
Die Erstellung einer Website ist der erste Schritt, um im Internet präsent zu sein. Um langfristig erfolgreich zu sein, musst du auch sicherstellen, dass deine Website skalierbar ist, damit sie wachsen kann. Einer der ersten Schritte ist die Implementierung einer Datenbank, die mit dir skalieren kann. Andernfalls riskierst du eine langsame Abfrageleistung und Datenbankausfälle.
In diesem Beitrag erfährst du, wie du mit Datenbank-Sharding eine hohe Skalierbarkeit und Verfügbarkeit für deine Daten erreichen kannst. Wir gehen auch auf die Nachteile von Sharding und die verschiedenen Sharding-Architekturen ein, die du verwenden kannst.
Was ist Datenbank-Sharding?
Sharding ist eine Optimierungstechnik, bei der Tabellen auf andere Datenbankserver verteilt werden. Es ähnelt der Partitionierung in dem Sinne, dass beide die Daten in kleinere Teilmengen aufteilen. Der Unterschied ist, dass beim Sharding diese Teilmengen auf verschiedene Server verteilt werden, während sie beim Partitioning in einer Datenbank gespeichert werden. Diese Server verwenden dieselbe Datenbank-Engine und denselben Hardware-Typ, um ein ähnliches Leistungsniveau für alle Shards zu erreichen.
Sharding zielt darauf ab, eine „share-nothing“-Architektur zu erreichen, die Verarbeitungsengpässe und „single points of failure“ ausschließt.
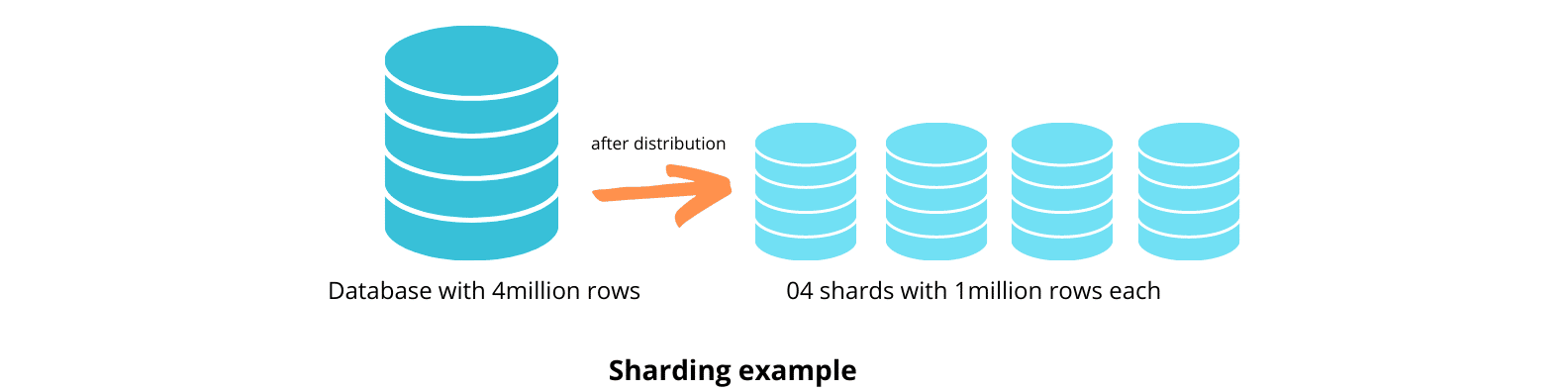
Du kannst Sharding auf zwei Arten implementieren – horizontal und vertikal. Beim horizontalen Sharding wird die Tabelle anhand der Zeilen unterteilt, beim vertikalen Sharding anhand der Spalten.
In dieser Hinsicht ist das Sharding wie die Partitionierung, bei der große Tabellen in kleinere unterteilt werden.
Horizontales Sharding eignet sich gut für Datenbanken, bei denen die meisten Abfragen nur eine Teilmenge von Zeilen zurückgeben, z. B. eine Kundendatenbank, die Daten (wie Name, Adresse, E-Mail usw.) auf einmal zurückgibt.
Vertikales Sharding eignet sich für Datenbanken, deren Abfragen einzelne Spalten zurückgeben. Wenn die Kundendatenbank z. B. den Namen oder die E-Mail-Adresse des Kunden separat zurückgibt, kannst du den Namen und die E-Mail-Adresse in verschiedene Cluster aufteilen.
Vorteile von Datenbank-Sharding
Nachfolgend sind einige der Vorteile von Datenbank-Sharding aufgeführt.
