La plupart des problèmes de performance de WordPress sont liés à l’environnement d’hébergement, ce qui est parfois le bon diagnostic. Cependant, les dépendances de tiers déclenchent les mêmes sonnettes d’alarme, bien qu’elles soient hors du contrôle de l’hébergeur.
Les passerelles de paiement qui ne fonctionnent pas, les API d’expédition qui ne répondent pas et les scripts d’analyse lents sont autant de défaillances pour lesquelles vous ne pouvez que mettre en place des mesures de contrôle des dommages. Cependant, cela dépend de votre infrastructure d’hébergement et de ce que vous pouvez faire au niveau de l’application pour que votre site continue à fonctionner lorsque les dépendances sont défaillantes.
Pourquoi les dépendances tierces créent des défaillances en cascade sur WordPress
Un site WordPress moderne fonctionne rarement de manière isolée. Par exemple, pensez à ce dont dépend un flux de paiement WooCommerce à un moment donné :
- Les passerelles de paiement traitent la transaction.
- Les API d’expédition calculent les tarifs en temps réel.
- Les services fiscaux s’occupent de la conformité.
D’autres sites peuvent charger un outil de suivi analytique, un script de synchronisation CRM, un widget de discussion en direct et de nombreuses autres dépendances, chacune hébergée sur un serveur externe différent.
Lorsque l’un de ces éléments ralentit ou cesse de répondre, l’effet ne se limite pas à cette fonctionnalité spécifique. Au contraire, il se propage à travers la couche d’exécution PHP et crée un problème qui peut affecter l’ensemble du site. En effet, lorsque WordPress sert une page qui nécessite une réponse d’API externe, un thread attend avant de compléter la requête.
Ainsi, une passerelle de paiement qui s’arrête au bout de 30 secondes bloque un thread pendant toute la durée de l’attente et ne peut rien traiter d’autre pendant ce temps. Si plusieurs visiteurs atteignent cette caisse lente en même temps, plusieurs threads peuvent retarder le chargement de la page pour toute la chaine. Avec l’hébergement mutualisé, les sites partagent un pool de threads.
Le manque de visibilité : problèmes de performance internes et externes
Il ne faut donc pas beaucoup de dépassements de délais simultanés pour épuiser entièrement un pool partagé. Lorsque cela se produit, l’API externe s’arrête et vos visiteurs restants reçoivent des erreurs liées au dépassement de temps, telles que 502 ou 504, pendant qu’ils attendent un thread libre.
Cependant, une erreur 504 se présente exactement de la même manière, quelle que soit son origine. Pour ce type de réponses d’erreur, vous commencez généralement par examiner les mesures du processeur, de la mémoire et de l’infrastructure. Cela peut donner l’impression que l’hébergement est le problème, même si le véritable problème est une dépendance externe.
Comment l’architecture de conteneurs de Kinsta limite l’impact des défaillances de tiers
Kinsta exécute chaque site WordPress dans son propre conteneur isolé, ce qui détermine le « rayon d’action » en cas de défaillance d’un service tiers.
Chaque conteneur dispose de son propre pool de threads PHP auquel les autres sites de la plateforme n’ont pas accès. Cela signifie que l’épuisement des threads PHP reste dans votre conteneur et n’affecte pas les autres sites de la même infrastructure. De plus, lorsque des appels d’API externes occupent tous les threads PHP de votre conteneur, les requêtes entrantes sont mises en file d’attente dans Nginx et PHP-FPM au lieu de renvoyer immédiatement des erreurs.
En pratique, une panne de la passerelle de paiement qui mettrait hors service tous les sites sur un serveur partagé n’affecte que votre conteneur sur Kinsta. Le pool de threads à l’intérieur de votre conteneur est mis à rude épreuve, mais les sites voisins ne sont pas du tout affectés.
