
Como qualquer proprietário de site lhe dirá, a perda de dados e o tempo de inatividade, mesmo em doses mínimas, podem ser catastróficos. Eles podem atingir o despreparado a qualquer momento, levando à redução da produtividade, acessibilidade e confiança no produto.
A fim de proteger a integridade do seu site, é essencial ter proteções contra a possibilidade de paradas ou perda de dados.
É aí que entra a replicação de dados.
A replicação de dados é um processo de backup automatizado no qual seus dados são repetidamente copiados de seu banco de dados principal para outro local remoto para serem mantidos em segurança. É uma tecnologia integral para qualquer site ou aplicativo rodando um servidor de banco de dados. Você também pode aproveitar o banco de dados replicado para processar SQL somente leitura, permitindo que mais processos sejam executados dentro do sistema.
A configuração da replicação entre duas bases de dados oferece tolerância a falhas contra contratempos inesperados. É considerada a melhor estratégia para se atingir alta disponibilidade durante desastres.
Neste artigo, vamos mergulhar nas diferentes estratégias que podem ser implementadas pelos desenvolvedores backend para a replicação sem problemas do PostgreSQL.
O que é replicação PostgreSQL?
A replicação PostgreSQL é definida como o processo de cópia de dados de um servidor de banco de dados PostgreSQL para outro servidor. O servidor de banco de dados de origem também é conhecido como servidor “primário”, enquanto o servidor de banco de dados que recebe os dados copiados é conhecido como servidor “réplica”.
O banco de dados PostgreSQL segue um modelo de replicação simples, onde todas as escritas vão para um node primário. O node primário pode então aplicar estas mudanças e transmiti-las para o node secundário.
O que é Failover automático?
Failover é um método para recuperar dados se o servidor primário ceder por qualquer razão. Desde que você tenha configurado o PostreSQL para gerenciar sua replicação física de streaming, você – e seus usuários – estarão protegidos do tempo de inatividade devido a um snafu do servidor primário.
Note que o processo de failover pode levar algum tempo para ser configurado e iniciado. Não há ferramentas integradas para monitorar e escanear falhas de servidor no PostgreSQL, então você precisará ser criativo.
Felizmente, você não precisa ser dependente do PostgreSQL para o failover. Existem ferramentas dedicadas que permitem o failover automático e a comutação automática para o modo standby, reduzindo o tempo de inatividade do banco de dados.
Ao configurar a replicação de failover, você garante uma alta disponibilidade, garantindo que os standbys estejam disponíveis se o servidor primário algum dia falhar.
Benefícios de usar a replicação PostgreSQL
Aqui estão alguns dos principais benefícios de alavancar a replicação do PostgreSQL:
- Migração de dados: Você pode aproveitar a replicação PostgreSQL para migração de dados através de uma mudança no hardware do servidor de banco de dados ou através da implantação do sistema.
- Tolerância a falhas: Se o servidor primário falhar, o servidor standby pode agir como um servidor porque os dados contidos tanto para o servidor primário quanto para o standby são os mesmos.
- Desempenho do processamento transacional online (OLTP): Você pode melhorar o tempo de processamento de transações e o tempo de consulta de um sistema OLTP, removendo a carga de consulta de relatórios. O tempo de processamento da transação é a duração que leva para que uma determinada consulta seja executada antes que uma transação seja concluída.
- Teste do sistema em paralelo: Ao atualizar um novo sistema, você precisa ter certeza de que o sistema funciona bem com os dados existentes, daí a necessidade de testar com uma cópia do banco de dados de produção antes da implantação.
Como funciona a replicação PostgreSQL
Em geral, as pessoas acreditam que quando você está se envolvendo com uma arquitetura primária e secundária, só há uma maneira de configurar backups e replicação. As implementações do PostgreSQL, no entanto, podem seguir qualquer um desses três métodos:
- Replicação em fluxo contínuo: Replica dados do node primário para o secundário, depois copia dados para o Amazon S3 ou Azure Blob para armazenamento de backup.
- Replicação em nível de volume: Replica dados na camada de armazenamento, começando do node primário para o secundário, depois copia os dados para o Amazon S3 ou Azure Blob para armazenamento de backup.
