
I problemi di scalabilità raramente appaiono dal nulla. Di solito si sviluppano silenziosamente fino a quando il lancio di una campagna, un picco di traffico, dei saldi stagionali o un’esperienza di checkout lenta costringono tutti a prestare attenzione.
Alcuni team ottimizzano in anticipo sulla base di ipotesi. Altri aspettano che i rallentamenti, i reclami o l’aumento dei costi rendano inevitabile un intervento. Entrambi gli approcci comportano dei rischi. Uno può sprecare budget. L’altro può lasciare il tuo sito impreparato quando arriva il momento della crescita.
Le analisi dei dati offrono ai team un modo migliore per decidere quando agire. In questo articolo ti spieghiamo come le analisi possono essere utilizzate come strumento di pianificazione per rivelare soglie, vincoli e modelli di utilizzo prima che diventino problemi più gravi.
Perché le decisioni di scalabilità spesso vengono prese troppo tardi
Le decisioni di scalare spesso avvengono nel momento peggiore, dopo che qualcosa ha già iniziato a rompersi.
Un sito rallenta durante una campagna. Il flusso di pagamento inizia a ritardare durante i picchi di traffico. I team interni iniziano a segnalare problemi che non riescono a spiegare completamente. Quello che poteva essere un aggiustamento pianificato si trasforma in una soluzione urgente da un giorno all’altro.
Questo modello reattivo è comune perché molti team non hanno una visione chiara di quando la loro infrastruttura si sta avvicinando ai suoi limiti. Possono vedere un aumento del traffico, ma non capire come questa crescita influisca sulle risorse del server, sulle prestazioni della cache, sulla larghezza di banda o sull’attività del database. Quindi aspettano che i segnali diventino impossibili da ignorare.
Succede anche il contrario. Alcuni team effettuano l’upgrade in anticipo perché preoccupati della crescita futura, anche quando i dati non mostrano una pressione costante. Questo porta a spese inutili, soprattutto quando il vero problema avrebbe potuto essere risolto con una migliore cache, una pulizia del codice o una modifica del flusso di lavoro.
Lo scaling reattivo crea diversi problemi che rendono la crescita più difficile da gestire:
Le decisioni vengono prese sotto pressione
Quando lo scaling è innescato da un rallentamento, un’interruzione o un picco di traffico, i team sono costretti a diagnosticare i problemi mentre l’azienda sta già subendo l’impatto. Questa pressione porta a scelte affrettate e a soluzioni temporanee che non affrontano la vera causa.
La pianificazione diventa una congettura
Invece di utilizzare le tendenze per guidare i budget e le tempistiche, i team legano le decisioni sull’infrastruttura alle emergenze. In questo modo è più difficile prevedere quando la capacità sarà necessaria o giustificare i costi.
La fiducia si riduce con il passare del tempo
Quando ogni decisione di scaling sembra urgente, i team iniziano a mettere in dubbio il proprio giudizio. Non sanno se hanno agito troppo tardi, troppo presto o per il motivo sbagliato. Con il passare del tempo, l’infrastruttura inizia a sembrare un rischio ricorrente anziché qualcosa che si può controllare.
I report raccontano cosa è successo, ma le analisi operative suggeriscono cosa fare dopo
La maggior parte dei team ha già accesso alla reportistica. Possono vedere le tendenze del traffico, le pagine viste, le conversioni e le fonti di riferimento. Queste informazioni sono utili, ma raccontano solo una parte della storia.
La reportistica di superficie mostra i risultati. Ti dice quante persone hanno visitato il sito, cosa hanno fatto e se hanno convertito. Quello che non mostra è come la tua infrastruttura ha gestito l’attività dietro le quinte. Questa lacuna è sempre più importante con la crescita dell’azienda.
Un picco di traffico può sembrare una vittoria in una dashboard di reportistica, ma non spiega se il tuo server era sotto sforzo, se i thread PHP erano al massimo o se la cache ha mantenuto le cose in ordine. Due siti possono registrare lo stesso aumento di visite e avere prestazioni completamente diverse a seconda di come vengono utilizzate le loro risorse.
