
Websites werden nicht nur erstellt, um Inhalte zu veröffentlichen, und Metadaten werden nicht nur zum Spaß gepflegt. All diese Aktivitäten arbeiten zusammen, damit deine Seiten leichter gefunden werden können. Jahrelang war die Google-Suche das wichtigste Tor zu dieser Sichtbarkeit, vor allem dank der Webcrawler von Google.
Seit den späten 1990er Jahren haben der Googlebot und andere traditionelle Crawler Websites gescannt, HTML-Seiten abgerufen und indexiert, um Menschen zu helfen, das zu finden, wonach sie suchen. Im Januar 2024 entfielen 63 % des gesamten Internettraffics in den USA auf Google, und zwar auf die 170 wichtigsten Domains.
Laut einer Umfrage von McKinsey wendet sich inzwischen die Hälfte der Kunden an KI-Tools wie ChatGPT, Claude, Gemini oder Perplexity, um sofortige Antworten zu erhalten, und selbst Google mischt KI-generierte Zusammenfassungen in die Suchergebnisse durch Funktionen wie KI-Überblicke.
Hinter diesen neuen KI-gesteuerten Erfahrungen steht eine wachsende Klasse von Bots, die als KI-Crawler bekannt sind. Wenn du eine WordPress-Website betreibst, ist es wichtiger denn je, zu verstehen, wie diese Crawler auf deine Inhalte zugreifen und sie nutzen.
Was sind KI-Crawler?
AI-Crawler sind automatisierte Bots, die öffentlich zugängliche Webseiten durchsuchen, ähnlich wie Suchmaschinen-Crawler, aber mit einem anderen Ziel. Anstatt Seiten für ein traditionelles Ranking zu indizieren, sammeln sie Inhalte, um große Sprachmodelle zu trainieren oder neue Informationen für KI-generierte Antworten zu liefern.
KI-Crawler lassen sich grob in zwei Gruppen einteilen:
- Trainingscrawler wie GPTBot (OpenAI) und ClaudeBot (Anthropic) sammeln Daten, um großen Sprachmodellen beizubringen, wie sie Fragen genauer beantworten können.
- Live-Retrieval-Crawler wie ChatGPT-User greifen in Echtzeit auf Websites zu, wenn jemand eine Frage stellt, für die aktuelle Daten benötigt werden, z. B. um eine Produktbeschreibung zu überprüfen oder eine Dokumentation zu lesen.
Andere Crawler, wie z. B. PerplexityBot oder AmazonBot, bauen ihre eigenen Indizes oder Systeme auf, um ihre Abhängigkeit von Drittquellen zu verringern. Und obwohl sich ihre Ziele unterscheiden, haben sie alle eines gemeinsam: Sie holen und lesen Inhalte von Websites wie der deinen.
Wie KI-Crawler funktionieren
Wenn ein KI-Crawler deine Website besucht, macht er normalerweise Folgendes:
- Er sendet eine einfache GET-Anfrage an die URL der Seite (ohne Interaktion, Scrollen oder DOM-Events).
- Er holt nur den ursprünglichen HTML-Code, der vom Server zurückgegeben wird. Es wird nicht darauf gewartet, dass clientseitiges JavaScript geladen oder ausgeführt wird.
- Extrahiert alle
<a href="">,<img src="">,<script src="">und andere Ressourcenlinks und fügt dann interne (und manchmal auch externe) URLs zu seiner Crawl-Warteschlange hinzu. In vielen Fällen werden auch defekte Links gefunden, die 404-Fehler zurückgeben. - Er kann versuchen, verlinkte Assets wie Bilder, CSS-Dateien oder Skripte zu holen, aber nur als Rohressourcen, nicht zum Rendern der Seite.
- Wiederholt diesen Prozess rekursiv für alle entdeckten Links, um die Website abzubilden.
