
A medida que evoluciona el desarrollo de aplicaciones, las bases de datos se erigen en el núcleo de la mayoría de las aplicaciones, almacenando y gestionando datos cruciales para los negocios digitales. A medida que estos datos crecen y se hacen más complejos, garantizar la eficiencia de tu base de datos es vital para satisfacer las necesidades de tu aplicación.
Ahí es donde entra en juego la idea del mantenimiento de la base de datos. El mantenimiento de la base de datos implica tareas como la limpieza, las copias de seguridad y la optimización de los índices para aumentar el rendimiento.
Este artículo ofrece información valiosa sobre los disparadores de mantenimiento y presenta instrucciones prácticas de configuración. Explica el proceso de implementación de varias tareas de mantenimiento de bases de datos, como hacer copias de seguridad de los datos, reconstruir índices, archivar y limpiar datos utilizando PostgreSQL, integrado con un disparador API en una aplicación Node.js.
Entender los Disparadores
Antes de crear operaciones de mantenimiento para tu base de datos, es importante comprender las distintas formas en que se pueden disparar. Cada desencadenante sirve para fines distintos a la hora de facilitar las tareas de mantenimiento. Los tres disparadores principales que se utilizan habitualmente son:
- Manual, basado en API: Este disparador te permite ejecutar operaciones puntuales mediante una llamada a la API. Es útil en situaciones como la restauración de una copia de seguridad de la base de datos o la reconstrucción de índices cuando el rendimiento cae repentinamente.
- Programado (como CRON): Este disparador te permite automatizar actividades de mantenimiento programadas durante periodos de bajo tráfico de usuarios. Es ideal para ejecutar operaciones que consumen muchos recursos, como el archivado y la limpieza. Puedes utilizar paquetes como node-schedule para configurar programaciones en Node.js que disparen las operaciones automáticamente cuando sea necesario.
- Notificaciones de la base de datos: Este disparador te permite realizar operaciones de mantenimiento en respuesta a cambios en la base de datos. Por ejemplo, cuando un usuario publica un comentario en una plataforma, los datos guardados pueden disparar instantáneamente comprobaciones de caracteres irregulares, lenguaje ofensivo o emojis. Implementar esta funcionalidad en Node.js es posible utilizando paquetes como pg-listen.
Requisitos Previos
Para seguir esta guía, debes tener las siguientes herramientas en tu ordenador local:
- Git: Para gestionar el control de versiones del código fuente de tu aplicación
- Node.js: Para construir tu aplicación backend
- psql: Para interactuar con tu base de datos PostgreSQL remota utilizando tu terminal
- PGAdmin (Opcional): Para interactuar con tu base de datos PostgreSQL remota utilizando una Interfaz Gráfica de Usuario (GUI).
Crear y Alojar una Aplicación Node.js
Vamos a crear un proyecto Node.js, hacer commit en GitHub y configurar un canal de despliegue automático en Kinsta. También necesitas aprovisionar una base de datos PostgreSQL en Kinsta para probar tus rutinas de mantenimiento en ella.
Empieza creando un nuevo directorio en tu sistema local utilizando el siguiente comando:
mkdir node-db-maintenanceA continuación, cambia a la carpeta recién creada y ejecuta el siguiente comando para crear un nuevo proyecto:
cd node-db-maintenance
yarn init -y # or npm init -yEsto inicializa un proyecto Node.js para ti con la configuración por defecto. Ahora puedes instalar las dependencias necesarias ejecutando el siguiente comando:
yarn add express pg nodemon dotenvAquí tienes una breve descripción de cada paquete:
express: te permite configurar una API REST basada en Express.pg: te permite interactuar con una base de datos PostgreSQL a través de tu aplicación Node.js.nodemonpermite que tu versión de desarrollo (dev build) se actualice a medida que desarrollas tu aplicación, liberándote de la constante necesidad de parar e iniciar tu aplicación cada vez que haces un cambio.dotenv: te permite cargar variables de entorno de un archivo .env en tu objetoprocess.env.
A continuación, añade los siguientes scripts en tu archivo package.json para que puedas iniciar fácilmente tu servidor dev y ejecutar también tu servidor en producción:
{
// ...
