
TL;DR
En novembre 2018, l’Internet Engineering Task Force (IETF) s’est réunie à Bangkok et un nouveau projet Internet a été adopté. Le protocole de transport QUIC, le successeur de HTTP/2, a été renommé en HTTP/3.
HTTP/3 s’appuie sur UDP et est déjà utilisé par d’importantes sociétés Internet telles que Google et Facebook. Si vous utilisez Chrome et vous connectez à un service Google, vous utilisez probablement déjà QUIC.
La nouvelle version du protocole HTTP bénéficie du bare-metal, du protocole UDP low-level, et définit un grand nombre des nouvelles fonctionnalités qui se trouvaient dans les versions précédentes du protocole HTTP sur la couche TCP. Cela permet de résoudre les contraintes au sein de l’infrastructure Internet existante.
Les premiers résultats sont prometteurs, et lorsque le projet Internet de l’IETF expirera, en août 2021, on peut s’attendre à ce que HTTP/3 soit présenté comme une nouvelle norme HTTP de troisième génération.
Progrès de HTTP/3 en 2026
Certains disent que la soif de vitesse et de latence de l’industrie du web n’a d’égal que la soif de Google Chrome pour plus de RAM.
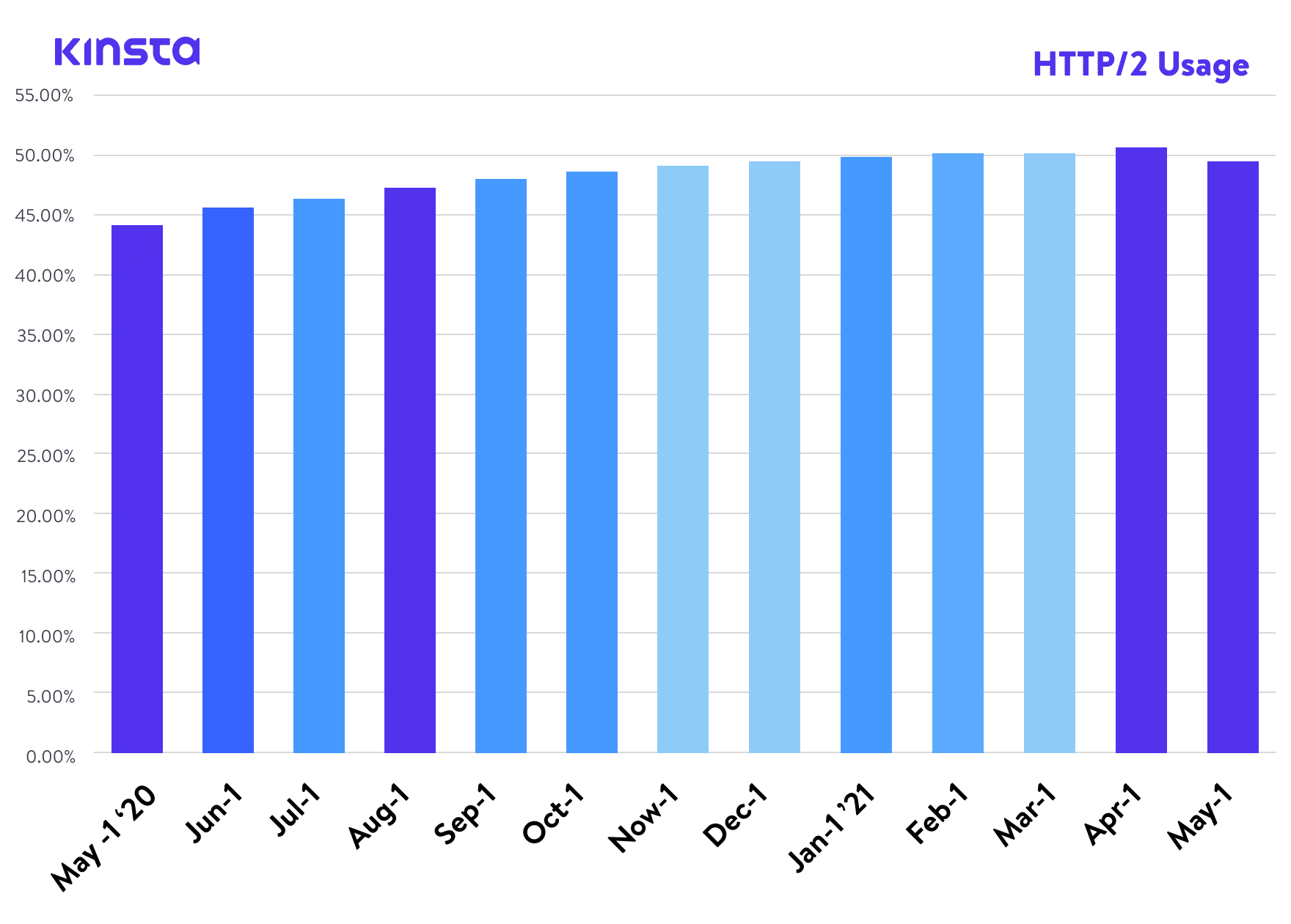
Il y a quelques années, nous avons publié un article sur HTTP/2, une norme qui, selon W3Techs, a désormais atteint un taux d’adoption mondial d’environ 45 %. Et selon Can I Use, elle est également prise en charge par tous les navigateurs web modernes. Pourtant, nous voici en train d’écrire un article sur la prochaine version du protocole, HTTP/3.