Les limites de temps d’attente des requêtes empêchent le blocage indéfini
Lorsqu’il n’est pas contrôlé, un thread PHP peut maintenir une connexion à une API externe défaillante pendant une période prolongée. Pour contrer cela, Kinsta fixe le max_execution_time à 300 secondes par défaut, ce qui limite la durée d’exécution active d’un script PHP.
Il existe un délai HTTP distinct qui détermine le moment où la connexion entre le navigateur et le serveur s’arrête et renvoie une erreur 504 au visiteur, qui, sur Kinsta, se déclenche au bout de 180 secondes.
Ensemble, ces limites signifient que votre scénario le plus défavorable a un point final défini du point de vue du visiteur. Cependant, aucune de ces limites ne permet à elle seule de couper un appel API sortant bloqué. Sous Linux, le compteur d’exécution de PHP ne compte pas le temps passé à attendre les opérations de flux, ce qui est le cas d’une requête HTTP sortante via l’API HTTP de WordPress.
Un thread bloqué sur une réponse de la passerelle de paiement n’accumule presque pas de temps d’exécution du point de vue de PHP, donc le plafond de 300 secondes offre moins de protection qu’il n’y parait. C’est pourquoi la mise en place de timeouts explicites dans les extensions via http_request_timeout est la manière la plus fiable de mettre fin à un appel externe bloqué au niveau de l’application.
Lorsqu’une requête arrive à son terme, le thread se libère et le conteneur commence une récupération qui prend généralement quelques minutes.
Utiliser Kinsta APM pour distinguer les goulots d’étranglement de l’hébergement de ceux des tiers
L’outil APM de Kinsta capture des données horodatées sur les processus PHP, les requêtes MySQL et les appels HTTP externes. C’est le moyen de surveiller l’écart de performance entre votre hébergement et les dépendances tierces.
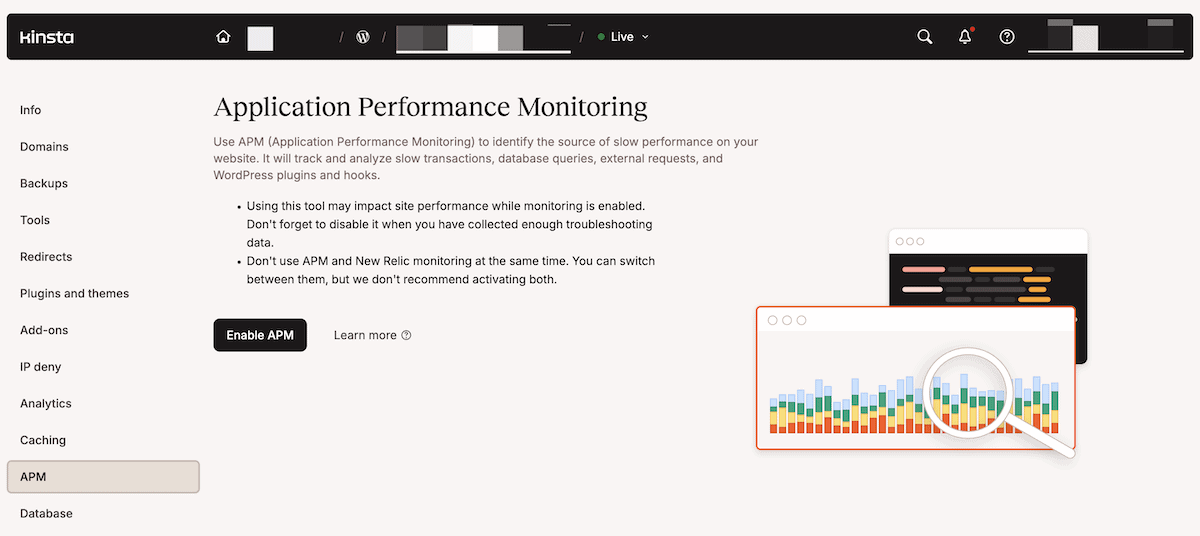
Vous activez l’APM à partir de la section APM dans MyKinsta, puis vous choisissez une fenêtre de surveillance parmi quatre options prédéfinies entre deux et 24 heures. Étant donné que l’APM de Kinsta utilise des ressources de serveur supplémentaires, la bonne approche consiste à l’activer lorsque vous soupçonnez qu’un problème se produit ou qu’il peut être reproduit.
