
MySQL et MariaDB exploitent de manière transparente l’efficacité de l’indexation par arbre équilibré (B-Tree) pour optimiser les opérations sur les données. Ce mécanisme d’indexation partagée garantit une récupération rapide des données, améliore les performances des requêtes et minimise les entrées/sorties (E/S) sur disque, contribuant ainsi à une expérience de base de données plus réactive et plus efficace.
Cet article examine de plus près l’indexation, vous guide dans la création d’index et vous donne des conseils pour les utiliser plus efficacement dans les bases de données MySQL et MariaDB.
Qu’est-ce qu’un index ?
Lorsque vous interrogez une base de données MySQL pour obtenir des informations spécifiques, la requête recherche chaque ligne d’une table de base de données jusqu’à ce qu’elle trouve la bonne. Cette opération peut prendre beaucoup de temps, en particulier lorsque la base de données est volumineuse.
Les gestionnaires de bases de données utilisent l’indexation pour accélérer les processus de recherche de données et optimiser l’efficacité des requêtes. L’indexation construit une structure de données qui minimise la quantité de données à rechercher en les organisant de manière systématique, ce qui permet une exécution plus rapide et plus efficace des requêtes.
Supposons que vous souhaitiez trouver un client dont le prénom est Ava dans la table Clients suivante :
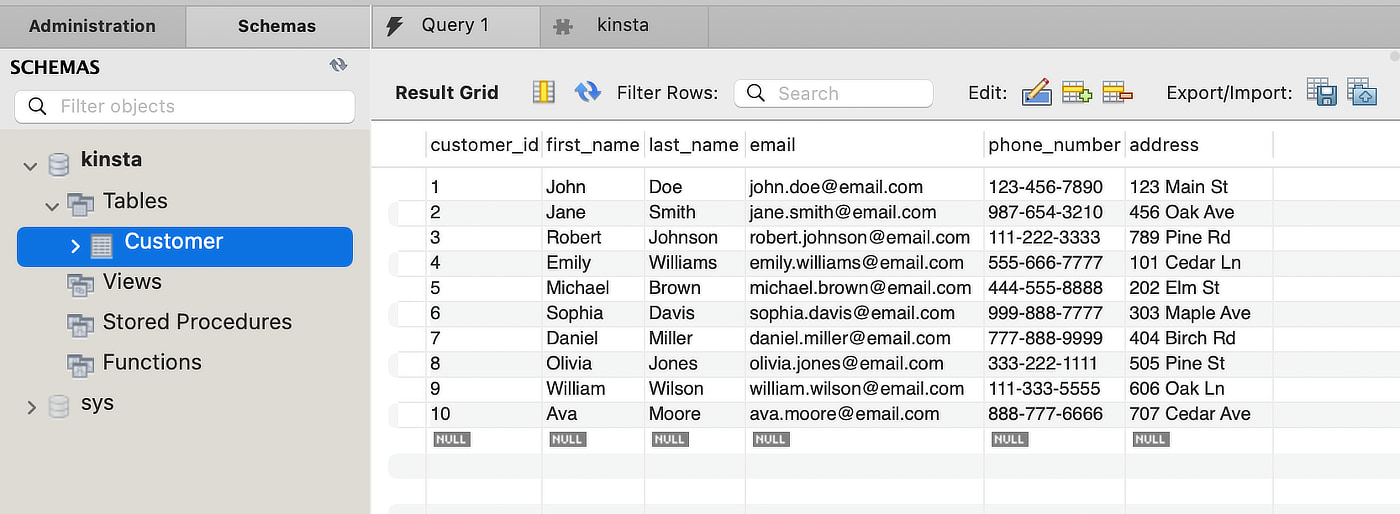
L’ajout d’un index B-Tree à la colonne first_name crée une structure qui facilite une recherche plus efficace des informations souhaitées. La structure ressemble à un arbre dont le nœud racine se trouve au sommet et qui se ramifie en nœuds feuilles au bas de l’arbre.