HTTP/3 est, au moment de la rédaction de cet article, un Internet-Draft ou ID de l’IETF, ce qui signifie qu’il est actuellement à l’étude pour une future norme Internet par l’Internet Engineering Task Force – un organisme international de normalisation Internet, chargé de définir et de promouvoir des normes de protocole Internet approuvées, comme TCP, IPv6, VoIP, Internet des objets, etc.
Il s’agit d’un organisme ouvert qui réunit l’industrie du web et facilite les discussions sur l’orientation d’Internet. Actuellement, la phase « Internet Draft » de HTTP/3 est la dernière phase avant que les propositions ne soient promues au niveau des demandes de commentaires (Request-for-Comments ou RFC), que nous pouvons considérer, à toutes fins utiles, comme des définitions officielles du protocole Internet.
Bien que HTTP/3 ne soit pas encore un protocole Internet officiel, de nombreuses entreprises et projets ont déjà commencé à ajouter la prise en charge de HTTP/3 dans leurs produits.
Qu'est-ce que le HTTP/3 - En termes simples ?
HTTP/3 est la troisième version du protocole HTTP (Hypertext Transfer Protocol), anciennement HTTP over-QUIC. QUIC (Quick UDP Internet Connections) a été initialement développé par Google et est le successeur de HTTP/2. Des entreprises comme Google et Facebook utilisent déjà QUIC pour accélérer le Web.
Support de HTTP/3 par les navigateurs web
En ce qui concerne les navigateurs web, Chrome v87, Firefox v88 et Edge v87 ont tous HTTP/3 activé par défaut. Pour les utilisateurs de Safari, l’option permettant d’activer HTTP/3 a été ajoutée dans Safari Technology Preview v104. Toutefois, le support de HTTP/3 n’est pas encore disponible dans la version stable de Safari.
Prise en charge de HTTP/3 par les bibliothèques
Pour les développeurs qui cherchent à exploiter les technologies HTTP/3, de nombreuses bibliothèques populaires ont déjà ajouté la prise en charge de HTTP/3. Étant donné que HTTP/3 n’en est encore qu’au stade de l’Internet Draft, vous devez vous assurer que vous êtes au courant des dernières mises à jour lorsque vous travaillez avec l’une des bibliothèques ci-dessous.
- Python – http3 et aioquic
- Rust – quiche, neqo, et quinn
- C – nghttp3 et lsquic
- Go – quicgo
- JavaScript – Node.js
Prise en charge de HTTP/3 par l’infrastructure
Du côté de l’infrastructure, Cloudflare a ouvert la voie en prenant en charge HTTP/3 sur l’ensemble de son réseau périphérique. Cela signifie que les sites ayant Cloudflare activé peuvent profiter de la sécurité et des améliorations de performance de HTTP/3 sans aucun travail supplémentaire.
Chez Kinsta, tous les sites que nous hébergeons sont protégés par notre intégration gratuite de Cloudflare. En plus d’un pare-feu de niveau entreprise et d’une protection DDoS, les clients de Kinsta ont également accès à HTTP/3 !