Wie KI-Crawler mit WordPress-Websites interagieren
WordPress ist eine serverseitig gerenderte Plattform, die PHP verwendet, um vollständige HTML-Seiten zu erzeugen, bevor sie an den Browser gesendet werden. Wenn ein Crawler eine WordPress-Website besucht, erhält er normalerweise alles, was er braucht (Inhalt, Überschriften, Metadaten, Navigation), in der HTML-Antwort.
Diese vom Server gelieferte Struktur macht die meisten WordPress-Seiten natürlich crawlerfreundlich. Egal ob Googlebot oder ein KI-Crawler, sie können deine Seite in der Regel scannen und deinen Inhalt leicht verstehen. Tatsächlich sind leicht crawlbare Inhalte einer der Gründe, warum WordPress sowohl bei der traditionellen Suche als auch bei neueren KI-gesteuerten Plattformen gut abschneidet.
Solltest du KI-Crawlern den Zugriff auf deine Inhalte erlauben?
KI-Crawler können die meisten WordPress-Seiten bereits standardmäßig lesen. Die eigentliche Frage ist, was du ihnen zugänglich machen willst – und wie du diese Sichtbarkeit kontrollieren kannst.
Content-getriebene Unternehmen sind im Moment sehr beschäftigt mit dieser Diskussion. Es geht um Blogbeiträge, Dokumentationen, Landing Pages … eigentlich um alles, was für das Web geschrieben wird. Wahrscheinlich hast du schon den Ratschlag gehört: „Schreib für die Maschinen“, denn KI-Plattformen ziehen zunehmend Live-Daten und enthalten in einigen Fällen auch Links zu Quellen. Wir alle wollen in der LLM-Ausgabe auftauchen, genauso wie wir in den Google-Suchergebnissen auftauchen wollen.
Auf dem Screenshot unten bitten wir ChatGPT, uns einige der neuesten Funktionen von Kinsta zu nennen. Es durchsucht das Internet, scannt Changelogs und verlinkte Seiten und liefert eine zusammengefasste Antwort mit direkten Links zurück zur Quelle.
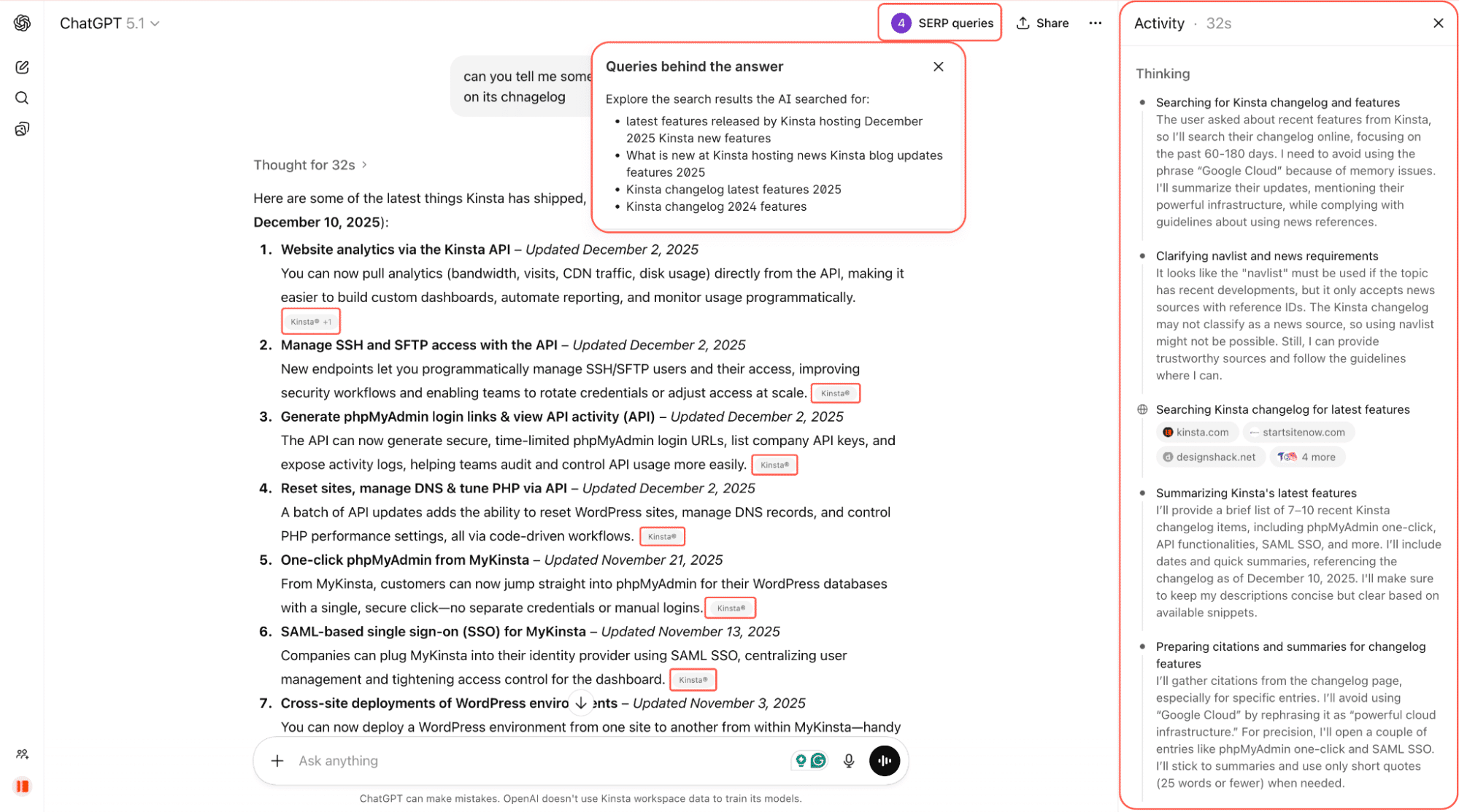
Es ist noch früh, aber die KI-Crawler beeinflussen bereits, was Menschen sehen, wenn sie online Fragen stellen. Und diese Reichweite könnte wichtig sein.
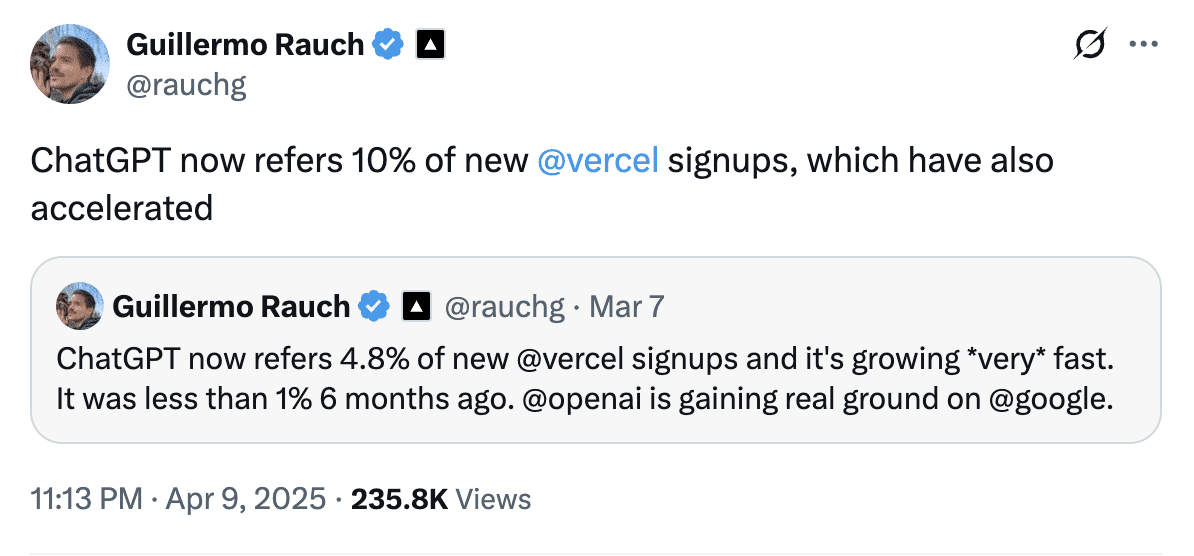
Guillermo Rauch, CEO von Vercel, teilte im April mit, dass ChatGPT für fast 10 % der Neuanmeldungen bei Vercel verantwortlich ist, während es sechs Monate zuvor noch weniger als 1 % waren. Das zeigt, wie schnell sich KI-gesteuerte Empfehlungen zu einem bedeutenden Akquisitionskanal entwickeln können.
