
Vous avez déjà entendu le terme robots.txt et vous vous demandez comment il s’applique à votre site web ? La plupart des sites web ont un fichier robots.txt, mais cela ne signifie pas que la plupart des propriétaires de sites le comprennent. Dans cet article, nous espérons changer cela en vous proposant une plongée en profondeur dans le fichier robots.txt de WordPress, ainsi que dans la manière dont il peut contrôler et limiter l’accès à votre site.
Il y a beaucoup de choses à couvrir, alors commençons !
Qu’est-ce qu’un fichier WordPress robots.txt ?
Avant de parler du fichier WordPress robots.txt, il est important de définir ce qu’est un « robot » dans ce cas. Les robots sont tous les types de « robots » qui visitent les sites web sur Internet. L’exemple le plus courant est celui des robots d’indexation des moteurs de recherche. Ces robots parcourent le web pour aider les moteurs de recherche comme Google à indexer et à classer les milliards de pages présentes sur l’internet.
Les robots sont donc, en général, une bonne chose pour l’internet… ou du moins une chose nécessaire. Mais cela ne signifie pas nécessairement que vous, ou d’autres propriétaires de sites, souhaitiez que les robots se promènent sans entrave. Le désir de contrôler la manière dont les robots web interagissent avec les sites web a conduit à la création de la norme d’exclusion des robots au milieu des années 1990. Robots.txt est la mise en œuvre pratique de cette norme. Il vous permet de contrôler la manière dont les robots participants interagissent avec votre site. Vous pouvez bloquer complètement les robots, restreindre leur accès à certaines zones de votre site, etc.
La notion de « participation » est importante. Robots.txt ne peut pas forcer un robot à suivre ses directives. Les robots malveillants peuvent ignorer le fichier robots.txt et le feront. En outre, même des organisations réputées ignorent certaines commandes que vous pouvez insérer dans le fichier robots.txt. Par exemple, Google ne tiendra pas compte des règles que vous ajoutez à votre fichier robots.txt concernant la fréquence des visites de ses robots. Vous pouvez régler la fréquence d’exploration de votre site web par Google dans la page Réglages de la fréquence d’exploration de votre site dans Google Search Console.
Si vous rencontrez de nombreux problèmes avec les robots, une solution de sécurité telle que Cloudflare ou Sucuri peut s’avérer utile.
Comment trouver le fichier robots.txt ?
Le fichier robots.txt se trouve à la racine de votre site web. En ajoutant /robots.txt après votre domaine, vous devriez charger le fichier (si vous en avez un). Par exemple, https://kinsta.com/robots.txt.
Quand devriez-vous utiliser un fichier robots.txt ?
Pour la plupart des propriétaires de sites, les avantages d’un fichier robots.txt bien structuré se résument à deux catégories :
- Optimiser les ressources d’exploration des moteurs de recherche en leur indiquant de ne pas perdre de temps sur les pages que vous ne souhaitez pas voir indexées. Cela permet de s’assurer que les moteurs de recherche se concentrent sur l’exploration des pages qui vous intéressent le plus.
- Optimiser l’utilisation de votre serveur en bloquant les robots qui gaspillent des ressources.
Robots.txt n’est pas spécifiquement destiné à contrôler quelles pages sont indexées dans les moteurs de recherche
Robots.txt n’est pas un moyen infaillible de contrôler les pages indexées par les moteurs de recherche. Si votre objectif principal est d’empêcher certaines pages d’être incluses dans les résultats des moteurs de recherche, l’approche appropriée consiste à utiliser une balise meta noindex ou une protection par mot de passe.
En effet, votre fichier robots.txt n’indique pas directement aux moteurs de recherche de ne pas indexer le contenu, mais simplement de ne pas l’explorer. Bien que Google n’explore pas les zones marquées à l’intérieur de votre site, Google lui-même indique que si un site externe crée un lien vers une page que vous avez exclue avec votre fichier robots.txt, Google peut tout de même indexer cette page.
John Mueller, analyste des webmasters chez Google, a également confirmé que si une page comporte des liens pointant vers elle, même si elle est bloquée par le fichier robots.txt, elle peut tout de même être indexée. Vous trouverez ci-dessous ce qu’il a déclaré lors d’une séance de discussion avec la Webmaster Central :
Il faut peut-être garder à l’esprit que si ces pages sont bloquées par robots.txt, il est théoriquement possible que quelqu’un crée un lien au hasard vers l’une de ces pages. Et s’il le fait, il se peut que nous indexions cette URL sans aucun contenu parce qu’elle est bloquée par robots.txt. Nous ne saurions donc pas que vous ne souhaitez pas que ces pages soient indexées.
En revanche, si elles ne sont pas bloquées par robots.txt, vous pouvez placer une balise méta noindex sur ces pages. Si quelqu’un crée un lien vers ces pages, que nous explorons ce lien et que nous pensons qu’il peut être utile, nous saurons alors que ces pages n’ont pas besoin d’être indexées et nous pourrons les exclure complètement de l’indexation.
