
今年に入り、多くのメディアで、自動化されたトラフィックが人間によるトラフィックを上回るという歴史的な転換点が報じられています。そして、その転換を裏付ける数字は、インターネットの歴史における多くの節目と比べても、見過ごすことのできないものです。
最も広く引用されているデータは、Impervaが公開した『2025 Bad Bot Report』です。これは、2013年から自動化トラフィックの動向を追跡してきた年次レポートシリーズの第12版にあたります。2024年のトラフィックパターンを分析したこのレポートによると、自動化されたアクティビティは、記録開始以来初めてトラフィック全体の50%を超え、51%に達しました。ただし、Impervaがこの水準に迫ったのは今回が初めてではありません。2024年版のレポートでは、ボットアクセスの割合は49.6%と報告されており、今回の結果は突然50%を超えたというよりも、複数のベンダーや測定手法で長年にわたって示されてきた傾向が裏付けられたものといえます。
Cloudflare、Akamai、TollBit、Human Securityも同様の傾向を示すデータを公開しています。Kinstaでも、マネージドインフラ全体で処理した100億件を超えるリクエストを分析した結果、同じ傾向が確認されました。AIボットによるトラフィックは1年間で300%増加しており、その影響はもはや抽象的なものではありません。
人間によるトラフィックと自動化トラフィックの差はまだわずかですが、その意味するところは非常に大きいものです。そこで今回は、このボットアクセスの変化がウェブをどのように形作っていくのか、少し先の未来を見据えながら考えてみましょう。
ボットとはそもそも何?従来の定義が通用しなくなった理由
従来、ボット(ロボットの略)とは、人の操作を必要とせず、自動でタスクを実行するソフトウェアアプリケーションを指します。最もよく知られている例が、検索のためにウェブページをクロールしてインデックス化するGoogleの自動クローラー「Googlebot」です。このほかにも、稼働状況の監視、インデックス作成、アクセス解析、セキュリティスキャンなど、ウェブを円滑に運用するためのさまざまな役割を担うボットが存在します。
こうしたボットの多くは無害であり、むしろ有益です。しかし近年では、それとは別に、はるかに大きな問題となる種類のボットが登場しています。それが、大規模に動作するAIクローラーです。悪意の有無にかかわらず、そのアクセス規模だけでインフラに大きな負荷をかけることがあります。
Kinstaの『AI・ボット時代におけるトラフィックの実態』の中で、Cloudflareの元データインサイト部門責任者であるDavid Belson氏は、「現在起きている問題の多くは、悪意のある攻撃ではない。ボットが大規模かつ非効率に動作していることが本当の問題」と述べています。
これまでボットは、JavaScriptを実行できず、ポインターの動きを再現できず、実際のブラウザーのようなセッションを維持することも、IPアドレスを効果的に切り替えることも難しかったため、比較的容易に見分けることができました。しかし、その状況は大きく変わっています。AIを活用した自動化により、ボットは驚くほど高度に人間の行動を模倣できるようになり、従来の検出手法で利用されていた典型的なシグナルを巧みに隠せるようになっています。
同氏は、「中には、昨日まで何をしているのかも分かっていなかった人が、ノリで作って公開したようなボットもある。robots.txtすら確認していないことも珍しくない」とも述べています。
