
¿Has oído alguna vez el término robots.txt y te has preguntado cómo se utiliza en tu sitio web? La mayoría de los sitios web tienen un archivo robots.txt, pero eso no significa que la mayoría de los propietarios de sitios lo entiendan. En este post, esperamos cambiar eso ofreciendo una inmersión profunda en el archivo robots.txt de WordPress, así como en la forma en que puede controlar y limitar el acceso a tu sitio.
Hay mucho que tratar, ¡así que empecemos!
¿Qué es el Archivo Robots.txt de WordPress?
Antes de hablar del archivo robots.txt de WordPress, es importante definir qué es un «robot» en este caso. Los robots son cualquier tipo de «bot»que visita sitios web en Internet. El ejemplo más común son los rastreadores de los motores de búsqueda. Estos robots «rastrean»la web para ayudar a los motores de búsqueda como Google a indexar y clasificar los miles de millones de páginas de Internet.
Así que, los robots son, en general, algo bueno para Internet… o al menos algo necesario. Pero eso no significa necesariamente que tú, u otros propietarios de sitios web, queráis que los robots anden sueltos por ahí. El deseo de controlar la forma en que los robots web interactúan con los sitios web llevó a la creación de la norma de exclusión de robots a mediados de la década de 1990. Robots.txt es la aplicación práctica de esa norma — te permite controlar cómo interactúan los robots participantes con tu sitio. Puedes bloquear los robots por completo, restringir su acceso a determinadas áreas de tu sitio, etc.
Sin embargo, esa parte de «participar» es importante. Robots.txt no puede obligar a un bot a seguir sus directrices. Y los robots maliciosos pueden ignorar el archivo robots.txt, y lo harán. Además, incluso las organizaciones reputadas ignoran algunas órdenes que puedes poner en robots.txt. Por ejemplo, Google ignorará cualquier regla que añadas a tu robots.txt sobre la frecuencia de visita de sus rastreadores. Puedes ajustar la frecuencia con la que Google rastrea tu sitio web en la página Configuración de la frecuencia de rastreo de tu propiedad en Google Search Console.
Si tienes muchos problemas con los robots, una solución de seguridad como Cloudflare o Sucuri puede resultarte útil.
¿Cómo Encontrar robots.txt?
El archivo robots.txt vive en el root de tu sitio web, por lo que añadir /robots.txt después de tu dominio debería cargar el archivo (si tienes uno). Por ejemplo, https://kinsta.com/robots.txt.
¿Cuándo Debes Utilizar un Archivo robots.txt?
Para la mayoría de los propietarios de sitios web, las ventajas de un archivo robots.txt bien estructurado se reducen a dos categorías:
- Optimizar los recursos de rastreo de los motores de búsqueda diciéndoles que no pierdan tiempo en páginas que no quieres que se indexen. Esto ayuda a garantizar que los motores de búsqueda se centren en rastrear las páginas que más te interesan.
- Optimizar el uso de tu servidor bloqueando los robots que malgastan recursos.
Robots.txt no Pretende Controlar Específicamente qué Páginas se Indexan en los Buscadores
Robots.txt no es una forma infalible de controlar qué páginas indexan los buscadores. Si tu objetivo principal es impedir que determinadas páginas se incluyan en los resultados de los motores de búsqueda, lo adecuado es utilizar una etiqueta meta noindex o una protección por contraseña.
Esto se debe a que tu robots.txt no está diciendo directamente a los motores de búsqueda que no indexen el contenido, sólo les está diciendo que no lo rastreen. Aunque Google no rastreará las áreas marcadas desde dentro de tu sitio, el propio Google afirma que si un sitio externo enlaza con una página que excluyes con tu archivo robots.txt, Google podría indexar esa página.
John Mueller, Analista de Google Webmaster, también ha confirmado que si una página tiene enlaces que apuntan a ella, aunque esté bloqueada por robots.txt, podría seguir siendo indexada. A continuación se muestra lo que dijo en un hangout de Webmaster Central:
Una cosa que quizá haya que tener en cuenta aquí es que si estas páginas están bloqueadas por robots.txt, entonces teóricamente podría ocurrir que alguien enlazara al azar a una de estas páginas. Y si lo hace, podría ocurrir que indexáramos esta URL sin ningún contenido porque está bloqueada por robots.txt. Así que no sabríamos que no quieres que se indexen estas páginas.
Mientras que si no están bloqueadas por robots.txt puedes poner una metaetiqueta noindex en esas páginas. Y si alguien enlaza con ellas, y nosotros rastreamos ese enlace y pensamos que puede haber algo útil aquí, sabremos que esas páginas no necesitan ser indexadas y podremos omitirlas por completo de la indexación.
Así que, en ese sentido, si tienes algo en estas páginas que no quieres que se indexen, no las deshabilites, utiliza noindex en su lugar.
¿Necesito un Archivo robots.txt?
Es importante recordar que no es necesario que tengas un archivo robots.txt en tu sitio. Si no tienes ningún problema con que todos los robots tengan vía libre para rastrear todas tus páginas, entonces puedes optar por no molestarte en añadir uno, ya que no tienes instrucciones reales que dar a los rastreadores.
En algunos casos, puede que ni siquiera puedas añadir un archivo robots.txt debido a las limitaciones del CMS que estés utilizando. Esto está bien, y existen otros métodos para dar instrucciones a los robots sobre cómo rastrear tus páginas sin utilizar un archivo robots.txt.
