
En un mundo basado en los datos como el actual, en el que el volumen y la complejidad de los datos siguen creciendo a un ritmo sin precedentes, la necesidad de soluciones de bases de datos sólidas y escalables se ha convertido en algo primordial. Se calcula que en 2025 se crearán 180 zettabytes de datos. Son grandes cifras en las que hay que pensar.
A medida que los datos y la demanda de los usuarios se disparan, confiar en una única ubicación de la base de datos resulta poco práctico. Ralentiza tu sistema y sobrecarga a los desarrolladores. Puedes adoptar varias soluciones para optimizar tu base de datos, como la fragmentación de bases de datos.
En esta completa guía, nos adentramos en las profundidades de la fragmentación de MongoDB, desmitificando sus ventajas, componentes, mejores prácticas, errores comunes y cómo puedes empezar.
¿Qué Es la Fragmentación de Bases de Datos?
La fragmentación de bases de datos es una técnica de gestión de bases de datos que consiste en particionar horizontalmente una base de datos en crecimiento en unidades más pequeñas y manejables, conocidas como fragmentos.
A medida que tu base de datos crece, resulta práctico dividirla en varias partes más pequeñas y almacenar cada parte por separado en máquinas distintas. Estas partes más pequeñas, o fragmentos, son subconjuntos independientes de la base de datos global. Este proceso de dividir y distribuir los datos es lo que constituye la fragmentación de la base de datos.
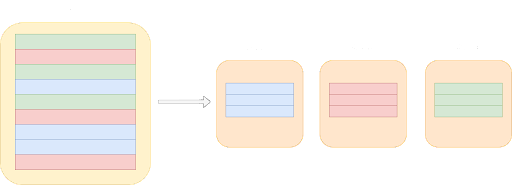
A la hora de implantar una base de datos fragmentada, existen dos enfoques principales: desarrollar una solución fragmentada personalizada o pagar por una ya existente. Esto plantea la cuestión de si es más adecuado crear una solución fragmentada o pagar por ella.

Para hacer esta elección, tienes que considerar el coste de la integración de terceros, teniendo en cuenta los siguientes factores:
- Habilidades y capacidad de aprendizaje del desarrollador: La curva de aprendizaje asociada al producto y lo bien que se alinea con las habilidades de tus desarrolladores.
- El modelo de datos y la API que ofrece el sistema: Cada sistema de datos tiene su propia forma de representar sus datos. La comodidad y facilidad con la que puedes integrar tus aplicaciones con el producto es un factor clave a tener en cuenta.
- Asistencia al cliente y documentación en línea: En los casos en los que te encuentres con dificultades o necesites ayuda durante la integración, la calidad y disponibilidad de la atención al cliente y de una completa documentación en línea resultan cruciales.
- Disponibilidad de despliegue en la nube: A medida que más empresas se pasan a la nube, es importante determinar si el producto de terceros puede desplegarse en la nube.
En función de estos factores, puedes decidir si construir una solución de fragmentación o pagar por una solución que haga el trabajo pesado por ti.
Hoy en día, la mayoría de las bases de datos del mercado admiten la fragmentación de bases de datos. Por ejemplo, bases de datos relacionales como MariaDB (que forma parte de la pila de servidores de alto rendimiento de Kinsta) y bases de datos NoSQL como MongoDB.
¿Qué Es el Sharding en MongoDB?
El objetivo principal de utilizar una base de datos NoSQL es su capacidad para hacer frente a las demandas informáticas y de almacenamiento que supone consultar y almacenar enormes volúmenes de datos.
Generalmente, una base de datos MongoDB contiene un gran número de colecciones. Cada colección consta de varios documentos que contienen datos en forma de pares clave-valor. Puedes dividir esta gran colección en varias colecciones más pequeñas utilizando el sharding MongoDB. Esto permite a MongoDB realizar consultas sin sobrecargar mucho el servidor.
Por ejemplo, Telefónica Tech gestiona más de 30 millones de dispositivos IoT en todo el mundo. Para seguir el ritmo del uso cada vez mayor de dispositivos, necesitaban una plataforma que pudiera escalar elásticamente y gestionar un entorno de datos en rápido crecimiento. La tecnología de fragmentación de MongoDB era la opción adecuada para ellos, ya que era la que mejor se adaptaba a sus necesidades de coste y capacidad.
