
Node.js es un entorno de ejecución JavaScript del lado del servidor que utiliza un modelo de entrada-salida (I/O, input-output ) basado en eventos y sin bloqueos. Es ampliamente conocido por construir aplicaciones web rápidas y escalables. También cuenta con una gran comunidad y una rica biblioteca de módulos que simplifican diversas tareas y procesos.
El clustering mejora el rendimiento de las aplicaciones Node.js al permitir que se ejecuten en varios procesos. Esta técnica les permite utilizar todo el potencial de un sistema multi-core.
Este artículo analiza en profundidad el clustering en Node.js y cómo afecta al rendimiento de una aplicación.
¿Qué es el clustering?
Por defecto, las aplicaciones Node.js se ejecutan en un único hilo. Esta naturaleza monohilo significa que Node.js no puede utilizar todos los cores de un sistema multi-core — como son actualmente la mayoría de los sistemas.
Aun así, Node.js puede gestionar varias peticiones simultáneamente aprovechando las operaciones I/O no bloqueantes y las técnicas de programación asíncrona.
Sin embargo, las tareas computacionales pesadas pueden bloquear el bucle de eventos y hacer que la aplicación deje de responder. Por eso, Node.js viene con un módulo de cluster nativo — independientemente de su naturaleza monohilo — para aprovechar la potencia total de procesamiento de un sistema multi-core.
La ejecución de varios procesos aprovecha la potencia de procesamiento de varios cores de la unidad central de proceso (CPU) para permitir el procesamiento paralelo, reducir los tiempos de respuesta y aumentar el rendimiento. Esto, a su vez, mejora el rendimiento y la escalabilidad de las aplicaciones Node.js.
¿Cómo funciona el clustering?
El módulo cluster de Node.js permite a una aplicación Node.js crear un cluster de procesos hijos que se ejecutan simultáneamente, cada uno de los cuales gestiona una parte de la carga de trabajo de la aplicación.
Al inicializar el módulo cluster, la aplicación crea el proceso primario, que a su vez divide los procesos hijos en procesos workers. El proceso primario actúa como equilibrador de carga, distribuyendo la carga de trabajo a los procesos workers mientras cada proceso worker escucha las peticiones entrantes.
El módulo cluster de Node.js tiene dos métodos para distribuir las conexiones entrantes.
- El enfoque round-robin — El proceso primario escucha en un puerto, acepta nuevas conexiones y distribuye uniformemente la carga de trabajo para garantizar que ningún proceso esté sobrecargado. Este es el enfoque por defecto en todos los sistemas operativos excepto Windows.
- El segundo enfoque — El proceso primario crea el socket de escucha y lo envía a los workers «interesados», que aceptan directamente las conexiones entrantes.
Teóricamente, el segundo enfoque — que es más complicado — debería proporcionar un mejor rendimiento. Pero en la práctica, la distribución de las conexiones está muy desequilibrada. La documentación de Node.js menciona que el 70% de todas las conexiones acaban en sólo dos procesos de un total de ocho.
Cómo clusterizar tus aplicaciones Node.js
Ahora, examinemos los efectos del clustering en una aplicación Node.js. Este tutorial utiliza una aplicación Express que ejecuta intencionadamente una tarea computacional pesada para bloquear el bucle de eventos.
Primero, ejecuta esta aplicación sin clustering. A continuación, registra el rendimiento con una herramienta de evaluación comparativa. Después, se implementa el clustering en la aplicación, y se repite la evaluación comparativa. Por último, compara los resultados para ver cómo el clustering mejora el rendimiento de tu aplicación.
Cómo empezar
Para entender este tutorial, debes estar familiarizado con Node.js y Express. Para configurar tu servidor Express:
- Empieza creando el proyecto.
mkdir cluster-tutorial - Navega hasta el directorio de la aplicación y crea dos archivos, no-cluster.js y cluster.js, ejecutando el comando que aparece a continuación:
cd cluster-tutorial && touch no-cluster.js && touch cluster.js - Inicializa NPM en tu proyecto:
npm init -y - Por último, instala Express ejecutando el siguiente comando:
npm install express
Crear una aplicación sin cluster
En tu archivo no-cluster.js, añade el siguiente bloque de código:
const express = require("express");
const PORT = 3000;
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/slow", (req, res) => {
//Start timer
console.time("slow");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});El bloque de código anterior crea un servidor express que se ejecuta en el puerto 3000. El servidor tiene dos rutas, una ruta root (/) y una ruta /slow. La ruta principal envía una respuesta al cliente con el mensaje «Respuesta del servidor»
Sin embargo, la ruta /slow realiza intencionadamente algunos cálculos pesados para bloquear el bucle de eventos. Esta ruta inicia un temporizador y luego rellena un array con 100.000 números aleatorios utilizando un bucle for.