L’analisi operativa offre uno sguardo più approfondito. Invece di concentrarsi solo sui risultati, mostra cosa succede sotto la superficie. I team possono vedere come vengono gestite le richieste, come vengono utilizzate le risorse e dove inizia a crearsi la pressione. Metriche come l’utilizzo della larghezza di banda, l’efficienza della cache, l’attività dei thread PHP e il comportamento di risposta forniscono ai team un quadro più chiaro di come la loro infrastruttura gestisce la domanda del mondo reale.
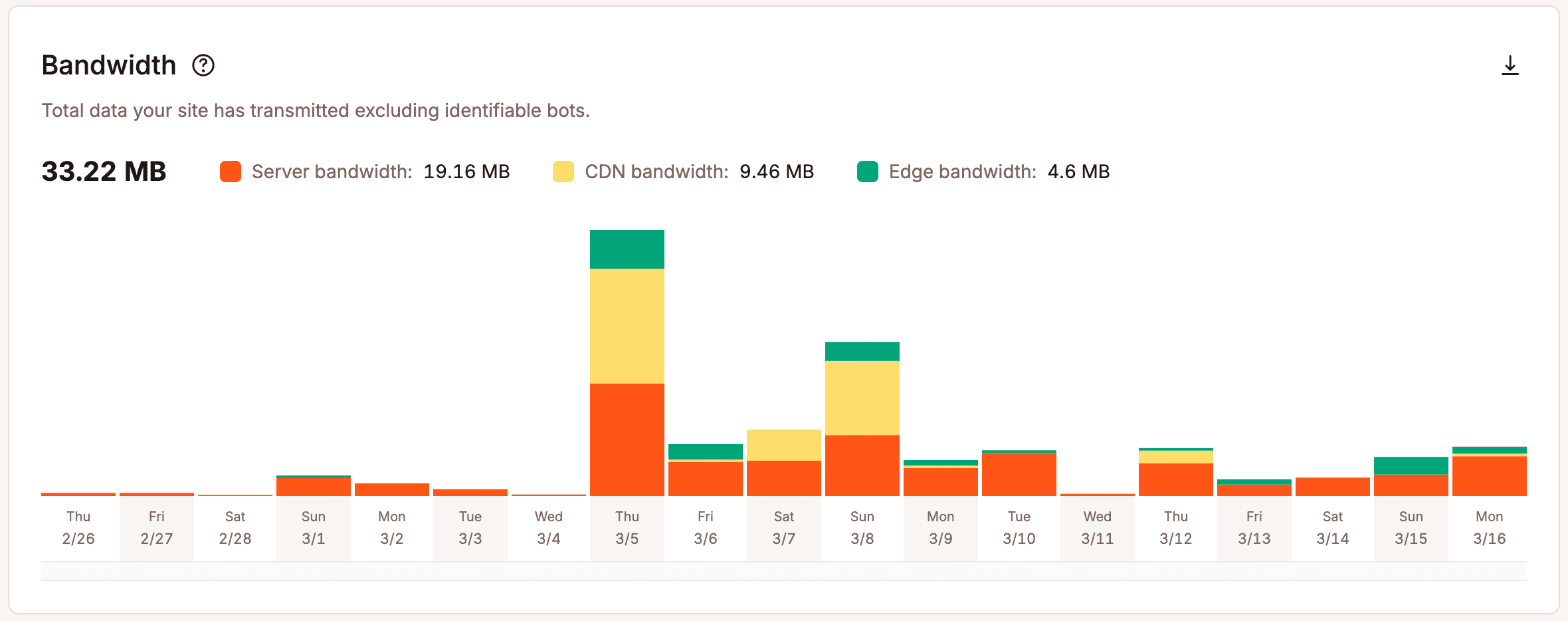
Senza questa visibilità, le decisioni sul ridimensionamento diventano soggettive. I team reagiscono a incidenti isolati, si affidano all’istinto o pianificano gli scenari peggiori senza sapere quanto siano probabili.