Elle est semblable à un arbre bien organisé, où chaque niveau guide la recherche en fonction de l’ordre de tri des données.
Cette image montre le chemin de recherche d’un index B-Tree :
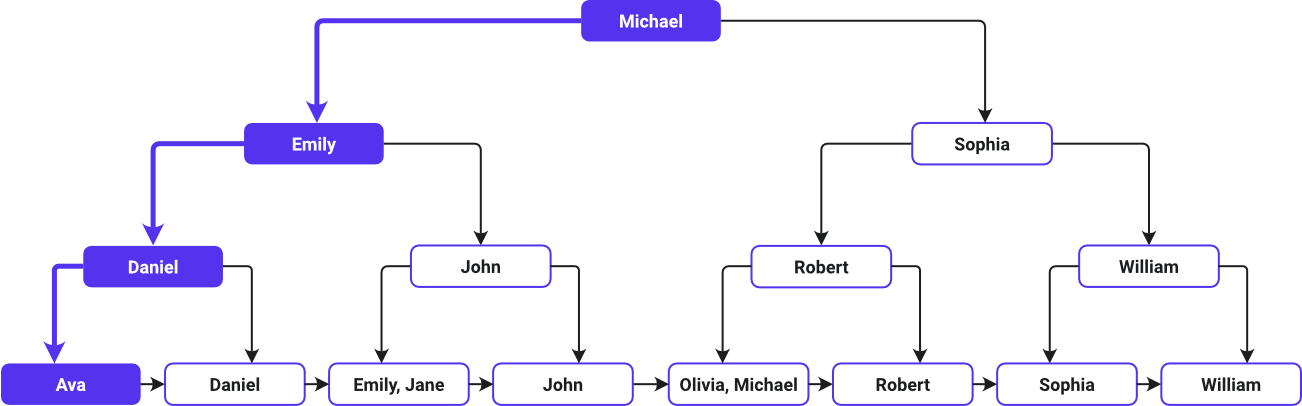
Ava est listé en premier, et William en dernier dans l’ordre alphabétique ascendant – la façon dont le B-Tree a arrangé les noms. Le système B-Tree désigne la valeur centrale de la liste comme nœud racine. Comme Michael se trouve au milieu de la liste alphabétique, il s’agit du nœud racine. L’arbre se ramifie ensuite, avec des valeurs à gauche et à droite de Michael.
Au fur et à mesure que vous descendez dans l’arbre, chaque nœud offre davantage de clés (liens directs vers les lignes de données d’origine) pour guider la recherche dans les noms classés par ordre alphabétique. Vous trouverez ensuite les données relatives au prénom de chaque client dans les nœuds feuilles.
La recherche commence par comparer Ava au nœud racine Michael. Elle se déplace vers la gauche après avoir déterminé que Ava apparait avant Michael dans l’ordre alphabétique. Elle descend jusqu’à l’enfant de gauche (Emily), puis de nouveau vers la gauche jusqu’à Daniel, et de nouveau vers la gauche jusqu’à Ava avant d’arriver au nœud feuille qui contient les informations de Ava.
L’arbre B fonctionne comme un système de navigation simplifié, guidant efficacement la recherche vers un endroit particulier sans vérifier chaque nom dans l’ensemble de données. C’est comme si vous naviguiez dans un répertoire soigneusement ordonné en suivant des panneaux de signalisation stratégiquement placés qui vous mènent directement à la destination.
Types d’index
Il existe différents types d’index pour différents objectifs. Nous allons examiner ces différents types ci-dessous.
1. Index à un niveau
Les index à un seul niveau, ou index plats, associent les clés de l’index aux données de la table. Chaque clé de l’index correspond à une seule ligne de la table.