¿Qué Código de Estado HTTP debe Devolver el Archivo robots.txt?
El archivo robots.txt debe devolver un código de estado HTTP 200 OK para que los rastreadores puedan acceder a él.
Si tienes problemas para que los motores de búsqueda indexen tus páginas, merece la pena que compruebes dos veces el código de estado que devuelve tu archivo robots.txt. Todo lo que no sea un código de estado 200 podría impedir que los rastreadores accedan a tu sitio.
Algunos propietarios de sitios han informado de la desindexación de páginas debido a que su archivo robots.txt devuelve un estado distinto de 200. Un propietario de un sitio web preguntó sobre un problema de indexación en un hangout de Google SEO office-hours en marzo de 2022 y John Mueller explicó que el archivo robots.txt debe devolver un estado 200 si está presente, o un estado 4XX si el archivo no existe. En este caso, se devolvía un error 500 de servidor interno, lo que, según Mueller, podría haber provocado que Googlebot excluyera el sitio de la indexación.
Lo mismo puede verse en este Tweet, en el que el propietario de un sitio informaba de que todo su sitio había sido desindexado debido a que un archivo robots.txt devolvía un error 500.
[Quick SEO tip]
If you are having issue with indexing, make sure your robots.txt file is returning either 200 or 404.
If your file returns 500, Google will eventually deindex your website, as I've seen with this project. pic.twitter.com/8KiYLgDVRo
— Antoine Eripret (@antoineripret) November 14, 2022
¿Se Puede Utilizar la Metaetiqueta Robots en Lugar de un Archivo robots.txt?
No. La metaetiqueta robots te permite controlar qué páginas se indexan, mientras que el archivo robots.txt te permite controlar qué páginas se rastrean. Los robots deben rastrear primero las páginas para poder ver las metaetiquetas, por lo que debes evitar intentar utilizar tanto una metaetiqueta disallow como una noindex, ya que la noindex no sería recogida.
Si tu objetivo es excluir una página de los motores de búsqueda, la metaetiqueta noindex suele ser la mejor opción.
Cómo Crear y Editar tu Archivo robots.txt de WordPress
Por defecto, WordPress crea automáticamente un archivo robots.txt virtual para tu sitio. Así que, aunque no muevas un dedo, tu sitio ya debería tener el archivo robots.txt por defecto. Puedes comprobar si es así añadiendo «/robots.txt» al final del nombre de tu dominio. Por ejemplo, «https://kinsta.com/robots.txt» muestra el archivo robots.txt que utilizamos en Kinsta.
Ejemplo de Archivo robots.txt
Aquí tienes un ejemplo del archivo robots.txt de Kinsta:
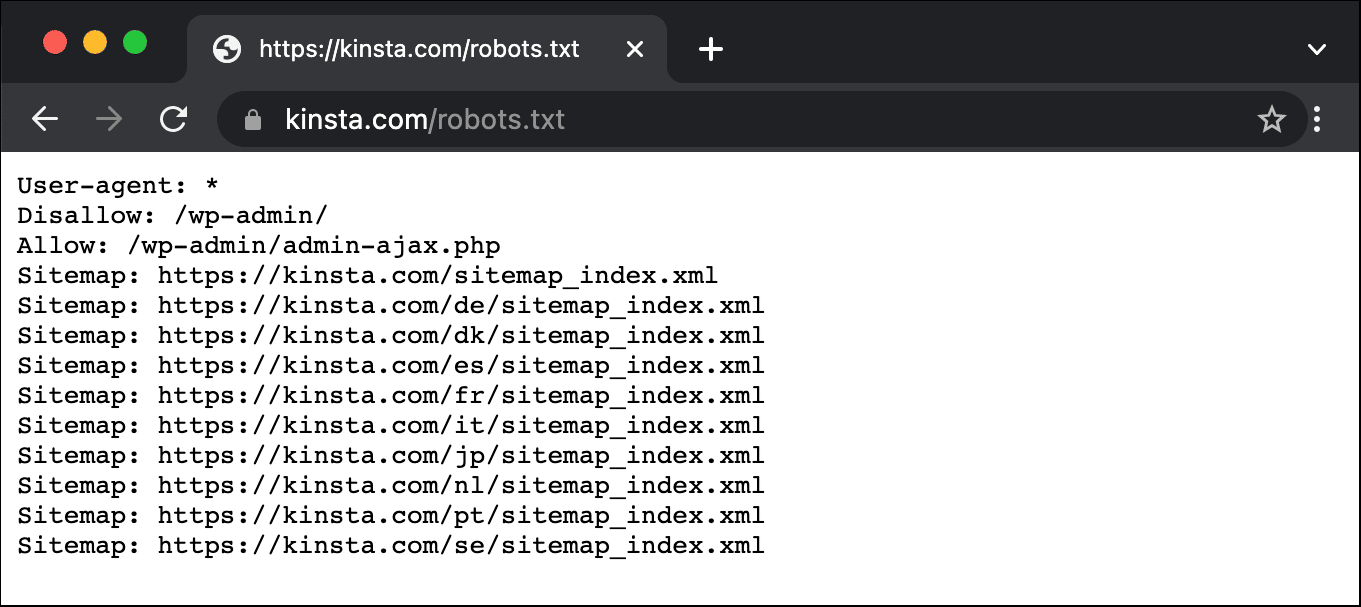
Esto proporciona a todos los robots instrucciones sobre qué rutas ignorar (por ejemplo, la ruta wp-admin), con sus excepciones (por ejemplo, el archivo admin-ajax.php), junto con las ubicaciones del mapa del sitio XML de Kinsta.
