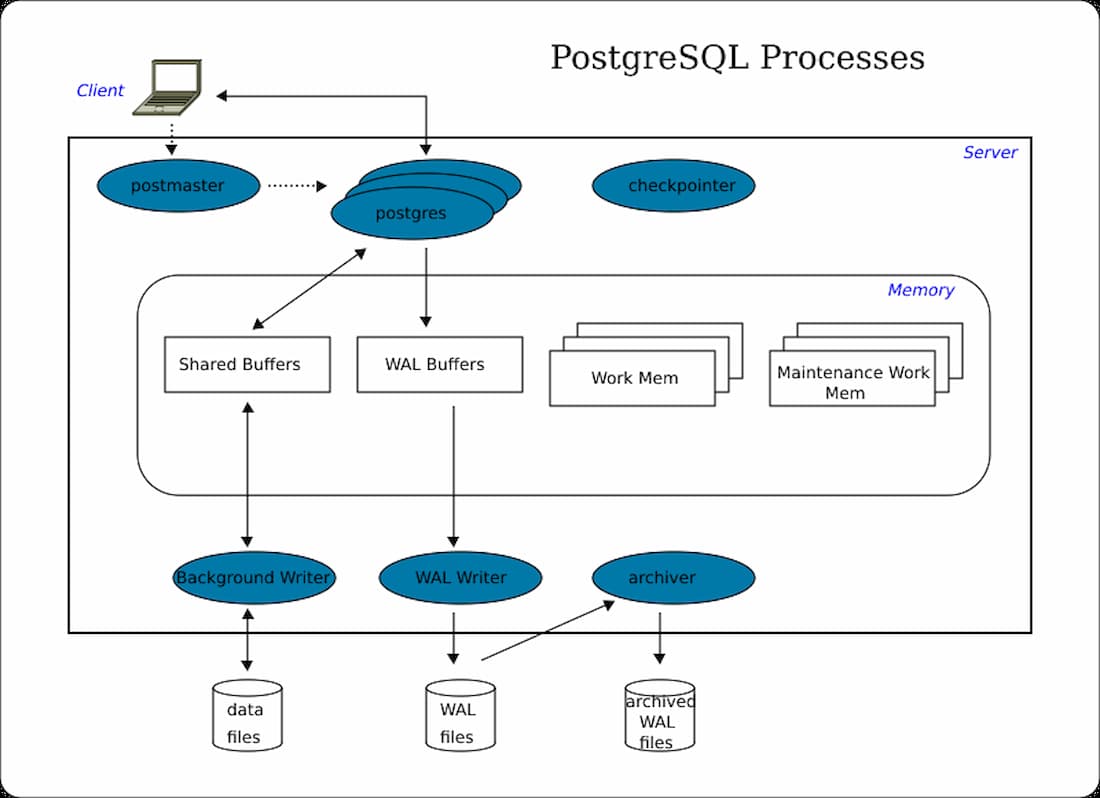
Memoria compartida
La memoria compartida está reservada para el almacenamiento en caché del registro de transacciones y de la base de datos. Además, tiene elementos como los Bufferes Compartidos, los Bufferes WAL, la Memoria de Trabajo y la Memoria de Trabajo de Mantenimiento. Vamos a sumergirnos en cada tema a continuación.
Bufferes compartidos
Estos bufferes sirven para minimizar el IO del disco del servidor. Para cumplir este objetivo, es justo establecer el valor del buffer compartido como el 25% de la memoria total si tenemos un servidor dedicado a PostgreSQL. El valor por defecto de los buffers compartidos a partir de la versión 9.3 es de 128 MB. Es imprescindible intentar minimizar la contención cuando varios usuarios acceden simultáneamente. Los bloques de uso frecuente deben estar en el buffer el mayor tiempo posible. Esto permite acceder a los datos lo más rápidamente posible.
Bufferes WAL
Los bufferes WAL almacenan temporalmente los cambios en la base de datos. El archivo WAL consiste en el contenido escrito por el buffer WAL en un momento predeterminado. Los archivos WAL y los bufferes WAL son significativos para recuperar los datos durante las copias de seguridad y la recuperación.
