
ウェブサイトの鮮度を保ち、検索エンジンでの表示順位を向上させるには、定期的なコンテンツの更新が不可欠。
とは言え、数百、数千もページあるサイトを運営していると、更新内容を検索エンジンにいちいちお知らせするのは、なかなか手間のかかる作業です。そして、サイトを頻繁に更新する場合、その変化がSEOに良い影響を与えているかどうかは、どのように確認すればいいのでしょうか。
そこで役に立つのが、ウェブクローラーです。クローラーは、サイトマップに加えられた変更をスクレイピングし、コンテンツを検索エンジンにインデックスする役割を担います。
この記事では、知っておくべき主要ウェブクローラーボットをご紹介していきます。本題に入る前に、まずはウェブクローラーの定義とその仕組みを押さえておきましょう。
ウェブクローラーとは
ウェブクローラーとは、ウェブページをスキャンし、検索エンジンにインデックス情報を提供するコンピュータプログラムです。「スパイダー」または「ボット(bot)」とも呼ばれます。
検索エンジンが、検索を行うユーザーに最新のページを表示するには、このクローリングが必要になります。この処理は、(クローラーとサイトの設定によって)自動で実行されることもあれば、サイト所有者がリクエストすることもできます。
ウェブページのSEOは、関連性、被リンク、利用しているサーバーサービスなど、さまざまな要素が関係しますが、まずは、検索エンジンにクロールされ、インデックス化されなければ意味がありません。サイトが適切にクロールされる様、妨げになる要素を排除し、クローラビリティを高めることが鍵となります。
クローラーは、できる限り正確な情報を表示するため、サイトを継続的に巡回し、スクレイピングしています。Googleは、米国で最も訪問者数の多いサイトであり、検索の約26.9%は米国拠点のユーザーによるものです。
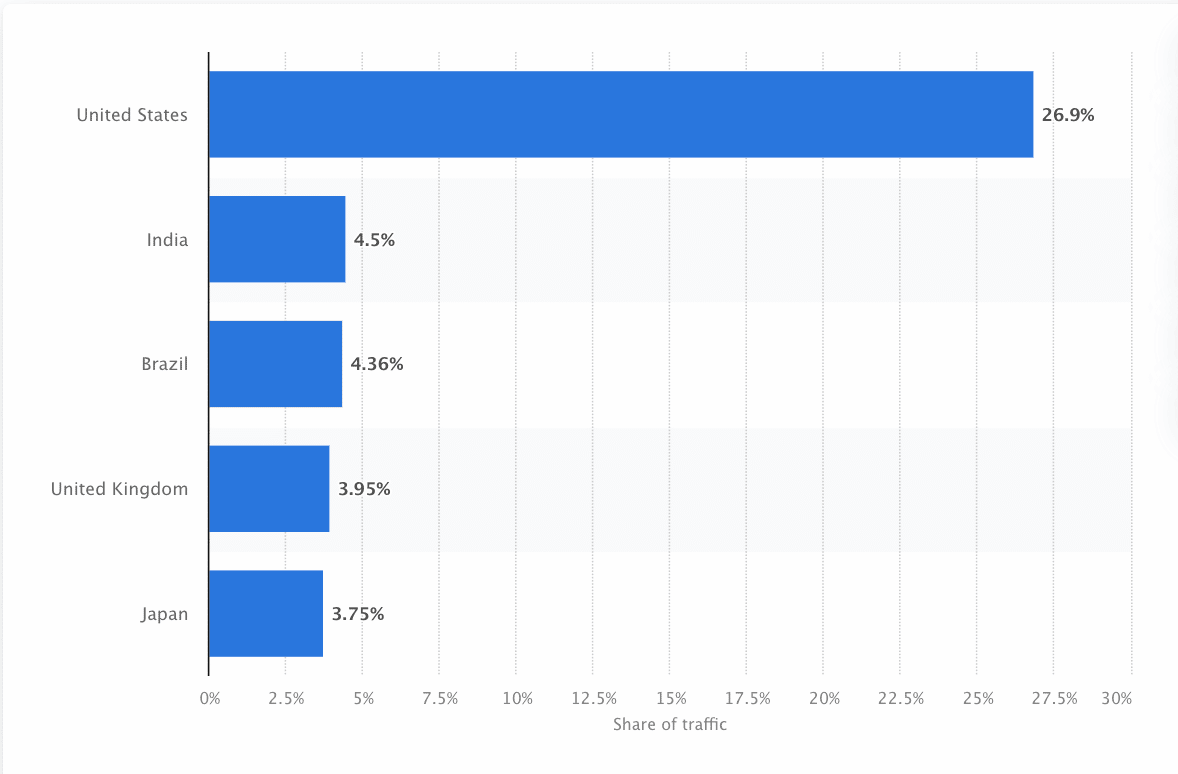
すべての検索エンジン向けにデータを収集する集約的なクローラーは存在しません。検索エンジンには、それぞれ特徴や強みがあります。主要なウェブクローラーを調べてリスト化しておくと、受け入れるべきクローラー、逆に拒否すべきクローラーを区別しやすくなるはずです。
また、マーケティング担当者は、あらゆるクローラーの存在を把握し、(コンテンツを再利用する悪質なコンテンツスクレイパーとは異なり)それぞれどのようにサイトを評価するかを理解した上で、検索エンジン向けランディングページを最適化したいところ。
ウェブクローラーの仕組み
ウェブクローラーは、公開されているウェブページを自動でスキャンし、データをインデックス化します。
そして、ウェブページに関連する特定のキーワードを検出し、取得したデータをGoogleやBingなどの関連検索エンジンに登録(インデックス化)します。
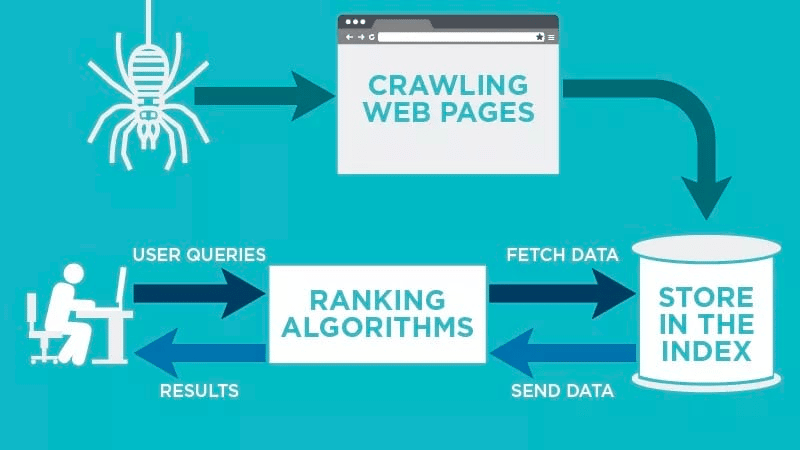
その後、一般ユーザーがキーワードで検索を行うと、検索エンジンのアルゴリズムがそのデータを取得します。
クロールは、既知のURLから優先的に行われます。既知のURLとは、ウェブクローラーの巡回を誘導するシグナルのあるページを意味します。そのシグナルには、以下のようなものが挙げられます。
- 被リンク─ そのページへのリンクが他のサイトに設置された回数
- 訪問者数─そのページへのアクセス数
- ドメインオーソリティ(DA)─ドメインの総合的な質
クローリング後、検索エンジンのインデックスにデータが格納されていきます。ユーザーが検索を開始すると、アルゴリズムがインデックスから取得したデータが検索結果のページに表示される仕組みです。この処理は、数ミリ秒以内に行われるため、ユーザーには検索結果がすぐに表示されるのが一般的です。
サイト運営者は、サーバー上のrobots.txtを使い、どのボットにサイトのクロールを許可するか決めることができます。
つまり、各ウェブページのrobots.txtに記述する内容によって、クローラーにスキャンされたり、インデックスがスキップされたりします。
クローラーが求めている要素を把握することで、その検索エンジンに対してより良いコンテンツを提示することができるようになります。
ウェブクローラーの種類
ウェブクローラーには、大きく分けて以下の3つの種類があります。
- 自社開発のクローラー:企業の開発チームがサイトをスキャンするために開発するクローラー。主にサイトの監査や最適化に使用される。
- SEOツールのクローラー:Screaming FrogのようなSEOツールとあわせて開発されるクローラー。SEO強化のために、自らのコンテンツをクロール、分析するのに使用。
- オープンソースのクローラー:世界中の開発者(またはハッカー)によって構築されるクローラーで無料で利用可能。
事業やサイトの成長に役立つクローラーを見極めるために、ぜひともクローラーの種類は押さえておきましょう。
主要ウェブクローラー12選
すべての検索エンジンに対応する万能クローラーは存在しません。
世界中で利用されている検索エンジンはそれぞれ、ウェブページを巡回し評価するクローラーを持っています。
ここからは、主要ウェブクローラーを見ていきましょう。
1. Googlebot
Googlebotは、Googleの検索エンジンに表示するサイトをクロールするGoogle専用のウェブクローラーです。