I segnali che indicano che è arrivato il momento di ottimizzare o scalare
La vera domanda non è: “Possiamo rendere il sito più veloce?”; la maggior parte dei team riesce sempre a trovare qualcosa da mettere a punto, pulire o migliorare.
La domanda migliore è: “Cosa ci dicono i dati per il prossimo passo?”.
I dati analitici aiutano i team a distinguere tra un problema temporaneo e un vero problema di capacità. Invece di agire sulla base di una preoccupazione vaga, possono osservare i segnali misurabili che mostrano quando l’ottimizzazione o il ridimensionamento necessitano di attenzione.
Tendenze del traffico che continuano a salire
Un singolo picco di traffico non sempre significa che un sito ha bisogno di maggiori risorse. Può derivare da una campagna e-mail unica, da una menzione sui social, da un successo di pubbliche relazioni o da un evento stagionale. Questi momenti meritano di essere analizzati, ma non sempre indicano una necessità di scalare a lungo termine.
Una crescita sostenuta racconta una storia diversa. Se le visite, le richieste o le attività di accesso continuano ad aumentare nel tempo, la tua configurazione attuale potrebbe richiedere un’analisi più approfondita. Gli aumenti ripetuti possono aumentare gradualmente la pressione sulle risorse del server, sull’attività del database, sui livelli di caching e sulla larghezza di banda.
I dati sulle tendenze aiutano i team a pianificare il futuro. Quando vedono il traffico aumentare mese dopo mese, possono testare le prestazioni, identificare i punti deboli e apportare miglioramenti prima che la crescita rallenti.
Modelli di utilizzo delle risorse che indicano una tensione
Il traffico da solo non mostra quanto il tuo sito lavori. Anche un numero modesto di visitatori può affaticare il sito quando le pagine dinamiche, le query pesanti al database, la cache debole o i processi in background consumano risorse eccessive.