その結果、ボット対策の仕組みは、「誰がアクセスしているか(IDベース)」 を見極める方法から、「どのような振る舞いをしているか(行動ベース)」 を分析する方法へと、徐々に移行しつつあります。
「人間によるトラフィック」の定義
誤解のないよう補足すると、ここでいう「人間によるトラフィック」とは、単にクリックや目に見えるユーザー操作だけを指すものではありません。ウェブページやアプリケーションを配信・表示する過程で発生する、さまざまなリクエストも含まれます。
ユーザーが1ページを閲覧するだけでも、数十件、多い場合は数百件ものリクエストが発生します。これには、HTML、CSS、JavaScript、フォント、画像、API、アクセス解析用スクリプト、広告アセットなど、現代のウェブページを表示するために必要なさまざまなリソースへのリクエストが含まれます。
この違いは重要です。というのも、ボットアクセスと人間によるトラフィックを比較する際は、実際にオンラインにいる人の数ではなく、リクエスト数やネットワークアクティビティを基準に測定されるのが一般的だからです。たとえ攻撃的なボットの数が少なくても、ページへの繰り返しアクセスやAPIのスクレイピング、アセットのダウンロード、自動化された処理をマシン規模で実行することで、膨大なトラフィックを発生させることがあります。
ボットアクセス急増の背景
ボットアクセスの増加を加速させている要因は、生成AIだけではありません。
1. 金銭的な利益
かつて、悪意のあるオンライン活動の主な動機といえば、いたずらや好奇心、あるいは技術力を誇示することでした。しかし、現在のインターネットでは、個人や大規模な犯罪組織による違法な活動が、数百万ドル規模の利益を生み出すことも珍しくありません。
詐欺、データの窃取、システムの悪用や破壊、市場操作、大規模なコンテンツスクレイピング、ランサムウェアの拡散など、違法な収益を目的としたさまざまな活動が、自動化システムや悪意のあるボットによって大規模に行われています。
個人情報への不正・違法なアクセスは巨大なビジネスとなっており、AIを活用したボットによって、こうした活動の検知、追跡、阻止はますます難しくなっています。
2. 不十分な規制環境
インターネットは、法律や法執行、司法管轄が国や地域によって大きく異なる、グローバルかつ断片化された環境です。このような状況は、悪意のある自動化が広がりやすい土壌となっています。
規制が十分に整っていない環境では、有害なAIボットが活動しやすくなります。その理由は、法律や法執行、そして国際的な連携が、AIによる自動化の急速な進化に追いついていないためです。これは以前からIT分野の課題ではありましたが、AIの発展スピードと規模によって、その問題はさらに深刻化しています。
3. ユーザーエージェントが信頼できるシグナルではなくなっている
ユーザーエージェントは、長年にわたり、ウェブ上で最も信頼できる識別情報の1つでした。リクエスト元のブラウザーやオペレーティングシステム、場合によってはデバイスの情報も含まれており、正規のブラウザや検索エンジンのクローラー、モバイル端末、自動化ボットを識別するための重要な手がかりとして利用されてきました。
しかし、その前提は崩れつつあります。現在のボットは、ユーザーエージェントを隠蔽したり、偽装したり、改ざんしたりする能力が大きく向上しており、その情報自体の信頼性は低下しています。悪意のあるボットは、正規のブラウザやモバイル端末になりすますだけでなく、信頼できるクローラーを装うことさえ可能です。さらに、AIによる自動化によって、高度ななりすましを低コストで大規模に展開できるようになったことも、この傾向に拍車をかけています。
その結果、現在のセキュリティシステムは、アクセス元の識別情報(ID)だけでなく、実際の振る舞い(行動パターン)を重視する方向へと移行しつつあります。