"scripts": {
"start-dev": "nodemon index.js",
"start": "NODE_ENV=production node index.js"
},
// …
}Ahora puedes crear un archivo index.js que contenga el código fuente de tu aplicación. Pega el siguiente código en el archivo:
const express = require("express")
const dotenv = require('dotenv');
if (process.env.NODE_ENV !== 'production') dotenv.config();
const app = express()
const port = process.env.PORT || 3000
app.get("/health", (req, res) => res.json({status: "UP"}))
app.listen(port, () => {
console.log(`Server running at port: ${port}`);
});Este código anterior inicializa un servidor Express y configura variables de entorno utilizando el paquete dotenv si no está en modo de producción. También configura una ruta /health que devuelve un objeto JSON {status: "UP"}. Por último, inicia la aplicación utilizando la función app.listen() para escuchar en el puerto especificado, por defecto 3000 si no se proporciona ningún puerto a través de la variable de entorno.
Ahora que ya tienes lista una aplicación básica, inicializa un nuevo repositorio git con tu proveedor git preferido (BitBucket, GitHub o GitLab) y envía tu código. Kinsta soporta el despliegue de aplicaciones desde todos estos proveedores git. Para este artículo, vamos a utilizar GitHub.
Cuando tu repositorio esté listo, sigue estos pasos para desplegar tu aplicación en Kinsta:
- Inicia sesión o crea una cuenta para ver tu panel MyKinsta.
- Autoriza a Kinsta con tu proveedor de Git.
- En la barra lateral izquierda, haz clic en Aplicaciones y luego en Añadir aplicación.
- Selecciona el repositorio y la rama desde la que deseas desplegar.
- Selecciona una de las ubicaciones de centros de datos disponibles en la lista de 28 opciones. Kinsta detecta automáticamente la configuración de construcción de tus aplicaciones a través de Nixpacks.
- Elige los recursos de tu aplicación, como RAM y espacio en disco.
- Haz clic en Crear aplicación.
Una vez completado el despliegue, copia el enlace de la aplicación desplegada y navega a /health. Deberías ver el siguiente JSON en tu navegador:
{status: "UP"}Esto indica que la aplicación se ha configurado correctamente.
Configurar una Instancia PostgreSQL en Kinsta
Kinsta proporciona una interfaz sencilla para aprovisionar instancias de bases de datos. Empieza por crear una nueva cuenta Kinsta si aún no tienes una. A continuación, sigue los siguientes pasos:
- Accede a tu panel MyKinsta.
- En la barra lateral izquierda, haz clic en Bases de datos y luego en Añadir base de datos.
- Selecciona PostgreSQL como tipo de Base de Datos y elige la versión que prefieras. Elige un nombre para tu base de datos y modifica el nombre de usuario y la contraseña si lo deseas.
- Selecciona una ubicación de centro de datos de la lista de 28 opciones.
- Elige el tamaño de tu base de datos.
- Haz clic en Crear base de datos.
Una vez creada la base de datos, asegúrate de recuperar el host, el puerto, el nombre de usuario y la contraseña de la base de datos.
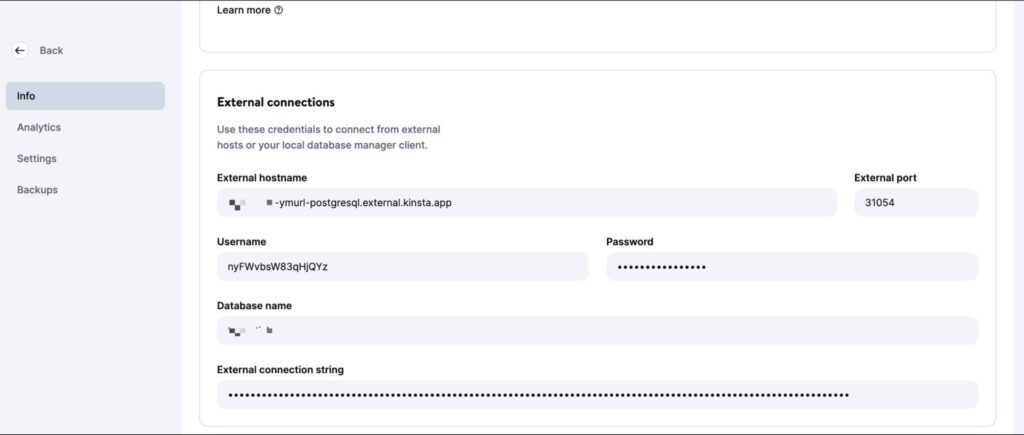
A continuación, puedes introducir estos valores en tu CLI psql (o GUI PGAdmin) para gestionar la base de datos. Para probar tu código localmente, crea un archivo .env en el directorio root de tu proyecto y almacena en él los siguientes secretos:
DB_USER_NAME=your database user name
DB_HOST=your database host
DB_DATABASE_NAME=your database’s name
DB_PORT=your database port
PGPASS=your database passwordCuando despliegues en Kinsta, deberás añadir estos valores como variables de entorno al despliegue de tu aplicación.