Sin embargo, como este archivo es virtual, no puedes editarlo. Si quieres editar tu archivo robots.txt, tendrás que crear un archivo físico en tu servidor que puedas manipular cuando sea necesario. Aquí tienes tres formas sencillas de hacerlo:
Cómo Crear y Editar un Archivo robots.txt en WordPress con Yoast SEO
Si utilizas el popular plugin Yoast SEO, puedes crear (y posteriormente editar) tu archivo robots.txt directamente desde la interfaz de Yoast. Sin embargo, antes de poder acceder a él, tienes que ir a SEO → Herramientas y hacer clic en Editor de archivos
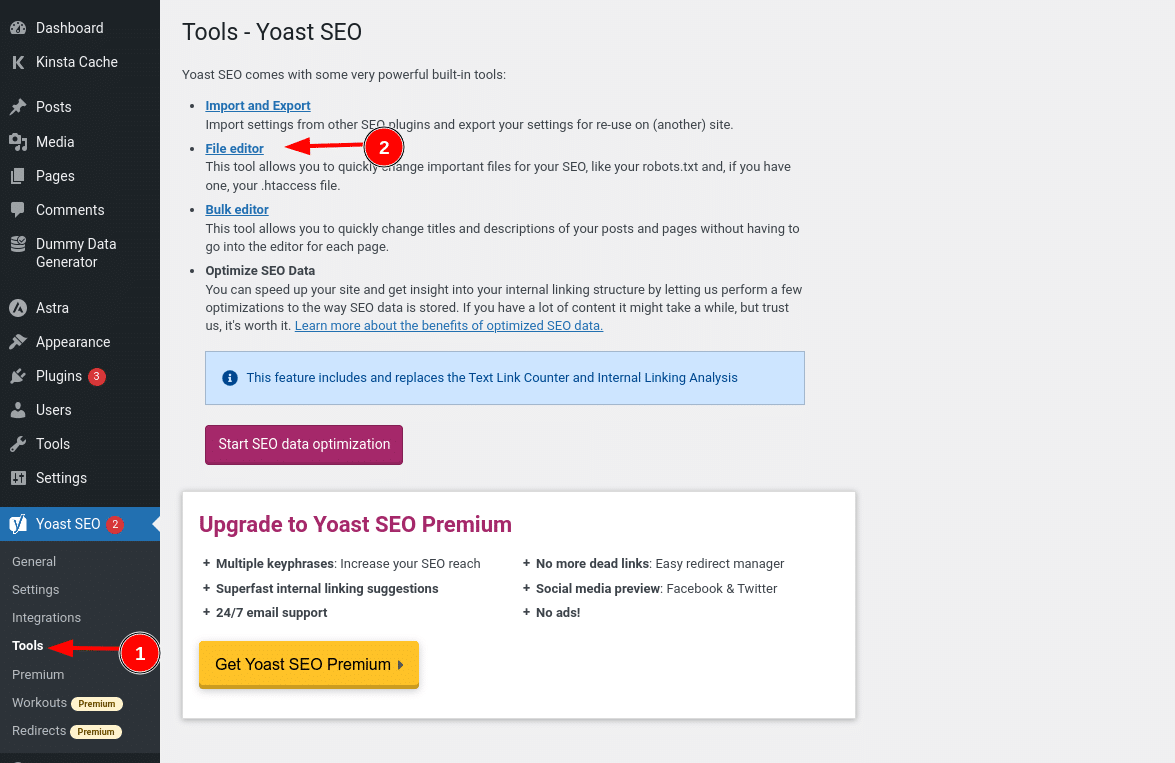
Y una vez que hagas clic en ese botón, podrás editar el contenido de tu archivo robots.txt directamente desde la misma interfaz y luego guardar los cambios realizados.