Und KI-Crawler sind weit verbreitet. Laut Cloudflare haben KI-Bots auf etwa 39 % der eine Million größten Websites zugegriffen, aber nur etwa 3 % dieser Websites haben diesen Traffic tatsächlich blockiert oder bekämpft.
Selbst wenn du noch keine Entscheidung getroffen hast, besuchen KI-Crawler deine Website mit ziemlicher Sicherheit bereits.
Solltest du KI-Crawler zulassen oder blockieren?
Es gibt keine allgemeingültige Antwort. Es gibt keine allgemeingültige Antwort, aber hier ist ein Rahmen:
- Blockiere Crawler auf sensiblen oder geringwertigen Routen wie
/login,/checkout,/adminoder Dashboards. Diese helfen nicht bei der Entdeckung und verschwenden nur Bandbreite. - Erlaube Crawler für „Entdeckungsinhalte“ wie Blogbeiträge, Dokumentationen, Produktseiten und Preisinformationen. Diese Seiten werden am ehesten in KI-Antworten zitiert und sorgen für qualifizierten Traffic.
- Entscheide dich strategisch für Premium- oder Gated-Inhalte. Wenn dein Inhalt dein Produkt ist (z. B. Nachrichten, Recherchen, Kurse), kann ein unbegrenzter Zugang zu KI dein Geschäft untergraben.
Es gibt neue Tools, die helfen können. Cloudflare zum Beispiel experimentiert mit einem Modell namens Pay Per Crawl, das es Website-Betreibern ermöglicht, KI-Unternehmen für den Zugang zu bezahlen. Das Modell befindet sich noch in der privaten Beta-Phase, aber die Idee wird von großen Verlagen unterstützt, die mehr Kontrolle darüber haben wollen, wie ihre Inhalte genutzt werden.
Andere in der Such- und Marketing-Community sind vorsichtiger, da die standardmäßige Sperrung die Sichtbarkeit in den KI-Suchergebnissen für Websites, die diese Sichtbarkeit tatsächlich wünschen, ungewollt verringern könnte. Im Moment ist es eher ein vielversprechendes Experiment als eine ausgereifte Einnahmequelle.
Bis diese Systeme ausgereift sind, ist der praktischste Ansatz die selektive Offenheit, bei der du die Entdeckungsinhalte crawlbar hältst, sensible Bereiche blockierst und deine Regeln überprüfst, wenn sich das Ökosystem weiterentwickelt.
So kontrollierst du den KI-Crawler-Zugriff auf WordPress
Wenn du dich nicht wohl dabei fühlst, dass KI-Crawler auf deine WordPress-Website zugreifen und deren Inhalte scannen, ist die gute Nachricht, dass du die Kontrolle zurückerlangen kannst.
Hier sind drei Möglichkeiten, den KI-Crawler-Zugriff auf WordPress zu steuern:
- Manuelles Bearbeiten deiner
robots.txtDatei. - Verwende ein Plugin, das dies für dich erledigt.
- Nutze den Bot-Schutz von Cloudflare.
Lass uns alle drei Optionen durchgehen.
Option 1: AI-Crawler manuell mit der robots.txt blockieren
Deine robots.txt Datei teilt Bots mit, welche Teile deiner Website sie crawlen dürfen. Die meisten bekannten KI-Crawler, wie GPTBot von OpenAI, Claude-Web von Anthropic und Google-Extended, halten sich an diese Regeln.