Donc, à cet égard, si vous avez quelque chose sur ces pages que vous ne voulez pas voir indexées, ne les désactivez pas, utilisez plutôt noindex.
Ai-je besoin d’un fichier robots.txt ?
Il est important de se rappeler que vous n’êtes pas obligé d’avoir un fichier robots.txt sur votre site. Si vous ne voyez pas d’inconvénient à ce que tous les robots puissent explorer librement toutes vos pages, vous pouvez choisir de ne pas vous embêter à en ajouter un, puisque vous n’avez pas de véritables instructions à donner aux robots.
Dans certains cas, vous ne pourrez même pas ajouter de fichier robots.txt en raison des limitations imposées par le CMS que vous utilisez. Ce n’est pas grave, et il existe d’autres méthodes pour indiquer aux robots comment explorer vos pages sans utiliser de fichier robots.txt.
Quel code d’état HTTP doit être renvoyé pour le fichier robots.txt ?
Le fichier robots.txt doit renvoyer un code d’état HTTP 200 OK pour que les robots d’exploration puissent y accéder.
Si vous avez des difficultés à faire indexer vos pages par les moteurs de recherche, il est utile de vérifier le code d’état renvoyé pour votre fichier robots.txt. Tout autre code d’état que 200 pourrait empêcher les robots d’accéder à votre site.
Certains propriétaires de sites ont signalé que des pages avaient été désindexées parce que leur fichier robots.txt renvoyait un code d’état autre que 200. Un propriétaire de site web a posé une question sur un problème d’indexation lors d’une séance de discussion sur le référencement Google en mars 2022 et John Mueller a expliqué que le fichier robots.txt devait renvoyer un état 200 s’il était présent, ou un état 4XX si le fichier n’existait pas. Dans le cas présent, une erreur de serveur interne 500 était renvoyée, ce qui, selon John Mueller, aurait pu conduire Googlebot à exclure le site de l’indexation.
Il en va de même dans ce tweet, où le propriétaire d’un site signale que son site entier a été désindexé en raison d’un fichier robots.txt renvoyant une erreur 500.
[Quick SEO tip]
If you are having issue with indexing, make sure your robots.txt file is returning either 200 or 404.
If your file returns 500, Google will eventually deindex your website, as I've seen with this project. pic.twitter.com/8KiYLgDVRo
— Antoine Eripret (@antoineripret) November 14, 2022
La balise méta robots peut-elle être utilisée à la place d’un fichier robots.txt ?
Non. La balise méta robots vous permet de contrôler les pages qui sont indexées, tandis que le fichier robots.txt vous permet de contrôler les pages qui sont explorées. Les robots doivent d’abord explorer les pages pour voir les balises méta. Vous devez donc éviter d’essayer d’utiliser à la fois une balise méta disallow et une balise méta noindex, car la balise noindex ne serait pas prise en compte.
Si votre objectif est d’exclure une page des moteurs de recherche, la balise méta noindex est généralement la meilleure option.
Comment créer et modifier votre fichier WordPress robots.txt ?
Par défaut, WordPress crée automatiquement un fichier robots.txt virtuel pour votre site. Ainsi, même si vous ne levez pas le petit doigt, votre site devrait déjà avoir le fichier robots.txt par défaut. Vous pouvez vérifier si c’est le cas en ajoutant « /robots.txt » à la fin de votre nom de domaine. Par exemple, « https://kinsta.com/robots.txt » affiche le fichier robots.txt que nous utilisons chez Kinsta.
Exemple de fichier robots.txt
Voici un exemple de fichier robots.txt de Kinsta :
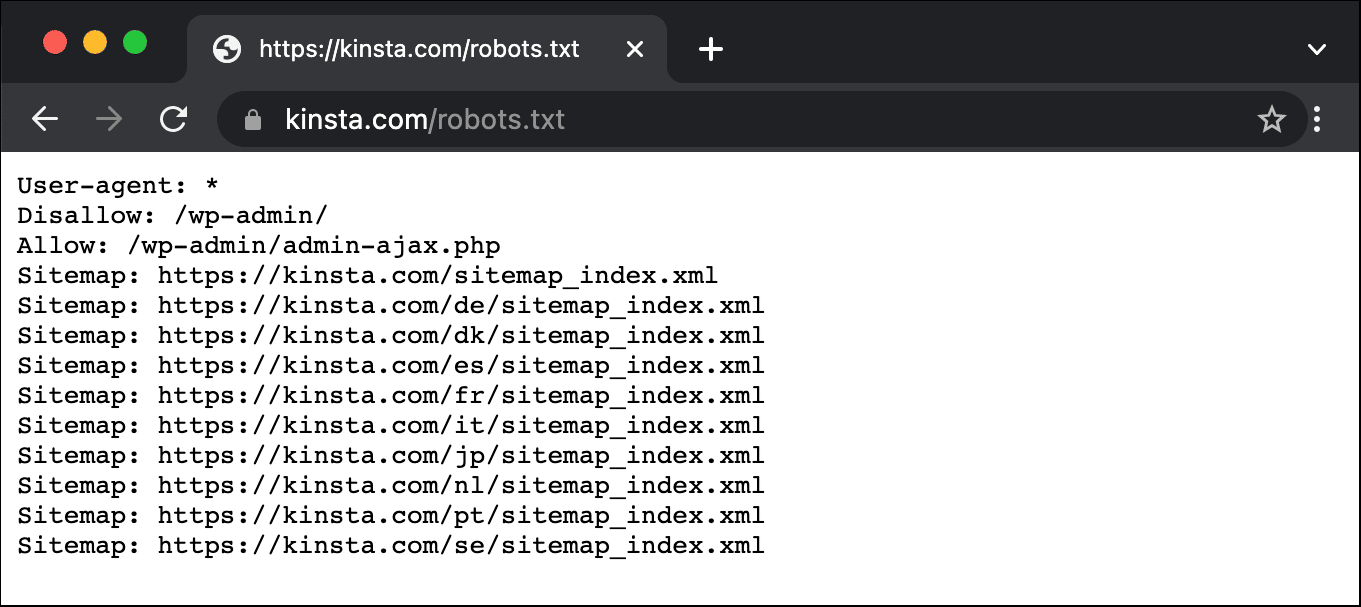
Ce fichier fournit à tous les robots des instructions sur les chemins à ignorer (par exemple le chemin wp-admin), avec toutes les exceptions (par exemple le fichier admin-ajax.php), ainsi que les emplacements du sitemap XML de Kinsta.
