
La plupart des pannes de WordPress ne commencent pas par des pics de trafic ou des pannes d’infrastructure. Elles commencent par des changements ordinaires, tels que la mise à jour d’une extension, l’ajustement d’un fichier de configuration, ou un petit correctif mis en ligne.
WordPress est puissant et flexible, mais son bon fonctionnement dépend aussi des gens, ce qui signifie que les erreurs font toujours partie de l’équation.
La fiabilité ne signifie donc pas que rien ne peut aller de travers. Il s’agit de comprendre que quelque chose finira par se produire.
La vraie question n’est pas de savoir comment éliminer complètement ces défaillances. Il s’agit de savoir dans quelle mesure vous êtes prêt lorsqu’elles se produisent. Avec quelle rapidité pouvez-vous identifier ce qui s’est cassé, comment pouvez-vous l’inverser en toute sécurité et quel est l’impact de la panne pendant que vous le faites ? C’est ce qui définit en fin de compte la fiabilité dans la pratique.
Pourquoi l’erreur humaine est la véritable source de la plupart des temps d’arrêt
Il est facile de penser que les temps d’arrêt sont dus à une augmentation du trafic ou à des problèmes d’infrastructure. En réalité, la plupart des problèmes proviennent de modifications apportées au site lui-même.
WordPress évolue constamment. Les extensions sont mises à jour, les thèmes sont ajustés, les configurations sont affinées et le contenu est édité. Chacune de ces modifications est effectuée avec l’intention claire d’améliorer quelque chose, mais chacune d’entre elles introduit également une nouvelle variable dans le système.
C’est là que de petites erreurs peuvent avoir des effets considérables. Une erreur de syntaxe mineure dans un fichier de configuration, une mise à jour d’extension ou un changement dans une partie du système peut entrainer l’effondrement d’un site.
C’est pourquoi ces incidents ne sont ni inhabituels ni évitables à long terme. Ils sont le résultat naturel de l’utilisation d’un système flexible et stratifié.
L’objectif n’est pas d’éliminer complètement l’erreur humaine, mais de reconnaitre qu’elle est inhérente au fonctionnement des sites WordPress modernes. Une fois que cela est clair, l’accent peut être mis non plus sur la prévention de chaque problème, mais sur la gestion de l’évolution de ces problèmes.
Là où les choses se cassent généralement
Lorsque quelque chose ne fonctionne pas, ce n’est généralement pas le fruit du hasard. La plupart des défaillances se répartissent en quelques catégories familières :
-
- Erreurs de configuration dans les fichiers principaux
- Conflits entre les extensions et les thèmes après les mises à jour
- Problèmes liés à l’éditeur et au JavaScript qui interrompent les flux de travail du contenu
- Problèmes de configuration moderne dans des fichiers tels que
theme.json
Chacun de ces problèmes se manifeste de manière légèrement différente, mais ils commencent souvent par de petites modifications de routine.
Au niveau de la configuration, même des erreurs mineures peuvent mettre un site hors ligne immédiatement. Une petite erreur de syntaxe dans un fichier .htaccess, par exemple, suffit à déclencher une panne au niveau du serveur.
RewriteEngine On
RewriteRule ^index\.php$ - [LIl est facile de ne pas remarquer cette parenthèse fermante manquante, mais elle peut entrainer une panne complète du site, qui se manifeste généralement par une erreur de type :
500 Internal Server Error
The server encountered an internal error or misconfiguration.D’autres problèmes de configuration se comportent de la même manière. Des identifiants de base de données incorrects dans wp-config.php peuvent empêcher WordPress de se connecter, tandis qu’une faute de frappe dans functions.php peut conduire à un écran blanc qui bloque à la fois les visiteurs et les administrateurs.
Les conflits entre les extensions et les thèmes sont une autre source fréquente de panne. Comme tout fonctionne dans le même espace d’exécution, les mises à jour d’un composant peuvent en affecter d’autres de manière inattendue. Une mise à jour de routine d’une extension peut interrompre un flux de paiement, désactiver une fonctionnalité ou introduire des erreurs qui n’existaient pas auparavant.