La colonne customer_id est une clé primaire de la table Customer, qui sert d’index à un seul niveau. La clé identifie chaque client et relie les informations le concernant dans la table.
| Index (customer_id) | Pointeur de ligne |
| 1 | Ligne 1 |
| 2 | Ligne 2 |
| 3 | Ligne 3 |
| 4 | Ligne 4 |
| .. | .. |
La relation entre les clés customer_id et les détails des clients individuels est simple. Les index à un niveau excellent dans les scénarios où les tableaux contiennent quelques lignes ou colonnes avec peu de valeurs distinctes. Les colonnes telles que le statut ou la catégorie, par exemple, sont de bons candidats.
Utilisez un index à niveau unique pour les requêtes simples qui localisent une ligne spécifique sur la base d’une seule colonne. Sa mise en œuvre est simple, directe et efficace pour les petits ensembles de données.
2. Index à plusieurs niveaux
Contrairement aux index à un niveau pour la recherche organisée de données, les index à plusieurs niveaux utilisent une structure hiérarchique. Ils comportent plusieurs niveaux d’orientation. L’index de premier niveau dirige la recherche vers un index de niveau inférieur, et ainsi de suite jusqu’à ce qu’il atteigne le niveau feuille, qui stocke les données. Cette structure réduit le nombre de comparaisons nécessaires lors des recherches.
Prenons l’exemple d’un index multi-niveau comportant les colonnes adress et customer_id.
| Index (adress) | Sous-index (customer_id) | Pointeur de ligne |
| 123 Main Street | 1 | Ligne 1 |
| 456 Oak Ave | 2 | Ligne 2 |
| 789 Pine Rd | 3 | Ligne 3 |
| .. | .. | .. |
Le premier niveau organise les adresses. Le deuxième niveau, à l’intérieur de chaque adresse, organise les identifiants des clients.
Cette organisation est excellente pour les ensembles de données plus importants qui nécessitent une hiérarchie de recherche organisée. Elle est également utile pour les colonnes telles que last_name avec une cardinalité modérée (l’unicité des valeurs de données dans une colonne particulière).
3. Index groupés
Les index groupés de MySQL dictent l’ordre logique de l’index et l’ordre des données dans la table. Si vous appliquez un index groupé à la colonne customer_id de la table Customer, les lignes sont triées en fonction des valeurs de la colonne. Cela signifie que l’ordre des données dans la table reflète l’ordre de l’index groupé, ce qui améliore les performances de récupération des données pour des modèles spécifiques en réduisant les E/S sur disque.
Cette stratégie est efficace lorsque le modèle de récupération des données correspond à l’ordre des identifiants des clients. Elle convient également aux colonnes à forte cardinalité, comme customer_id.
Si les index groupés offrent des avantages en termes de performances de recherche de données pour des modèles spécifiques, il est important de noter un inconvénient potentiel. Le tri des lignes sur la base de l’index groupé peut avoir un impact sur les performances des opérations d’insertion et de mise à jour, en particulier si le modèle d’insertion ou de mise à jour ne correspond pas à l’ordre de l’index groupé. En effet, les nouvelles données doivent être insérées ou mises à jour de manière à conserver l’ordre de tri, ce qui entraine des frais supplémentaires.
4. Index non groupés
Les index non groupés offrent une plus grande flexibilité aux structures des bases de données. Supposons que vous utilisiez un index non groupé sur une colonne email. Contrairement à un index groupé, il ne modifie pas l’ordre des entrées dans la table.
En revanche, il crée une nouvelle structure qui associe les clés – dans ce cas, les adresses e-mail – aux lignes de données. Lorsque vous interrogez la base de données à la recherche d’une adresse électronique spécifique, l’index non groupé guide la recherche directement vers la ligne concernée, sans tenir compte de l’ordre de la table.
La flexibilité des index non groupés est leur principal avantage. Ils permettent des recherches efficaces sur plusieurs colonnes sans imposer d’ordre aux données stockées. Ce système rend les index non groupés polyvalents, car ils peuvent répondre à des requêtes qui ne suivent pas l’ordre primaire de la table.