A continuación, utilizando otro bucle for, eleva al cuadrado cada número del array generado y los suma. El temporizador finaliza cuando esto se ha completado, y el servidor responde con los resultados.
Inicia tu servidor ejecutando el siguiente comando:
node no-cluster.jsA continuación, haz una petición GET a localhost:3000/slow.
Durante este tiempo, si intentas hacer cualquier otra petición a tu servidor — como a la ruta root (/) — las respuestas serán lentas, ya que la ruta /slow está bloqueando el bucle de eventos.
Crear una aplicación en cluster
Genera procesos hijo utilizando el módulo de cluster para asegurarte de que tu aplicación no deja de responder y bloquea las peticiones posteriores durante las tareas de cálculo pesadas.
Cada proceso hijo ejecuta su bucle de eventos y comparte el puerto del servidor con el proceso padre, lo que permite un mejor uso de los recursos disponibles.
En primer lugar, importa el módulo cluster de Node.js y os en tu archivo cluster.js. El módulo cluster permite crear procesos hijo para distribuir la carga de trabajo entre varios cores de CPU.
El módulo os proporciona información sobre el sistema operativo de tu ordenador. Necesitas este módulo para recuperar el número de cores disponibles en tu sistema y asegurarte de que no creas más procesos hijo que cores en tu sistema.
Añade el siguiente bloque de código para importar estos módulos y obtener el número de cores de tu sistema:
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;A continuación, añade el siguiente bloque de código a tu archivo cluster.js:
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
console.log(`This machine has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Replace the dead worker
console.log("Starting a new worker");
cluster.fork();
});
}El bloque de código anterior comprueba si el proceso actual es el proceso primario o el proceso worker. Si es cierto, el bloque de código genera procesos hijos en función del número de cores de tu sistema. A continuación, escucha el evento de salida de los procesos y los sustituye generando nuevos procesos.
Por último, envuelve toda la lógica express relacionada en un bloque else. Tu archivo cluster.js terminado debería ser similar al bloque de código siguiente.
//cluster.js
const express = require("express");
const PORT = 3000;
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
console.log(`This machine has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Replace the dead worker
console.log("Starting a new worker");
cluster.fork();
});
} else {
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/slow", (req, res) => {
console.time("slow");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});
}Tras implementar el clustering, varios procesos gestionarán las peticiones. Esto significa que tu aplicación seguirá respondiendo incluso durante una tarea computacional pesada.
Cómo evaluar el rendimiento mediante loadtest
Para demostrar y mostrar con precisión los efectos del clustering en una aplicación Node.js, utiliza el paquete npm loadtest para comparar el rendimiento de tu aplicación antes y después del clustering.
Ejecuta el siguiente comando para instalar loadtest globalmente:
npm install -g loadtestEl paquete loadtest ejecuta una prueba de carga en una URL HTTP/WebSockets especificada.