Ce fichier étant virtuel, vous ne pouvez pas le modifier. Si vous souhaitez modifier votre fichier robots.txt, vous devrez créer un fichier physique sur votre serveur que vous pourrez manipuler selon vos besoins. Voici trois méthodes simples pour y parvenir :
Comment créer et modifier un fichier robots.txt dans WordPress avec Yoast SEO
Si vous utilisez la célèbre extension Yoast SEO, vous pouvez créer (et plus tard modifier) votre fichier robots.txt directement depuis l’interface de Yoast. Avant de pouvoir y accéder, vous devez vous rendre dans SEO → Outils et cliquer sur Éditeur de fichiers
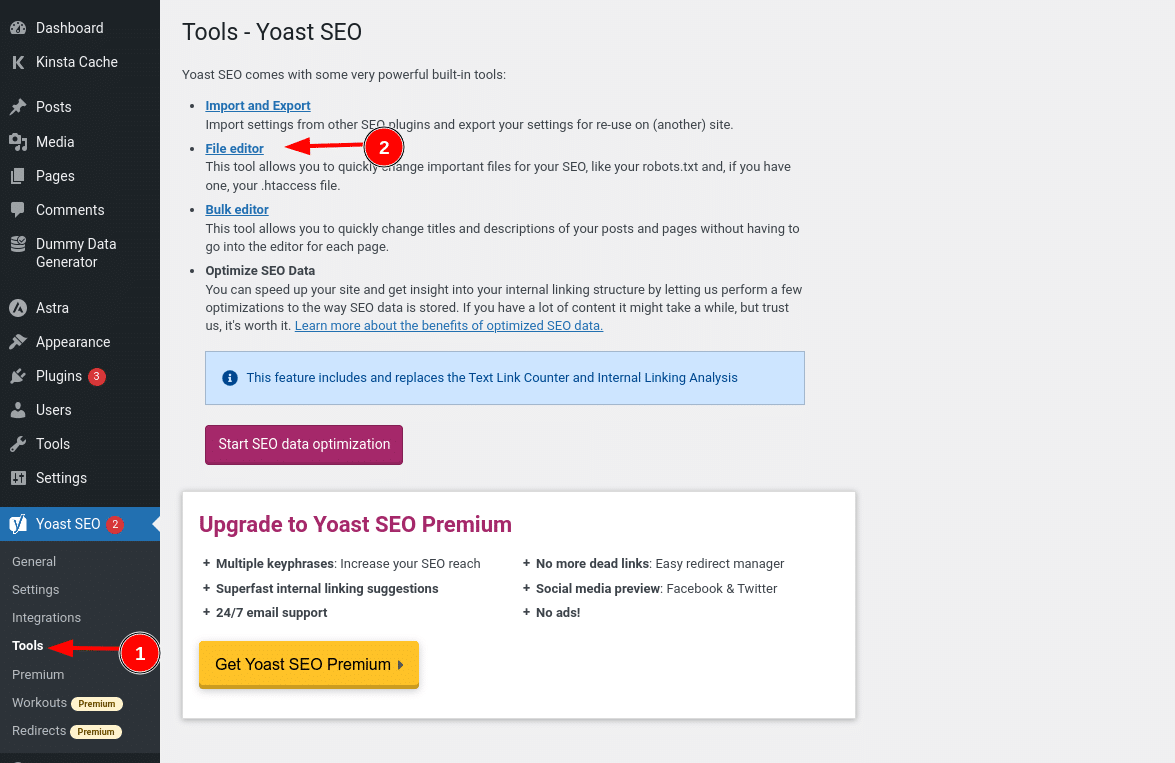
Une fois que vous aurez cliqué sur ce bouton, vous pourrez modifier le contenu de votre fichier robots.txt directement depuis la même interface, puis enregistrer les modifications apportées.
