
ウェブサイトは、ただコンテンツを公開するためだけに作られているわけではなく、メタデータは、見栄えのために形だけ整えてられているものではありません。Google検索は長年にわたり、Webクローラーの巡回を通じて、サイトの可視性を左右する主要な入口であり続けています。
1990年代後半以降、Googlebotをはじめとする従来のクローラーは、サイトを巡回してHTMLページを取得し、インデックスを作成することで、人々が探している情報にたどり着けるよう支えてきました。2024年1月時点では、Googleが米国のウェブトラフィックの63%を占め、その大部分は上位170のドメインによって牽引されています。
ところが今、その状況は変わりつつあります。マッキンゼーの調査によれば、顧客の約半数が、ChatGPT、Claude、Gemini、PerplexityといったAIツールに即座に答えを求めます。Google自身も、AI Overviewsのような機能を通じて、AI生成の要約を検索結果に組み込むようになりました。
こうしたAI主導の新しい体験の裏側では、「AIクローラー」と呼ばれるボットの存在感が急速に増しています。WordPressサイトを運営している場合、これらのクローラーがコンテンツにどのようにアクセスし、どのように利用しているのかを理解することは、これまで以上に重要です。この記事では、AIクローラーとは何か、そしてWordPressサイトでの対応策をご紹介します。
AIクローラーとは?
AIクローラーは、一般にアクセス可能なウェブページをスキャンするボットで、検索エンジンのクローラーと似ていますが、目的が異なります。AIクローラーは、検索順位のためにページをインデックス化するのではなく、大規模な言語モデルを学習させたり、AIが生成するレスポンスに最新の情報を提供したりするためにコンテンツを収集します。
AIクローラーは、大きく分けて2つのグループに分類できます。
- GPTBot(OpenAI)やClaudeBot(Anthropic)などのトレーニング用クローラー:より正確に質問に答える方法を大規模な言語モデルに教えるため、トレーニング用のデータを収集
- ChatGPT-Userなどのリアルタイムクローラー:製品説明の確認やドキュメントの閲覧など、最新の情報が必要な質問をされた際に、リアルタイムでサイトにアクセス
また、PerplexityBotやAmazonBotなど、サードパーティのソースへの依存を減らすために、独自のインデックスやシステムを構築しているクローラーもあります。目的はそれぞれ異なりますが、サイトからコンテンツを取得して読み取るという点は共通しています。
AIクローラーの仕組み
AIクローラーがサイトに訪問すると、通常以下のようなことを行います。
- ページのURLに基本的なGETリクエストを送る(インタラクション、スクロール、DOMイベントは行わない)
- サーバーから返された最初のHTMLのみを取得(クライアント側のJavaScriptの読み込みや実行を待たない)
<a href="">、<img src="">、<script src="">、その他のリソースリンクをすべて抽出し、内部(場合によっては外部)のURLをクロールキューに追加(多くの場合、404エラーを返すリンク切れもヒット)- 画像、CSSファイル、スクリプトなどのリンク先のアセットを取得しようとすることもあるが、あくまで生のリソースとしてであり、ページをレンダリングするわけではない
- 発見されたリンクに対してこのプロセスを再帰的に繰り返し、サイトをマッピングする
AIクローラーとWordPressサイトの関係
WordPressは、PHPを使用して完全なHTMLページを生成してからブラウザに送信するサーバーレンダリングプラットフォームです。通常クローラーがWordPressサイトを訪問すると、必要なものすべて(コンテンツ、見出し、メタデータ、ナビゲーション)をHTMLレスポンスで取得します。