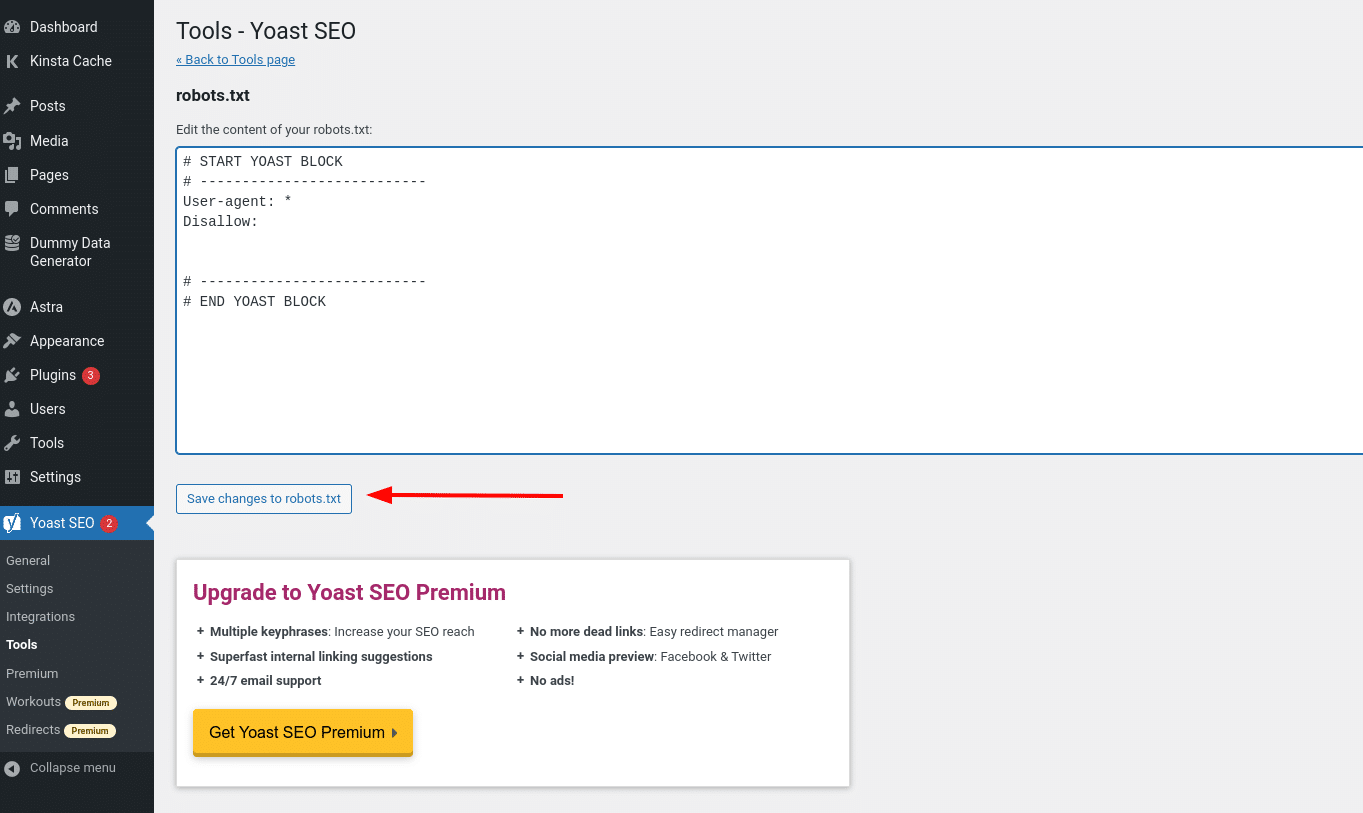
Suponiendo que aún no tengas un archivo robots.txt físico, Yoast te dará la opción de Crear archivo robots.txt:
A medida que sigas leyendo, profundizaremos en los tipos de directivas que debes incluir en tu archivo robots.txt de WordPress.
Cómo Crear y Editar un Archivo robots.txt con All in One SEO
Si utilizas el plugin All in One SEO Pack, casi tan popular como Yoast, también puedes crear y editar tu archivo robots.txt de WordPress directamente desde la interfaz del plugin. Todo lo que tienes que hacer es ir a All in One SEO → Herramientas:
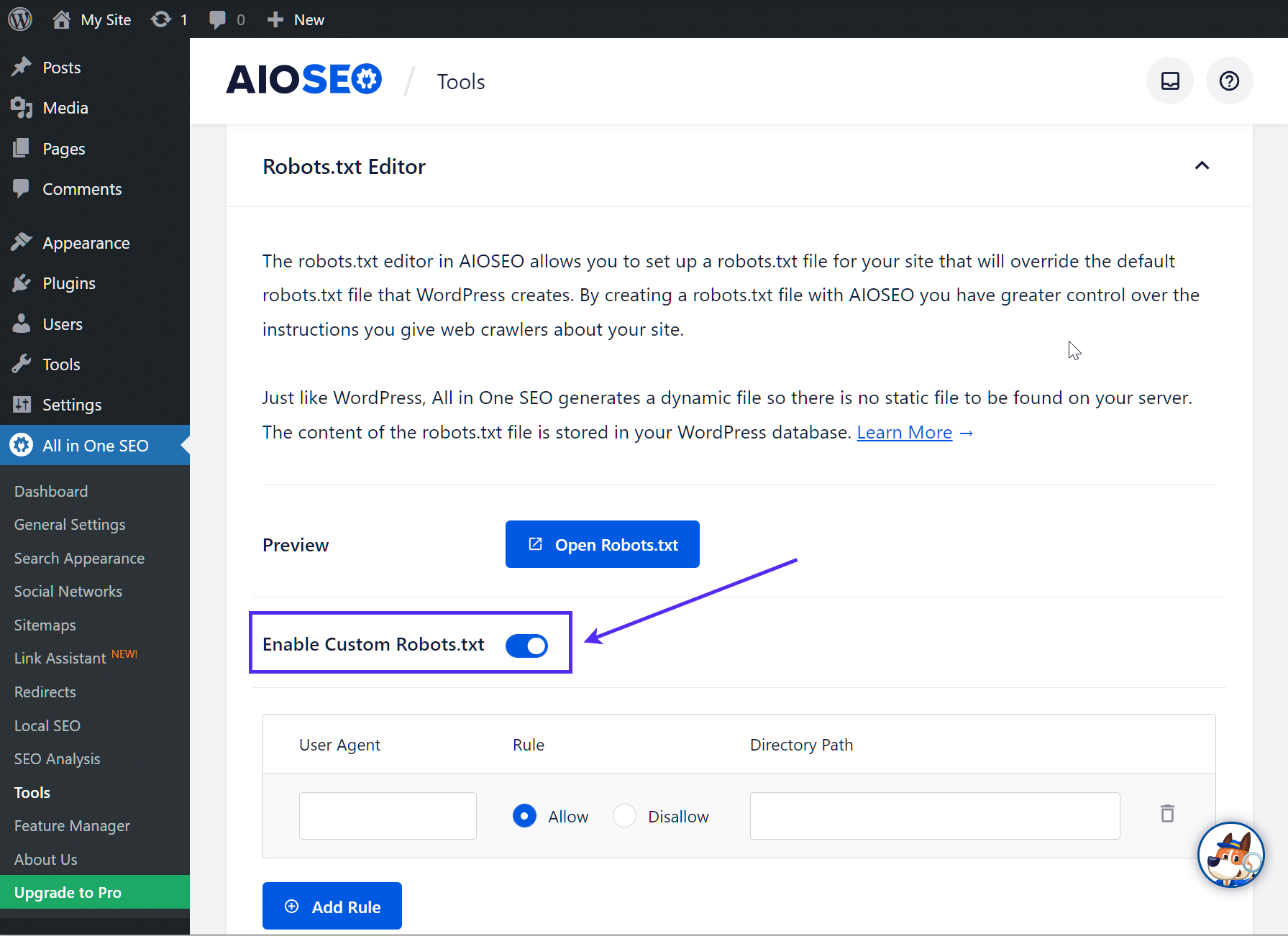
A continuación, activa el botón de opción Activar robots.txt Personalizados. Esto te permitirá crear reglas personalizadas y añadirlas a tu archivo robots.txt:
Cómo Crear y Editar un Archivo robots.txt mediante FTP
Si no utilizas un plugin SEO que ofrezca la funcionalidad robots.txt, puedes crear y gestionar tu archivo robots.txt a través de SFTP. En primer lugar, utiliza cualquier editor de texto para crear un archivo vacío llamado «robots.txt»:
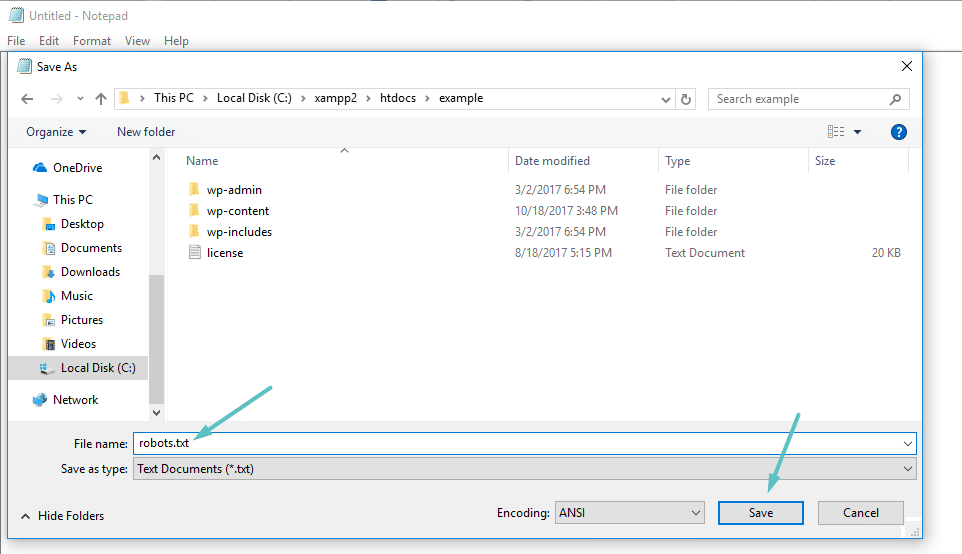
A continuación, conéctate a tu sitio mediante SFTP y sube ese archivo a la carpeta root de tu sitio. Puedes realizar más modificaciones en tu archivo robots.txt editándolo a través de SFTP o subiendo nuevas versiones del archivo.
Qué Poner en Tu Archivo robots.txt