Con la fragmentación de MongoDB, Telefónica Tech ejecuta más de 115.000 consultas por segundo. Eso son 30.000 inserciones en la base de datos por segundo, ¡con menos de un milisegundo de latencia!
Ventajas del sharding de MongoDB
Aquí tienes algunas ventajas de la fragmentación de MongoDB para datos a gran escala de las que puedes disfrutar:
Capacidad de almacenamiento
Ya hemos visto que la fragmentación distribuye los datos entre los fragmentos del clúster. Esta distribución permite que cada shard contenga un fragmento de los datos totales del clúster. Los fragmentos adicionales aumentarán la capacidad de almacenamiento del clúster a medida que aumente el tamaño de tu conjunto de datos.
Lecturas/Escrituras
MongoDB distribuye la carga de trabajo de lectura y escritura entre los fragmentos de un clúster fragmentado, permitiendo que cada fragmento procese un subconjunto de las operaciones del clúster. Ambas cargas de trabajo pueden escalarse horizontalmente en el clúster añadiendo más fragmentos.
Alta disponibilidad
El despliegue de shards y servidores de configuración como conjuntos de réplica ofrece una mayor disponibilidad. Ahora, incluso si uno o más conjuntos de réplicas de fragmentos dejan de estar disponibles por completo, el clúster fragmentado puede realizar lecturas y escrituras parciales.
Protección ante una interrupción
Muchos usuarios se ven afectados si una máquina muerde el polvo debido a una interrupción no planificada. En un sistema no fragmentado, como toda la base de datos se habría caído, el impacto es masivo. El radio de explosión de la mala experiencia/impacto del usuario puede contenerse mediante el sharding MongoDB.
Geo-Distribución y Rendimiento
Los shards replicados pueden colocarse en diferentes regiones. Esto significa que se puede proporcionar a los clientes un acceso de baja latencia a sus datos, es decir, redirigir las peticiones de los consumidores al shard más cercano a ellos. En función de la política de gobierno de datos de una región, se pueden configurar fragmentos específicos para colocarlos en una región concreta.
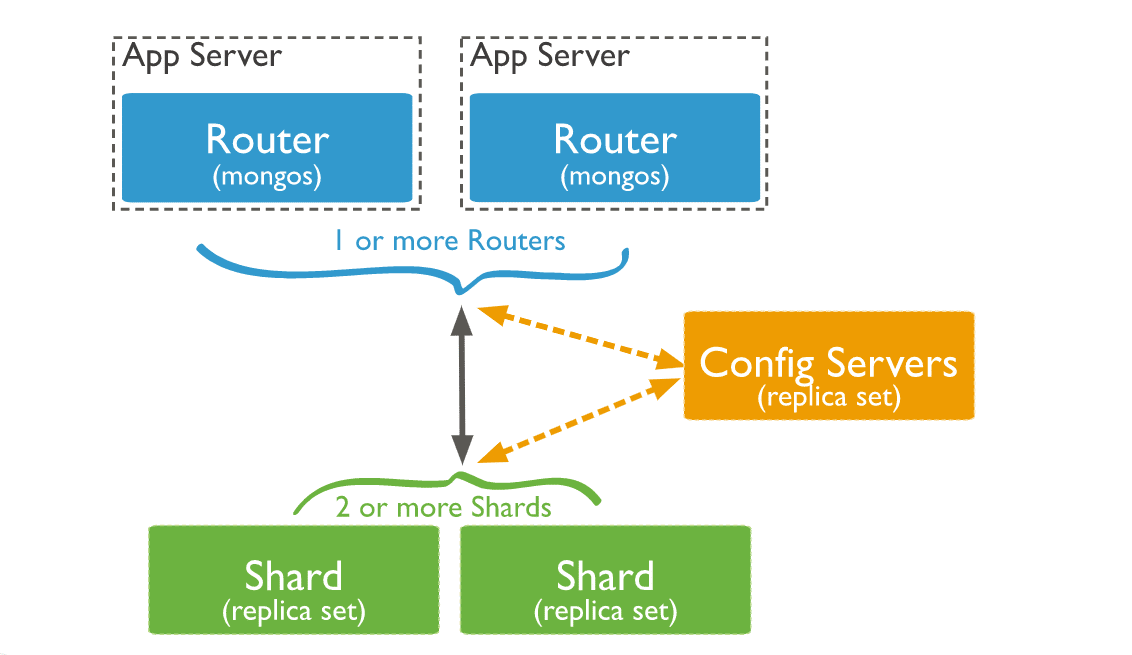
Componentes de los Clusters Sharded de MongoDB
Una vez explicado el concepto de clúster fragmentado MongoDB, vamos a profundizar en los componentes que integran dichos clústeres.