Verbesserte horizontale Skalierung
Du kannst deine Datenbank vertikal oder horizontal skalieren. Vertikale Skalierung bedeutet, dass du dem Server mehr zentrale Recheneinheiten (CPU) und Arbeitsspeicher (RAM) hinzufügst, um die Leistung zu verbessern. Vertikale Skalierung ist eine hilfreiche Lösung für kleine bis mittlere Datenbanken. Wenn deine Daten jedoch wachsen, ist eine vertikale Skalierung nicht mehr praktikabel. Es gibt nur so viel Leistung, wie du einem einzelnen Server hinzufügen kannst.
Die horizontale Skalierung ist flexibler. Sie ermöglicht es dir, deine Datenbank nach Bedarf zu skalieren, indem du weitere Server zu deinem System hinzufügst. Jeder dieser Server stellt Ressourcen für verschiedene Shards der Datenbank bereit. Dadurch wird die Arbeitslast verteilt und das System kann mehr Anfragen bearbeiten.
Schnellere Abfrage-Antwortzeiten
Shards haben nur ein paar Zeilen und Spalten. Deshalb dauert die Bearbeitung von Datenbankabfragen weniger lang. Im Gegensatz dazu kann eine Abfrage einer nicht gesharten Datenbank die Suche in Hunderten oder sogar Tausenden von Zeilen erfordern.
Erhöhte Verlässlichkeit bei Ausfällen
Datenbankausfälle können aus verschiedenen Gründen auftreten, z. B. durch versehentliches Löschen von Daten, Verbindungsfehler oder Cybersecurity-Angriffe. Sharding minimiert die Auswirkungen von Ausfällen. Da jeder Shard autonom ist, ist nur der betroffene Shard von Ausfallzeiten betroffen. Wenn du zum Beispiel vier Shards hast und einer davon ausfällt, sind nur 25 Prozent des Betriebs betroffen.
Nachteile von Sharding
Obwohl Sharding die Zuverlässigkeit und Verfügbarkeit einer Datenbank verbessert, ist die Implementierung komplex. Eine falsche Sharding-Architektur kann die Leistung beeinträchtigen und zu Datenverlusten führen.
Achte darauf, eine Sharding-Technik zu wählen, die eine ausgewogene Verteilung der Daten auf alle Shards ermöglicht. Ohne diese Ausgewogenheit riskierst du die Entstehung von Datenbank-Hotspots, die entstehen, wenn ein Shard den Großteil der Daten speichert, während andere Shards praktisch leer bleiben. Dadurch verringert sich der Schreibdurchsatz auf dem einzelnen Shard.
Um dieses Problem zu lösen, könntest du den unausgewogenen Shard noch weiter partitionieren, aber das ist ein schwieriger Prozess, der deine Datenbank während der Datenmigration lahmlegen kann.
Ein weiterer Nachteil des Sharding ist, dass SQL-Joins mit mehreren Tabellen in verschiedenen Shards zu langsam werden und die Leistung beeinträchtigen können. Mit der richtigen Architektur kannst du dieses Problem jedoch vermeiden.
Sharding-Architekturen
Du kannst Sharding mit drei Architekturen umsetzen:
- Schlüsselbasiertes Sharding
- Bereichsbasiertes Sharding
- Verzeichnisbasiertes Sharding
Welche Architektur du wählst, hängt von deinem Anwendungsfall ab.
Schlüsselbasiertes Sharding
Bei einer schlüssel- oder hashed-basierten Sharding-Architektur verwendet eine Datenbankanwendung einen Shard-Schlüssel, um einen Shard zu finden. Eine Hash-Funktion verschlüsselt den Wert des Sharding-Schlüssels, und die Ausgabe ordnet die Daten einem bestimmten Shard zu. Eine einfache Hashing-Funktion kann der Modulus des Schlüssels und die Anzahl der Shards sein.
Die Hash-Funktion kann mehr als einen Sharding-Schlüssel annehmen. Aus diesem Grund eignet sich das schlüsselbasierte Sharding für Datensätze, die gemeinsame Schlüssel haben. Durch die algorithmische Verteilung der Daten wird die Möglichkeit minimiert, dass Datenbank-Hotspots entstehen, in denen ein Shard mehr Daten enthält als der andere.
Da die Verteilung jedoch nur auf der Hashing-Funktion beruht, ist es unmöglich, Daten logisch zusammenzufassen. Daher können Datenbankoperationen, die Daten aus mehreren Shards benötigen, ineffizient sein, da sie das Lesen von Daten aus jedem Shard erfordern.
Bereichsbasiertes Sharding
Beim bereichsbasierten Sharding wird eine Datenbank in Abhängigkeit von einem bestimmten Wertebereich gesharded.
Dabei wird ein Sharding-Schlüssel verwendet, um zu bestimmen, welchem Shard ein Wert zugewiesen werden soll. Die Datenbankanwendung prüft den Shard, der dem Sharding-Schlüssel in einer Nachschlagetabelle entspricht, und speichert die Daten. Aus diesem Grund ist das bereichsbasierte Sharding einfach zu entwerfen und zu implementieren.