現在のボットはどのように見分けるのか
IPレピュテーションなど、従来の識別情報だけでは十分に信頼できなくなったため、現在の検知システムでは、自動化や悪意のある活動を示す行動パターンに重点が置かれるようになっています。
人間には再現できない速度や規模、頻度で送られてくるリクエストは、今でも最も分かりやすい警告サインの1つです。また、ログインの繰り返し試行、規則的なスクレイピング、大量のAPI利用、短時間に集中する大量のリクエストなども、自動化されたアクセスであることを示す典型的な特徴です。
Kinstaのインフラで収集したデータでは、あるサイトに対して1体のボットが24時間で375万件もの「カートに追加(add-to-cart)」URLへのリクエストを送信した事例が確認されました。これは約23ミリ秒ごとに1件のリクエストを24時間送り続けた計算になり、そのすべてがキャッシュされない新規リクエストとしてサーバーに到達していました。
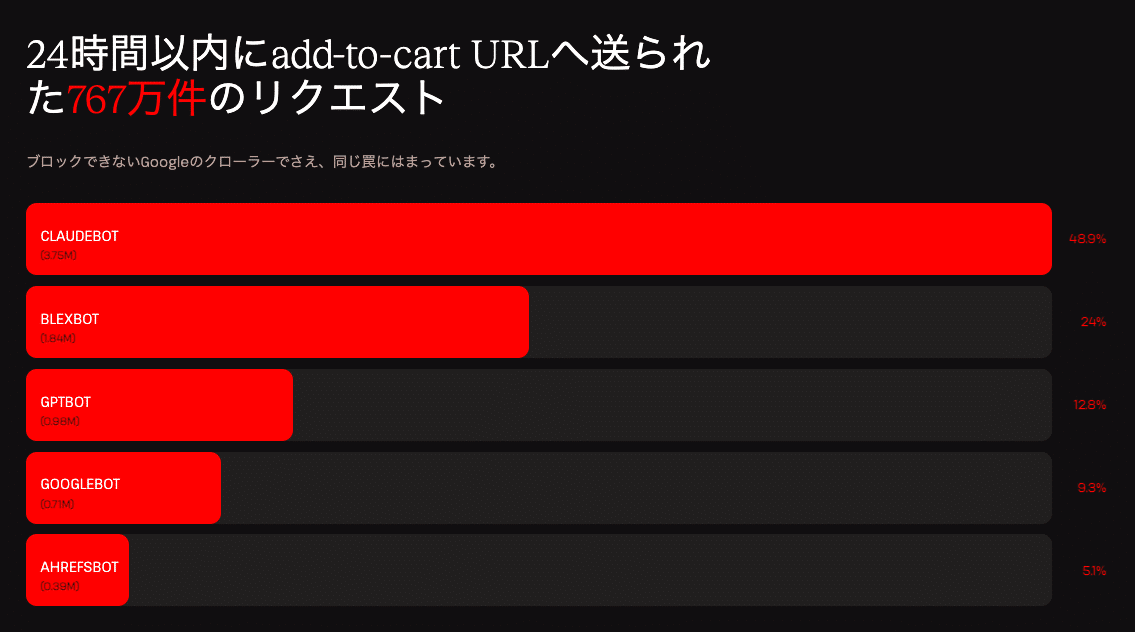
人間によるブラウジングは、ある程度予測しにくい動きをします。一方で、ボットは高度なものであっても、JavaScriptの実行や現実的なブラウザセッション、マウス操作を巧みに再現できたとしても、繰り返しの多い操作パターンや規則的なナビゲーション、不自然なほど体系的なデータ取得を行う傾向があります。そのため現在では、アクセス元が名乗る情報ではなく、実際の振る舞いに基づいて判定する手法へと移行しています。
Kinstaでも、ホスティングするサイト全体のトラフィックを分類する際には、この考え方を採用しています。単純に「人間」か「ボット」かで判断するのではなく、ボット対策システムでは、検証済みボット、人間の可能性が高い、ボットの可能性が高い、自動化トラフィック、未分類トラフィック、悪意のあるトラフィックなどのカテゴリに分類しています。さらに、正規のクローラーであっても、意図にかかわらずインフラに大きな負荷をかける高頻度のAIクローラーについては、別のカテゴリとして識別しています。
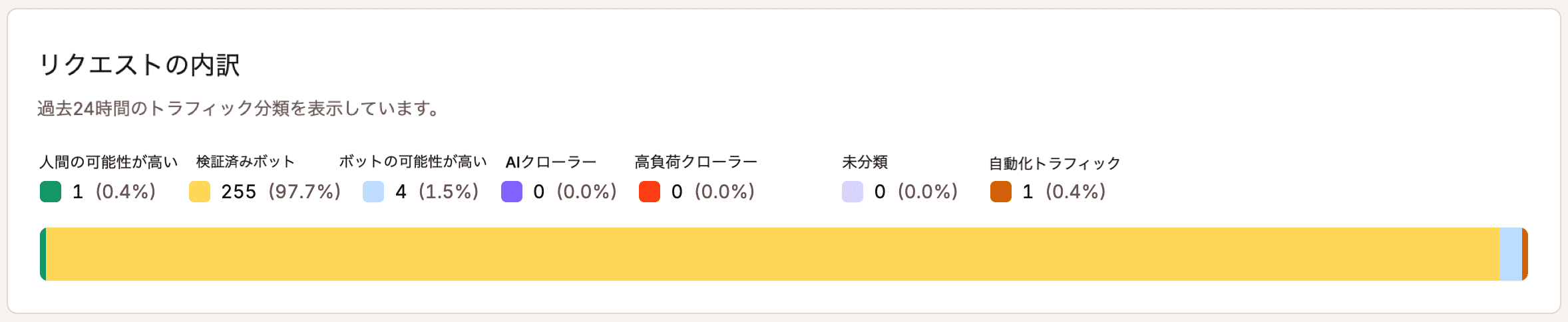
各カテゴリは、それぞれ異なる方法で対処されます。例えば、設定に問題のあるAI学習用クローラーへの対応と、クレデンシャルスタッフィング攻撃への対応はおないでは無いためです。
Kinstaでは、プラットフォームレベルの対策機能により、悪意のあるトラフィックと判定されたアクセスの約15〜20%を、サイトに到達する前の段階でブロックしています。さらに、その基盤となる防御に加えて、ボット対策機能を利用すると、トラフィックの特性や許容できるリスクに応じて、追加のカテゴリに対して検証したり、ブロックしたりすることができます。

今後の影響と注目すべきトレンド
こうしたシステムの進化による影響は、もはやサイバーセキュリティだけにとどまりません。インフラ、コンテンツ配信、アクセス解析、ECサイト、さらにはウェブ全体の品質にまで及び始めています。
ボットアクセスの増加を抑えるような変化は今後期待できるのか。現在のデータを見る限り、その兆しはありません。AIボットによるトラフィックは1年間で300%増加し、AIボットのアクセス比率も、200回に1回から31回に1回へと、12か月足らずで大きく変化しました。
サーバーインフラのコスト
ボットアクセスの増加による最も直接的な影響の1つが、インフラコストの上昇です。サイトへのリクエストは1件ごとに、帯域幅、コンピューティングリソース、データベースクエリ、メモリ、キャッシュシステム、ストレージなどのリソースを消費します。
