
Sia MySQL che MariaDB sfruttano perfettamente l’efficienza dell’indicizzazione ad albero bilanciato (B-Tree) per ottimizzare le operazioni sui dati. Questo meccanismo di indicizzazione condivisa garantisce un rapido recupero dei dati, migliora le prestazioni delle query e riduce al minimo l’input/output (I/O) su disco, contribuendo a un’esperienza di database più reattiva ed efficiente.
Questo articolo analizza più da vicino l’indicizzazione, funge da guida nella creazione degli indici e condivide i consigli per utilizzarli in modo più efficace nei database MySQL e MariaDB.
Che cos’è un indice?
Quando interroghiamo un database MySQL per ottenere informazioni specifiche, la query cerca ogni riga di una tabella del database finché non trova quella giusta. Questa operazione può richiedere molto tempo, soprattutto nei casi in cui il database è molto esteso.
I gestori di database utilizzano l’indicizzazione per accelerare i processi di recupero dei dati e ottimizzare l’efficienza delle query. L’indicizzazione crea una struttura di dati che riduce al minimo la quantità di dati da ricercare, organizzandoli in modo sistematico e rendendo l’esecuzione delle query più rapida ed efficace.
Supponiamo di voler trovare un cliente il cui nome è Ava nella seguente tabella Customer:
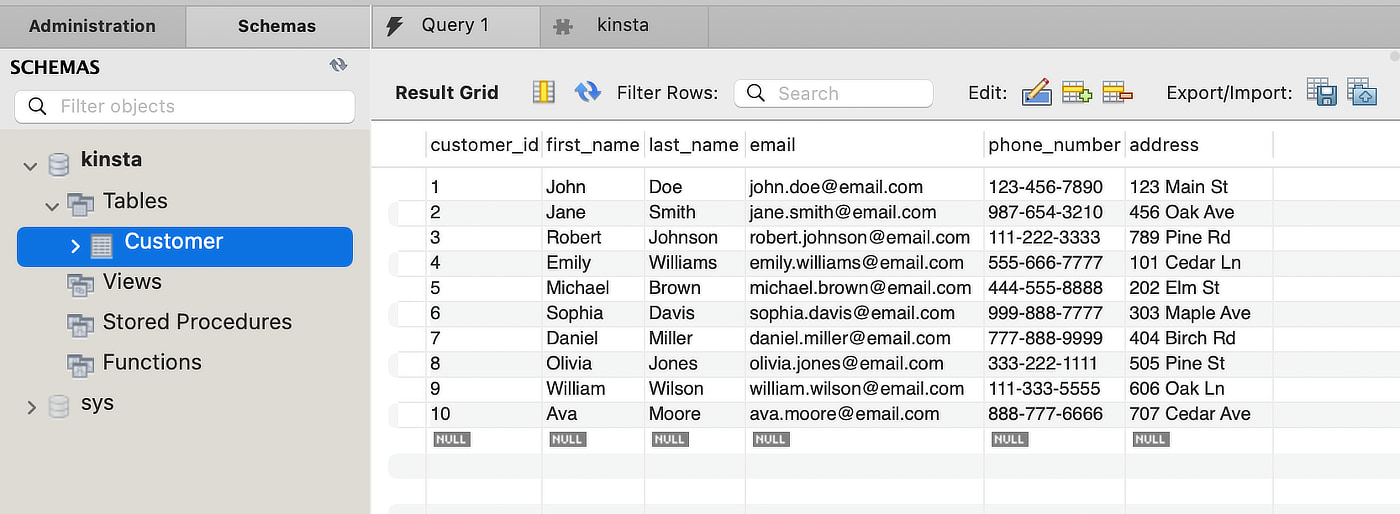
L’aggiunta di un indice B-Tree alla colonna first_name crea una struttura che facilita una ricerca più efficiente delle informazioni desiderate. La struttura assomiglia a un albero con il nodo radice in cima, che si dirama fino ai nodi foglia in fondo.