- Backups incrementais: Replica dados do node primário enquanto constrói um novo node secundário do armazenamento do Amazon S3 ou do Azure Blob, permitindo o streaming diretamente do node primário.
Método 1: Streaming
A replicação do PostgreSQL também conhecida como replicação WAL pode ser configurada perfeitamente após a instalação do PostgreSQL em todos os servidores. Esta abordagem de replicação é baseada em mover os arquivos WAL do banco de dados primário para o banco de dados alvo.
Você pode implementar a replicação do PostgreSQL através de uma configuração primária secundária. O servidor primário é a instância principal que lida com o banco de dados primário e todas as suas operações. O servidor secundário atua como instância suplementar e executa todas as mudanças feitas no banco de dados primário em si mesmo, gerando uma cópia idêntica no processo. O servidor primário é o servidor de leitura/gravação enquanto o servidor secundário é meramente de leitura.
Para este método, você precisa configurar tanto o node primário quanto o node de espera. As seções seguintes irão elucidar os passos envolvidos na configuração deles com facilidade.
Configurando o Node primário
Você pode configurar o node primário para replicação de streaming, executando os seguintes passos:
Passo 1: Inicialize o banco de dados
Para inicializar o banco de dados, você pode utilizar o comando utilitário initdb. Em seguida, você pode criar um novo usuário com privilégios de replicação, utilizando o seguinte comando:
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';O usuário terá que fornecer uma senha e um nome de usuário para a consulta em questão. A palavra-chave de replicação é usada para dar ao usuário os privilégios necessários. Um exemplo de consulta seria algo parecido com isto:
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';Passo 2: Configure as propriedades do Streaming
A seguir, você pode configurar as propriedades de streaming com o arquivo de configuração do PostgreSQL (postgresql.conf) que pode ser modificado da seguinte forma:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onAqui está um pequeno fundo em torno dos parâmetros usados no trecho anterior:
wal_log_hints: Este parâmetro é necessário para a capacidadepg_rewindque vem a calhar quando o servidor standby está fora de sincronia com o servidor primário.wal_level: Você pode usar este parâmetro para habilitar a replicação de fluxo do PostgreSQL, com possíveis valores incluindominimal,replica, oulogical.max_wal_size: Isto pode ser usado para especificar o tamanho dos arquivos WAL que podem ser retidos em arquivos de log.hot_standby: Você pode utilizar este parâmetro para uma conexão de leitura com o secundário quando ele estiver definido como ON.max_wal_senders: Você pode usarmax_wal_senderspara especificar o número máximo de conexões simultâneas que podem ser estabelecidas com os servidores standby.
Passo 3: Criando nova entrada
Após você ter modificado os parâmetros no arquivo postgresql.conf, uma nova entrada de replicação no arquivo pg_hba.conf pode permitir que os servidores estabeleçam uma conexão uns com os outros para replicação.
Você geralmente pode encontrar este arquivo no diretório de dados do PostgreSQL. Você pode usar o seguinte trecho de código para o mesmo:
host replication rep_user IPaddress md5Uma vez que o trecho de código é executado, o servidor primário permite que um usuário chamado rep_user se conecte e atue como servidor de espera, usando o IP especificado para replicação. Por exemplo, o IP especificado para replicação:
host replication rep_user 192.168.0.22/32 md5Configurando o node de espera
Para configurar o node de espera para replicação de streaming, siga estes passos:
Passo 1: Backup do node primário
Para configurar o node de espera, utilize o utilitário pg_basebackup para gerar um backup do node primário. Isto servirá como um ponto de partida para o node de espera. Você pode usar este utilitário com a seguinte sintaxe:
pg_basebackp -D -h -X stream -c fast -U rep_user -WOs parâmetros usados na sintaxe mencionada acima são os seguintes:
-h: Você pode usar isto para mencionar o host primário.-D: Este parâmetro indica o diretório no qual você está trabalhando atualmente.-C: Você pode usar isto para definir os pontos de verificação.-X: Este parâmetro pode ser usado para incluir os arquivos de log transacional necessários.-W: Você pode usar este parâmetro para solicitar ao usuário uma senha antes de criar um link para o banco de dados.