Memoria de trabajo
Este espacio de memoria se utiliza para las operaciones de mapa de bits, la ordenación, las uniones de fusión y las uniones de hash para escribir datos en archivos temporales de disco. La configuración por defecto a partir de la versión 9.3 es de 4 MB.
Memoria de trabajo de mantenimiento
Esta ranura de memoria se utiliza para las operaciones de la base de datos, como ANALIZAR, VACUAR, ALTER TABLE y CREAR ÍNDICE. La configuración por defecto a partir de la versión 9.4 es de 64 MB.
Procesos en segundo plano
Cada proceso en segundo plano es integral y realiza una función única para gestionar el servidor. A continuación se detallan algunos procesos en segundo plano importantes:
Proceso de punto de control
Cuando se produce un punto de control, el buffer sucio se escribe en el archivo. El Checkpointer esencialmente escribe todas las páginas sucias de la memoria en el disco y limpia el área del buffer compartido. Si la base de datos se bloquea, la pérdida de datos puede medirse obteniendo la diferencia entre el tiempo del último punto de control y el tiempo de parada de PostgreSQL.
Proceso de escritura en segundo plano
Actualiza los registros y la información de las copias de seguridad. Hasta la versión 9.1, este proceso se integraba junto con el proceso de checkpointer que se realizaba regularmente. Sin embargo, a partir de la versión 9.2, el proceso de checkpointer se separó del proceso de escritura en segundo plano.
Escritor de WAL
Este proceso escribe y descarga los datos de la WAL en el buffer de la WAL periódicamente en el almacenamiento persistente.
Archivador
Si está activado, este proceso tiene la responsabilidad de copiar los archivos de registro de la WAL a un directorio especificado.
Registrador/Recolector de registros
Este proceso escribe un buffer WAL en el archivo WAL.
Archivos de datos/Estructura del directorio de datos
PostgreSQL tiene varias bases de datos, que juntas forman un cluster de bases de datos. Cuando se inicializa, se crean las bases de datos plantilla 0, plantilla1 y Postgres. La creación de la nueva base de datos del usuario se realiza a través de las bases de datos de plantilla, que consisten en las tablas del catálogo del sistema. Aunque la lista de tablas de plantilla0 y plantilla 1 es la misma tras la inicialización, sólo la base de datos plantilla 1 puede crear los objetos que el usuario necesita, por lo que la base de datos del usuario se crea clonando la base de datos plantilla 1.
Los datos necesarios para el clúster se almacenan en el directorio de datos del clúster, que también se denomina «PGDATA». Consta de varios subdirectorios. A continuación se mencionan algunos importantes:
- Global: El subdirectorio global está formado por las tablas del clúster, como la base de datos de usuarios.
- Base: El subdirectorio Base es la ubicación física del espacio de tablas por defecto. Contiene varios subdirectorios por base de datos, dentro de los cuales se almacenan los catálogos del sistema.
- PID: El archivo PID consiste en el ID del proceso postmaster actual (PID).
- PG_VERSION: Este subdirectorio consiste en la información de la versión de la base de datos.
- PG_NOTIFY: Este subdirectorio contiene los datos de estado de LISTEN/NOTIFY. Estos archivos pueden ser útiles para la resolución de problemas.
¿Por qué utilizar PostgreSQL?
Además de proporcionar una serie de características como índices, vistas y procedimientos almacenados, PostgreSQL tiene mucho más que ofrecer, a saber
- Soporte de idiomas
- Código abierto
- Base de datos relacional de objetos
- Rendimiento
- Extensibilidad
- Capacidades de equilibrio de carga
- Fiabilidad
- Internacionalización
Vamos a examinarlas con más detalle.
Soporte de idiomas
PL/PGSQL es un lenguaje procedimental nativo proporcionado por PostgreSQL que tiene diferentes características modernas. Respalda el tipo de datos JSON, que es ligero y garantiza la flexibilidad incluida en un único paquete. Como resultado, PostgreSQL admite varios lenguajes de programación y protocolos, como Perl, Ruby, Python, .Net, C/C++, Java, ODBC y Go.