1. Shard
Cada shard tiene un subconjunto de datos fragmentados. A partir de MongoDB 3.6, los shards deben desplegarse como un conjunto de réplicas para proporcionar alta disponibilidad y redundancia.
Cada base de datos del clúster fragmentado tiene un fragmento primario que contendrá todas las colecciones no fragmentadas de esa base de datos. El shard primario no está relacionado con el primario de un conjunto de réplicas.
Para cambiar el shard primario de una base de datos, puedes utilizar el comando movePrimary. El proceso de migración del shard primario puede tardar bastante tiempo en completarse.
Durante ese tiempo, no debes intentar acceder a las colecciones asociadas a la base de datos hasta que finalice el proceso de migración. Este proceso podría afectar a las operaciones generales del clúster en función de la cantidad de datos que se migren.
Puedes utilizar el método sh.status() de mongosh para consultar la vista general del clúster. Este método te devolverá el fragmento principal de la base de datos junto con la distribución de fragmentos entre los fragmentos.
2. Servidores de configuración
Desplegar servidores de configuración para clusters fragmentados como conjuntos de réplicas mejoraría la consistencia en el servidor de configuración. Esto se debe a que MongoDB puede aprovechar los protocolos estándar de lectura y escritura de conjuntos de réplica para los datos de configuración.
Para desplegar servidores de configuración como un conjunto de réplica, tendrás que ejecutar el motor de almacenamiento WiredTiger. WiredTiger utiliza el control de concurrencia a nivel de documento para sus operaciones de escritura. Por tanto, varios clientes pueden modificar distintos documentos de una colección al mismo tiempo.
Los servidores de configuración almacenan los metadatos de un cluster fragmentado en la base de datos de configuración. Para acceder a la base de datos config, puedes utilizar el siguiente comando en el shell de mongo:
use configAquí tienes algunas restricciones que debes tener en cuenta:
- Una configuración de conjunto de réplicas utilizada para servidores config debe tener cero árbitros. Un árbitro participa en una elección para el primario, pero no tiene una copia del conjunto de datos y no puede convertirse en el primario.
- Este conjunto de réplicas no puede tener miembros retrasados. Los miembros retrasados tienen copias del conjunto de datos del conjunto de réplica. Pero el conjunto de datos de un miembro retrasado contiene un estado anterior o retrasado del conjunto de datos.
- Necesitas crear índices para los servidores de configuración. En pocas palabras, ningún miembro debe tener la configuración
members[n].buildIndexesestablecida enfalse.
Si el conjunto de réplicas del servidor config pierde a su miembro principal y no puede elegir uno, los metadatos del clúster pasan a ser de sólo lectura. Seguirás pudiendo leer y escribir en los fragmentos, pero no se producirán divisiones de fragmentos ni migraciones hasta que el conjunto de réplicas pueda elegir un primario.
3. Enrutadores de consultas
Las instancias mongos de MongoDB pueden servir como enrutadores de consultas, permitiendo que las aplicaciones cliente y los clusters fragmentados se conecten fácilmente.
A partir de MongoDB 4.4, mongos puede soportar lecturas cubiertas para reducir las latencias. Con las lecturas cubiertas, las instancias de mongos enviarán operaciones de lectura a dos miembros del conjunto de réplicas por cada fragmento consultado. Entonces devolverá los resultados del primer respondedor por fragmento.
He aquí cómo interactúan los tres componentes en un clúster fragmentado:
Una instancia de mongos dirigirá una consulta a un clúster por:
- Comprobando la lista de shards que deben recibir la consulta.
- Establecer un cursor en todos los shards objetivo.
