
Node.js est un moteur d’exécution JavaScript côté serveur qui utilise un modèle d’entrée-sortie (E/S) non bloquant et piloté par les évènements. Il est largement reconnu pour la construction d’applications web rapides et évolutives. Il dispose également d’une grande communauté et d’une riche bibliothèque de modules qui simplifient diverses tâches et processus.
Le clustering améliore les performances des applications Node.js en leur permettant de s’exécuter sur plusieurs processus. Cette technique leur permet d’utiliser tout le potentiel d’un système multicœur.
Cet article présente une vue d’ensemble du clustering dans Node.js et de la manière dont il affecte les performances d’une application.
Qu’est-ce que le clustering ?
Par défaut, les applications Node.js s’exécutent sur un seul thread. Cette nature monotâche signifie que Node.js ne peut pas utiliser tous les cœurs d’un système multicœur – ce qui est le cas de la plupart des systèmes actuels.
Node.js peut néanmoins traiter plusieurs requêtes simultanément en exploitant les opérations d’E/S non bloquantes et les techniques de programmation asynchrones.
Toutefois, les tâches de calcul lourdes peuvent bloquer la boucle d’évènements et empêcher l’application de répondre. Par conséquent, Node.js est livré avec un module cluster natif – indépendamment de sa nature monotâche – pour tirer parti de la puissance de traitement totale d’un système multicœur.
L’exécution de plusieurs processus tire parti de la puissance de traitement de plusieurs cœurs d’unité centrale de traitement (CPU) pour permettre un traitement parallèle, réduire les temps de réponse et augmenter le débit. Cela permet d’améliorer les performances et l’évolutivité des applications Node.js.
Comment fonctionne le clustering ?
Le module de cluster Node.js permet à une application Node.js de créer un cluster de processus enfants fonctionnant simultanément, chacun gérant une partie de la charge de travail de l’application.
Lors de l’initialisation du module cluster, l’application crée le processus principal, qui transforme ensuite les processus enfants en processus workers. Le processus primaire agit comme un équilibreur de charge, distribuant la charge de travail aux processus workers pendant que chaque processus worker est à l’écoute des requêtes entrantes.
Le module de cluster Node.js dispose de deux méthodes pour distribuer les connexions entrantes.
- L’approche approche round-robin – Le processus principal écoute sur un port, accepte les nouvelles connexions et répartit uniformément la charge de travail pour s’assurer qu’aucun processus n’est surchargé. Il s’agit de l’approche par défaut sur tous les systèmes d’exploitation, à l’exception de Windows.
- La deuxième approche – Le processus principal crée la socket d’écoute et l’envoie aux workers « intéressés », qui acceptent directement les connexions entrantes.
En théorie, la deuxième approche – qui est plus compliquée – devrait offrir de meilleures performances. Mais en pratique, la distribution des connexions est très déséquilibrée. La documentation de Node.js mentionne que 70 % de toutes les connexions aboutissent à seulement deux processus sur huit.
Comment regrouper vos applications Node.js ?
Examinons maintenant les effets du clustering dans une application Node.js. Ce tutoriel utilise une application Express qui exécute intentionnellement une tâche de calcul lourde pour bloquer la boucle d’évènements.
Tout d’abord, exécutez cette application sans clustering. Ensuite, enregistrez les performances à l’aide d’un outil d’analyse comparative. Ensuite, le clustering est implémenté dans l’application et l’analyse comparative est répétée. Enfin, comparez les résultats pour voir comment le clustering améliore les performances de votre application.
Premiers pas
Pour comprendre ce tutoriel, vous devez être familiarisé avec Node.js et Express. Pour configurer votre serveur Express :
- Commencez par créer le projet.
mkdir cluster-tutorial - Naviguez jusqu’au répertoire de l’application et créez deux fichiers, no-cluster.js et cluster.js, en exécutant la commande ci-dessous :
cd cluster-tutorial && touch no-cluster.js && touch cluster.js - Initialisez NPM dans votre projet :
npm init -y - Enfin, installez Express en exécutant la commande ci-dessous :
npm install express
Création d’une application non groupée
Dans votre fichier no-cluster.js, ajoutez le bloc de code ci-dessous :
const express = require("express");
const PORT = 3000;
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/slow", (req, res) => {
//Start timer
console.time("slow");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});Le bloc de code ci-dessus crée un serveur express qui fonctionne sur le port 3000. Le serveur a deux routes, une route racine (/) et une route /slow. La route racine envoie une réponse au client avec le message suivant : « Response from server »
Cependant, la route /slow effectue intentionnellement des calculs lourds pour bloquer la boucle d’évènements. Cette route démarre un minuteur et remplit ensuite un tableau avec 100.000 nombres aléatoires à l’aide d’une boucle for.