Código abierto
Es gratuito y de código abierto: ésta es, con mucho, la ventaja más importante de PostgreSQL. Está respaldado por más de 20 años de desarrollo de la comunidad, lo que ha contribuido a su alto nivel de integridad. Su código fuente está disponible bajo una licencia de código abierto que te permite utilizarlo, modificarlo e implementarlo como creas conveniente, sin ningún coste adicional.
Base de datos relacional con objetos
Los objetos, las clases y la sobrecarga de funciones se soportan directamente en PostgreSQL. Es posible ampliar los tipos de datos para crear tipos de datos personalizados, debido a sus características orientadas a objetos. Esto garantiza una gran flexibilidad para los desarrolladores que trabajan con modelos de datos complejos que requieren la integración de la base de datos.
La herencia de tablas es otra característica soportada por PostgreSQL debido a sus características orientadas a objetos. La tabla hija puede heredar las columnas de su tabla padre, además de las otras columnas que posee la tabla hija, haciéndola diferente de sí misma.
Rendimiento
Las operaciones de escritura en PostgreSQL pueden realizarse de forma concurrente sin necesidad de bloqueos de lectura/escritura. Los índices se utilizan para acelerar las consultas cuando se trata de grandes cantidades de datos, lo que permite a las bases de datos encontrar una fila específica sin tener que recorrer todos los datos.
Con PostgreSQL, puedes incluso crear un índice de expresión, que funciona sobre el resultado de una expresión o una función en lugar de sobre el valor de una columna. También se admite la indexación parcial, en la que sólo se indexa una parte de la tabla. También admite la paralelización de las consultas de lectura, la compilación justo a tiempo (JIT) de las expresiones y las transacciones anidadas (mediante puntos de guardado), lo que garantiza un gran rendimiento y eficiencia.
Extensibilidad
PostgreSQL es altamente extensible, ya que su funcionamiento se basa en el catálogo, es decir, la información se almacena en bases de datos, columnas, tablas, etc. PostgreSQL no sólo guarda una gran cantidad de información en sus catálogos, sino también detalles sobre los tipos de datos, métodos de acceso, funciones, etc. Incluso puedes llegar a escribir tus códigos desde diferentes lenguajes de programación sin tener que recompilar tu Base de Datos, y definir tus tipos de datos.
Capacidades de equilibrio de carga
Garantiza la alta disponibilidad y el equilibrio de carga mediante el funcionamiento del servidor en espera, la planificación continua, la preparación del primario para los servidores en espera, la configuración de un servidor en espera, la replicación en flujo, las ranuras de replicación, la replicación en cascada y el archivo continuo en espera. Además, PostgreSQL admite la replicación sincrónica, en la que dos instancias de base de datos pueden ejecutarse al mismo tiempo y la base de datos maestra se sincroniza con una base de datos esclava simultáneamente, lo que garantiza aún más la alta disponibilidad.
Fiabilidad
Además de almacenar los datos de forma segura y permitir que el usuario los recupere cuando se procesa la solicitud, está respaldado por una comunidad de colaboradores que encuentran regularmente errores e intentan mejorar el software, lo que hace que PostgreSQL sea fiable.
Internacionalización
El proceso de diseñar el software para que pueda ser utilizado en diversas regiones se conoce como internacionalización. Soporta conjuntos de caracteres internacionales a través de codificaciones de caracteres multibyte, colaciones ICU, Unicode, y es consciente de la localización para la ordenación, el formato y la sensibilidad a las mayúsculas y minúsculas. Ver los mensajes generados por PostgreSQL en el idioma que elijas es un ejemplo de internacionalización.
Cuándo usar PostgreSQL
¿Necesitas construir consultas y relaciones complejas que deben actualizarse con frecuencia y mantenerse de forma consistente de la manera más rentable posible? PostgreSQL puede ser una opción adecuada. PostgreSQL no sólo es gratuito, sino que además es multiplataforma, y no se limita al sistema operativo Windows. Si quieres analizar datos, PostgreSQL proporciona una gran cantidad de expresiones regulares como base para el trabajo analítico.