Para prepararte para las operaciones con la base de datos, descarga y ejecuta este script SQL para crear tablas (usuarios, entradas, comentarios) e insertar datos de ejemplo. Utiliza el siguiente comando, sustituyendo los marcadores de posición por tus datos específicos, para añadir los datos a tu base de datos PostgreSQL recién creada:
psql -h <host> -p <port> -U <username> -d <db_name> -a -f <sql file e.g. test-data.sql>Asegúrate de introducir el nombre de archivo y la ruta exactos en el comando anterior. La ejecución de este comando te pide que introduzcas la contraseña de tu base de datos para autorizarte.
Una vez que este comando termine de ejecutarse, estarás listo para empezar a escribir operaciones para el mantenimiento de tu base de datos. No dudes en enviar tu código a tu repositorio Git cuando termines con cada operación para verlo en acción en la plataforma Kinsta.
Escribir Rutinas de Mantenimiento
En esta sección se explican varias operaciones de uso común para el mantenimiento de bases de datos PostgreSQL.
1. Crear Copias de Seguridad
Hacer copias de seguridad periódicas de las bases de datos es una operación común y esencial. Consiste en crear una copia de todo el contenido de la base de datos, que se almacena en una ubicación segura. Estas copias de seguridad son cruciales para restaurar los datos en caso de pérdida accidental o de errores que afecten a su integridad.
Aunque plataformas como Kinsta ofrecen copias de seguridad automatizadas como parte de sus servicios, es importante saber cómo configurar una rutina de copia de seguridad personalizada si es necesario.
PostgreSQL ofrece la herramienta pg_dump para crear copias de seguridad de la base de datos. Sin embargo, debe ejecutarse directamente desde la línea de comandos, y no existe un paquete npm para ella. Así que tienes que utilizar el paquete @getvim/execute para ejecutar el comando pg_dump en el entorno local de tu aplicación Node.
Instala el paquete ejecutando el siguiente comando:
yarn add @getvim/executeA continuación, importa el paquete en tu archivo index.js añadiendo esta línea de código en la parte superior:
const {execute} = require('@getvim/execute');Las copias de seguridad se generan como archivos en el sistema de archivos local de tu aplicación Node. Por tanto, es mejor crear un directorio dedicado para ellas con el nombre de backup en el directorio root del proyecto.
Ahora, puedes utilizar la siguiente ruta para generar y descargar copias de seguridad de tu base de datos cuando sea necesario:
app.get('/backup', async (req, res) => {
// Create a name for the backup file
const fileName = "database-backup-" + new Date().valueOf() + ".tar";
// Execute the pg_dump command to generate the backup file
execute("PGPASSWORD=" + process.env.PGPASS + " pg_dump -U " + process.env.DB_USER_NAME
+ " -d " + process.env.DB_DATABASE_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -f backup/" + fileName + " -F t"
).then(async () => {
console.log("Backup created");
res.redirect("/backup/" + fileName)
}).catch(err => {
console.log(err);
res.json({message: "Something went wrong"})
})
})Además, tienes que añadir la siguiente línea al principio de tu archivo index.js después de inicializar la aplicación Express:
app.use('/backup', express.static('backup'))Esto permite que la carpeta de backup se sirva estáticamente utilizando la función de middleware express.static, permitiendo al usuario descargar los archivos de copia de seguridad generados desde la app Node.