Si vous n’avez pas encore de fichier robots.txt physique, Yoast vous propose de créer un fichier robots.txt:
En lisant la suite, nous allons approfondir les types de directives à placer dans votre fichier robots.txt de WordPress.
Comment créer et modifier un fichier robots.txt avec All in One SEO
Si vous utilisez l’extension All in One SEO Pack, presque aussi populaire que Yoast, vous pouvez également créer et modifier votre fichier robots.txt WordPress directement depuis l’interface de l’extension. Tout ce que vous avez à faire est d’aller dans All in One SEO → Outils:
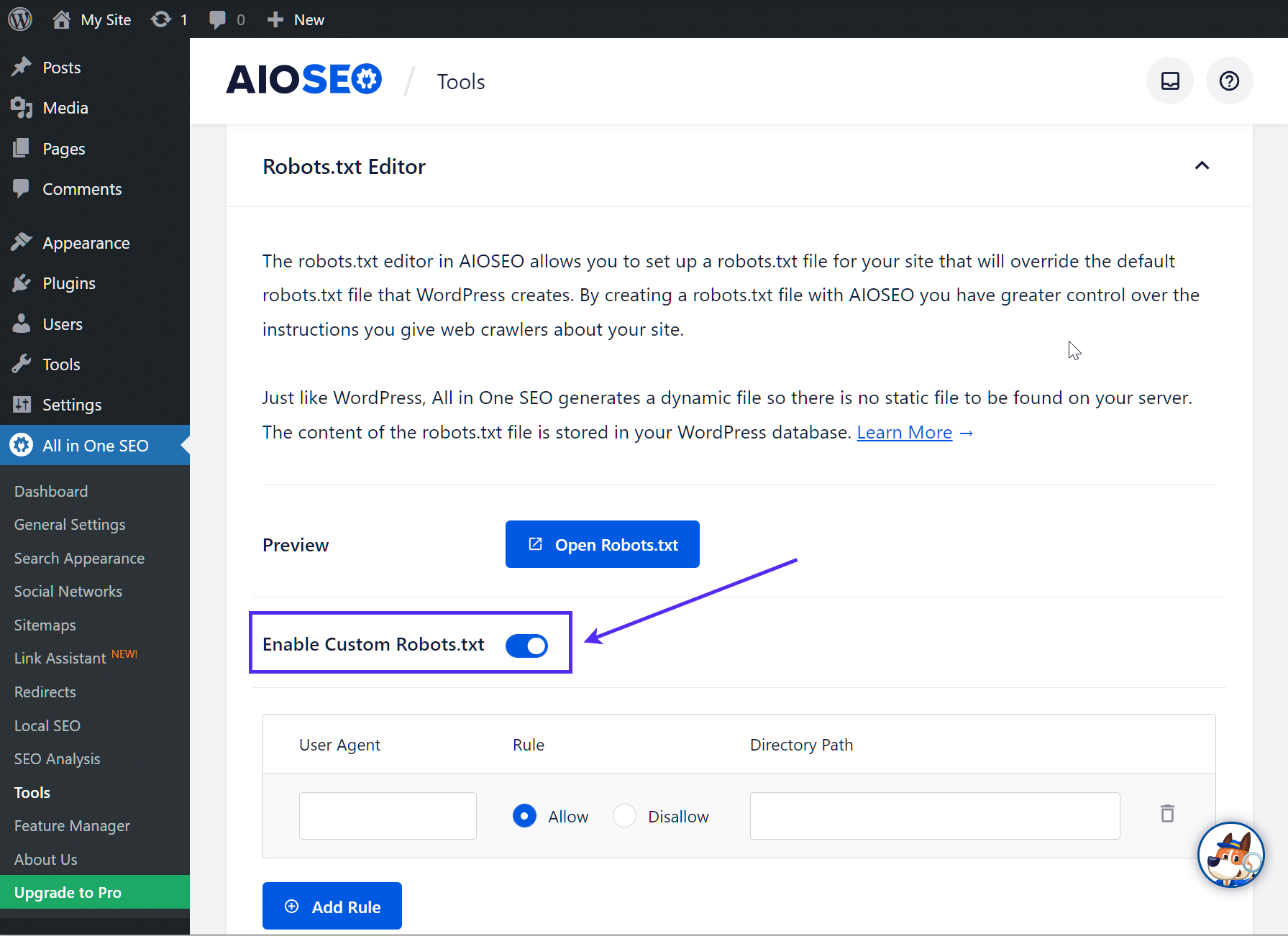
Ensuite, activez le bouton radio Activer robots.txt personnalisé. Cela vous permettra de créer des règles personnalisées et de les ajouter à votre fichier robots.txt :
Comment créer et modifier un fichier Robots.txt via FTP
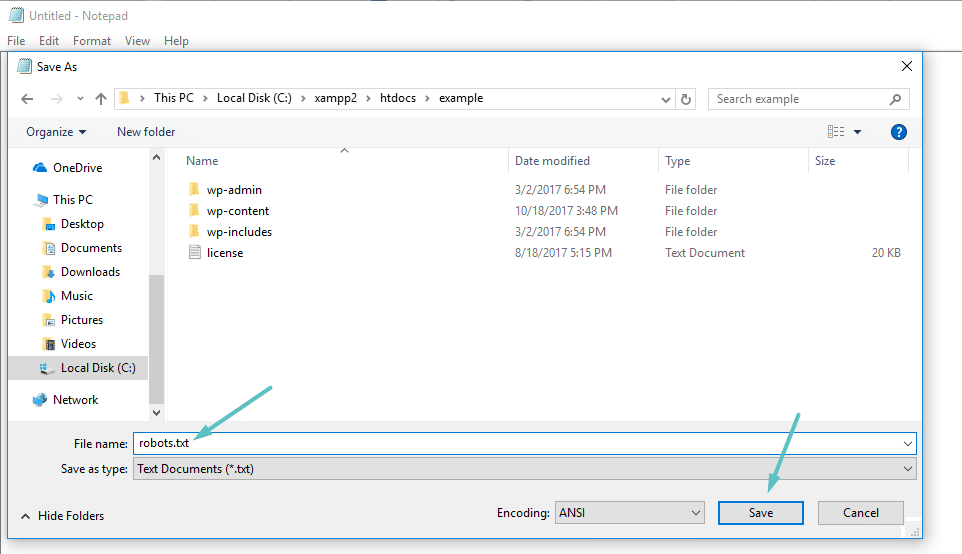
Si vous n’utilisez pas une extension de SEO qui offre la fonctionnalité robots.txt, vous pouvez toujours créer et gérer votre fichier robots.txt via SFTP. Tout d’abord, utilisez n’importe quel éditeur de texte pour créer un fichier vide nommé « robots.txt » :
Ensuite, connectez-vous à votre site via SFTP et téléchargez ce fichier dans le dossier racine de votre site. Vous pouvez apporter d’autres modifications à votre fichier robots.txt en l’éditant via SFTP ou en téléversant de nouvelles versions du fichier.
Que mettre dans votre fichier robots.txt ?
Vous disposez à présent d’un fichier robots.txt physique sur votre serveur, que vous pouvez modifier si nécessaire. Mais que faites-vous réellement avec ce fichier ? Comme vous l’avez appris dans la première section, le fichier robots.txt vous permet de contrôler la manière dont les robots interagissent avec votre site. Pour ce faire, vous disposez de deux commandes principales :
- User-agent – Cette commande vous permet de cibler des robots spécifiques. Les agents utilisateurs sont les éléments que les robots utilisent pour s’identifier. Grâce à eux, vous pouvez, par exemple, créer une règle qui s’applique à Bing, mais pas à Google.
