
El almacenamiento persistente se refiere a la retención de datos de forma no volátil, de modo que sigan estando disponibles incluso después de que un dispositivo o aplicación se apague o reinicie. El almacenamiento y la recuperación de datos permiten a las aplicaciones web guardar la información y los estados del usuario y funcionar de forma fiable.
En las aplicaciones monolíticas, el acceso al almacenamiento es sencillo porque el servidor y el almacenamiento conviven juntos. Sin embargo, los sistemas distribuidos geográficamente hacen que el acceso sea más complejo, ya que el sistema de almacenamiento debe permanecer disponible para todos los componentes en todo el mundo.
La contenedorización complica aún más la cuestión, porque los contenedores son ligeros, sin estado y efímeros, características inadecuadas para almacenar datos. Por tanto, cualquier solución de almacenamiento persistente debe ser capaz de trabajar sin problemas con contenedores, lo que añade otra capa de complejidad.
La plataforma de Alojamiento de Aplicaciones en contenedores de Kinsta utiliza volúmenes persistentes Kubernetes para asociar el almacenamiento persistente con uno o más procesos de una aplicación. Los usuarios de Kinsta pueden definir sus requisitos de almacenamiento persistente mientras crean aplicaciones en el panel MyKinsta.
Este artículo analiza el almacenamiento persistente independientemente de la plataforma, explorando sus tipos, arquitectura y casos de uso. También proporciona una demostración práctica que ilustra la diferencia entre el almacenamiento de volumen y el almacenamiento de volumen persistente en Docker.
Tipos de Almacenamiento Persistente
Existen varios tipos de almacenamiento no volátil, como los discos giratorios tradicionales (discos duros o HDD), las unidades de estado sólido (SSD), el almacenamiento conectado a la red (NAS) y las redes de área de almacenamiento (SAN).
- Los HDD son dispositivos electromecánicos de almacenamiento de datos que almacenan y recuperan datos digitales mediante discos giratorios de soporte magnético. Los discos utilizan cabezales magnéticos en un brazo actuador móvil que lee y escribe datos.
- Los SSD, a veces llamados dispositivos de almacenamiento semiconductores, dispositivos de estado sólido o discos de estado sólido, utilizan conjuntos de circuitos integrados para almacenar datos de forma persistente, normalmente utilizando dispositivos flash interconectados que no contienen piezas móviles. Su naturaleza estacionaria los hace más rápidos y fiables que los HDD.
- El almacenamiento conectado a red es un grupo de HDD, SSD o ambos, conectados a través de una red local mediante un sistema de archivos como el Sistema de Archivos de Nueva Tecnología (NTFS) o el cuarto sistema de archivos extendido (EXT4).
- Las SAN son dispositivos de almacenamiento en red de alta velocidad y a nivel de bloque, como las bibliotecas de cintas o las matrices de discos. Su conexión aparece ante el sistema operativo como almacenamiento local y no es accesible a través de la red de área local (LAN).
Arquitectura del Almacenamiento Persistente
Hay tres enfoques del almacenamiento persistente, cada uno con casos de uso y limitaciones únicos.
Arquitectura persistente de objetos
El enfoque de la arquitectura persistente de objetos utiliza el mapeo objeto-relacional (ORM) para almacenar los datos como objetos en una base de datos relacional o de valores clave. Este enfoque es útil cuando los datos no tienen un esquema definido, ya que el ORM se encarga de su almacenamiento y recuperación.
Arquitectura persistente de bloques
La arquitectura persistente de bloques utiliza dispositivos de almacenamiento a nivel de bloque, que son útiles cuando se almacenan archivos de gran tamaño. Este enfoque es beneficioso cuando se almacenan grandes cantidades de datos, ya que puedes utilizar varios bloques para aumentar la capacidad de almacenamiento.
Arquitectura persistente de almacén de archivos
Como su nombre indica, la arquitectura persistente de almacén de archivos utiliza un sistema de archivos para almacenar datos. Un método consiste en utilizar servidores de bases de datos, que proporcionan una forma centralizada de almacenar datos. Las soluciones de alojamiento en la nube, como las de Kinsta, utilizan servidores de bases de datos que se conectan fácilmente a las aplicaciones y ofrecen persistencia.
La arquitectura de almacenamiento persistente es útil en aplicaciones que requieren la recuperación frecuente de archivos y cuando necesitas una interfaz para gestionarlos.
Casos de uso del almacenamiento persistente
Esta sección trata algunos de los casos de uso de cada tipo de almacenamiento.
Almacenamiento persistente de objetos
- Almacenamiento en la nube: El almacenamiento persistente de objetos se utiliza habitualmente en las soluciones de almacenamiento en la nube para almacenar y recuperar grandes cantidades de datos no estructurados, como imágenes, vídeos y documentos. Los proveedores de la nube utilizan el almacenamiento de objetos para ofrecer a los clientes servicios de almacenamiento escalables, de alta disponibilidad y duraderos.