También es una de las mejores bases de datos en lo que respecta al soporte de CSV. Comandos sencillos como «copiar desde» y «copiar a» ayudan a procesar rápidamente los datos. Si hay un problema de importación, lanzará un error y detendrá la importación inmediatamente. Las siguientes secciones cubrirán algunas de las aplicaciones más comunes de PostgreSQL en el mundo moderno. Comencemos.
Datos geoespaciales gubernamentales
El complemento de la base de datos geoespacial PostGIS para PostgreSQL es indudablemente beneficioso. Cuando se utiliza junto con la extensión PostGIS, PostgreSQL admite objetos geográficos y puede utilizarse como almacén de datos geoespaciales para sistemas de información geográfica (SIG) y servicios basados en la localización.
Industria financiera
PostgreSQL es un sistema DBMS ideal para la industria financiera. Como es totalmente compatible con ACID, es una opción ideal para OLTP (Procesamiento de Transacciones en Línea), ya que estas bases de datos necesitan ser escritas, leídas y actualizadas con frecuencia, junto con un énfasis en el procesamiento rápido. También es apto para ejecutar análisis de bases de datos. Se puede integrar con cualquier software que realice operaciones matemáticas, como Matlab y R.
Datos científicos
Los datos científicos requieren terabytes de datos. Es imprescindible manejar los datos de la forma más eficiente posible. PostgreSQL proporciona una maravillosa analítica y un potente motor SQL. Esto ayuda a gestionar una gran cantidad de datos con facilidad.
Tecnología web
Los sitios web suelen manejar cientos o miles de peticiones por segundo. Si el desarrollador busca una solución rentable y escalable, PostgreSQL sería la mejor opción. PostgreSQL puede ejecutar sitios web y aplicaciones dinámicas como parte de una alternativa robusta a la pila LAMP, es decir, la pila LAPP. (Linux, Apache, PostgreSQL, PHP, Python y Perl)
Fabricación
Muchas startups y grandes empresas utilizan PostgreSQL como solución principal de almacenamiento de datos para productos, soluciones y aplicaciones a escala de Internet. El rendimiento de la cadena de suministro puede optimizarse utilizando este DBMS de código abierto como backend de almacenamiento. Como resultado, esto permite a las empresas reducir el coste operativo de su negocio.
Desafíos operativos de PostgreSQL
Hasta ahora sólo hemos cantado las alabanzas de PostgreSQL en este artículo, así que es justo que te mostremos un par de deficiencias con las que podrías tropezar mientras te adentras en PostgreSQL. He aquí algunos retos operativos que puedes encontrar durante el proceso de adopción de PostgreSQL.
- Falta de un ecosistema de bases de datos maduro: PostgreSQL cuenta con una de las comunidades de más rápido crecimiento, pero a diferencia de los proveedores de bases de datos tradicionales, la comunidad PostgreSQL no cuenta con la comodidad de un ecosistema de bases de datos desarrollado.
- La escasez de conocimientos: PostgreSQL se suele acoplar a varias bases de datos, como MongoDB. Ahora, cada base de datos necesita una destreza especializada, y la contratación de personal técnico con la competencia deseada en PostgreSQL puede ser una tarea difícil de cumplir. Junto con las herramientas de gestión para PostgreSQL, los expertos en bases de datos y los equipos de DevOps tienen que enfrentarse a varias bases de datos de múltiples proveedores. Esto puede ser difícil de gestionar cuando no se puede cambiar entre los procesos existentes.
- Inconsistencia: Dado que PostgreSQL es una herramienta de código abierto, diferentes equipos de desarrollo de TI dentro de una organización pueden empezar a aprovecharla de forma orgánica. Esto puede llevar a otro obstáculo: la falta de un único punto de conocimiento para todas las instancias de PostgreSQL dentro del entorno de TI. Otro problema que puede derivarse de que distintos equipos intenten resolver el mismo problema es la duplicación y la redundancia del trabajo.