Passo 2: Prepare o arquivo de configuração da replicação
A seguir, você precisa verificar se o arquivo de configuração da replicação existe. Se não existir, você pode gerar o arquivo de configuração de replicação como recovery.conf.
Você deve criar este arquivo no diretório de dados da instalação do PostgreSQL. Você pode gerá-lo automaticamente usando a opção -R dentro do utilitário pg_basebackup.
O arquivo recovery.conf deve conter os seguintes comandos:
standby_mode = 'on'primary_conninfo = 'host=<master host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"''recovery_target_timeline = 'latest' (mais recente)
Os parâmetros usados nos comandos acima são os seguintes:
primary_conninfo: Você pode usar isto para fazer uma conexão entre os servidores primário e secundário, alavancando uma cadeia de conexão.standby_mode: Este parâmetro pode fazer com que o servidor primário comece como standby quando ligado.recovery_target_timeline: Você pode usar isto para definir o tempo de recuperação.
Para configurar uma conexão, você precisa fornecer o nome de usuário, endereço IP e senha como valores para o parâmetro primary_conninfo. Por exemplo:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Passo 3: Reinicie o servidor secundário
Finalmente, você pode reiniciar o servidor secundário para completar o processo de configuração.
No entanto, a replicação do streaming vem com vários desafios, como por exemplo:
- Vários clientes PostgreSQL (escritos em diferentes linguagens de programação) conversam com um único endpoint. Quando o node primário falha, estes clientes continuarão tentando novamente o mesmo DNS ou nome IP. Isto torna o failover visível para a aplicação.
- A replicação do PostgreSQL não vem com failover e monitoramento embutidos. Quando o node primário falhar, você precisa promover um secundário para ser o novo primário. Esta promoção precisa ser executada de forma que os clientes escrevam para apenas um node primário, e eles não observem inconsistências de dados.
- O PostgreSQL replica todo o seu estado. Quando você precisa desenvolver um novo node secundário, o secundário precisa recapitular todo o histórico de mudança de estado do node primário, o que é intensivo em recursos e torna caro eliminar os node na cabeça e criar novos.
Método 2: Dispositivo de bloco replicado
O método do dispositivo de bloco replicado depende do espelhamento de disco (também conhecido como replicação de volume). Nesta abordagem, as mudanças são escritas em um volume persistente que é espelhado de forma síncrona em outro volume.
O benefício adicional deste método é sua compatibilidade e durabilidade de dados em ambientes de nuvem com todos os bancos de dados relacionais, incluindo PostgreSQL, MySQL, e SQL Server, para citar alguns.
Entretanto, a abordagem de espelhamento em disco da replicação do PostgreSQL precisa que você replique tanto o log WAL quanto os dados da tabela. Já que cada um escreve no banco de dados agora precisa passar pela rede de forma síncrona, você não pode se dar ao luxo de perder um único byte, pois isso poderia deixar seu banco de dados em um estado corrupto.
Este método é normalmente alavancada usando o Azure PostgreSQL e o Amazon RDS.
Método 3: WAL
WAL consiste de arquivos de segmento (16 MB por padrão). Cada segmento tem um ou mais registros. Um log sequence record (LSN) é um ponteiro para um registro no WAL, deixando você saber a posição/localização onde o registro foi salvo no arquivo de registro.
Um servidor standby utiliza segmentos WAL – também conhecido como XLOGS na terminologia do PostgreSQL – para replicar continuamente as mudanças de seu servidor primário. Você pode usar o registro write-ahead para garantir durabilidade e atomicidade em um SGBD através da serialização de pedaços de dados de byte-array (cada um com um LSN único) para armazenamento estável antes que eles sejam aplicados a um banco de dados.
A aplicação de uma mutação em um banco de dados pode levar a várias operações de sistema de arquivos. Uma questão pertinente que surge é como um banco de dados pode assegurar atomicidade no caso de uma falha no servidor devido a uma queda de energia enquanto ele está no meio de uma atualização do sistema de arquivos. Quando um banco de dados inicia, ele inicia um processo de inicialização ou replay que pode ler os segmentos WAL disponíveis e os compara com o LSN armazenado em cada página de dados (cada página de dados é marcada com o LSN do último registro WAL que afeta a página).
