
カメラの性能が向上して以来、リアルタイム物体検出技術の需要はますます高まりを見せています。この技術は現在、自動運転車やスマート監視システムから、拡張現実(AR)アプリケーションに至るまで、さまざまな分野で利用されています。
コンピュータビジョンは、カメラとコンピュータを使用して上のような処理を実現可能にする複雑で大規模な分野です。しかし、意外と簡単にブラウザでリアルタイムの物体検出を実現できることは、知らない人が多いかもしれません。
今回は、Reactを使用してリアルタイム物体検出アプリを構築し、Kinstaにデプロイする手順をご紹介します。リアルタイム物体検出アプリには、ユーザーのデバイスに搭載されているウェブカメラを利用します。
前提条件
今回ご紹介する手順には、以下が必要になります。
- React:アプリケーションのユーザーインターフェース(UI)を構築するために使用します。Reactは動的コンテンツのレンダリングに優れているため、ブラウザ内でウェブカメラのフィードと検出された物体を表示することができます。
- TensorFlow.js:機械学習のパワーをブラウザにもたらすJavaScriptライブラリです。物体検出のために事前にトレーニングされたモデルを読み込み、ブラウザ内で直接実行することができるため、複雑なサーバーサイドの処理が不要になります。
- Coco SSD:事前にトレーニングの施された物体検出モデルです。軽量でありながら、膨大な数の日常的な物体をリアルタイムで検出できます。強力なツールであり、トレーニングには一般的なデータセットが使われています。特定の検出要件がある場合はこちらを参考に、TensorFlow.jsでカスタムモデルをトレーニングすることができます。
Reactプロジェクトのセットアップ
- 以下のコマンドを使って、Reactプロジェクトを作成。
npm create vite@latest kinsta-object-detection --template reactこれにより、viteを使用してベースラインのReactプロジェクトがスキャフォールディングされます。
- プロジェクト内で以下のコマンドを実行し、TensorFlowとCoco SSDライブラリをインストールします。
npm i @tensorflow-models/coco-ssd @tensorflow/tfjs
以上でアプリ開発の準備が整いました。
アプリの設定
物体検出ロジックのコードを書く前に、アプリの完成像を押さえておきましょう。アプリのUIは以下のようになります。
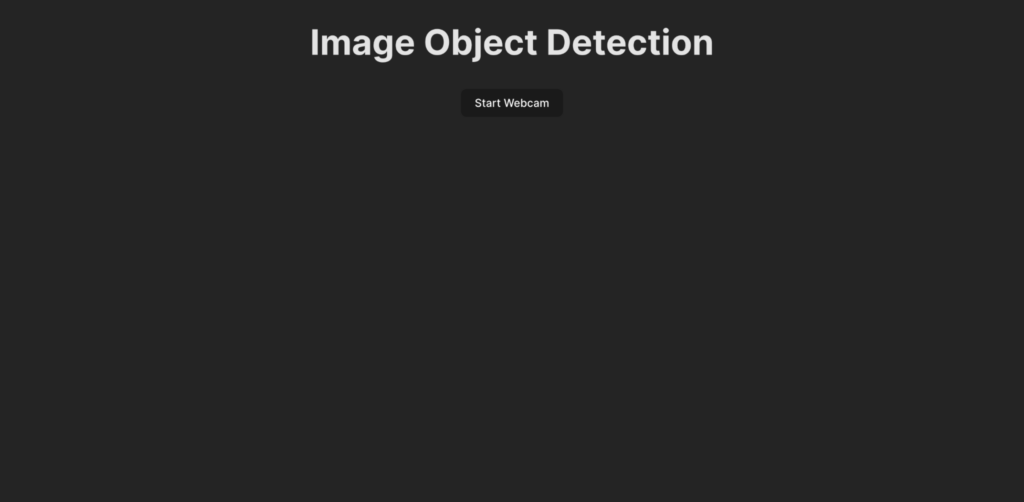
ユーザーが「ウェブカメラを開始(Start Webcam)」をクリックすると、ウェブカメラのフィードへのアクセス許可をアプリに付与するように促されます。アクセスが許可されると、アプリがウェブカメラフィードを表示し、フィードに存在する物体を検出します。また、検出された物体を表示するために、ライブフィード上にボックスをレンダリングし、ラベルを追加します。
まずは、App.jsxファイルに以下のコードを貼り付けて、アプリのUIを作成します。
import ObjectDetection from './ObjectDetection';
function App() {
return (
<div className="app">
<h1>画像物体検出</h1>
<ObjectDetection />
</div>
);
}
export default App;このコードは、ページのヘッダーを指定し、ObjectDetectionというカスタムコンポーネントをインポートします。これには、ウェブカメラのフィードをキャプチャしリアルタイムで物体を検出するためのロジックが含まれます。
このコンポーネントを作成するには、srcディレクトリに「ObjectDetection.jsx」という名前でファイルを作成し、以下のコードを貼り付けます。
import { useEffect, useRef, useState } from 'react';
const ObjectDetection = () => {
const videoRef = useRef(null);
const [isWebcamStarted, setIsWebcamStarted] = useState(false)
const startWebcam = async () => {
// TODO
};
const stopWebcam = () => {
// TODO
};
return (
<div className="object-detection">
<div className="buttons">
<button onClick={isWebcamStarted ? stopWebcam : startWebcam}>ウェブカメラを{isWebcamStarted ? "停止" : "開始"}</button>
</div>
<div className="feed">
{isWebcamStarted ? <video ref={videoRef} autoPlay muted /> : <div />}
</div>
</div>
);
};