Bien, ahora tienes un archivo robots.txt físico en tu servidor que puedes editar cuando lo necesites. Pero, ¿qué haces realmente con ese archivo? Bueno, como aprendiste en la primera sección, robots.txt te permite controlar cómo interactúan los robots con tu sitio. Lo haces con dos comandos principales:
- User-agent — te permite dirigirte a robots específicos. Los agentes de usuario son lo que utilizan los robots para identificarse. Con ellos puedes, por ejemplo, crear una regla que se aplique a Bing, pero no a Google.
- Disallow — te permite indicar a los robots que no accedan a determinadas áreas de tu sitio.
También hay un comando Allow que utilizarás en situaciones específicas. Por defecto, todo en tu sitio está marcado con Allow, por lo que no es necesario utilizar el comando Allow en el 99% de las situaciones. Pero resulta útil cuando quieres No Permitir (disallow) el acceso a una carpeta y a sus carpetas hijas, pero Permitir (allow) el acceso a una carpeta hija concreta.
Para añadir reglas, primero hay que especificar a qué User-agent se debe aplicar la regla y, a continuación, enumerar las reglas que se deben aplicar mediante Disallow y Allow. También hay algunos otros comandos como Crawl-delay y Sitemap, pero estos son:
- Ignorados por la mayoría de los rastreadores principales, o interpretados de formas muy diferentes (en el caso del retardo de rastreo)
- Redundantes gracias a herramientas como Google Search Console (para los sitemaps)
Veamos algunos casos de uso específicos para mostrarte cómo funciona todo esto.