Replicação baseada no envio de logs (nível de bloco)
A replicação em fluxo refina o processo de envio de log. Ao contrário de esperar pela chave WAL, os registros são enviados à medida que são criados, diminuindo assim o atraso de replicação.
A replicação em fluxo contínuo também supera o envio de logs porque o servidor standby se conecta com o servidor primário através da rede, alavancando um protocolo de replicação. O servidor primário pode então enviar registros WAL diretamente sobre esta conexão sem ter que depender de scripts fornecidos pelo usuário final.
Replicação baseada no envio de logs (nível de arquivo)
O envio de logs é definido como cópia de arquivos de log para outro servidor PostgreSQL para gerar outro servidor standby através da reprodução de arquivos WAL. Este servidor é configurado para trabalhar em modo de recuperação, e seu único propósito é aplicar quaisquer novos arquivos WAL conforme eles aparecem.
Este servidor secundário então se torna um backup quente do servidor primário do PostgreSQL. Ele também pode ser configurado para ser uma réplica lida, onde ele pode oferecer consultas somente leitura, também chamada de hot standby.
Arquivamento WAL Contínuo
A duplicação de arquivos WAL como eles são criados em qualquer local que não seja o subdiretório pg_wal para arquivá-los é conhecida como arquivamento WAL. PostgreSQL irá chamar um script dado pelo usuário para arquivamento, cada vez que um arquivo WAL for criado.
O script pode aproveitar o comando scp para duplicar o arquivo para um ou mais locais, como uma montagem NFS. Uma vez arquivados, os arquivos do segmento WAL podem ser alavancados para recuperar o banco de dados em qualquer ponto no tempo.
Outras configurações baseadas em log incluem:
- Replicação síncrona: Antes de cada transação de replicação síncrona ser comprometida, o servidor primário espera até que os standbys confirmem que eles receberam os dados. O benefício desta configuração é que não haverá conflitos causados devido a processos de escrita paralelos.
- Replicação síncrona multi-mester: Aqui, cada servidor pode aceitar solicitações de escrita, e os dados modificados são transmitidos do servidor original para todos os outros servidores antes de cada transação ser comprometida. Ele aproveita o protocolo 2PC e adere à regra do “tudo ou nada”.
Detalhes do protocolo WAL Streaming
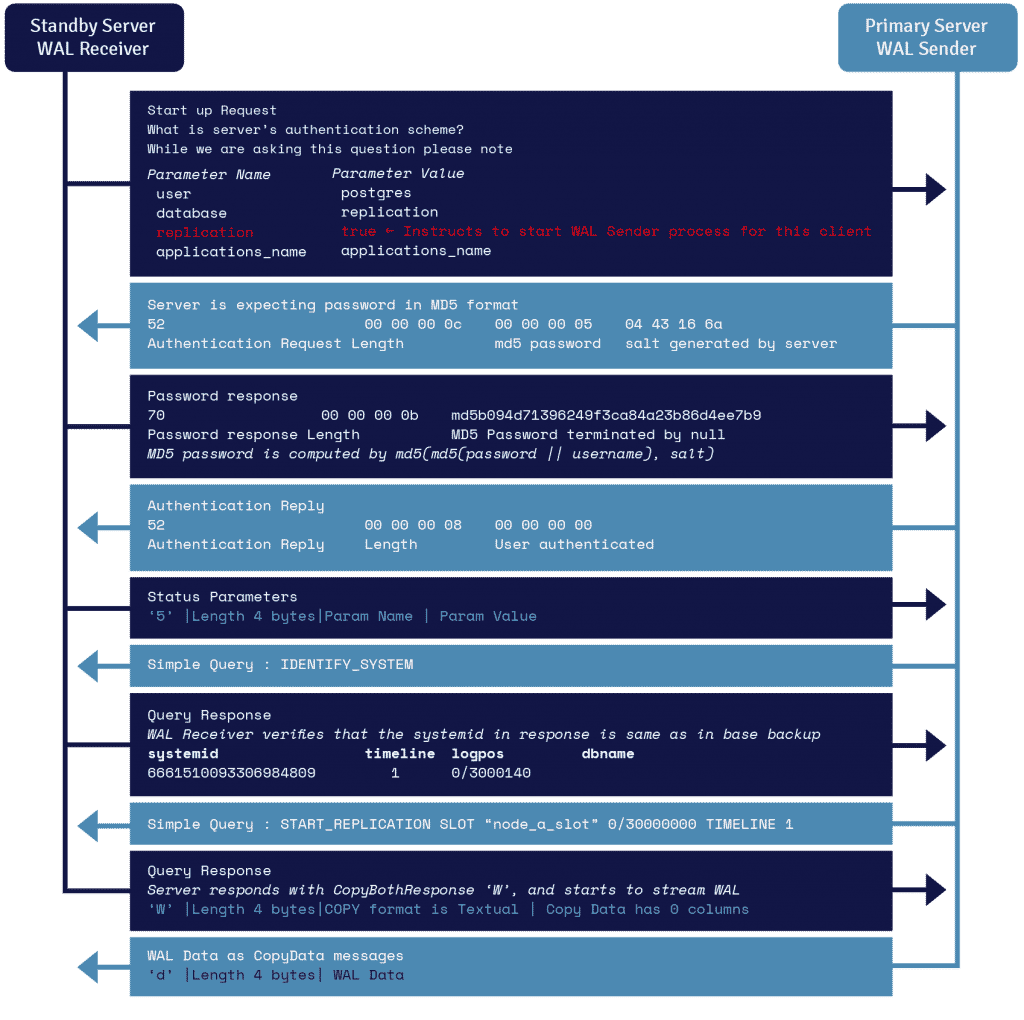
Um processo conhecido como receptor WAL, rodando no servidor standby, aproveita os detalhes da conexão fornecidos no parâmetro de recovery.conf primary_conninfo e se conecta ao servidor primário alavancando uma conexão TCP/IP.