Principales alternativas a PostgreSQL
Aquí tienes algunas alternativas clave de PostgreSQL que puedes aprovechar para tu sitio web de WordPress.
MySQL
Cuando piensas en bases de datos, tu mente se dirige instantáneamente a MySQL. Fue una opción bastante omnipresente para los desarrolladores durante mucho tiempo, antes de que empezaran a surgir alternativas viables. Más del 39% de los desarrolladores la utilizaban en 2019. Aunque carece de la versatilidad de PostgreSQL, sigue siendo útil para varios casos de uso, como las aplicaciones web escalables.
MySQL ha sido mantenido por Oracle desde su creación en 1995. Oracle también ofrece versiones de élite de MySQL con plugins propios, servicios complementarios, extensiones y un sólido soporte para el usuario. Para entender mejor MySQL, debes comprender mejor los modelos cliente-servidor y las bases de datos relacionales. En pocas palabras, tus datos se dividen en varias áreas de almacenamiento separadas, también conocidas como tablas, en lugar de descargarlo todo en una gran unidad de almacenamiento solitario. Esta es la esencia de una base de datos relacional.
Además de ser una plataforma de base de datos fiable y sólida, es bastante fácil de dominar. La curva de aprendizaje no es tan pronunciada como la de algunos de sus contemporáneos, ya que no es necesario tener un conocimiento completo de SQL para empezar a trabajar con MySQL.
Si aprovechas WordPress para tu sitio web y quieres entender cómo hacer que MySQL funcione más rápido, tu mejor opción sería perfeccionar tu base de datos para alinearla con tu forma de utilizar WordPress. En términos técnicos, esto se conoce como ajuste de rendimiento de MySQL. La ventaja obvia de optimizar MySQL es la reducción de los tiempos de carga junto con un sitio web más rápido en general. Aparte de esto, si mantienes tu base de datos adecuadamente, deberías ver una mejora constante en su crecimiento, incluso a medida que se expande.
MariaDB
MariaDB es una bifurcación comercial del sistema de gestión de bases de datos relacionales MySQL que cuenta con un enfoque fundamentalmente distinto para satisfacer las necesidades del mundo moderno. El motor de almacenamiento de MariaDB, construido a propósito y conectable, ofrece soporte para cargas de trabajo que antes necesitaban una amplia gama de bases de datos especializadas. Esto le permite ser una ventanilla única para las organizaciones, ya sea en la nube o en el hardware básico que deseen.
Puedes desplegar MariaDB en cuestión de minutos para casos de uso analítico, transaccional o híbrido, para ofrecer una destreza operativa inigualable sin renunciar a las características empresariales clave. Esto incluye el cumplimiento total de SQL y ACID real.
MariaDB ofrece los siguientes productos a sus usuarios:
- MariaDB Enterprise: MariaDB Enterprise es una solución de base de datos de código abierto absoluta y de grado de producción que puede abordar con elegancia las cargas de trabajo analíticas, transaccionales o híbridas analíticas/transaccionales. MariaDB Enterprise también posee la capacidad de escalar desde bases de datos columnares y autónomas hasta bases de datos SQL totalmente distribuidas que pueden realizar millones de transacciones por segundo. También te permite realizar análisis interactivos e improvisados sobre miles de millones de filas.
- Servidor de la Comunidad MariaDB: MariaDB Community Server es la base de datos relacional de código abierto que utilizan la gran mayoría de los desarrolladores actuales. MariaDB Community Server no sólo es compatible con Oracle, MySQL y otras bases de datos, sino que también garantiza que seguirá siendo de código abierto para siempre. Entre sus características más destacadas están el almacenamiento en columnas para el análisis, el SQL moderno, los motores de almacenamiento enchufables y la alta disponibilidad.