この問題は、WooCommerceやサイト内検索、多数のプラグインを利用するWordPressサイトで特に深刻です。キャッシュから配信される静的ページとは異なり、動的エンドポイントでは、リクエストのたびにサーバー側で実際の処理が発生します。クエリ文字列のループに陥ったボットは、キャッシュ可能なページと、処理負荷の高いページを区別できません。実際に、Kinstaで管理しているあるサイトでは、このようなループによって30日間で5億5,000万件ものリクエストが発生し、専用の緩和ルールによってようやく検知・対処されました。
KinstaのCTOであるDaniel Patakiは、「インフラの観点では、『単なるボットアクセス』というものは存在せず、すべてのリクエストが実際の処理負荷になる。非効率なクロールは、規模が大きくなるにつれて、単なるトラフィックの問題から、リソースの問題に変化する」という見解を述べています。
こうした影響を特に受けやすいのが、小規模なメディアや個人サイトの運営者です。大規模な組織が利用できるような高度なボット対策を導入できないケースが少なくないためです。
アクセス解析の精度低下
AIボットによるアクセスは、アクセス解析の指標にも大きな影響を及ぼしています。水増しされたページビュー、実態のないエンゲージメント、人工的なリファラートラフィック、自動化されたユーザー操作などによって、実際とは異なるデータが記録され、誤った意思決定につながる可能性があります。
さらに、ボットが人間の行動をより巧みに模倣するようになったことで、この問題は一層深刻になっています。Google アナリティクスのようにJavaScriptベースで計測するツールでは、多くのボットがJavaScriptを実行しないため、ボットアクセスを過少に計測する傾向があります。一方、IPアドレスごとのリクエストをすべて記録するサーバーレベルのアクセス解析では、JavaScriptでは検出できないボットも含めて計測されるため、実際より多く計上されることがあります。
Kinstaでは、MyKinstaの分析機能はサーバーレベルのアクセスログをもとに集計されており、既知のボットのユーザーエージェントは課金対象の訪問数から除外されています。しかし、人間の行動を巧みに模倣する自動化トラフィックは、レポート上では通常のアクセスとして記録される場合があるため、この方法にも限界があります。
そのためKinstaでは、2025年11月以降、MyKinstaの「分析」画面の「上位リクエスト」タブにボットを含むすべてのトラフィックを表示するようにしました。これにより、実際にインフラへ到達しているトラフィックと、課金対象として計上される訪問数の違いをより正確に把握できるようになっています。
ページビューは増えているのに、ブランド名での検索数やコンバージョン数、ダイレクトトラフィックが横ばいのままであれば、その差はボットによるトラフィックである可能性が極めて高いといえます。
「デッドウェブ」の到来
低品質なAI生成コンテンツがインターネット上にあふれつつある現象は、「デッドウェブ(dead web)」と呼ばれています。この説には憶測を含む極端な主張もありますが、AIによって、自動生成された記事や偽のレビュー、スパムブログ、自動生成メディアなど、価値の低いコンテンツを大規模に作成できるようになったことは疑いようがありません。
その結果、インターネットは有益で信頼できる情報を見つけることがますます難しい環境になりつつあります。
悪意のあるボットによるセキュリティリスクの増大