Para iniciar a replicação do streaming, o frontend pode enviar o parâmetro de replicação dentro da mensagem de inicialização. Um valor booleano de verdadeiro, sim, 1, ou ON permite ao backend saber que ele precisa entrar no modo walsender de replicação física.
O WAL sender é outro processo que roda no servidor primário e está encarregado de enviar os registros WAL para o servidor de espera à medida que eles são gerados. O receptor WAL salva os registros WAL no WAL como se eles fossem criados pela atividade do cliente de clientes conectados localmente.
Assim que os registros WAL chegam aos arquivos do segmento WAL, o servidor de espera continua constantemente reproduzindo o WAL para que o primário e o de espera estejam atualizados.
Elementos da replicação do PostgreSQL
Nesta seção, você terá uma compreensão mais profunda dos modelos comumente utilizados (replicação single-master e multi-master), tipos (replicação física e lógica) e modos (síncrono e assíncrono) de replicação PostgreSQL.
Modelos de replicação do banco de dados PostgreSQL
Escalabilidade significa adicionar mais recursos/ hardware aos nodes existentes para aumentar a capacidade do banco de dados de armazenar e processar mais dados que podem ser alcançados horizontal e verticalmente. A replicação do PostgreSQL é um exemplo de escalabilidade horizontal que é muito mais difícil de implementar do que a escalabilidade vertical. Nós podemos alcançar escalabilidade horizontal principalmente pela replicação de um single-master (SMR) e replicação multi-master (MMR).
A replicação multi-master permite que os dados sejam modificados somente em um único node, e estas modificações são replicadas em um ou mais nodes. As tabelas replicadas no banco de dados de réplicas não têm permissão para aceitar quaisquer alterações, exceto aquelas do servidor primário. Mesmo que aceitem, as alterações não são replicadas de volta ao servidor primário.
Na maioria das vezes, o SMR é suficiente para a aplicação porque é menos complicado de configurar e gerenciar, sem chances de conflitos. A replicação de um single-master também é unidirecional, uma vez que os dados de replicação fluem em uma direção principalmente, do banco de dados primário para o banco de dados de réplicas.
Em alguns casos, SMR sozinho pode não ser suficiente, e você pode precisar implementar MMR. O MMR permite que mais de um node aja como o node primário. Mudanças nas linhas da tabela em mais de um banco de dados primário designado são replicadas para suas tabelas contrapartes em todos os outros bancos de dados primários. Neste modelo, esquemas de resolução de conflitos são frequentemente empregados para evitar problemas como duplicação de chaves primárias.