- MariaDB SkySQL: SkySQL se conoce como una oferta de base de datos como servicio (DBaaS) que lleva toda la potencia de MariaDB Enterprise a la nube junto con su compatibilidad con cargas de trabajo analíticas, transaccionales e híbridas. SkySQL está construido sobre Kubernetes y renovado para los servicios y la infraestructura en la nube. SkySQL se ha hecho un nombre en este espacio al combinar el autoservicio y la facilidad de uso con capacidades de soporte de primera categoría y fiabilidad empresarial. Bastante evidente por la última afirmación, esto comprende todo lo necesario para ejecutar con seguridad bases de datos fundamentales en la nube, junto con la gobernanza empresarial.
Debido a su compatibilidad con MySQL, puedes aprovechar MariaDB como «sustituto» de MySQL sin apenas consecuencias.
Mejores prácticas para tu base de datos
Cuando piensas en plataformas fáciles de usar para los propietarios de sitios web por primera vez, probablemente pienses en WordPress. WordPress te permite conseguir muchas cosas sin ninguna experiencia previa en codificación. Sin embargo, para extraer el máximo valor de WordPress, todavía necesitas tener una clara comprensión de cómo funcionan algunos de sus elementos básicos. Por ejemplo, si llevas bastante tiempo utilizando WordPress para tu sitio web, probablemente sea un buen momento para comprender cómo funcionan las bases de datos de WordPress.
Esto hace que surja inmediatamente una pregunta común, ¿por qué necesita WordPress una base de datos después de todo? Puede que no lo parezca, pero en WordPress hay más de lo que parece. Hay mucho trabajo entre bastidores para que funcione con eficacia, independientemente del tamaño de tu sitio web.
Para profundizar, tienes que saber que un sitio web de WordPress se compone de muchos tipos de datos diferentes. Ahora bien, es obvio que toda esta información se almacena en una base de datos consolidada de WordPress. Esta base de datos es fundamental para tu sitio web de WordPress, ya que guarda todos los cambios que tú o tus visitantes hacéis y permite que tu sitio web funcione sin problemas. Estos son algunos de los datos que se recopilan en tu base de datos de WordPress:
- Información organizativa, como etiquetas y categorías.
- Ajustes de todo el sitio.
- Páginas, entradas y contenido relacionado.
- Datos relacionados con temas y plugins.
- Comentarios y datos de los usuarios.
Cuando instalas un sitio web de WordPress, una parte del proceso es crear una base de datos para él. Normalmente, esto tiene lugar de forma automática. Sin embargo, existe una disposición si quieres crear una base de datos manualmente, o incluso aprovechar una base de datos existente con un nuevo sitio web.
La siguiente sección hablará de las prácticas recomendadas para tu base de datos de WordPress.
Utilizar una herramienta de gestión de bases de datos
La función básica de las herramientas de gestión de bases de datos es permitirte ver el contenido de tu base de datos. Para que una base de datos funcione sin problemas, aprovechar una herramienta de gestión de bases de datos podría ser tu mejor opción. En general, las herramientas de gestión de bases de datos consolidan funciones que satisfacen las necesidades de tres profesionales distintos de las bases de datos:
- Los analistas de bases de datos pueden extraer los datos de múltiples fuentes. A continuación, limpian, integran y preparan los datos para su análisis. Para los analistas de bases de datos, tener la capacidad de colaborar en conjuntos de datos y consultas sin tener que depender de TI para acceder a ellos es un requisito integral.
- Los desarrolladores de bases de datos necesitan herramientas que les permitan escribir código de alta calidad la primera vez y mantenerlo sin problemas. Los desarrolladores de bases de datos valoran las herramientas de colaboración y automatización de la programación. Esto les permite condensar los ciclos de desarrollo sin aumentar el riesgo.
- Los administradores de bases de datos aprovechan las herramientas creadas para controlar el rendimiento y la salud de las bases de datos. Se ocupan de tareas que van desde desentrañar y diagnosticar los obstáculos al rendimiento hasta ejecutar cambios en el esquema de la base de datos.
Cuando busques en el mercado una herramienta de gestión de bases de datos que satisfaga los requisitos de tu empresa, debes buscar herramientas que puedan incorporar las tareas de prueba, desarrollo de bases de datos y despliegue al proceso de entrega continua e integración continua, facilitando así el desarrollo de la aplicación.