Du kannst bestimmte Bots komplett blockieren, ihnen vollen Zugang gewähren oder den Zugang zu bestimmten Bereichen deiner Website einschränken. Wenn du zum Beispiel alles blockieren willst, kannst du dies in deine robots.txt Datei aufnehmen, obwohl dies für die meisten Websites nicht empfohlen wird:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Google-Extended
Disallow: /Um OpenAIs GPTBot vollen Zugriff zu gewähren:
User-agent: GPTBot
Disallow:Um nur einen Teil deiner Website für OpenAIs GPTBot zu sperren. Zum Beispiel deine Anmeldeseite, auf der Crawler keinen Mehrwert schaffen:
User-agent: GPTBot
Disallow: /login/Diese Art des selektiven Blockierens ist entscheidend. Sensible Routen wie /login, /checkout oder /admin tragen nicht zur Auffindbarkeit bei und sollten fast immer blockiert werden. Andererseits sind Produktseiten, Funktionsübersichten oder dein Hilfecenter gute Kandidaten, um sie für Crawler offen zu halten, da sie für Zitate und Verweise sorgen können.
Du kannst diese robots.txt Datei manuell hinzufügen, indem du:
- Mit einem SEO-Plugin wie Yoast (Extras > Dateieditor).
- Mit einem Dateimanager-Plugin wie WP File Manager.
- Oder du bearbeitest deine
robots.txtDatei direkt auf dem Server per FTP.
Option 2: Ein WordPress-Plugin verwenden
Wenn du die Datei robots.txt nicht direkt bearbeiten möchtest oder einfach einen schnelleren und sichereren Weg suchst, um den Zugriff von AI-Crawlern zu verwalten, können Plugins diese Aufgabe mit ein paar Klicks für dich übernehmen.
Raptive Ads
Das WordPress-Plugin Raptive Ads bietet integrierte Unterstützung für das Blockieren von AI-Crawlern:
- Du kannst direkt in den Einstellungen des Plugins festlegen, welche Bots blockiert werden sollen.
- Die meisten AI-Bots (wie GPTBot und Claude) sind standardmäßig blockiert.
- Google-Extended wird nicht standardmäßig blockiert, aber du kannst das Kästchen ankreuzen, wenn du das KI-Training von Google ablehnen möchtest.
Ein wichtiger Vorteil dieses Plugins ist, dass das Blockieren von Google-Extended keine Auswirkungen auf dein Google-Ranking oder deine Sichtbarkeit in den regulären Suchergebnissen hat.
KI-Crawler blockieren
Das Plugin Block AI Crawlers wurde speziell entwickelt, um WordPress-Seitenbesitzern mehr Kontrolle darüber zu geben, wie AI-Crawler mit ihren Inhalten interagieren. So geht’s:
- Blockiert 75+ bekannte AI Bots, indem es automatisch die richtigen
DisallowRegeln zu deiner Websiterobots.txthinzufügt. - Es ist keine Konfiguration erforderlich. Installiere das Plugin, gehe zu Einstellungen > Lesen und aktiviere das Kästchen KI-Crawler blockieren.
- Leichtgewichtig und quelloffen, mit regelmäßigen Updates von GitHub.
- Das Plugin ist so konzipiert, dass es auf den meisten WordPress-Installationen sofort funktioniert.
Das Block AI Crawlers Plugin ist eine der einfachsten Methoden, um unerwünschte KI-Bots von deiner Website fernzuhalten, vor allem, wenn du keine erweiterten SEO-Plugins verwendest.
Option 3: Nutze den One-Click AI Bot Blocker von Cloudflare
Wenn deine WordPress-Website Cloudflare nutzt (und das tun viele), kannst du Dutzende von bekannten und unbekannten KI-Bots mit einem einzigen Schalter blockieren.
Mitte 2024 hat Cloudflare eine spezielle Funktion für AI Scrapers und Crawlers eingeführt, die sogar im kostenlosen Tarif verfügbar ist. Diese Funktion verlässt sich nicht nur auf robots.txt, sondern blockiert Bots auf der Netzwerkebene, auch solche, die lügen, wer sie sind.