2. Restaurar Desde una Copia de Seguridad
Postgres permite restaurar a partir de copias de seguridad utilizando la herramienta de línea de comandos pg_restore. Sin embargo, tienes que utilizarla a través del paquete execute de forma similar a como utilizaste el comando pg_dump. Aquí tienes el código de la ruta:
app.get('/restore', async (req, res) => {
const dir = 'backup'
// Sort the backup files according to when they were created
const files = fs.readdirSync(dir)
.filter((file) => fs.lstatSync(path.join(dir, file)).isFile())
.map((file) => ({ file, mtime: fs.lstatSync(path.join(dir, file)).mtime }))
.sort((a, b) => b.mtime.getTime() - a.mtime.getTime());
if (!files.length){
res.json({message: "No backups available to restore from"})
}
const fileName = files[0].file
// Restore the database from the chosen backup file
execute("PGPASSWORD=" + process.env.PGPASS + " pg_restore -cC "
+ "-U " + process.env.DB_USER_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -d postgres backup/" + fileName
)
.then(async ()=> {
console.log("Restored");
res.json({message: "Backup restored"})
}).catch(err=> {
console.log(err);
res.json({message: "Something went wrong"})
})
})El fragmento de código anterior busca primero los archivos almacenados en el directorio local de la copia de seguridad. Después, los ordena por la fecha en que se crearon para encontrar el archivo de copia de seguridad más reciente. Por último, utiliza el paquete execute para restaurar el archivo de copia de seguridad elegido.
Asegúrate de añadir los siguientes imports a tu archivo index.js para que se importen los módulos necesarios para acceder al sistema de archivos local, permitiendo que la función se ejecute correctamente:
const fs = require('fs')
const path = require('path')3. Reconstruir un Índice
Los índices de las tablas Postgres a veces se corrompen, y el rendimiento de la base de datos se degrada. Esto puede deberse a fallos o errores de software. A veces, los índices también pueden hincharse debido a demasiadas páginas vacías o casi vacías.
En estos casos, tienes que reconstruir el índice para asegurarte de que obtienes el máximo rendimiento de tu instancia Postgres.
Postgres ofrece el comando REINDEX para este fin. Puedes utilizar el paquete node-postgres para ejecutar este comando (y también para ejecutar otras operaciones más adelante), así que instálalo ejecutando primero el siguiente comando:
yarn add pgA continuación, añade las siguientes líneas al principio del archivo index.js, debajo de las importaciones, para inicializar correctamente la conexión a la base de datos:
const {Client} = require('pg')
const client = new Client({
user: process.env.DB_USER_NAME,
host: process.env.DB_HOST,
database: process.env.DB_DATABASE_NAME,
password: process.env.PGPASS,
port: process.env.DB_PORT
})
client.connect(err => {
if (err) throw err;
console.log("Connected!")
})La implementación de esta operación es bastante sencilla:
app.get("/reindex", async (req, res) => {
// Run the REINDEX command as needed
await client.query("REINDEX TABLE Users;")
res.json({message: "Reindexed table successfully"})
})El comando mostrado anteriormente reindexa la tabla Usuarios completa. Puedes personalizar el comando según tus necesidades para reconstruir un índice concreto o incluso para reindexar toda la base de datos.
4. Archivo y Purga de Datos
Para las bases de datos que crecen con el tiempo (y a las que rara vez se accede a los datos históricos), puede tener sentido establecer rutinas que descarguen los datos antiguos en un lago de datos donde puedan almacenarse y procesarse más cómodamente.
Los archivos Parquet son un estándar común para el almacenamiento y transferencia de datos en muchos lagos de datos. Utilizando la biblioteca ParquetJS, puedes crear archivos parquet a partir de tus datos Postgres y utilizar servicios como AWS Athena para leerlos directamente sin necesidad de volver a cargarlos en la base de datos en el futuro.
Instala la biblioteca ParquetJS ejecutando el siguiente comando:
yarn add parquetjsAl crear archivos, necesitas consultar un gran número de registros de tus tablas. Almacenar tal cantidad de datos en la memoria de tu aplicación puede consumir muchos recursos, ser costoso y propenso a errores.