このサーバーレンダリング構造により、ほとんどのWordPressサイトはデフォルトで「クローラーフレンドリー」になります。Googlebotであっても、AIクローラーであっても、基本的にはサイトをスキャンし、コンテンツを簡単に理解します。実際、コンテンツがクロールされやすいことは、WordPressが従来の検索だけでなく、新しいAI駆動型プラットフォームでも高いパフォーマンスを発揮できる理由のひとつです。
AIクローラーへの対応
AIクローラーは、デフォルトの状態でもすでに多くのWordPressサイトの内容を読み取れます。したがって、「何をアクセスさせたいのか」、そしてその可視性をどのようにコントロールするかが重要です。
今日、コンテンツ主導のビジネスではこのテーマへの関心が高まっており、対象はブログ記事、ドキュメント、ランディングページなど、ウェブ向けに書かれたあらゆるコンテンツに及びます。AIプラットフォームがますますリアルタイムデータを取り込むようになり、場合によっては参照元へのリンクも含めるようになったことから、「機械のために書く」という声も一部あります。Googleの検索結果と同じように、LLM(大規模言語モデル)の回答でも自社コンテンツが参照されることが重要になってきています。
以下は、ChatGPTにKinstaが最近リリースした機能について尋ねた例です。ChatGPTはウェブを検索し、変更履歴やリンク先のページをスキャンしたうえで、参照元への直接リンク付きで要約した回答を返します。
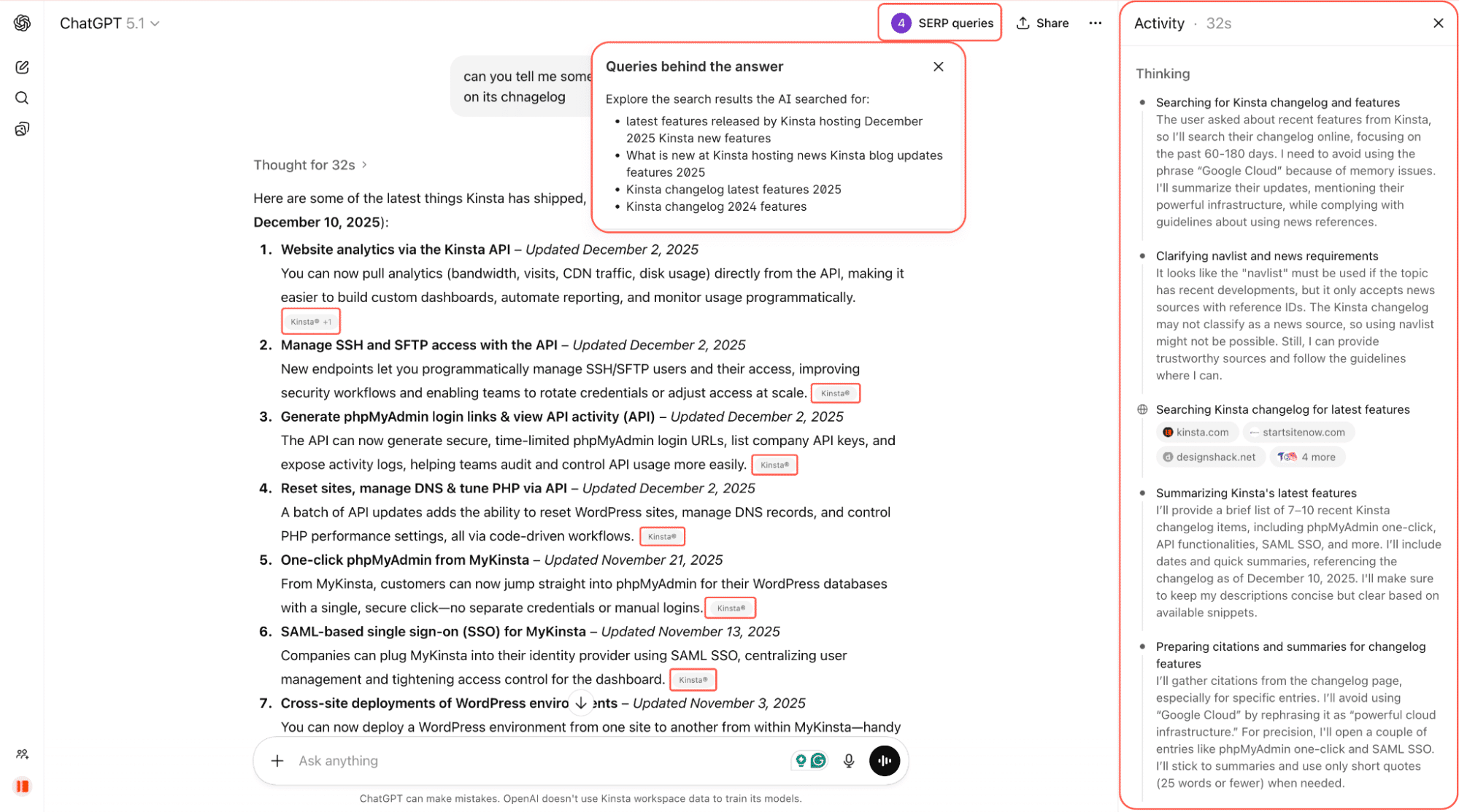
まだ始まったばかりとはいえ、AIクローラーはすでに、一般ユーザーがオンラインで質問したときに目にする情報に影響を与えています。そして、その影響範囲は今後ますます重要になるかもしれません。
VercelのCEOであるGuillermo Rauch氏は、昨年4月、ChatGPT経由の新規登録がVercel全体の約10%に近づき、わずか6か月前は1%未満だったとXで明かしています。これは、AI経由の紹介が短期間で重要な獲得チャネルへと成長し得ることを示しています。
また、AIクローラーはすでに広く普及しています。Cloudflareによると、AIボットは上位100万サイトの約39%にアクセスしていましたが、そのトラフィックをブロックしたり制限をかけたりしたサイトは、そのうち約3%にとどまっていました。
したがって、AIクローラーの対応を検討する以前に、すでにAIクローラーがサイトを訪問している可能性が非常に高いです。
AIクローラーを許可するべきか、ブロックすべきか
AIクローラーを許可すべきか、それともブロックすべきかという問いに正解はありません。とはいえ、方針を決めるときの基準はいくつかります。
-
機密性が高い、または価値の低いパスはブロックする
例:/login、/checkout、/admin、ダッシュボードなどは、検索やAIの回答で「見つけてもらう」ことにほとんど役立たないため、クローラーに巡回させても得るものが少なく、サーバーの通信量や負荷が増えるだけになりがち。 -
「発見されるためのコンテンツ」は許可する
例:ブログ記事、ドキュメント、製品ページ、料金ページなどは、AIの回答で引用されやすく、適切なトラフィック(見込みの高い訪問)につながりやすい領域。 -
プレミアム/ゲート付きコンテンツは戦略的に判断する
コンテンツ自体がビジネスの中核(ニュース、調査レポート、講座など)であれば、AIに制限なくアクセスを許可すると収益や競争力を損なう可能性がある。
また、新たな仕組みも登場しており、例えば、Cloudflareは「Pay Per Crawl」というモデルを試験的に導入しています。現時点ではクローズドベータで本格導入は行われていませんが、コンテンツの利用方法をより細かく制御したいと考える大手パブリッシャーから強い関心を集めています。