A continuación, mongos fusionará los datos de cada fragmento objetivo y devolverá el documento resultante. Algunos modificadores de la consulta, como la ordenación, se ejecutan en cada fragmento antes de que los mongos recuperen los resultados.
En algunos casos, cuando la clave de fragmento o un prefijo de clave de fragmento forma parte de la consulta, mongos ejecutará una operación planificada previamente, dirigiendo las consultas a una subclase de fragmentos del clúster.
Para un clúster de producción, asegúrate de que los datos son redundantes y de que tus sistemas están altamente disponibles. Puedes elegir la siguiente configuración para un despliegue de clúster con fragmentos de producción:
- Despliega cada shard como un conjunto de réplicas de 3 miembros
- Despliega servidores de configuración como un conjunto de réplicas de 3 miembros
- Despliega uno o más routers mongos
Para un clúster que no sea de producción, puedes desplegar un clúster fragmentado con los siguientes componentes:
- Un conjunto de réplica de shard único
- Un servidor de configuración del conjunto de réplicas
- Una instancia de mongos
¿Cómo Funciona el Sharding de MongoDB?
Ahora que hemos hablado de los distintos componentes de un clúster fragmentado, es hora de que nos sumerjamos en el proceso.
Para fragmentar los datos en varios servidores, utilizarás mongos. Cuando te conectes para enviar las consultas a MongoDB, mongos buscará y encontrará dónde residen los datos. A continuación, los obtendrá del servidor correcto y lo fusionará todo si estaba dividido en varios servidores.
Como de eso se encargará el backend, no tendrás que hacer nada en el lado de la aplicación. MongoDB actuará como si fuera una conexión de consulta normal. Tu cliente se conectará a mongos, y el servidor de configuración se encargará del resto.
¿Cómo Configurar MongoDB Sharding Paso a Paso?
Configurar el Sharding de MongoDB es un proceso que implica varios pasos para garantizar un clúster de base de datos estable y eficiente. Aquí tienes instrucciones detalladas paso a paso sobre cómo configurar el Sharding de MongoDB.
Antes de empezar, es importante tener en cuenta que para configurar el Sharding en MongoDB, necesitarás tener al menos tres servidores: uno para el servidor de configuración, uno para la instancia de mongos y uno o más para los fragmentos.
1. Crear un directorio desde el servidor de configuración
Para empezar, crearemos un directorio para los datos del servidor de configuración. Esto se puede hacer ejecutando el siguiente comando en el primer servidor:
mkdir /data/configdb2. Iniciar MongoDB en modo configuración
A continuación, iniciaremos MongoDB en modo configuración en el primer servidor utilizando el siguiente comando:
mongod --configsvr --dbpath /data/configdb --port 27019Esto iniciará el servidor config en port 27019 y almacenará sus datos en el directorio /data/configdb. Ten en cuenta que estamos utilizando la bandera --configsvr para indicar que este servidor se utilizará como servidor de configuración.
3. Iniciar la Instancia Mongos
El siguiente paso es iniciar la instancia de mongos. Este proceso dirigirá las consultas a los shards correctos en función de la clave de sharding. Para iniciar la instancia de mongos, utiliza el siguiente comando:
mongos --configdb <config server>:27019Sustituye <config server> por la dirección IP o el nombre de host de la máquina donde se ejecuta el servidor de configuración.
4. Conectarse a la instancia de Mongos
Una vez que la instancia de mongos se está ejecutando, podemos conectarnos a ella utilizando la shell de MongoDB. Esto puede hacerse ejecutando el siguiente comando:
mongo --host <mongos-server> --port 27017En este comando, <mongos-server> debe sustituirse por el nombre de host o la dirección IP del servidor que ejecuta la instancia de mongos. Esto abrirá la shell de MongoDB, permitiéndonos interactuar con la instancia de mongos y añadir servidores al clúster.
Sustituye<mongos-server> por la dirección IP o el nombre de host de la máquina donde se ejecuta la instancia de mongos.
5. Añadir servidores a los clusters
Ahora que estamos conectados a la instancia de mongos, podemos añadir servidores al clúster ejecutando el siguiente comando:
sh.addShard("<shard-server>:27017")En este comando, <shard-server> debe sustituirse por el nombre de host o la dirección IP del servidor que ejecuta el fragmento. Este comando añadirá el shard al clúster y lo hará disponible para su uso.