Ensuite, à l’aide d’une autre boucle for, il met au carré chaque nombre du tableau généré et les additionne. La minuterie se termine à la fin de l’opération et le serveur répond avec les résultats.
Démarrez votre serveur en exécutant la commande ci-dessous :
node no-cluster.jsEffectuez ensuite une requête GET à l’adresse localhost:3000/slow.
Pendant ce temps, si vous tentez d’envoyer d’autres requêtes à votre serveur – par exemple à la route racine (/) – les réponses sont lentes car la route /slow bloque la boucle d’évènements.
Création d’une application groupée
Créez des processus enfants à l’aide du module cluster pour vous assurer que votre application ne devient pas insensible et ne bloque pas les requêtes ultérieures lors de tâches de calcul lourdes.
Chaque processus enfant exécute sa boucle d’évènements et partage le port du serveur avec le processus parent, ce qui permet une meilleure utilisation des ressources disponibles.
Tout d’abord, importez le module Node.js cluster et os dans votre fichier cluster.js. Le module cluster permet de créer des processus enfants afin de répartir la charge de travail sur plusieurs cœurs de processeur.
Le module os fournit des informations sur le système d’exploitation de votre ordinateur. Vous avez besoin de ce module pour connaitre le nombre de cœurs disponibles sur votre système et vous assurer que vous ne créez pas plus de processus enfants que de cœurs sur votre système.
Ajoutez le bloc de code ci-dessous pour importer ces modules et récupérer le nombre de cœurs sur votre système :
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;Ensuite, ajoutez le bloc de code ci-dessous à votre fichier cluster.js:
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
console.log(`This machine has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Replace the dead worker
console.log("Starting a new worker");
cluster.fork();
});
}Le bloc de code ci-dessus vérifie si le processus en cours est le processus principal ou le processus ouvrier. Si c’est le cas, le bloc de code crée des processus enfants en fonction du nombre de cœurs de votre système. Ensuite, il écoute l’évènement de sortie des processus et les remplace en créant de nouveaux processus.
Enfin, enveloppez toute la logique express connexe dans un bloc else. Votre fichier cluster.js terminé devrait ressembler au bloc de code ci-dessous.
//cluster.js
const express = require("express");
const PORT = 3000;
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
console.log(`This machine has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Replace the dead worker
console.log("Starting a new worker");
cluster.fork();
});
} else {
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/slow", (req, res) => {
console.time("slow");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});
}Après avoir mis en œuvre le clustering, plusieurs processus traiteront les requêtes. Cela signifie que votre application reste réactive même lors d’une tâche de calcul lourde.
Comment évaluer les performances à l’aide de loadtest
Pour démontrer et afficher avec précision les effets de la mise en cluster dans une application Node.js, utilisez le paquet npm loadtest pour comparer les performances de votre application avant et après la mise en cluster.
Exécutez la commande ci-dessous pour installer loadtest globalement :
npm install -g loadtestLe paquet loadtest exécute un test de charge sur une URL HTTP/WebSockets spécifiée.