Du kannst sie wie folgt aktivieren:
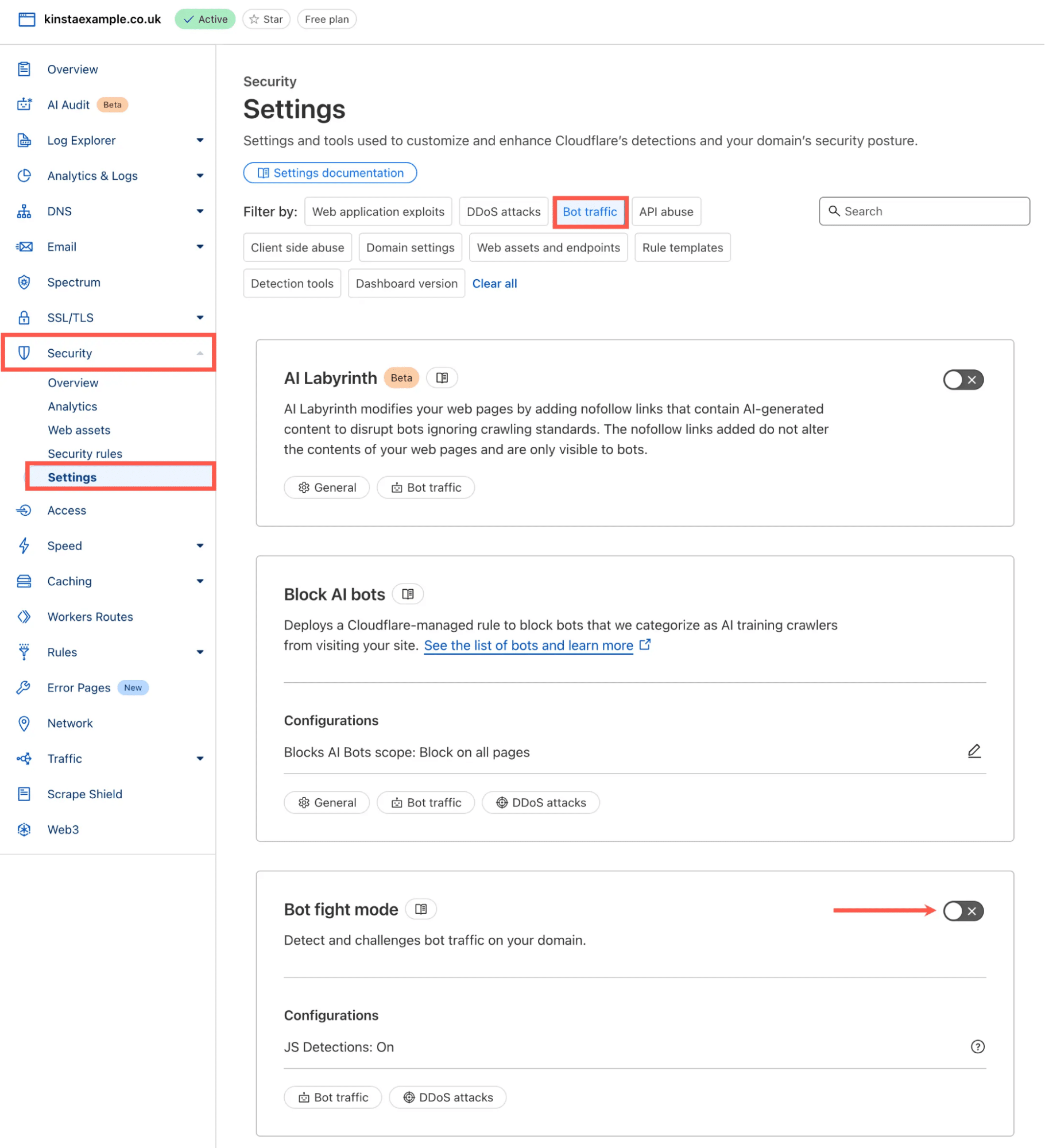
- Melde dich in deinem Cloudflare Dashboard an
- Gehe zu Sicherheit > Einstellungen
- Wähle unter dem Abschnitt Filtern nach die Option Bot-Traffic.