Le analisi a livello di hosting mostrano dove si accumula la pressione. I team possono esaminare l’utilizzo dei thread PHP, il consumo di banda, le percentuali di hit e miss della cache, l’attività del database, i codici di risposta e il volume delle richieste.
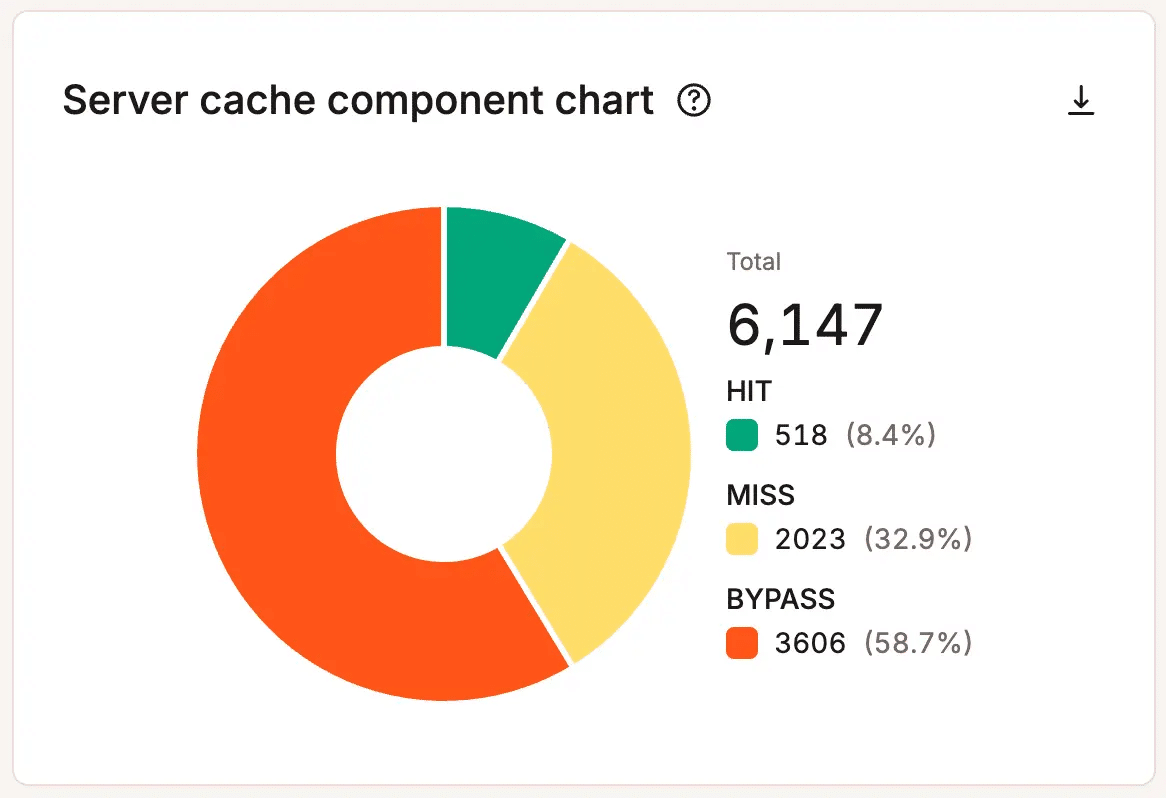
Cerca gli schemi, non i picchi singoli. Un breve picco di thread PHP durante un’ora di punta potrebbe non essere importante. Ma picchi ripetuti, richieste crescenti di larghezza di banda o prestazioni della cache costantemente scarse possono indicare che il tuo sito ha bisogno di un’ottimizzazione, di una revisione del flusso di lavoro o di una maggiore capacità.
Problemi di prestazioni che si manifestano in condizioni specifiche
Alcuni problemi di prestazioni si manifestano solo quando il sito è sotto pressione. Un sito può risultare veloce in un giorno normale e poi rallentare durante il lancio di un prodotto, un raccolta fondi, un periodo di iscrizione, i saldi del Black Friday o una campagna di contenuti importante.
Questi momenti spesso rivelano i veri limiti della tua configurazione attuale.
Le analisi aiutano i team a determinare se il problema è temporaneo, ricorrente o destinato a peggiorare. Se le prestazioni calano solo durante i rari picchi di traffico, il team potrebbe dover migliorare la preparazione della campagna. Se i rallentamenti si verificano ogni volta che la domanda aumenta, è probabile che il sito abbia bisogno di un’ottimizzazione più profonda o di una configurazione di hosting più scalabile.
Errori e anomalie che si trasformano in segnali di allarme precoci
Errori, richieste fallite e attività insolite possono mettere in guardia i team prima che i visitatori ne avvertano l’impatto.