Por lo tanto, tiene sentido utilizar cursores para cargar trozos de datos de la base de datos y procesarlos. Instala el módulo cursors del paquete node-postgres ejecutando el siguiente comando:
yarn add pg-cursorA continuación, asegúrate de importar ambas bibliotecas en tu archivo index.js:
const Cursor = require('pg-cursor')
const parquet = require('parquetjs')Ahora, puedes utilizar el fragmento de código siguiente para crear archivos de parquet a partir de tu base de datos:
app.get('/archive', async (req, res) => {
// Query all comments through a cursor, reading only 10 at a time
// You can change the query here to meet your requirements, such as archiving records older than at least a month, or only archiving records from inactive users, etc.
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
// Define the schema for the parquet file
let schema = new parquet.ParquetSchema({
comment_id: { type: 'INT64' },
post_id: { type: 'INT64' },
user_id: { type: 'INT64' },
comment_text: { type: 'UTF8' },
timestamp: { type: 'TIMESTAMP_MILLIS' }
});
// Open a parquet file writer
let writer = await parquet.ParquetWriter.openFile(schema, 'archive/archive.parquet');
let rows = await cursor.read(10)
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// Write each row from table to the parquet file
await writer.appendRow(rows[i])
}
rows = await cursor.read(10)
}
await writer.close()
// Once the parquet file is generated, you can consider deleting the records from the table at this point to free up some space
// Redirect user to the file path to allow them to download the file
res.redirect("/archive/archive.parquet")
})A continuación, añade el siguiente código al principio de tu archivo index.js después de inicializar la aplicación Express:
app.use('/archive', express.static('archive'))Esto permite que la carpeta archive se sirva estáticamente, permitiéndote descargar del servidor los archivos de parquet generados.
No olvides crear el directorio archive en el directorio del proyecto para almacenar los ficheros de archivo.
Puedes personalizar aún más este fragmento de código para subir automáticamente los archivos de parquet a un bucket de AWS S3 y utilizar trabajos CRON para activar la operación en una rutina automáticamente.
5. Limpieza de Datos
Un propósito común para ejecutar operaciones de mantenimiento de bases de datos es limpiar los datos que envejecen o se vuelven irrelevantes con el tiempo. En esta sección se tratan dos casos comunes en los que se realizan limpiezas de datos como parte del mantenimiento.
En realidad, puedes configurar tu propia rutina de limpieza de datos según requieran los modelos de datos de tu aplicación. Los ejemplos que se dan a continuación son sólo de referencia.
Borrar Registros por Antigüedad (Última Modificación o Último Acceso)
Limpiar registros en función de su antigüedad es relativamente sencillo en comparación con otras operaciones de esta lista. Puedes escribir una consulta de eliminación que borre los registros que sean anteriores a una fecha establecida.
Aquí tienes un ejemplo para borrar comentarios anteriores al 9 de octubre de 2023:
app.get("/clean-by-age", async (req, res) => {
// Filter and delete all comments that were made on or before 9th October, 2023
const result = await client.query("DELETE FROM COMMENTS WHERE timestamp < '09-10-2023 00:00:00'")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})Puedes probarlo enviando una solicitud GET a la ruta /clean-by-age.
Borrar Registros Basándose en Condiciones Personalizadas
También puedes configurar limpiezas basadas en otras condiciones, como eliminar registros que no estén vinculados a otros registros activos en el sistema (creando una situación de orfandad ).
Por ejemplo, puedes configurar una operación de limpieza que busque comentarios vinculados a entradas eliminadas y los elimine, ya que probablemente nunca vuelvan a aparecer en la aplicación:
app.get('/conditional', async (req, res) => {
// Filter and delete all comments that are not linked to any active posts
const result = await client.query("DELETE FROM COMMENTS WHERE post_id NOT IN (SELECT post_id from Posts);")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})Puedes idear tus propias condiciones específicas para tu caso de uso.
6. Manipulación de Datos
Las operaciones de mantenimiento de bases de datos también se utilizan para realizar manipulaciones y transformaciones de datos, como censurar lenguaje obsceno o convertir combinaciones de texto en emoji.