È simile a un albero ben organizzato, dove ogni livello guida la ricerca in base all’ordine dei dati.
Questa immagine mostra il percorso di ricerca di un indice B-Tree:
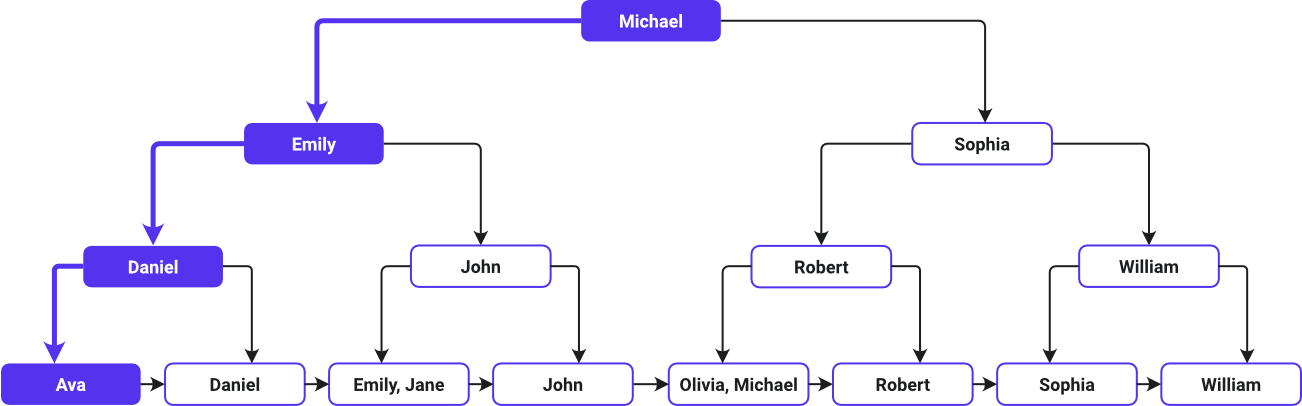
Ava è elencato per primo e William per ultimo in ordine alfabetico ascendente, come il B-Tree ha disposto i nomi. Il sistema B-Tree designa il valore centrale dell’elenco come nodo radice. Poiché Michael si trova al centro dell’elenco alfabetico, è il nodo radice. L’albero si ramifica poi con i valori a sinistra e a destra di Michael.
Man mano che si procede lungo i livelli dell’albero, ogni nodo offre altre chiavi (collegamenti diretti alle righe di dati originali) per guidare la ricerca attraverso i nomi ordinati alfabeticamente. Quindi, i dati relativi al nome di tutti i clienti si trovano nei nodi foglia.
La ricerca inizia confrontando Ava con il nodo radice Michael. Si sposta a sinistra dopo aver determinato che Ava compare prima di Michael in ordine alfabetico. Scende fino al figlio di sinistra (Emily), poi ancora a sinistra fino a Daniel, e ancora a sinistra fino a Ava prima di arrivare al nodo foglia che contiene le informazioni di Ava.
Il B-Tree funziona come un sistema di navigazione semplificato, guidando efficacemente la ricerca verso un luogo particolare senza controllare tutti i nomi presenti nel dataset. È come navigare in una directory accuratamente ordinata seguendo indicazioni strategiche che portano direttamente a destinazione.
Tipi di indici
Esistono diversi tipi di indici, con scopi diversi. Vediamoli qui di seguito.
1. Indici a livello singolo
Gli indici a livello singolo, o indici piatti, mappano le chiavi dell’indice ai dati della tabella. Ogni chiave dell’indice corrisponde a una singola riga della tabella.