Une fois que l’APM fonctionne, vous pouvez consulter un certain nombre de tableaux, de graphiques et d’affichages dans quatre sections : Transactions, WordPress, Base de données et Externe. Cette dernière est essentielle pour comprendre où se situent les goulets d’étranglement.
Utiliser l’écran Externe dans Kinsta APM
L’onglet Externe liste toutes les requêtes HTTP externes de votre site, y compris les appels initiés par les extensionbs et les thèmes pour le traitement des paiements, les calculs d’expédition, les intégrations CRM et les analyses. Chaque entrée indique la durée totale, maximale et moyenne, ainsi que le taux de requête par minute.
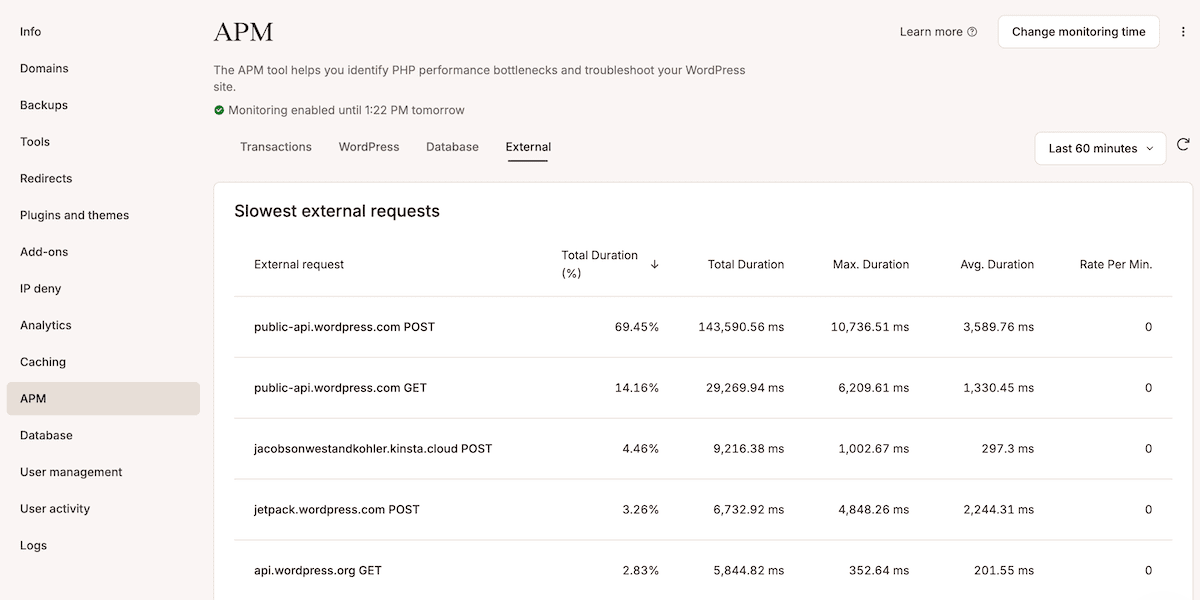
Par exemple, une API de paiement apparaissant en haut de la liste, avec une durée maximale mesurée en plusieurs secondes, indique clairement que la passerelle est la source du problème.
Suivi des transactions
En cliquant sur l’URL d’une requête dans l’onglet Externe, vous ouvrez une liste d’échantillons de transactions. La sélection d’un échantillon spécifique ouvre alors la chronologie de la trace de la transaction, qui montre une décomposition complète de chaque processus qui s’est produit, chaque processus étant représenté par une durée.