Googlebotには、PC版とスマートフォン版がありますが、基本的には1つのクローラーであると言われています。
というのも、どちらも各サイトのrobots.txtに記述された同じユーザーエージェント(UA)名「Googlebot」に従っているためです。
Googlebotは、通常、数秒ごとにサイトを訪れます(サイトのrobots.txtで拒否されていない場合)。スキャンされたページのバックアップは、統合データベースであるGoogleキャッシュに保存され、サイトの旧バージョンも確認することができます。
また、Google Search Consoleは、Googlebotがどのようにサイトをクロールしているかを把握し、ページを検索エンジン向けに最適化するウェブサービスとして存在します。
| User Agent | Googlebot |
| Full User Agent String | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
2. Bingbot
Bingbotは、2010年にMicrosoftによって開発されました。Bingで最新の検索結果が表示されるよう、URLのスキャンとインデックスを行います。
Googlebot同様、サイトのrobots.txtで、Bingbot(ユーザーエージェント名「bingbot」)のクロールを許可するかどうかを定義できます。
Bingbotでは、最近ユーザーエージェント名に変更があり、モバイルファーストインデックスのクローラーとPC版のクローラーが区別されるようになりました。これにより、Bing Webmaster Toolsを駆使することで、サイトへのアクセスや検索結果表示状況について高い柔軟性が確保できます。
| User Agent | Bingbot |
| Full User Agent String | Desktop – Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36
Mobile – Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) “W.X.Y.Z” will be substituted with the latest Microsoft Edge version Bing is using, for eg. “100.0.4896.127″ |
3. Yandex Bot
Yandex Botは、Yandex専用のクローラーです。Yandexは、ロシア最大、かつロシアで最も使用されている検索エンジンです。