Cómo Utilizar Robots.txt Disallow All para Bloquear el Acceso a Todo tu Sitio Web
Supongamos que quieres bloquear el acceso de todos los rastreadores a tu sitio. Es poco probable que esto ocurra en un sitio activo, pero resulta útil para un sitio en desarrollo. Para ello, añade el código robots.txt disallow all a tu archivo robots.txt de WordPress:
User-agent: *
Disallow: /¿Qué ocurre en ese código?
El *asterisco junto a User-agent significa «todos los agentes de usuario». El asterisco es un comodín, lo que significa que se aplica a todos los agentes de usuario. La barra / junto a Disallow indica que quieres denegar el acceso a todas las páginas que contengan «tudominio.com/» (es decir, todas las páginas de tu sitio).
Cómo Utilizar Robots.txt para Bloquear el Acceso de un Único Bot a tu Sitio Web
Vamos a cambiar las cosas. En este ejemplo, fingiremos que no te gusta que Bing rastree tus páginas. Eres del Equipo Google hasta el final y ni siquiera quieres que Bing eche un vistazo a tu sitio. Para impedir que sólo Bing rastree tu sitio, sustituirías el comodín *asterisk por Bingbot:
User-agent: Bingbot
Disallow: /Esencialmente, el código anterior dice que sólo se aplique la regla Disallow a los bots con el User-agent «Bingbot». Ahora bien, es poco probable que quieras bloquear el acceso a Bing, pero este escenario resulta útil si hay un bot específico que no quieres que acceda a tu sitio. Este sitio tiene una buena lista de los nombres de agente de usuario conocidos de la mayoría de los servicios.
Cómo Utilizar Robots.txt para Bloquear el Acceso a una Carpeta o Archivo Específico
Para este ejemplo, digamos que sólo quieres bloquear el acceso a un archivo o carpeta específicos (y a todas las subcarpetas de esa carpeta). Para que esto se aplique a WordPress, digamos que quieres bloquear:
- Toda la carpeta wp-admin
- wp-login.php
Podrías utilizar los siguientes comandos:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpCómo Utilizar Robots.txt Allow All para Dar a los Robots Acceso Completo a Tu Sitio Web
Si actualmente no tienes ninguna razón para bloquear el acceso de los rastreadores a ninguna de tus páginas, puedes añadir el siguiente comando.
User-agent: *
Allow: /
O alternativamente:
User-agent: *
Disallow:
Cómo Utilizar Robots.txt para Permitir el Acceso a un Archivo Específico en una Carpeta No Permitida
Vale, digamos que quieres bloquear una carpeta entera, pero quieres permitir el acceso a un archivo específico dentro de esa carpeta. Aquí es donde resulta útil el comando Allow. Y en realidad es muy aplicable a WordPress. De hecho, el archivo virtual robots.txt de WordPress ilustra perfectamente este ejemplo:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpEste fragmento bloquea el acceso a toda la carpeta /wp-admin/ excepto al archivo /wp-admin/admin-ajax.php.
Cómo Utilizar Robots.txt para Impedir que los Robots Rastreen los Resultados de Búsqueda de WordPress
Un ajuste específico de WordPress que tal vez quieras hacer es impedir que los robots de búsqueda rastreen tus páginas de resultados de búsqueda. Por defecto, WordPress utiliza el parámetro de consulta «?s=». Así que para bloquear el acceso, todo lo que tienes que hacer es añadir la siguiente regla:
User-agent: *
Disallow: /?s=
Disallow: /search/Esta puede ser una forma eficaz de detener también los errores soft 404 si los estás recibiendo. Asegúrate de leer nuestra guía detallada sobre cómo acelerar la búsqueda en WordPress.
Cómo Crear Diferentes Reglas para Diferentes Robots en Robots.txt
Hasta ahora, todos los ejemplos se han referido a una sola regla a la vez. Pero, ¿y si quieres aplicar reglas diferentes a distintos robots? Sólo tienes que añadir cada conjunto de reglas en el campo User-agent de cada bot. Por ejemplo, si quieres hacer una regla que se aplique a todos los bots y otra que se aplique sólo a Bingbot, podrías hacerlo así:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /En este ejemplo, todos los bots tendrán bloqueado el acceso a /wp-admin/, pero Bingbot no podrá acceder a todo tu sitio.
Probar Tu Archivo robots.txt
Para asegurarte de que tu archivo robots.txt se ha configurado correctamente y funciona según lo esperado, debes probarlo a fondo. Un sólo carácter mal colocado puede ser catastrófico para el rendimiento de un sitio en los motores de búsqueda, por lo que las pruebas pueden ayudar a evitar posibles problemas.
Comprobador de robots.txt de Google
La herramienta robots.txt Tester de Google (que antes formaba parte de Google Search Console) es fácil de usar y pone de manifiesto posibles problemas en tu archivo robots.txt.