Des problèmes apparaissent également dans l’éditeur, en particulier sur les sites qui s’appuient fortement sur des blocs et du JavaScript. Une erreur de script peut entrainer le chargement de l’éditeur sans contrôles ou empêcher l’enregistrement du contenu. Dans certains cas, le frontend continue de fonctionner alors que le backend devient inutilisable pour les équipes chargées du contenu.
Plus récemment, la configuration par le biais de fichiers tels que theme.json a introduit un autre niveau de risque. Un paramètre mal placé ou une structure non valide n’entrainera peut-être pas l’effondrement de l’ensemble du site, mais il peut en résulter des problèmes subtils plus difficiles à repérer.
Par exemple, une petite erreur structurelle comme celle-ci :
{
"settings" : {
"color" : {
"palette" : [
{
"name" : "Primary",
"slug" : "primary",
"color" : "#0073aa"
}
]
}
},
"styles" : {
"color" : {
"text" : "#333333"
}
}
}Cela peut sembler correct à première vue, mais si les clés sont mal placées, dupliquées, ou ne correspondent pas au schéma attendu, WordPress peut ignorer silencieusement certaines parties de la configuration.
Le résultat n’est pas un message d’erreur visible. Au lieu de cela, vous pouvez remarquer que les styles attendus ne s’appliquent pas, que les contrôles de l’éditeur disparaissent, ou que les blocs se comportent de manière incohérente d’une page à l’autre.
L’ensemble de ces éléments reflète le comportement de WordPress au quotidien, où de petites modifications peuvent avoir des répercussions qui ne sont pas toujours évidentes au premier abord.
Pourquoi la prévention seule ne résout pas le problème
Il est naturel de répondre à ces risques en renforçant les processus. Les équipes sont plus prudentes avec les mises à jour, les changements sont examinés de plus près et, dans la mesure du possible, des tests sont effectués avant la mise en production.
Ces pratiques réduisent la probabilité de problèmes et sont essentielles à la gestion de tout site WordPress. Mais elles n’éliminent pas le problème.
Les extensions évoluent indépendamment, les dépendances changent avec le temps et les interactions entre les composants ne sont pas toujours prévisibles. Une modification qui semble sure pendant les tests peut se comporter différemment en production, en particulier lorsqu’elle rencontre des données réelles, un trafic réel ou une combinaison d’extensions qui n’ont pas été pris en compte. Dans de nombreux cas, les problèmes ne sont pas dus à une seule erreur, mais à la façon dont plusieurs parties du système interagissent dans des conditions réelles.
C’est pourquoi la prudence n’est pas une garantie de stabilité. Cela réduit les risques de défaillance, mais n’élimine pas complètement cette possibilité.
Les sauvegardes sont souvent considérées comme la solution de repli, et elles sont essentielles. Cependant, la mise en place de sauvegardes n’est qu’une partie de l’équation. Ce qui compte tout autant, c’est la rapidité et la sécurité avec lesquelles ces sauvegardes peuvent être utilisées en cas de problème. Dans certains environnements, la restauration d’un site est immédiate et contrôlée. Dans d’autres, elle implique des retards, des étapes manuelles ou l’attente d’une assistance, ce qui prolonge l’impact du problème.
Et si ces incidents ne se produisent pas tous les jours, leur impact est rarement mineur. Une caisse cassée, une zone d’administration inaccessible ou une erreur à l’échelle du site peuvent perturber les opérations en quelques minutes.
Ce que la fiabilité signifie en pratique
À ce stade, il apparait clairement que la fiabilité ne consiste pas seulement à éviter les erreurs, mais aussi à savoir comment le système réagit lorsque ces erreurs se produisent inévitablement. Un site qui ne tombe jamais en panne n’est pas réaliste. Un site qui se rétablit rapidement et de manière prévisible est beaucoup plus utile dans la pratique.