一方で、検索・マーケティングのコミュニティでは慎重な見方も。というのも、デフォルトでブロックしてしまうと、本来露出を増やしたいサイトまでAI検索結果での可視性が意図せず下がる可能性があります。今のところ、成熟した収益モデルというよりは、有望な実験段階と言えます。
こうした仕組みが成熟するまでは、現実的なのは「選択的にオープンにする」アプローチです。発見コンテンツはクロール可能な状態を保ちつつ、センシティブな領域はブロックし、エコシステムの変化に合わせてルールを定期的に見直していくのがおすすめです。
WordPressサイトでできるAIクローラー対応策
AIクローラーに自社のWordPressサイトにアクセスされ、コンテンツをスキャンされることに抵抗がある場合は、以下のような対応策があります。
WordPressサイトでAIクローラーのアクセスを制御する3つの方法をご紹介します。
robots.txtファイルを使ってブロック- プラグインを使う
- Cloudflareのボット対策機能を利用する
方法1. robots.txtでAIクローラーをブロックする
robots.txtファイルは、ボットにサイトのどの部分のクロールを許可するかを伝える役割を持っており、OpenAIのGPTBot、AnthropicのClaude-Web、Google-Extendedなど、ほとんどの主要AIクローラーはこれらのルールを尊重しています。
特定のボットを完全にブロックしたり、あるいはアクセスを完全に許可したり、サイトの特定のセクションへのアクセスを制限したりすることができます。例えば、完全にブロックするには、robots.txtファイルに以下を追加します。
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Google-Extended
Disallow: /OpenAIのGPTBotにアクセスを完全に許可する場合は以下。
User-agent: GPTBot
Disallow:サイトの一部分だけをOpenAIのGPTBotからブロック(クローラーが何の価値も与えないログインページなど)する場合は以下。
User-agent: GPTBot
Disallow: /login/このように、必要な領域だけを選んでブロックすることが重要です。/login、/checkout、/adminのような機密性の高いパスは、検索やAIの回答で「見つけてもらう」ことにほとんど役立たないため、基本的にはブロックしておくのが無難です。一方で、製品ページや機能概要、ヘルプセンターなどは、引用や紹介につながりやすいので、クローラーに公開しておく有力な候補になります。
robots.txtファイルは、以下の方法で編集可能です。
- YoastのようなSEOプラグインを使用する(「ツール」>「ファイルエディター」)
- WP File Managerのようなファイルマネージャプラグインを使う
robots.txtファイルをFTP経由でサーバー上で直接編集する
方法2. WordPressプラグインを使う
robots.txtファイルを直接編集するのが面倒な場合や、AIクローラーのアクセスをより速く安全に管理したい場合は、プラグインを使うのが便利です。
Raptive Ads
Raptive Adsプラグインには、AIクローラーをブロックする機能が組み込まれています。
- プラグインの設定からどのボットをブロックするかを設定
- ほとんどのAIボット(GPTBotやClaudeなど)はデフォルトでブロックされる
- Google-Extendedはデフォルトではブロックされないが、必要に応じてGoogleのAIトレーニングをブロックすることができる
このプラグインの主なメリットの1つとして、Google-Extendedをブロックしても、Googleでの表示順位や通常の検索結果での表示には影響しません。