Les index non groupés sont utiles lorsque le modèle de recherche des données diffère de l’ordre alphabétique et pour les colonnes dont la cardinalité est moyenne à élevée, comme l’e-mail.
Comment créer des index
Maintenant que nous avons vu ce que sont les index d’un point de vue général, passons à des exemples pratiques de création d’index à l’aide de MySQL Workbench.
Pré-requis
Pour suivre, vous avez besoin de :
- Une base de données MySQL (compatible avec MariaDB)
- Une certaine expérience de SQL et de MySQL
- MySQL Workbench
Comment créer la table des clients
- Lancez MySQL Workbench et connectez-vous à votre serveur MySQL.
- Exécutez la requête SQL suivante pour créer une table Customer :
CREATE TABLE Customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(15), address VARCHAR(255) ); - Insérez les données suivantes :
-- Adding Data to the Customer Table INSERT INTO Customer (customer_id, first_name, last_name, email, phone_number, address) VALUES (1, 'John', 'Doe', '[email protected]', '123-456-7890', '123 Main St'), (2, 'Jane', 'Smith', '[email protected]', '987-654-3210', '456 Oak Ave'), (3, 'Robert', 'Johnson', '[email protected]', '111-222-3333', '789 Pine Rd'), (4, 'Emily', 'Williams', '[email protected]', '555-666-7777', '101 Cedar Ln'), (5, 'Michael', 'Brown', '[email protected]', '444-555-8888', '202 Elm St'), (6, 'Sophia', 'Davis', '[email protected]', '999-888-7777', '303 Maple Ave'), (7, 'Daniel', 'Miller', '[email protected]', '777-888-9999', '404 Birch Rd'), (8, 'Olivia', 'Jones', '[email protected]', '333-222-1111', '505 Pine St'), (9, 'William', 'Wilson', '[email protected]', '111-333-5555', '606 Oak Ln'), (10, 'Ava', 'Moore', '[email protected]', '888-777-6666', '707 Cedar Ave');
Index à niveau unique
Une tactique pour optimiser les performances des requêtes dans MySQL et MariaDB consiste à utiliser des index à niveau unique.
Pour ajouter un index à niveau unique à la table Customer, utilisez l’instruction CREATE INDEX
-- Creating a Single-Level Index on "customer_id"
CREATE INDEX idx_customer_id ON Customer(customer_id);Une fois l’exécution réussie, la base de données confirme la création de l’index en renvoyant le code suivant :
0 row(s) affected Records: 0 Duplicates: 0 Warnings: 0Désormais, les requêtes qui filtrent les données en fonction des valeurs de la colonne customer_id sont traitées de manière optimale par la base de données, ce qui augmente considérablement l’efficacité.
Index multi-niveaux
MySQL et MariaDB vont au-delà de l’indexation des colonnes individuelles en proposant des index multi-niveaux. Ces index couvrent plus d’un niveau ou d’une colonne, combinant les valeurs de plusieurs colonnes en un seul index pour rendre l’exécution des requêtes plus efficace.
Utilisez le code suivant pour créer un index multi-niveaux dans MySQL ou MariaDB, en vous concentrant sur les colonnes address et customer_id:
-- Creating a Multi-Level Index based on "address" and "customer_id"
CREATE INDEX idx_address_customer_id ON Customer(address, customer_id);L’utilisation stratégique d’index multi-niveaux permet d’améliorer considérablement les performances des requêtes, en particulier lorsqu’il s’agit d’ensembles de colonnes.
Index groupés
Outre l’indexation individuelle et multi-niveaux, MySQL et MariaDB utilisent des index groupés, un outil dynamique permettant d’améliorer les performances des bases de données en alignant les lignes de données sur l’ordre des pointeurs de l’index.
Par exemple, l’application d’un index en grappe à la colonne customer_id de la table Customer aligne l’ordre des identifiants des clients.