- Análisis de big data: El almacenamiento persistente de objetos se utiliza en la analítica de big data para almacenar y gestionar grandes conjuntos de datos utilizados a menudo para el análisis de datos, el aprendizaje automático y la IA. El almacenamiento de objetos permite acceder a los datos de forma rápida y eficaz, lo que lo convierte en un componente clave de las arquitecturas de big data.
- Redes de distribución de contenidos: El almacenamiento persistente de objetos se utiliza en las redes de distribución de contenidos (CDN) para almacenar y distribuir contenidos, como imágenes, vídeos y archivos estáticos, a través de una red global de servidores. El almacenamiento de objetos permite a las CDN entregar contenidos de alta velocidad a usuarios de todo el mundo, independientemente de su ubicación.
Almacenamiento persistente en bloque
- Informática de alto rendimiento (HPC): Los entornos HPC procesan de forma rápida y eficiente volúmenes considerables de datos. El almacenamiento persistente en bloque permite a los clusters de HPC almacenar y recuperar grandes conjuntos de datos, como simulaciones científicas, modelos meteorológicos y análisis financieros. A menudo se prefiere el almacenamiento en bloque para la HPC porque proporciona un acceso de alto rendimiento y baja latencia a los datos, y permite operaciones paralelas de entrada/salida (E/S), que pueden mejorar significativamente los tiempos de procesamiento.
- Edición de vídeo: Las aplicaciones de edición de vídeo requieren un acceso de alto rendimiento y baja latencia a grandes archivos de vídeo. También deben acomodar un número significativo de operaciones de E/S por segundo y baja latencia para renderizar y editar archivos de vídeo en tiempo real. El almacenamiento en bloque proporciona estas capacidades, por lo que es una solución ideal para los flujos de trabajo de edición de vídeo.
- Juegos: Las aplicaciones de juegos también exigen alto rendimiento y baja latencia para acceder a los activos del juego y a los datos de los jugadores. El almacenamiento en bloque almacena y recupera rápidamente grandes cantidades de datos, garantizando que los entornos de juego se carguen rápidamente y sigan respondiendo durante la partida.
Almacenamiento persistente Filestore
- Medios de comunicación y entretenimiento: Las aplicaciones de edición de vídeo, animación y renderizado suelen utilizar almacenamiento persistente. Estas aplicaciones requieren un acceso de alto rendimiento y baja latencia a archivos multimedia de gran tamaño, como vídeo, audio e imágenes. Filestore proporciona un sistema de archivos compartido al que pueden acceder varios clientes, lo que lo convierte en una solución de almacenamiento ideal para estas aplicaciones.
- Gestión de contenidos web: Los sistemas de gestión de contenidos web (CMS) utilizan el almacenamiento persistente de Filestore en sistemas de archivos compartidos para almacenar y gestionar contenidos de sitios web, como texto, imágenes y archivos multimedia. Filestore proporciona una ubicación central para el contenido del sitio web, facilitando su gestión y actualización. También permite que varios usuarios trabajen simultáneamente en el mismo contenido, mejorando la colaboración y la productividad.
Almacenamiento Persistente en Contenedores
Los contenedores son ligeros, portátiles, seguros y sencillos, y ofrecen una fusión entre distintas aplicaciones. Deben tener un mecanismo para persistir los datos entre reinicios y eliminaciones del contenedor. Los contenedores tienen almacenamiento de archivos o un sistema de archivos como las aplicaciones tradicionales, pero cada vez que los reconstruyes con nuevos cambios, pierdes todos los datos no persistentes.
Por eso los contenedores ofrecen la opción de incluir un volumen de almacenamiento o montar un volumen de almacenamiento. Los contenedores tratan los volúmenes de almacenamiento como un directorio. Cualquier dato escrito en el volumen va al sistema de archivos del contenedor.
El almacenamiento persistente para contenedores debe funcionar de este modo porque al reiniciar un contenedor se crea una nueva instancia y se descarta la antigua. Si un contenedor no tiene una visión consistente de los datos, éstos desaparecerán cuando se reinicie el contenedor. Un volumen de almacenamiento conserva los datos a través de las sesiones y los reinicios del contenedor, permitiendo que éste mantenga su estado aunque se mueva o se reinicie.
Volumen vs Volumen Persistente
Los contenedores ofrecen 2 formas de almacenar datos persistentes: mediante volúmenes y mediante volúmenes persistentes. Hay una diferencia significativa entre ellos. Un contenedor gestiona los datos almacenados en volúmenes. Cuando detienes un contenedor, los datos permanecen y están disponibles cuando reinicias el contenedor. Sin embargo, cuando borras o eliminas un contenedor, los datos se pierden, ya que también borras el almacenamiento en volumen subyacente.