L’accent n’est donc plus mis sur la prévention, mais sur le contrôle. Au lieu de se demander si un changement peut introduire un risque, il est plus utile de se demander dans quelle mesure ce risque est maitrisé.
Si un problème survient, peut-il être isolé sans affecter l’ensemble du site ? Le problème peut-il être identifié immédiatement ou faut-il du temps avant que quelqu’un s’en aperçoive ? Et une fois qu’il est identifié, est-il possible d’y remédier sans ajouter de la complexité à une situation déjà stressante ?
Concrètement, les systèmes fiables sont conçus pour rendre les défaillances gérables. Les changements sont testés dans des environnements qui reflètent la production, et non pas directement sur des sites en direct. En cas de panne, il existe un moyen clair et rapide de revenir à un état de fonctionnement connu. Surveiller les problèmes à un stade précoce, souvent avant que les utilisateurs ne les signalent. L’objectif n’est pas d’éliminer les défaillances, mais de faire en sorte qu’elles ne se transforment pas en temps d’arrêt prolongé ou en perturbations plus importantes.
C’est ici que la différence entre les configurations devient plus visible. Deux sites peuvent rencontrer le même problème, comme une mise à jour problématique d’une extension ou une erreur de configuration, mais le résultat peut être complètement différent. L’un se rétablit en quelques minutes avec un impact minimal. L’autre reste instable pendant que l’équipe travaille sur des corrections manuelles, des restaurations ou des processus d’assistance. L’erreur initiale est la même, mais c’est le système qui l’entoure qui détermine le degré de perturbation qu’elle entraine.
Comment votre environnement d’hébergement devient le système de sécurité
Une fois que vous commencez à penser à la fiabilité en termes de prévention et de récupération, le rôle de votre environnement d’hébergement change.
Il devient le système qui détermine la sécurité avec laquelle vous pouvez effectuer des changements et la rapidité avec laquelle vous pouvez vous rétablir en cas de problème.
En ce qui concerne la prévention, l’objectif est d’éviter d’introduire des risques inutiles dans un site réel. Cela signifie généralement qu’il faut disposer d’un moyen de tester les modifications avant qu’elles n’atteignent la production. Qu’il s’agisse d’une mise à jour d’extension, d’une modification de configuration ou d’une nouvelle fonctionnalité, le fait de pouvoir valider ces changements dans un environnement de staging réduit les risques de panne devant les utilisateurs.
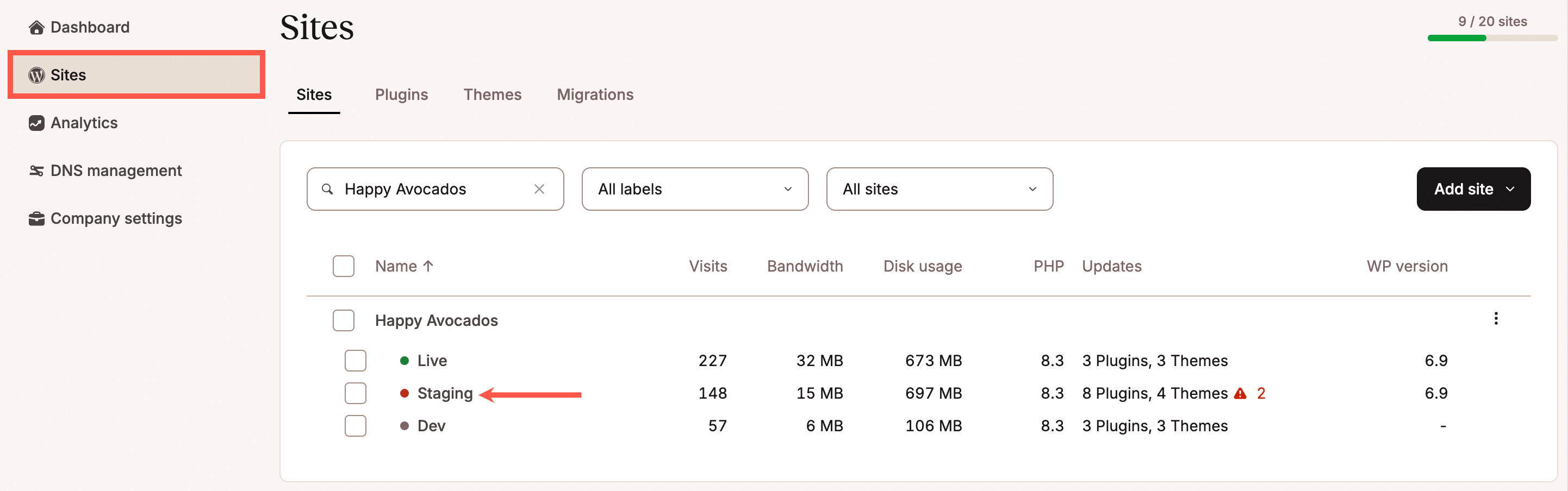
Cela n’élimine pas complètement le risque, mais le déplace dans un espace contrôlé où les problèmes peuvent être détectés rapidement.