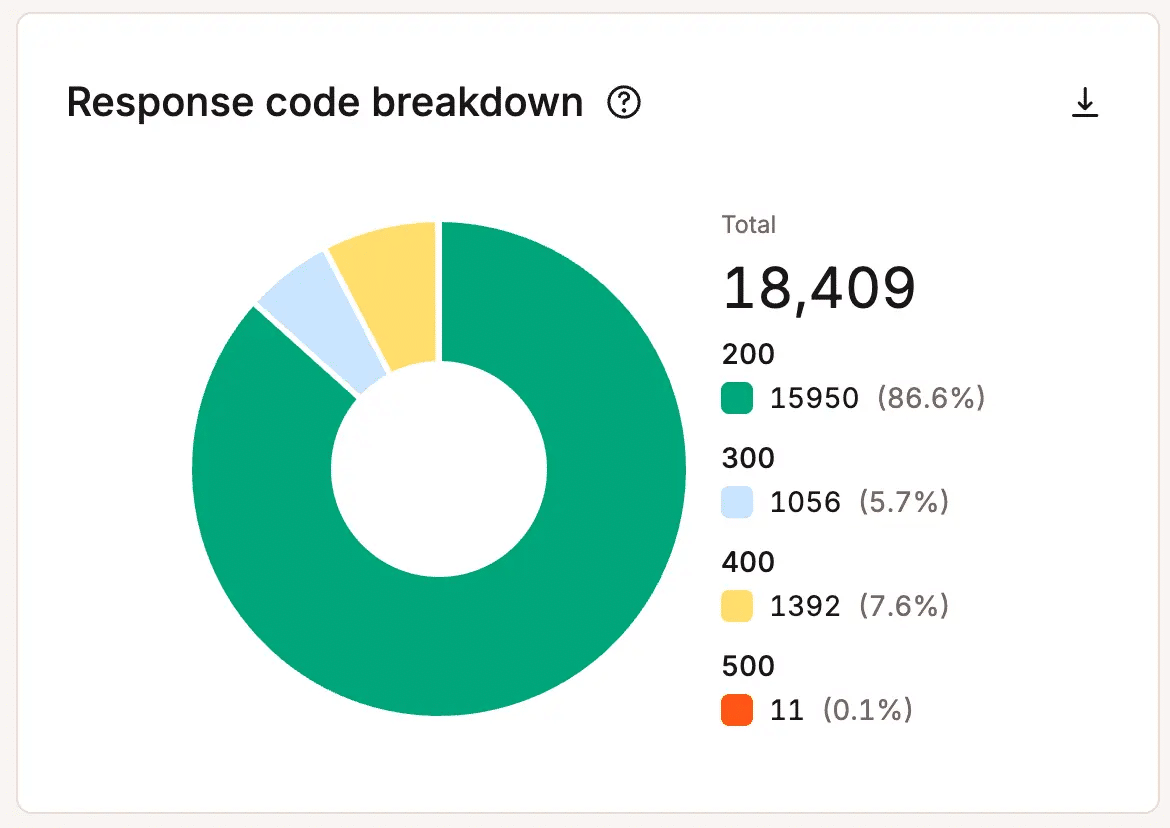
L’aumento dei tassi di errore può indicare una tensione dell’infrastruttura, problemi di applicazione, colli di bottiglia delle risorse o processi non funzionanti. Un andamento insolito del traffico può rivelare la presenza di bot, richieste abusive o picchi di domanda inaspettati che utilizzano le risorse senza creare valore per l’azienda.
Questi segnali danno ai team la possibilità di agire tempestivamente. Quando vedono errori e anomalie nel contesto, possono indagare sulla causa, ridurre le tensioni inutili e proteggere l’esperienza del cliente prima che i piccoli segnali di allarme si trasformino in problemi visibili.
Come i dati analitici supportano decisioni di scalabilità più intelligenti
I dati analitici aiutano i team a passare dal “qualcosa non quadra” al “ecco cosa mostrano i dati”. Questo passaggio rende le decisioni di scaling più pratiche, meno reattive e più facili da difendere.
Inoltre, aiutano i team a scegliere il giusto passo successivo. Non tutti i rallentamenti o i picchi richiedono un piano di hosting più grande. A volte l’ottimizzazione ha più senso. Altre volte i dati indicano un problema di flusso di lavoro, un processo che richiede molte risorse o una modifica più ampia dell’infrastruttura.
Sapere se ottimizzare prima di aggiornare
Una maggiore capacità non è sempre la prima mossa migliore. Se l’analisi mostra una scarsa efficienza della cache, richieste insolitamente pesanti, codice inefficiente o attività in background che richiedono molte risorse, il team può migliorare le prestazioni prima di cambiare i piani.
Ciò può significare affinare le regole di cache, ripulire i plugin o il codice personalizzato, rivedere le query del database o regolare i processi che creano un carico evitabile. In questi casi, l’analisi aiuta i team a evitare di pagare per una maggiore capacità quando una migliore efficienza risolve il problema.