Há algumas vantagens no uso do MMR, a saber:
- No caso de falha do host, outros hosts ainda podem dar serviços de atualização e inserção.
- Os nós primários estão espalhados em vários locais diferentes, então a chance de falha de todos os nós primários é muito pequena.
- Capacidade de empregar uma rede de área ampla (WAN) de bancos de dados primários que podem estar geograficamente próximos a grupos de clientes, mas mantendo a consistência dos dados em toda a rede.
Entretanto, o lado negativo da implementação do MMR é a complexidade e sua dificuldade para resolver conflitos.
Vários ramos e aplicações fornecem soluções MMR, pois o PostgreSQL não o suporta nativamente. Estas soluções podem ser open-source, gratuitas ou pagas. Uma dessas extensões é a replicação bidirecional (BDR) que é assíncrona e é baseada na função de decodificação lógica do PostgreSQL.
Como a aplicação BDR reproduz transações em outros nodes, a operação de replay pode falhar se houver um conflito entre a transação sendo aplicada e a transação comprometida no node receptor.
Tipos de replicação PostgreSQL
Existem dois tipos de replicação PostgreSQL: replicação lógica e física.
Uma simples operação lógica initdb realizaria a operação física de criar um diretório base para um cluster. Da mesma forma, uma simples operação lógica CREATE DATABASE realizaria a operação física de criação de um subdiretório no diretório base.
A replicação física geralmente lida com arquivos e diretórios. Ela não sabe o que esses arquivos e diretórios representam. Estes métodos são usados para manter uma cópia completa dos dados completos de um único cluster, tipicamente em outra máquina, e são feitos no nível do sistema de arquivos ou no nível do disco e usam endereços de bloco exatos.
A replicação lógica é uma forma de reproduzir entidades de dados e suas modificações, com base em sua identidade de replicação (geralmente uma chave primária). Ao contrário da replicação física, ela lida com bancos de dados, tabelas e operações de DML e é feita em nível de cluster de bancos de dados. Ele usa um modelo de publicação e assinatura onde um ou mais assinantes são assinantes de uma ou mais publicações em um node editor.
O processo de replicação começa tirando um instantâneo dos dados no banco de dados da editora e depois copiando-os para o assinante. Os assinantes retiram os dados das publicações que assinam e podem re-publicar os dados posteriormente para permitir replicação em cascata ou configurações mais complexas. O assinante aplica os dados na mesma ordem que o editor para que a consistência transacional seja garantida para publicações dentro de uma única assinatura, também conhecida como replicação transacional.
Os casos típicos de uso para replicação lógica são:
- Envio de mudanças incrementais em um único banco de dados (ou um subconjunto de um banco de dados) aos assinantes à medida que elas ocorrem.
- Compartilhar um subconjunto da base de dados entre múltiplas bases de dados.
- Acionar o disparo de mudanças individuais à medida que elas chegam ao assinante.
- Consolidação de múltiplas bases de dados em uma só.
- Fornecendo acesso a dados replicados para diferentes grupos de usuários.
O banco de dados de assinantes comporta-se da mesma forma que qualquer outra instância PostgreSQL e pode ser usado como editor para outros bancos de dados definindo suas publicações.
Quando o assinante é tratado como somente leitura por aplicação, não haverá conflitos a partir de uma única assinatura. Por outro lado, se houver outras escritas feitas por um aplicativo ou por outros assinantes para o mesmo conjunto de tabelas, podem surgir conflitos.
O PostgreSQL suporta ambos os mecanismos simultaneamente. A replicação lógica permite um controle fino tanto sobre a replicação de dados quanto sobre a segurança.
Modos de replicação
Há principalmente dois modos de replicação PostgreSQL: síncrono e assíncrono. A replicação síncrona permite que os dados sejam escritos no servidor primário e secundário ao mesmo tempo, enquanto a replicação assíncrona assegura que os dados sejam primeiro escritos no host e depois copiados para o servidor secundário.