Ensuite, démarrez votre fichier no-cluster.js sur une instance de terminal. Ensuite, ouvrez une autre instance de terminal et exécutez le test de charge ci-dessous :
loadtest http://localhost:3000/slow -n 100 -c 10La commande ci-dessus envoie 100 requêtes avec une concurrence de 10 à votre application non clusterisée. L’exécution de cette commande produit les résultats ci-dessous :
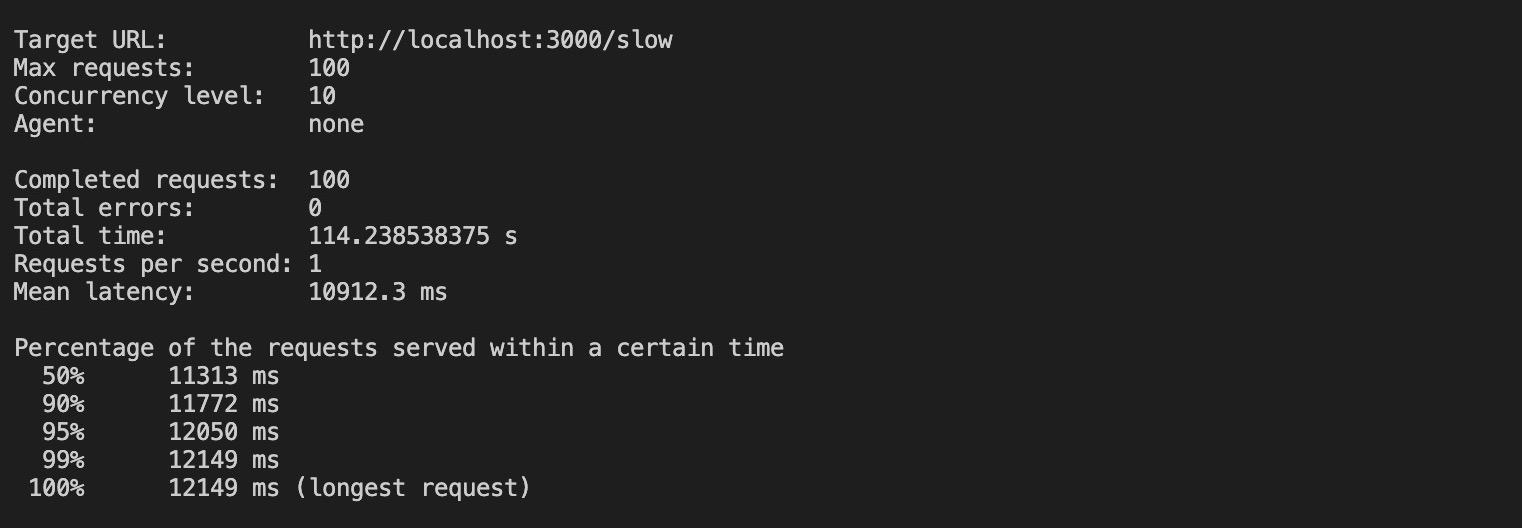
D’après les résultats, il a fallu environ 100 secondes pour traiter toutes les demandes sans clustering, et la requête la plus longue a pris jusqu’à 12 secondes pour être traitée.
Les résultats varieront en fonction de votre système.
Ensuite, arrêtez d’exécuter le fichier no-cluster.js et démarrez votre fichier cluster.js sur une instance de terminal. Ensuite, ouvrez une autre instance de terminal et exécutez ce test de charge :
loadtest http://localhost:3000/slow -n 100 -c 10La commande ci-dessus enverra 100 requêtes avec une concurrence 10 à votre application clusterisée.
L’exécution de cette commande produit les résultats ci-dessous :
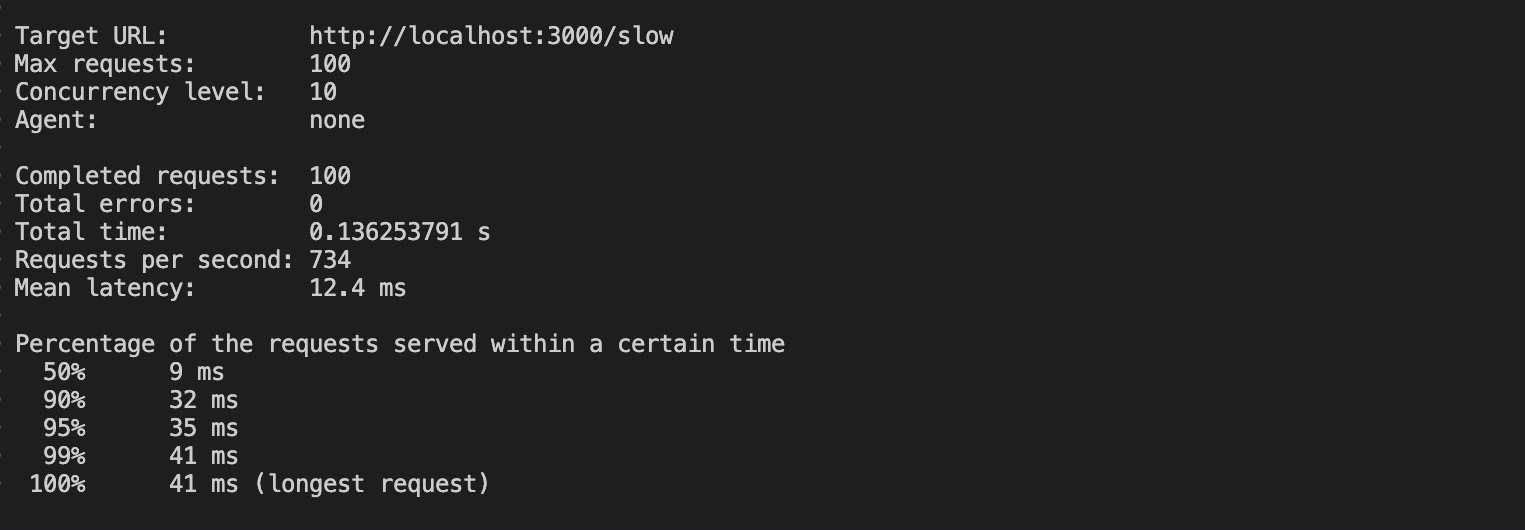
Avec le clustering, les requêtes ont pris 0,13 seconde (136 ms) pour s’exécuter, ce qui représente une énorme diminution par rapport aux 100 secondes nécessaires à l’application non mise en grappe. En outre, la requête la plus longue de l’application groupée a pris 41 ms pour s’exécuter.
Ces résultats démontrent que la mise en place d’un clustering améliore considérablement les performances de votre application. Notez que vous devriez utiliser un logiciel de gestion de processus tel que PM2 pour gérer votre clustering dans les environnements de production.
Utiliser Node.js avec l’hébergement d’applications de Kinsta
Kinsta est une société d’hébergement qui facilite le déploiement de vos applications Node.js. Sa plateforme d’hébergement est construite sur Google Cloud Platform, qui fournit une infrastructure fiable conçue pour gérer un trafic élevé et prendre en charge des applications complexes. En fin de compte, cela améliore les performances des applications Node.js.