-- Creating a Clustered Index on "customer_id"
CREATE CLUSTERED INDEX idx_customer_id_clustered ON Customer(customer_id);Grâce à l’optimisation de l’ordre des données, cette stratégie améliore considérablement la récupération des données de modèles spécifiques tout en réduisant les entrées/sorties sur disque.
Index non groupés
Les index non groupés permettent d’optimiser les requêtes en fonction des colonnes sans forcer l’ordre des données. Dans MySQL et MariaDB, vous n’avez pas besoin de spécifier qu’un index est non groupé.
L’architecture de la table l’implique. Seule la clé primaire ou la première clé unique non nulle peut être un index groupé. Les autres index de la table sont tous implicitement non groupés. Voici un exemple d’index non groupé :
-- Creating a Non-clustered Index on "email"
CREATE INDEX idx_email_non_clustered ON Customer(email);Les index non groupés permettent d’effectuer des recherches efficaces sur plusieurs colonnes, ce qui se traduit par une base de données plus polyvalente et plus réactive.
Meilleures pratiques et points clés
Choisissez des index à un seul niveau lorsque vous travaillez avec des colonnes ayant une petite plage de valeurs différentes, comme le statut ou la catégorie. Utilisez des index multi-niveaux et non groupés pour les colonnes dont l’éventail de valeurs est plus large, comme l’adresse e-mail.
Les schémas de recherche de données que vous préférez sont essentiels lorsque vous choisissez entre des index groupés et des index non groupés. Pour les index groupés, choisissez des colonnes à forte cardinalité, comme l’identifiant du client. Pour les index non groupés, choisissez des colonnes de cardinalité moyenne à élevée, comme l’adresse e-mail.
Comment optimiser les index
Pour améliorer les performances de vos index, vous pouvez utiliser certaines stratégies pratiques, telles que la couverture des index et la suppression des index redondants.
1. Couverture des index
La couverture des index améliore les performances des requêtes en créant des index qui couvrent toutes les données nécessaires. Le terme « index couvrant » signifie qu’un index comprend toutes les colonnes nécessaires pour répondre à une requête, ce qui évite d’avoir à accéder aux lignes de données.
-- Create a Covering Index on "first_name" and "last_name"
CREATE INDEX idx_covering_name ON Customer(first_name, last_name);2. Supprimer les redondances
Supprimez les index redondants, mais soyez prudent, car la suppression d’index peut avoir un impact sur les performances de certaines requêtes.
-- Remove an Unnecessary Index
DROP INDEX idx_unnecessary_index ON Customer;Examinez régulièrement les index redondants et supprimez-les afin de garantir une structure de base de données rationalisée et efficace.
3. Éviter la sur-indexation
Évitez les pièges courants tels que la sur-indexation. Si les index améliorent les performances des requêtes, le fait d’en créer trop peut diminuer les résultats. Il est essentiel de trouver un équilibre et d’éviter la sur-indexation, qui peut entrainer une augmentation des besoins en stockage et une dégradation potentielle des performances.
4. Analyser les modèles de requête
Il est également fréquent de négliger l’analyse des modèles de requête avant de créer des index. Il est essentiel de comprendre les requêtes fréquemment exécutées et de se concentrer sur l’indexation des colonnes utilisées dans les clauses WHERE ou les conditions JOIN pour obtenir des performances optimales.
Résumé
Cet article a exploré l’indexation de MySQL et MariaDB, en mettant l’accent sur l’efficacité du mécanisme B-Tree. Il a couvert les principes fondamentaux de l’indexation et les différents types d’index (à un niveau, à plusieurs niveaux, groupés et non groupés).
Que vous souhaitiez optimiser les charges de travail en lecture ou améliorer les performances en écriture, le service d’hébergement de bases de données de Kinsta offre aux utilisateurs de MySQL et de MariaDB une solution fiable et performante pour leurs besoins d’indexation. Essayez l’hébergement de base de données de Kinsta pour profiter de MySQL et MariaDB et de leurs capacités d’indexation.