Du könntest zum Beispiel den Wert der Benutzer-ID in einer Benutzerdatenbank als Sharding-Schlüssel verwenden. Du könntest Benutzer mit IDs zwischen 0 und 2.000 in einem Shard speichern, Benutzer mit IDs zwischen 2.000 und 4.000 in einem anderen Shard, und so weiter.
Das bereichsbasierte Sharding kann zu Hotspots in der Datenbank führen. Stell dir eine Benutzerdatenbank vor, in der die meisten deiner Benutzer-IDs zwischen 2.001 und 4.000 liegen. Der Prozess ordnet sie einem einzigen Shard zu, wodurch im Laufe der Zeit ein Ungleichgewicht entsteht. Das bereichsbasierte Sharding funktioniert daher am besten bei gleichmäßig verteilten Daten.
Verzeichnisbasiertes Sharding
Beim verzeichnisbasierten Sharding werden logisch zusammengehörige Daten im selben Shard zusammengefasst. Dabei wird eine Nachschlagetabelle verwendet, die eine Liste von Zuordnungen für jede Entität in der Datenbank enthält. Jedes Mapping entspricht einem Datenbank-Shard.
Das verzeichnisbasierte Sharding ist flexibler als das bereichs- oder schlüsselbasierte Sharding, weil du Daten dynamisch zu Shards hinzufügen kannst. Es gibt keine Sharding-Funktion, der du folgen musst, und auch keine Bereichswerte, die du einhalten musst. Diese Flexibilität erhöht die Effizienz der Datenbank: Du kannst zusammenhängende Daten in einem Shard speichern, was bedeutet, dass die Ausführung gemeinsamer Abfragen weniger Zeit in Anspruch nimmt.
Wenn du z. B. verzeichnisbasiertes Sharding verwendest und die Benutzer/innen nach ihrem Standort gruppierst, um die Benutzer/innen von einem bestimmten Ort abzurufen, fragst du nur einen einzigen Shard ab.
Datenbank-Sharding mit Kinsta
Die meisten modernen Datenbank-Engines bieten Unterstützung für Datenbank-Sharding. Eine dieser Datenbank-Engines ist MariaDB, eine kommerziell unterstützte Abspaltung von MySQL. Es ist ein hochleistungsfähiges Open-Source-Datenbanksystem, das von Unternehmen wie IBM, GitHub und Wikimedia eingesetzt wird. Es ist auch Teil des Hochleistungsserver-Stacks bei Kinsta.
MariaDB bietet integrierte Sharding-Funktionen durch die Spider Storage Engine. Die Spider Storage Engine ist eine Engine zur Clusterbildung, die Partitionierung und Extended Architecture (XA)-Transaktionen unterstützt. Sie ermöglicht es dir, entfernte Tabellen aus verschiedenen Instanzen so zu behandeln, als befänden sie sich in derselben Instanz. Sobald du eine Tabelle in der Spider Storage Engine erstellst, wird die Tabelle mit einer anderen Tabelle auf dem entfernten MariaDB-Server verknüpft. Sobald die Verbindung hergestellt ist, teilt die Storage Engine die Verknüpfung mit allen Tabellen, die Teil derselben Transaktion sind.
Zusammenfassung
Das Sharding von Datenbanken ist eine Skalierungstechnik, bei der Tabellen in kleinere Teilmengen aufgeteilt und auf verschiedene Server, die sogenannten Shards, verteilt werden. Du kannst Sharding auf verschiedene Weise implementieren, z. B. durch schlüsselbasiertes Sharding, bereichsbasiertes Sharding und verzeichnisbasiertes Sharding.
Sharding verbessert zwar die Skalierbarkeit, Zuverlässigkeit und Verfügbarkeit einer Datenbank, ist aber sehr komplex in der Umsetzung. Außerdem ist es nach der Erstellung eines Shards nicht einfach, die Datenbank in den Zustand ohne Sharding zurückzuversetzen. Deshalb solltest du Sharding nur dann zur Optimierung einsetzen, wenn du sicher bist, dass andere Skalierungsoptionen nicht funktionieren.
Ganz gleich, ob es sich bei deinem Unternehmen um eine gemeinnützige Organisation oder ein Großunternehmen handelt, mit den Expertenlösungen von Kinsta kannst du dich um dein Website-Hosting kümmern und dich auf das Wesentliche konzentrieren.

Salman Ravoof ist ein autodidaktischer Webentwickler, Autor, Kreativer und ein großer Bewunderer von Free and Open Source Software (FOSS). Neben Technik begeistert er sich für Wissenschaft, Philosophie, Fotografie, Kunst, Katzen und Essen. Erfahre mehr über ihn auf seiner Website und trete mit Salman auf X in Kontakt.