A diferencia de la mayoría de las demás operaciones, es mejor ejecutar estas operaciones cuando se producen actualizaciones de la base de datos (en lugar de ejecutarlas en todas las filas en un momento fijo de la semana o del mes).
En esta sección se enumeran dos de estas operaciones, pero la implementación para cualquier otra operación de manipulación personalizada sigue siendo bastante similar a éstas.
Convertir Texto en Emoji
Puedes considerar convertir combinaciones de texto como «:)» y «xD» en emojis reales para ofrecer una mejor experiencia al usuario y mantener también la coherencia de la información. Aquí tienes un fragmento de código que te ayudará a hacerlo:
app.get("/emoji", async (req, res) => {
// Define a list of emojis that need to be converted
const emojiMap = {
xD: '😁',
':)': '😊',
':-)': '😄',
':jack_o_lantern:': '🎃',
':ghost:': '👻',
':santa:': '🎅',
':christmas_tree:': '🎄',
':gift:': '🎁',
':bell:': '🔔',
':no_bell:': '🔕',
':tanabata_tree:': '🎋',
':tada:': '🎉',
':confetti_ball:': '🎊',
':balloon:': '🎈'
}
// Build the SQL query adding conditional checks for all emojis from the map
let queryString = "SELECT * FROM COMMENTS WHERE"
queryString += " COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[0] + "%' "
if (Object.keys(emojiMap).length > 1) {
for (let i = 1; i < Object.keys(emojiMap).length; i++) {
queryString += " OR COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[i] + "%' "
}
}
queryString += ";"
const result = await client.query(queryString)
if (result.rowCount === 0) {
res.json({message: "No rows to clean up!"})
} else {
for (let i = 0; i < result.rows.length; i++) {
const currentRow = result.rows[i]
let emoji
// Identify each row that contains an emoji along with which emoji it contains
for (let j = 0; j < Object.keys(emojiMap).length; j++) {
if (currentRow.comment_text.includes(Object.keys(emojiMap)[j])) {
emoji = Object.keys(emojiMap)[j]
break
}
}
// Replace the emoji in the text and update the row before moving on to the next row
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + currentRow.comment_text.replace(emoji, emojiMap[emoji]) + "' WHERE COMMENT_ID = " + currentRow.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "All emojis cleaned up successfully!"})
}
})Este fragmento de código primero requiere que definas una lista de emojis y sus representaciones textuales. Después, consulta la base de datos para buscar esas combinaciones textuales y las sustituye por emojis.
Censura el Lenguaje Obsceno
Una operación bastante habitual en las aplicaciones que permiten contenidos generados por los usuarios es censurar cualquier lenguaje indecente. El enfoque aquí es similar — identifica los casos de lenguaje obsceno y sustitúyelos por caracteres asterisco. Puedes utilizar el paquete bad-words (malas-palabras) para comprobar y censurar fácilmente las blasfemias.
Instala el paquete ejecutando el siguiente comando:
yarn add bad-wordsA continuación, inicializa el paquete en tu archivo index.js:
const Filter = require('bad-words');
filter = new Filter();Ahora, utiliza el siguiente fragmento de código para censurar el contenido obsceno en tu tabla de comentarios:
app.get('/obscene', async (req, res) => {
// Query all comments using a cursor, reading only 10 at a time
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
let rows = await cursor.read(10)
const affectedRows = []
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// Check each comment for profane content
if (filter.isProfane(rows[i].comment_text)) {
affectedRows.push(rows[i])
}
}
rows = await cursor.read(10)
}
cursor.close()
// Update each comment that has profane content with a censored version of the text
for (let i = 0; i < affectedRows.length; i++) {
const row = affectedRows[i]
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + filter.clean(row.comment_text) + "' WHERE COMMENT_ID = " + row.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "Cleanup complete"})
})Puedes encontrar el código completo de este tutorial en este repositorio de GitHub.
Comprender el Vacuum de PostgreSQL y su Finalidad
Aparte de configurar rutinas de mantenimiento personalizadas como las comentadas anteriormente, también puedes hacer uso de una de las funcionalidades de mantenimiento nativas que ofrece PostgreSQL para garantizar la salud y el rendimiento continuos de tu base de datos: el proceso Vacuum.