Yandex Botについても、robots.txtファイルを使用して、自分のサイトのページをクロールさせるように設定できます。
さらに、特定のページに「Yandex.Metrica」タグを追加したり、Yandex Webmasterでページを再インデックスしたり、IndexNowプロトコル(新規、変更、無効化されたページが表示される)を作成したりすることも可能です。
| User Agent | YandexBot |
| Full User Agent String | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
4. Applebot
Applebotは、AppleのSiriやSpotlightの提案で紹介されるウェブページのクロールとインデックス作成を行います。
SiriとSpotlightの提案に表示させるコンテンツの順位を決定する際には、さまざまな要素が考慮されます。これには、ユーザーエンゲージメント、検索キーワードの関連性、リンク数と質、位置情報ベースのシグナル、ウェブページのデザインが挙げられます。
| User Agent | Applebot |
| Full User Agent String | Mozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, like Gecko) Version/Safari_version Safari/WebKit_version (Applebot/Applebot_version) |
5. DuckDuckBot
DuckDuckBotは、ウェブブラウザ上でシームレスなプライバシー保護を提供するDuckDuckGoの専用クローラーです。
DuckDuckBot APIを使用すると、DuckDuckBotが自分のサイトを巡回しているかどうかを確認することができます。クロールされると、DuckDuckBot APIのデータベースにIPアドレスとユーザーエージェントが保存されます。
これによって、DuckDuckBotになりすました偽物や悪質なボットを特定できます。
| User Agent | DuckDuckBot |
| Full User Agent String | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
6. Baidu Spider
Baidu Spiderは、中国の大手検索エンジンであるBaidu(百度)の専用クローラーです。

中国では、Googleの利用が禁止されているため、中国市場に事業を拡大する場合には、Baidu Spiderによるクロールを有効にすることが重要です。
自分のサイトがBaidu Spiderにクロールされているかを確認するには、baiduspider、 baiduspider-image、baiduspider-videoなどのユーザーエージェント名に注目してください。
中国市場に事業を展開する予定がない場合には、robots.txtでBaidu Spiderをブロックすると、Baiduの検索結果ページ(SERP)にサイトが表示されなくなります。
| User Agent | Baiduspider |
| Full User Agent String | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
7. Sogou Spider
Sogou(捜狗)もまた中国の検索エンジンです。100億件の中国語ページをインデックスした最初の検索エンジンと言われています。