- Disallow – Cette règle vous permet d’interdire aux robots d’accéder à certaines parties de votre site.
Il existe également une commande Allow que vous utiliserez dans des situations de niche. Par défaut, tout ce qui se trouve sur votre site est marqué par Allow, il n’est donc pas nécessaire d’utiliser la commande Allow dans 99 % des cas. Mais elle peut s’avérer utile lorsque vous souhaitez interdire l’accès à un dossier et à ses dossiers enfants, mais autoriser l’accès à un dossier enfant spécifique.
Vous ajoutez des règles en spécifiant d’abord l’agent utilisateur auquel la règle doit s’appliquer, puis en énumérant les règles à appliquer à l’aide des commandes Disallow et Allow. Il existe également d’autres commandes telles que Crawl-delay et Sitemap, mais elles ne sont pas obligatoires :
- Ignorées par la plupart des robots d’indexation, ou interprétées de manière très différente (dans le cas du délai d’indexation)
- Rendues redondantes par des outils tels que Google Search Console (pour les sitemaps)
Passons en revue quelques cas d’utilisation spécifiques pour vous montrer comment tout cela s’articule.
Comment utiliser robots.txt Disallow All pour bloquer l’accès à l’ensemble de votre site ?
Supposons que vous souhaitiez bloquer l’accès à votre site à tous les robots d’indexation. Il est peu probable que cela se produise sur un site en ligne, mais cela peut s’avérer utile pour un site en développement. Pour cela, vous devez ajouter le code robots.txt disallow all à votre fichier WordPress robots.txt :
User-agent: *
Disallow: /Que se passe-t-il dans ce code ?
L’astérisque à côté de User-agent signifie « tous les agents utilisateurs ». L’astérisque est un caractère générique, ce qui signifie qu’il s’applique à tous les agents utilisateurs. La barre oblique à côté de Disallow indique que vous voulez interdire l’accès à toutes les pages qui contiennent « yourdomain.com/ » (c’est-à-dire toutes les pages de votre site).
Comment utiliser robots.txt pour empêcher un seul robot d’accéder à votre site ?