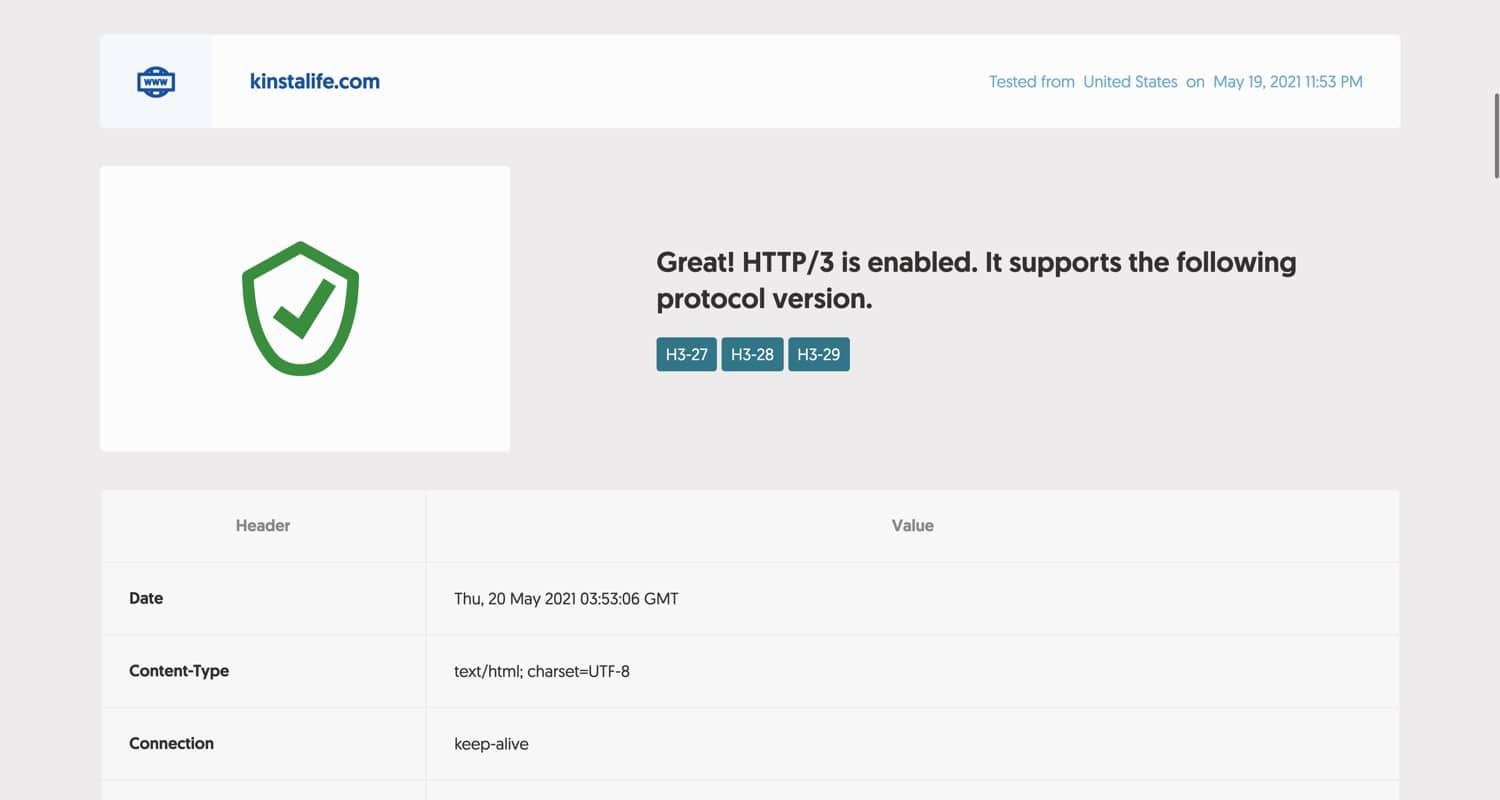
Pour tester si votre site prend en charge HTTP/3, vous pouvez utiliser l’outil de test HTTP/3 de Geekflare. Il suffit de saisir votre domaine et de cliquer sur le bouton « Check HTTP/3 », et l’outil vous fera savoir si votre site est compatible avec HTTP/3.

Si votre site prend en charge HTTP/3, vous devriez voir un message comme celui ci-dessous. Comme kinstalife.com est hébergé sur Kinsta, HTTP/3 est entièrement pris en charge grâce à notre intégration Cloudflare.