La colonna customer_id è una chiave primaria della tabella Customer e funge da indice a livello singolo. La chiave identifica ogni cliente e collega le sue informazioni nella tabella.
| Indice (customer_id) | Puntatore di riga |
| 1 | Riga 1 |
| 2 | Riga 2 |
| 3 | Fila 3 |
| 4 | Fila 4 |
| .. | .. |
La relazione tra le chiavi customer_id e i dettagli dei singoli clienti è semplice. Gli indici a livello singolo eccellono in scenari con tabelle contenenti poche righe o colonne con pochi valori distinti. Colonne come stato o categoria, ad esempio, sono ottimi candidati.
Si può utilizzare un indice a livello singolo per semplici query che individuano una riga specifica in base a una sola colonna. La sua implementazione è semplice, diretta ed efficiente per i dataset più piccoli.
2. Indici multilivello
A differenza degli indici a livello singolo per il recupero organizzato dei dati, gli indici multilivello utilizzano una struttura gerarchica. Hanno più livelli di guida. L’indice di primo livello indirizza la ricerca verso un indice di livello inferiore e così via fino a raggiungere il livello foglia, che memorizza i dati. Questa struttura riduce il numero di confronti necessari durante le ricerche.
Consideriamo un indice a più livelli con le colonne indirizzo e customer_id.
| Indice (indirizzo) | Sottoindice (customer_id) | Puntatore di riga |
| 123 Main Street | 1 | Fila 1 |
| 456 Oak Ave | 2 | Fila 2 |
| 789 Pine Rd | 3 | Fila 3 |
| .. | .. | .. |
Il primo livello organizza gli indirizzi. Il secondo livello, all’interno di ogni indirizzo, organizza ulteriormente gli ID dei clienti.
Questa organizzazione è eccellente per i set di dati più estesi che richiedono una gerarchia di ricerca organizzata. È utile anche per colonne come cognome_nome con una cardinalità moderata (l’unicità dei valori dei dati in una particolare colonna).
3. Indici cluster
Gli indici cluster in MySQL dettano l’ordine logico dell’indice e l’ordine dei dati nella tabella. Se applichiamo un indice cluster alla colonna customer_id della tabella Customer, le righe vengono ordinate in base ai valori della colonna. Ciò significa che l’ordine dei dati nella tabella riflette l’ordine dell’indice clusterizzato, migliorando le prestazioni di recupero dei dati per modelli specifici e riducendo l’I/O su disco.
Questa strategia è efficace quando il modello di recupero dei dati si allinea con l’ordine degli ID dei clienti. È adatta anche alle colonne con una cardinalità elevata, come customer_id.
Sebbene gli indici clusterizzati offrano dei vantaggi per quanto riguarda le prestazioni di recupero dei dati per modelli specifici, è importante notare un potenziale svantaggio. L’ordinamento delle righe in base all’indice clusterizzato può influire sulle prestazioni delle operazioni di inserimento e aggiornamento, soprattutto se lo schema di inserimento o aggiornamento non corrisponde all’ordine dell’indice clusterizzato. Questo perché i nuovi dati devono essere inseriti o aggiornati in modo da mantenere l’ordine di smistamento, con conseguente sovraccarico di lavoro.
4. Indici non cluster
Gli indici non cluster offrono alle strutture di database una maggiore flessibilità. Supponiamo di utilizzare un indice non cluster su una colonna e-mail. A differenza di un indice cluster, non cambia l’ordine delle voci nella tabella.
Al contrario, costruisce una nuova struttura che mappa le chiavi – in questo caso gli indirizzi e-mail – con le righe di dati. Quando interroghiamo il database alla ricerca di un indirizzo e-mail specifico, l’indice non cluster guida la ricerca direttamente alla riga pertinente senza basarsi sull’ordine della tabella.
La flessibilità degli indici non cluster è il loro principale vantaggio. Permettono di effettuare ricerche efficienti su più colonne senza imporre un ordine ai dati memorizzati. Questo sistema rende gli indici non cluster versatili, in quanto sono in grado di soddisfare query che non seguono l’ordine primario della tabella.