En cas de panne, l’accent est immédiatement mis sur la récupération. C’est là que la différence entre les environnements devient plus évidente. Dans certaines configurations, la restauration d’un site est un processus lent et manuel qui implique de multiples étapes et une incertitude quant à l’état dans lequel le site reviendra. Dans d’autres, il s’agit d’une action simple qui peut être réalisée en quelques minutes, avec des points de restauration clairs et une interruption minimale. Cet écart dans la vitesse de récupération est souvent ce qui détermine si un problème est ressenti comme un revers mineur ou un incident majeur.
La détection joue également un rôle à cet égard. Si un problème n’est pas visible immédiatement, il peut continuer à affecter les utilisateurs bien avant que quelqu’un de l’équipe s’en aperçoive. Les environnements qui assurent une surveillance claire et font remonter les problèmes à la surface rapidement raccourcissent cette fenêtre, permettant aux équipes de réagir avant que l’impact ne s’étende.
Prises ensemble, ces capacités changent la façon dont les équipes travaillent. Les mises à jour ne sont plus à retarder par prudence, et les erreurs ne comportent plus le même niveau de risque parce qu’il existe un chemin clair vers le rétablissement. Le système prend en charge à la fois les changements prudents et les corrections rapides, ce qui rend le développement continu durable.
La fiabilité, c’est ce qui se passe quand les choses tournent mal
Quelle que soit l’expérience de l’équipe ou le soin apporté aux changements, quelque chose finira par se briser. Il ne s’agit pas d’un échec du processus ou de la discipline. C’est le résultat naturel du travail avec un système en constante évolution.
Ce qui distingue les sites stables des sites fragiles, c’est la manière dont ces erreurs sont gérées. Lorsque les problèmes peuvent être identifiés rapidement, résolus en toute sécurité et maitrisés sans affecter l’ensemble du site, ils cessent d’être des incidents majeurs et deviennent partie intégrante des opérations normales.
C’est le type d’environnement pour lequel Kinsta a été conçu. Du staging intégrée et des sauvegardes automatiques aux points de restauration rapides et contrôlés, l’objectif n’est pas seulement de maintenir les sites en ligne, mais de les rendre résistants aux changements quotidiens qui causent généralement des problèmes.
Si votre configuration actuelle rend la restauration lente, incertaine ou stressante, il peut être utile de repenser non seulement la façon dont vous gérez votre site, mais aussi le système qui le prend en charge.

Bud Kraus travaille dans l'écosystème WordPress depuis 2009 en tant que formateur (en présentiel et en ligne), développeur de sites et créateur de contenu. Il a réalisé des vidéos pédagogiques et rédigé de nombreux articles pour des entreprises du secteur WordPress.