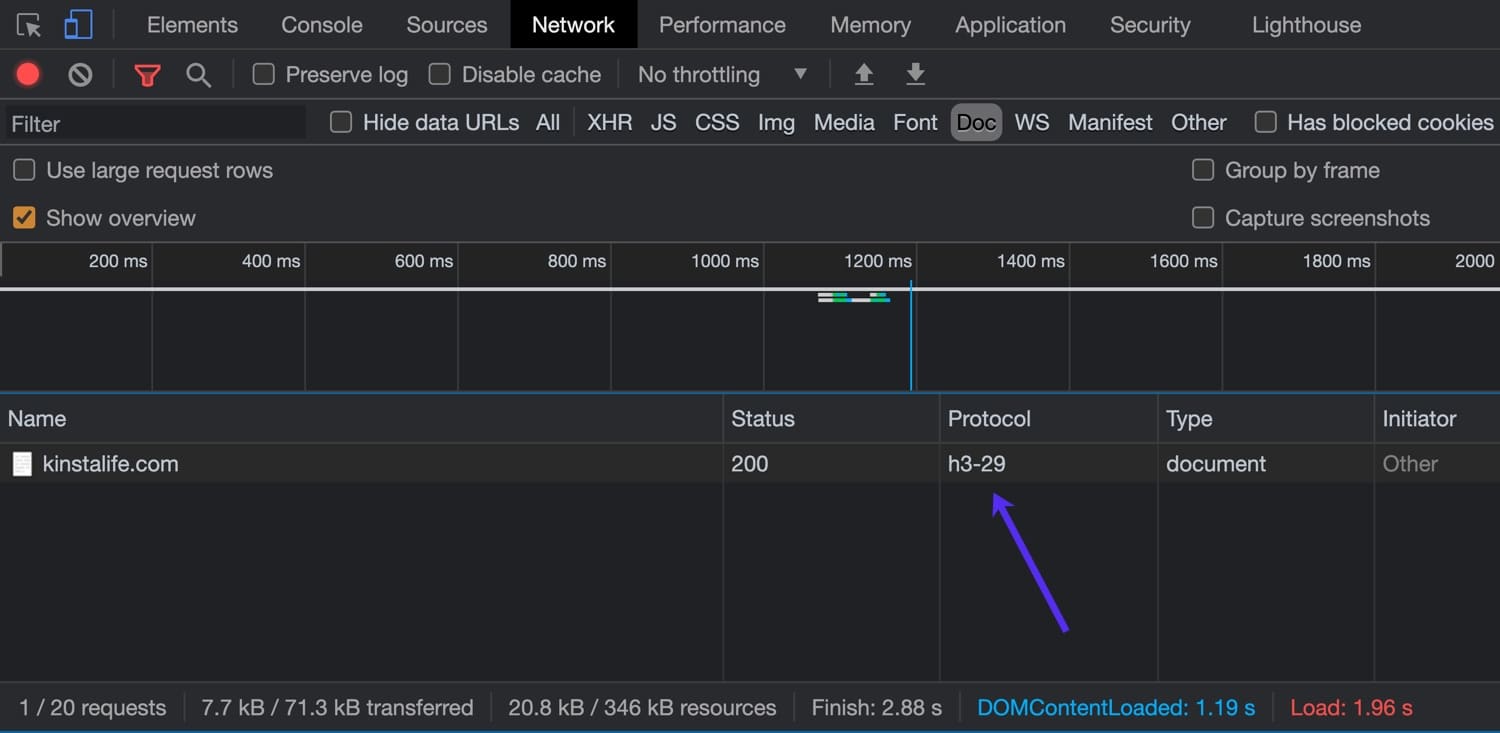
Vous pouvez également utiliser l’inspecteur de votre navigateur pour vérifier la prise en charge de HTTP/3. Pour cet exemple, nous utiliserons la dernière version de Google Chrome qui prend en charge HTTP/3.
Pour ouvrir l’inspecteur, faites un clic droit sur la page et cliquez sur « Inspecter », puis accédez à l’onglet « Réseau ». Dans la colonne « Protocole », vous pouvez voir le protocole HTTP utilisé pour la connexion. Les connexions HTTP/2 apparaissent sous la forme « h2 », tandis que les connexions HTTP/3 apparaissent sous la forme « h3-XX » (XX fait référence à un projet HTTP/3 spécifique). Comme vous pouvez le voir dans l’image ci-dessous, kinstalife.com prend en charge les connexions sur « h3-29 », ce qui signifie « HTTP/3 Draft 29 ».
Maintenant que nous avons passé en revue l’état actuel de HTTP/3, plongeons dans les différences entre HTTP/2 et HTTP/3 !
Retour en arrière – Ça a commencé avec HTTP/2
HTTP/2 a apporté de sérieuses améliorations avec des téléchargements non bloquants, des pipelines et les serveurs push qui nous ont aidé à surmonter certaines limitations du protocole TCP sous-jacent. Cela nous a permis de réduire au minimum le nombre de cycles de requêtes-réponses.
HTTP/2 permettait de pousser plus d’une ressource dans une seule connexion TCP – le multiplexage. Nous avons également obtenu plus de flexibilité dans l’ordre des téléchargements statiques, et nos pages ne sont maintenant plus limitées par une progression linéaire des téléchargements.