Gli indici non cluster sono utili quando il modello di recupero dei dati è diverso dall’ordine alfabetico e per le colonne con cardinalità da moderata a elevata, come l’email.
Come creare gli indici
Ora che abbiamo esaminato cosa sono gli indici ad alto livello, vediamo alcuni esempi pratici di creazione di indici con MySQL Workbench.
Prerequisiti
Per seguirci, è necessario avere:
- Un database MySQL (compatibile con MariaDB)
- Un po’ di esperienza in SQL e MySQL
- MySQL Workbench
Come creare la tabella Customer
- Avviamo MySQL Workbench e colleghiamoci al server MySQL.
- Eseguiamo questa query SQL per creare una tabella Customer:
CREATE TABLE Customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(15), address VARCHAR(255) ); - Inseriamo i seguenti dati:
-- Adding Data to the Customer Table INSERT INTO Customer (customer_id, first_name, last_name, email, phone_number, address) VALUES (1, 'John', 'Doe', '[email protected]', '123-456-7890', '123 Main St'), (2, 'Jane', 'Smith', '[email protected]', '987-654-3210', '456 Oak Ave'), (3, 'Robert', 'Johnson', '[email protected]', '111-222-3333', '789 Pine Rd'), (4, 'Emily', 'Williams', '[email protected]', '555-666-7777', '101 Cedar Ln'), (5, 'Michael', 'Brown', '[email protected]', '444-555-8888', '202 Elm St'), (6, 'Sophia', 'Davis', '[email protected]', '999-888-7777', '303 Maple Ave'), (7, 'Daniel', 'Miller', '[email protected]', '777-888-9999', '404 Birch Rd'), (8, 'Olivia', 'Jones', '[email protected]', '333-222-1111', '505 Pine St'), (9, 'William', 'Wilson', '[email protected]', '111-333-5555', '606 Oak Ln'), (10, 'Ava', 'Moore', '[email protected]', '888-777-6666', '707 Cedar Ave');
Indici a livello singolo
Una tattica per ottimizzare le prestazioni delle query in MySQL e MariaDB è quella di utilizzare indici a livello singolo.
Per aggiungere un indice a livello singolo alla tabella Customer, usiamo l’istruzione CREATE INDEX :
-- Creating a Single-Level Index on "customer_id"
CREATE INDEX idx_customer_id ON Customer(customer_id);Se l’esecuzione va a buon fine, il database conferma la creazione dell’indice restituendo il seguente codice:
0 row(s) affected Records: 0 Duplicates: 0 Warnings: 0Ora le query che filtrano i dati in base ai valori della colonna customer_id vengono gestite in modo ottimale dal database, aumentando notevolmente l’efficienza.
Indici a più livelli
MySQL e MariaDB vanno oltre l’indicizzazione delle singole colonne offrendo indici multilivello. Questi indici coprono più di un livello o di una colonna, combinando i valori di più colonne in un unico indice per rendere più efficiente l’esecuzione delle query.
Usiamo il seguente codice per creare un indice multilivello in MySQL o MariaDB, concentrandoci sulle colonne address e customer_id:
-- Creating a Multi-Level Index based on "address" and "customer_id"
CREATE INDEX idx_address_customer_id ON Customer(address, customer_id);L’utilizzo di indici multilivello in modo strategico consente di migliorare notevolmente le prestazioni delle query, soprattutto quando si tratta di insiemi di colonne.
Indici cluster
Oltre all’indicizzazione individuale e multilivello, MySQL e MariaDB utilizzano gli indici cluster, uno strumento dinamico per migliorare le prestazioni del database allineando le righe di dati all’ordine dei puntatori dell’indice.
Ad esempio, l’applicazione di un indice cluster alla colonna customer_id della tabella Customer allinea l’ordine degli ID dei clienti.
-- Creating a Clustered Index on "customer_id"
CREATE CLUSTERED INDEX idx_customer_id_clustered ON Customer(customer_id);Grazie all’ordine ottimizzato dei dati, questa strategia migliora significativamente il recupero di modelli specifici e riduce l’I/O su disco.