Sólo tienes que acceder a la herramienta y seleccionar la propiedad del sitio que deseas comprobar, luego desplazarte hasta el final de la página e introducir cualquier URL en el campo, después hacer clic en el botón rojo PRUEBA:
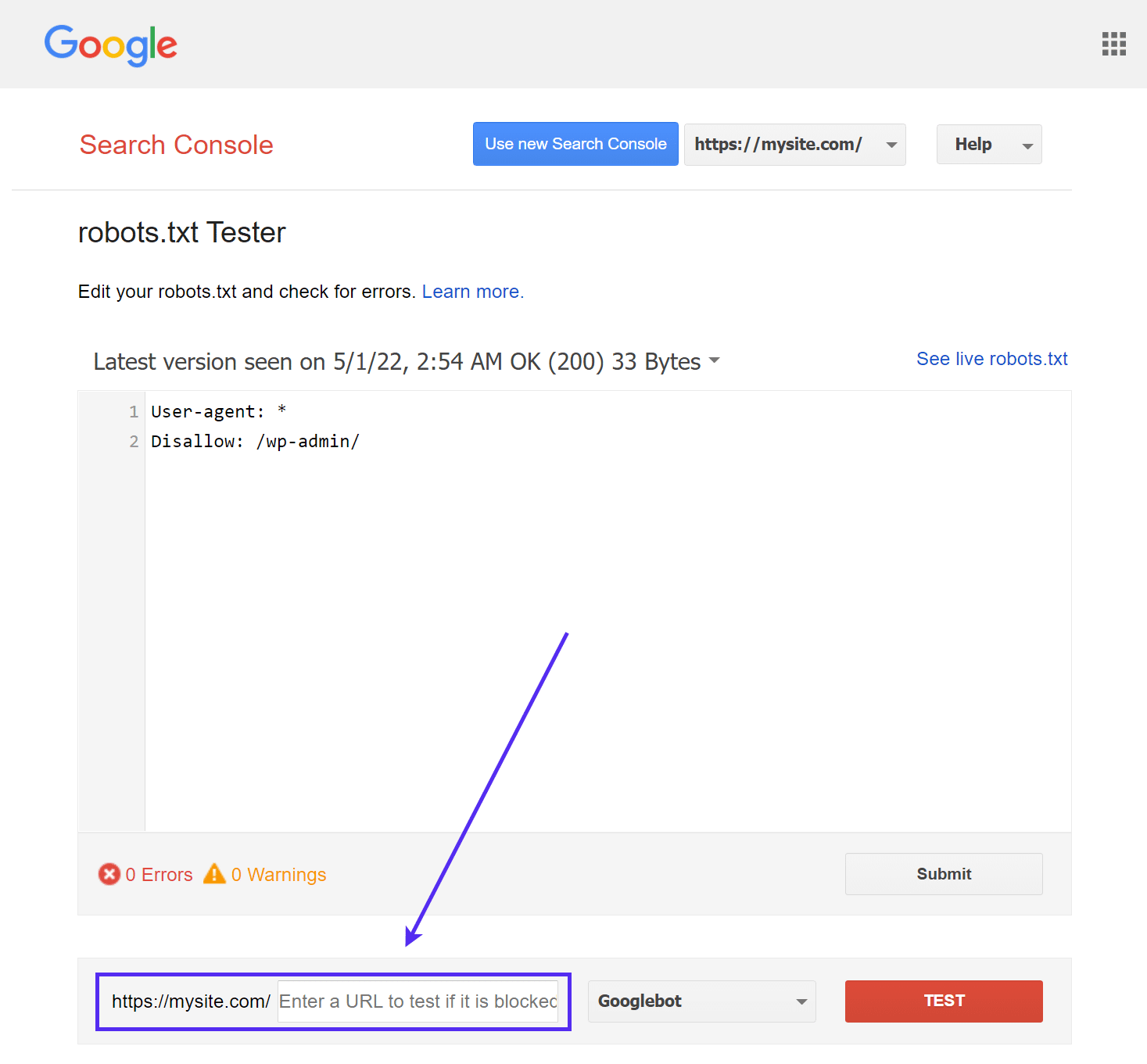
Verás una respuesta verde de Permitido si todo es rastreable.
También puedes seleccionar con qué versión de Googlebot quieres realizar la prueba, eligiendo entre Googlebot, Googlebot-News, Googlebot-Image, Googlebot-Video, Googlebot-Mobile, Mediapartners-Google o Adsbot-Google.
También puedes probar cada URL individual que hayas bloqueado para asegurarte de que, efectivamente, están bloqueadas y/o No Permitidas.
Cuidado con el UTF-8 BOM
BOM significa marca de orden de bytes y es básicamente un carácter invisible que a veces añaden a los archivos los viejos editores de texto y similares. Si esto ocurre con tu archivo robots.txt, Google podría no leerlo correctamente. Por eso es importante que compruebes si tu archivo contiene errores. Por ejemplo, como se ve a continuación, nuestro archivo tenía un carácter invisible y Google se queja de que no se entiende la sintaxis. Esto invalida por completo la primera línea de nuestro archivo robots.txt, ¡lo cual no es bueno! Glenn Gabe tiene un excelente artículo sobre cómo una Bom UTF-8 podría acabar con tu SEO.

Googlebot Se Basa Principalmente en EE.UU.
También es importante no bloquear el Googlebot de Estados Unidos, aunque te dirijas a una región local fuera de Estados Unidos. A veces hacen rastreo local, pero Googlebot se basa principalmente en Estados Unidos.