No modo de replicação síncrona, as transações no banco de dados primário são consideradas completas somente quando essas mudanças tiverem sido replicadas em todas as réplicas. Os servidores de réplicas devem estar todos disponíveis o tempo todo para que as transações sejam completadas no banco de dados primário. O modo síncrono de replicação é usado em ambientes transacionais high-end com requisitos de failover imediato.
No modo assíncrono, as transações no servidor primário podem ser declaradas completas quando as mudanças tiverem sido feitas apenas no servidor primário. Estas mudanças são então replicadas nas réplicas mais tarde no tempo. Os servidores de réplicas podem permanecer fora da sincronização por uma certa duração, chamada de lag de replicação. No caso de uma falha, pode ocorrer perda de dados, mas a sobrecarga fornecida pela replicação assíncrona é pequena, então é aceitável na maioria dos casos (não sobrecarrega o host). O failover do banco de dados primário para o banco de dados secundário leva mais tempo do que a replicação síncrona.
Como configurar a replicação do PostgreSQL
Para esta seção, estaremos demonstrando como configurar o processo de replicação PostgreSQL em um sistema operacional Linux. Para este exemplo, estaremos usando Ubuntu 18.04 LTS e PostgreSQL 10.
Vamos ao que interessa!
Instalação
Você vai começar instalando o PostgreSQL no Linux com estes passos:
- Primeiramente, você teria que importar a chave de assinatura do PostgreSQL digitando o comando abaixo no terminal:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Então, adicione o repositório PostgreSQL digitando o comando abaixo no terminal:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Atualize o Índice Repositório digitando o seguinte comando no terminal:
sudo apt-get update - Instale o pacote PostgreSQL usando o comando apt:
sudo apt-get install -y postgresql-10 - Finalmente, defina a senha para o usuário do PostgreSQL usando o seguinte comando:
sudo passwd postgres
A instalação do PostgreSQL é obrigatória tanto para os servidores primários quanto secundários antes de iniciar o processo de replicação do PostgreSQL.
Uma vez que você tenha configurado o PostgreSQL em ambos os servidores, você pode passar para a configuração de replicação do servidor primário e secundário.
Configurando a replicação no servidor primário
Execute estes passos uma vez que você tenha instalado o PostgreSQL tanto no servidor primário quanto no secundário.
- Em primeiro lugar, faça o login no banco de dados do PostgreSQL com o seguinte comando:
su - postgres - Crie um usuário replicador com o seguinte comando:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Edite pg_hba.cnf com qualquer aplicação nano no Ubuntu e adicione a seguinte configuração:
nano /etc/postgresql/10/main/pg_hba.confPara configurar o arquivo, use o seguinte comando:
host replication replication MasterIP/24 md5 - Abra e edite o postgresql.conf e coloque a seguinte configuração no servidor primário:
nano /etc/postgresql/10/main/postgresql.confUse as seguintes configurações:
listen_addresses = 'localhost,MasterIP' wal_level = replica wal_keep_segments = 64 max_wal_senders = 10 - Finalmente, reiniciar o PostgreSQL no servidor principal:
systemctl restart postgresqlAgora você completou a configuração no servidor primário.
Configurando a replicação no servidor secundário
Siga estes passos para configurar a replicação no servidor secundário:
- Acesse o PostgreSQL RDMS com o comando abaixo:
su - postgres - Pare o serviço PostgreSQL de funcionar para que possamos trabalhar nele com o comando abaixo:
systemctl stop postgresql - Edite o arquivo pg_hba.conf com este comando e adicione a seguinte configuração:
// "Edit" command nano /etc/postgresql/10/main/pg_hba.conf // "Configuration" command host replication replication MasterIP/24 md5 - Abra e edite o postgresql.conf no servidor secundário e coloque a seguinte configuração ou uncomment se for comentado:
nano /etc/postgresql/10/main/postgresql.conf listen_addresses = 'localhost,SecondaryIP' wal_keep_segments = 64 wal_level = replica hot_standby = on max_wal_senders = 10SecondaryIP é o endereço do servidor secundário
- Acesse o diretório de dados do PostgreSQL no servidor secundário e remova tudo:
cd /var/lib/postgresql/10/main rm -rfv * - Copie os arquivos do diretório de dados do servidor primário PostgreSQL para o diretório de dados do servidor secundário PostgreSQL e escreva este comando no servidor secundário:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -U replication --wal-method=fetch - Digite a senha do servidor primário PostgreSQL e pressione enter. A seguir, adicione o seguinte comando para a configuração da recuperação:
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configuration standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'</code>Aqui,
YOUR_PASSWORDé a senha para o usuário replicador no servidor primário PostgreSQL criado - Uma vez que a senha tenha sido definida, você teria que reiniciar o banco de dados secundário do PostgreSQL desde que ele foi parado:
systemctl start postgresqlTestando sua configuração
Agora que já executamos os passos, vamos testar o processo de replicação e observar o banco de dados do servidor secundário. Para isso, nós criamos uma tabela no servidor primário e observamos se o mesmo é refletido no servidor secundário.