- Finde den Bot-Bekämpfungsmodus und schalte ihn ein.
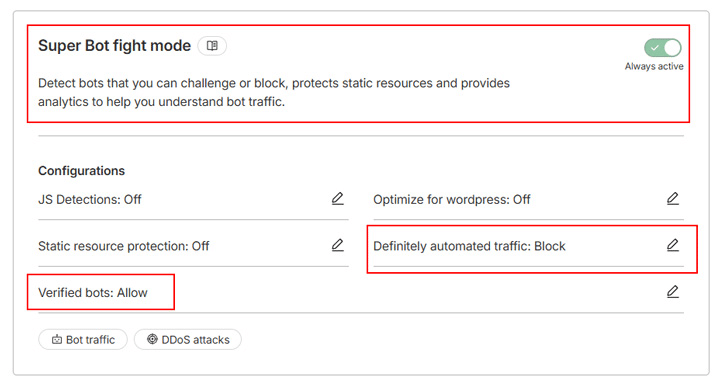
Wenn du einen kostenpflichtigen Cloudflare-Tarif nutzt, hast du Zugriff auf den Super Bot Fight Mode, eine erweiterte Version des Bot Fight Mode mit mehr Flexibilität. Er basiert auf der gleichen Technologie, lässt dich aber wählen, wie du mit verschiedenen Arten von Datenverkehr umgehen willst. So kannst du JavaScript-Erkennungen aktivieren, um Headless-Browser, heimliche Scraper und anderen bösartigen Datenverkehr abzufangen.
Anstatt alle Crawler zu blockieren, kannst du das Tool zum Beispiel so konfigurieren, dass es nur „definitiv automatisierten Verkehr“ blockiert und „verifizierte Bots“ wie Suchmaschinen-Crawler zulässt:
Das war’s. Cloudflare blockiert automatisch Anfragen von KI-Bots.
Wenn du einen genaueren Blick darauf werfen willst, wie diese Tools zusammenarbeiten, einschließlich Bot Fight Mode, Super Bot Fight Mode und gezielte Challenge-Regeln, kannst du unseren vollständigen Leitfaden zum Schutz deiner WordPress-Website vor unerwünschtem Bot-Traffic mit Cloudflare lesen.
Was diese Veränderung für deine WordPress-Website bedeutet
KI-Crawler sind jetzt Teil der Art und Weise, wie Menschen Informationen online entdecken. Die Technologie ist neu, die Regeln sind noch im Entstehen begriffen, und die Website-Besitzer entscheiden, wie viele ihrer Inhalte sie zur Verfügung stellen wollen.
Die gute Nachricht ist, dass WordPress-Seiten bereits in einer starken Position sind. Da WordPress vollständig gerendertes HTML ausgibt, können die meisten KI-Crawler deine Inhalte ohne besondere Behandlung klar interpretieren. Die wirkliche strategische Entscheidung ist nicht , ob KI-Crawler auf deine Website zugreifen können – es geht darum, wie sehr der Zugriff deine Ziele unterstützt.
Und da sich der Mix an Traffic-Arten weiterentwickelt, ist es hilfreich, Hosting-Optionen zu haben, die die Ressourcennutzung leichter verständlich und überschaubar machen. Die neuen bandbreitenbasierten Tarife von Kinsta bieten eine berechenbarere Möglichkeit, den gesamten Datentransfer abzurechnen, unabhängig von der Quelle der Anfragen. In Kombination mit dem Bot-Schutz von Cloudflare und deinen eigenen Crawler-Regeln hast du die volle Kontrolle darüber, wie auf deine Website zugegriffen wird.

Joel ist Frontend-Entwickler und arbeitet bei Kinsta als Technical Editor. Er ist ein leidenschaftlicher Lehrer mit einer Vorliebe für Open Source und hat über 200 technische Artikel geschrieben, die sich hauptsächlich um JavaScript und seine Frameworks drehen.