Sogou Spiderは、中国市場で事業を行うなら、Baidu同様、必ず押さえておきたい人気検索エンジンクローラーです。robots.txtとcrawl-delayの設定に従ってクロールを行います。
Baidu Spider同様、中国に顧客や読者を持たない場合には、サイト速度の最適化のため拒否することをお勧めします。
| User Agent | Sogou Pic Spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou head spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07) Sogou Orion spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (compatible; MSIE 5.5; Windows 98) |
8. Facebookクローラー
Facebookクローラー(別名Facebook External Hit)は、Facebook上で共有されているアプリやウェブサイトのHTMLをクロールします。

クローリングによって、Facebook上に投稿された各リンクについて、(共有時に有用となる)タイトル、説明文、サムネイル画像などのプレビューが生成されます。
数秒以内にコンテンツをクロールできないとFacebook上にコンテンツが表示されなくなるため、注意が必要です。
| User Agent | facebot facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
9. Exabot
2000年に誕生した、パリに本社を構えるソフトウェア会社Exalead。同社は、消費者および企業向けの検索プラットフォームを運営しています。
Exabotは、同社のCloudView製品上に構築されたコア検索エンジンのクローラーです。
多くの検索エンジンと同様、Exaleadでは、被リンクとウェブページのコンテンツを指標に、表示順位が決まります。Exaleadのクローラー(ユーザーエージェント)であるExabotにより、訪問者に表示する検索結果をまとめたメインインデックスが作成されます。
| User Agent | Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Exabot-Thumbnails) Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot) |
10. Swiftbot
続いては、Swiftypeというサイト内検索サービスのクローラーです。同サービスは、一流の検索技術、アルゴリズム、コンテンツ取得フレームワーク、クライアント、分析ツールの融合を謳っています。
ページ数の膨大な複雑なサイトであっても、Swiftypeを使ってすべてのページを簡単にカタログ化、インデックス化できます。
SwiftypeのウェブクローラーであるSwiftbotは、他のボットとは異なり、顧客にリクエストされたサイトのみをクロールします。
| User Agent | Swiftbot |
| Full User Agent String | Mozilla/5.0 (compatible; Swiftbot/1.0; UID/54e1c2ebd3b687d3c8000018; +http://swiftype.com/swiftbot) |
11. Slurp Bot
Slurp Botは、Yahoo!の検索ボットで、Yahoo!の検索結果に表示されるページのクロール、インデックス化を担います。
また、Slurp Botは、Yahoo.comだけでなく、Yahoo!ニュース、Yahoo!ファイナンス、Yahoo!スポーツなどのクローラーでもあり、関連サイトの一覧表示に貢献しています。
コンテンツのインデックス化により、検索結果における関連性が高まり、利用者にとってのパーソナライズも実現します。
| User Agent | Slurp |
| Full User Agent String | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) |
12. CCBot

CCBotは、非営利団体Common Crawlが開発したNutchベースのウェブクローラー。法人個人を問わず、オンライン調査を行うユーザー向けにインターネットのコピーを無償提供することを目的としています。CCBotは、MapReduceというプログラミングフレームワークを採用しており、大量のデータを価値ある集計結果に凝縮することができます。
このCCBotの機能を活用して、Common Crawlのデータを使って言語翻訳ソフトを改良したり、トレンドを予測したりすることも。今話題のGPT-3の大部分は、Common Crawlから得たデータセットで訓練されています。
| User Agent | CCBot/2.0 (https://commoncrawl.org/faq/) CCBot/2.0 CCBot/2.0 (http://commoncrawl.org/faq/) |
SEOツールのクローラー8選
主要ウェブクローラーを12種類押さえたところで、次に、人気のSEOツールとそのクローラーも見ていきましょう。
1. AhrefsBot
AhrefsBotは、人気SEOソフトウェアであるAhrefsが提供する12兆件のリンクデータベースを集計し、インデックスを作成するウェブクローラーです。
AhrefsBotは、毎日60億のウェブサイトを巡回し、Googlebotに次いで2番目にアクティブなクローラーとして知られています。
他のボットと同様、robots.txtの設定、および各サイトのコードにある許可/不許可の指示に従って動作します。
2. Semrush Bot
Semrush Botは、SEOソフトウェアの代表企業Semrushのクローラーです。同社のプラットフォーム上で顧客が使用するサイトデータを収集、インデックス化しています。
取得されたデータは、Semrushの機能であるバックリンク(被リンク)分析、Site Audit、Backlink Audit、Link Building Tool、SEO Writing Assistantに使用されます。
Semrush Botによるサイト巡回は、具体的には、ページのURL一覧作成、各ページの訪問、次回以降のクロールを考慮した特定のハイパーリンクの保存といった流れになります。
3. Rogerbot
Rogerbotは、大手SEOサイトMozの専用クローラーで、主にMoz Pro Campaign機能のサイト監査用にコンテンツを収集します。