El proceso Vacuum ayuda a optimizar el rendimiento de la base de datos y a recuperar espacio en disco. PostgreSQL ejecuta operaciones de vacuum de manera programada mediante su daemon de auto-vacuum, pero también puedes activarlo manualmente si es necesario. A continuación, se presentan algunas maneras en las que el vacuuming frecuente es beneficioso:
- Recuperar espacio de disco bloqueado: Uno de los principales objetivos de Vacuum es recuperar el espacio de disco bloqueado en la base de datos. Como los datos se insertan, actualizan y eliminan constantemente, PostgreSQL puede llenarse de filas «muertas» u obsoletas que siguen ocupando espacio en el disco. Vacuum identifica y elimina estas filas muertas, dejando el espacio disponible para nuevos datos. Sin Vacuum, el espacio en disco se agotaría gradualmente, lo que podría provocar una degradación del rendimiento e incluso fallos del sistema.
- Actualizar las Métricas del Planificador de Consultas: Vacuuming también ayuda a PostgreSQL a mantener actualizadas las estadísticas y métricas utilizadas por su planificador de consultas. El planificador de consultas depende de una distribución precisa de los datos y de la información estadística para generar planes de ejecución eficientes. Al ejecutar regularmente Vacuum, PostgreSQL se asegura de que estas métricas están actualizadas, lo que le permite tomar mejores decisiones sobre cómo recuperar datos y optimizar las consultas.
- Actualizar el Mapa de Visibilidad: El Mapa de Visibilidad es otro aspecto crucial del proceso Vacuum de PostgreSQL. Ayuda a identificar qué bloques de datos de una tabla son totalmente visibles para todas las transacciones, lo que permite a Vacuum seleccionar sólo los bloques de datos necesarios para su limpieza. Esto aumenta la eficacia del proceso Vacuum al minimizar las operaciones de E/S innecesarias, que serían costosas y llevarían mucho tiempo.
- Prevención de Fallos por Envoltura de ID de Transacción: Vacuum también desempeña un papel fundamental en la prevención de fallos de envoltura del ID de transacción. PostgreSQL utiliza un contador de ID de transacción de 32 bits, que puede provocar un wraparound cuando alcanza su valor máximo. Vacuum marca las transacciones antiguas como «congeladas», evitando que el contador de ID se envuelva y provoque la corrupción de los datos. Descuidar este aspecto podría provocar fallos catastróficos en la base de datos.
Como ya se ha dicho, PostgreSQL ofrece dos opciones para ejecutar Vacuum: Autovacuum y Vacuum Manual.
Autovacuum es la opción recomendada para la mayoría de los escenarios, ya que gestiona automáticamente el proceso de Vacuum basándose en ajustes predefinidos y en la actividad de la base de datos. El Vacuum Manual, en cambio, proporciona más control, pero requiere un conocimiento más profundo del mantenimiento de la base de datos.
La decisión entre ambos depende de factores como el tamaño de la base de datos, la carga de trabajo y los recursos disponibles. Las bases de datos de tamaño pequeño o mediano pueden confiar a menudo en el Vacuum Automático, mientras que las bases de datos más grandes o complejas pueden requerir la intervención manual.
Resumen
El mantenimiento de las bases de datos no es sólo una cuestión de limpieza rutinaria; es la base de una aplicación sana y eficaz. Optimizando, limpiando y organizando tus datos con regularidad, te aseguras de que tu base de datos PostgreSQL siga ofreciendo el máximo rendimiento, se mantenga libre de corrupción y funcione con eficacia, incluso cuando tu aplicación se amplíe.
En esta completa guía, exploramos la importancia crítica de establecer planes de mantenimiento de bases de datos bien estructurados para PostgreSQL cuando se trabaja con Node.js y Express.
¿Hemos pasado por alto alguna operación rutinaria de mantenimiento de bases de datos que hayas implementado para tu base de datos? ¿O conoces una forma mejor de poner en práctica alguna de las comentadas anteriormente? ¡No dudes en hacérnoslo saber en los comentarios!

Kumar es desarrollador de software y editor técnico residente en la India. Está especializado en JavaScript y DevOps. Puedes obtener más información sobre su trabajo en su sitio web.