Les intervalles consommant plus de 5 % de la durée totale de la transaction apparaissent en orange ; ceux consommant plus de 25 % apparaissent en rouge.
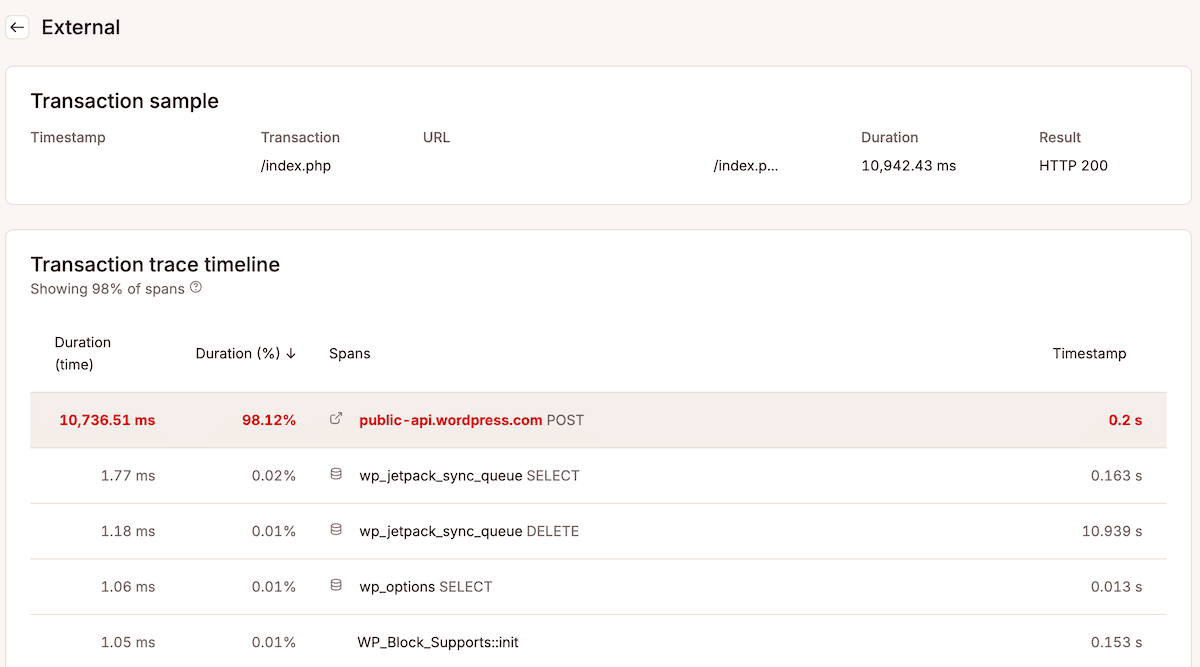
Les traces vous aident à déterminer les dépendances à optimiser ou à remplacer en priorité. Par exemple, si un appel HTTP externe à une API de paiement occupe cinq secondes d’une transaction de 5,5 secondes, l’infrastructure d’hébergement a traité tout le reste en une demi-seconde.
Pour utiliser Kinsta APM lors d’un problème présumé, le flux de travail se déroule comme suit :
- Activez la surveillance APM et sélectionnez une durée qui couvre la fenêtre du problème.
- Reproduisez le problème s’il ne se produit pas actuellement (ou attendez que l’outil capture des données en direct).
- Laissez les données s’accumuler, puis ouvrez l’onglet Externe, cliquez sur n’importe quelle requête externe pour ouvrir la trace de la transaction et examinez les durées d’intervalle.
Si les appels HTTP externes apparaissent en tête des résultats avec des durées qui représentent la majeure partie de la durée de la transaction, vous disposez des informations nécessaires pour commencer à résoudre le problème.
Stratégies opérationnelles pour la gestion des dépendances de tiers
L’isolation des conteneurs limite les dommages causés par les défaillances externes, mais la manière dont vous chargez et appelez les services externes est également importante. Même avec un hébergement bien architecturé, les dépendances tierces nécessitent une gestion proactive au niveau de l’application.