A continuación, inicia tu archivo no-cluster.js en un terminal. Después, abre otra instancia de terminal y ejecuta la prueba de carga que aparece a continuación:
loadtest http://localhost:3000/slow -n 100 -c 10El comando anterior envía 100 peticiones con una concurrencia de 10 a tu aplicación no clusterizada. La ejecución de este comando produce los siguientes resultados:
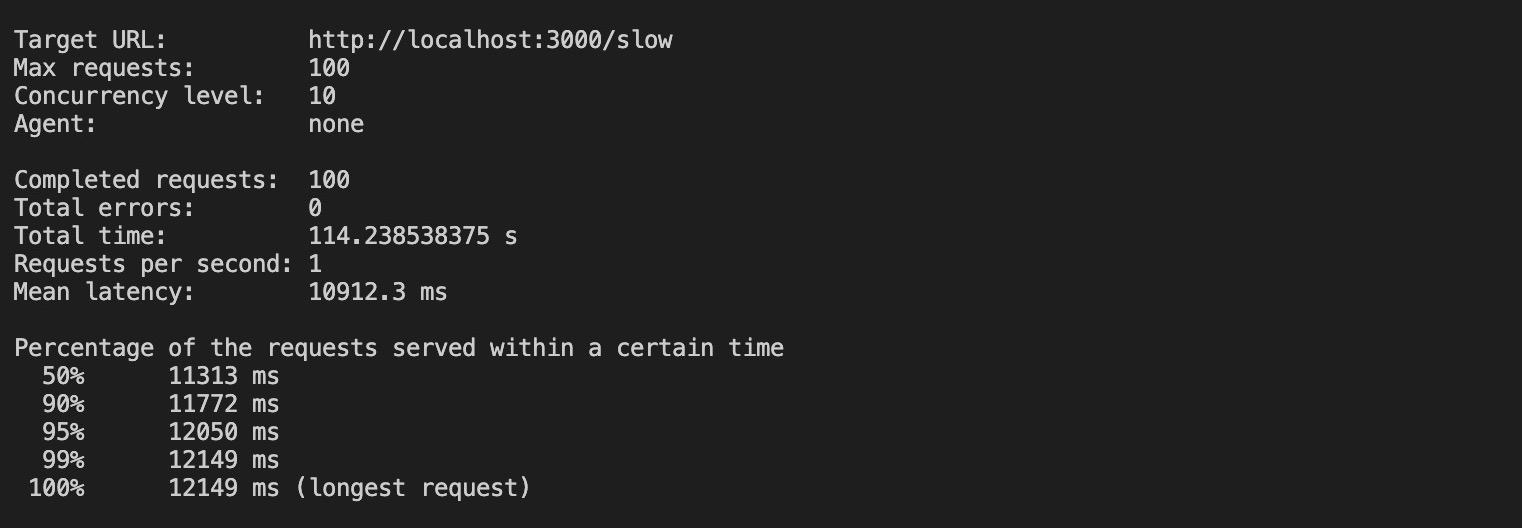
Según los resultados, se tardaron aproximadamente 100 segundos en completar todas las peticiones sin clustering, y la petición más larga tardó hasta 12 segundos en completarse.
Los resultados variarán en función de tu sistema.
A continuación, deja de ejecutar el archivo no-cluster.js e inicia tu archivo cluster.js en una instancia de terminal. A continuación, abre otra instancia de terminal y ejecuta esta prueba de carga:
loadtest http://localhost:3000/slow -n 100 -c 10El comando anterior enviará 100 peticiones con una concurrencia 10 a tu aplicación clusterizada.
La ejecución de este comando produce los siguientes resultados:
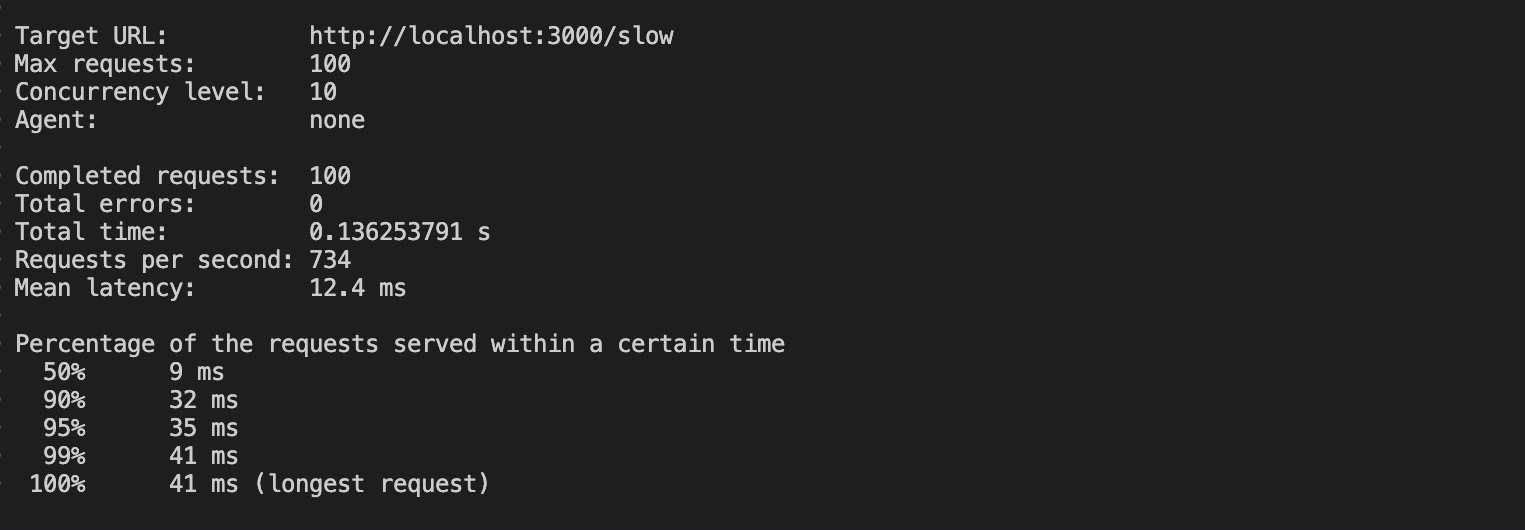
Con el clustering, las peticiones tardaron 0,13 segundos (136 ms) en completar sus peticiones, una enorme disminución respecto a los 100 segundos que necesitó la app no clusterizada. Además, la petición más larga de la aplicación agrupada tardó 41 ms en completarse.
Estos resultados demuestran que implementar el clustering mejora significativamente el rendimiento de tu aplicación. Ten en cuenta que debes utilizar un software de gestión de procesos como PM2 para gestionar tu clustering en entornos de producción.
Uso de Node.js con el Alojamiento de Aplicaciones de Kinsta
Kinsta es una empresa de alojamiento que facilita el despliegue de tus aplicaciones Node.js. Su plataforma de alojamiento está construida sobre Google Cloud Platform, que proporciona una infraestructura fiable diseñada para manejar un alto tráfico y soportar aplicaciones complejas. En última instancia, esto mejora el rendimiento de las aplicaciones Node.js.