En pratique, cela signifie qu’une ressource javascript importante n’équivaut pas nécessairement à un point d’étranglement pour toutes les autres ressources statiques qui attendent leur tour.

Ajoutez à cela la compression HPACK de l’en-tête HTTP/2 et le format binaire par défaut du transfert de données, et nous avons, dans de nombreux cas, un protocole beaucoup plus efficace.

Les implémentations majeures de navigateurs ont rendu nécessaire l’implémentation du cryptage – SSL – pour pouvoir bénéficier des avantages de HTTP/2 – et parfois cela a entraîné un surcoût de calcul qui a rendu les améliorations de vitesse imperceptibles. Il y a même eu des cas où les utilisateurs ont signalé un ralentissement après la transition vers HTTP/2.
Disons simplement que les premiers jours de l’adoption de cette version n’étaient pas pour les cœurs fragiles.
L’implémentation de Nginx ne disposait pas non plus de la fonction de push serveur, s’appuyant sur un module. Et les modules Nginx ne sont pas les modules Apache habituels que vous pouvez simplement copier – NGINX doit être recompilé avec ceux-ci.
Bien que certains de ces problèmes soient maintenant résolus, si nous regardons l’ensemble de la pile de protocoles, nous constatons que la contrainte principale se situe à un niveau inférieur à celui que HTTP/2 a osé tenter.
Pour élaborer ceci, nous allons disséquer la pile de protocole Internet d’aujourd’hui de sa couche inférieure vers le haut. Si vous voulez en savoir plus sur l’arrière-plan de HTTP/2, n’hésitez pas à consulter notre guide HTTP/2 ultime.
Protocole Internet (IP)
Le protocole Internet (IP) définit la partie inférieure de toute la topologie Internet. C’est la partie de la pile Internet qui n’est, nous pouvons le dire, vraiment pas négociable sans tout changer, y compris le remplacement de toute l’infrastructure matérielle, des routeurs aux serveurs et même aux machines des utilisateurs finaux.
Ainsi, bien que la révision du protocole soit peut-être due, une entreprise d’une telle envergure n’est pas à l’horizon en ce moment, principalement parce que nous n’avons pas encore trouvé une solution de rechange viable, révolutionnaire, mais compatible avec le passé.
Les débuts du protocole IP remontent à 1974, avec un article publié par l’Institute of Electrical and Electronics Engineers et rédigé par Vint Cerf et Bob Cahn. Il détaille les paquets envoyés sur un réseau, les achemine à travers les adresses IP et les adresses numériques définies des nœuds d’un réseau/réseaux. Le protocole définissait le format de ces paquets, ou datagrammes – ses en-têtes et sa charge utile.
Après la définition de la RFC 760 de 1980, l’IETF a adopté la définition largement utilisée à ce jour, dans sa Demande de Commentaires 791. C’est la quatrième version du protocole, mais on peut dire qu’il s’agit de la première version en production.

Il utilise des adresses 32 bits, ce qui limite le nombre d’adresses à environ 4 milliards. Cette limitation explique le mystère de savoir pourquoi les internautes non professionnels obtiennent des « adresses IP dynamiques » de la part de leur FAI, et une IP statique est considérée comme une « valeur ajoutée » et souvent soumise à des frais supplémentaires.
Ils sont en train de rationner.
Il n’a pas fallu longtemps avant que l’on se rende compte que les adresses 32 bits ne suffisaient pas et que la pénurie était imminente, de nombreux RFCs ont donc été publiés pour tenter d’y remédier. Bien que ces solutions soient largement utilisées aujourd’hui et qu’elles fassent partie de notre vie quotidienne, on peut probablement dire sans risque de se tromper qu’elles sont très populaires.
Le protocole Internet version 6 ou IPv6 est venu comme un moyen d’aborder ces limitations, y compris d’être progressivement adopté par rapport à la version précédente. Il est devenu un projet de norme pour l’IETF en 1998 et a été élevé au rang de norme Internet en 2017.
Alors que l’espace adresse IPv4 était limité par sa longueur d’adresse de 32 bits, la norme IPv6 était de 128 bits, soit 3,4 * 10 ^ 38 adresses possibles. Cela devrait suffire à nous faire durer un certain temps.
Selon Google et la connectivité IPv6 parmi ses utilisateurs, l’adoption d’IPv6 est légèrement supérieure à 35 % en juin 2021.