export default ObjectDetection;上のコードでは、ウェブカメラのフィードを開始および停止するためのボタン、ウェブカメラのフィードが有効になった際に表示する<video>要素を含むHTML構造を定義しています。状態コンテナisWebcamStartedは、ウェブカメラのフィードの状態を保存します。startWebcamとstopWebcamの 2つの関数は、ウェブカメラフィードの開始と停止に使用されます。
startWebcam関数のコードは以下のとおりです。
const startWebcam = async () => {
try {
setIsWebcamStarted(true)
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
if (videoRef.current) {
videoRef.current.srcObject = stream;
}
} catch (error) {
setIsWebcamStarted(false)
console.error('Error accessing webcam:', error);
}
};この関数は、ユーザーにウェブカメラへのアクセスを許可するよう要求し、許可されると、<video>にウェブカメラのライブフィードを表示するよう設定します。
(デバイスにウェブカメラが搭載されていない、ユーザーが拒否したなどの理由で)ウェブカメラフィードへのアクセスに失敗すると、この関数でコンソールにメッセージを表示し、エラーブロックを使用して、アクセスに失敗した理由を表示することができます。
次に、stopWebcam関数を以下のコードに置き換えます。
const stopWebcam = () => {
const video = videoRef.current;
if (video) {
const stream = video.srcObject;
const tracks = stream.getTracks();
tracks.forEach((track) => {
track.stop();
});
video.srcObject = null;
setPredictions([])
setIsWebcamStarted(false)
}
};このコードでは、<video>オブジェクトによってアクセスされている実行中のビデオストリームのトラックを確認し、それぞれを停止します。その後、isWebcamStartedの状態をfalseに設定します。
この時点で、アプリを実行し、ウェブカメラのフィードにアクセスして表示できるかどうかを確認します。
以下のコードをindex.cssファイルに貼り付けて、アプリが先のプレビューと同じように見えるかどうかを確かめます。
#root {
font-family: Inter, system-ui, Avenir, Helvetica, Arial, sans-serif;
line-height: 1.5;
font-weight: 400;
color-scheme: light dark;
color: rgba(255, 255, 255, 0.87);
background-color: #242424;
min-width: 100vw;
min-height: 100vh;
font-synthesis: none;
text-rendering: optimizeLegibility;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
a {
font-weight: 500;
color: #646cff;
text-decoration: inherit;
}
a:hover {
color: #535bf2;
}
body {
margin: 0;
display: flex;
place-items: center;
min-width: 100vw;
min-height: 100vh;
}
h1 {
font-size: 3.2em;
line-height: 1.1;
}
button {
border-radius: 8px;
border: 1px solid transparent;
padding: 0.6em 1.2em;
font-size: 1em;
font-weight: 500;
font-family: inherit;
background-color: #1a1a1a;
cursor: pointer;
transition: border-color 0.25s;
}
button:hover {
border-color: #646cff;
}
button:focus,
button:focus-visible {
outline: 4px auto -webkit-focus-ring-color;
}
@media (prefers-color-scheme: light) {
:root {
color: #213547;
background-color: #ffffff;
}
a:hover {
color: #747bff;
}
button {
background-color: #f9f9f9;
}
}
.app {
width: 100%;