El almacenamiento de volumen persistente o bind mounts es una forma de almacenar los datos fuera del sistema de archivos del contenedor. De esta forma, los datos no se pierden aunque borres el contenedor. Son persistentes hasta que se borran manualmente.
La siguiente sección muestra ambos tipos de volumen con ejemplos.
Demostración de Almacenamiento Persistente en Contenedores
Hemos creado una pequeña aplicación web para demostrar el almacenamiento persistente con contenedores Docker. Puedes seguirla instalando Docker y utilizando el código de este repositorio de GitHub.
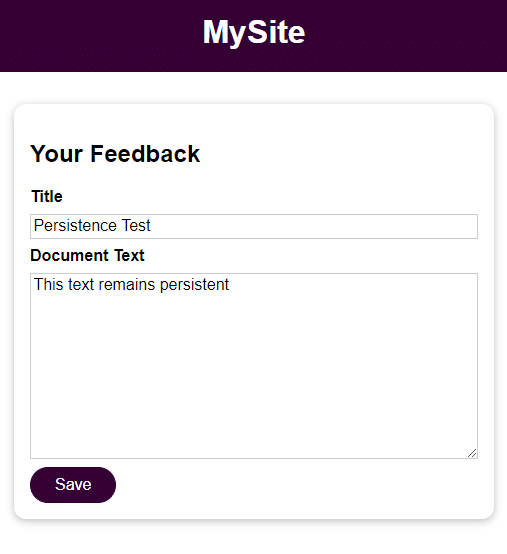
La aplicación es un formulario elemental con 2 campos para la entrada del usuario:
- Título
- Texto del documento
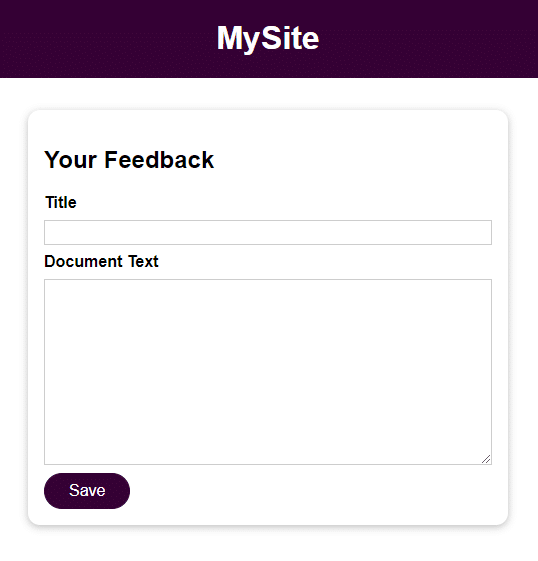
Una vez guardada la entrada del usuario, puedes acceder a ella abriendo el archivo en el directorio de respuesta con el nombre proporcionado en el campo Título. La entrada del campo Texto del Documento es el contenido del archivo.
Cómo utilizar el Almacenamiento en Volumen
Una vez que hayas instalado la aplicación en tu propia máquina, puede utilizar el almacenamiento por volumen como se muestra en el archivo Dockerfile.
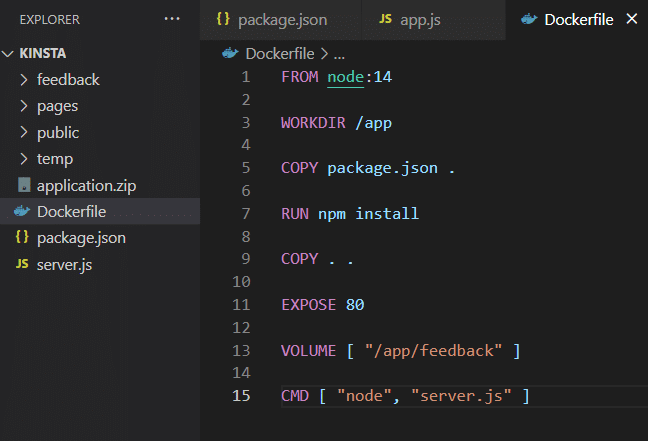
Ahora, construye la imagen y ejecuta el contenedor. Para ello, ejecuta los siguientes comandos.
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app feedback-node:volumes
Una vez que se ejecute la aplicación, navega a localhost:3000 para enviar comentarios.