L’IP est une couche rudimentaire de la pile Internet, définissant la plupart des choses de base, sans garantie de livraison, d’intégrité des données, ou de commande des paquets transmis. À lui seul, il n’est pas fiable. Le format d’en-tête d’IPv4 fournit la somme de contrôle d’en-tête que les nœuds de transmission utilisent pour vérifier l’intégrité de l’en-tête. Cela le rend différent de la version IPv6, qui s’appuie sur la couche de liaison en dessous, ce qui lui permet d’être plus rapide.

Comprendre le rôle du TCP et UDP
Maintenant, il est temps d’explorer où HTTP/3 s’intègre avec TCP et UDP.
TCP
Alors que l’IP est la couche sous-jacente de toutes nos communications en ligne aujourd’hui, le TCP (Transmission Control Protocol) est une partie de plus haut niveau de la suite de protocoles Internet, fournissant la fiabilité nécessaire pour le Web, le courrier, le transfert de fichiers (FTP) – pour les couches d’applications/protocoles de l’Internet.
Cela comprend l’établissement d’une connexion à plusieurs étapes, l’ordre assuré des paquets et la retransmission des paquets perdus. Il fournit un feedback (Acks) de la livraison à l’expéditeur et ainsi de suite. Il y a aussi le calcul de la somme de contrôle pour détecter les erreurs.
Toutes ces choses indiquent un grand nombre d’étapes qui font de TCP un protocole fiable, ce qui en fait le fondement des services Internet les plus célèbres que nous utilisons aujourd’hui.
Ses spécifications remontant à 1974 (RFC 675) et 1981 (RFC 793) n’ont pas beaucoup changé à ce jour.
La fiabilité que fournit TCP n’est cependant pas sans coût. Les frais généraux de tous les allers-retours requis par les prises de contact, les retours de livraison, les commandes de garanties et les sommes de contrôle qui pourraient être considérés comme faibles et redondants. Il a fait de TCP un goulot d’étranglement de la pile de protocoles moderne. HTTP/2 a atteint un plateau d’améliorations de vitesse qui peuvent être réalisées sur TCP.
Changer le TCP de manière substantielle n’est pas une tâche simple, car le protocole fait partie de la pile TCP/IP qui remonte aux années 70. Cela est profondément ancré dans les systèmes d’exploitation, le micrologiciel de l’appareil, etc.
UDP
UDP (User Datagram Protocol) est également l’une des parties de la suite de protocole Internet, avec ses spécifications qui remontent à 1980 (RFC 768).
Il s’agit, comme son nom l’indique, d’un protocole sans connexion basé sur un datagramme. Ce qui signifie qu’il n’y a pas de prise de contact et qu’il n’y a aucune garantie de commande ou de livraison. Cela signifie que toutes les étapes possibles pour assurer la livraison, l’intégrité des données et d’autres choses sont laissées sur la couche application. Cela signifie qu’une application construite sur UDP peut choisir les stratégies qu’elle utilisera en fonction du cas concret, ou qu’elle peut éventuellement utiliser des éléments de la couche de lien, comme les sommes de contrôle, pour éviter les frais généraux.
Étant donné que le protocole UDP est très répandu, tout comme le protocole TCP, il permet d’apporter des améliorations sans nécessiter de mises à jour des firmwares d’un grand nombre d’appareils connectés à Internet, ni de modifications importantes des systèmes d’exploitation.
Le déploiement de nouveaux protocoles est entravé par de nombreux pare-feu, NATs, routeurs et autres middle-box qui n’autorisent que le déploiement TCP ou UDP entre les utilisateurs et les serveurs qu’ils doivent atteindre. – Explication de HTTP/3
Ce fil de discussion sur Hacker News peut nous aider à commencer à comprendre le raisonnement derrière la construction de la nouvelle version HTTP sur la pile réseau existante, plutôt que de la réinventer (bien qu’il y ait plus que cela).
La spécification du format de paquet UDP est plutôt minimale, son en-tête se compose du port source, du port de destination, de la longueur, en octets, de l’en-tête du paquet et des données du paquet et de la somme de contrôle. La somme de contrôle peut être utilisée pour vérifier l’intégrité des données tant pour l’en-tête que pour la partie données du paquet.
La somme de contrôle est facultative lorsque la couche de protocole sous-jacente est IPv4, et obligatoire avec IPv6. Jusqu’à présent, l’UDP a été utilisé pour des choses comme la synchronisation de l’horloge des systèmes informatiques (NTP), applications VoIP, le streaming vidéo, le système DNS et le protocole DHCP.