Repite este paso para cada fragmento que quieras añadir al clúster.
6. Activar el Sharding de la base de datos
Por último, habilitaremos la fragmentación para una base de datos ejecutando el siguiente comando:
sh.enableSharding("<database>")En este comando, <database> debe sustituirse por el nombre de la base de datos que deseas fragmentar. Esto activará la fragmentación de la base de datos especificada, permitiéndote distribuir sus datos en varios fragmentos.
¡Y listo! Siguiendo estos pasos, ahora deberías tener un clúster fragmentado MongoDB completamente funcional, listo para escalar horizontalmente y manejar cargas de alto tráfico.
Buenas Prácticas para el Sharding de MongoDB
Aunque hayamos configurado nuestro clúster fragmentado, es esencial supervisar y mantener el clúster con regularidad para garantizar un rendimiento óptimo. Algunas de las mejores prácticas para la fragmentación de MongoDB son:
1. Determinar la clave de shard correcta
La clave de shard es un factor crítico en la fragmentación de MongoDB que determina cómo se distribuyen los datos entre los shards. Es importante elegir una clave de shard que distribuya uniformemente los datos entre los fragmentos y admita las consultas más habituales. Debes evitar elegir una clave de shard que provoque puntos calientes, o una distribución desigual de los datos, ya que esto puede provocar problemas de rendimiento.
Para elegir la clave de shard adecuada, debes analizar tus datos y los tipos de consultas que vas a realizar, y seleccionar una clave que satisfaga esos requisitos.
2. Planifica el crecimiento de los datos
Cuando configures tu clúster fragmentado, planifica el crecimiento futuro empezando con suficientes fragmentos para gestionar tu carga de trabajo actual y añadiendo más según sea necesario. Asegúrate de que tu infraestructura de hardware y red puede soportar el número de shards y la cantidad de datos que esperas tener en el futuro.
3. Utiliza hardware dedicado para los shards
Utiliza hardware dedicado para cada fragmento para obtener un rendimiento y una fiabilidad óptimas. Cada fragmento debe tener su propio servidor o máquina virtual, para que pueda utilizar todos los recursos sin interferencias.
Utilizar hardware compartido puede provocar contención de recursos y degradación del rendimiento, afectando a la fiabilidad general del sistema.
4. Utiliza conjuntos de réplica para los servidores de fragmentos
Utilizar conjuntos de réplicas para los servidores de fragmentos proporciona alta disponibilidad y tolerancia a fallos para tu clúster de fragmentos MongoDB. Cada conjunto de réplicas debe tener tres o más miembros, y cada miembro debe residir en una máquina física independiente. Esta configuración garantiza que tu clúster fragmentado pueda sobrevivir al fallo de un único servidor o miembro del conjunto de réplicas.
5. Supervisar el rendimiento de los shards
Supervisar el rendimiento de tus shards es crucial para identificar los problemas antes de que se conviertan en problemas graves. Debes controlar la CPU, la memoria, la E/S de disco y la E/S de red de cada servidor fragmentado para asegurarte de que el fragmentado puede gestionar la carga de trabajo.
Puedes utilizar las herramientas de monitorización integradas en MongoDB, como mongostat y mongotop, o herramientas de monitorización de terceros, como Datadog, Dynatrace y Zabbix, para hacer un seguimiento del rendimiento de los fragmentos.
6. Planifica la recuperación ante desastres
Planificar la recuperación ante desastres es esencial para mantener la fiabilidad de tu clúster fragmentado MongoDB. Debes tener un plan de recuperación ante desastres que incluya copias de seguridad periódicas, pruebas de las copias de seguridad para garantizar que son válidas, y un plan para restaurar las copias de seguridad en caso de fallo.
7. Utiliza la fragmentación basada en hash cuando sea apropiado
Cuando las aplicaciones realizan consultas basadas en rangos, la fragmentación basada en rangos es beneficiosa porque las operaciones pueden limitarse a menos fragmentos, en la mayoría de los casos a un único fragmento. Necesitas entender tus datos y los patrones de consulta para implementar esto.