Modèles de chargement asynchrone pour les scripts non critiques
WordPress charge les scripts de manière synchrone par défaut, ce qui signifie qu’un script dans l’en-tête du document empêche le navigateur d’afficher le contenu jusqu’à ce que le téléchargement et l’exécution soient terminés. Pour les scripts d’analyse, les outils de cartographie thermique et l’automatisation du marketing, cela signifie qu’un serveur tiers lent bloque l’ensemble de votre page.
La distinction à faire ici est que le chargement par synchro et asynchro produit des résultats différents lorsqu’un serveur externe est lent :
- Le chargement synchrone (bloquant) interrompt l’analyse HTML jusqu’à ce que le script soit téléchargé et exécuté. Si le serveur externe est sous charge, votre page attend.
- Le chargement asynchrone permet au navigateur de poursuivre l’analyse HTML et le rendu du contenu pendant que le script se charge en arrière-plan. Si le serveur externe est lent, votre page est quand même rendue.
WordPress supporte nativement les stratégies de chargement async et defer grâce à wp_enqueue_script(). Ces deux stratégies empêchent les scripts non critiques de bloquer le rendu de la page, mais elles se comportent différemment : defer exécute les scripts dans l’ordre (ce qui convient donc aux scripts ayant des dépendances), tandis que async exécute les scripts dès qu’ils sont chargés, quel que soit l’ordre dans lequel ils sont chargés.
L’utilisation de async est idéale pour les trackers autonomes où l’ordre d’exécution n’a pas d’importance.
add_action( 'wp_enqueue_scripts', function() {
// Analytics — deferred so it doesn't block the critical path.
wp_enqueue_script(
'google-analytics',
'https://www.googletagmanager.com/gtag/js?id=G-XXXXXXXX',
[],
null,
['strategy' => 'defer', 'in_footer' => false ]
) ;
// Marketing script — async because execution order doesn't matter.
wp_enqueue_script(
'hotjar',
'https://static.hotjar.com/c/hotjar-XXXXXX.js',
[],
null,
['strategy' => 'async', 'in_footer' => false ]
) ;
} ) ;Cependant, les scripts critiques pour le paiement nécessitent souvent un comportement de chargement plus prudent que les tags d’analyse ou de marketing, et certaines intégrations de paiement peuvent nécessiter de rester bloquées ou ordonnées pour éviter d’interrompre le paiement. En bref, les scripts non critiques qui peuvent échouer sans interrompre la page bénéficient d’async ou de defer; les scripts dont l’utilisateur a besoin pour terminer une transaction ne le font pas.
Configuration du délai d’attente pour les appels d’API externes
Le temps d'exécution maximal par défaut de Kinsta est suffisamment long pour les opérations complexes, mais beaucoup trop long pour faire attendre un utilisateur. En tant que telle, une extension effectuant des appels d’API externes devrait définir son propre délai d’attente plutôt que de se rabattre sur la limite au niveau du serveur.
WordPress propose par défaut un délai HTTP de 5 secondes pour les requêtes externes, à moins qu’une extension ou un filtre ne le supplante. Si une extension a besoin d’une limite différente, WordPress fournit un filtre pour cela : http_request_timeout. Il s’exécute avant qu’une requête ne soit faite et accepte à la fois la valeur actuelle du délai d’attente et l’URL cible, de sorte que vous pouvez définir des limites différentes pour différents services :
add_filter( 'http_request_timeout', function( $timeout, $url ) {
if ( str_contains( $url, 'api.example.com' ) ) {
return 10 ; // Don't wait longer than 10 seconds.
}
return $timeout ;
}, 10, 2 ) ;Ce type de plafond signifie qu’un service défaillant renvoie rapidement une erreur à votre utilisateur, plutôt que d’occuper un thread PHP. Garder les délais d’attente au niveau de l’extension bien en dessous du plafond du serveur est ce qui empêche une API lente de consommer un thread pendant une durée déraisonnable.