QUIC et HTTP/3
QUIC (Quick UDP Internet Connections) a été déployé pour la première fois par Google en 2012. Il redéfinit les limites des couches réseau en s’appuyant sur le protocole UDP de niveau inférieur, en redéfinissant les prises de contact, les fonctions de fiabilité et les fonctions de sécurité dans « l’espace utilisateur », ce qui évite d’avoir à mettre à niveau les noyaux des systèmes Internet.

Tout comme avec HTTP/2, une avancée qui a été menée par Google SPDY ou Speedy, HTTP/3 s’appuiera à nouveau sur ces réalisations.
Bien que HTTP/2 nous ait donné le multiplexage et atténué le blocage en tête de ligne, il est limité par TCP. Vous pouvez utiliser une seule connexion TCP pour plusieurs flux multiplexés ensemble pour transférer des données, mais lorsque l’un de ces flux subit une perte de paquets, toute la connexion (et tous ses flux) sont retenus en otage, pour ainsi dire, jusqu’à ce que TCP fasse son travail (retransmettre le paquet perdu).
Cela signifie que tous les paquets, même s’ils sont déjà transmis et en attente, sont bloqués dans le tampon du noeud de destination jusqu’à ce que le paquet perdu soit retransmis. Daniel Stenberg dans son livre sur http/3 appelle ça un « bloc de tête de ligne basé sur TCP ». Il affirme qu’avec 2% de perte de paquets, les utilisateurs feront mieux avec HTTP/1, avec six connexions pour couvrir ce risque.
QUIC n’est pas contraint par cela. Avec QUIC s’appuyant sur le protocole UDP connectionless, le concept de connexion n’a pas les limites de TCP et les échecs d’un flux n’ont pas à influencer le reste.
Comme l’a dit Lucas Pardue de Cloudflare :

En mettant l’accent sur les flux UDP, QUIC réalise le multiplexage sans avoir à utiliser une seule connexion TCP. QUIC construit sa connexion à un niveau plus élevé que TCP. Les nouveaux flux dans les connexions QUIC ne sont pas obligés d’attendre que les autres se terminent. Les connexions QUIC bénéficient également de l’élimination de la surcharge du handshake TCP, ce qui réduit la latence.
Les gens de Cisco ont fait une vidéo intéressante expliquant la prise de contact à 3 voies de TCP:
Alors que QUIC supprime les fonctions de fiabilité TCP, il compense par la couche UDP, en assurant la retransmission des paquets, la commande, etc. Google Cloud Platform a introduit le support QUIC pour ses load balancers en 2018 et a vu une amélioration du temps moyen de chargement des pages de 8% au niveau mondial, et jusqu’à 13% dans les régions où la latence est plus élevée.
Entre Google Chrome, YouTube, Gmail, la recherche de Google et d’autres services, Google a pu déployer QUIC sur une bonne partie d’Internet, sans attendre l’IETF. Les ingénieurs de Google affirment qu’en 2017, 7% du trafic Internet était déjà réalisé sur QUIC.
La version de QUIC de Google se concentrait uniquement sur le transport HTTP, en utilisant la syntaxe HTTP/2. Les gens de l’IETF (ceux en charge de la standardisation de QUIC), ont décidé que la version IETF de QUIC devrait être capable de transporter plus que seulement HTTP. Pour l’instant, cependant, tout travail sur les protocoles autres que le protocole HTTP sur QUIC est en suspens.
Le groupe de travail de l’IETF a également décidé que la version standardisée utilisera le cryptage TLS 1.3 au lieu de la solution personnalisée de Google. TLS 1.3, par rapport aux anciennes versions, contribue également à la vitesse du protocole, car ses prises de contact nécessitent moins d’aller-retour. Kinsta supporte le TLS 1.3 sur tous nos serveurs et notre CDN Kinsta.
Actuellement, Google continue d’utiliser sa propre version de QUIC dans son produit, tout en orientant ses efforts de développement vers les normes IETF. La plupart des autres acteurs de l’Internet s’appuient sur la version de l’IETF (les deux diffèrent sur d’autres aspects que le cryptage).
Si nous ouvrons Chrome Dev Tools et chargeons certains produits Google, comme Gmail, dans la colonne Protocole de l’onglet Réseau, nous verrons beaucoup de ressources chargées via la version Google du protocole QUIC. C’est également le cas pour les produits Google comme Analytics, Google Tag Manager, etc.

Cloudflare a récemment publié une mise à jour très complète sur les progrès de la normalisation.
Bien que le protocole UDP offre certains avantages inhérents au QUIC et au HTTP/3, il comporte aussi certains défis.