Kinsta offre diverses fonctionnalités pour les déploiements Node.js, telles que les connexions internes aux bases de données, l’intégration Cloudflare, les déploiements GitHub et les Google C2 Machines.
Ces fonctionnalités facilitent le déploiement et la gestion des applications Node.js et rationalisent le processus de développement.
Pour déployer votre application Node.js sur l’hébergement d’applications de Kinsta, il est essentiel de pousser le code et les fichiers de votre application vers le fournisseur Git de votre choix (Bitbucket, GitHub ou GitLab).
Une fois que votre dépôt est configuré, suivez les étapes suivantes pour déployer votre application Express sur Kinsta :
- Connectez-vous ou créez un compte pour afficher votre tableau de bord MyKinsta.
- Autorisez Kinsta avec votre fournisseur Git.
- Cliquez sur Applications dans la colonne latérale de gauche, puis sur Ajouter une application.
- Sélectionnez le dépôt et la branche à partir desquels vous souhaitez déployer l’application.
- Attribuez un nom unique à votre application et choisissez l’emplacement du centre de données.
- Configurez ensuite votre environnement de construction. Sélectionnez la configuration Machine de construction standard avec l’option Nixpacks recommandée pour cette démo.Utilisez toutes les configurations par défaut, puis cliquez sur Créer une application.
Résumé
Le clustering dans Node.js permet la création de plusieurs processus de travail pour distribuer la charge de travail, améliorant ainsi les performances et l’évolutivité des applications Node.js. Il est essentiel d’implémenter correctement le clustering afin d’atteindre le plein potentiel de cette technique.
La conception de l’architecture, la gestion de l’allocation des ressources et la minimisation de la latence du réseau sont des facteurs essentiels lors de la mise en œuvre du clustering dans Node.js. L’importance et la complexité de cette mise en œuvre expliquent pourquoi les gestionnaires de processus tels que PM2 devraient être utilisés dans les environnements de production.
Que pensez-vous du clustering dans Node.js ? L’avez-vous déjà utilisé ? Partagez dans la section des commentaires !