Block AI Crawlers
Block AI Crawlersプラグインは、WordPressサイトの所有者がAIクローラーとコンテンツのやり取りをよりコントロールできるようにするために開発されています。
- サイトの
robots.txtに適切なDisallowルールを自動的に追加し、75以上の既知のAIボットをブロック - 設定が不要で、プラグインをインストールし、「設定」>「表示設定」に移動して「Block AI Crawlers(AIクローラーをブロック)」にチェックを入れるだけでOK
- 軽量かつオープンソースで、GitHubから定期的に更新されている
- ほとんどのWordPressサイトですぐ使えるように設計されている
特に高度なSEOプラグインを使っていないサイトでは、手っ取り早く不要なAIボットをサイトから排除できます。
方法3. Cloudflareのボットファイトモードをオンにする
Cloudflareを使用している場合は、トグルをオンにするだけで、何十もの既知および未知のAIボットをブロックすることができます。
2024年半ば、Cloudflareは、無料プランでも利用可能な専用のAIスクレイパーとクローラー機能を提供開始しました。この機能は、robots.txtに依存するだけでなく、ネットワークレベルでボットをブロックし、その正体を偽るボットもブロックしてくれます。
ボットファイトモードは、以下の手順で有効にできます。
- Cloudflareの管理画面にログイン
- 「セキュリティ」>「設定」に移動
- 上部の「フィルタ条件」から「ボット トラフィック」を選択
- 「ボット ファイト モード」のトグルをオンに

Cloudflareの有料プランを利用している場合は、より柔軟性の高いスーパーボットファイトモードを使用することができます。同じ技術をベースに、異なるトラフィックタイプの処理方法を選択することができ、JavaScript検出を有効にしてヘッドレスブラウザ、ステルススクレイパー、その他の悪意のあるトラフィックを捕捉することが可能です。
例えば、すべてのクローラーをブロックする代わりに、「Definitely automated traffic(確実に自動化されたトラフィック)」だけをブロックし、検索エンジンのクローラーのような「Verified bots(検証済みボット)」を許可するといった設定が可能です。
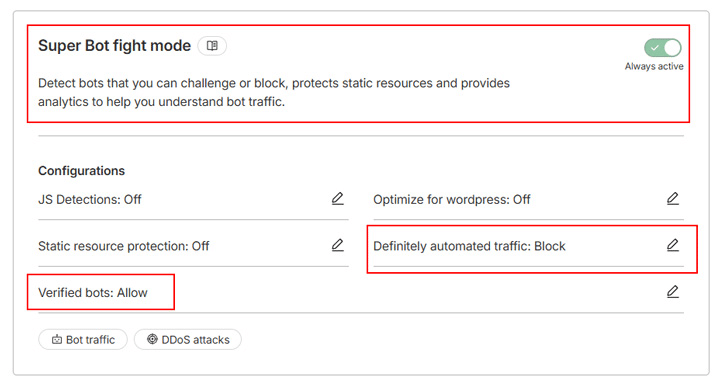
この設定だけで、CloudflareがAIボットからのリクエストを自動的にブロックしてくれます。
Cloudflareを使って不要なボットトラフィックからWordPressサイトを守る方法はこちらで詳しくご紹介しています。
WordPressサイトにとってこの変化が意味すること
AIクローラーは今や、人々がオンラインで情報を見つける方法の一部になっています。技術はまだ新しく、ルールも固まりきっていない中で、サイト運営者は自社のコンテンツをどこまで公開するかを選び始めています。
幸い、WordPressはレンダリング済みのHTMLを出力するため、多くのAIクローラーは特別な対応をしなくてもコンテンツを明確に解釈できます。重要なのは、「AIクローラーがアクセスできるかどうか」ではなく、目的に応じてどの程度のアクセスを許可するかです。
また、サーバー選びには、トラフィックの種類の構成が変化していくにつれて、リソース使用状況を把握し、管理しやすくするものがおすすめです。例えば、Kinstaの帯域幅ベースの料金プランでは、リクエストの発生元にかかわらず、総データ転送量をより予測しやすい形で把握することができます。Cloudflareのボット保護や独自のクローラールールと組み合わせれば、サイトへのアクセス方法を細かく制御することができます。