Changeons les choses. Dans cet exemple, nous supposerons que vous n’aimez pas que Bing explore vos pages. Vous faites partie de l’équipe Google et ne voulez même pas que Bing consulte votre site. Pour empêcher uniquement Bing d’explorer votre site, vous devez remplacer le caractère générique *asterisque par Bingbot :
User-agent: Bingbot
Disallow: /En substance, le code ci-dessus indique qu’il ne faut appliquer la règle Disallow qu’aux robots dont l’agent utilisateur est « Bingbot ». Il est peu probable que vous souhaitiez bloquer l’accès à Bing, mais ce scénario peut s’avérer utile si vous ne souhaitez pas qu’un robot spécifique accède à votre site. Ce site contient une bonne liste des noms d’agents utilisateurs connus de la plupart des services.
Comment utiliser robots.txt pour bloquer l’accès à un dossier ou à un fichier spécifique ?
Pour cet exemple, disons que vous ne voulez bloquer l’accès qu’à un fichier ou dossier spécifique (et à tous les sous-dossiers de ce dossier). Pour que cela s’applique à WordPress, disons que vous voulez bloquer :
- L’ensemble du dossier wp-admin
- wp-login.php
Vous pouvez utiliser les commandes suivantes :
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpComment utiliser robots.txt Allow all pour donner aux robots un accès complet à votre site
Si vous n’avez actuellement aucune raison d’empêcher les robots d’accéder à vos pages, vous pouvez ajouter la commande suivante.
User-agent: *
Allow: /
Ou alternativement :
User-agent: *
Disallow:
Comment utiliser robots.txt pour autoriser l’accès à un fichier spécifique dans un dossier interdit ?
Imaginons que vous souhaitiez bloquer un dossier entier, mais que vous vouliez quand même autoriser l’accès à un fichier spécifique à l’intérieur de ce dossier. C’est là que la commande Allow s’avère très utile. Et elle s’applique parfaitement à WordPress. En fait, le fichier robots.txt virtuel de WordPress illustre parfaitement cet exemple :
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpCet extrait bloque l’accès à l’ensemble du dossier /wp-admin/, à l’exception du fichier /wp-admin/admin-ajax.php.
Comment utiliser robots.txt pour empêcher les robots d’explorer les résultats de recherche de WordPress ?
Une modification spécifique à WordPress que vous pourriez vouloir faire est d’empêcher les robots de recherche d’explorer vos pages de résultats de recherche. Par défaut, WordPress utilise le paramètre de requête « ?s= ». Ainsi, pour bloquer l’accès, tout ce que vous avez à faire est d’ajouter la règle suivante :
User-agent: *
Disallow: /?s=
Disallow: /search/Cela peut être un moyen efficace d’arrêter les erreurs 404 si vous en obtenez. Assurez-vous de lire notre guide approfondi sur la façon d’accélérer la recherche sur WordPress.
Comment créer des règles différentes pour différents robots dans robots.txt ?
Jusqu’à présent, tous les exemples ont traité d’une règle à la fois. Mais qu’en est-il si vous souhaitez appliquer différentes règles à différents robots ? Il vous suffit d’ajouter chaque ensemble de règles sous la déclaration User-agent de chaque robot. Par exemple, si vous voulez créer une règle qui s’applique à tous les robots et une autre qui s’applique uniquement à Bingbot, vous pouvez procéder comme suit :
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /Dans cet exemple, tous les robots seront empêchés d’accéder à /wp-admin/, mais Bingbot sera empêché d’accéder à l’ensemble de votre site.
Test de votre fichier robots.txt
Pour vous assurer que votre fichier robots.txt a été correctement configuré et qu’il fonctionne comme prévu, vous devez le tester minutieusement. Un seul caractère mal placé peut être catastrophique pour les performances d’un site dans les moteurs de recherche, c’est pourquoi les tests permettent d’éviter les problèmes potentiels.
Testeur de robots.txt de Google
L’outil robots.txt Tester de Google (qui faisait auparavant partie de Google Search Console) est facile à utiliser et met en évidence les problèmes potentiels dans votre fichier robots.txt.