Kinsta ofrece varias funciones para los despliegues de Node.js, como conexiones de bases de datos internas, integración con Cloudflare, despliegues de GitHub y Google C2 Machines.
Estas funciones facilitan el despliegue y la gestión de aplicaciones Node.js y agilizan el proceso de desarrollo.
Para desplegar tu aplicación Node.js en el Alojamiento de Aplicaciones de Kinsta, es crucial enviar el código y los archivos de tu aplicación al proveedor de Git que hayas elegido (Bitbucket, GitHub o GitLab).
Una vez configurado tu repositorio, sigue estos pasos para desplegar tu aplicación Express en Kinsta:
- Inicia sesión o crea una cuenta para ver tu panel MyKinsta.
- Autoriza a Kinsta con tu proveedor Git.
- Haz clic en Aplicaciones en la barra lateral izquierda, y luego en Añadir aplicación.
- Selecciona el repositorio y la rama desde la que deseas desplegar.
- Asigna un nombre único a tu aplicación y elige una ubicación para el centro de datos.
- A continuación, configura tu entorno de construcción. Selecciona la configuración de máquina de construcción estándar con la opción Nixpacks recomendada para esta demo.
- Utiliza todas las configuraciones por defecto y luego haz clic en Crear aplicación.
Resumen
El clustering en Node.js permite la creación de múltiples procesos worker para distribuir la carga de trabajo, mejorando el rendimiento y la escalabilidad de las aplicaciones Node.js. Implementar correctamente el clustering es crucial para alcanzar todo el potencial de esta técnica.
Diseñar la arquitectura, gestionar la asignación de recursos y minimizar la latencia de la red son factores vitales a la hora de implementar el clustering en Node.js. La importancia y complejidad de esta implementación son las razones por las que los gestores de procesos como PM2 deben utilizarse en entornos de producción.
¿Qué opinas del clustering de Node.js? ¿Lo has utilizado antes? ¡Compártela en la sección de comentarios!