Indici non cluster
Gli indici non cluster possono ottimizzare le query in base alle colonne senza forzare i dati in un determinato ordine. In MySQL e MariaDB, non è necessario specificare che un indice non è cluster.
L’architettura della tabella lo implica. Solo la chiave primaria o la prima chiave univoca non nulla può essere un indice cluster. Gli altri indici della tabella sono tutti implicitamente non cluster. Come esempio di indice non cluster, consideriamo il seguente:
-- Creating a Non-clustered Index on "email"
CREATE INDEX idx_email_non_clustered ON Customer(email);Gli indici non cluster permettono di effettuare ricerche efficienti su più colonne, ottenendo un database più versatile e reattivo.
Best practice e punti chiave
Scegliamo indici a livello singolo quando lavoriamo con colonne con una gamma ridotta di valori diversi, come lo stato o la categoria. Usiamo indici multilivello e non cluster per le colonne con una gamma di valori più ampia, come l’email.
I modelli di recupero dei dati che preferiamo sono fondamentali per scegliere tra indici cluster e non cluster. Per gli indici cluster, scegliamo colonne con una cardinalità elevata, come l’ID del cliente. Per gli indici non cluster, scegliamo colonne con cardinalità da moderata ad alta, come l’email.
Come ottimizzare gli indici
Per aumentare le prestazioni degli indici, possiamo utilizzare alcune strategie pratiche, come la copertura degli indici e la rimozione degli indici ridondanti.
1. Coprire gli indici
La copertura degli indici migliora le prestazioni delle query creando indici che coprono tutti i dati necessari. Il termine indice di copertura significa che un indice include tutte le colonne necessarie per soddisfare una query, evitando di dover accedere alle righe di dati.
-- Create a Covering Index on "first_name" and "last_name"
CREATE INDEX idx_covering_name ON Customer(first_name, last_name);2. Rimuovere le ridondanze
Un’altra opzione è quella di rimuovere gli indici ridondanti, ma è bene fare attenzione perché la rimozione degli indici può avere un impatto sulle prestazioni di alcune query.
-- Remove an Unnecessary Index
DROP INDEX idx_unnecessary_index ON Customer;Esaminando e rimuovendo regolarmente gli indici ridondanti è possibile garantire una struttura del database snella ed efficiente.
3. Evitare l’indicizzazione eccessiva
Si possono evitare le insidie più comuni come l’indicizzazione eccessiva. Se da un lato gli indici migliorano le prestazioni delle query, dall’altro la creazione di un numero eccessivo di indici può diminuire i rendimenti. È fondamentale trovare un equilibrio ed evitare l’indicizzazione eccessiva, che può comportare un aumento dei requisiti di archiviazione e un potenziale degrado delle prestazioni.
4. Analizzare i modelli di query
Un’altra insidia comune è quella di trascurare l’analisi dei modelli di query prima di creare gli indici. Comprendere le query eseguite di frequente e concentrarsi sull’indicizzazione delle colonne utilizzate nelle clausole WHERE o nelle condizioni JOIN è essenziale per ottenere prestazioni ottimali.
Riepilogo
Questo articolo ha esplorato l’indicizzazione di MySQL e MariaDB, sottolineando l’efficienza del meccanismo B-Tree. Abbiamo illustrato i fondamenti dell’indicizzazione e i vari tipi di indice (a livello singolo, multilivello, clusterizzato e non clusterizzato).
Che si tratti di ottimizzare i carichi di lavoro in lettura o di migliorare le prestazioni in scrittura, il servizio di Hosting di Database di Kinsta offre agli utenti di MySQL e MariaDB una soluzione affidabile e performante per le loro esigenze di indicizzazione. Provate subito l’Hosting di Database di Kinsta per trarre vantaggio da MySQL e MariaDB e dalle loro capacità di indicizzazione.