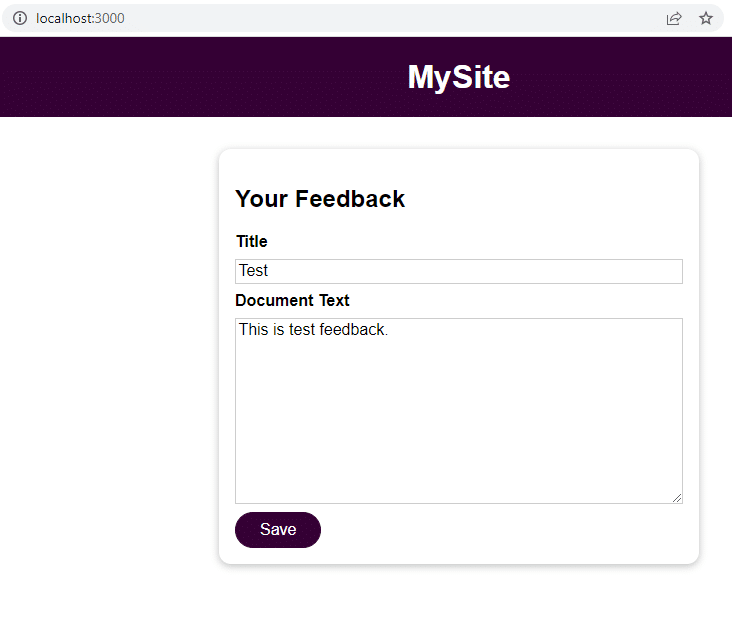
Haz clic en Guardar y navega a localhost:3000/feedback/test.txt para ver si la entrada se ha almacenado correctamente o no.
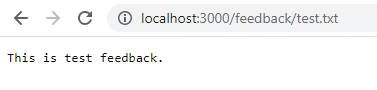
Elimina y reinicia el contenedor para ver si la entrada persiste.
docker stop feedback-app
docker start feedback-appSi ahora visitas la misma URL, verás que la respuesta sigue ahí. Pero, ¿qué ocurre si eliminas el contenedor y lo reinicias?
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app feedback-node:volumesUna vez reiniciado, si vuelves a esa URL, ya no existe porque los datos se perdieron cuando eliminaste el contenedor. Los datos de volumen sólo persisten cuando se detiene el contenedor, no cuando se elimina.
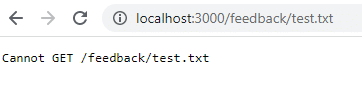
Para mitigar este problema y que los datos persistan incluso cuando eliminas el contenedor, debes utilizar un almacenamiento de volumen persistente o un almacenamiento con nombre. En primer lugar, debes limpiar los contenedores y las imágenes.
docker stop feedback-app
docker rm feedback-app
docker rmi feedback-node:volumesCómo utilizar el almacenamiento de volumen persistente
Antes de probarlo, debes eliminar el atributo VOLUMEN del archivo Dockerfile y reconstruir la imagen.
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesComo puedes ver, en el segundo comando, utilizas la bandera -v para definir el volumen persistente fuera del contenedor, que persiste incluso cuando eliminas el contenedor.
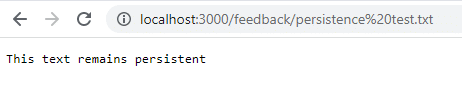
Como en el paso anterior, prueba a añadir la retroalimentación y accede a ella una vez que detengas, elimines y reinicies el contenedor.
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesComo ves, incluso después de parar y quitar el contenedor, los datos son accesibles y permanecen.
Resumen
El almacenamiento persistente es vital para las aplicaciones en contenedores porque permite persistir los datos fuera del ciclo de vida de un contenedor. Los 2 tipos principales de almacenamiento persistente para aplicaciones en contenedores son los volúmenes y los montajes bind, cada uno con sus ventajas y casos de uso.
Los volúmenes se almacenan dentro del sistema de archivos del contenedor, mientras que los montajes de enlace son directamente accesibles en la máquina del host.
El almacenamiento persistente permite compartir datos entre contenedores, haciendo posible construir aplicaciones complejas de varios niveles. El almacenamiento persistente es esencial para garantizar la estabilidad y continuidad de las aplicaciones en contenedores, proporcionando una forma fiable y flexible de almacenar datos cruciales.
¿Estás desarrollando una aplicación que requiere almacenamiento persistente? Explora nuestra biblioteca de ejemplos de inicio rápido para ver cómo implementar tu aplicación en Kinsta desde alojamientos Git como GitHub, GitLab y Bitbucket.
Nuestra documentación oficial sobre Almacenamiento Persistente te ayudará a poner tu aplicación y tus datos online rápidamente.

Steve Bonisteel es un Editor Técnico de Kinsta que comenzó su carrera de redactor como periodista de prensa escrita, persiguiendo ambulancias y camiones de bomberos. Lleva tratando temas relacionados con la tecnología de Internet desde finales de la década de 1990.