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
}
.object-detection {
width: 100%;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
.buttons {
width: 100%;
display: flex;
justify-content: center;
align-items: center;
flex-direction: row;
button {
margin: 2px;
}
}
div {
margin: 4px;
}
}また、コンポーネントのスタイルを保つため、App.cssファイルは削除してください。これで、リアルタイム物体検出技術をアプリに統合するためのロジックを書く準備ができました。
リアルタイム物体検出のセットアップ
- ObjectDetection.jsxの先頭でTensorflowとCoco SSDをインポートします。
import * as cocoSsd from '@tensorflow-models/coco-ssd'; import '@tensorflow/tfjs'; ObjectDetectionコンポーネントに状態を作成し、Coco SSDモデルによって生成された予測の配列を格納します。const [predictions, setPredictions] = useState([]);- Coco SSDモデルを読み込んでビデオフィードを収集し、予測を生成する関数を記述します。
const predictObject = async () => { const model = await cocoSsd.load(); model.detect(videoRef.current).then((predictions) => { setPredictions(predictions); }) .catch(err => { console.error(err) }); };この関数は、ビデオフィードを使用して、フィードに存在する物体の予測を生成します。予測された物体の配列が提供され、それぞれにラベル、信頼度を示すパーセンテージ、動画フレーム内の物体の位置を示す座標が含まれます。
この関数を継続的に呼び出してビデオフレームを処理し、
predictionsという状態コンテナに格納された予測値を使用して、ライブビデオフィード上で識別された各オブジェクトのボックスとラベルを表示する必要があります。 setInterval関数で、この関数を継続的に呼び出します。同時に、ユーザーがウェブカメラのフィードを停止した後は、この関数が呼び出されないようにしなければなりません。これにはJavaScriptからclearInterval関数を使用します。ObjectDetectionコンポーネントに以下の状態コンテナとuseEffectフックを追加して、ウェブカメラの有効時にpredictObject関数が継続的に呼び出され、ウェブカメラの無効時には削除されるように設定します。const [detectionInterval, setDetectionInterval] = useState() useEffect(() => { if (isWebcamStarted) { setDetectionInterval(setInterval(predictObject, 500)) } else { if (detectionInterval) { clearInterval(detectionInterval) setDetectionInterval(null) } } }, [isWebcamStarted])これで、アプリが500ミリ秒ごとにウェブカメラの前に存在する物体を検出するように設定されます。この値は、物体検出の速度に応じて変更可能ですが、頻繁に行いすぎると、アプリがブラウザのメモリを大量に消費する可能性があるため注意が必要です。
- 状態コンテナ
predictionに予測データが格納されたため、これを使用してライブビデオフィードにラベルと物体周辺のボックスを表示することができます。これには、ObjectDetectionのreturnを以下のように更新します。return ( <div className="object-detection"> <div className="buttons"> <button onClick={isWebcamStarted ? stopWebcam : startWebcam}>ウェブカメラを{isWebcamStarted ? "停止" : "開始"}</button> </div> <div className="feed"> {isWebcamStarted ? <video ref={videoRef} autoPlay muted /> : <div />} {/* 以下のタグを追加して、p要素でラベルをdiv要素でボックスを表示 */} {predictions.length > 0 && ( predictions.map(prediction => { return <> <p style={{ left: `${prediction.bbox[0]}px`, top: `${prediction.bbox[1]}px`, width: `${prediction.bbox[2] - 100}px` }}>{prediction.class + ' - with ' + Math.round(parseFloat(prediction.score) * 100) + '% confidence.'