Il vous suffit de vous rendre sur l’outil et de sélectionner la propriété du site que vous souhaitez tester, puis de faire défiler la page jusqu’en bas et d’entrer une URL dans le champ, avant de cliquer sur le bouton rouge TEST :
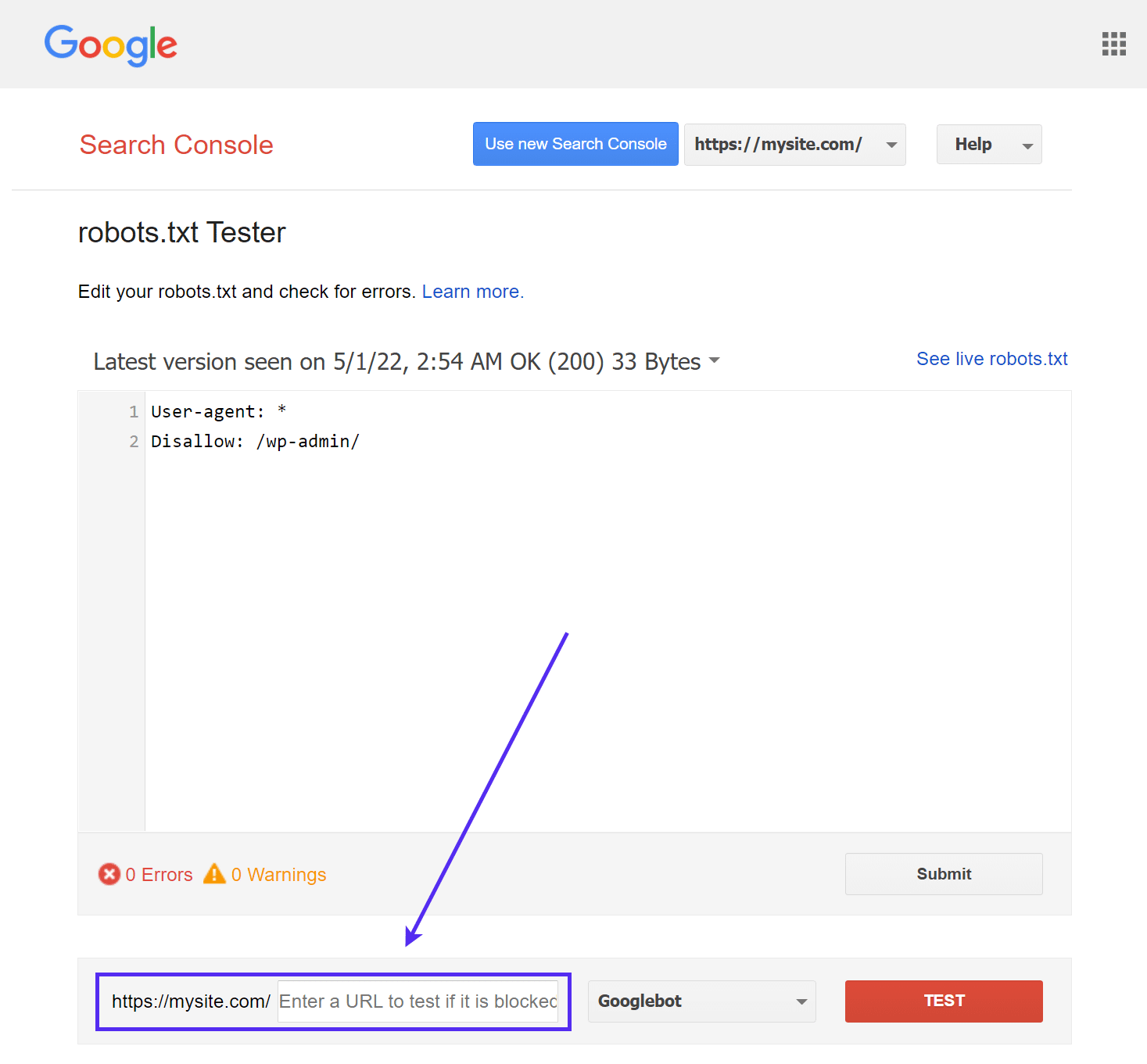
Vous verrez une réponse verte « Autorisé » si tout est crawlable.
Vous pouvez également sélectionner la version de Googlebot avec laquelle vous souhaitez effectuer le test : Googlebot, Googlebot-News, Googlebot-Image, Googlebot-Video, Googlebot-Mobile, Mediapartners-Google ou Adsbot-Google.
Vous pouvez également tester chaque URL que vous avez bloquée pour vous assurer qu’elle est effectivement bloquée et/ou interdite.
Méfiez-vous du BOM UTF-8
BOM signifie byte order mark et est en fait un caractère invisible qui est parfois ajouté aux fichiers par les anciens éditeurs de texte et autres. Si cela se produit dans votre fichier robots.txt, Google risque de ne pas le lire correctement. C’est pourquoi il est important de vérifier que votre fichier ne contient pas d’erreurs. Par exemple, comme on peut le voir ci-dessous, notre fichier contient un caractère invisible et Google se plaint que la syntaxe n’est pas comprise. La première ligne de notre fichier robots.txt est donc complètement invalidée, ce qui n’est pas une bonne chose ! Glenn Gabe a publié un excellent article sur la façon dont un UTF-8 Bom pourrait anéantir votre référencement.

Googlebot est principalement basé aux États-Unis
Il est également important de ne pas bloquer le Googlebot des États-Unis, même si vous ciblez une région locale en dehors des États-Unis. Ils font parfois de l’exploration locale, mais le Googlebot est principalement basé aux États-Unis.
Googlebot is mostly US-based, but we also sometimes do local crawling. https://t.co/9KnmN4yXpe
— Google Search Central (@googlesearchc) November 13, 2017
Ce que les sites WordPress populaires mettent dans leur fichier Robots.txt
Pour mettre en contexte les points énumérés ci-dessus, voici comment certains des sites WordPress les plus populaires utilisent leurs fichiers robots.txt.