Una herramienta eficaz de gestión de bases de datos debe permitir también la visualización de datos a partir de resultados tabulares en tablas, histogramas y gráficos, con una fácil distribución a los responsables de la toma de decisiones. También debe ayudar a los administradores a localizar los problemas antes de que se produzcan en la producción, localizando las sentencias SQL y las aplicaciones que no escalan bien con el aumento del volumen de transacciones.
Adminer (antes conocido como phpMinAdmin) es una herramienta de gestión de bases de datos gratuita y de código abierto que ofrece montones de funciones útiles y una interfaz de usuario más elegante. Puedes desplegar fácilmente esta práctica herramienta de gestión de bases de datos en tu servidor, y todo lo que tienes que hacer es subir su único archivo PHP, apuntar tu navegador a él e iniciar sesión.
Utilizar un plugin de base de datos
Si quieres evaluar la calidad de un sitio web, no busques más allá de su base de datos. Cada grano de información asociado a tu sitio web llega a tu base de datos de WordPress. Parte de ella es crucial, mientras que otra simplemente te frena. Esto incluiría tablas malas, borradores antiguos, comentarios de spam. Para evitar que obstaculicen tu sitio web, necesitas incorporar plugins de base de datos de WordPress.
Los plugins de base de datos pueden presentarse de varias formas. Algunos plugins pueden utilizarse para limpiar la base de datos de archivos basura de forma mensual o semanal. Otros plugins pueden aprovecharse para hacer una copia de seguridad de tu base de datos antes de realizar cambios, por ejemplo, durante una migración. Además de mejorar la velocidad de tu sitio web, puedes utilizar los plugins de base de datos para ofrecer una experiencia de usuario más eficiente, al tiempo que mejoras tus posibilidades de posicionarte mejor en los motores de búsqueda.
Diagnosticar y reparar tu base de datos
Como usuario de WordPress, es probable que te hayas topado con un par de errores molestos de WordPress. Aquí tienes uno de los mensajes de error más comunes con los que te puedes haber encontrado:
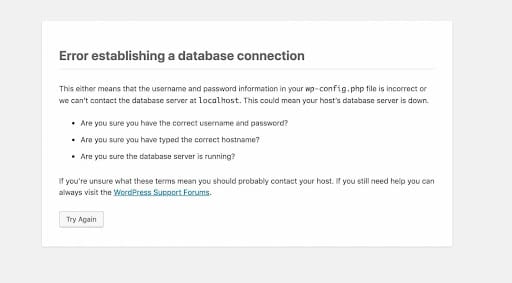
La importancia de arreglar tu base de datos debería ser bastante obvia. Los errores de WordPress no sólo dificultan el buen funcionamiento de tu sitio web, sino que pueden tener un efecto perjudicial en la experiencia del consumidor. Las instalaciones y actualizaciones fallidas, el tiempo de inactividad y la falta de recursos pueden hacer mella en tu potencial de ganancias y perjudicar tu credibilidad.
Resumen
PostgreSQL es un sistema de gestión de bases de datos relacionales gratuito y de código abierto que se centra en el cumplimiento y la extensibilidad de SQL. Tras más de 30 años de desarrollo activo, PostgreSQL es una de las herramientas de bases de datos de código abierto más utilizadas en todo el mundo.
En este artículo, cubrimos algunas de las características más destacadas de PostgreSQL, la arquitectura de PostgreSQL, sus casos de uso, las ventajas, los retos operativos y las principales alternativas. Terminamos con algunas prácticas recomendadas para mantener tu base de datos de WordPress en condiciones óptimas mientras sigues escalando.

Salman Ravoof es desarrollador web autodidacta, escritor, creador y un gran admirador del Software Libre y de Código Abierto (FOSS, Free and Open Source Software). Además de la tecnología, le apasionan la ciencia, la filosofía, la fotografía, las artes, los gatos y la comida. Obtén más información sobre él en su sitio web, y conecta con Salman en X.


{kind=link}