}</p> <div className={"marker"} style={{ left: `${prediction.bbox[0]}px`, top: `${prediction.bbox[1]}px`, width: `${prediction.bbox[2]}px`, height: `${prediction.bbox[3]}px` }} /> </> }) )} </div> {/* 以下のタグを追加して、ユーザーに予測一覧を表示 */} {predictions.length > 0 && ( <div> <h3>予測一覧</h3> <ul> {predictions.map((prediction, index) => ( <li key={index}> {`${prediction.class} (${(prediction.score * 100).toFixed(2)}%)`} </li> ))} </ul> </div> )} </div> );これにより、ウェブカメラのフィードのすぐ下に予測値の一覧がレンダリングされます。Coco SSDからの座標を使用して予測した物体の周りにボックスが描画され、ボックスの上部にはラベルが表示されます。
- ボックスとラベルのスタイリングとして、index.cssファイルに以下のコードを貼り付けます。
.feed { position: relative; p { position: absolute; padding: 5px; background-color: rgba(255, 111, 0, 0.85); color: #FFF; border: 1px dashed rgba(255, 255, 255, 0.7); z-index: 2; font-size: 12px; margin: 0; } .marker { background: rgba(0, 255, 0, 0.25); border: 1px dashed #fff; z-index: 1; position: absolute; } }以上でアプリの開発が完了です。開発サーバーを再起動して、アプリケーションをテストしてみましょう。以下のようになるはずです。

ウェブカメラを利用したリアルタイム物体検出のデモ
コードの全貌は、GitHubリポジトリでご覧いただけます。
構築したアプリをKinstaにデプロイする
最後に、構築したアプリケーションをKinstaにデプロイし、実際にユーザーが利用できるようにします。Kinstaでは任意のGitサービス(Bitbucket、GitHub、GitLab)から、最大100まで静的サイトを無料でホスティングすることができます。
Gitリポジトリを用意したら、以下の手順に従って物体検出アプリをKinstaにデプロイしていきます。
- ログインするか、アカウントを作成してMyKinstaを開く
- GitサービスでKinstaを認証する
- 左サイドバーの「静的サイト」を選択し「サイトの追加」をクリック
- デプロイしたいリポジトリとブランチを選択
- サイトに一意の名前を割り当てる
- 次の形式でビルド設定を追加
- ビルドコマンド:
yarn buildまたはnpm run build - Nodeのバージョン:
20.2.0 - 公開ディレクトリ:
dist
- ビルドコマンド:
- 「サイトを作成」をクリック
アプリがデプロイされたら、ダッシュボードでアプリを選択し、右上の「アプリケーションに移動」をクリックすると、アプリを開くことができます。さまざまなカメラ付きデバイスを実行し、パフォーマンスをテストしてみてください。
静的サイトサーバーだけでなく、Kinstaのウェブアプリケーションサーバーでも静的サイトをデプロイすることができます。優れたスケーラビリティ、Dockerfileを使用したデプロイメントのカスタマイズ、リアルタイムおよび過去のデータを網羅する包括的な分析など、より高度な機能をご利用いただけます。
まとめ
React、TensorFlow.js、Kinstaを使用したリアルタイムの物体検出アプリケーションの構築方法をご紹介しました。コンピュータビジョンの世界を探求しながら、ブラウザでインタラクティブな体験を提供できるようになります。
今回例として使用したCoco SSDモデルは、あくまでプロジェクトの出発点です。TensorFlow.jsを使ってカスタムオブジェクト検出を探求することで、要件に応じた特定の物体を検出するためのアプリも構築することができます。
このアプリは、拡張現実体験やスマート監視システムのような、より高度なアプリケーションを構築するための足掛かりとなります。Kinstaの信頼性に優れたサーバーにアプリをデプロイすることで、構築したアプリを世界に配信し、コンピュータビジョンの力を具現化することができます。
リアルタイム物体検出が役に立つような課題に遭遇したことはありますか?以下のコメント欄でぜひお聞かせください。