TCP est le protocole courant depuis des années, alors que UDP ne l’est pas, de sorte que les systèmes d’exploitation et la pile logicielle n’est généralement pas aussi optimisée. Par conséquent, il y a beaucoup plus de charge/besoins CPU avec QUIC, selon certaines estimations, deux fois plus qu’avec HTTP/2.
Les optimisations vont en profondeur jusqu’au noyau des systèmes d’exploitation et aux différents routeurs et micrologiciels des appareils. Ce guide Red Hat Tuning peut apporter plus de lumière sur le sujet pour ceux qui sont plus enclins sur le plan technique.
Nous pourrions dire que QUIC tente de réinventer les fonctionnalités TCP en plus d’un protocole plus minimal et plus flexible.
Les connexions QUIC, que nous avons mentionnées plus haut, combinent le TLS et les poignées de main de transport. Une fois établis, ils sont identifiés par des CIDs uniques (ID de connexion). Ces IDs persistent à travers les changements d’IP et peuvent aider à sécuriser les téléchargements ininterrompus sur, par exemple, un passage de la 4G vers le WiFi. Cela est d’autant plus important que le trafic Internet est de plus en plus important sur les appareils mobiles. On peut se demander si cet élément est conçu par Google pour faciliter un meilleur suivi des utilisateurs entre les différentes connexions et les différents fournisseurs d’accès à Internet.
Le protocole TLS est obligatoire et vise à empêcher les périphériques situés au milieu d’altérer ou de snifer le trafic. C’est pourquoi il n’est pas rare de voir des fournisseurs de pare-feu comme Cisco voir le protocole UDP comme un problème, et de fournir des moyens de le désactiver. Il est plus difficile pour les intermédiaires d’inspecter et de superviser ou de filtrer le trafic QUIC.
Les flux QUIC sont envoyés via des connexions QUIC, unidirectionnelles ou bidirectionnelles. Les flux ont des IDs qui identifient l’initiateur et indiquent si le flux est unidirectionnel ou bidirectionnel, et servent également au contrôle du débit dans le flux.
Alors que QUIC est un protocole de couche de transport, HTTP est la couche supérieure, un protocole de couche d’application, ou protocole d’application.
Comme la rétrocompatibilité est de la plus haute importance, l’IETF a encouragé la mise en œuvre de HTTP/3 en incluant l’ancienne version (HTT1 ou HTTP/2) dans la réponse. Il comprendra un en-tête qui informe le client que HTTP/3 est disponible, ainsi que des informations sur le port/hôte, comme décrit dans la RFC 7838.
C’est différent de HTTP/2, dans lequel le transport peut être négocié dans le cadre de la prise de contact TLS. Mais comme l’IETF a pratiquement adopté le protocole HTTP/3 basé sur QUIC comme norme suivante, nous pouvons nous attendre à ce que les clients Web anticipent de plus en plus le support de HTTP/3. Il est possible pour les clients de mettre en cache les données des connexions HTTP/3 précédentes, et de se connecter directement (zero-round-trip, ou 0-RTT) lors de visites ultérieures sur le même hébergeur.
Résumé
Il y a ceux qui pensent qu’avec l’adoption incomplète de la norme HTTP/2, il est peut-être trop tôt pour faire pression en faveur de HTTP/3. C’est un point valable, mais, comme nous l’avons mentionné, ce protocole a déjà fait l’objet d’essais et de mises en œuvre à grande échelle. Google a commencé à le tester dès 2015, ainsi que Facebook en 2017.
En 2026, les principaux navigateurs comme Google Chrome et Brave prennent en charge HTTP/3. Sur le plan de l’infrastructure, des serveurs web comme Litespeed et Nginx disposent tous deux d’implémentations fonctionnelles de HTTP/3, tandis que des fournisseurs de réseaux comme Cloudflare ont déjà déployé un support complet de HTTP/3.
À l’heure actuelle, HTTP/3 est toujours en phase Internet Draft, et la dernière révision doit expirer en août 2021. Cette année sera passionnante, car nous pouvons nous attendre à voir les principaux fournisseurs de logiciels mettre en œuvre la nouvelle norme.

Tonino est un entrepreneur, un passionné de Linux et de logiciels libres, un développeur et un éducateur en technologie. Il a plus de dix ans d'expérience dans le développement et est dans l'espace blockchain depuis plus de 3 ans. Quand il ne code pas, il écrit pour SitePoint et Alibaba Cloud, regarde les dernières œuvres de fiction sur Netflix et explore de nouvelles destinations de voyage.