AIを活用したボットは、サイバー攻撃をこれまで以上に高度化させています。クレデンシャルスタッフィング攻撃、アカウント乗っ取り、APIの悪用、フィッシング、脆弱性スキャン、ランサムウェアの展開などは、自動化によって、より高速かつ大規模、さらに状況に応じて柔軟に実行できるようになっています。
また、AIは失敗から学習し、手法を継続的に改善できるため、従来のルールベースの防御だけでは対応がますます難しくなっています。
スクレイピングエコノミーと経済構造の変化
これまで、Googlebotのような検索クローラーは、コンテンツ制作者との間に比較的健全な経済的関係を築いていました。コンテンツをクロールしてインデックス化し、その見返りとして、検索結果から元のサイトへトラフィックを送り返していたためです。
しかし、最新のAIスクレイピングシステムは、この関係を大きく変えつつあります。AIはコンテンツを収集して要約し、その内容を別の場所で直接ユーザーに提供するため、元のサイトへトラフィックが戻らないケースが増えています。
その結果、「スクレイピングエコノミー」とも呼べる状況が生まれつつあります。これは、サイト運営者がコンテンツ制作やインフラ維持のコストを負担する一方で、自動化システムがその価値の多くを享受するという構図です。
AI搭載ブラウザーと自律型エージェント
こうしたシステムは、単なるクローリングの段階をすでに超えています。AIエージェントはサイトの閲覧だけでなく、アプリケーションの操作、情報収集、オンラインショッピング、予定の調整、フォーム入力、さらには意思決定まで、人間がほとんど、あるいはまったく関与しなくても実行できるようになっています。
こうしたシステムの性能が向上し続けるにつれて、人間による活動と機械による活動の境界はますます曖昧になっています。この変化は将来、「ウェブトラフィック」という言葉そのものの意味を根本から変える可能性があります。
インターネットはもともと、人間が主な利用者であることを前提として設計されていましたが、その前提は急速に崩れつつあります。AIによる自動化がさらに自律性を高めるなか、これからのウェブにとって重要なのは、人間とボットを見分けることではなく、どのような機械主体のインターネットを受け入れるのかを決めることなのかもしれません。
人間と機械を隔てる境界線は、もはや存在しない
この変化がもたらす影響は、多くのサイト運営者が考えている以上に広範囲に及びます。インフラコストは増加し、アクセス解析の信頼性は低下しています。また、スクレイピングエコノミーによって、コンテンツを生み出すサイト運営者から、それを収集・活用するシステムへと価値が移りつつあります。そして、AIエージェントがウェブの閲覧や情報収集、意思決定まで自律的に行えるようになった今、「ボットアクセスをどう管理するか」という問いは、さらに大きな問いへと変わり始めています。
インターネットはもともと、すべてのリクエストの先には人間がいるという前提のもとに構築されました。しかし、その前提は急速に通用しなくなっており、インフラや法規制、そしてビジネスモデルは、その変化に十分対応できていません。
すでに私たちは、人間が介在することなく、機械同士がやり取りを行う時代に足を踏み入れています。
この変化を裏付けるデータの詳細は、『AI・ボット時代におけるトラフィックの実態』レポートをご覧ください。また、すでにサイトでボットアクセスによる影響を受けている場合は、Kinstaのボット対策機能をご利用ください。サイトトラフィックを柔軟に制御することができます。

2009年からWordPressの対面・オンライン講師として活動するほか、サイト開発やコンテンツ制作にも携わっている。これまでに、WordPress関連企業向けの教育動画を制作し、多数の記事を執筆してきた。