Googlebot is mostly US-based, but we also sometimes do local crawling. https://t.co/9KnmN4yXpe
— Google Search Central (@googlesearchc) November 13, 2017
Qué Ponen los Sitios Populares de WordPress en su Archivo Robots.txt
Para contextualizar un poco los puntos anteriores, a continuación te mostramos cómo utilizan sus archivos robots.txt algunos de los sitios más populares de WordPress.
TechCrunch
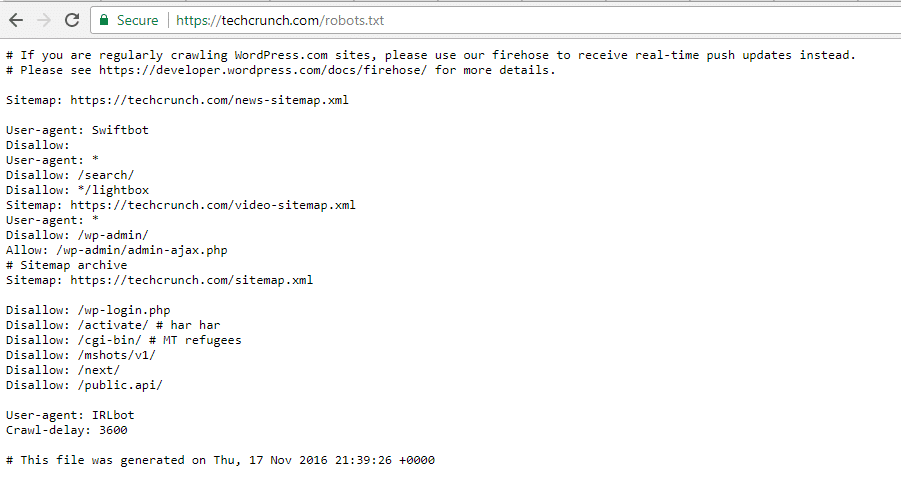
Además de restringir el acceso a una serie de páginas exclusivas, TechCrunch prohíbe especialmente a los rastreadores:
- /wp-admin/
- /wp-login.php
También han establecido restricciones especiales para dos robots:
- Swiftbot
- IRLbot
Por si te interesa, IRLbot es un rastreador de un proyecto de investigación de la Universidad A&M de Texas. ¡Qué raro!
La Fundación Obama
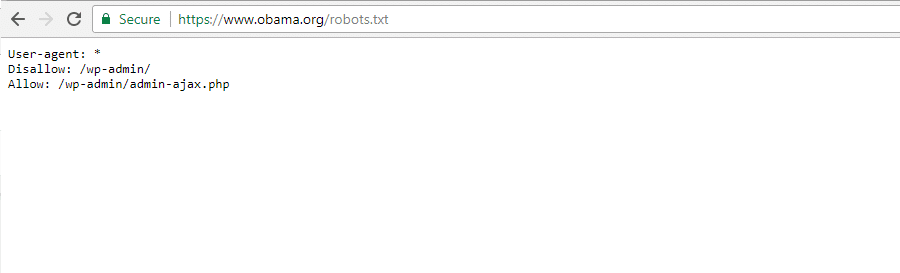
La Fundación Obama no ha hecho ninguna adición especial, optando exclusivamente por restringir el acceso a /wp-admin/.
Angry Birds
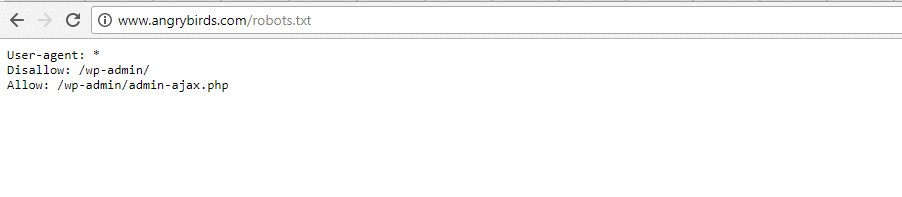
Angry Birds tiene la misma configuración por defecto que la Fundación Obama. No se añade nada especial.
Drift

Por último, Drift opta por definir sus sitemaps en el archivo Robots.txt, pero por lo demás, deja las mismas restricciones por defecto que La Fundación Obama y Angry Birds.
Utiliza Robots.txt de la Forma Correcta
Para terminar nuestra guía sobre robots.txt, queremos recordarte una vez más que utilizar un comando Disallow en tu archivo robots.txt no es lo mismo que utilizar una etiqueta noindex. Robots.txt bloquea el rastreo, pero no necesariamente la indexación. Puedes utilizarlo para añadir reglas específicas que configuren la forma en que los motores de búsqueda y otros robots interactúan con tu sitio, pero no controlará explícitamente si tu contenido se indexa o no.
Para la mayoría de los usuarios ocasionales de WordPress, no existe una necesidad urgente de modificar el archivo virtual robots.txt predeterminado. Pero si tienes problemas con un bot específico, o quieres cambiar la forma en que los motores de búsqueda interactúan con un determinado plugin o tema que estés utilizando, puede que quieras añadir tus propias reglas.
Esperamos que te haya gustado esta guía y asegúrate de dejar un comentario si tienes más preguntas sobre el uso del archivo robots.txt de WordPress.

Brian tiene una gran pasión por WordPress, lo ha estado utilizando durante más de 10 años e incluso ha desarrollado un par de plugins premium. Brian disfruta de los blogs, las películas y el senderismo. Conéctese con Brian en Twitter.