robots.txtファイルで設定されたすべてのルールに準拠するため、Rogerbotによるクロールの許可/不許可の指定が可能です。
また、Rogerbotでは多面的なアプローチが採用されており、固定IPアドレスを検索して、自分のサイトのどのページがクロールされたかを確認することはできません。
4. Screaming Frog
Screaming Frogは、SEO担当者向けのクローラーで、サイトを監査し、検索エンジンの表示順位に影響を与える問題点を特定することができます。

クロールでリアルタイムのデータを確認し、リンク切れやページタイトル、メタデータ、ボット、重複コンテンツなどの改善点を把握することができます。
クロールのパラメータを設定するには、ライセンスの購入が必要です。
5. Lumar(旧DeepCrawl)
Lumarは、サイトの技術的健全性確保のための「司令室」のようなテクニカルSEOツールです。Lumarを使用してサイトをクロールし、サイトの設計を行うことができます。
Lumarは、市場最速のサイトクローラーであると謳っており、1秒間に最大450件のURLをクロールします。
6. Majestic
Majesticは、サイトの被リンクの追跡と特定に重点を置いたツールです。

同社は、インターネット上で最も包括的な被リンクデータを有している企業の1社であると宣言し、「ヒストリックインデックス」(2021年には5年から15年分のリンクに増加)を売りにしています。
クローラーによって収集された情報は、同社SEOツールを利用することで詳細データとして確認することができます。
7. cognitiveSEO
cognitiveSEOもまた、多くのSEO担当者やマーケターが利用する優れたSEOソフトウェアです。
cognitiveSEOのクローラーを使用し、サイトアーキテクチャや包括的なSEOの施策を支えるサイト監査を行うことができます。
ページをクロールし、利用者の設定に従って柔軟にデータを収集してくれます。他のクローラーの扱いの面でどのようにサイトを改善できるか、といった提案もされます。検索結果上位表示や不要なクローラーの拒否に利用できる有益な情報です。
8. Oncrawl
Oncrawlは、業界を牽引するSEOクローラーおよびログ分析ツールで、大企業向けにサービスを展開しています。
アカウントを作成し、特定のパラメータ(開始URL、クロール制限、最大クロール速度など)を設定することが可能で、設定を保存しておけば、いつでも同じパラメータでクロールを行うことができます。
悪意のあるウェブクローラーからサイトを守るには
残念ながら、サイトにとって、すべてのクローラーが有益になるというわけではありません。ページの表示速度に悪影響を与えるものもあれば、ハッキングなどの悪意のあるクローラーも存在します。
したがって、ボットのクロールを拒否する方法も知っておくことが重要です。
主要クローラーを網羅し、どのクローラーが優良であるかを把握して、怪しいクローラーはブロックリストに追加しましょう。
悪質なクローラーをブロックする方法
主要なクローラーを幅広く押さえておけば、どれを許可し、どれを拒否するかを選別しやすくなります。
まずは、各クローラーに関連する識別情報、ユーザーエージェントとUA文字列、およびIPアドレスを一覧にしましょう。
ユーザーエージェントとIPアドレスがあれば、DNSルックアップ、またはIP照合で、この2つが一致するかどうかを調べることができます。完全に一致しない場合は、優良なクローラーを装った悪意のあるボットである可能性があります。
その場合は、robots.txtのメタタグでクロールの許可設定を変更し、悪質なクローラーを拒否しましょう。
まとめ
ウェブクローラーは、検索エンジンを支える存在。マーケターであれば、深い理解が必要です。
サイトの成功のためには、適切なクローラーに巡回されることが不可欠。主要なクローラーを幅広く把握しておくことで、ログが表示された際に、どのクローラーに注意すべきかを確認することができます。
SEOツールのクローラーの推奨事項をもとに、サイトのコンテンツと速度を改善すれば、サイトのクローラビリティが向上し、検索エンジンと検索を行うユーザーに向けて、正しい情報をインデックスすることができます。