La fragmentación en hash garantiza una distribución uniforme de lecturas y escrituras. Sin embargo, no proporciona operaciones eficientes basadas en rangos.
¿Cuáles Son los Errores Más Comunes que Debes Evitar al Fragmentar tu Base de Datos MongoDB?
El sharding de MongoDB es una potente técnica que puede ayudarte a escalar tu base de datos horizontalmente y distribuir los datos entre varios servidores. Sin embargo, hay varios errores comunes que debes evitar al fragmentar tu base de datos MongoDB. A continuación te mostramos algunos de los errores más comunes y cómo evitarlos.
1. Elegir la clave de shard incorrecta
Una de las decisiones más cruciales que tomarás al fragmentar tu base de datos MongoDB es elegir la clave de shard. La clave de shard determina cómo se distribuyen los datos entre los fragmentos, y elegir una clave incorrecta puede provocar una distribución desigual de los datos, puntos calientes y un rendimiento deficiente.
Un error común es elegir un valor de clave de fragmentación que sólo aumente para los nuevos documentos cuando se utiliza la fragmentación basada en rangos, en lugar de la fragmentación en hash. Por ejemplo, una marca de tiempo (naturalmente) o cualquier cosa con un componente temporal como componente más fundamental, como ObjectID (los cuatro primeros bytes son una marca de tiempo).
Si seleccionas una clave de shard, todas las inserciones irán al fragmento con más rango. Aunque sigas añadiendo nuevos fragmentos, tu capacidad máxima de escritura nunca aumentará.
Si planeas escalar por capacidad de escritura, prueba a utilizar una clave de fragmento basada en hash, que permitirá utilizar el mismo campo a la vez que proporciona una buena escalabilidad de escritura.
2. Intentar cambiar el valor de la clave de shard
Las claves de shard son inmutables para un documento existente, lo que significa que no puedes cambiar la clave. Puedes hacer ciertas actualizaciones antes de la fragmentación, pero no después. Si intentas modificar la clave de fragmento de un documento existente, se producirá el siguiente error:
cannot modify shard key's value fieldid for collection: collectionnamePuedes eliminar y volver a insertar el documento para renovar la clave de fragmento en lugar de intentar modificarla.
3. Error al supervisar el clúster
La fragmentación introduce una complejidad adicional en el entorno de la base de datos, por lo que es esencial supervisar de cerca el clúster. No supervisar el clúster puede provocar problemas de rendimiento, pérdida de datos y otros problemas.
Para evitar este error, debes configurar herramientas de supervisión para realizar un seguimiento de las métricas clave, como el uso de la CPU, la memoria, el espacio en disco y el tráfico de red. También debes configurar alertas cuando se superen determinados umbrales.
4. Esperar demasiado para añadir un nuevo shard (sobrecargado)
Un error común que debes evitar al fragmentar tu base de datos MongoDB es esperar demasiado para añadir un nuevo shard. Cuando un fragmento se sobrecarga con datos o consultas, puede provocar problemas de rendimiento y ralentizar todo el clúster.
Supongamos que tienes un clúster imaginario formado por 2 shard, con 20000 chunks (5000 considerados «activos»), y necesitamos añadir un 3er shard. Este 3er shard acabará almacenando un tercio de los fragmentos activos (y del total de fragmentos).
El reto consiste en averiguar cuándo el fragmento deja de añadir sobrecarga y se convierte en un activo. Tendríamos que calcular la carga que produciría el sistema al migrar los fragmentos activos al nuevo fragmento y cuándo sería insignificante en comparación con la ganancia global del sistema.
En la mayoría de los escenarios, es relativamente fácil imaginar que este conjunto de migraciones tardaría aún más en un conjunto de fragmentos sobrecargados, y que nuestro fragmento recién añadido tardaría mucho más en cruzar el umbral y convertirse en una ganancia neta. Por ello, es mejor ser proactivo y añadir capacidad antes de que sea necesario.
Entre las posibles estrategias de mitigación se incluyen la supervisión periódica del clúster y la adición proactiva de nuevos fragmentos en momentos de poco tráfico, para que haya menos competencia por los recursos. Se sugiere equilibrar manualmente los shard «calientes» (a los que se accede más que a otros) para trasladar la actividad al nuevo fragmento más rápidamente.