Sapere quando un aggiornamento è giustificato
A un certo punto, l’ottimizzazione potrebbe non essere sufficiente. Se i dati mostrano una pressione costante sulle risorse, rallentamenti ricorrenti durante la normale crescita, aumento delle esigenze di larghezza di banda o chiari limiti di utilizzo, il team può giustificare più facilmente un upgrade.
Ad esempio, il grafico sottostante mostra che questo sito ha raggiunto il numero massimo di thread PHP allocati, 69, 69 volte in meno di 30 giorni.
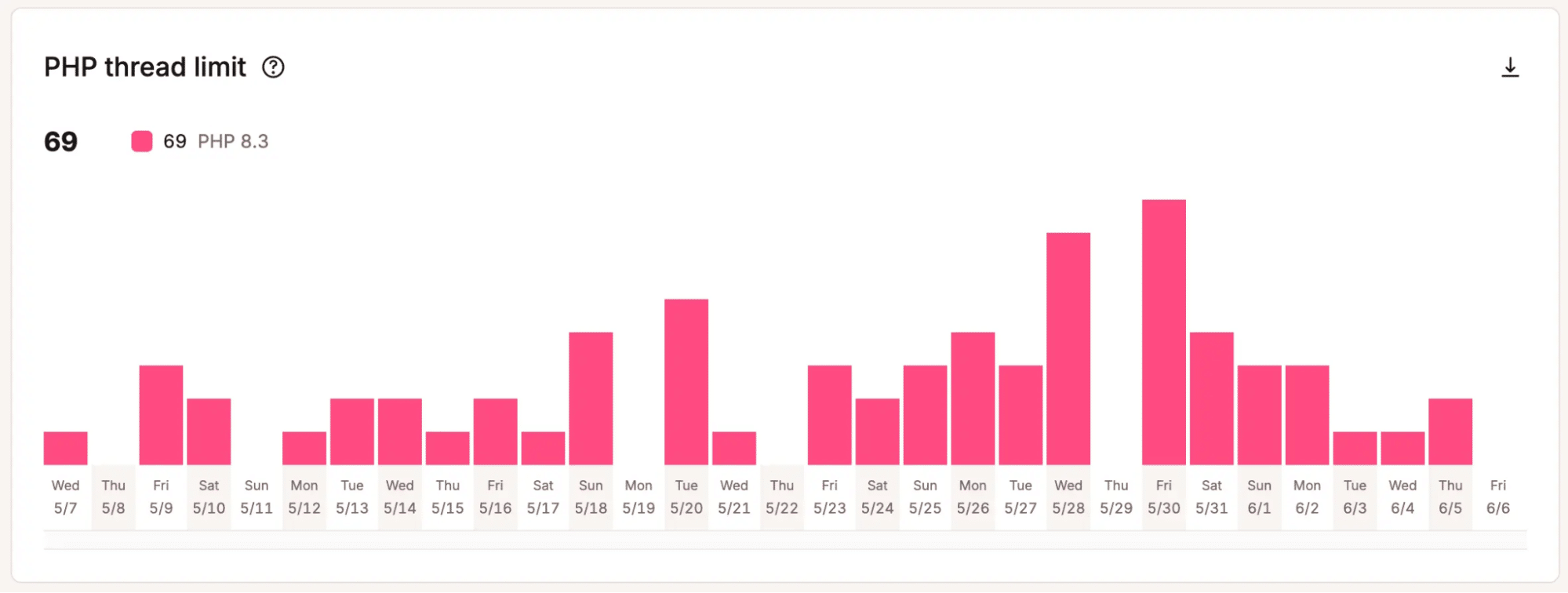
Questo è importante quando i team devono decidere se la capacità aggiuntiva vale il costo. Invece di affidarsi a un’intuizione, possono indicare gli schemi che dimostrano che la configurazione attuale sta raggiungendo i suoi limiti.