Cependant, l’augmentation des valeurs de délai d’attente ne résout pas le problème des API lentes, mais empêche les défaillances prématurées lorsqu’un service fonctionne mais est sous charge. La bonne approche est celle d’un délai court qui échoue rapidement et passe à une solution de repli.
Mécanismes de repli et dégradation progressive
Les mécanismes de repli permettent à votre site de rester fonctionnel en cas de défaillance externe plutôt que d’afficher une erreur. Le modèle utilise les transitoires de WordPress pour mettre en cache les réponses réussies de l’API, puis sert les données mises en cache lorsque l’appel en direct échoue.
Voici un exemple :
function get_shipping_rates_with_fallback( $package ) {
$cache_key = 'live_shipping_rates_' . md5( serialize( $package ) );
$backup_key = 'backup_shipping_rates_' . md5( serialize( $package ) );
// Return fresh cached rates if they're available.
$cached = get_transient( $cache_key );
if ( $cached !== false ) {
return $cached;
}
// Attempt the live API call with a short timeout.
$response = wp_remote_post( 'https://api.example.com/rates', [
'timeout' => 8,
'body' => [
'destination' => $package['destination'],
'weight' => $package['contents_weight'],
],
] );
// On success: cache the result and update the longer-lived backup.
if ( ! is_wp_error( $response ) && wp_remote_retrieve_response_code( $response ) === 200 ) {
$rates = json_decode( wp_remote_retrieve_body( $response ), true );
set_transient( $cache_key, $rates, HOUR_IN_SECONDS );
set_transient( $backup_key, $rates, DAY_IN_SECONDS );
return $rates;
}
// On failure: serve stale backup rates rather than an error.
$backup = get_transient( $backup_key );
if ( $backup !== false ) {
return $backup;
}
// No cached data at all: return a flat-rate fallback.
return [
[ 'id' => 'fallback_flat', 'label' => 'Standard Shipping', 'cost' => 9.99 ],
];
}Le transitoire d’une heure gère la mise en cache normale pour éviter les appels d’API inutiles. La version transitoire de 24 heures n’est mise à jour que lorsque l’API en direct renvoie une réponse positive, ce qui permet à votre site de revenir à la réponse positive la plus récente. Lorsque l’API tombe en panne, votre site affiche les tarifs d’expédition d’hier au lieu d’une erreur.
La dégradation progressive permet à votre fonctionnalité principale de continuer à fonctionner même lorsque les services externes sont indisponibles. Elle fonctionne mieux avec une infrastructure d’hébergement qui limite les défaillances au niveau du conteneur, de sorte qu’un problème de dépendance n’accapare pas les ressources.
Votre hébergement ne doit pas se contenter de donner de la vitesse à votre site
Les défaillances de tiers font partie de l’exploitation d’un site WordPress avec des dépendances réelles. Ce que vous pouvez contrôler, c’est la part de votre site qui va avec, ce qui est déterminé par la façon dont votre environnement d’hébergement réagit.
L’utilisation d’une infrastructure qui met en œuvre l’isolation des conteneurs, un pool de threads PHP dédié, des limites de temps intégrées, et la surveillance des applications vous permet de comprendre un problème d’hébergement à partir d’un problème de dépendance.
Si vous êtes prêt à voir comment l’infrastructure de Kinsta gère cela pour vos sites WordPress, explorez les plans d’hébergement de Kinsta. Vous pouvez également vous adresser à l’équipe pour savoir comment Kinsta peut bénéficier à votre installation spécifique.

Joel est un développeur d'interfaces publiques qui travaille chez Kinsta en tant que rédacteur technique. Il est un enseignant passionné par l'open source et a écrit plus de 200 articles techniques, principalement autour de JavaScript et de ses frameworks.