Vamos a isso.
- Já que estamos criando a tabela no servidor primário, você precisará fazer o login no servidor primário:
su - postgres psql - Agora nós criamos uma tabela simples chamada ‘testtable’ e inserimos dados na tabela executando as seguintes consultas do PostgreSQL no terminal:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Observe o banco de dados secundário do servidor PostgreSQL fazendo login no servidor secundário:
su - postgres psql - Agora, nós verificamos se a tabela ‘testtable’ existe, e podemos retornar os dados executando as seguintes consultas do PostgreSQL no terminal. Este comando essencialmente exibe a tabela inteira.
select * from testtable;
Esta é a saída da tabela de teste:
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------Você deve ser capaz de observar os mesmos dados que os do servidor primário.
Se você vir o acima, então você realizou com sucesso o processo de replicação!
Quais são as etapas de failover do manual do PostgreSQL?
Vamos rever os passos para um failover manual do PostgreSQL:
- Crash no servidor primário.
- Promova o servidor standby executando o seguinte comando no servidor standby:
./pg_ctl promote -D ../sb_data/ server promoting - Conecte-se ao servidor standby promovido e insira uma linha:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
Se o encarte funcionar bem, então o standby, anteriormente um servidor somente de leitura, foi promovido como o novo servidor primário.
Como automatizar o failover no PostgreSQL
Configurar o failover automático é fácil.
Você vai precisar do gerenciador de failover do EDB PostgreSQL (EFM). Após baixar e instalar o EFM em cada node primário e de espera, você pode criar um Cluster EFM, que consiste de um node primário, um ou mais nodes de espera e um node de testemunha opcional que confirma as afirmações em caso de falha.
A EFM monitora continuamente a saúde do sistema e envia alertas por e-mail com base nos eventos do sistema. Quando ocorre uma falha, ele muda automaticamente para o standby mais atualizado e reconfigura todos os outros servidores standby para reconhecer o novo node primário.
Ele também reconfigura os balanceadores de carga (como o pgPool) e evita a ocorrência de “split-brain” (quando dois nós pensam que cada um deles é primário).
Resumo
Devido à alta quantidade de dados, escalabilidade e segurança tornaram-se dois dos critérios mais importantes no gerenciamento de bancos de dados, especialmente em um ambiente de transação. Embora possamos melhorar a escalabilidade verticalmente adicionando mais recursos/hardware aos nodes existentes, isso nem sempre é possível, muitas vezes devido ao custo ou às limitações de adicionar novo hardware.
Portanto, a escalabilidade horizontal é necessária, o que significa adicionar mais nodes aos node s de rede existentes em vez de melhorar a funcionalidade dos nodes existentes. É aqui que a replicação do PostgreSQL entra em cena.
Neste artigo, nós discutimos os tipos de replicações PostgreSQL, benefícios, modos de replicação, instalação e failover do PostgreSQL entre SMR e MMR. Agora vamos ouvir de você.
Qual você costuma implementar? Qual recurso de banco de dados é o mais importante para você e por quê? Nós adoraríamos ler seus pensamentos! Compartilhe-os na seção de comentários abaixo.

Salman Ravoof é um desenvolvedor web autodidata, escritor, criador e grande admirador de Software Livre e de Código Aberto (FOSS). Além de tecnologia, ele se entusiasma com ciência, filosofia, fotografia, artes, gatos e comida. Saiba mais sobre ele em seu site e conecte-se com Salman no X.