TechCrunch
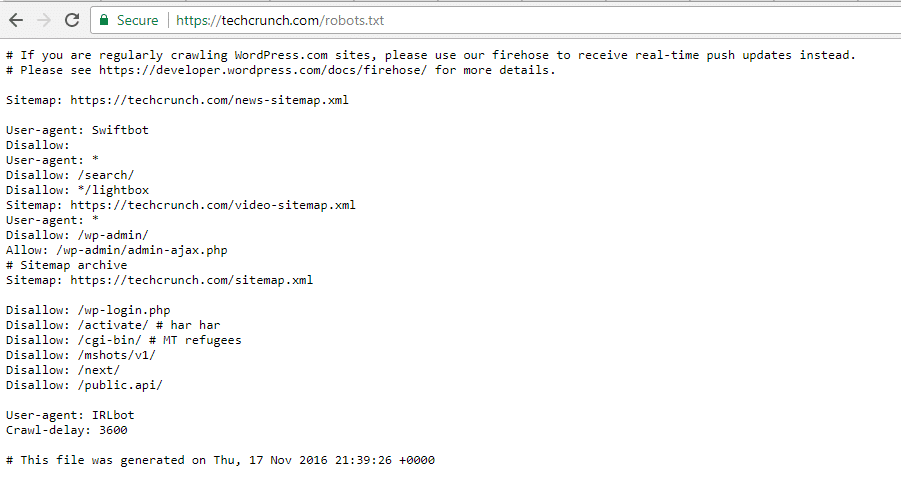
En plus de restreindre l’accès à un certain nombre de pages uniques, TechCrunch interdit notamment aux robots d’explorer :
- /wp-admin/
- /wp-login.php
Des restrictions particulières ont également été imposées à deux robots :
- Swiftbot
- IRLbot
Au cas où cela vous intéresserait, IRLbot est un crawler issu d’un projet de recherche de l’université A&M du Texas. C’est bizarre !
La Fondation Obama
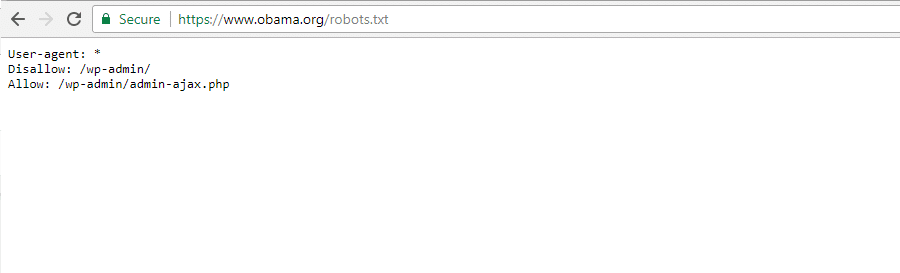
La Fondation Obama n’a pas fait d’ajouts particuliers, choisissant uniquement de restreindre l’accès à /wp-admin/.
Angry Birds
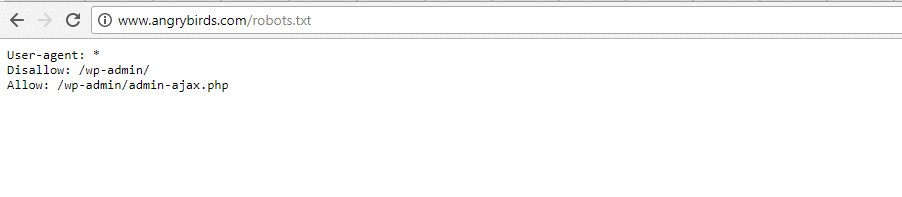
Angry Birds a la même configuration par défaut que la Fondation Obama. Rien de spécial n’est ajouté.
Drift

Enfin, Drift choisit de définir ses sitemaps dans le fichier Robots.txt, mais sinon, il laisse les mêmes restrictions par défaut que la Fondation Obama et Angry Birds.
Utilisez robots.txt de la bonne manière
En conclusion de notre guide sur les robots.txt, nous souhaitons vous rappeler une fois de plus que l’utilisation d’une commande Disallow dans votre fichier robots.txt n’est pas la même chose que l’utilisation d’une balise noindex . Le fichier robots.txt bloque l’exploration, mais pas nécessairement l’indexation. Vous pouvez l’utiliser pour ajouter des règles spécifiques afin de déterminer comment les moteurs de recherche et autres robots interagissent avec votre site, mais il ne contrôlera pas explicitement si votre contenu est indexé ou non.
Pour la plupart des utilisateurs occasionnels de WordPress, il n’est pas urgent de modifier le fichier robots.txt virtuel par défaut. Mais si vous rencontrez des problèmes avec un robot spécifique, ou si vous souhaitez modifier la façon dont les moteurs de recherche interagissent avec un certain plugin ou thème que vous utilisez, vous pouvez ajouter vos propres règles.
Nous espérons que vous avez apprécié ce guide et n’hésitez pas à laisser un commentaire si vous avez d’autres questions sur l’utilisation du fichier robots.txt de WordPress.

Brian a une grande passion pour WordPress, l'utilise depuis plus de dix ans et développe même quelques plugins de qualité. Brian aime les blogs, les films et les randonnées. Connectez avec Brian sur Twitter.