Saper spiegare la decisione internamente
Le decisioni di scalare raramente rimangono all’interno del team tecnico. La leadership, il team finance, i reparti marketing e operations vogliono capire perché il cambiamento è importante e perché ora.
I dati analitici aiutano i team a costruire un chiaro business case. Invece di basarsi sulle opinioni, possono puntare su dati reali e collegare la spesa per l’infrastruttura all’affidabilità del sito, alla prontezza delle campagne, all’esperienza dei clienti e alla protezione dei ricavi. Questo sposta la conversazione dalle preferenze tecniche ai rischi misurabili, ai tempi e all’impatto previsto.
Perché l’hosting reattivo rende più difficile la scalabilità
L’hosting reattivo rende la crescita più difficile da gestire perché i team non vedono i limiti fino a quando non ne sentono l’impatto.
Molti ambienti di hosting offrono ai team solo una visione limitata delle soglie di capacità effettive. I team possono conoscere i limiti del loro piano, ma non sempre riescono a capire quanto il sito sia vicino alla soglia o quali siano le parti dello stack che creano maggiore pressione.
Questo crea uno schema frustrante. Il sito rallenta, una campagna non funziona bene o iniziano ad arrivare ticket di assistenza. Il team indaga, contatta l’host e prende in considerazione un aggiornamento dopo che il problema ha già avuto ripercussioni sull’azienda.
Questo modello aggiunge incertezza. Rende l’infrastruttura più difficile da prevedere, giustificare e fidarsi. Per i team in crescita, questa mancanza di chiarezza trasforma lo scaling in una reazione invece che in una parte pianificata della crescita.
Come Kinsta aiuta i team a scalare con maggiore sicurezza
Kinsta offre ai team una visione più chiara delle prestazioni dei loro siti WordPress in presenza di una domanda reale. Con le Statistiche di MyKinsta, i team possono monitorare i modelli di traffico, l’utilizzo delle risorse, i segnali di performance e i punti di pressione emergenti senza trattare l’hosting come una scatola nera.
Questa visibilità rende lo scaling meno reattivo. I team individuano prima le tendenze, pianificano la crescita con maggiore sicurezza e prendono decisioni sull’infrastruttura basate su dati reali.
Dati che rivelano i vincoli reali