5. Infraprovisión de servidores de configuración
Si los servidores de configuración están infraaprovisionados, pueden producirse problemas de rendimiento e inestabilidad. La infradotación puede deberse a una asignación insuficiente de recursos, como CPU, memoria o almacenamiento.
Esto puede provocar un rendimiento lento de las consultas, tiempos de espera e incluso fallos. Para evitarlo, es esencial asignar suficientes recursos a los servidores de configuración, especialmente en clusters grandes. Supervisar regularmente el uso de recursos de los servidores de configuración puede ayudar a identificar problemas de infradotación.
Otra forma de evitarlo es utilizar hardware dedicado para los servidores de configuración, en lugar de compartir recursos con otros componentes del clúster. Esto puede ayudar a garantizar que los servidores de configuración tengan suficientes recursos para manejar su carga de trabajo.
6. No hacer copias de seguridad ni restaurar los datos
Las copias de seguridad son esenciales para garantizar que los datos no se pierdan en caso de fallo. La pérdida de datos puede producirse por varias razones, como fallos del hardware, errores humanos y ataques malintencionados.
No hacer copias de seguridad y restaurar los datos puede provocar su pérdida y el tiempo de inactividad. Para evitar este error, debes establecer una estrategia de copia de seguridad y restauración que incluya copias de seguridad periódicas, copias de seguridad de prueba y restauración de datos en un entorno de prueba.
7. No probar el clúster fragmentado
Antes de desplegar tu cluster fragmentado en producción, debes probarlo a fondo para asegurarte de que puede manejar la carga y las consultas esperadas. No probar el clúster fragmentado puede provocar un rendimiento deficiente y fallos.
MongoDB Sharding vs Índices Agrupados: ¿Cuál Es Más Eficaz para Grandes Conjuntos de Datos?
Tanto el sharding como los índices agrupados de MongoDB son estrategias eficaces para manejar grandes conjuntos de datos. Pero sirven para fines distintos. Elegir el enfoque adecuado depende de los requisitos específicos de tu aplicación.
El sharding es una técnica de escalado horizontal que distribuye los datos entre muchos nodos, lo que la convierte en una solución eficaz para manejar grandes conjuntos de datos con altas tasas de escritura. Es transparente para las aplicaciones, permitiéndoles interactuar con MongoDB como si fuera un único servidor.
Por otro lado, los índices agrupados mejoran el rendimiento de las consultas que recuperan datos de grandes conjuntos de datos, ya que permiten a MongoDB localizar los datos de forma más eficiente cuando una consulta coincide con el campo indexado.
Entonces, ¿cuál es más eficaz para los grandes conjuntos de datos? La respuesta depende del caso de uso específico y de los requisitos de la carga de trabajo.
Si la aplicación requiere un alto rendimiento de escritura y consulta, y necesita escalar horizontalmente, entonces el sharding de MongoDB es probablemente la mejor opción. Sin embargo, los índices agrupados pueden ser más eficaces si la aplicación tiene una carga de trabajo de lectura pesada y requiere que los datos consultados con frecuencia se organicen en un orden específico.
Tanto la fragmentación como los índices agrupados son herramientas potentes para gestionar grandes conjuntos de datos en MongoDB. La clave está en evaluar cuidadosamente los requisitos de tu aplicación y las características de la carga de trabajo para determinar el mejor enfoque para tu caso de uso específico.
Resumen
Un clúster fragmentado es una potente arquitectura que puede gestionar grandes cantidades de datos y escalar horizontalmente para satisfacer las necesidades de las aplicaciones en crecimiento. El clúster consta de shard, servidores de configuración, procesos mongos y aplicaciones cliente, y los datos se particionan en función de una clave de shard elegida cuidadosamente para garantizar una distribución y consulta eficientes.
Aprovechando la potencia de la fragmentación, las aplicaciones pueden lograr una alta disponibilidad, un rendimiento mejorado y un uso eficiente de los recursos de hardware. Elegir la clave de fragmentación adecuada es crucial para la distribución uniforme de los datos.
¿Qué opinas sobre MongoDB y la práctica del Sharding de bases de datos? ¿Hay algún aspecto de la fragmentación que crees que deberíamos haber tratado? Háznoslo saber en los comentarios