Kinsta aiuta i team a capire dove iniziano a emergere i limiti. Le statistiche di MyKinsta mostrano segnali come le tendenze del traffico, l’utilizzo della larghezza di banda, le prestazioni della cache, i codici di risposta e l’attività delle risorse, dando ai team una visione più pratica di come il loro sito gestisce la domanda.
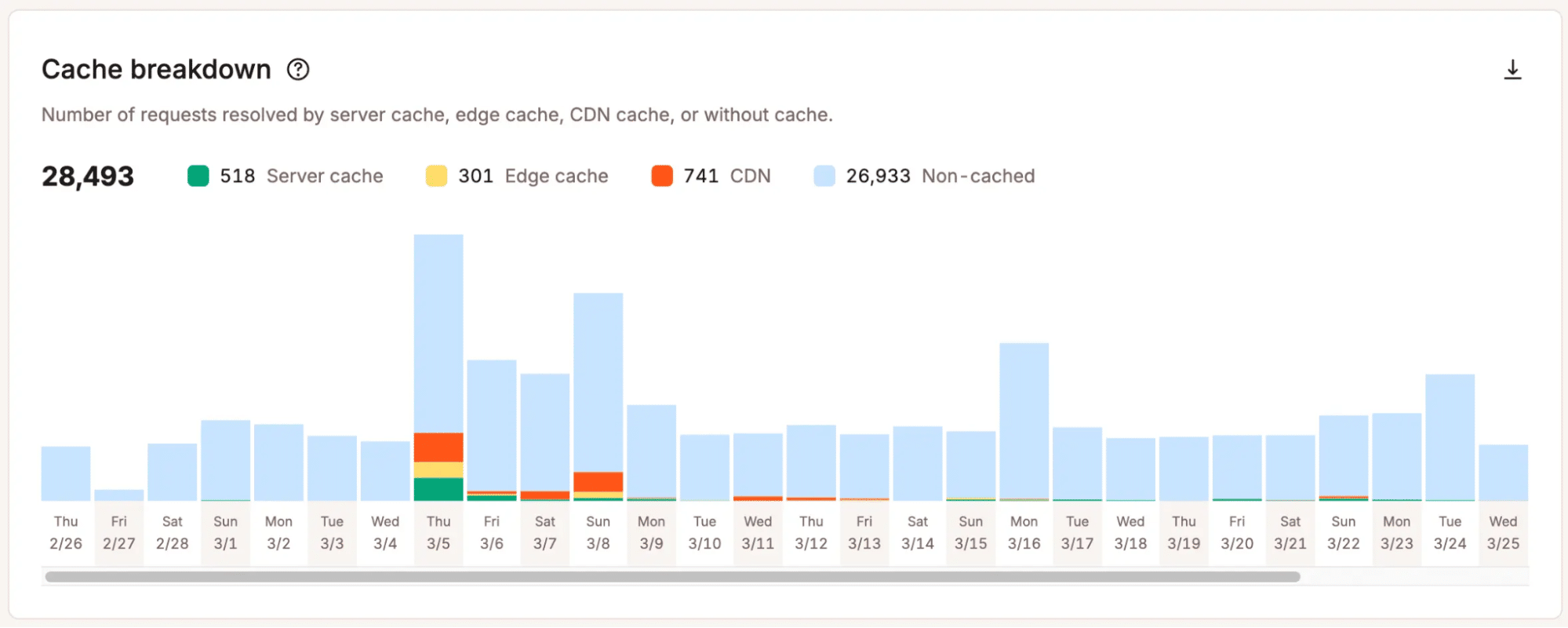
Questa chiarezza è importante perché le decisioni di scalabilità non devono dipendere da ipotesi vaghe. Quando i team vedono dove si accumula la pressione, possono decidere se ottimizzare, modificare il piano o approfondire la questione tecnica.
Una piattaforma costruita per prendere decisioni informate
La crescita spesso porta con sé questioni di budget, pianificazione dei lanci e pressione per giustificare le nuove spese. Kinsta supporta queste conversazioni con dati più chiari sull’utilizzo e le prestazioni del sito.
In questo modo la pianificazione dell’infrastruttura è più facile da spiegare. Invece di chiedere più capacità perché il sito “sembra lento”, i team possono collegare la decisione a tendenze misurabili, a sollecitazioni ricorrenti o a esigenze di crescita specifiche.
La prevedibilità come vantaggio per la crescita
La scalabilità è meno stressante quando i team vedono cosa sta cambiando prima che diventi urgente. Con una migliore visibilità dei modelli di utilizzo e dei segnali di performance, i team possono prepararsi alle campagne, alla domanda stagionale e alla crescita a lungo termine con maggiore sicurezza.
Questa prevedibilità offre alle aziende una piattaforma di hosting che possono comprendere, su cui possono basare la propria pianificazione e di cui possono fidarsi man mano che la loro attività cresce.
Smetti di trattare l’analisi dei dati come un add-on della reportistica
L’analisi dei dati è sfruttata al meglio quando modella il modo in cui si pianifica, non solo quando si esaminano le prestazioni a posteriori.
Quando puoi vedere le tendenze, gli schemi di utilizzo e i primi segnali di stress, puoi pianificare meglio le decisioni di scaling e giustificarle in modo più chiaro. Non dovrai più tirare a indovinare quando agire o reagire sotto pressione. Potrai fare scelte consapevoli basate su ciò che il tuo sito fa realmente.
In questo modo la crescita è più prevedibile e meno stressante.
Fai un giro su MyKinsta per capire meglio i tuoi modelli di utilizzo, i segnali di performance e le esigenze di scalabilità prima che diventino urgenti.


